前言
在前面的课程中,你已经通过自动化评测发现答疑机器人的一些问题。优化提示词并不能解决检索召回不准确引起的回答错误问题,就像你在开卷考试时拿着错误的参考书很难给出正确的答案一样。
前文回顾
在上一章节,你发现答疑机器人不能很好的回答【张伟是哪个部门的?】。你可以通过这段代码复现问题。
python
# 导入所需的依赖包
import os
os.environ["TRANSFORMERS_VERBOSITY"] = "error"
# 本章不使用transformer库,我们可以只关注transformer库中error级别的报警信息
from config.load_key import load_key
import logging
from llama_index.core import Settings, SimpleDirectoryReader, VectorStoreIndex, PromptTemplate
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
from llama_index.llms.openai_like import OpenAILike
from llama_index.core.node_parser import (
SentenceSplitter,
SemanticSplitterNodeParser,
SentenceWindowNodeParser,
MarkdownNodeParser,
TokenTextSplitter
)
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
from langchain_community.llms.tongyi import Tongyi
from langchain_community.embeddings import DashScopeEmbeddings
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import context_recall, context_precision, answer_correctness
from chatbot import rag
from IPython.display import display
python
# 设置日志级别
logging.basicConfig(level=logging.ERROR)
python
# 加载API密钥
load_key()
# 生产环境中请勿将 API Key 输出到日志中,避免泄露
print(f'''你配置的 API Key 是:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}''')
python
# 配置通义千问大模型和文本向量模型
Settings.llm = OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
)
python
# 配置文本向量模型,设置批处理大小和最大输入长度
Settings.embed_model = DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3,
embed_batch_size=6,
embed_input_length=8192
)
python
# 定义问答函数
def ask(question, query_engine):
# 更新提示模板
rag.update_prompt_template(query_engine=query_engine)
# 输出问题
print('=' * 50) # 使用乘法生成分割线
print(f'🤔 问题:{question}')
print('=' * 50 + '\n') # 使用乘法生成分割线
# 获取回答
response = query_engine.query(question)
# 输出回答
print('🤖 回答:')
if hasattr(response, 'print_response_stream') and callable(response.print_response_stream):
response.print_response_stream()
else:
print(str(response))
# 输出参考文档
print('\n' + '-' * 50) # 使用乘法生成分割线
print('📚 参考文档:\n')
for i, source_node in enumerate(response.source_nodes, start=1):
print(f'文档 {i}:')
print(source_node)
print()
print('-' * 50) # 使用乘法生成分割线
return response
python
query_engine = rag.create_query_engine(rag.load_index())
response = ask('张伟是哪个部门的', query_engine)
python
==================================================
🤔 问题:张伟是哪个部门的
==================================================
🤖 回答:
根据提供的参考信息,没有找到名为张伟的员工信息。如果您能提供更多详细信息,比如部门名称或其他联系方式,我可以帮助您进一步查找。如果确实存在同名员工的情况,也请告知具体的工作内容或部门,以便准确回答您的问题。
--------------------------------------------------
📚 参考文档:
文档 1:
Node ID: e4bf6cef-a1c6-4060-9934-408a6a709d45
Text: 核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034
qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布,
Score: 0.193
文档 2:
Node ID: 311fbc80-e445-4399-871a-f7a3cd7a2aa5
Text: ⽀持。 绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源 绩效专员 13800000041
hanshan@educompany.com 建⽴并维护员⼯绩效档案,定期组织绩效评价会议,协调各部⻔反馈,制定考核流程与标准,确保绩效
Score: 0.189
--------------------------------------------------你会发现,产生问题的原因是检索阶段没有召回到正确的参考信息(文档切片)。如何改进这个问题呢?你可以参考几个简单的改进策略,初步优化检索效果。
初步优化检索效果
正如前言提到的,你需要让大模型拿到正确的"参考书",才能给出正确的"答案"。因此,你可以尝试增加每次拿到"参考书"的数量(增加召回的文档切片数量),或者将"参考书中的知识点"整理成结构化的表格(文档内容结构化)。你可以先从前者入手:
让大模型获取到更多参考信息
既然知识库中存在张伟的任职信息,那么你可以通过增加一次性召回的文档切片数量的方式,从而扩大检索范围,提升找到相关信息的概率。在之前的代码里,你只召回了2个文档切片,现在,你可以将召回数量增加至5个,再次观察召回效果是否得到了提升。
调整代码
你可以通过以下设置,让检索引擎召回前5个最相关的文档切片
python
index = rag.load_index()
query_engine = index.as_query_engine(
streaming=True,
# 一次检索出 5 个文档切片,默认为 2
similarity_top_k=5
)
python
response = ask('张伟是哪个部门的', query_engine)
python
==================================================
