在上一篇里我们介绍了 CPU 前端微架构中取指单元和分支预测等关键部件的基本原理及探测方法,本篇我们继续讨论CPU微架构中后端部分的几个核心部件:
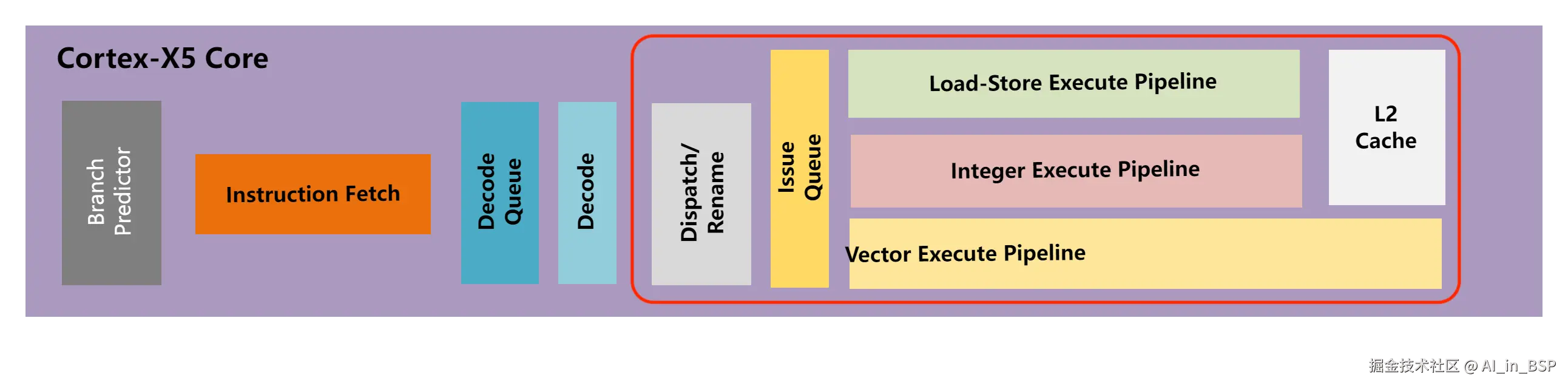
CPU后端主要作用
根据我们前面介绍的知识,前端负责取指和译码,而后端则主要负责指令的调度执行:
调度 (Scheduling) :将前端送来的指令译码分发到合适的执行单元;
执行 (Execution) :在 ALU、FPU、Load/Store 等不同功能部件中完成运算或访存操作;
回写 (Retirement):当所有依赖满足后,将结果提交到寄存器文件或存储层级,保证架构状态的正确性。
为了完成上面的逻辑处理工作,后端通常由重排序缓冲区(ROB)、调度与发射逻辑、执行单元(整数/浮点/特殊功能单元) 和 Load/Store 队列(LSQ) 组成,后端微架构直接决定了 CPU 的乱序执行能力和指令级并行度(ILP),从而对CPU整体性能表现有非常重大的影响。
乱序执行与调度窗口
现代高性能 CPU 的后端几乎都采用 乱序执行 (Out-of-Order Execution, OoO),其核心思想是:只要指令操作数所需资源准备好,指令就可以立即被调度执行,而不必严格按照顺序等待前一条指令的完成。负责完成指令乱序的关键部件主要包括有:
ROB (Reorder Buffer) 重排缓冲区,用于保证最终提交结果仍然按照程序顺序。
对于ROB,我们可以把它理解成一个循环队列,Decode译码完成的指令按顺序进入,但是却不需要按照该顺序执行,只要指令依赖的寄存器和执行单元等资源Ready就可以派发,因此每个ROB slot中就记录了该指令的执行信息,包括指令当前状态、目的寄存器以及指令的依赖和被依赖信息,而ROB的大小就直接影响CPU可以支持的乱序调度指令的数量,同时乱序窗口大小也直接决定了 CPU 能否"隐藏"访存延迟。比如先进的性能CPU乱序ROB调度窗口基本都在300以上(Cortex-X4的ROB在~380左右,Apple M4的ROB在~400左右),因此即使在遇到部分指令 L2 miss(L2 miss L3 hit的latency一般在20~50 cycle左右)甚至L3 miss需要去外部总线访存时,仍然找到可并行执行的指令,从而避免流水线空转。
寄存器重命名 (Register Renaming) 消除寄存器假依赖 我们知道程序代码在编译器阶段生成指令段时只能看到有限的逻辑寄存器(如 AArch64 只有 32 个通用寄存器)。如果直接用这些逻辑寄存器去做数据依赖检查,就会出现很多"假依赖":
- 写后写 (WAW):指令 B 重写某寄存器,但其实和指令 A 的结果无关;
- 写后读 (WAR):指令 B 先写某寄存器,指令 A 再读,顺序被强行绑定。
因此在重命名阶段引入物理寄存器文件(Physical Register File, PRF) ,通常远大于逻辑寄存器数目(一般在200+以上)以及寄存器别名表(Register Alias Table, RAT) 复杂将逻辑寄存器动态映射到更大的物理寄存器集合,当遇到一条指令时,Rename 分配一个新的物理寄存器,并更新 RAT,这样消除了 WAW/WAR假依赖,只保留真正的 RAW(读后写),例如
css
I1: ADD x1, x2, x3 ; x1 ← x2 + x3
I2: ADD x1, x4, x5 ; x1 ← x4 + x5- 如果只有逻辑寄存器:I1 和 I2 都写 x1,会产生 WAW 假依赖。
- Rename 后:I1 映射到 P10,I2 映射到 P11,它们互不冲突。
CPU后端微架构探测原理
