本章代码见:
https://gitee.com/jxxx404/cpp-language-learning/commit/87650b1238aa09c04105a38433f4d73b593e5029
上一章文章:https://blog.csdn.net/2401_86123468/article/details/151836484?spm=1001.2014.3001.5501
大略复习上一章文章:注意using namespace std;的使用,在算法竞赛中换行推荐使用'\n',若使用endl;会更新缓冲区,影响效率。以及在竞赛中可以先添加下面三行代码:
#include<iostream>
using namespace std;
int main()
{
// 在io需求比较高的地方,如部分大量输入的竞赛题中,加上以下3行代码
// 可以提高C++IO效率
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}1.缺省参数
缺省参数是声明或定义 函数时为函数的参数指定一个缺省值 。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参,缺省参数分为全缺省和半缺省参数。(有些地方把缺省参数也叫默认参数)
全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。
带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。
函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现 ,规定必须函数声明给缺省值。
#include<iostream>
using namespace std;
void Func(int a = 0)//赋予参数值,此为缺省值,a为缺省参数
{
cout << a << endl;
}
int main()
{
Func(); // 没有传参时,使⽤参数的默认值
Func(10); // 传参时,使⽤指定的实参
return 0;
}
得到的结果:
0
10全缺省:
#include<iostream>
using namespace std;
// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func1(1, 2, 3);
Func1(1, 2);
Func1(1);
Func1();
return 0;
}
得到的结果:
a = 1
b = 2
c = 3
a = 1
b = 2
c = 30
a = 1
b = 20
c = 30
a = 10
b = 20
c = 30半缺省:
#include<iostream>
using namespace std;
// 半缺省
void Func2(int b, int c = 20, int a = 10)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func2(1);
Func2(1, 2);
Func2(1, 2, 3);
return 0;
}
得到的结果:
a = 10
b = 1
c = 20
a = 10
b = 1
c = 2
a = 3
b = 1
c = 2
// Stack.h
#include <iostream>
#include <assert.h>
using namespace std;
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* ps, int n = 4);
// Stack.cpp
#include"Stack.h"
// 缺省参数不能声明和定义同时给
void STInit(ST* ps, int n)//在定义时要写好
{
assert(ps && n > 0);
ps->a = (STDataType*)malloc(n * sizeof(STDataType));
ps->top = 0;
ps->capacity = n;
}
// test.cpp
#include"Stack.h"
int main()
{
ST s1;
STInit(&s1);
// 确定知道要插⼊1000个数据,初始化时⼀把开好,避免扩容
ST s2;
STInit(&s2, 1000);
return 0;
}2.函数重载
C++支持在同一作用域中出现同名函数 ,但是要求这些同名函数的形参不同 ,可以是参数个数不同或者类型不同。这样C++函数调用就表现出了多态行为,使用更灵活。C语言是不支持同一作用域中出现同名函数的。
2.1参数类型不同
#include<iostream>
using namespace std;
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.1, 2.2) << endl;
return 0;
}
结果为:
int Add(int left, int right)
3
double Add(double left, double right)
3.32.2参数个数不同
#include<iostream>
using namespace std;
void f()
{
cout << "f()" << endl;
}
void f(int a)//1个int参数
{
cout << "f(int a)" << endl;
}
int main()
{
f();
f(10);
return 0;
}
结果为:
f()
f(int a)2.3参数类型顺序不同
#include<iostream>
using namespace std;
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
int main() {
