目录
[1. HTTP 协议](#1. HTTP 协议)
[2. Fiddler](#2. Fiddler)
[3. 协议格式](#3. 协议格式)
[1. HTTP 请求](#1. HTTP 请求)
[2. HTTP 响应](#2. HTTP 响应)
[4. URL](#4. URL)
[1. 方法](#1. 方法)
[2. 请求/响应头](#2. 请求/响应头)
[3. 常见状态码](#3. 常见状态码)
[三、构造 HTTP 请求](#三、构造 HTTP 请求)
[1. 使用 Postman](#1. 使用 Postman)
[2. 调用SocketAPI](#2. 调用SocketAPI)
[3. html 和 js](#3. html 和 js)
[1. 基本概念](#1. 基本概念)
[2. 对称加密](#2. 对称加密)
[3. 非对称加密](#3. 非对称加密)
[4. 中间人攻击](#4. 中间人攻击)
[5. 公证机构](#5. 公证机构)
前言
本文系统介绍了HTTP协议及其相关技术要点。主要内容包括:1. HTTP协议概述:解释了HTTP协议的基本特性、交互过程及Fiddler抓包工具的使用方法;2. 协议格式解析:详细说明了HTTP请求和响应的四部分结构(首行、头、空行、正文)及URL的组成要素;3. GET/POST方法对比:澄清了常见误解,强调两者本质区别在于使用习惯而非安全性;4. 状态码和头部字段:列举了常见状态码含义及Cookie等重要头部字段的作用机制;5. 请求构造方式:介绍了Postman工具及Socket API实现方法;6. HTTPS加密机制:阐述了对称/非对称加密原理、SSL握手过程及中间人攻击防范措施。文章全面覆盖了HTTP/HTTPS协议的核心概念和应用场景。
一、 概述
1. HTTP 协议
HTTP 协议是一个超文本传输协议,不仅仅可以携带字符串,还可以携带图片,html 等特殊格式;
HTTP 协议目前广泛使用的版本仍然是 HTTP/1.0;
HTTP/1.0 是基于 TCP 协议的;
HTTP 最主要的应用场景是网站,用于客户端和服务器之间传输数据;
HTTP 的交互过程是典型的"一问一答",客户端不请求,服务器是不能主动给客户端发消息的;
2. Fiddler
HTTP 协议的报文,可以使用 Fiddler 进行抓包;
Fiddler 本质上是一个客户端代理;
客户端把请求发给代理,代理再把请求发给服务器; 服务器返回响应给代理,代理再把响应发给客户端;
代理有客户端代理,也有服务器代理;客户端代理也叫正向代理,服务器代理也叫反向代理;
打开网站的过程:
- 打开网站,客户端和服务器之间进行交互,不是只有一次,通常都会有很多次;
- 客户端和服务器第一次交互,是拿到页面的 html;