下面我们以探测ROB大小为例进行介绍,借助我们上一篇探测CPU前端微架构的核心原理,我们需要构造占用ROB slot瓶颈并且最好不消耗任何后端执行单元的资源,因此NOP指令就是最好的对象,因为当前已知的绝大多数CPU架构都会为NOP分配ROB slot但是基本上所有的CPU都不会为NOP指令分配后端资源,仅在Decode或Rename阶段就标记为指令完成,因此我们需要引入一条执行时间较长的指令来阻塞ROB,因为虽然指令在后端的执行是乱序的,但是完成后的指令在ROB slot只是标记为完成状态,指令的Retire退出释放ROB slot还是要按照之前进入的顺序,所以我们可以在ROB队列最前端放置一条执行时间长的FSQRT指令,一般执行时延在10个cycle以上,当然,对于现代CPU一般 300+以上的ROB大小,1个FSQRT还不足以阻塞后面的NOP指令,因此我们可以逐步增加FSQRT的数量直到测试的结果出现明显的因阻塞而导致的延迟增加现象;
核心的测试代码块如下,通过对应指令机器码构造一段核心代码块由固定数量的FSQRT+不断增加的NOP指令构成:
C
uint32_t o = 0;
for (int i = 0; i < FSQRT_NUM; i++) {
ibuff[o++] = 0x1e61c000; // fsqrt d0, d0
}
for (int i = 0; i < pp->probeCount; i++) {
ibuff[o++] = 0xd503201f; // nop
}
return o;我们同样借助上一篇中测量该核心代码块的执行延时来进行结果判断,在SM8750性能核上测试结果如下: 可以看到,NOP指令数量为661左右出现突变,此时的大小就是我们测得的该CPU的ROB Size大小。 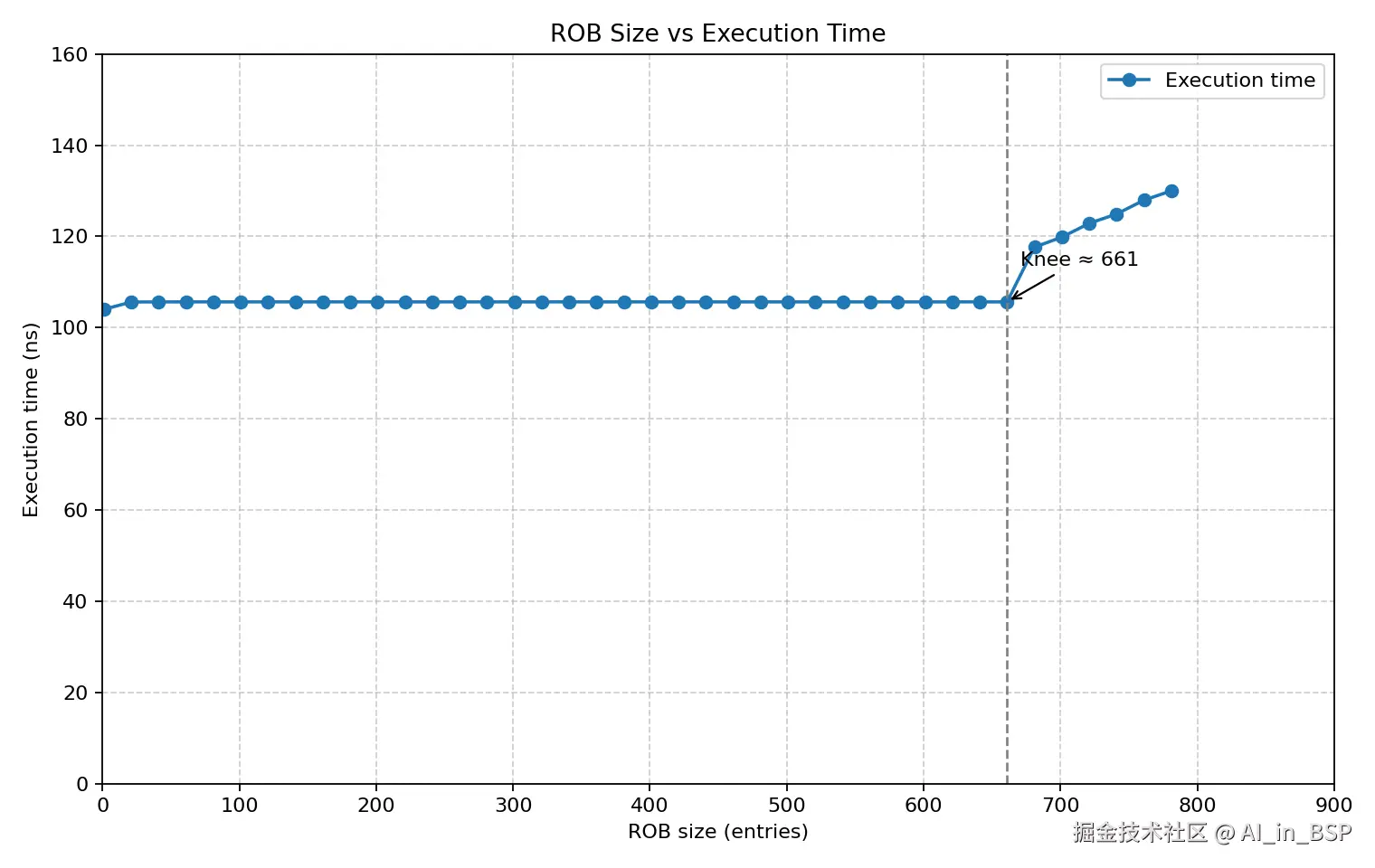
保留站 (Reservation Station)
保留站RS是连接 Rename 与执行单元的缓冲与调度逻辑,我们可以把它类比为等待调度的"候车大厅",Rename完成的指令进入保留站,同时将每条指令的操作数tag写入RS slot中,当tag对应的寄存器写回时就指令就标记为Ready,而一旦指令对应的所有源操作数都Ready,并且执行单元空闲,该RS slot就被选中发射出去。RS 的大小决定了能同时等待多少条指令,太小会导致乱序深度受限,太大会增加唤醒/选择电路复杂度,并且现代CPU通常都是设计成不同的功能单元配备独立的RS(如整数 RS、浮点 RS、Load/Store RS),以此来减少不同操作之间的耦合,从而从硬件上避免全局广播带来的功耗损耗。而我们常见的发射宽度 (Issue Width) 则是表示每个周期能从保留站送入执行单元的最大指令数,例如"6-wide"表示 CPU 每周期最多能发射 6 条 µOps 到后端执行,Apple M4是10-wide,而 Cortex-X4 则是 6-wide,发射宽度直接影响CPU的峰值 IPC。过宽的 issue发射宽度设计能提高 ILP,但指令本身有执行依赖,同时为了防止指令饿死等情况,因此对依赖检查、仲裁逻辑的电路复杂度与功耗都要求极高。
执行单元 (Execution Unit)
指令被发射后,会进入不同的功能单元,这里主要包括:
- 整数单元 (ALU):处理加减、逻辑运算、移位等,简单运算例如add通常花费1 cycle,复杂乘除通常在3~10 cycle左右;
- 乘法/除法单元 (IMUL/IDIV):通常延迟较大,部分 CPU 可能只提供少量专用单元。
- 浮点/向量单元 (FPU):处理浮点运算FMAC、FSQRT以及向量加减,由于AI应用的普及,现代CPU架构都在不断强化向量化支持,例如高峰值算力的指令NEON/SVE, AVX/AVX-512等。
- Load/Store 单元 (LSU):负责内存读写,和 Cache/TLB 强相关,是内存延迟的主要瓶颈点。
- 分支单元 (BRU):与上一篇我们讲到的前端分支预测相呼应,负责真正计算分支条件。
