在大数据时代,数据湖因 灵活、低成本、存算分离 而成为主流选择,但也面临一致性、查询性能等挑战。为解决这些问题,新一代 数据湖格式 在数据文件之上引入独立元数据层,为数据湖带来了 ACID 事务 和 Schema 演进等 数据库级能力。
本文将对比当前最主流的三种开源湖格式:Iceberg、Delta Lake 和 Paimon,深入分析它们的差异,帮助大家更好地进行技术选型。
另外,文章末尾我们准备了一份 生产级教程,带你从零构建可落地的实时数据湖方案。
核心原理简析
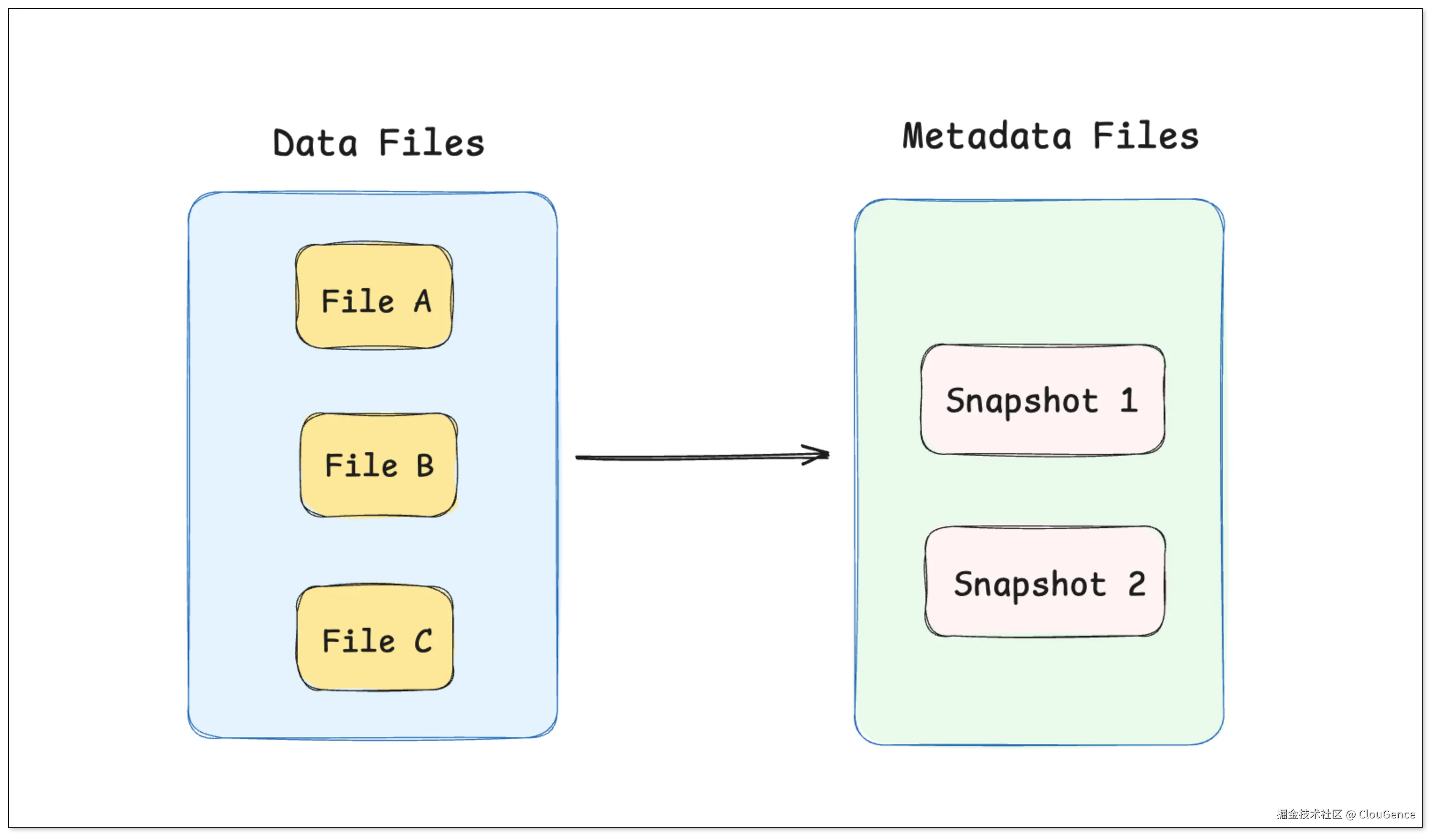
在现代数据湖格式中,元数据是保证数据一致性与可管理性的核心。
数据写入时,原始数据会被转换为实际的数据文件,然后通过一次快照提交原子化完成写入。
每次成功提交都会生成一个全新且一致的快照,查询引擎只需访问指定快照即可获得一致的数据视图,从而实现读写分离、版本回溯和并发写入下的一致性保障。
数据湖格式的核心思想是将表的状态信息(实际文件组成、Schema、分区等)集中管理。
-
元数据(Metadata) :记录了每一个 快照 的状态,包括写入了哪些文件,文件存储的位置等信息。它可以存储在文件系统(如 JSON、Avro)或托管服务(如 Hive Metastore)中。
-
数据文件(Data Files) :真正存储用户数据的 物理文件,通常是 Parquet、ORC 等列式格式,写入后不可变。
数据写入
下面通过一个简单的例子来理解数据湖的核心原理,假设我们有一张用户表(users),要执行以下操作:
-
初始写入 2 条用户记录。
-
再插入 1 条新用户记录。
-
更新 1 条用户记录。
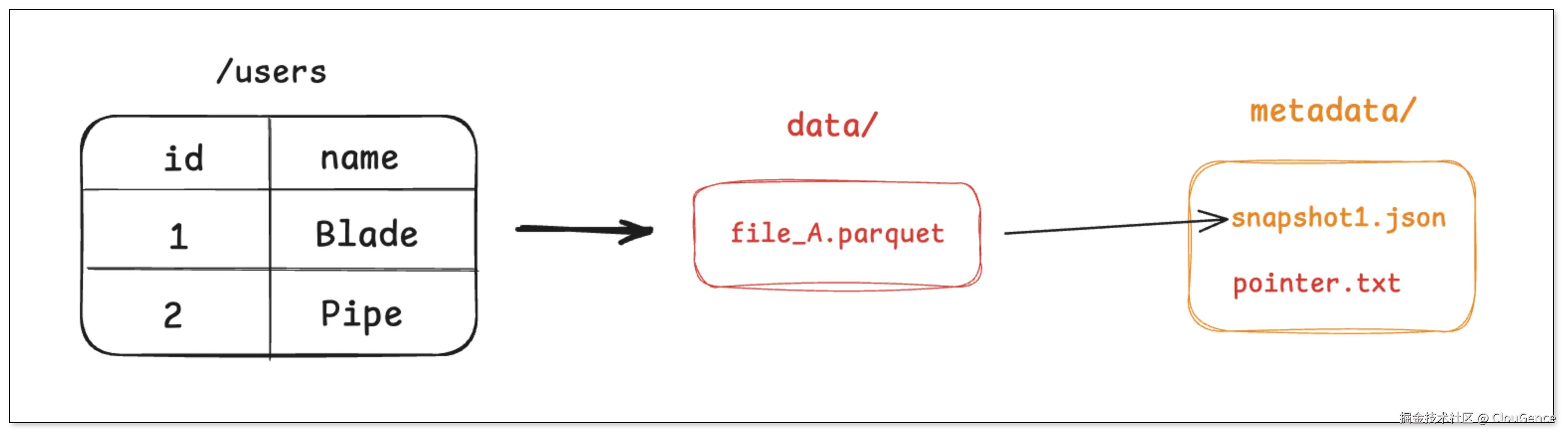