- html 还会依赖 css和 js,html 被浏览器加载之后,又会触发其它的 http 请求,获取 css 和 js 等;
- 当执行到 js,又会触发一些 http 请求,获取到数据;
在 Fiddler 中,蓝色的报文往往表示返回的是一个 html,往往是访问网站的入口请求;
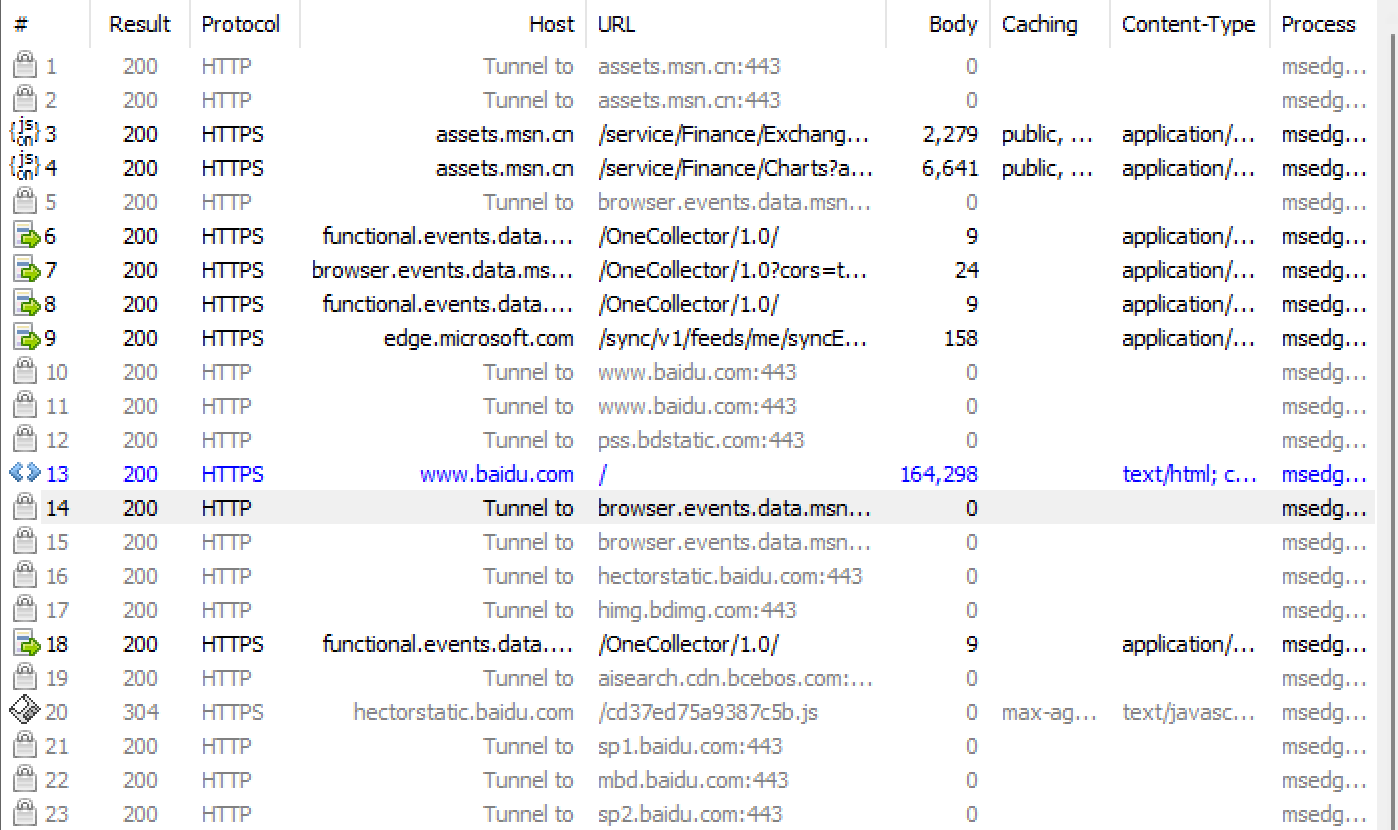
双击报文,可以看到明细,上面的是请求,下面的是响应,点击 Raw 可以看到原始数据,也可以点击 View in Notepad 在记事本中查看:
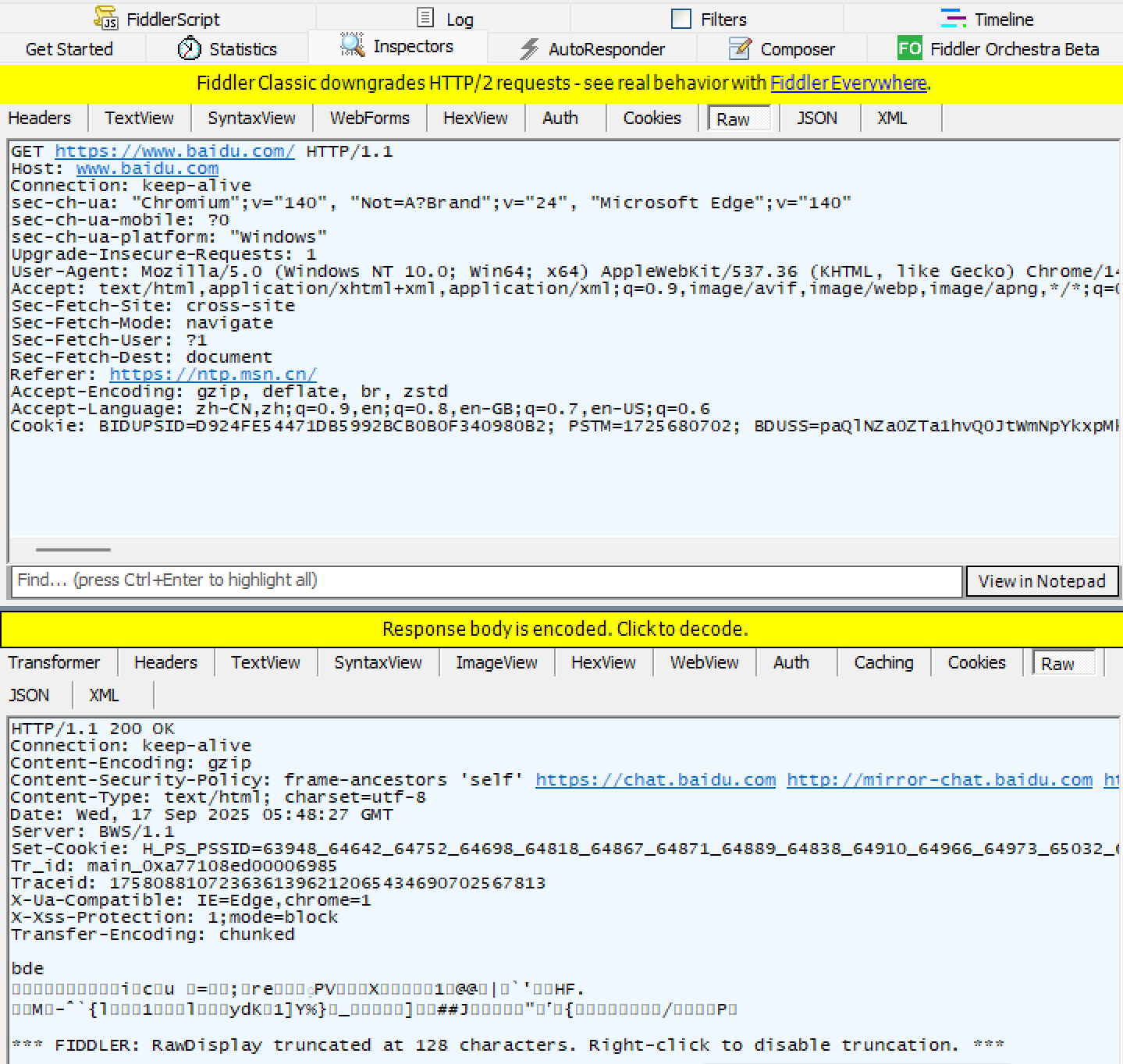
如果响应中出现乱码,是因为为了节省带宽,将响应中的正文压缩了;
可以点击 Response body is encoded. Click to decode 解压,显示就正常了;
3. 协议格式
1. HTTP 请求
HTTP 请求中包含四个部分:首行,请求头,空行,正文(body);
首行:包括方法,URL 和 协议版本号;

请求头:
包含多个键值对,这些键值对是 HTTP 协议中定义的;
键值对之间使用换行分割,键和值之间使用冒号空格分割;

空行:表示请求头结束

正文(body):
就是 http 协议的载荷,有的请求有正文,有的没有;
正文的可以是各种格式,例如:json;

2. HTTP 响应
HTTP响应中也包含四个部分:首行,响应头,空行,正文(body);
首行:
也包含三个部分:协议版本号,状态码,和状态码描述;
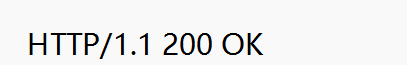
响应头:
同请求头;

空行:表示响应头结束;
正文(body):可以是各种格式,例如 html,json等;
4. URL
用于描述一个网络上资源的位置;
网络上的资源位置是如何描述的:
- 通过 IP 地址,知道服务器的位置;
- 通过端口号知道进程;
- 通过带层次的文件路径知道具体资源的位置;
URL 可以用于 HTTP 协议,也可以用于其它协议;
以下面 URL 为例:
http://user:pass@www.example.com:80/dir/index.html?uid=1\&name=1#ch1
URL 包括:协议方案名,登录信息,域名或者 IP 地址,端口号,带层次的文件路径,查询字符串和片段表示符;
登录认证信息:
写在 URL 中并不安全,因此基本不在 URL 中写了;
IP 地址:
写域名或者 IP 地址都可以;
端口号:
如果不写端口号,就会使用默认端口号,http 协议的默认端口号是 80,https 的默认端口号是 443;
查询字符串:
是给服务器传递信息的重要途经,也是按照键值对组织的,通过 ?开始,键值对之间使用 & 分割,键和值使用 = 分割;