f(10, 'A'); // 调用参数为「int, char」的版本
f('B', 20); // 调用参数为「char, int」的版本
return 0;
}
结果为:
f(int a,char b)
f(char b, int a)注意:
1.返回值不同不能作为重载条件,因为调用时无法区分
#include<iostream>
using namespace std;
// 返回值不同不能作为重载条件,因为调⽤时也⽆法区分
void fxx()
{
return 0;
}
int fxx()
{
return 0;
}
int main()
{
// 调用时无法确定要调用哪个
fxx();
return 0;
}2.下面两个函数构成重载,但是不传参调用时,存在调用歧义。
//此时是错误代码
#include<iostream>
using namespace std;
void f1()
{
cout << "f()" << endl;
}
void f1(int a = 10)
{
cout << "f(int a)" << endl;
}
int main()
{
//f1(1);
f1();
}3.引用
3.1引用的概念和定义
引用不是新定义一个变量 ,而是给已存在变量取了一个别名 ,编译器不会为引用变量开辟内存空间
它和它引用的变量共用同一块内存空间。
类型&引用别名=引用对象;
#include<iostream>
using namespace std;
int main()
{
int a = 0;
// 引⽤:b和c是a的别名
int& b = a;
int& c = a;
// 也可以给别名b取别名,d相当于还是a的别名
int& d = b;
++d;
// 这⾥取地址我们看到是⼀样的
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &d << endl;
return 0;
}
结果为:
000000D9471BF854
000000D9471BF854
000000D9471BF854
000000D9471BF854
3.2引用的特性
1.引用在定义时必须初始化
2.一个变量可以有多个引用
3.引用一旦引用一个实体,再不能引用其他实体
#include<iostream>
using namespace std;
int main()
{
int i = 1;
int& j = i;
cout << &i << endl;
cout << &j << endl;
++j;
// 一个变量可以有多个引用
int& k = j;
k = 10;
// 引用在定义时必须初始化
/*int& x;
x = i;*/
// 引用一旦引用一个实体,再不能引用其他实体
int m = 20;
k = m;//此时是赋值
return 0;
}3.3引用的使用
引用在实践中主要是于引用传参 和传引用返回 中减少拷贝(深拷贝)提高效率 和改变引用对象 时同时改变被引用对象。
引用传参跟指针传参功能是类似的,引用传参相对更方便一些。
#include<iostream>
using namespace std;
// 指针
// 引用
// 大部分场景去替代指针,部分场景还是离不开指针
void Swap(int* rx, int* ry)
{
int tmp = *rx;
*rx = *ry;
*ry = tmp;
}
void Swap(int& rx, int& ry)
{
int tmp = rx;
rx = ry;
ry = tmp;
}
int main()
{
int x = 0, y = 1;
cout << x << " " << y << endl;
// Swap(&x, &y);
cout << x << " " << y << endl;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}
结果为:
0 1
0 1
1 0也可以这样:
typedef struct SeqList
{
//...
}SL;
//void SLInit(SL* psl, int n = 4)
void SLInit(SL& psl, int n = 4)
{
//...
}对于二级指针,可以这样:
void Swap(int** pp1, int** pp2)
{
int* tmp = *pp1;
*pp1 = *pp2;
*pp2 = tmp;
}
void Swap(int*& rp1, int*& rp2)
{
int* tmp = rp1;
rp1 = rp2;
rp2 = tmp;
}
int main()
{
int x = 0, y = 1;
cout <<x<<!<< y << endl;
Swap(&x, &y);
cout << x<<<< y << endl;
Swap(x, y);
cout <<x<<""<< y << endl;
SL s;
SLInit(s) ;
int* pl = &x, * p2 = &y;
Swap(&p1, &p2);
Swap(pl, p2);//区别
}传引用返回:
引用返回值的场景相对比较复杂,这里先只简单讲一下场景。
错误做法:
注意下方演示:若返回局部变量的引用,会因局部变量生命周期结束导致 "野引用",是错误用法。
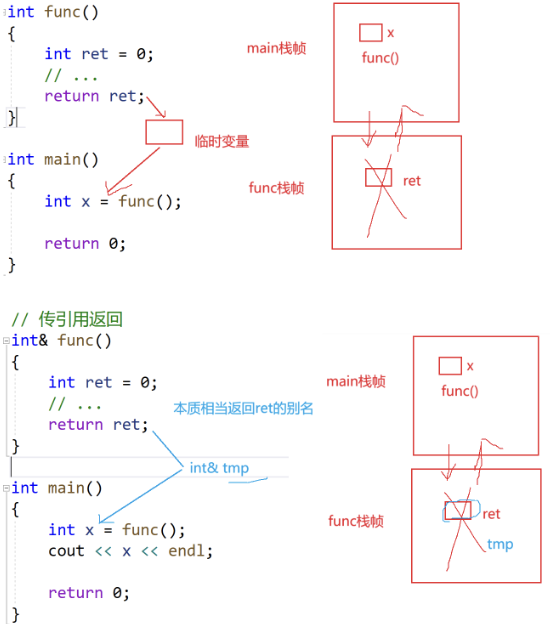
以及下面的代码,即使在return ret后被销毁,但仍可能结果相同。
因为局部变量的生命周期仅限于函数执行期间:当函数返回后,其栈帧(包含局部变量的内存)会被 "释放"(不再受程序控制),但内存空间本身不会立即 "清空",只是标记为 "可复用"。此时,main 中的 x 作为引用,指向的是一块已释放的栈内存 (野引用),后续对 x 的访问属于未定义行为(结果不可预测)。
int& func1()
{
int ret = 0;
// ...