步骤一:写入 2 条用户记录
-
引擎将这两条记录写入到一个新的 Parquet 文件中,例如 file_A.parquet。
-
引擎创建一个元数据文件,记录下当前表的第一个快照 (snapshot_1) 包含了 file_A 这个文件。
-
最后引擎通过一次原子操作,将一个指针指向这个最新的 元数据文件。
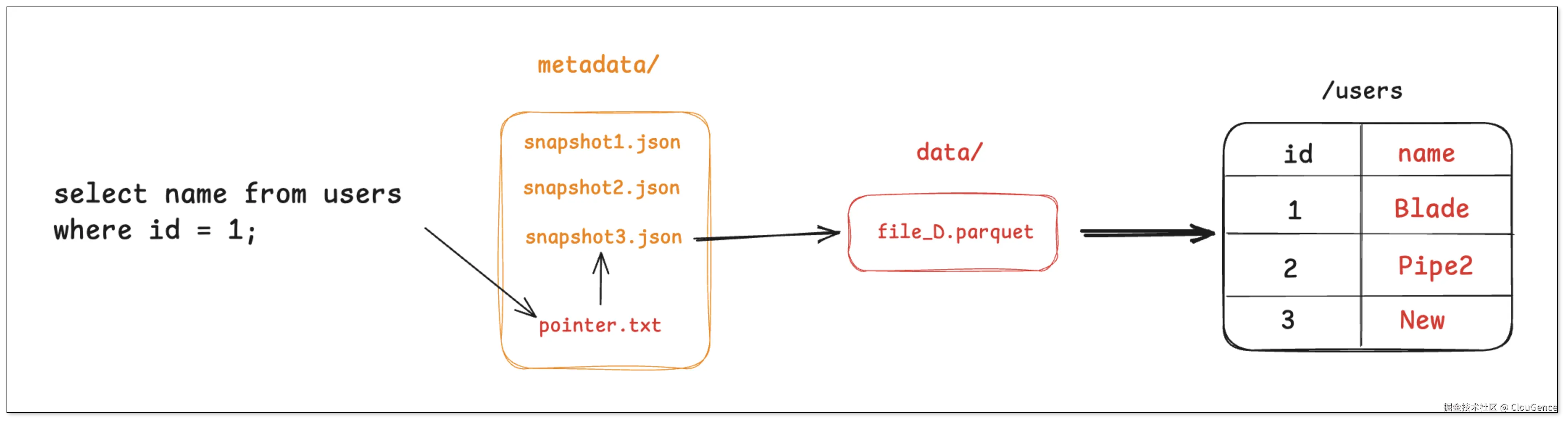
任何查询 users 表的查询请求,都会先找到 pointer.txt ,读取 snapshot_1 ,然后直接去访问 file_A。
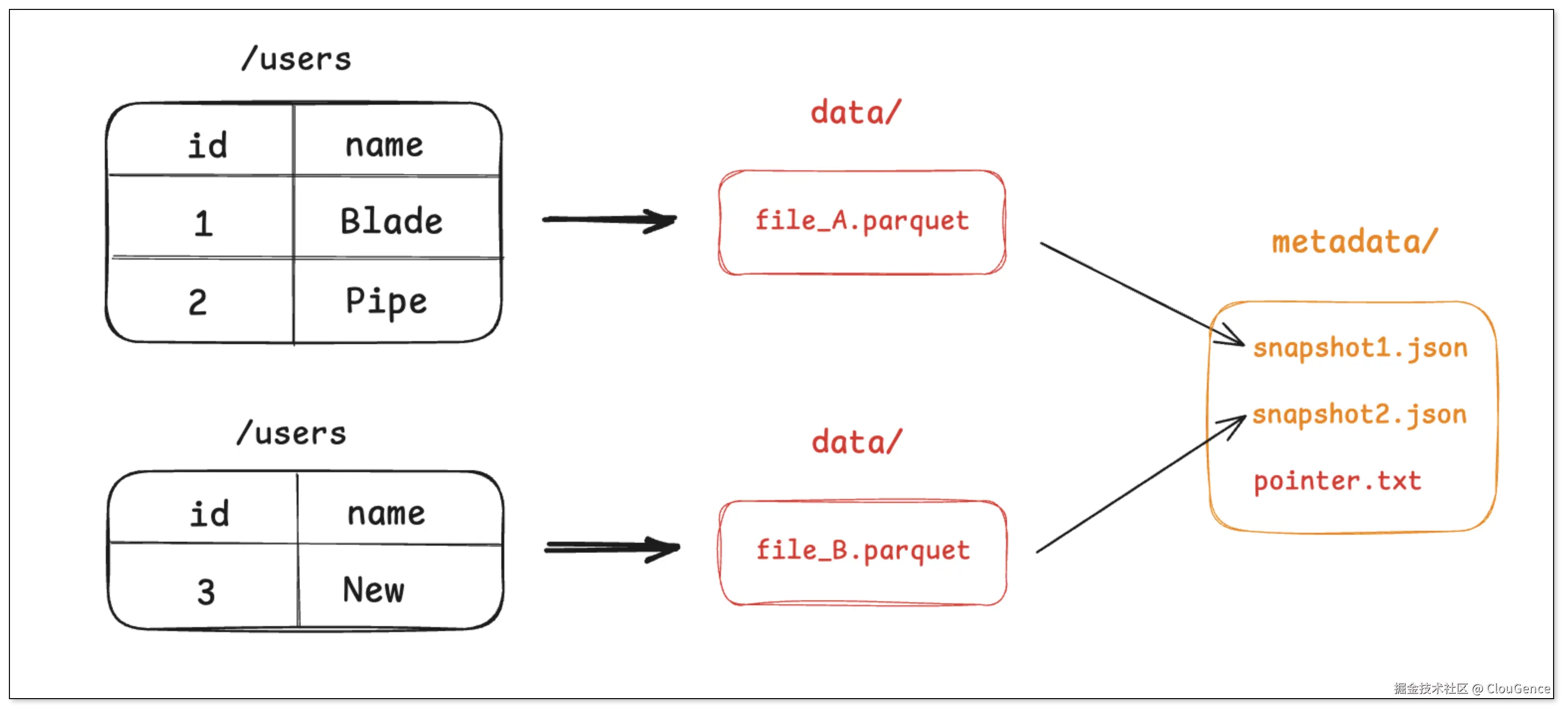
步骤二:插入 1 条新记录
-
引擎将这条新记录写入一个新的 Parquet 文件 file_B.parquet。
-
引擎创建一个新元数据文件 snapshot_2.json ,这个文件会记录当前最新状态(snapshot_2 )由 file_A 和 file_B 两个文件组成。
-
通过原子操作,将 pointer.txt 指向 snapshot_2。
老的快照 snapshot_1 依然存在,这为查询历史版本的数据提供了可能。
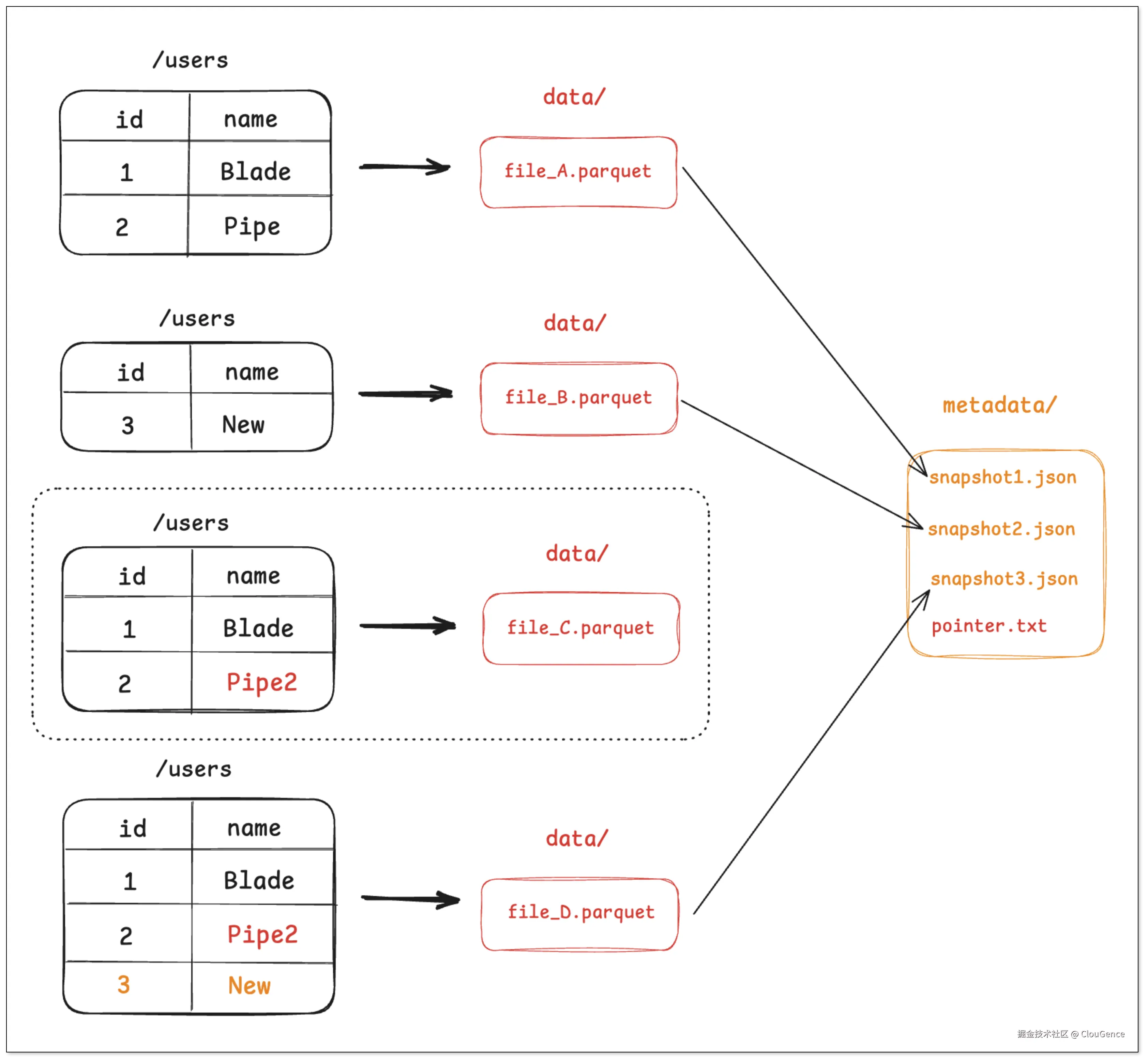
步骤三:更新数据与合并
-
由于 Parquet 文件不可变,引擎需要读取 file_A 的内容,在内存中进行修改,然后将修改后的结果(连同未修改的数据)写入到一个新的 Parquet 文件 file_C.parquet。
-
同时,为了优化小文件问题,系统可能会触发一个合并 (Compaction )任务,将 file_B 和 file_C 合并成一个更大的文件 file_D.parquet。
-