查询字符串中键值对是程序员自定义的;
片段标识符:
用来分割页面的某个部分,通过片段表示可以完成页面内跳转;
URL encode:
在 URL 中 /,:,?,&,@ 等符号都是具有特殊含义的;
在查询字符串里面使用键值对,如果想使用特殊符号,汉字或者其它语言,应该进行转义;
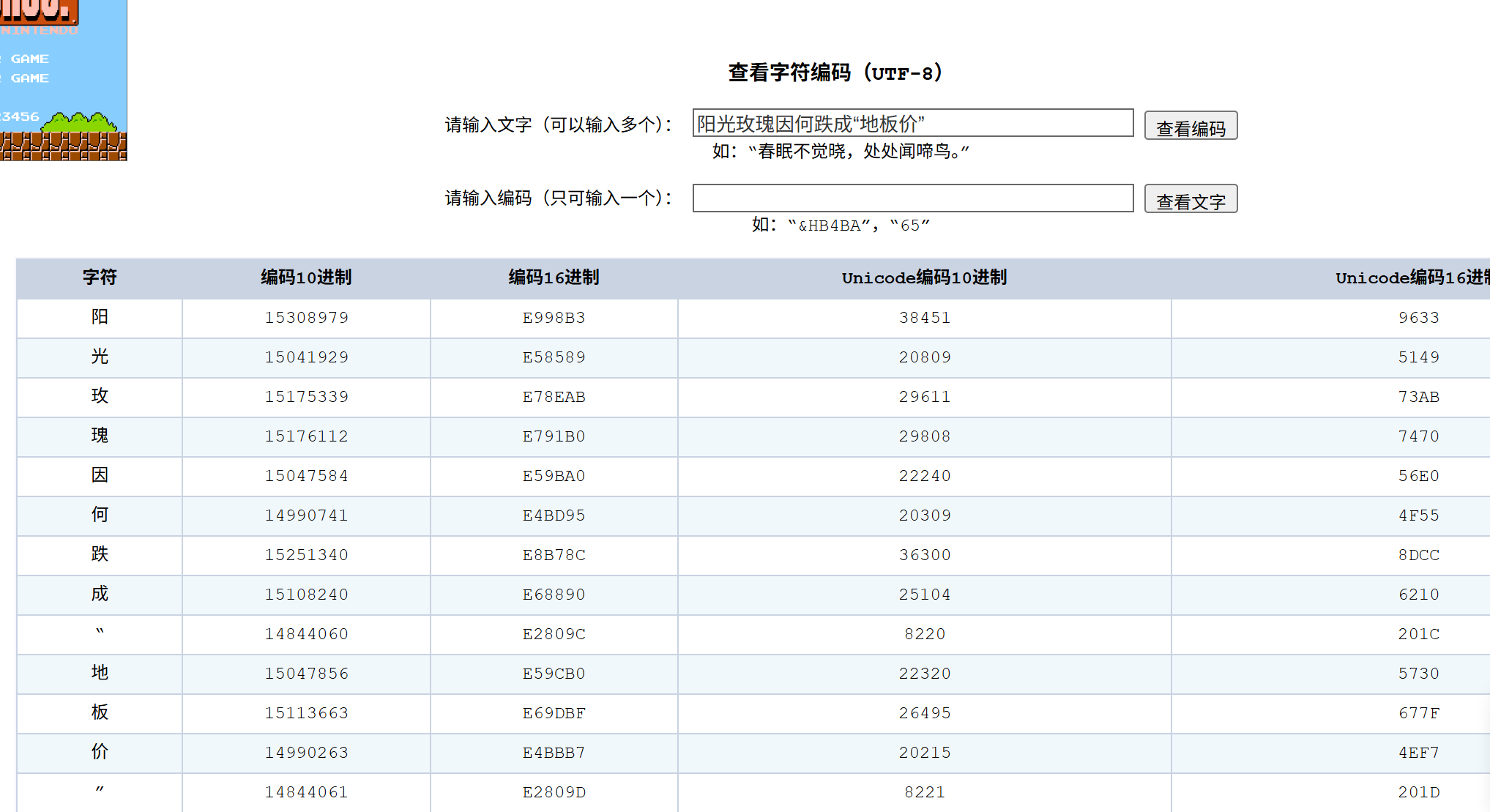
转义的方式是通过 % 加上字符在 UTF8 码表中的编码值的 16 进制表示;
例如:

真实的 URL 中是没有汉字的,而是使用了转义的方式:
二、协议解析
1. 方法
http 协议中使用最多的方法是 GET 和 POST;
GET 操作可以理解为从服务器获取资源,也叫做读操作;
POST 操作可以理解为向服务器传输内容,也叫做写操作,常用于登录和上传;
GET 和 POST 的区别:
- GET 和 POST 本质上没有区别,可以互相替换;
- 在使用习惯上,GET 习惯于把数据放到 URL 的查询字符串中,POST 习惯于把数据放到正文中;实际上 GET 也可以把数据放到正文中,POST 也可以把数据放到查询字符串中;
- 语义上 GET 是用来从服务器获取数据,POST 是给服务器传输数据;
- 关于幂等性,标准文档建议 GET 实现成幂等的,POST 则无要求;幂等指的是输入内容一定,输出结果也一定;
关于 POST 和 GET 的错误说法:
-
- POST 比 GET 更安全,登录的时候如果使用 GET,用户名和密码就会显示在 URL 上;
- 如果使用明文传输,不管是 GET 方法,还是 POST 方法,只要通过抓包,都可以获取用户名和密码,本质上这都是不安全的,不存在 POST 比 GET 更安全的说法;
- 安全的实现关键在于加密,加密做的好,放在 URL 或者正文中,都不容易被破解,都是安全的;
-
- GET 的数据传输量小,POST 的数据传输量大;
- GET 虽然习惯于把传输的数据放在查询字符串中,但是 URL 的长度本身是没有限制的,因此 GET 可以把放在正文传输的数据都放在 URL 中,POST 比 GET 传输数据量大的说法不成立;
-
- GET 只能携带文本数据,POST 能携带二进制数据;
- 虽然 URL 中只能携带文本数据,但是可以对二进制数据进行 urlencode,转化成文本,服务器接收到再进行 urldecode,就能将文本还原成二进制数据;
- POST 请求中虽然经常携带二进制数据,但也不是直接携带,也是通过 urlencode 或者 base64 转码成文本数据;
2. 请求/响应头