🤔 问题:张伟是哪个部门的
==================================================
🤖 回答:
张伟是IT部的。
--------------------------------------------------
📚 参考文档:
文档 1:
Node ID: e4bf6cef-a1c6-4060-9934-408a6a709d45
Text: 核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034
qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布,
Score: 0.193
文档 2:
Node ID: 311fbc80-e445-4399-871a-f7a3cd7a2aa5
Text: ⽀持。 绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源 绩效专员 13800000041
hanshan@educompany.com 建⽴并维护员⼯绩效档案,定期组织绩效评价会议,协调各部⻔反馈,制定考核流程与标准,确保绩效
Score: 0.189
文档 3:
Node ID: b9e8dd24-6fb2-4ad9-9d7c-b3ba4170487c
Text: 效管理部 南 ⻜ 0 ⼒资源 效专员 0
责制定绩效考核体系,组织绩效评估的实施与反馈,撰写评估报告,分析绩效数据以提出优化建议,提供决策
Score: 0.176
文档 4:
Node ID: 392a1724-fb54-4380-8f33-b857af24b9a1
Text: ⽀持,确保⼈⼒资源部⻔顺畅运作。 ⾏政部 黎晗 蔡静 G704 033 ⾏政 ⾏政专员 13800000033
lih@educompany.com 负责采购办公设备与耗材,登记与管理公司固定资产,协助实施绩效考
Score: 0.164
文档 5:
Node ID: 3f0c4caa-d750-4c67-9f01-9c40d439e3f1
Text: 组织公司活动的前期准备与后期评估,确保公司各项⼯作的顺利进⾏。 IT部 张伟 ⻢云 H802 036 IT⽀撑 IT专员
13800000036 zhangwei036@educompany.com 进⾏公司⽹络及硬件设备的配置
Score: 0.161
--------------------------------------------------可以看到:在调整了召回数量后,你的答疑机器人能够回答【张伟是哪个部门?】了,这是因为召回的文档切片已经包含了张伟和他的部门信息。
不过单纯增加召回的切片数量并不是一个好方法。想想看,如果这种方法能解决问题,那么不如召回整个知识库,这样不会遗漏任何的信息...可是这不仅会超出大模型的输入长度限制,过多的无关信息还会降低大模型回答的效率和准确性。
而且,事实上你们公司可能有很多叫张伟的同事,这会导致一个问题:当用户问"张伟是哪个部门的"时候,系统无法确定用户想问的是哪一个张伟。如果只是简单地增加召回数量,可能会召回多个张伟的信息,但系统仍然无法准确判断应该返回哪个张伟 的信息。因此,我们还需要用其他方法来进一步改进RAG效果。
评估改进效果
为了在接下来的改进中,能够量化改效果,你可以继续使用上一个章节中的Ragas来进行评测。假设你们公司有三名叫张伟的同事,他们分别在教研部、课程开发部、IT部。
python
# 定义评估函数
def evaluate_result(question, response, ground_truth):
# 获取回答内容
if hasattr(response, 'response_txt'):
answer = response.response_txt
else:
answer = str(response)
# 获取检索到的上下文
context = [source_node.get_content() for source_node in response.source_nodes]
# 构造评估数据集
data_samples = {
'question': [question],
'answer': [answer],
'ground_truth':[ground_truth],
'contexts' : [context],
}
dataset = Dataset.from_dict(data_samples)
# 使用Ragas进行评估
score = evaluate(
dataset = dataset,
metrics=[answer_correctness, context_recall, context_precision],
llm=Tongyi(model_name="qwen-plus"),
embeddings=DashScopeEmbeddings(model="text-embedding-v3")
)
return score.to_pandas()
python
# 定义评估函数
def evaluate_result(question, response, ground_truth):
# 获取回答内容
if hasattr(response, 'response_txt'):
answer = response.response_txt
else:
answer = str(response)
# 获取检索到的上下文
context = [source_node.get_content() for source_node in response.source_nodes]
# 构造评估数据集
data_samples = {
'question': [question],
'answer': [answer],
'ground_truth':[ground_truth],
'contexts' : [context],
}
dataset = Dataset.from_dict(data_samples)
# 使用Ragas进行评估
score = evaluate(
dataset = dataset,
metrics=[answer_correctness, context_recall, context_precision],
llm=Tongyi(model_name="qwen-plus"),
embeddings=DashScopeEmbeddings(model="text-embedding-v3")
)
return score.to_pandas()
python
evaluate_result(question=question, response=response, ground_truth=ground_truth)
可以看到,当前的RAG系统还无法高效地运行,召回的文档 切片在存在了无关信息,且有效信息也没有被完全召回,最终形成的答案并不正确。你需要考虑其他改进策略。
给大模型结构更清晰的参考信息
在实际应用中,文档 的组织结构对检索效果有着重要影响。想象一下,同样的信息,放在一个结构清晰的表格中和散落在一段普通文字里,哪个更容易查找和理解?显然是前者。
大语言模型也是如此。当把原本在表格中的信息转换成普通文本时,虽然信息本身没有丢失,但结构性却降低了。这就像是把一个整齐的抽屉变成了一堆散落的物品,虽然东西都在,但查找起来就没那么方便了。
重建索引
Markdown格式是一个很好的选择,因为它:
- 结构清晰,层次分明
- 语法简单,易于阅读和维护
- 特别适合RAG(检索增强生成)场景下的文档组织
为了验证结构化文档的效果,课程准备了一份经过优化的Markdown格式文件。接下来,你将:
- 把这份Markdown文件添加到docs目录
- 重新建立索引
- 测试检索效果的提升
python
# 将 markdown 格式的员工信息文档复制到 ./docs 目录下
! mkdir -p ./docs/2_5
! cp ./resources/2_4/内容公司各部门职责与关键角色联系信息汇总.md ./docs/2_5
python
print('=' * 50)
print('📂 正在加载文档...')