引擎创建 snapshot_3.json ,记录当前最新状态只由 file_D 组成。
-
最后,原子地更新 pointer.txt 指向 snapshot_3。
在这个过程中,不再被最新快照引用的文件(如 file_A ,file_B )会成为"孤立文件",并由后台垃圾回收机制清理。这种设计将复杂的数据操作,转化为了对元数据文件的原子操作,从而保障了事务的 ACID 特性。
数据查询
查询时,引擎会经历以下步骤:
-
先读取 pointer.txt,解析到当前最新快照或用户指定的历史快照。
-
从快照拿到要扫描的数据文件列表与其统计信息(分区、行数、列 min/max、行组统计、bloom 过滤器等)。
-
基于谓词做 分区裁剪 与 列统计裁剪 ,只保留可能命中的文件或行,并做 列裁剪与谓词下推 到 Parquet/ORC。
-
合并读取文件
-
CoW:直接读取被选中的最新文件。
-
MoR:读取 文件 + 增量/删除向量文件,在读取阶段完成 合并与应用删除。
-
综上,数据湖的本质是将复杂的数据操作转化为对元数据的原子操作,从而实现 ACID 事务与高效查询。接下来,我们将进一步对比 Iceberg、Delta Lake 与 Paimon 的实现差异。
Iceberg vs Delta vs Paimon
虽然核心思想相似,但 Iceberg 、Delta Lake 与 Paimon 在元数据结构、设计思路上存在显著差异,下面我们从几个核心维度进行更具体的对比。
Iceberg
元数据
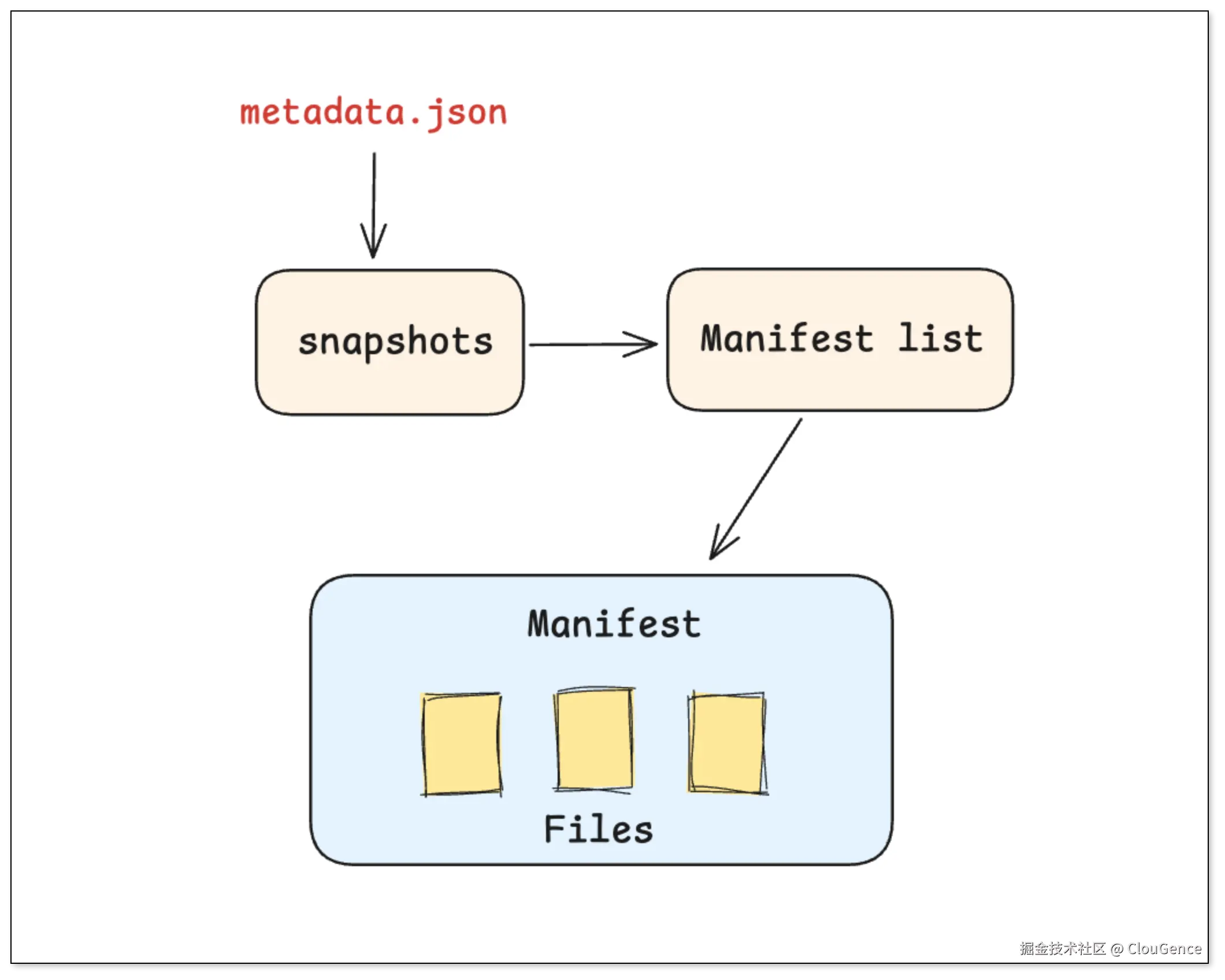
Iceberg 的元数据设计采用了层次分明的 树状结构。这种结构使得查询引擎可以从顶层元数据开始,逐层向下筛选,从而实现高效的元数据剪枝。
-