**Host:**表示服务器的主机和端口;虽然 url 中已经有 IP 地址和端口号了,并且绝大部分都是相同的,但是也存在 Host 和 url 中不相同的情况;
**Content-Length:**http 协议的底层也是 TCP,接收方的缓存区中数据会连在一起,因此也存在粘包问题。使用这个长度就可以知道正文中的内容占多少字节,明确包之间的边界,解决粘包问题;
**Content-Type:**表示正文中的数据格式;
请求中常见的格式:
- application/json;
- application/x-www-form-urlencoded,也称为 form 表单;
- mutipart/form-data,上的文件需要用到;
响应中常见的格式:
- text/plain 纯文本;
- text/html;
- text/css;
- application/javascript;
- application/json;
- img/png;
- img/jpg;
浏览器和服务器交互时,为了提高效率,会把不变的内容在浏览器本地的硬盘上进行缓存,后续再向服务器请求就会直接读本地的,减小网络开销;
调试时,经常通过 ctrl+F5 的方式清除缓存;
**User-Agent(简称 UA):**描述了操作系统和浏览器的信息;根据用户的操作系统和浏览器的信息,给用户展示不同的排版;
**Referer:**描述了页面是从哪里跳转的;
直接输入 URL 和从收藏夹打开,是没有 Referer 的,从其它网站跳转过来,就会有 Referer;
**Cookie:**本质上是浏览器本地持久化存储数据的机制;
为了保证用户数据安全,浏览器不允许网页直接调用浏览器的 API 去操作用户的数据;
而是给网页提供了一些 API,可以让网页有限度的操作,而不允许随意访问用户的文件系统;
Cookie 是键值对格式的,是程序员自定义的;
http 请求中的 Cookie 字段,就是把本地存储的 Cookie 信息,发送给服务器;
http 响应中可以有 Set-Cookie 字段,就是让浏览器在本地保存这个字段保存成 Cookie;
Cookie 的重要结论:
- 从哪里来:Cookie 是服务器返回给浏览器的,通常是首次访问或者登录之后;
- 到哪里去:Cookie 会存在浏览器本地的硬盘上,后续每次访问服务器,都会带上 Cookie;不同的客户端保存的 Cookie 是不同的;
- 存什么:Cookie 中存的是键值对格式的数据,内容是程序员自定义的;
- 在浏览器中如何组织:Cookie 在硬盘本地保存,按照不同的域名分别存储;
- 用途是什么:Cookie 的主要用途是在客户端保存数据,经常用来保存用户的身份标识,通过身份标识,找到服务器中存储的业务数据;业务数据不会保存在 Cookie 中,因为 Cookie 很容易被删除;
3. 常见状态码
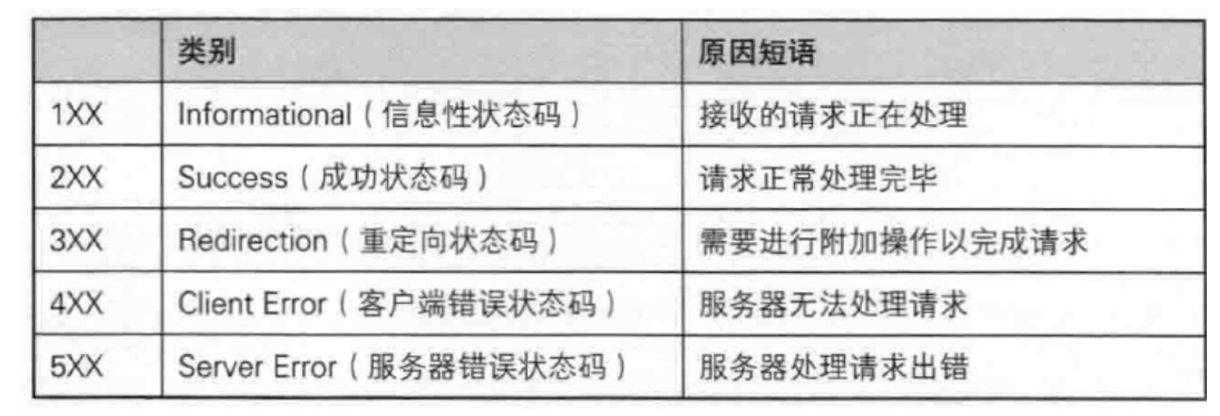
-
- 200 OK,表示请求成功;