print('=' * 50 + '\n')
# 加载文档
documents = SimpleDirectoryReader('./docs/2_5').load_data()
print(f'✅ 文档加载完成。\n')
print('=' * 50)
print('🛠️ 正在重建索引...')
print('=' * 50 + '\n')
# 重建索引
index = VectorStoreIndex.from_documents(
documents
)
print('✅ 索引重建完成!')
print('=' * 50)
python
query_engine = index.as_query_engine(
streaming=True,
similarity_top_k=5
)
python
response = ask('张伟是哪个部门的', query_engine)
python
==================================================
🤔 问题:张伟是哪个部门的
==================================================
🤖 回答:
张伟是IT部的。
--------------------------------------------------
📚 参考文档:
文档 1:
Node ID: e4bf6cef-a1c6-4060-9934-408a6a709d45
Text: 核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034
qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布,
Score: 0.193
文档 2:
Node ID: 311fbc80-e445-4399-871a-f7a3cd7a2aa5
Text: ⽀持。 绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源 绩效专员 13800000041
hanshan@educompany.com 建⽴并维护员⼯绩效档案,定期组织绩效评价会议,协调各部⻔反馈,制定考核流程与标准,确保绩效
Score: 0.189
文档 3:
Node ID: b9e8dd24-6fb2-4ad9-9d7c-b3ba4170487c
Text: 效管理部 南 ⻜ 0 ⼒资源 效专员 0
责制定绩效考核体系,组织绩效评估的实施与反馈,撰写评估报告,分析绩效数据以提出优化建议,提供决策
Score: 0.176
文档 4:
Node ID: 392a1724-fb54-4380-8f33-b857af24b9a1
Text: ⽀持,确保⼈⼒资源部⻔顺畅运作。 ⾏政部 黎晗 蔡静 G704 033 ⾏政 ⾏政专员 13800000033
lih@educompany.com 负责采购办公设备与耗材,登记与管理公司固定资产,协助实施绩效考
Score: 0.164
文档 5:
Node ID: 3f0c4caa-d750-4c67-9f01-9c40d439e3f1
Text: 组织公司活动的前期准备与后期评估,确保公司各项⼯作的顺利进⾏。 IT部 张伟 ⻢云 H802 036 IT⽀撑 IT专员
13800000036 zhangwei036@educompany.com 进⾏公司⽹络及硬件设备的配置
Score: 0.161
--------------------------------------------------评估改进效果
可以看到,你的答疑机器人能够准确回答这个问题。你可以再运行一次 Ragas 评测,评测数据同样显示:回答准确度更高了
python
evaluate_result(question=question, response=response, ground_truth=ground_truth)
熟悉RAG的工作流程
截至目前,你已经完成了一些改进,让答疑机器 人的问答准确更高了。但在实际生产环境中,你可能会遇到的问题远不止于此。之前你已经了解了一些RAG的工作流程,在这里你可以回顾一下重要的步骤,方便你发现新的改进点:
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的技术,能够在生成答案时利用外部知识库的相关信息。它的工作流程可以分为几个关键步骤:解析与切片、向量存储、检索召回、生成答案等。具体的概念你可以回顾"扩展答疑机器人的知识范围"这一节。