元数据文件 (Metadata) :一个总览全局的元数据文件,记录了表的 Schema、分区规则,以及所有 (Snapshots)历史快照的索引。
-
清单列表(Manifest List):每个快照版本都有一份清单文件,记录了构成这个版本需要哪些批次的 Manifest 文件,以及每个 Manifest 文件的分区。
-
清单文件(Manifest):每个 Manifest 文件里,才真正记录了具体的数据文件列表和它们的详细参数、列统计信息、最大值最小值等。
更新数据
-
创建一个新的 Delete 文件 ,如:del_file_A.parquet ,在里面记录 file_A 文件的第 N 行被删除或 user_id = 1 的行被删除。
-
创建 v2 快照 ,这个新快照会同时包含 file_A.parquet 和 del_file_A.parquet。查询引擎在读取时,会根据 Delete 文件自动过滤掉被删除的行。
查询数据
- 引擎先读取顶层元数据,找到对应版本的 清单列表 ,根据分区信息筛选出需要的 清单文件,最后只打开这些文件中记录的数据文件。
Delta Lake
元数据
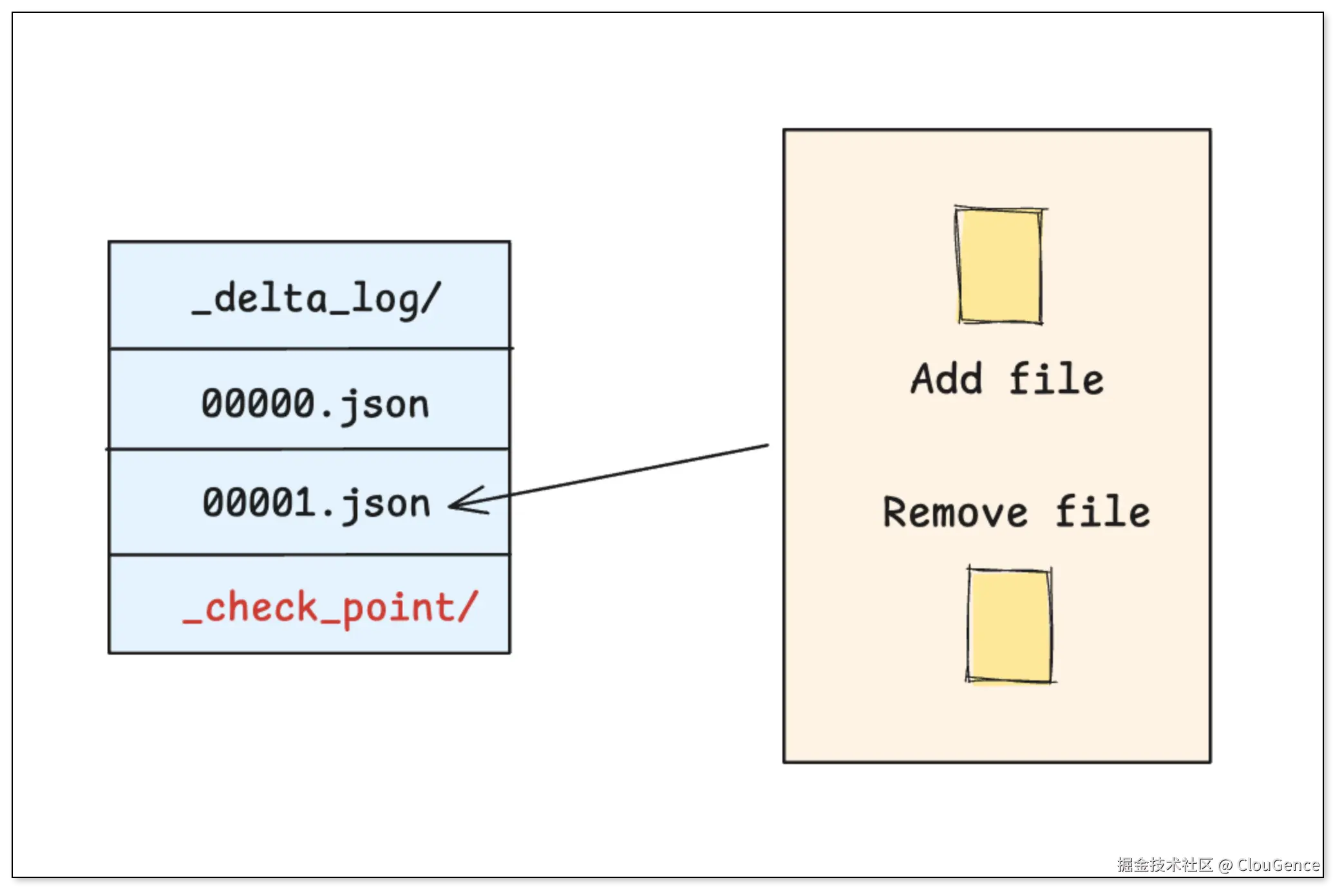
Delta Lake 的核心是一套严格按时间顺序排列的 事务日志(_delta_log/),用于记录表的每一次变更。
-
事务日志 (Transaction Log) :每一次对表的写入、更新或删除,都会生成一个新的 JSON 文件 ,清晰地记录了本次操作 增加 了哪些文件,删除 了哪些文件。
-
检查点文件 (Checkpoint) :当事务日志积累过多时,Delta Lake 会将之前的状态合并成一个 检查点文件 ,在查询时就不需要从头读取所有日志,只需从最近的 检查点 开始读取即可。
更新数据
-
