2000字的源码分析,聊聊Spring的扫描机制底层到底是如何实现的?所谓的默认扫描路径到底是如何实现的?
记得点赞、关注、收藏,可以关注我的公众号:IT周瑜,有更多技术干货。
首先,当我们启动SpringBoot时,会传入一个类,这个类通常是启动类,但是也可以是其他类:
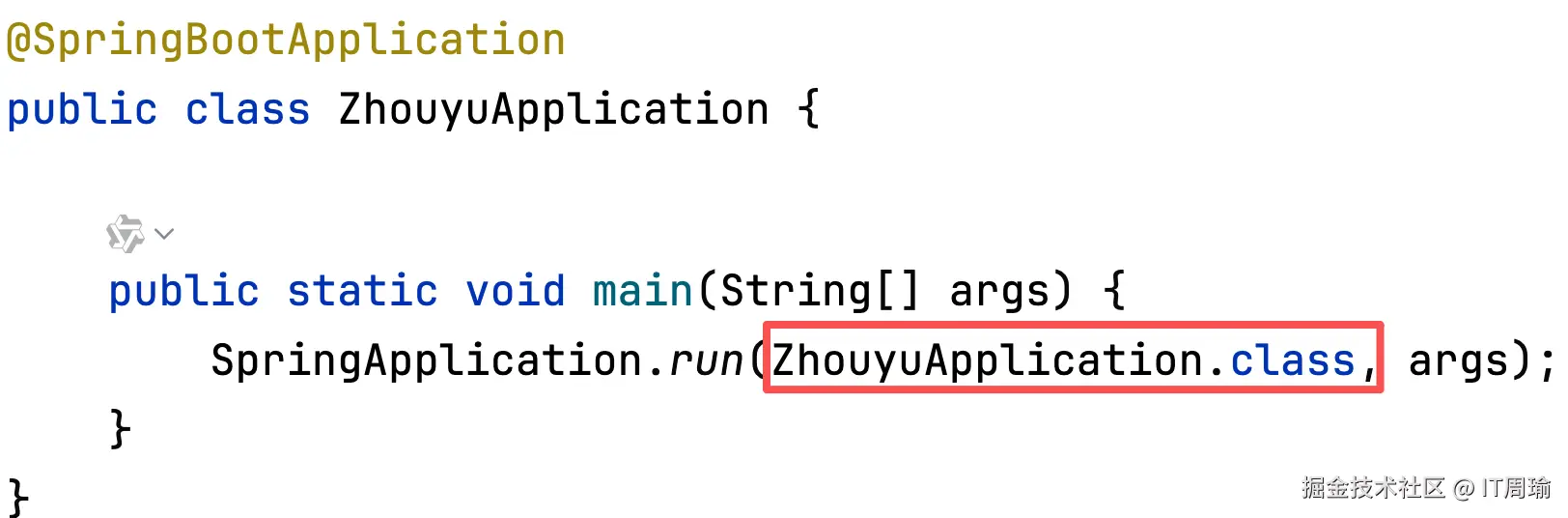
在run()方法里面,SpringBoot会先创建Spring容器,也就是ApplicationContext对象,然后refresh容器。
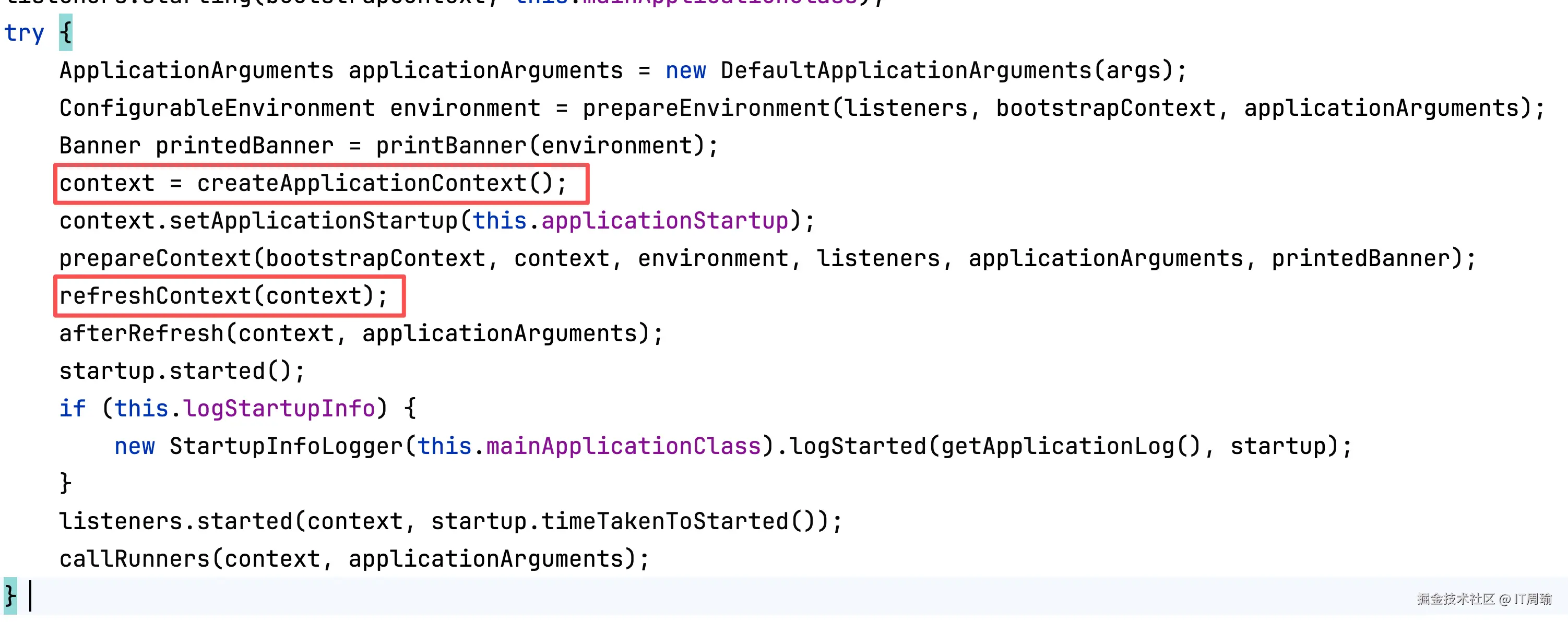
这里的refresh直接理解为启动就可以了,接下来就进入到了Spring容器的启动过程。
Spring容器启动过程就是执行refresh()方法,而在refresh()方法中有一个步骤叫做:执行BeanFactoryPostProcessor,俗称BeanFacotry后置处理器。
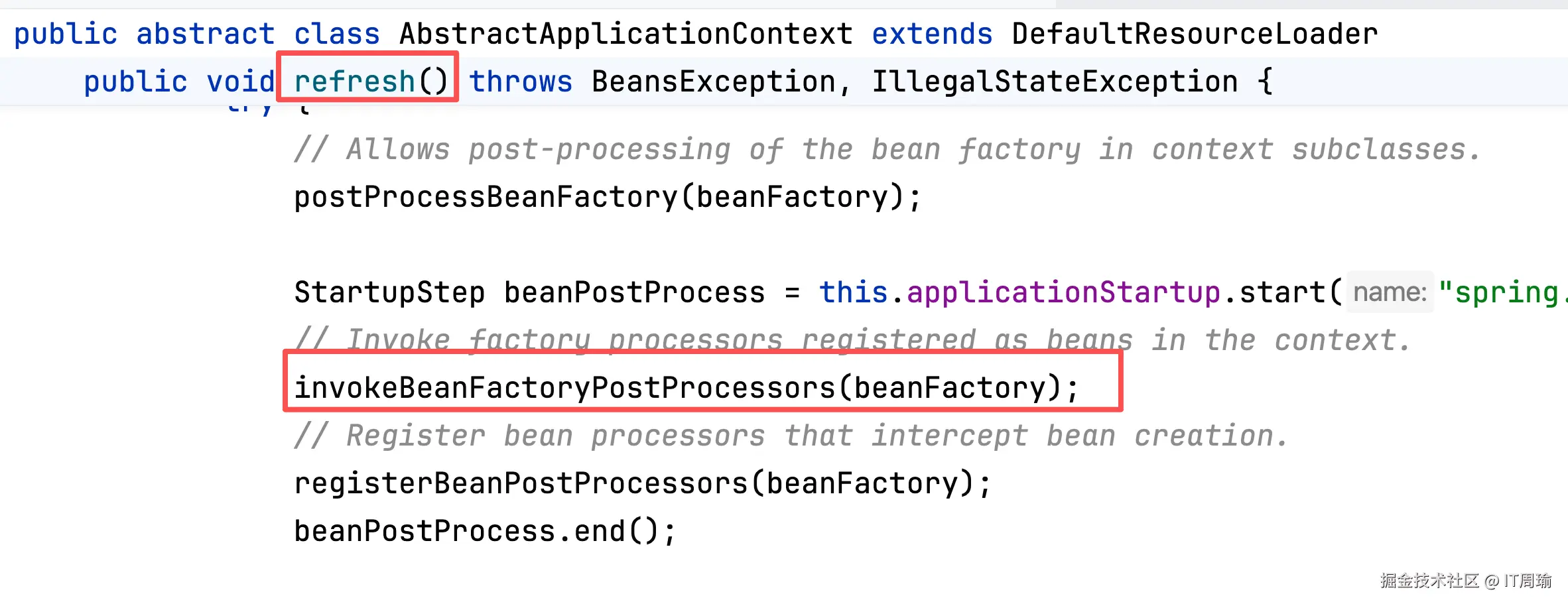