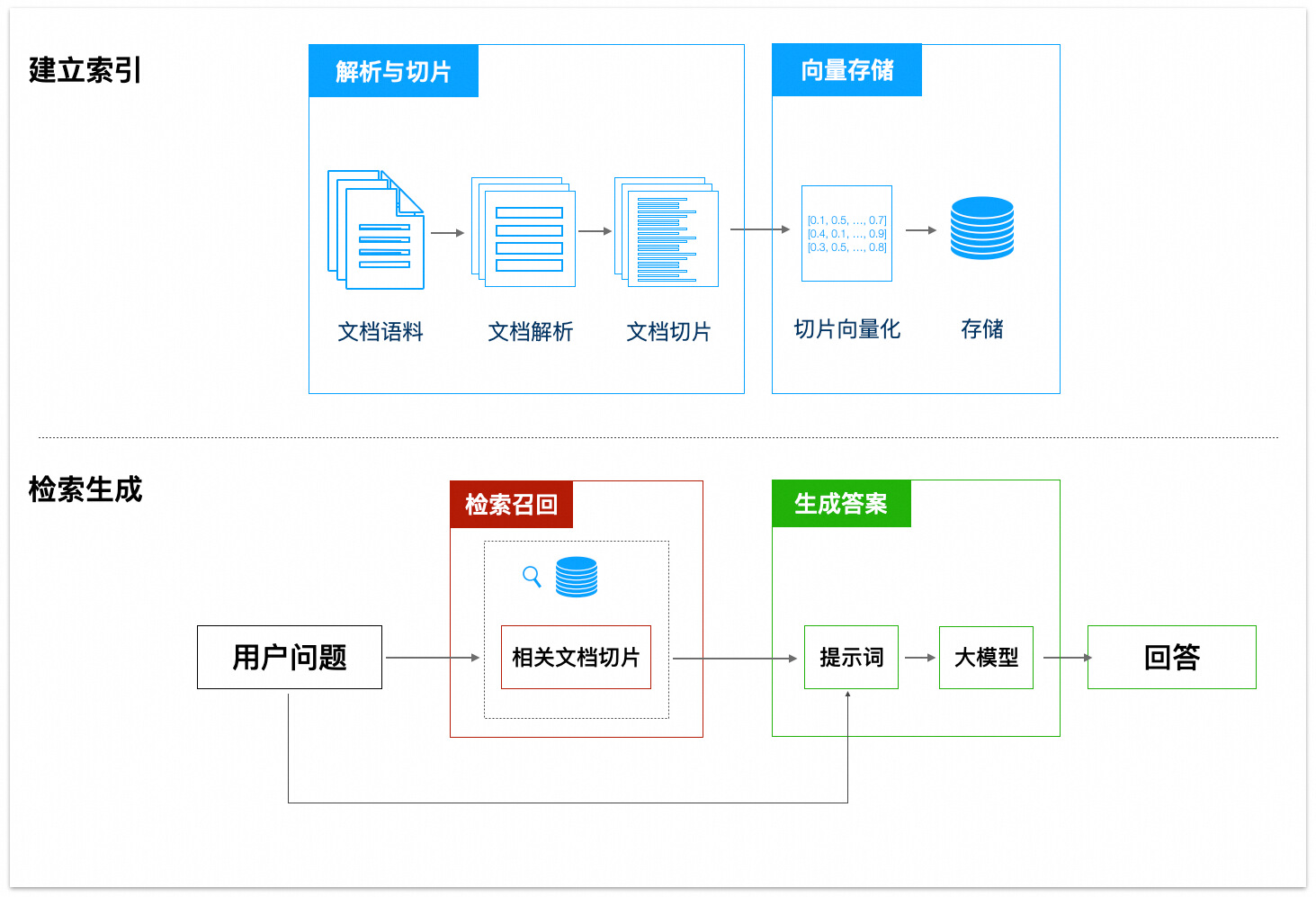
接下来,将从 RAG 中的每一个环节入手,尝试优化 RAG 的效果。
RAG应用各个环节与改进策略
文档准备阶段
在传统的客服阶段中,客服人员会根据用户所提问题,积累知识库,并共享给其他客服人员参考。在构建RAG应用时,这一过程同样不可缺少。
- 意图空间:我们可以把用户提问背后中的需求绘制成点,这些点组成了一个用户意图空间。
- 知识空间:而你沉淀在知识库文档 中的知识点,则构成了组成一个知识空间。这里的知识点,可以是一个段落、或者一个章节。
当我们将意图空间和知识空间投影到一起,会发现两个空间存在交集与差异。这些区域分别对应了我们后续的三个优化策略:
- 重叠区域:
- 即可以依靠知识库的内容来回答用户问题的部分,这是RAG应用效果保障的基础。
- 对于这部分用户意图,你可以通过优化内容质量、优化工程和算法,不断地提升回答质量。
- 未被覆盖的意图空间
- 因为缺乏知识库内容的支撑,大模型型容易输出"幻觉"回答,例如,公司新增了一个"数据分析部",但知识库中没有相关文档,不论如何改进工程算法,RAG应用都无法准确回答这一问题。
- 你需要做的是主动补充缺漏的知识,不断跟进用户意图空间的变化
- 未被利用的知识空间:
- 召回不相关知识点可能会干扰大模型的回答。
- 因此,需要你召回算法避免召回无关内容 。此外,你还需要定期查验知识库,剔除无关内容
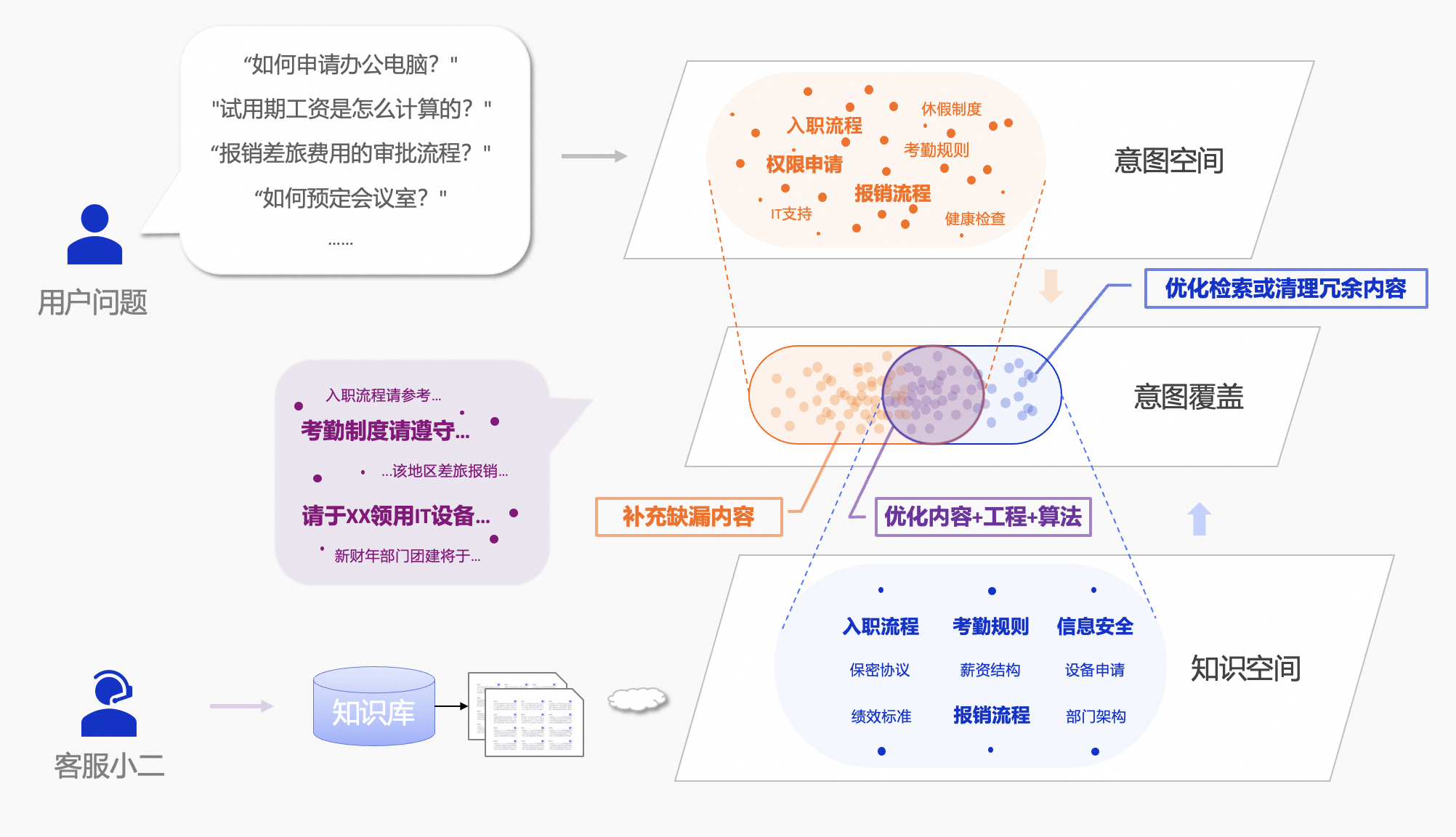
在尝试优化工程或算法之前,你应该优先构建一套可以持续收集用户意图的机制。通过系统化采集真实用户需求来完善知识库内容,并邀请对用户意图有深刻理解的领域专家参与效果评估,形成"数据采集-知识更新-专家验证"的闭环优化流程,保障 RAG 应用的效果。
当你准备好这些,就可以进一步优化 RAG 应用的各个环节了
问题分类及改进策略
在文档解析与切片阶段,你可能会遇到以下问题:
| 类别 | 细分类型 | 改进策略 | 场景化示例 |
|---|---|---|---|
| 文档解析 | 文档类型不统一,部分格式的文档不支持解析 比如前面用到的 SimpleDirectoryLoader 并不支持 Keynote 格式的文件 | 开发对应格式的解析器,或转换文档格式 | 例如,某公司使用了大量的 Keynote 文件存储员工信息,但现有的解析器不支持 Keynote 格式。可以开发 Keynote 解析器或将文件转换为支持的格式(如 PDF)。 |
| 文档解析 | 已支持解析的文档格式里,存在一些特殊内容 比如文档里嵌入了表格、图片、视频等 | 改进文档解析器 | 例如,某文档中包含了大量的表格和图片,现有解析器无法正确提取表格中的信息。可以改进解析器,使其能够处理表格和图片。 |
| 文档解析 | ... | ... | ... |
| 文档切片 | 文档中有很多主题接近的内容 比如工作手册文档中,需求分析、开发、发布等每个阶段都有注意事项、操作指导 | 扩写文档标题及子标题 「注意事项」=>「需求分析>注意事项」 建立文档元数据(打标) | 例如,某文档中包含多个阶段的注意事项,用户提问"需求分析的注意事项是什么?"时,系统返回了所有阶段的注意事项。可以通过扩展标题和打标来区分不同阶段的内容。 |
| 文档切片 | 文档切片长度过大,引入过多干扰项 | 减少切片长度,或结合具体业务开发为更合适的切片策略 | 例如,某文档的切片长度过大,包含了多个不相关的主题,导致检索时返回了无关信息。可以减少切片长度,确保每个切片只包含一个主题。 |
| 文档切片 | 文档切片长度过短,有效信息被截断 | 扩大切片长度,或结合具体业务开发为更合适的切片策略 | 例如,某文档中每个切片只有一句话,导致检索时无法获取完整的上下文信息。可以增加切片长度,确保每个切片包含完整的上下文。 |
| 文档切片 | ... | ... | ... |
借助百炼解析 PDF 文件
在前面的学习过程中,为了让你更快地看到格式转换带来的效果,本课程直接提供了一份从 PDF 转换的 Markdown 格式文档。但在实际工作中,编写代码将 PDF 妥善地转为 Markdown 并非易事。
实际工作中,你也可以借助百炼提供的 DashScopeParse 来完成 PDF、Word 等格式的文件解析。DashScopeParse 背后使用了阿里云的文档智能服务,能够帮助你从 PDF、Word 等格式的文件中识别文档中的图片、提取出结构化的文本信息。