return ret;
}
int& func2()
{
int y = 456;
// ...
return y;
}
int main()
{
int& x = func1();
cout << x << endl;
func2();
cout << x << endl;
return 0;
}正确做法:加static。
int& func1()
{
static int ret = 0;
// ...
return ret;
}
int& func2()
{
int y = 456;
// ...
return y;
}
int main()
{
int& x = func1();
cout << x << endl;
func2();
cout << x << endl;
return 0;
}通过修改顺序表第i个位置的值,了解引用的特性:语法简洁、无需解引用、必须初始化,以及它与指针在内存和使用上的不同。
指针写法:
#include"SeqList.h"
int main()
{
// 1. 定义顺序表对象s,并初始化(初始容量为10)
SL s;
SLInit(&s, 10); // 初始化顺序表,分配初始空间
// 2. 向顺序表尾部插入10个元素(0~9)
for (size_t i = 0; i < 10; i++)
{
SLPushBack(&s, i); // 尾插操作:将i插入到顺序表s的末尾
}
// 3. 打印顺序表中的所有元素
for (size_t i = 0; i < 10; i++)
{
// SLat函数:获取顺序表s中第i个位置的元素
cout << SLat(&s, i) << " ";
}
cout << endl; // 输出结果:0 1 2 3 4 5 6 7 8 9
// 4. 修改顺序表中指定位置的元素
int i = 0, x = 0;
cin >> i; // 输入要修改的位置(假设输入3)
cin >> x; // 输入新值(假设输入100)
// 关键操作:通过SLat函数的返回值直接修改元素
// 前提:SLat函数的返回类型必须是int&(元素的引用)
SLat(&s, i) = x; // 等价于修改顺序表第i个元素的值为x
// 5. 再次打印顺序表,验证修改结果
for (size_t i = 0; i < 10; i++)
{
cout << SLat(&s, i) << " ";
}
cout << endl; // 若输入i=3、x=100,输出:0 1 2 100 4 5 6 7 8 9
return 0;
}引用写法:
#include<iostream>
using namespace std;
int main()
{
int i = 0; // 定义int变量i,初始值为0
// 1. 引用的定义:r1是i的别名(必须初始化,且绑定后不可更改指向)
// 引用不占用额外内存空间,与i共享同一块内存
int& r1 = i;
// 2. 指针的定义:p存储i的地址(可以先定义后初始化,可更改指向)
// 指针本身占用内存(32位系统4字节,64位系统8字节)
int* p = &i;
// 3. 通过引用操作原始变量i
r1++; // 等价于i++,i的值变为1
// 4. 通过指针操作原始变量i
(*p)++; // 指针需解引用(*)才能访问i,等价于i++,i的值变为2
return 0; // 最终i的值为2
}引用和指针在实践中相辅相成,功能有重叠性,但是各有特点,互相不可替代 。C++的引用跟其他语言的引用(如Java)是有很大的区别的,除了用法,最大的点,C++引用定义后不能改变指向,
Java的引用可以改变指向。
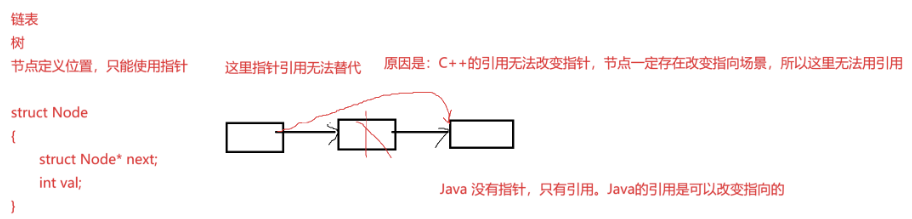
一些主要用C代码实现版本数据结构教材中,使用C++引用替代指针传参,目的是简化程序,避开复杂的指针。
void SeqPushBack(SLT& sl, int x)
{
//...