Spring默认内置了多个BeanFactoryPostProcessor,其中包括一个叫做ConfigurationClassPostProcessor的:
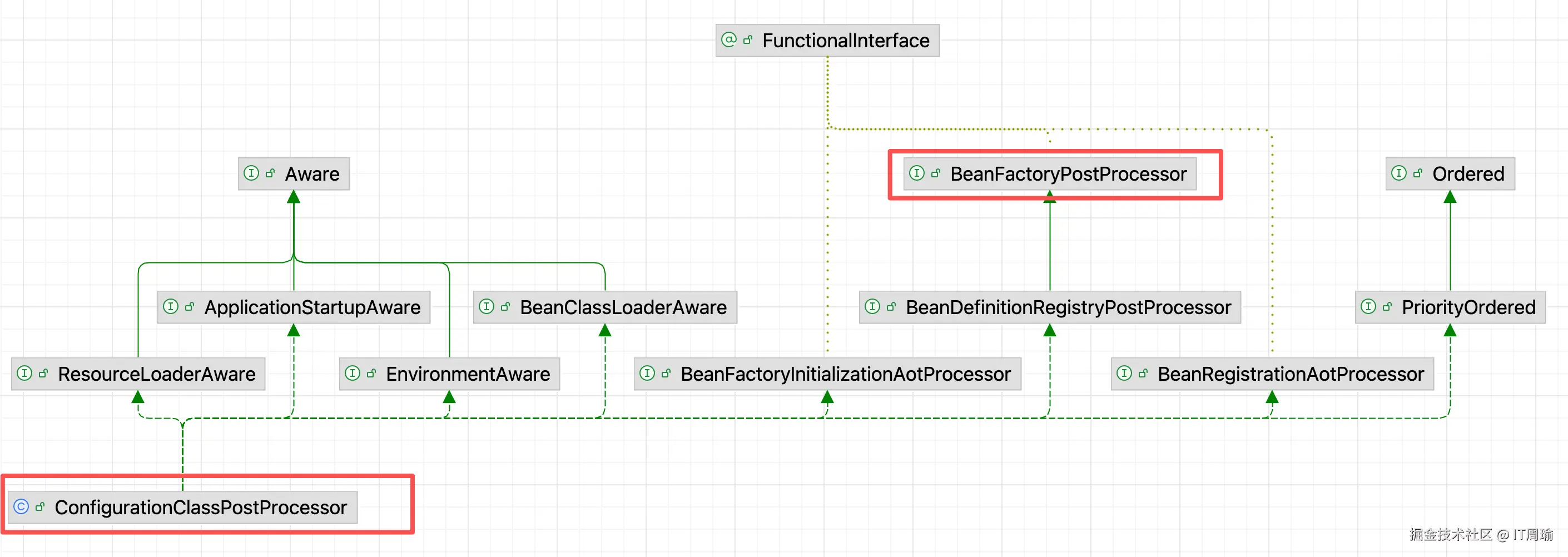
也就是说,Spring容器在启动时,会利用ConfigurationClassPostProcessor来对BeanFactory进行处理,处理啥呢?看名字就知道,处理ConfigurationClass,也就是配置类。
因此,Spring容器在启动时,会利用ConfigurationClassPostProcessor来解析配置类,也就是解析它:
而所谓解析配置类,就是解析:
- 类上的注解,比如@ComponentScan、@Import
- 类中方法上的注解,比如@Bean
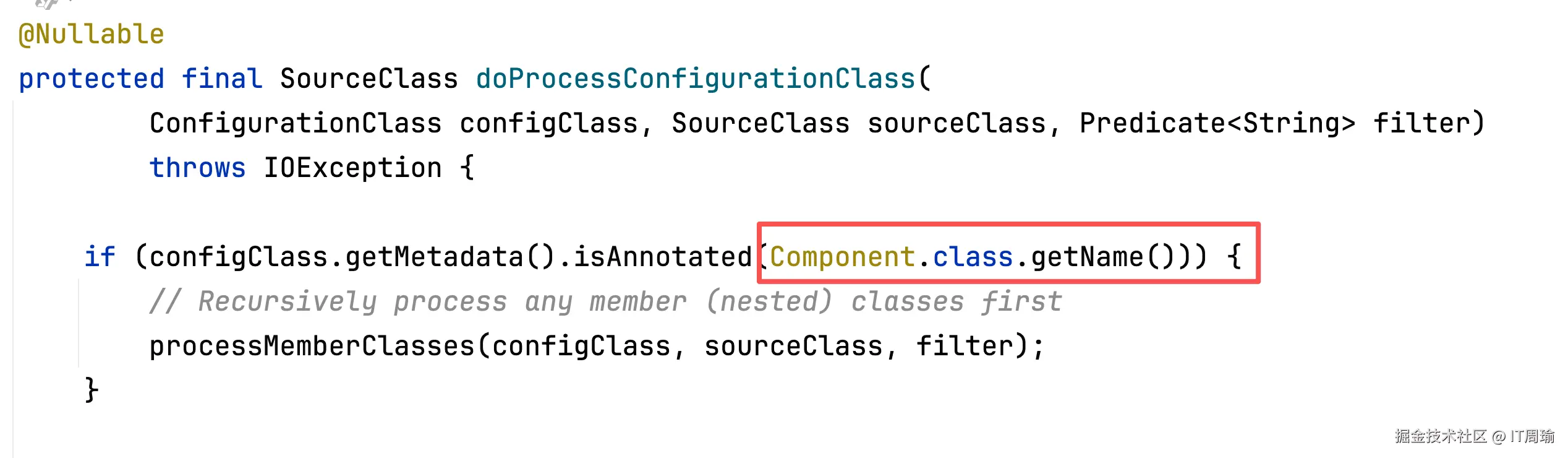
配置类上可能有多个注解,解析的顺序并不是按你定义来的,而是这样的,先解析@Component:
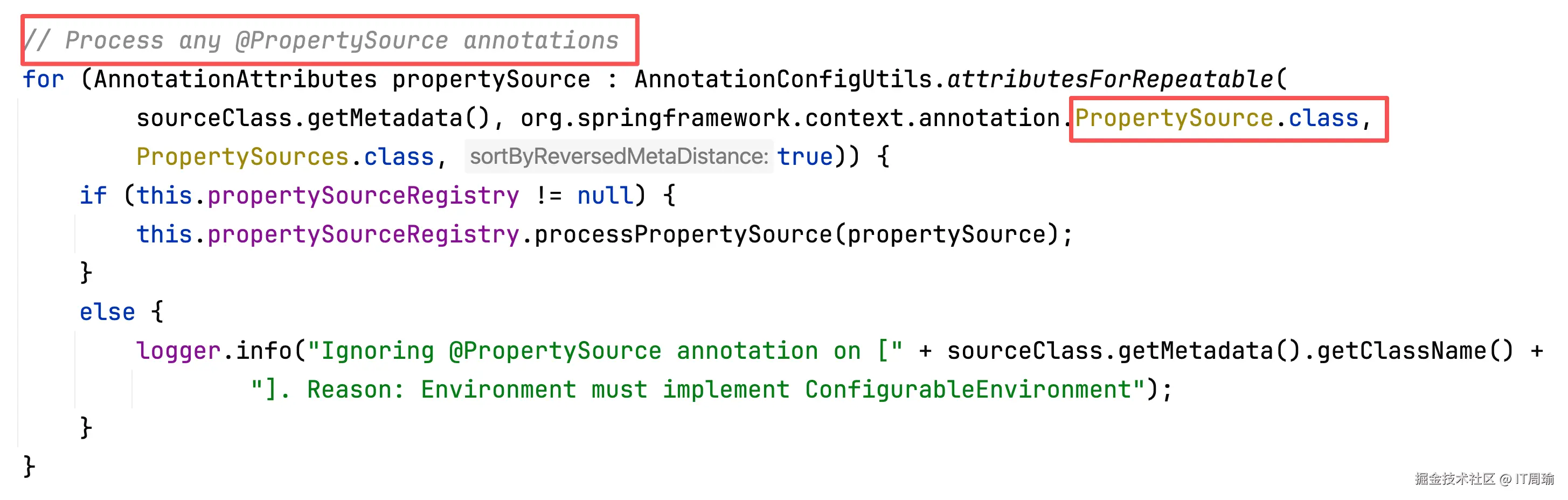