-
- 404 Not Found,表示访问的资源没找到;
-
- 403 Forbidden,请求的资源没有权限访问;
-
- 405 Method Not Allowed,服务器不支持这个方法;
-
- 500 Internal Server Error,服务器内部错误;
-
- 504 Gateway Timeout,访问服务器超时;
-
- 302 Move Temporarily,临时重定向;
-
- 301 Move Permanently,永久重定向;
301 和 302 会影响浏览器的缓存:
如果是 301,表示永久重定向,浏览器会把重定向的地址缓存下来,后续继续访问直接访问重定向的地址即可,不需要再跳转;
如果是 302,表示临时重定向,浏览器不会缓存重定向的地址;
三、构造 HTTP 请求
1. 使用 Postman
Postman 界面如下:
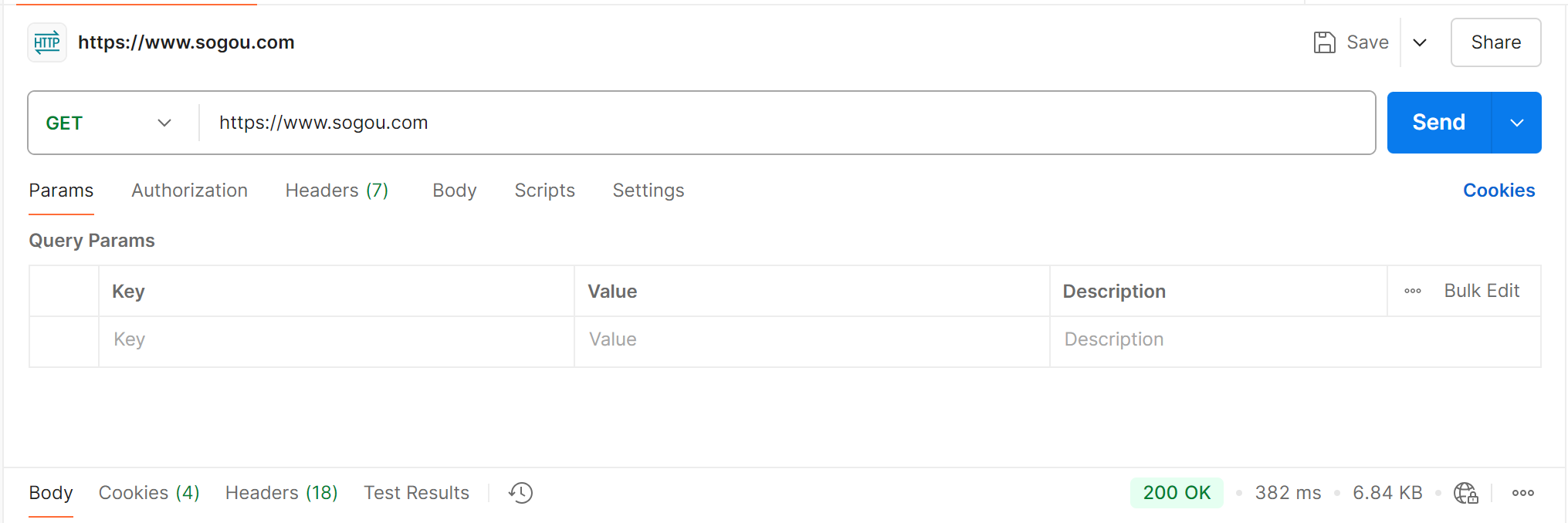
可以选择要使用的方法,方法后面写 URL;
Params 指的是 url 中的查询字符串;
Headers 指的是请求头;
Body 指的是正文,可以在里面添加多种格式的正文,例如 json,x-www-form-urlencoded等;
2. 调用SocketAPI
http 协议是一个文本协议,只需要按照 http 协议的格式拼接字符串即可,如下:
java
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
public class HttpClient {
private Socket socket;
private String serverIp;
private int port;
public HttpClient(String serverIp, int port) throws IOException {
socket = new Socket(serverIp, port);
this.serverIp = serverIp;
this.port = port;
}
public String get(String url){
// 按照 http 协议构造 http 请求报文
StringBuilder request = new StringBuilder();
// 首行
request.append("GET " + url + " HTTP/1.1\n");
// 请求头
request.append("Host: " + serverIp + ":" + port + "\n");
// 空行
request.append("\n");
String response = null;