python
from llama_index.readers.dashscope.utils import ResultType
from llama_index.readers.dashscope.base import DashScopeParse
import os
import json
import nest_asyncio
python
nest_asyncio.apply()
# 使用环境变量
os.environ['DASHSCOPE_API_KEY'] = os.getenv('DASHSCOPE_API_KEY')
python
# 创建一个静默的日志记录器来替换原始的 logger
silent_logger = logging.getLogger(__name__)
# 设置日志级别为 ERROR,以避免输出无关信息。如果您需要查看更详细的日志信息,请设置为 INFO
silent_logger.setLevel(logging.ERROR)
class SilentDashScopeParse(DashScopeParse):
def __init__(self, *args, **kwargs):
# 替换所有相关模块的 logger
import llama_index.readers.dashscope.base as base_module
import llama_index.readers.dashscope.domain.lease_domains as lease_domains_module
import llama_index.readers.dashscope.utils as utils_module
base_module.logger = silent_logger
lease_domains_module.logger = silent_logger
utils_module.logger = silent_logger
# 调用父类初始化
super().__init__(*args, **kwargs)
python
# 文件通过DashScopeParse接口解析为程序与大模型易于处理的markdown文本
def file_to_md(file, category_id):
parse = SilentDashScopeParse(
result_type=ResultType.DASHSCOPE_DOCMIND,
category_id=category_id
)
documents = parse.load_data(file_path=file)
# 初始化一个空字符串来存储Markdown内容
markdown_content = ""
for doc in documents:
doc_json = json.loads(json.loads(doc.text))
for item in doc_json["layouts"]:
if item["text"] in item["markdownContent"]:
markdown_content += item["markdownContent"]
else:
# DashScopeParse处理时,会将文档图片内的文本信息也解析到初始markdown文本中(类似OCR),这对于本文示例文件中的命令行截图、文本截图是足够的,示例无需深层次解析图片。
# 实际场景中的知识库文档,如果涉及不规则、复杂信息的图片并且需要深层次理解图片内容,您可以调用视觉模型进一步理解图片含义。
# (DashScopeParse返回的数据结构中,针对图片数据,markdownContent字段是图片url,text字段是解析出的文本)
# if ".jpg" in item["markdownContent"] or ".jpeg" in item["markdownContent"] or ".png" in item["markdownContent"]:
# image_url = re.findall(r'\!\[.*?\]\((https?://.*?)\)', item["markdownContent"])[0]
# print(image_url)
# markdown_content = markdown_content + parse_image_to_text(image_url)+"\n"
# else:
# markdown_content = markdown_content + item["text"]+"\n"
markdown_content = markdown_content + item["text"]+"\n"