复制写入 :读取旧文件,在内存中修改后,写入一个新文件 ,然后在 /_delta_log 中记录日志。
-
删除向量 :不重写文件,而是在 /_delta_log 日志记录里附加 删除向量 信息,用于标记文件内部的某些行已失效。
查询数据
- 引擎先找到最近的 检查点,然后依次应用后续的每一个事务日志,就能快速构建出表的最终准确状态。
Paimon
元数据
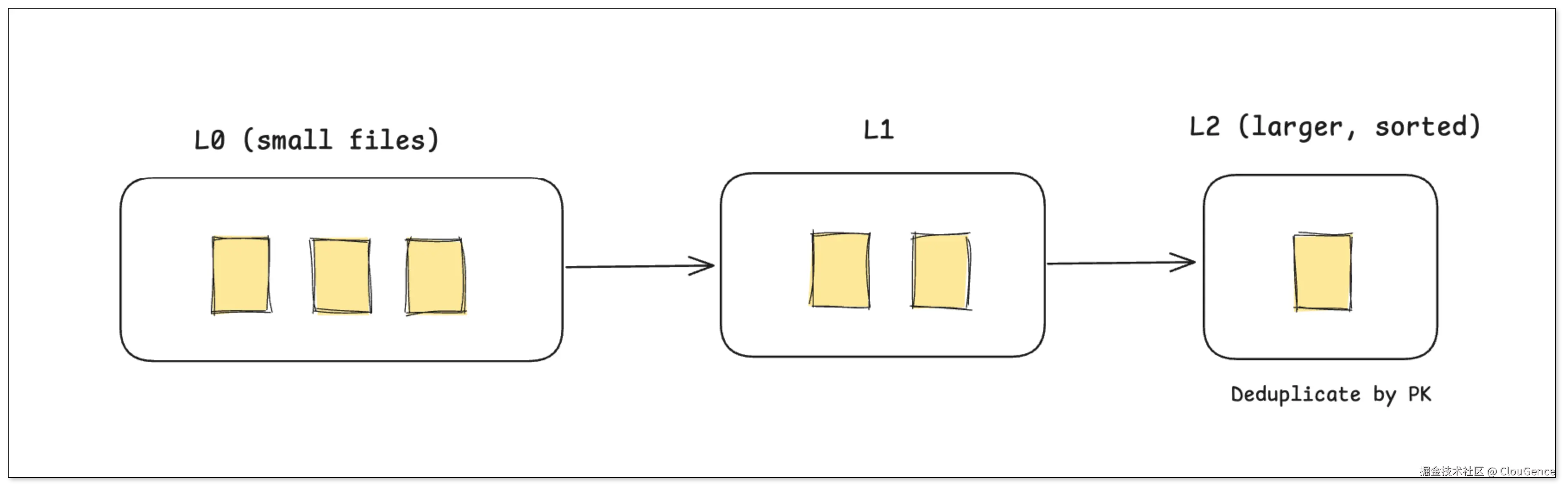
Paimon 借鉴了数据库的 LSM-Tree 思想,其分层式的架构特别擅长处理源源不断流入的实时数据。
-
临时写入区(L0):新来的数据会立刻被写入 L0 层的小文件中,保证写入延迟极低。此时,同一主键的数据可能会有多个版本共存。
-
后台自动合并(Compaction) :后台线程会自动将 L0 的小文件合并到 L1、L2 等更大的、更有序的文件层中。在合并过程中,相同主键的数据会自动去重,只保留最新版本。
-
状态快照 (Snapshot):同样用快照来记录在任一时刻,表由哪些层级(L0, L1, ...)的文件构成。
更新数据
-
将包含更新后数据的 新版本 ,写入另一个 L0 文件。
-
后台的 Compaction 任务 会在稍后自动将这两个 L0 文件合并,在合并过程中根据主键保留最新版本的数据,生成一个更大的 L1 文件。
查询数据
- 引擎需要同时读取所有层级的文件,并在内存中进行归并去重,以确保返回给用户的是最新数据。
计算瓶颈的演变
上述三种格式的 元数据 虽组织方式不同,但都以 文件形式 来管理,在自建开源环境中,这意味着合并计算通常落在 本地节点,成为潜在瓶颈。
-
CoW(写时合并) :频繁更新可能触发文件重写/小文件合并,CPU 与 IO 压力集中在 写入节点。
-
MoR(读时合并) :查询需合并主文件与删除信息,压力落在 查询节点。