try(OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream()){
// 发送 http 请求
outputStream.write(request.toString().getBytes());
// 接收 http 响应
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
response = new String( buffer, 0, n, "utf-8");
} catch (IOException e) {
throw new RuntimeException(e);
}
return response;
}
public String post(String url, String body){
// 按照 http 协议构造 http 请求报文
StringBuilder request = new StringBuilder();
// 首行
request.append("POST " + url + " HTTP/1.1\n");
// 请求头
request.append("Host: " + serverIp + ":" + port + "\n");
request.append("Content-Length: " + body.getBytes().length + "\n");
request.append("Content-Type: txt/plain\n");
// 空行
request.append("\n");
// 正文
request.append(body);
String response = null;
try(OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream()){
outputStream.write(request.toString().getBytes());
// 接收 http 响应
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
response = new String(buffer, 0, n, "utf-8");
} catch (IOException e) {
throw new RuntimeException(e);
}
return response;
}
public static void main(String[] args) throws IOException {
HttpClient httpClient = new HttpClient("www.sogou.com", 80);
String getResp = httpClient.get("/index.html");
System.out.println(getResp);
}
}实际应用中,基本不需要自己手动构造 http 协议请求,而是使用一些第三方库;
第三方库的代码,可以在 Postman 中把请求构造好,点击 </> 图标,查看 Postman 给出的实现;
3. html 和 js
实际工作中,会涉及到用 html 和 js 构造 http 请求;
四、HTTPS
1. 基本概念
HTTPS 是在 HTTP 的基础上引入了一个 SSL 加密层;
引入 HTTPS 的主要目的是防止数据被劫持篡改;
解决安全问题的核心就是加密,加密和破解是一个对抗的过程,理论上没有绝对的安全,只要破解的成本高于数据本身的价值,就是绝对安全的;
明文:加密前的数据;
密文:加密后的数据;
密钥:加密和解密过程中,需要用到密钥;
**对称加密:**加密和解密用的是同一个密钥;
非对称加密:
加密和解密用的是两个不同的密钥,两个不同的密钥一个是公钥,一个是私钥,公钥和私钥是成对出现的;
使用公钥加密,就需要使用私钥解密;
使用私钥加密,就需要使用公钥解密;
公钥是公开的,私钥是自己保存好的;
对 HTTPS 数据进行解密,得到的就是 HTTP 格式的数据;
引入加密是为了对传输的数据进行保护,加密的主要对象就是 HTTP 协议的请求/响应头和正文;
2. 对称加密
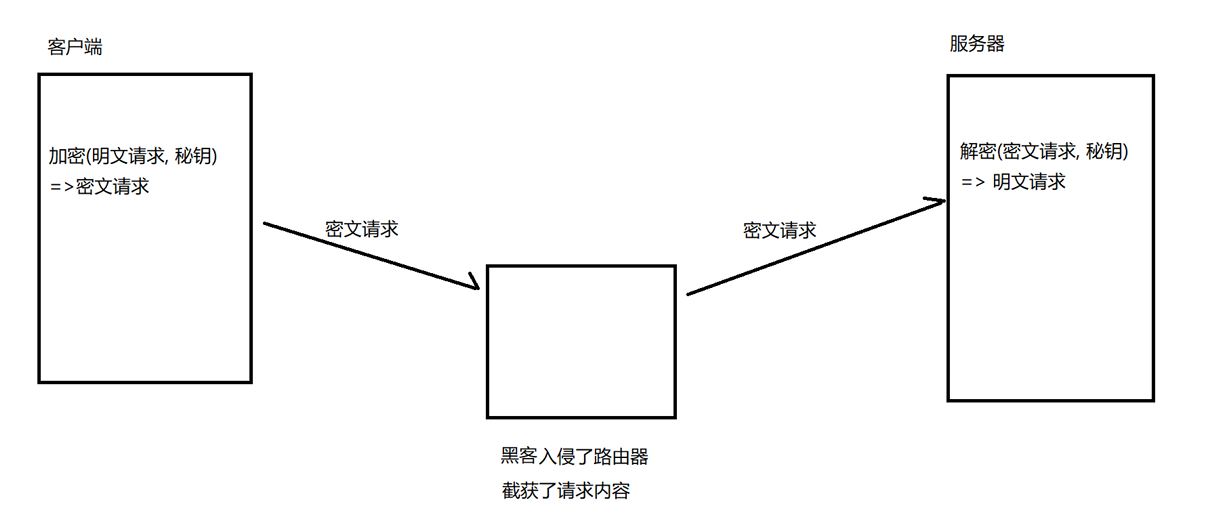
对称加密,加密和解密使用的是同一个密钥;
不同的客户端需要使用不同的密钥;
客户端连接服务器时,需要生成一个随机的密钥,传输给服务器,也可以服务器生成密钥传输给客户端,关键在于要将密钥传输给对方;
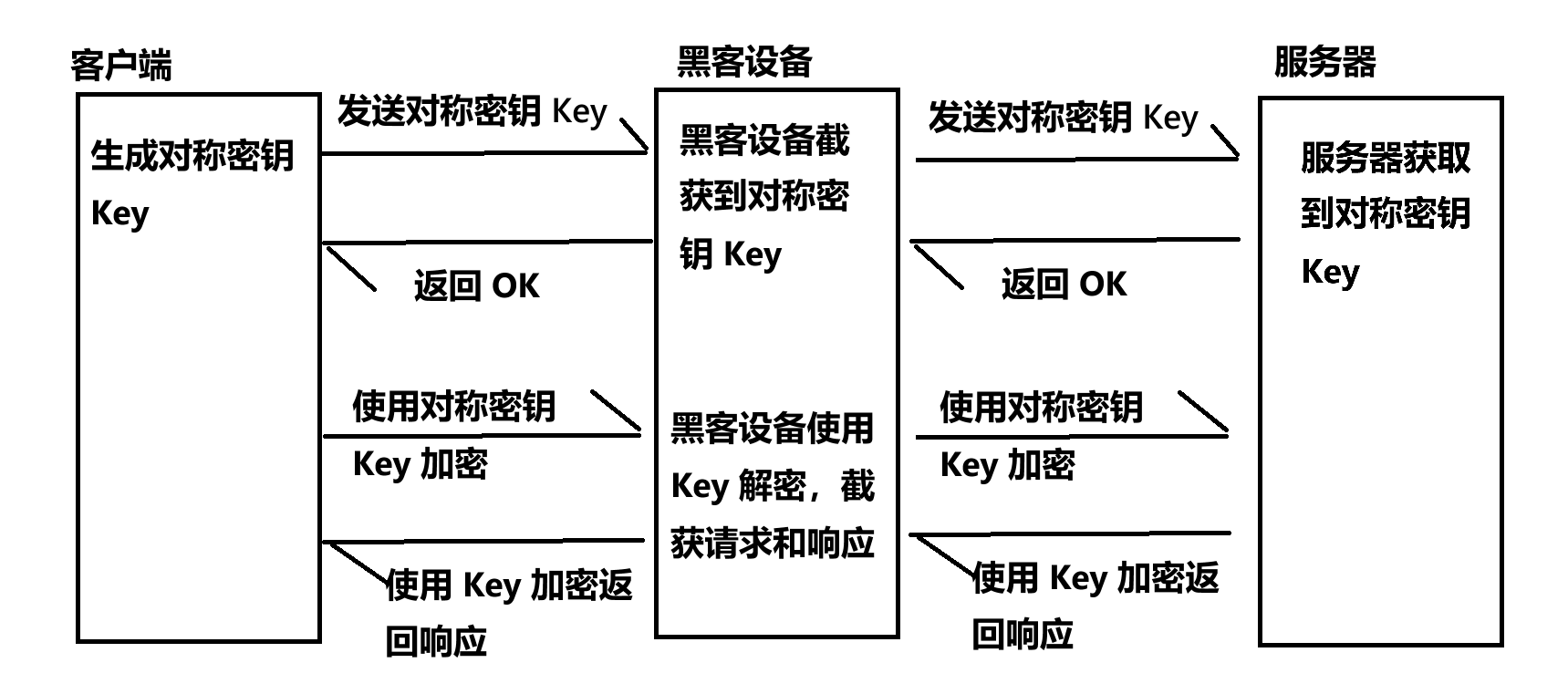
传输时,如果经过黑客的设备,传输的密钥就会被截获,加密就形同虚设;
3. 非对称加密
引入非对称加密的主要目的是对对称密钥进行加密,确保对称密钥的安全性;
非对称加密的加密解密成本远高于对称加密,直接使用非对称加密,如果数据量较大,加密和解密的开销就会非常大,因此非对称加密不适用于数据量较大的场景;
非对称加密使用一对密钥,一个公钥,一个私钥,公钥加密使用私钥解密,私钥加密使用公钥解密;
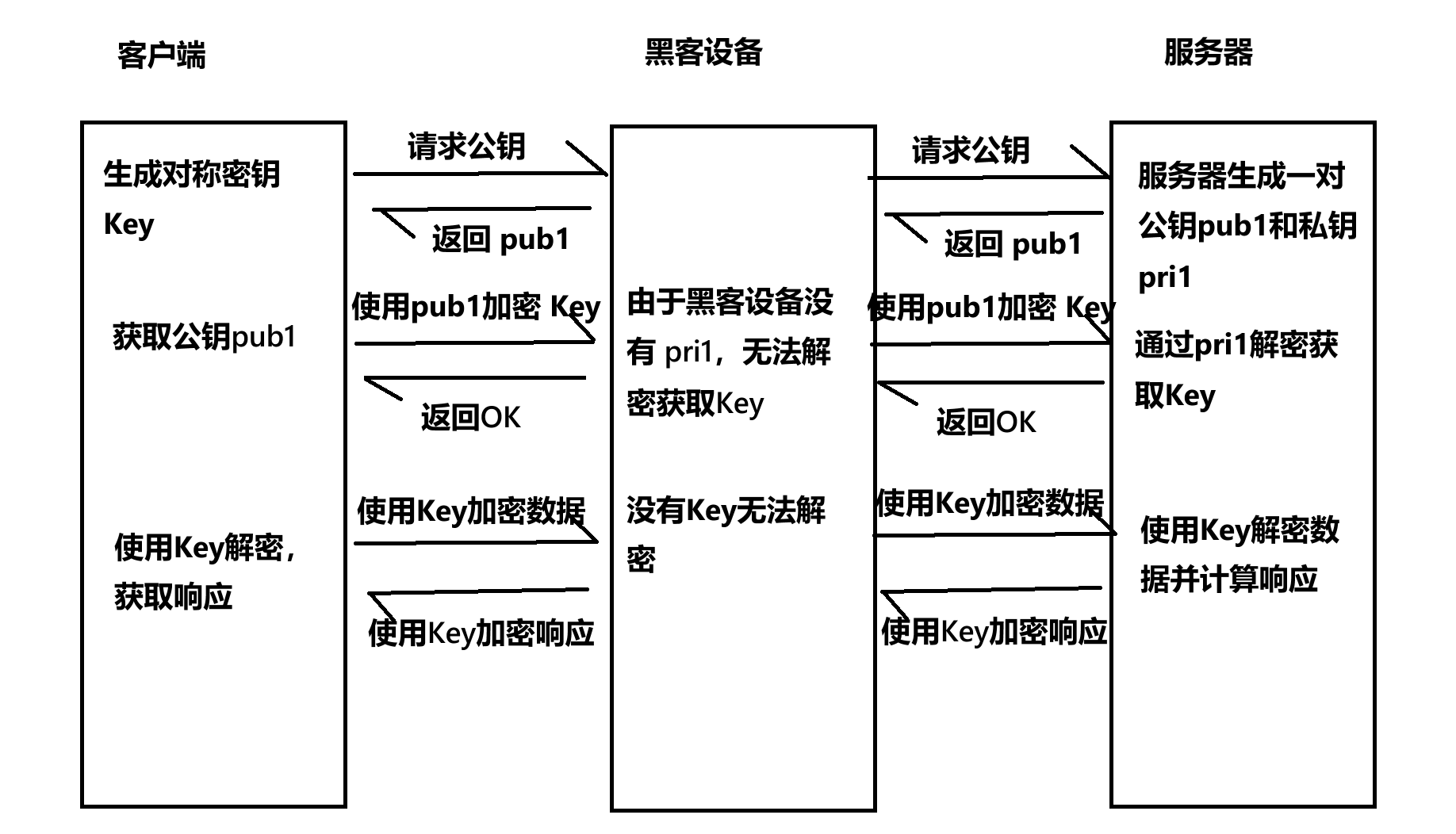
服务器持有私钥,并将公钥发送给客户端,黑客设备也能获取到公钥;
客户端可服务器交互时,假设数据经过黑客的设备:
- 客户端使用公钥加密,将对称密钥发送给服务器;
- 黑客设备截获到这个数据,但是没有私钥,不能解密,无法获取对称密钥;
- 对称密钥转发给服务器后,服务器使用私钥解密,获取对称密钥;
- 后续双方使用对称密钥,加密数据,进行通信;由于黑客设备没有获取到对称密钥,后续的通信就是安全的;
交换密钥的过程就是 SSL 的握手过程;