}
typedef struct ListNode
{
int val;
struct ListNode* next;
}LTNode, *PNode;
// 指针变量也可以取别名,这⾥LTNode*& phead就是给指针变量取别名
// 这样就不需要⽤⼆级指针了,相对⽽⾔简化了程序
//void ListPushBack(LTNode** phead, int x)
//void ListPushBack(LTNode*& phead, int x)
void ListPushBack(PNode& phead, int x)
{
PNode newnode = (PNode)malloc(sizeof(LTNode));
newnode->val = x;
newnode->next = NULL;
if (phead == NULL)
{
phead = newnode;
}
else
{
//...
}
}
int main()
{
PNode plist = NULL;
ListPushBack(plist, 1);
return 0;
}有些C语言书上是运用了引用的知识
typedef struct SListNode
{
int val;
struct SListNode* next;
}SLTNode,* PSLTNode;具体这样理解更清楚:

4.const引用
可以引用一个const对象,但是必须用const引用。const引用也可以引用普通对象,因为对象的访问权限在引用过程中可以缩小,但是不能放大。
如原本可以根据引用b来对a进行修改:
#include<iostream>
using namespace std;
int main()
{
int a = 0;
int& b = a;
return 0;
}但由于对a进行const引用,那么此代码就不能运行:此时的引用是对a访问权限的放大
#include<iostream>
using namespace std;
int main()
{
//int a = 0;
const int a = 10;
// 编译报错:error C2440: "初始化": ⽆法从"const int"转换为"int &"
// 这⾥的引⽤是对a访问权限的放⼤
int& b = a;
return 0;
}当两者都有const引用时,代码正确:
int main()
{
//int a = 0;
const int a = 10;
// 编译报错:error C2440: "初始化": ⽆法从"const int"转换为"int &"
// 这⾥的引⽤是对a访问权限的放⼤
const int& b = a;
return 0;
}以下代码为对c权限的缩小:
因为c 原本是int类型,可读可写,但通过const对c的别名d的引用,导致其别名只读不可写(不能放大权限,可以缩小权限)。
int main()
{
const int a = 10;
//不能权限放大
//int& b = a;
int c = 0;
//可以权限缩小
const int& d = c;
return 0;
}注意:不要将权限放大/缩小与下面举例的拷贝混淆:
int main()
{
const int a = 0;
//不能权限放大
//int& b = a;
//不是权限放大,是拷贝赋值
int e = a;
const int& b = a;