-
Paimon(LSM 分层) :前台写入延迟低,但 后台合并 依旧吃算力与存储 IO。
为分担这些负载,云厂商开始把 合并 和 存储优化 的一部分工作托管到平台:
-
AWS Glue + Iceberg :在管理元数据之外,提供 自动小文件合并 和 表优化,把众多小 Parquet 文件合并为更大的对象,降低元数据与读放大开销。
-
Databricks Delta Lake :在托管环境中,Delta Lake 提供 自动合并 和 OPTIMIZE/ZORDER 功能,平台会自动在后台合并小文件、优化数据布局,从而减轻 Spark 作业节点的负担。
-
阿里云 DLF + Paimon :DLF 作为 托管的元数据平台 ,提供 存储优化策略 能力,可与作业配合调度后台优化与合并,减少小文件碎片与维护成本。
这种变化不仅提升了性能,也降低了运维复杂度,但具体效果取决于 云平台的能力与配置策略。
综合对比
| 特性 | Apache Iceberg | Delta Lake | Apache Paimon |
|---|---|---|---|
| 设计哲学 | 开放标准,引擎解耦 | 简单高效,与 Spark 深度集成 | 流批一体,实时更新优先 |
| 核心贡献者 | Netflix, Apple, Dremio | Databricks | Flink 社区 |
| 元数据结构 | 树状结构 (Metadata -> Manifest List -> Manifest) | 线性事务日志 (JSON + Parquet Checkpoint) | 类 LSM-Tree 结构 |
| 主要优势 | 强大的 Schema 演进、分区演进、高效元数据裁剪 | 简单易用,与 Spark/Databricks 生态无缝衔接 | 极佳的实时 Upsert/Delete 性能 |