再解析@PropertySource:
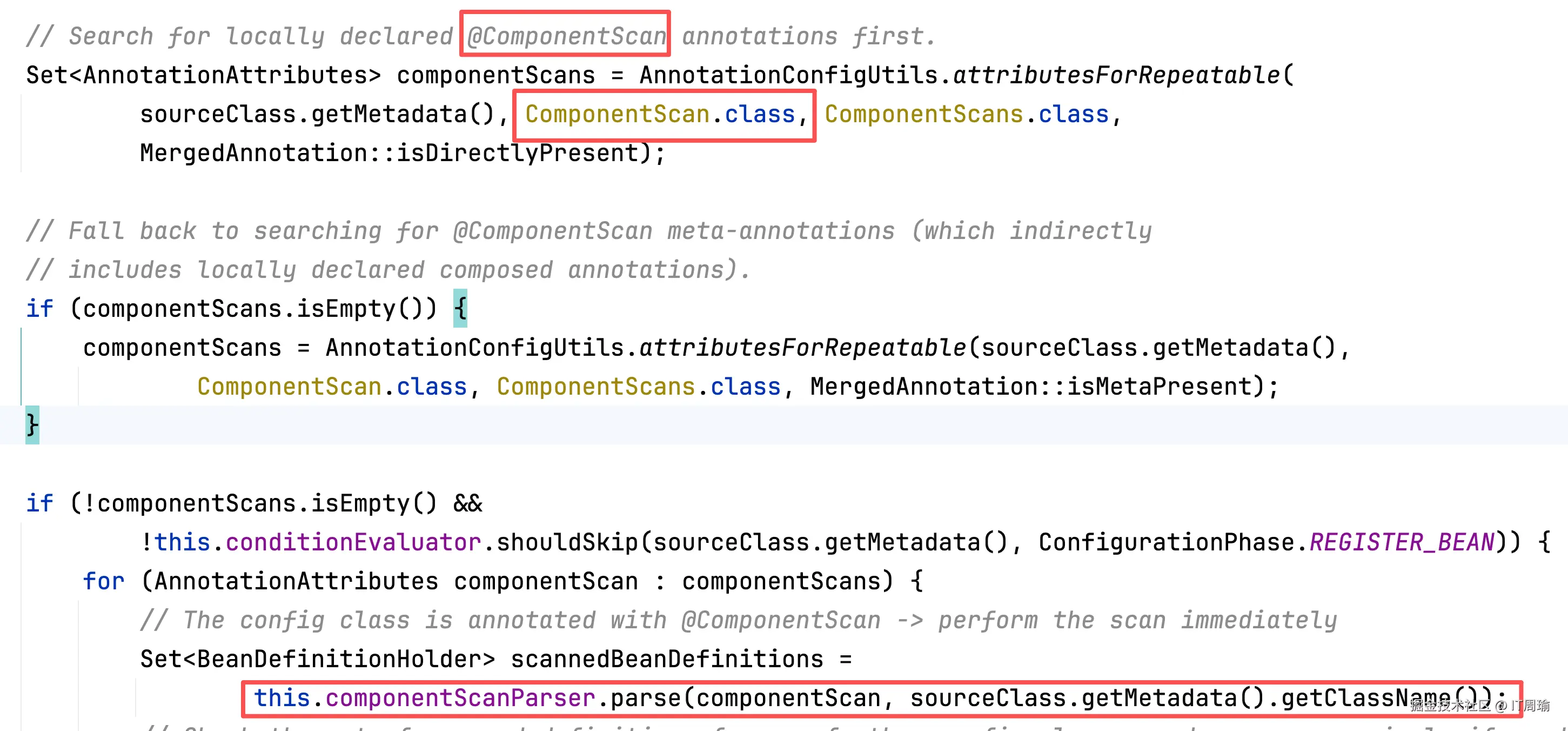
然后才是@ComponentScan:
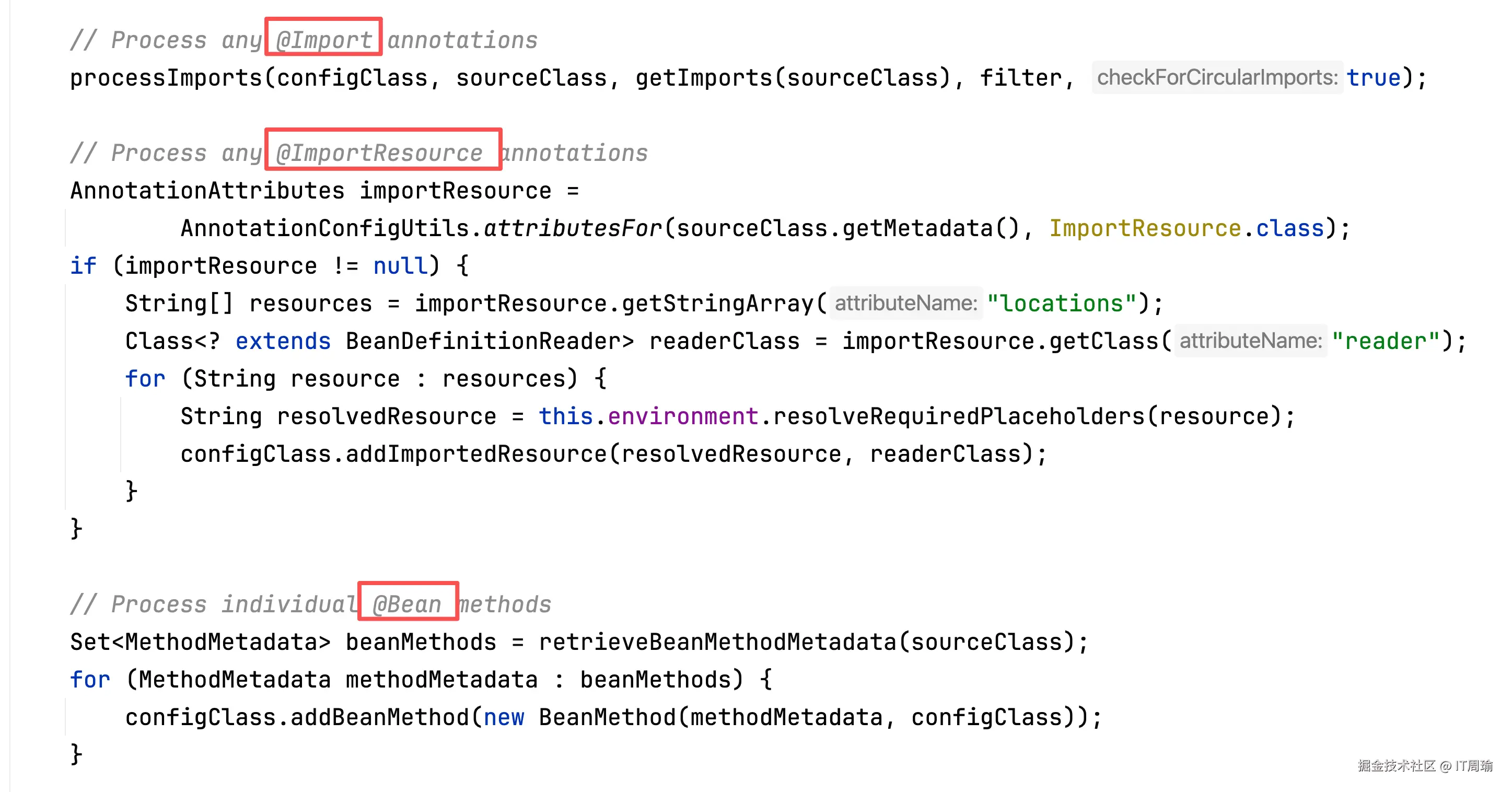
再往后,依次是@Import、@ImportResource、@Bean:
从这可以看出,所谓的扫描,其实只是Spring解析配置类中的一个步骤而已。
重点来看扫描:
Spring会利用一个ComponentScanAnnotationParser解析器来专门负责解析@ComponentScan注解,话说人家这类名取得是真的简单明了,一看就知道是干嘛的,好的开源项目,代码写得好,自然没人吐槽。
而解析@ComponentScan注解时,会先获取注解中定义的各个属性值或默认值,比如获取BeanNameGenerator:

它是用来给扫描出来的Bean取名字的。
然后是ScopedProxyMode:
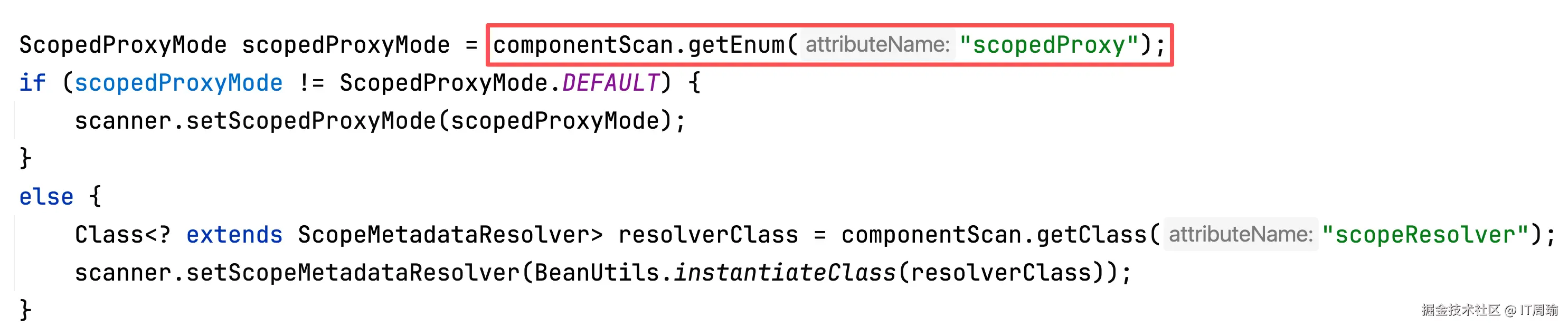
这个稍微复杂点,下次单独分析,关注我。