int c = 0;
//权限缩小
const int& d = c;
return 0;
}权限放大/缩小,可通过const也可以对指针引用:
int main()
{
const int a = 0;
const int* p1 = &a;
//不能权限放大
//int* p2 = p1;
const int* p2 = p1;
//可以权限缩小
int e = a;
int* p3 = &e;
const int* p4 = p3;
return 0;
}拓展:const可以引用常量,同样在传参的场景下,可加入const:
void func(const int& x)//可以减少拷贝,可以传普通对象
{
}
int main()
{
//const int& a = 10;
int y = 0;
func(y);
const int z = 1;
func(z);
func(2);
double d = 2.2;
func(d);
return 0;
}需要注意的是类似 int& rb=a*3;doubled =12.34;int& rd= d;这样一些场景下a*3的和结果保存在一个临时对象中,int& rd=d也是类似,在类型转换中会产生临时对象存储中间值 ,也就是,rb和rd引用的都是临时对象,而C++规定临时对象具有常性 ,所以这里就触发了权限放大,必须要用常引用才可以。
所谓临时对象就是编译器需要一个空间暂存表达式的求值结果时临时创建的一个未命名的对象,C++中把这个未命名对象叫做临时对象。
在c语言中存在隐式类型转换和强制类型转换:
int main()
{
int i = 1;
double d = i;
int p = (int)&i;
return 0;
}而当我们之间使用引用时,代码会显示错误,如下:
int main()
{
int i = 1;
double d = i;
int p = (int)&i;
double& rd = i;
return 0;
}但是当加入const时,一切就正常了:
int main()
{
int i = 1;
double d = i;
int p = (int)&i;
const double& rd = i;
const int& rp = (int)&i;
return 0;
}原因:在c语言中,类型转换会创建出临时变量,具有常性,就像被const修饰一样。

之前不加const,类似于权限的放大,所以需要加const。
5.指针和引用的关系
C++中指针和引用就像两个性格迥异的亲兄弟,指针是哥哥,引用是弟弟,在实践中他们相辅相成,功能有重叠性,但是各有自己的特点,互相不可替代。
语法概念上引用是一个变量的取别名不开空间 ,指针是存储一个变量地址 ,要开空间。
引用在定义时必须初始化 ,指针建议初始化,但是语法上不是必须的。
引用在初始化时引用一个对象后,就不能再引用其他对象;而指针可以在不断地改变指向对象。
引用可以直接访问指向对象 ,指针需要解引用才是访问指向对象。
sizeof中含义不同,引用结果为引用类型的大小 ,但指针始终是地址空间所占字节个数 (32位平台下
占4个字节,64位下是8byte)
指针很容易出现空指针和野指针的问题,引用很少出现,引用使用起来相对更安全一些。
6.inline
C语言实现宏函数也会在预处理时替换展开,但是宏函数实现很复杂很容易出错的,且不方便调
试,C++设计了inline目的就是替代C的宏函数。