| 并发控制 | 乐观并发控制 (OCC) | 乐观并发控制 (OCC) | 乐观并发控制 (OCC) |
| 最适用场景 | 大规模、多引擎分析的批处理场景 | 以 Spark 为核心的批处理和流处理 | Flink CDC、实时数据湖、流批一体 |
| 开放性 | 极高,被 Flink, Spark, Trino, StarRocks 等广泛支持 | 较高,但与 Databricks 生态绑定更深 | 高,与 Flink/Spark 生态紧密结合 |
从对比中可以看到,三者的差异核心在于 元数据组织方式 与 更新模型:
-
Iceberg :适合 批量处理 + 多引擎分析,强调灵活 Schema/分区演进与查询性能。
-
Delta Lake :适合 强依赖 Spark 生态 的场景,特别是需要 可审计的事务日志。
-
Paimon :在 高频实时 CDC 与 流批一体 场景下表现突出。
构建实时数据湖
前面我们分析了三种数据湖格式的差异,那么如何将各数据库的数据变更实时导入到数据湖中呢?CloudCanal 作为专业的数据实时同步工具,支持将多源数据实时同步到 Paimon 、Iceberg 与 Delta Lake。
下面我们以 MySQL -> 阿里云 DLF + Paimon 为示例,展示如何快速构建一个 实时数据湖。
前置准备
-
安装 CloudCanal SaaS :www.clougence.com/
-
准备 阿里云 DLF :help.aliyun.com/dlf/
数据同步
添加数据源
- 登录 CloudCanal 平台 ,点击 数据源管理 > 添加数据源 ,分别添加 MySQL 和 阿里云 DLF 数据源。