然后是resourcePattern:

看一眼它的默认值就知道是干嘛的了:

然后是includeFilters、excludeFilters、lazyInit:
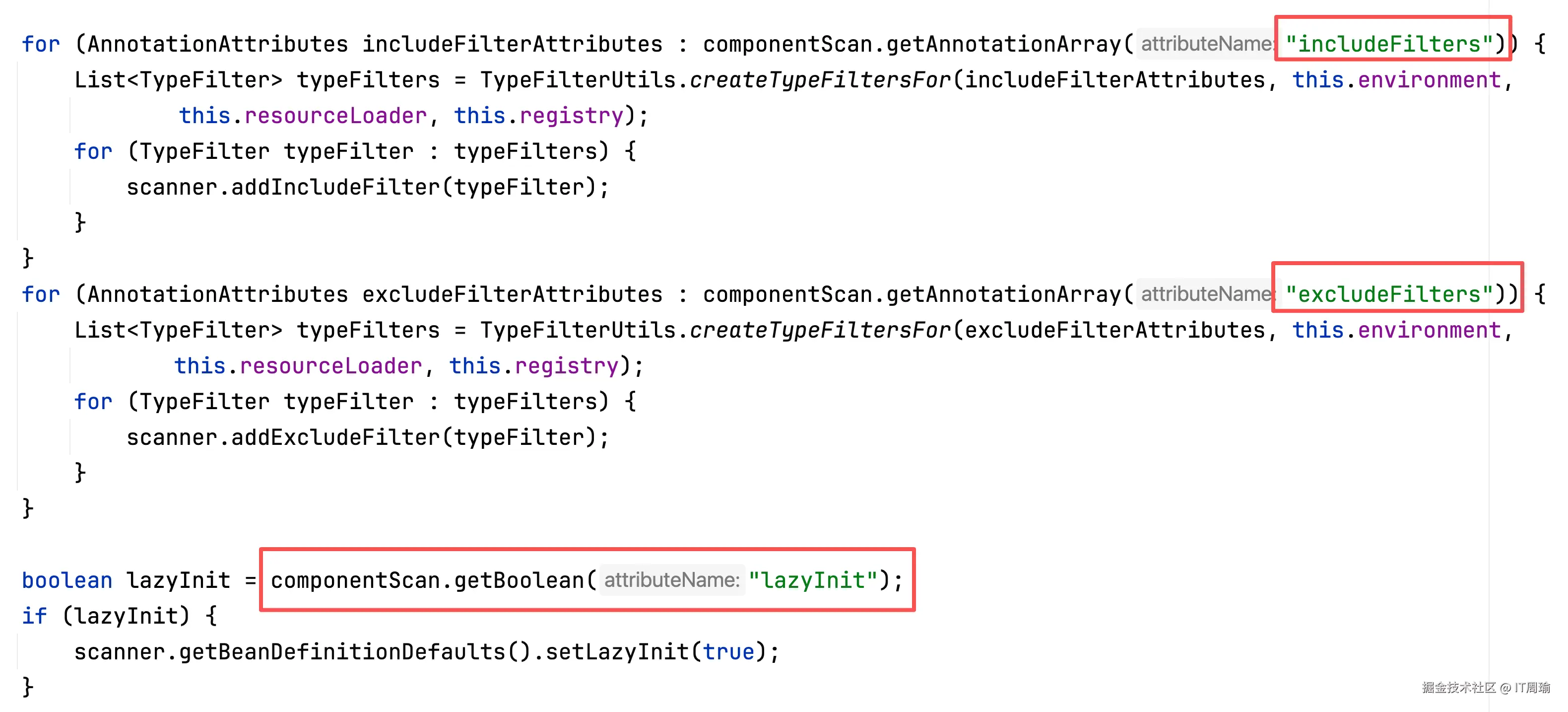
这些都留着后面单独分享。
再往后就是获取扫描路径了:

- 先获取basePackages属性的配置,添加到basePackages中
- 再获取basePackageClasses,因为配的是类,所以会取类所在的包路径,添加到basePackages中
- 最后判断basePackages是否为空,也就是SpringBoot默认的情况,如果为空,就获取declaringClass类的包路径,而declaringClass就是当前正在解析的配置类
所以,SpringBoot默认会扫描传给run()方法的配置类所在的包路径,通常我们把启动类传给了run()方法,所以有说法说,"SpringBoot默认会扫描启动类所在的包路径",这是不严谨的,因为我们完全可以不把启动类传给run()方法,而传其他的配置类,比如:
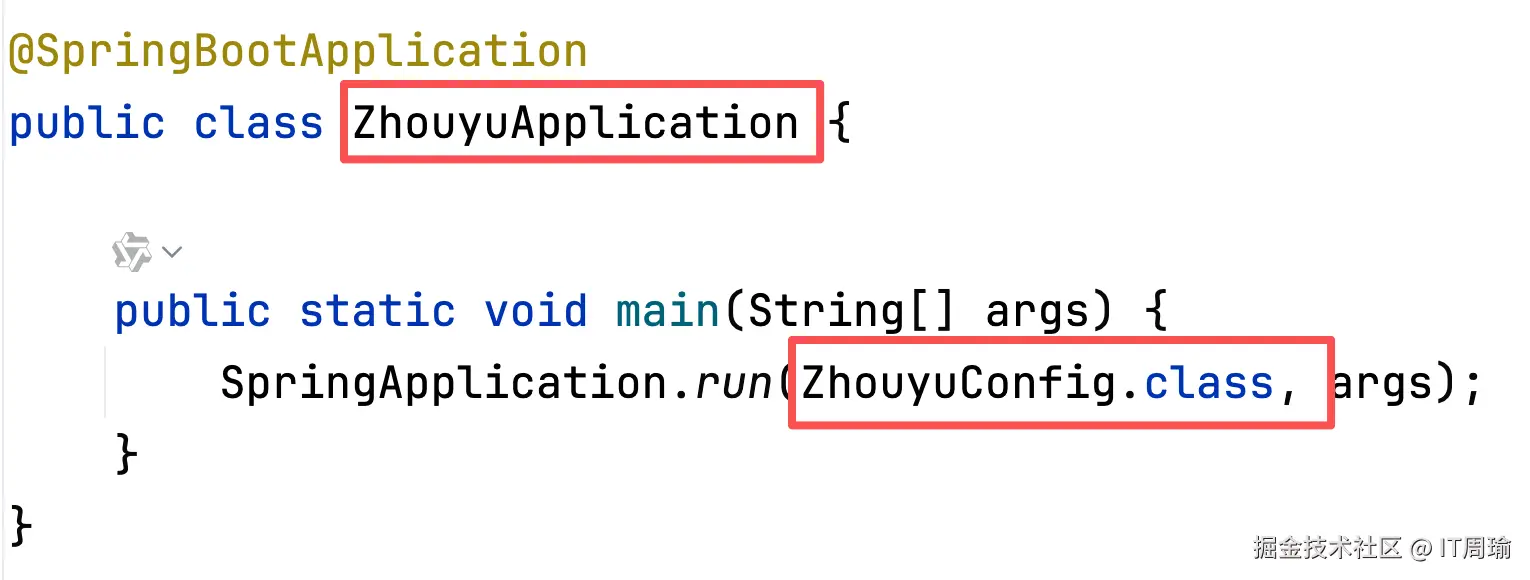
这样,SpringBoot会扫描ZhouyuConfig这个类所在的包路径,而不是启动类ZhouyuApplication。
回到上面,确定了basePackages之后,就要开始进行真正的扫描了:
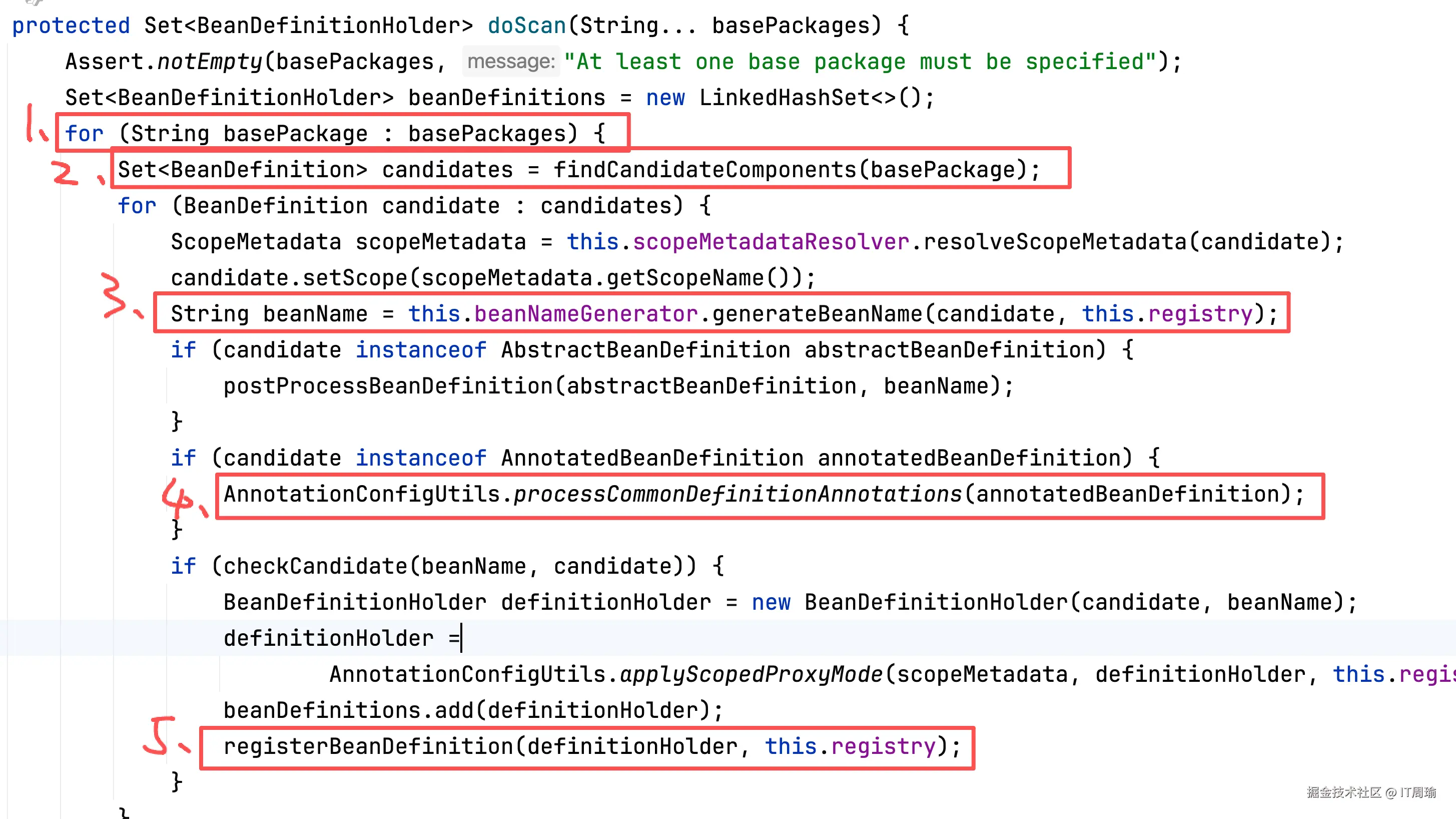
扫描又分为5大步骤:
- 遍历basePackages,也就是说你可以定义多个扫描路径,如果你觉得你的项目启动慢,可以检查一下是不是扫描路径定义的太大了,扫描了太多无效的目录,因为你要理解,所谓扫描Bean,就是Spring要去遍历你指定的包路径下的每个类,去判断这个类是不是Bean,比如是不是加了@Component注解,如果加了就是Bean,没加就不是Bean,因此如果一个包路径下面类越多,Spring扫描起来就越耗时,这时候合理的拆分包路径,多定义几个更高效的包路径,会更好