return markdown_content
### 调用示例
# 1、可选配置。
# 百炼平台上,可以对不同项目配置不同的业务空间,默认情况下是使用默认业务空间。
# 如果需要使用非默认空间,可以前往[百炼控制台-业务空间管理](https://bailian.console.aliyun.com/?admin=1#/efm/business_management),配置业务空间并获取Workspace ID。
# 完成后,取消注释并修改这段代码为实际值:
# os.environ['DASHSCOPE_WORKSPACE_ID'] = "<Your Workspace id, Default workspace is empty.>"
# 2、可选配置。
# 文件通过DashScopeParse进行解析时,需要配置上传的数据目录id。可以前往[百炼控制台-数据管理](https://bailian.console.aliyun.com/#/data-center),配置类目并获取ID
category_id="default" # 建议修改为自定义的类目ID,以便分类管理文件
md_content = file_to_md(['./docs/内容公司各部门职责与关键角色联系信息汇总.pdf'], category_id)
print("解析后的Markdown文本:")
print("-"*100)
print(md_content)由于pdf/docx等多种文件格式来源的多样性,文件解析到markdown过程中可能存在一些格式上的小问题,比如 PDF 里的跨页表格行可能被解析为多行。
可以使用大模型对生成的markdown文本进行润色,修正目录层级、缺失信息等。
python
from dashscope import Generation
python
def md_polisher(data):
messages = [
{'role': 'user', 'content': '下面这段文本是由pdf转为markdown的,格式和内容可能存在一些问题,需要你帮我优化下:\n1、目录层级,如果目录层级顺序不对请以markdown形式补全或修改;\n2、内容错误,如果存在上下文不一致的情况,请你修改下;\n3、如果有表格,注意上下行不一致的情况;\n4、输出文本整体应该与输入没有较大差异,不要自己制造内容,我是需要对原文进行润色;\n4、输出格式要求:markdown文本,你的所有回答都应该放在一个markdown文件里面。\n特别注意:只输出转换后的 markdown 内容本身,不输出任何其他信息。\n需要处理的内容是:' + data}
]
response = Generation.call(
model="qwen-plus",
messages=messages,
result_format='message',
stream=True,
incremental_output=True
)
result = ""
print("润色后的Markdown文本:")
print("-"*100)
for chunk in response:
print(chunk.output.choices[0].message.content, end='')
result += chunk.output.choices[0].message.content
return(result)
python
md_polisher(md_content)使用多种文档切片方法
在文档切片的过程中,切片方式会影响检索召回的效果。让我们通过具体例子来了解不同切片方法的特点。首先创建一个通用的评测函数
python
def evaluate_splitter(splitter, documents, question, ground_truth, splitter_name):
"""评测不同文档切片方法的效果"""
print(f"\n{'='*50}")
print(f"🔍 正在使用 {splitter_name} 方法进行测试...")
print(f"{'='*50}\n")
# 构建索引
print("📑 正在处理文档...")