由于 阿里云 DLF 不支持公网访问,需要进行以下操作。
- 购买 阿里云 ECS 打通隧道。
shell
ssh -N -L 9999:cn-hangzhou-vpc.dlf.aliyuncs.com:80 root@ecs_ip- catalogProps 配置中自定义 OSS 存储。
json
{
"dlf.region": "cn-hangzhou",
"fs.oss.endpoint": "oss-cn-hangzhou.aliyuncs.com",
"token.provider": "dlf"
}创建同步任务
-
点击 同步任务 > 创建任务。
-
选择源和目标实例,并分别点击 测试连接。
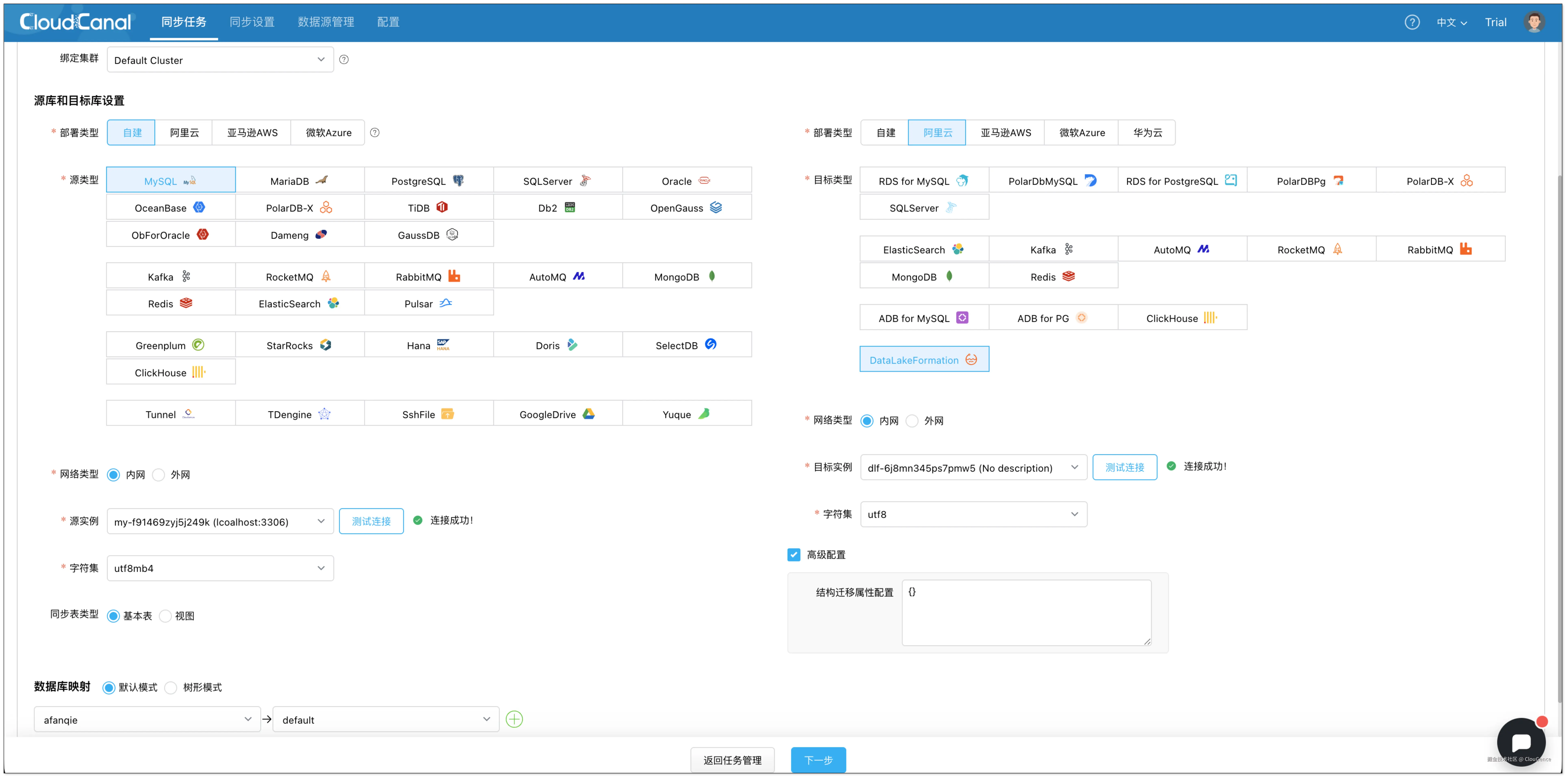
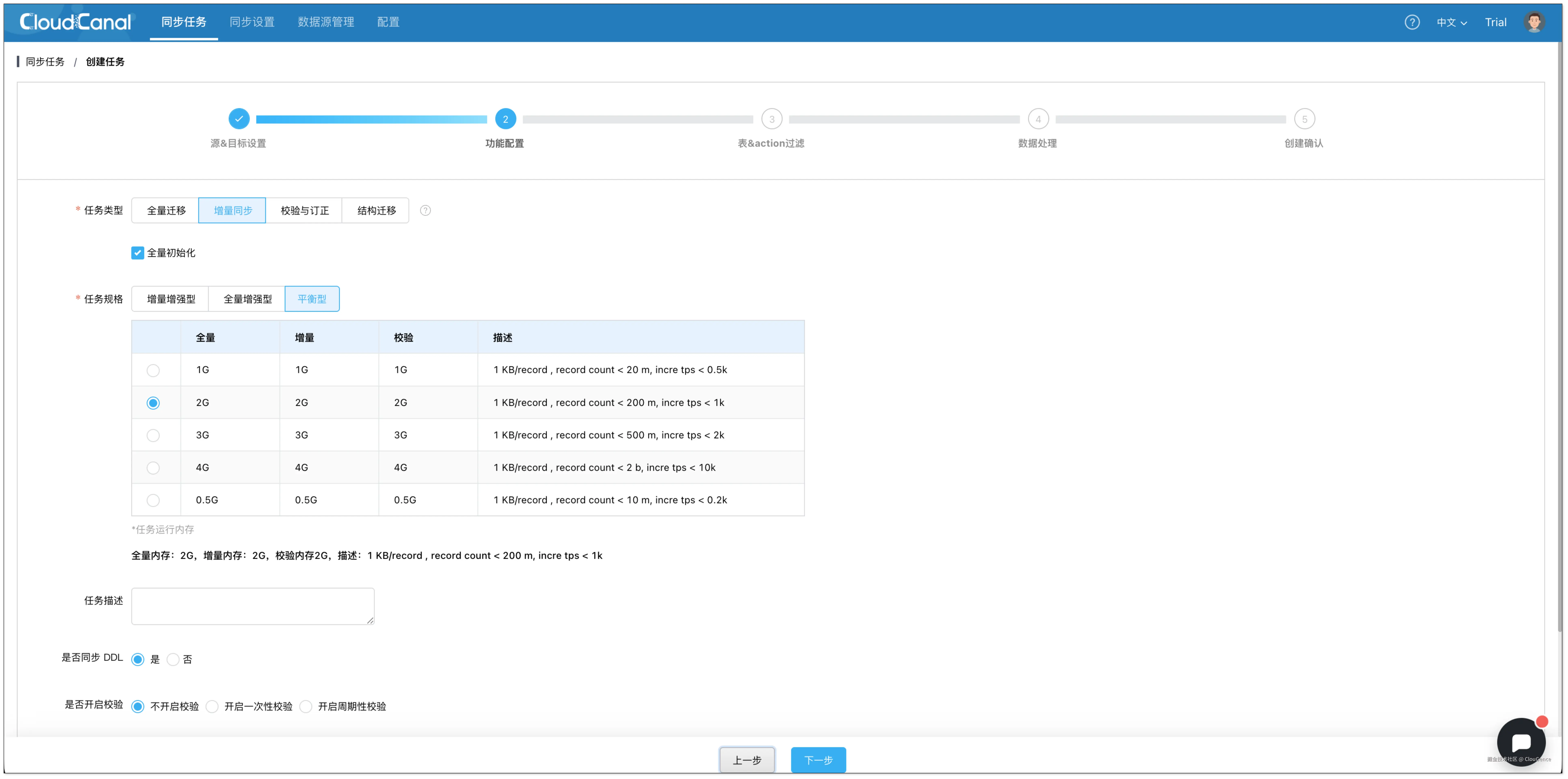
- 在 功能配置 页面,选择 增量同步 ,并勾选 全量初始化。
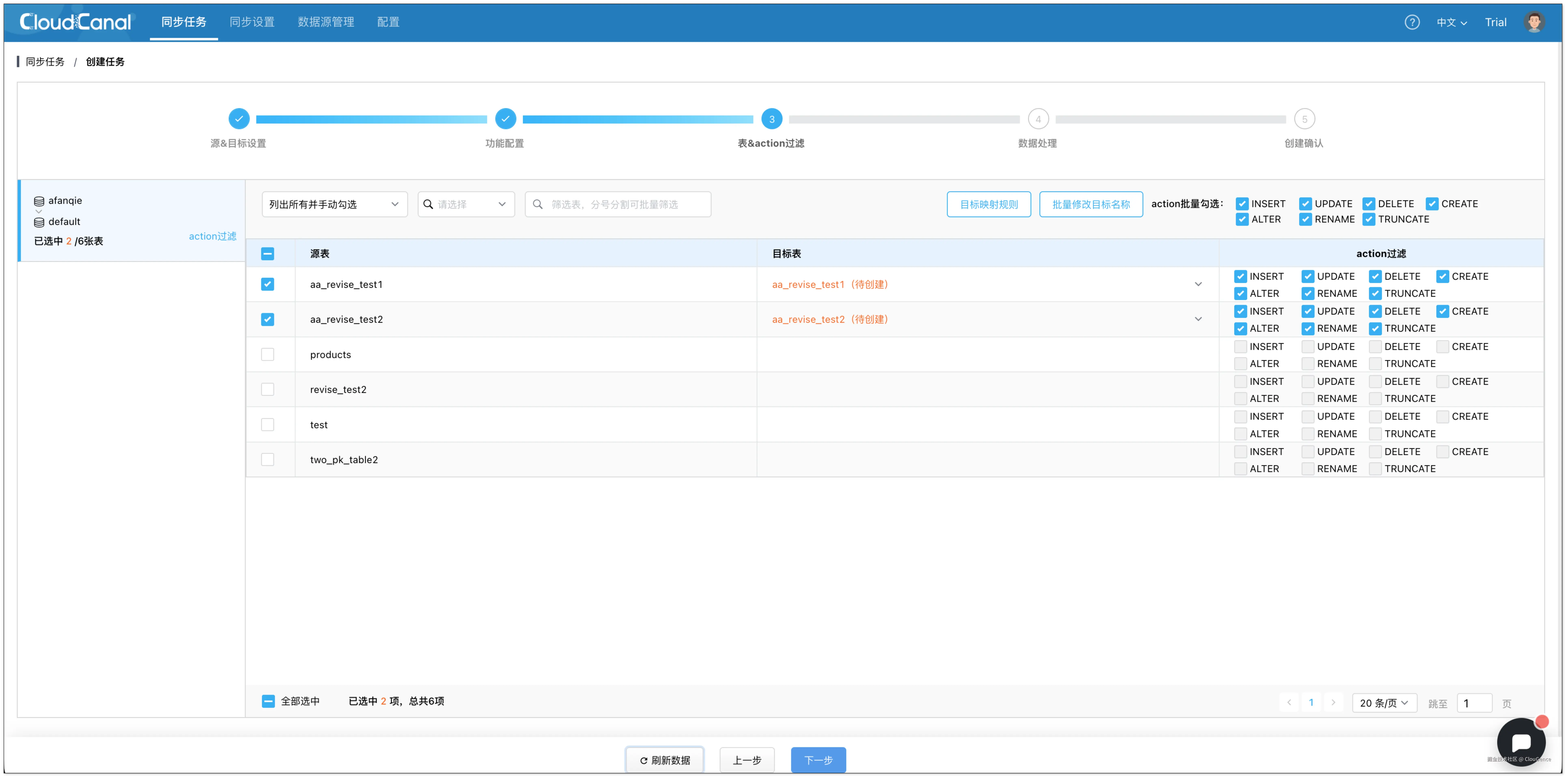
- 在 表和操作过滤 页面,选择需要迁移同步的表,可同时选择多张。
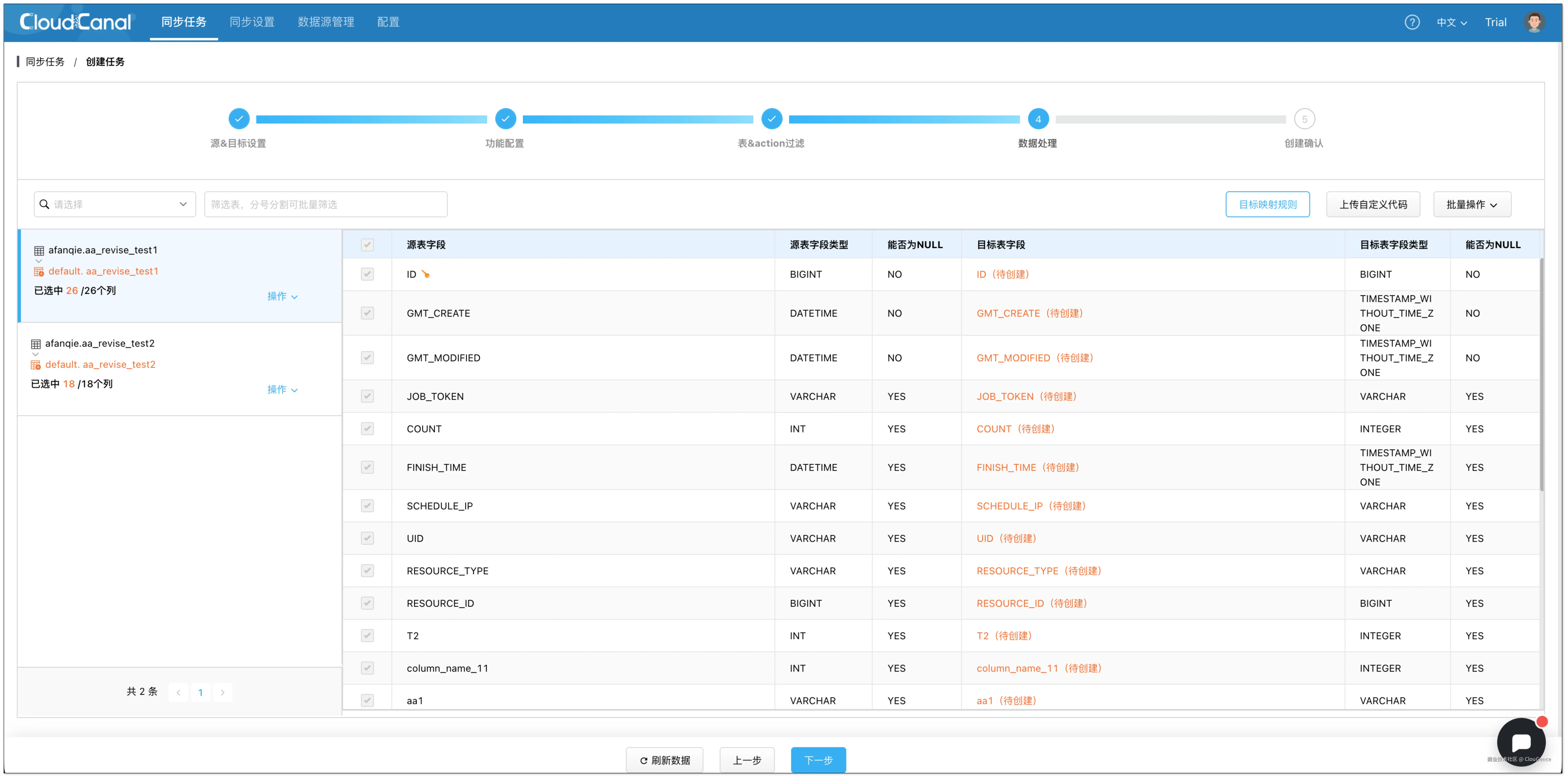
- 在 数据处理 页面,保持默认配置。
- 在 创建确认 页面,点击 创建任务,开始运行。
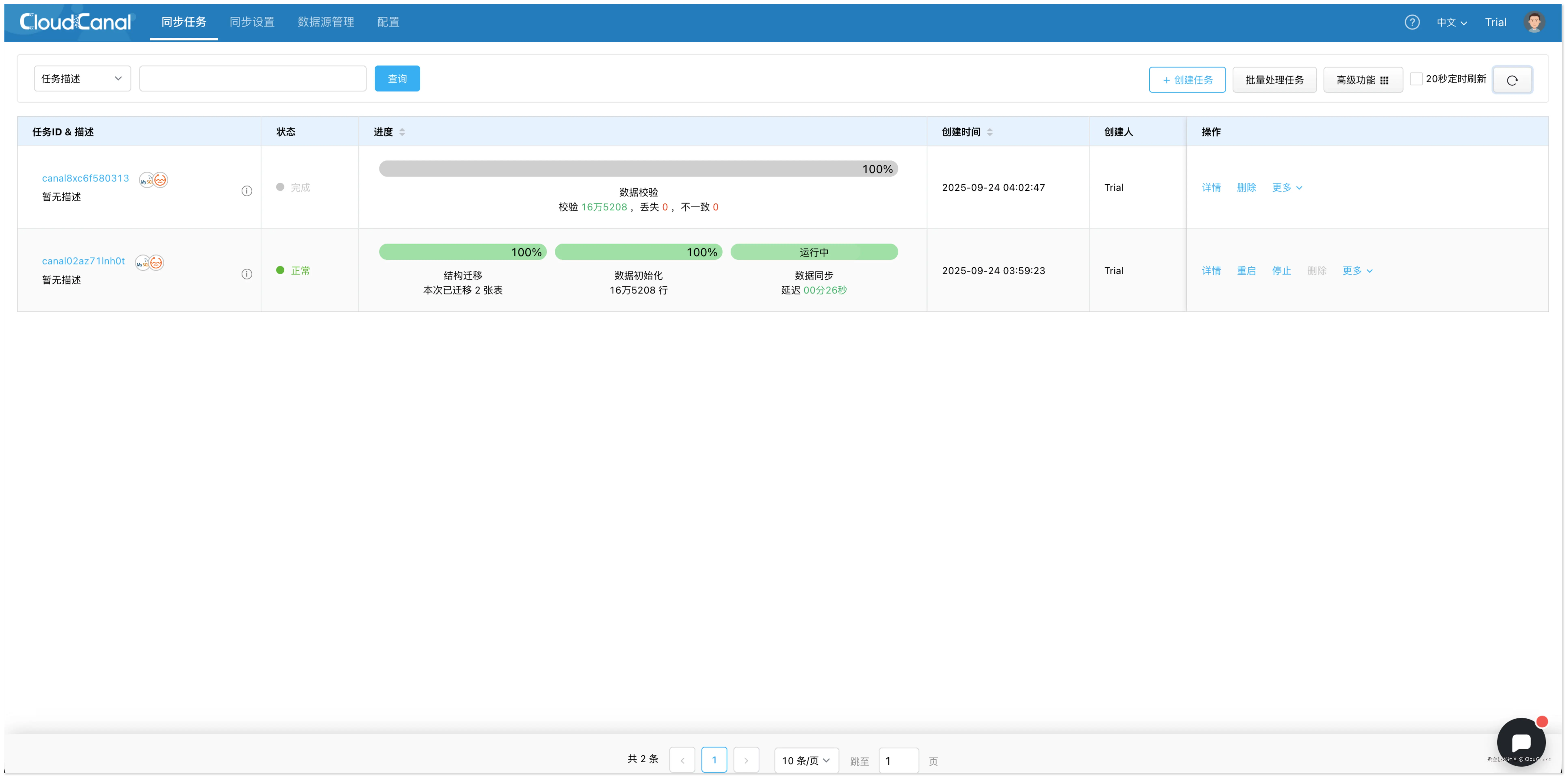
任务启动后,CloudCanal 将自动完成全量数据的初始化,并实时捕获增量变更写入 阿里云 DLF。
总结
Iceberg 、Delta Lake 与 Paimon 展示了数据湖在不同场景下的技术路径,企业可根据业务特点灵活选型。而借助 CloudCanal ,用户能够轻松将数据库变更实时写入这些湖格式,加速构建低延迟、可扩展的 实时数据湖。