以C语言ADD的宏函数举例:
//宏是一种替换机制
//错误一:
#define ADD(int a, int b) return a + b;
//错误二:
#define ADD(a, b) a + b;//后面加了分号,主函数中ret2不能运行
//错误三:
#define ADD(a, b) a + b//影响优先级,主函数中ret2运行错误
//错误四:
#define ADD(a, b) (a + b)
//正确:
#define ADD(a, b) ((a) + (b))
// 宏函数很复杂,容易写出问题,还不能调试
// 优点:高频调用小函数,写成宏函数,可以提高效率,预处理阶段宏会替换,提高效率,不建立栈帧
int main()
{
int ret1 = ADD(1, 2); // 被替换为int ret1 = 1+2;;
cout << ret1 << endl;
int ret2 = ADD(1, 2)*3;
cout << ret2 << endl;
// a和b是表达式,表达式中的运算符比+优先级低
int x = 0, y = 1;
ADD(x | y, x & y); //如果不加括号: ((x|y) + (x&y));
return 0;
}用inline修饰的函数叫做内联函数,编译时C++编译器会在调用的地方展开内联函数,这样调用内联函数就需要建立栈帧了,就可以提高效率。(内联函数就是用来代替宏函数)
inline int Add(int x, int y)
{
return x + y;
}
int main()
{
int ret = Add(1, 2) * 3;
cout << ret << endl;
int x = 0, y = 1;
Add(x | y, x & y);
return 0;
}inline对于编译器而言只是一个建议,也就是说,加了inline编译器也可以选择在调用的地方不展
开,不同编译器关于inline什么情况展开各不相同,因为C++标准没有规定这个。inline适用于频繁
调用的短小函数,对于递归函数,代码相对多一些的函数,加上inline也会被编译器忽略,否则可执行程序(安装包)会很大。
将上述代码转到汇编:
int main()
{
00F21D20 push ebp
00F21D21 mov ebp,esp
00F21D23 sub esp,0CCh
00F21D29 push ebx
00F21D2A push esi
00F21D2B push edi
00F21D2C lea edi,[ebp-0Ch]
00F21D2F mov ecx,3
00F21D34 mov eax,0CCCCCCCCh
00F21D39 rep stos dword ptr es:[edi]
00F21D3B mov ecx,offset _8E1CBA9C_test@cpp (0F2C086h)
00F21D40 call @__CheckForDebuggerJustMyCode@4 (0F21366h)
00F21D45 nop
int ret = Add(1, 2) * 3;
00F21D46 push 2
00F21D48 push 1
00F21D4A call Add (0F211E5h)
00F21D4F add esp,8
00F21D52 imul eax,eax,3