CPU微架构设计中后端执行单元的数量是一个关键指标,因此我们对后端的探测也以对应类型的后端执行单元端口数量为主,以整数 ALU 数量为例,我们主要是通过构造完全独立的整数加法指令流,测量 IPC 上限来得到 ALU 数量。而对于浮点单元延迟,则主要是构造依赖链(如连续FSQRT,前后寄存器相同),观测每条指令平均时延来近似获得单条浮点指令延迟。
高通8750实测结果
下面是通过构造对应指令测量其在SM8750性能核上的执行throughput得到的结果:
Decode & Rename Width: (scalar nop and move)
| instruction | latency | throughput |
|---|---|---|
| nop | - | 8.02 |
| mov (x -> x) | 0.87 | 8.02 |
| mov (x -> x; chain) | - | 8.02 |
| mov / movz (imm; 0x00) | - | 6.02 |
| mov / movz (imm; 0x01) | - | 6.02 |
| mov / movz (imm; 0xffc) | - | 6.02 |
| movk (0x00) | - | 6.02 |
| movk (0x01) | - | 6.02 |
| movk (0x1ffc) | - | 6.02 |
| eor | 1.00 | 5.98 |
| sub | 1.00 | 5.96 |
ALU size: (Scalar integer add/sub/div/adc/adcs)
| instruction | latency | throughput |
|---|---|---|
| add (reg) | 1.00 | 5.97 |
| sub (reg) | 1.00 | 5.96 |
| neg (reg) | 1.00 | 6.02 |
ALU size: (Scalar integer multiply and multiply-accumulate)
| instruction | latency | throughput |
|---|---|---|
| mul | 3.00 | 2.00 |
| mneg | 3.00 | 2.00 |
| madd | 3.00 | 2.00 |
| msub | 3.00 | 2.00 |
| smull | 3.00 | 2.00 |
| smnegl | 3.00 | 2.00 |
| smaddl | 3.00 | 2.00 |
| smsubl | 3.00 | 2.00 |
| smulh | 3.00 | 2.00 |
| umull | 3.00 | 2.00 |
| umnegl | 3.00 | 2.00 |
| umaddl | 3.00 | 2.00 |
| umsubl | 3.00 | 2.00 |
| umulh | 3.00 | 2.00 |
ALU size: (Scalar integer divide)
| instruction | latency | throughput |
|---|---|---|
| sdiv | 7.00 | 0.50 |
| udiv | 7.00 | 0.50 |
BRU: (b/blr/cbz/tbz)
| instruction | latency | throughput |
|---|---|---|
| b (pc+4) | 1.01 | 0.99 |
AGU load: (Scalar load)
| instruction | latency | throughput |
|---|---|---|
| ldr (imm; ofs = 0) | 3.00 | 3.81 |
| ldr (imm; ofs = 16) | 3.00 | 3.81 |
AGU store: (Scalar store)