- 第二步才是重点,会真正的去扫描包路径下面到底有哪些Bean,并返回对应的BeanDefinition对象,也就是Bean的定义,注意这里只是Bean的定义对象,并不是最终的Bean对象,扫描是不会创建Bean对象的,它只是要找到包路径下面有哪些Bean,以及它的定义是什么,比如Bean的类型
- 第三步,利用BeanNameGenerator生成bean的名字
- 第四步,处理其他注解,比如@Lazy、@Primary等,这里也是Bean定义,比如如果当前扫描到的Bean上面有@Lazy注解,那么就表示这个Bean是一个懒加载的Bean,对应的BeanDefinition对象中的lazyInit属性为true。
- 第五步,将扫描到的Bean定义对象,注册到Spring容器中,BeanDefinitionHolder实际上就是BeanDefinition,只不过额外包含了beanName,BeanDefinition对象是没有beanName属性的。
重点是第二步,扫描过程中到底是如何根据扫描路径找到有哪些Bean的?
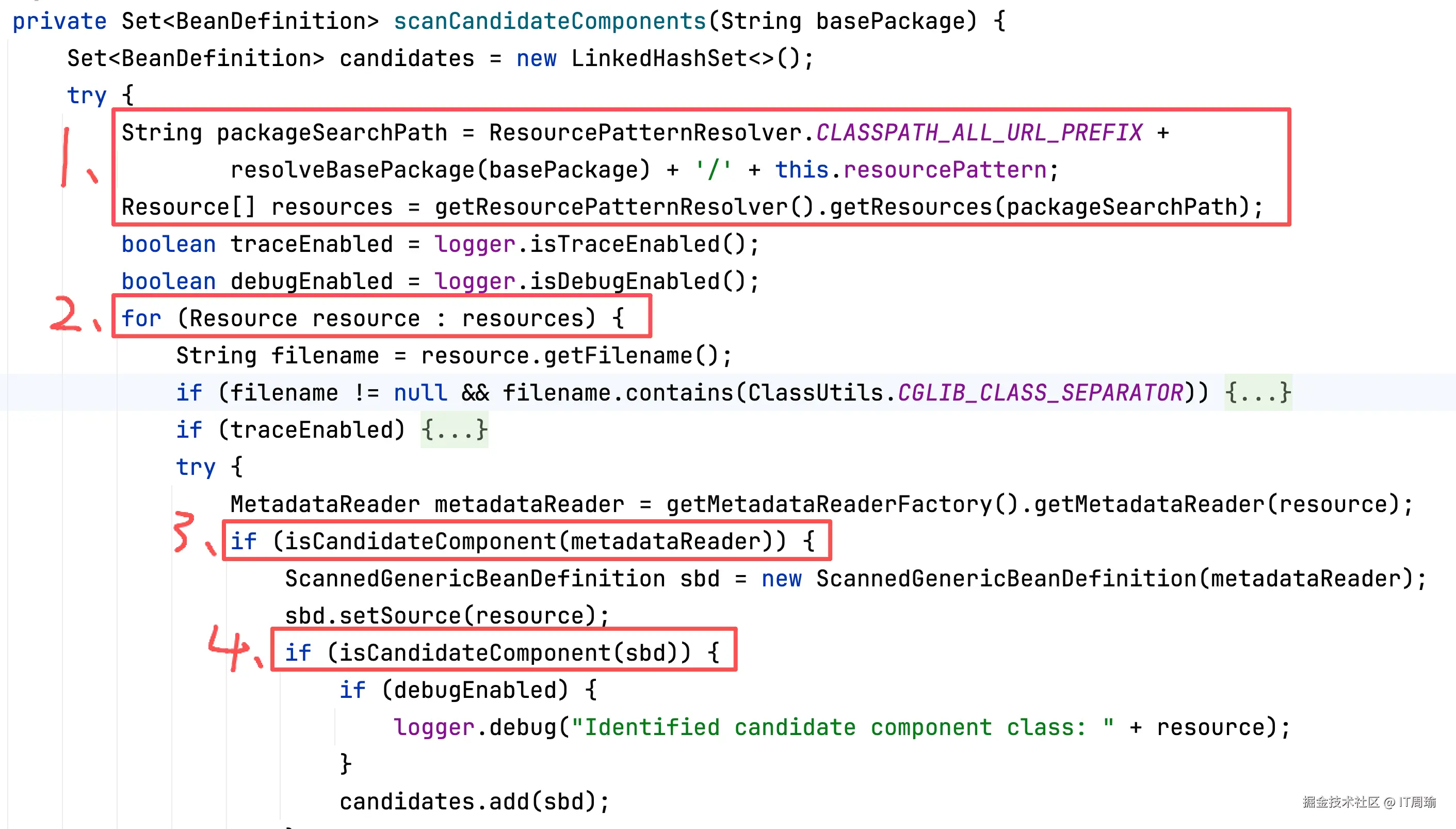
这里又分为四步,第一步,找到包路径下面所有的class文件,还记得resourcePattern的默认值吧:
第二步,遍历每个class文件。
第三步,判断class文件对应的类符不符合excludeFilters和includeFilters,如果和excludeFilters匹配就过滤掉,如果和includeFilters匹配,就会调用isConditionMatch(),会进一步判断@Conditional条件注解。
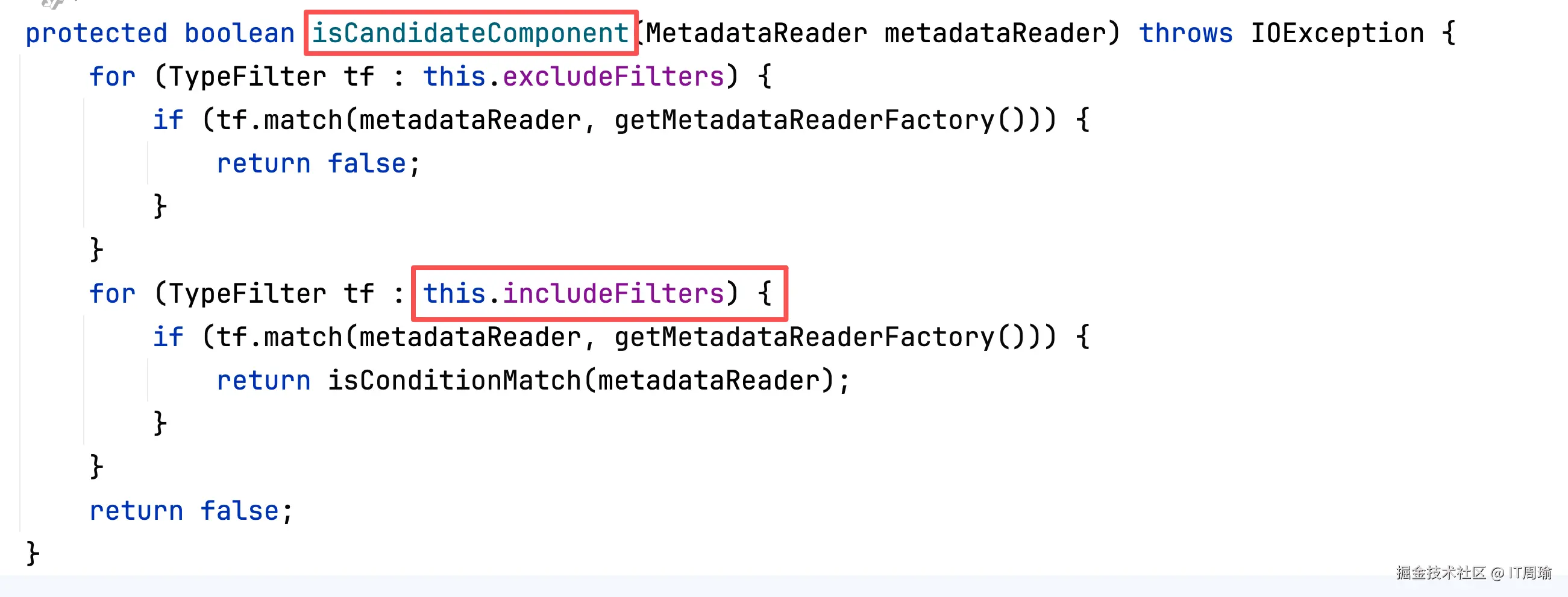
这里的重点是,默认includeFilters中会包含一个@Component注解对应的AnnotationTypeFilter:

作用是判断当前类上面是不是有@Component注解,如果有就跟这个Filter匹配。
总结一下,会先获取扫描路径下的所有class文件,然后判断类上是不是有@Component注解,会利用includeFilters来进行判断。
正常来说,一个class上有@Component注解,那么它应该就是Bean了,可是还有第四步,第四步也是一次过滤,它判断的是:

当前class是不是接口,是不是抽象类,如果是抽象类,有没有@Lookup注解。
如果class是一个接口,就算加了@Component注解,它也不能成为Bean,因为接口不能实例化,更没办法创建Bean对象。
如果class是一个抽象类,如果加了@Lookup注解,那么它会是一个Bean,关于@Lookup注解的作用是什么,也只能留在后面再分析了,可以关注我。
到此为止!Spring整个扫描的过程就分析完了,最后再总结一下:
- SpringBoot启动时,会触发Spring容器启动
- Spring容器启动过程中,会解析配置类
- 解析配置类时会解析@ComponentScan注解,从而进行扫描
- 扫描时,会先获取扫描路径下的class文件
- 然后判断是不是加了@Component注解,是不是接口,是不是抽象类
- 如果是一个Bean,就会生成对应的BeanDefinition对象
- 然后将BeanDefinition对象注册到Spring容器中
这就是Spring扫描的流程。
我是IT周瑜,期待你的关注、点赞、分享,也欢迎各位关注我的公众号:IT周瑜,有更多技术干货。