00F21D55 mov dword ptr [ret],eax
cout << ret << endl;
00F21D58 mov esi,esp
00F21D5A push offset std::endl<char,std::char_traits<char> > (0F21041h)
00F21D5F mov edi,esp
00F21D61 mov eax,dword ptr [ret]
00F21D64 push eax
00F21D65 mov ecx,dword ptr [__imp_std::cout (0F2B0A8h)]
00F21D6B call dword ptr [__imp_std::basic_ostream<char,std::char_traits<char> >::operator<< (0F2B09Ch)]
00F21D71 cmp edi,esp
00F21D73 call __RTC_CheckEsp (0F21276h)
00F21D78 mov ecx,eax
00F21D7A call dword ptr [__imp_std::basic_ostream<char,std::char_traits<char> >::operator<< (0F2B0A0h)]
00F21D80 cmp esi,esp
00F21D82 call __RTC_CheckEsp (0F21276h)
00F21D87 nop
return 0;
00F21D88 xor eax,eax
}不过,在汇编代码中,貌似没有内联函数的出现,原因是:默认debug版本下,inline也不展开,为了方便调试。debug版本想展开需要设置一下以下两个地方
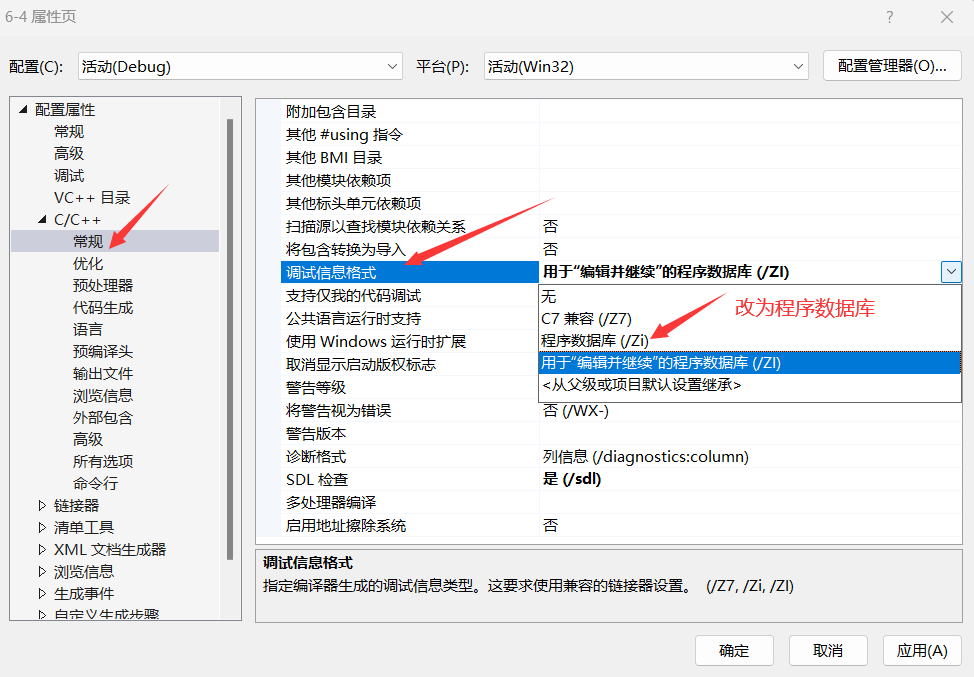
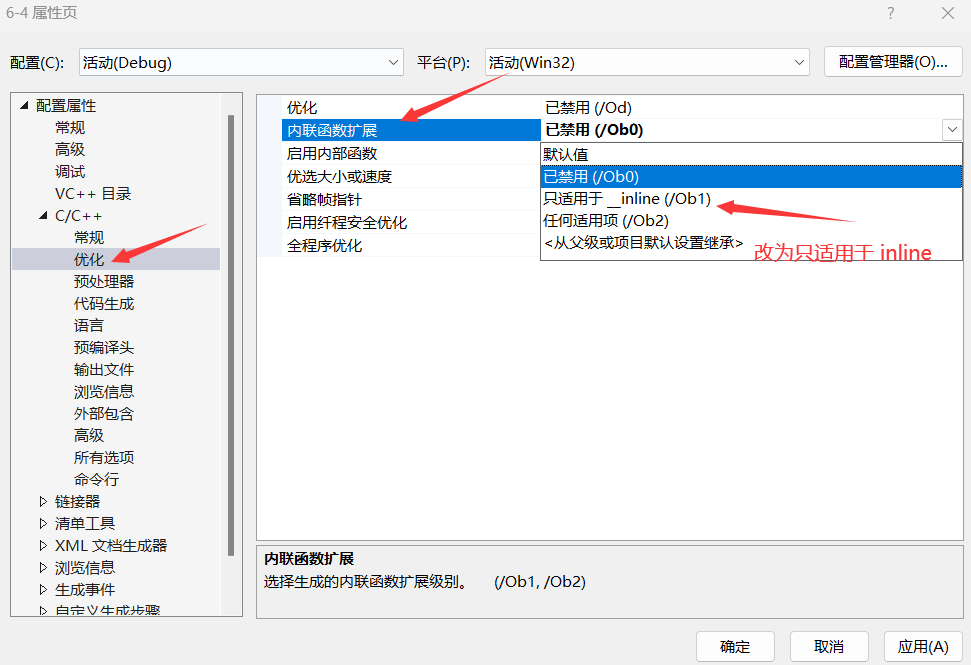
最终如下:
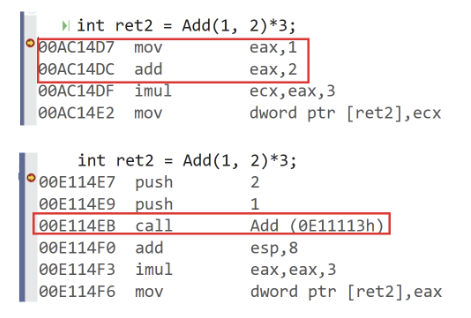
inline不建议声明和定义分离到两个文件, 分离会导致链接错误。因为inline被展开,就没有函数地
址(在符号表中不会放自己的地址),inline函数直接定义到.h文件,链接时会出现报错。
错误示例:
//seqlist.h
#pragma once
#include<stdlib.h>
typedef struct Seqlist
{
int* a;
int size;
int capacity;
}SL;
inline void SLInit(SL* pls, int n = 4);
void SLPushBack(SL* pls, int x);
int SLFind(SL* pls, int x, int i = 0);
int& SLat(SL* pls, int i);
void SLModify(SL* pls, int i, int x);
//seqlist.cpp
#include"SeqList.h"
void SLInit(SL* pls, int n)
{
pls->a = (int*)malloc(n * sizeof(int));
pls->size = 0;
pls->capacity = n;
}
//test.cpp
#include"SeqList.h"
int main()
{
SL s;
SLInit(&s); // call 地址
return 0;