4. 中间人攻击
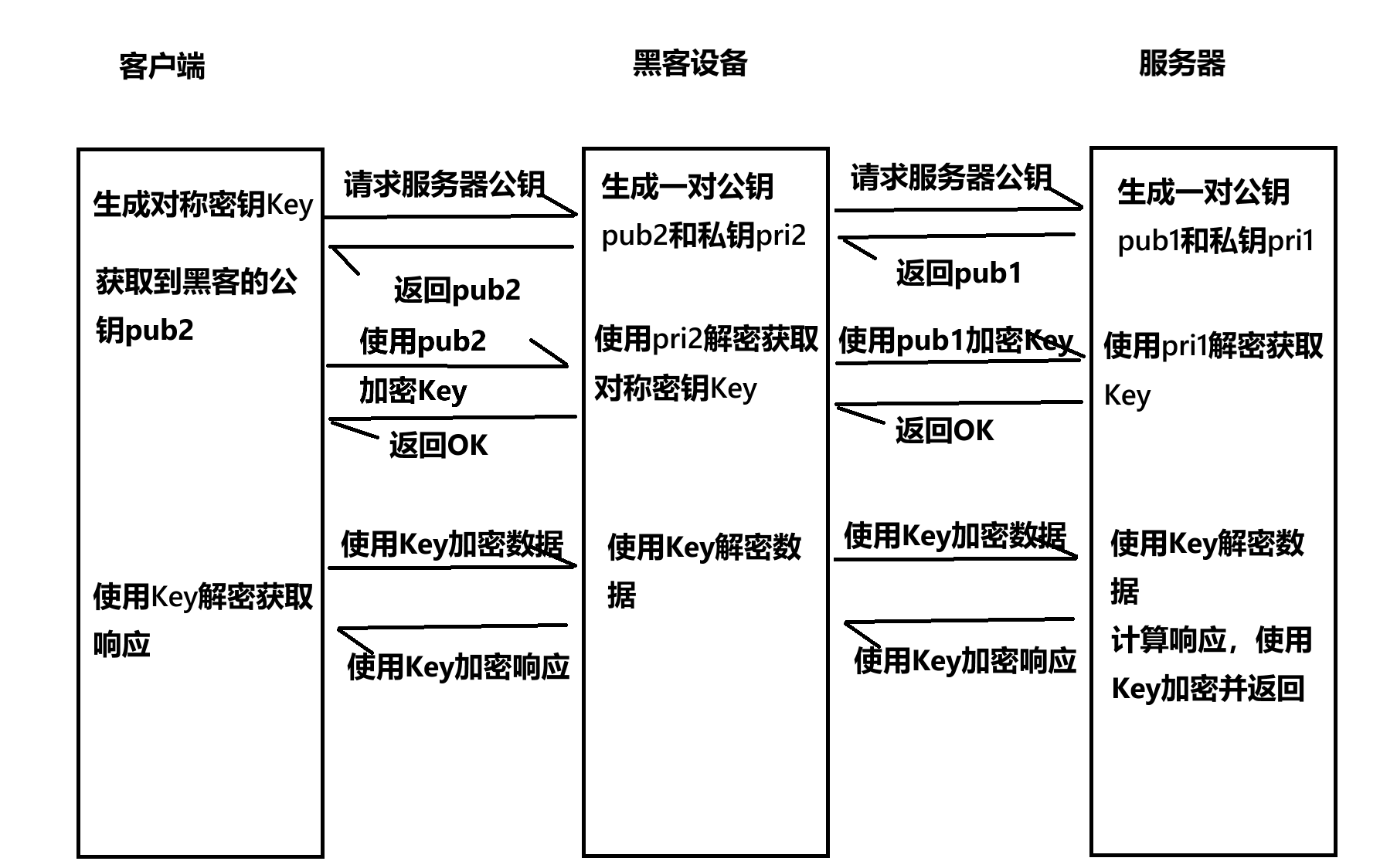
假设客户端生成的堆成密钥是 key;
非加密过程中服务器使用的公钥和私钥分别是 pub1 和 pri1;
针对非对称密钥加密的过程,黑客设备也可以生一对公钥和私钥 pub2 和 pri2;
过程如下:
- 客户端请求服务器的公钥时,服务器返回 pub1;
- 黑客设备将 pub1 替换为 pub2,返回给客户端;
- 客户端拿到 pub2 后,使用 pub2 针对 key 进行加密,并将加密后的密钥发送给服务器;
- 黑客设备拿到使用 pub2 加密的 key 后,使用 pri2 进行解密,获取到 key;
- 黑客设备再使用 pub1 对 key 进行加密,将加密后的 key 发送给服务器;
- 服务器拿到加密的 key 后,使用 pri1 进行解密,拿到对称密钥 key;
- 后续客户端和服务器使用对称密钥进行通信,由于黑客设备也获取到了对称密钥 key,因此后续的通信都将被黑客截获;
5. 公证机构
上述中间人攻击的过程,关键在于客户端无法区分拿到的公钥是服务器的还是黑客设备的;
如果客户端能识别服务器的公钥,上述问题将迎刃而解;
于是为了解决上述问题,引入了第三方公证机构;
搭建服务器的人,向第三方公证机构申请,公证机构为服务器提供一个证书;
证书的内容:
证书是一个结构化的数据,包含多个属性,有服务器的域名,证书的有效时间,服务器的公钥,公证机构的信息,以及证书的签名等;
颁发证书的公证机构,会在办法证书的时候给这个证书计算一个校验和,然后用公证机构的私钥给这个校验和加密,就得到了证书的签名;
签名本质上是一个经过加密的校验和;
证书中的其它字段,通过一系列的算法,如 MD5,CRC等,得到一个较短的字符串,表示校验和;
证书的验证过程:
每次通讯的之前,客户端先发送信息,向服务器申请证书;
客户端拿到证书后,针对证书进行验证:
-
按照相同的校验和算法,保证书的其他字段都重新算一遍,得到校验和 1;
-
使用系统的内置的公证机构的公钥对数字签名进行解密,得到校验和 2;
-
对比两个校验和,如果没发生变化,则表示证书没有被篡改,里面的公钥就是服务器的公钥;
黑客设备能否篡改服务器公钥?
不能,因为一旦篡改公钥,客户端在计算证书的校验和的时候就会和证书自带的校验和不同;
黑客设备能否篡改证书自带的数字签名?
不能,黑客设备可以通过第三方公证机构的公钥进行解密,但是不能篡改:
- 如果篡改了,没有第三方公证机构的私钥,无法进行加密;
- 如果使用黑客设备的私钥进行加密,则客户端无法通过第三方公证机构的公钥解密;
黑客能否自己去第三方机构申请证书?
可以申请证书,但是不能替换服务器的,因为域名不一样,域名都是唯一的;即使替换了证书,也很容易被客户端发现;