nodes = splitter.get_nodes_from_documents(documents)
index = VectorStoreIndex(nodes, embed_model=Settings.embed_model)
# 创建查询引擎
query_engine = index.as_query_engine(
similarity_top_k=5,
streaming=True
)
# 执行查询
print(f"\n❓ 测试问题: {question}")
print("\n🤖 模型回答:")
response = query_engine.query(question)
response.print_response_stream()
# 输出参考片段
print(f"\n📚 {splitter_name} 召回的参考片段:")
for i, node in enumerate(response.source_nodes, 1):
print(f"\n文档片段 {i}:")
print("-" * 40)
print(node)
# 评估结果
print(f"\n📊 {splitter_name} 评估结果:")
print("-" * 40)
display(evaluate_result(question, response, ground_truth))接下来,让我们看看各种切片方法的特点和示例:
Token切片
适合对Token数量有严格要求的场景,比如使用上下文长度较小的模型时。
示例文本:"LlamaIndex是一个强大的RAG框架。它提价了多种文档处理方式。用户可以根据需要选择合适的方法。"
使用Token切片(chunk_size=10)后可能的结果:
- 切片1:"LlamaIndex是一个强大的RAG"
- 切片2:"框架。它提供了多种文"
- 切片3:"档处理方式。用户可以"
python
token_splitter = TokenTextSplitter(
chunk_size=1024,
chunk_overlap=20
)
evaluate_splitter(token_splitter, documents, question, ground_truth, "Token")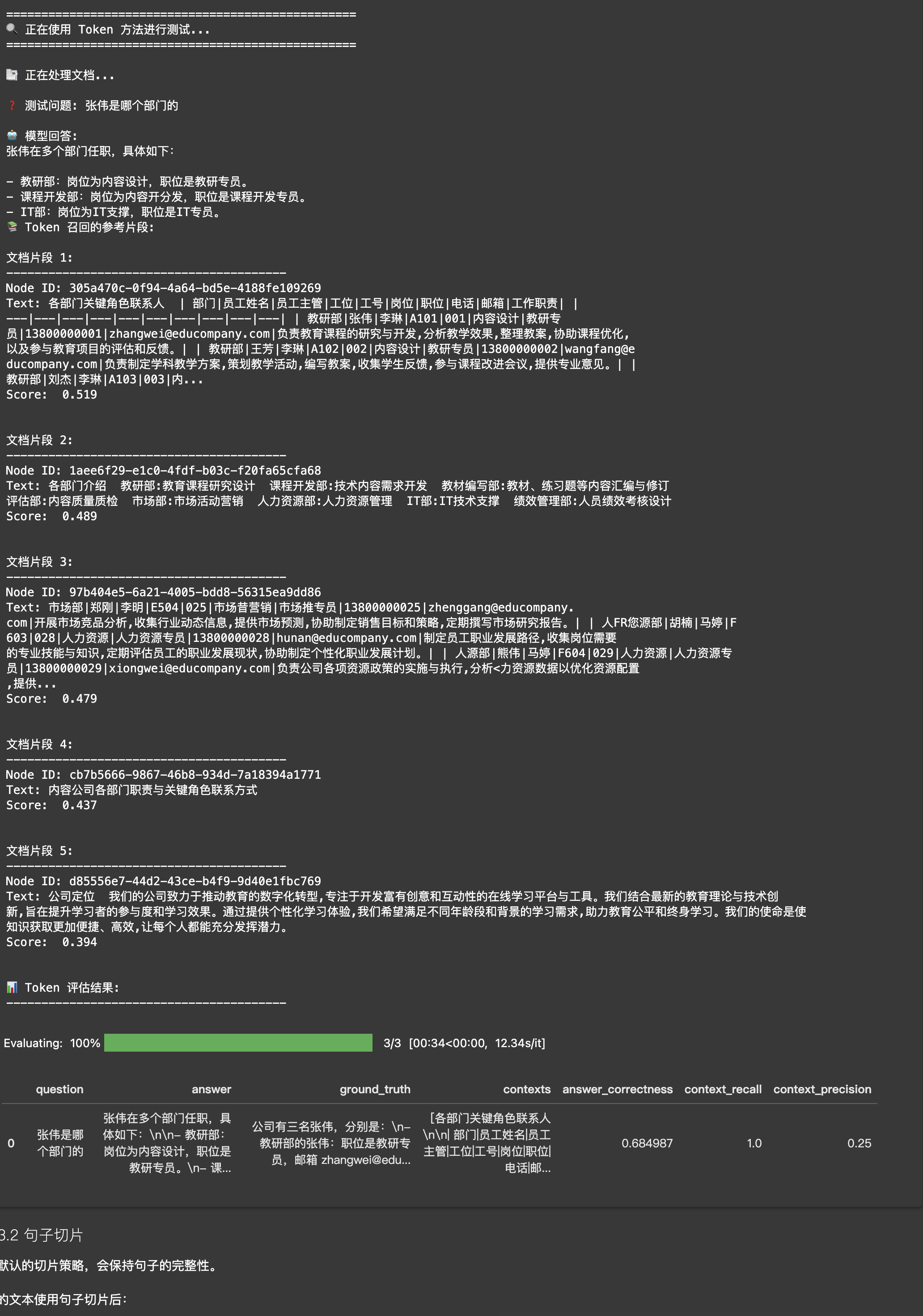
句子切片
这是默认的切片策略,会保持句子的完整性。
同样的文本使用兔子切片后:
- 切片1:"LlamaIndex是一个强大的RAG框架"
- 切片2:"它提供了多种文档处理方式"
- 切片3:"用户可以根据需求选择合适的方法"
python
sentence_splitter = SentenceSplitter(
chunk_size=512,