| instruction | latency | throughput |
|---|---|---|
| str (imm; ofs = 0) | - | 2.00 |
| str (imm; ofs = 16) | - | 2.00 |
AGU(ld/st): (share load & store)
| instruction | latency | throughput |
|---|---|---|
| ldr | - | 3.81 (~ 61/16, 42/11) |
| ldr x 2 | - | 1.90 (~ 19/10) |
| ldr x 3 | - | 1.27 (~ 14/11) |
| ldr x 4 | - | 0.95 (~ 1/1) |
| ldr x 5 | - | 0.76 (~ 13/17, 3/4) |
| str | - | 2.00 (~ 2/1) |
| str x 2 | - | 1.00 (~ 1/1) |
| str x 3 | - | 0.67 (~ 2/3) |
| str x 4 | - | 0.50 (~ 1/2) |
| str x 5 | - | 0.40 (~ 2/5) |
| ldr x 3 // str x 1 | - | 0.44 (~ 7/16) |
| ldr x 2 // str x 2 | - | 0.37 (~ 3/8) |
| ldr x 3 // str x 2 | - | 0.31 (~ 5/16) |
FPU: (floating add, sub, abs)
| instruction | latency | throughput |
|---|---|---|
| fadd.h (scl) | 3.00 | 4.01 |
| fadd.s (scl) | 3.00 | 4.01 |
| fadd.d (scl) | 3.00 | 4.00 |
| fadd.h (vec) | 3.00 | 4.01 |
| fadd.s (vec) | 3.00 | 4.01 |
| fadd.d (vec) | 3.00 | 4.01 |
| fsub.h (scl) | 3.00 | 4.01 |
| fsub.s (scl) | 3.00 | 4.01 |
| fsub.d (scl) | 3.00 | 4.01 |
| fsub.h (vec) | 3.00 | 4.01 |
| fsub.s (vec) | 3.00 | 4.01 |
| fsub.d (vec) | 3.00 | 4.01 |
| fabs.h (scl) | 2.00 | 4.01 |
| fabs.s (scl) | 2.00 | 4.01 |
| fabs.d (scl) | 2.00 | 4.01 |
| fabs.h (vec) | 2.00 | 4.01 |
| fabs.s (vec) | 2.00 | 4.01 |
| fabs.d (vec) | 2.00 | 4.01 |
FPU: (Floating point max / min)
| instruction | latency | throughput |
|---|---|---|
| fmax.h (scl) | 2.00 | 4.01 |
| fmax.s (scl) | 2.00 | 4.01 |
| fmax.d (scl) | 2.00 | 4.01 |
| fmax.h (vec) | 2.00 | 4.01 |
| fmax.s (vec) | 2.00 | 4.01 |
| fmax.d (vec) | 2.00 | 4.01 |
| fmin.h (scl) | 2.00 | 4.01 |
| fmin.s (scl) | 2.00 | 4.01 |
| fmin.d (scl) | 2.00 | 4.01 |
| fmin.h (vec) | 2.00 | 4.01 |
