q前言 当我们在讨论数据湖表格式(Table Format),我们在讨论什么?没错,我们在讨论数据湖表格式- -!。言归正传,数据湖表格式的出现是为了解决什么问题呢?是为了融合传统数仓的一些特性,用于解决传统数据湖在数据管理、查询性能和事务支持上的不足。而表格式就是 Lakehouse 架构上的一个额外的组件 - 事务层,它是文件格式之上的附加层,这个额外的层将 Lakehouse 与数据湖区别开。它使 Lakehouse 能够获得数据仓库功能,例如 ACID 事务支持、更新/删除支持、更好的 BI 性能。以下是表格式的核心价值:
- ACID 事务支持,保证数据一致性和可靠性;
- 支持 Schema 演化;
- 增量更新和删除;
- 数据裁剪,更高的查询性能;
- 时间旅行和版本控制;
而本文要剖析的元数据,我认为是 Paimon 的 2 块核心之一,另一个则是基于 LSM 的高效更新机制。正是有了这层元数据,才能解决传统数据湖的缺陷(在 ACID 事务支持上的不足);才有了 Version 的概念,进而才能支持历史数据查询;才能更好地做 Data Skipping,进而保障高效的查询性能;
一. 元数据文件的结构和布局
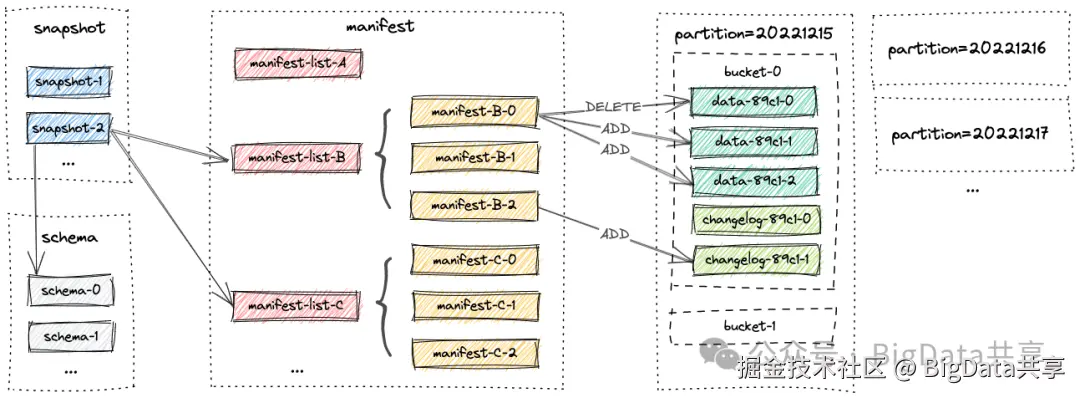
表的所有文件都存储在一个基本目录下。Paimon 文件以分层风格组织。下图说明了文件布局。从快照文件开始,Paimon 阅读器可以递归访问表中的所有记录。
本地测试代码用例,用于 paimon append 表的写入,每隔 10s 做一次 checkpoint。
vbnet
/** * @author BigData共享 */public class ScalableTable { public static void main(String[] args) throws Exception { // 初始化 Flink 环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.enableCheckpointing(10000L); env.getCheckpointConfig().setCheckpointStorage(new