}正确示例:
//seqlist.h
#pragma once
#include<stdlib.h>
typedef struct Seqlist
{
int* a;
int size;
int capacity;
}SL;
inline void SLInit(SL* pls, int n)
{
pls->a = (int*)malloc(n * sizeof(int));
pls->size = 0;
pls->capacity = n;
}
void SLInit(SL* pls, int n = 4);
void SLPushBack(SL* pls, int x);
int SLFind(SL* pls, int x, int i = 0);
int& SLat(SL* pls, int i);
void SLModify(SL* pls, int i, int x);7.nullptr
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif不过这里有个问题:
void f(int x)
{
cout << "f(int x)" << endl;
}
void f(int* ptr)
{
cout << "f(int* ptr)" << endl;
}
int main()
{
f(0);
// 本想通过f(NULL)调⽤指针版本的f(int*)函数,但是由于NULL被定义成0,调⽤了f(int
//x),因此与程序的初衷相悖。
f(NULL);
//f((void*)0);
// 编译报错:error C2665: "f": 2 个重载中没有⼀个可以转换所有参数类型
int* p1 = NULL;
char* p2 = NULL;
return 0;
}导致输出的结果为:
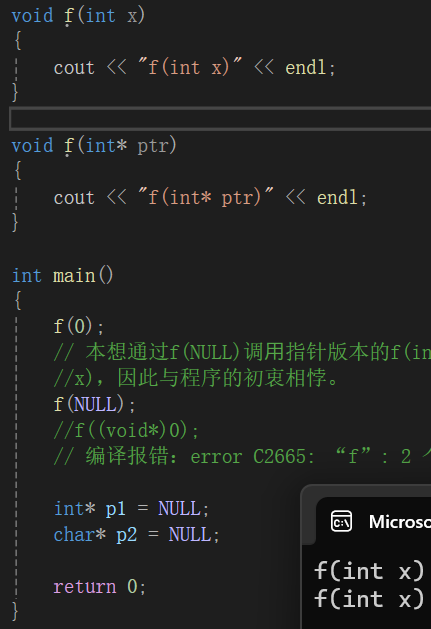
C++中NULL可能被定义为字面常量0,或者C中被定义为无类型指针(void*)的常量。不论采取何种
定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,本想通过f(NULL)调用指针版本的
f(int*)函数,但是由于NULL被定义成0,调用了f(intx),因此与程序的初衷相悖。f((void*)NULL);
调用会报错。
C++11中引入nullptr,nullptr是一个特殊的关键字,nullptr是一种特殊类型的字面量 ,它可以转换
成任意其他类型的指针类型。使用nullptr定义空指针可以避免类型转换的问题,因为nullptr只能被
隐式地转换为指针类型,而不能被转换为整数类型。
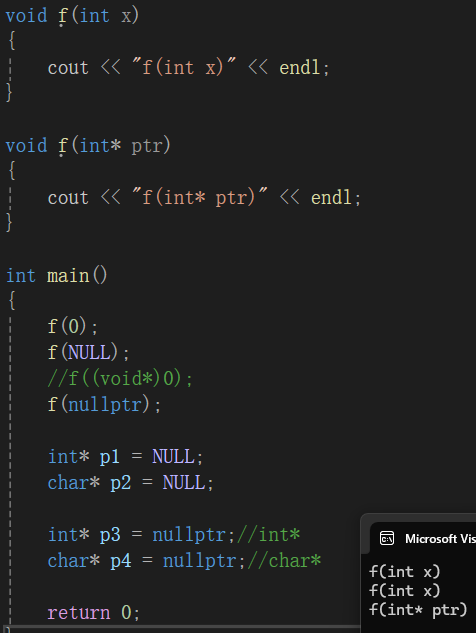
所以上述问题代码,转换为:
void f(int x)
{
cout << "f(int x)" << endl;
}
void f(int* ptr)
{
cout << "f(int* ptr)" << endl;
}
int main()
{
f(0);
f(NULL);
//f((void*)0);
f(nullptr);
int* p1 = NULL;
char* p2 = NULL;
int* p3 = nullptr;//int*
char* p4 = nullptr;//char*
return 0;
}结果为:
本章完。