| fmin.s (vec) | 2.00 | 4.01 |
| fmin.d (vec) | 2.00 | 4.01 |
FPU: (Floating point multiply)
| instruction | latency | throughput |
|---|---|---|
| fmul.h (scl) | 4.00 | 4.01 |
| fmul.s (scl) | 4.00 | 4.01 |
| fmul.d (scl) | 4.00 | 4.01 |
| fmul.h (vec) | 4.00 | 4.01 |
| fmul.s (vec) | 4.00 | 4.01 |
| fmul.d (vec) | 4.00 | 4.01 |
测试结果汇总
根据上面的测试结果我们就可以得到SM8750 Oryon的CPU微架构后端配置:
| Components | Qualcomm x-lite Oryon |
|---|---|
| Decode Width | 8 |
| Issue Width | 8 |
| IX | 6 |
| VX | 4 |
| ALU | 6 |
| BRU | 2 |
| LSU | 4 |
| AGU | 4 |
| AGU(ld+st) | 0 |
| AGU(ld) | 4 |
| AGU(st) | 2 |
访存系统与 Load/Store 队列
除了执行逻辑的乱序,现代CPU为了支持访存乱序,还设计了Load Queue (LQ) 和 Store Queue (SQ),分别缓存尚未提交的读写请求,用于乱序访存与内存依赖检测。与LSU紧密配合的是AGU,用于根据基址/偏移/索引产生虚拟地址,配合 D-TLB做地址翻译。
- Load 指令:在重命名和发射后进入 LQ,如果地址和数据依赖尚未解析,Load 读操作可能会投机执行,同时为了防止读写乱序,执行结果在写回时仍需与 SQ 中未提交的 Store 进行地址检查。
- Store 指令:在 SQ 中排队,直到提交(Retire)阶段才真正写入 DCache,以保证程序顺序的正确性。
作为软件工程师我们都知道,ARM是典型的弱内存序(Relax Memory Order),也就是再没有显式的原子屏障语义时,硬件可以对Load/Store广泛重排。我们以约束最轻的Acquire/Release举例:
- Acquire :禁止 后续 访问"穿越到"该 load 之前(后序不可上穿)。
- Release :禁止 先前 访问"穿越到"该 store 之后(前序不可下沉)。
而上述定义的语义在硬件层面上实现就需要LSU的支持: Acquire Load(LDAR/LDAXR)
- LSU 给该 load 打上 ordering point标记;
- 后续指令的内存访问在 全局可见性上不得上穿该ordering point; Release Store(STLR/STLXR)
- 在该 store 对外可见之前,所有先前内存访问 必须已被"发布"(至少在相同 shareability 域内)。
总而言之,ARM 的 relaxed memory order让 LSU 可以大胆投机、重排与缓冲,从而把内存层级的长延迟掩藏在乱序窗口后面;而 Acquire/Release 和更严格的DMB/DSB一样,都是对这种自由度的一种控制,而硬件工程师把这个性能控制的"钥匙"扔给了软件开发者,我们就需要深入了解学习其原理,才能写出真正正确而又高性能的代码。
小结
CPU 后端的核心在于 乱序窗口大小(ROB/Rename/RS)、宽度(Issue)、算力(执行单元)、访存乱序能力(LSQ)。这些单元在硬件上以"乱序+投机"来榨取性能,但又通过 提交顺序、屏障与内存模型来保证架构语义。通过合理的微基准测试,我们不仅能理解这些设计的原理,还能"窥探"出一颗 CPU 的真实微架构特征。