MemoryStateBackend(20 * 1024 * 1024)); TableEnvironment tableEnv = StreamTableEnvironment.create(env); // 创建 Paimon Catalog tableEnv.executeSql("CREATE CATALOG paimon_catalog WITH (" + "'type'='paimon', " + "'warehouse'='file:///tmp/paimon'" + ")"); tableEnv.executeSql("USE CATALOG paimon_catalog"); // 创建 Scalable Table tableEnv.executeSql("CREATE TABLE IF NOT EXISTS scalable_table (" + "word STRING, " + "dt STRING" + ") PARTITIONED BY (dt) WITH (" + "'bucket' = '-1'" + ")"); // 创建临时数据源表 tableEnv.executeSql( "CREATE TEMPORARY TABLE word_table (" + "id INT, " + "word STRING" + ") WITH (" + "'connector' = 'datagen', " + "'fields.id.kind' = 'random', " + "'fields.id.min' = '1', " + "'fields.id.max' = '100', " + "'fields.word.length' = '1'" + ")"); // 插入数据 tableEnv.executeSql("INSERT INTO scalable_table SELECT word, '20250816' FROM word_table"); env.execute(); } }我们来看下该表 queue_table 生成的元数据文件布局
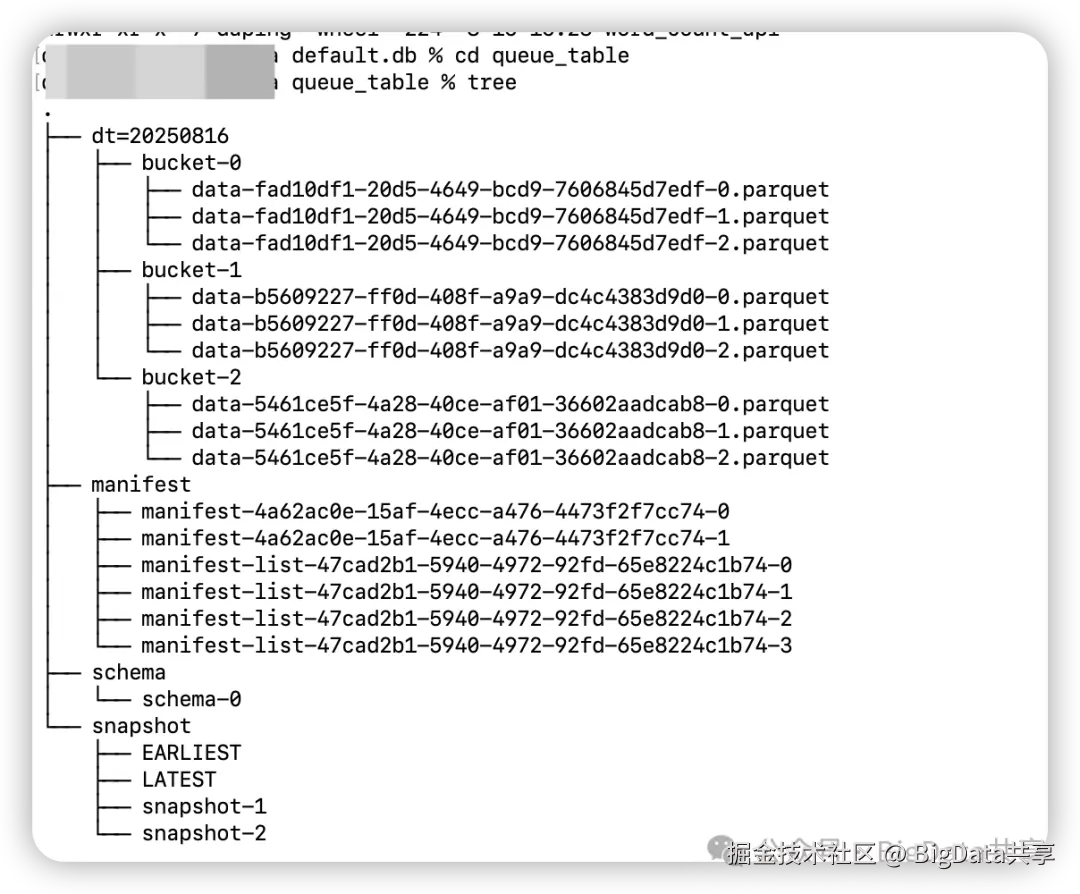
- snapshotFlink 每一次 checkpoint 会触发生成快照,所有快照文件都存储在 snapshot 目录中。快照捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据;通过时间旅行,用户还可以通过早期快照访问表的先前状态。snapshot 是个 json 文件。

- schema
schema存放的就是表结构信息:字段、分区键、主键、options等,每次表结构变更生成新的schema文件;

- manifest
该目录下包含两种文件: 清单列表(manifest-list)和清单文件(manifest)。清单列表是清单文件名的列表。清单文件是包含有关 LSM 数据文件和变更日志文件的更改的文件。例如,在对应的快照中创建了哪个 LSM 数据文件,删除了哪个文件。manifest 文件是 avro 格式。
查看 manifest-list 文件,可以找到对应的 manifest 文件
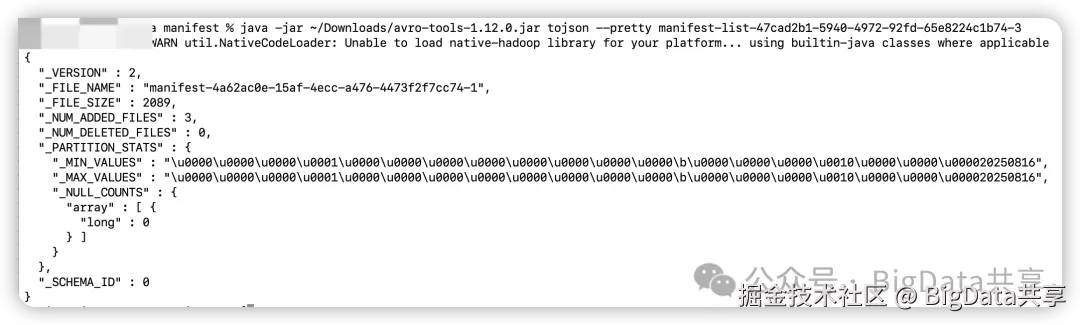
查看 manifest 文件,可以找到对应的 datafile 文件,也就是实际存储数据的文件
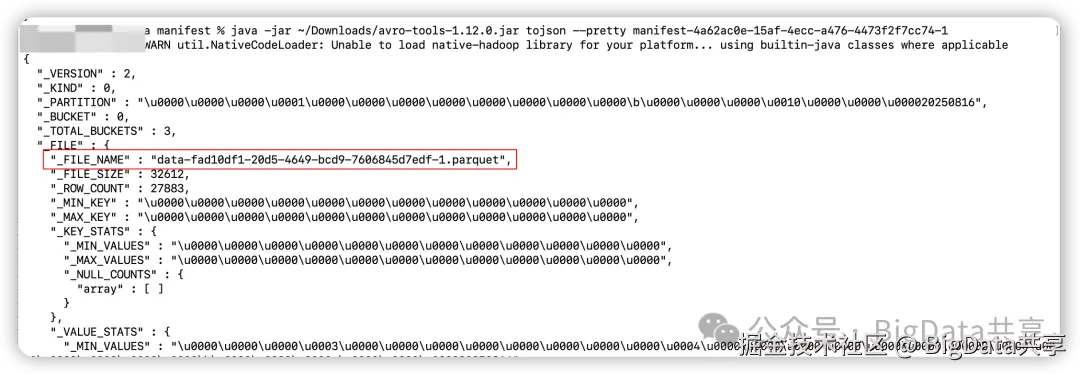
- datafile
数据文件按分区分桶分组。目前,Paimon 支持使用 parquet(默认)、orc 和 avro 作为数据文件的格式。Bucket 桶是 Paimon 表读写操作的最小单元。非分区、分区的数据都会写入到对应的桶中,需要注意的是,Bucket 个数会影响并发度,影响性能。

二. 怎么实现的数据的ACID等数仓特性
ACID特性
通过上面的元数据文件结构和布局可以看出,该元数据层由多个文件组成,形成一个树状结构,每个写操作都会创建一个新的表版本。写操作(如插入、更新、删除)在 Flink 做 Checkpoint 中原子提交,通过原子性地提交快照文件,如果失败,整个操作回滚,不影响现有数据,所有元数据和数据文件持久化到分布式存储(如HDFS或S3),实现了数仓的 ACID 特性。
模式演化(Schema Evolution)和 时间旅行(Time Travel)
每个快照引用一个模式 ID,新模式在提交时创建新文件,旧快照保持兼容。如果用户添加,删除,重命名列,不重写现有数据,而是通过新生成的 schema 文件来表示,在快照中引用新的 schema ID。通过指定旧快照 ID 查询历史版本,实现时间旅行。
三. 通过元数据文件怎么做的数据裁剪(Data Skipping)
数据裁剪(Data Skipping)是 Paimon 优化查询性能的关键机制,通过元数据中的统计信息,在查询规划阶段跳过无关数据文件,减少I/O开销。
如下图所示,根据要读的 snapshot 快照 ID 和 ScanMode,获取到对应的 manifestList 文件,根据 Partition_Stats(该 manifest 文件中各分区字段的最小值 Min, 最大值 Max, NullCounts),按分区条件进行过滤,得到 manifest 文件;然后读取对应的 manifest 文件,该文件记录有 Partition, Bucket, Key_Stats, Value_Stats,再根据这4个条件进行过滤,得到最终要读取的 datafile 文件。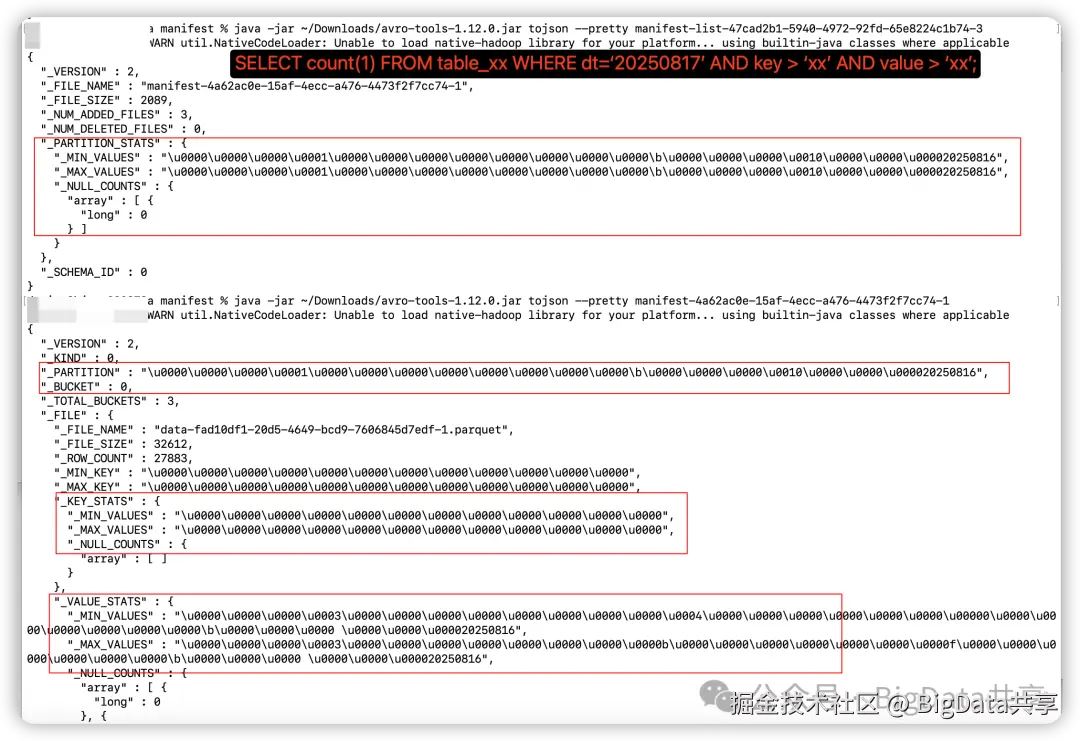
四. 元数据存在文件系统上优缺点
Paimon 或 Iceberg 等都旨在构建一个开放、通用的数据湖表格式,摆脱对特定元数据存储(如 Hive Metastore)的依赖,减少外部系统的依赖和可能存在的单点故障。另一方面,将元数据存储在文件系统(如 HDFS、S3)上也能实现高扩展性。但是对比数据库存储,读写方面的性能要差一些,元数据的访问依赖文件系统性能,我们线上就有遇到因为 HDFS 慢节点的问题导致在读写元数据阶段耗时过长的问题。在业界,也有 lakehouse 方案把元数据存储在数据库中。 更多大数据干货,欢迎关注我的微信公众号---BigData共享