chunk_overlap=50
)
evaluate_splitter(sentence_splitter, documents, question, ground_truth, "Sentence")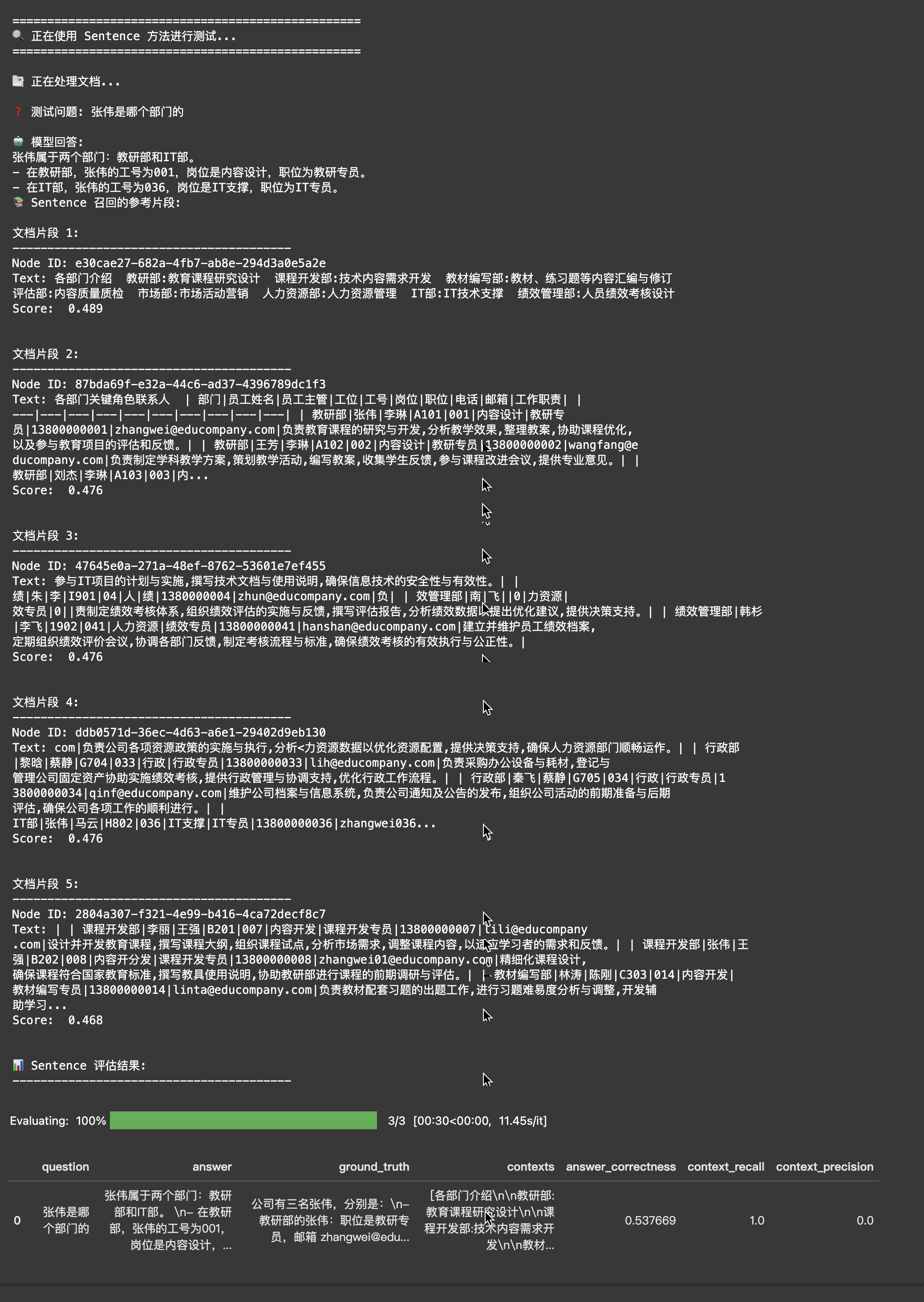
句子窗口切片
每个切片都包含周围的句子作为上下文窗口。
示例文本使用句子窗口切片(window_size=1)后:
- 切片1:"LlamaIndex是一个强大的RAG框架" 上下文:"它提供了多种文档处理方式"
- 切片2:"它提供了多种文档处理方式" 上下文:"LlamaIndex是一个强大的RAG框架,用户可以根据需求选择合适的方法"
- 切片3:"用户可以根据需求选择合适的方法" 上下文:"它提供了多种文档处理方式"
python
sentence_window_splitter = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text"
)
# 注意:句子窗口切片需要特殊的后处理器
query_engine = index.as_query_engine(
similarity_top_k=5,
streaming=True,
node_postprocessors=[MetadataReplacementPostProcessor(target_metadata_key="window")]
)
evaluate_splitter(sentence_window_splitter, documents, question, ground_truth, "Sentence Window")
语义切片
根据语义相关性自适应地选择切片点
示例文本: "LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需求选择合适的方法。此外,它还支持向量检索。这种检索方式非常高效。"
语义切片可能的结果:
- 切片1: "LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需求选择合适的方法。"
- 切片2: "此外,它还支持向量检索。这种检索方式非常高效。" (注意这里是按语义相关性分组的)
python
semantic_splitter = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=Settings.embed_model
)
evaluate_splitter(semantic_splitter, documents, question, ground_truth, "Semantic")
Markdown 切片 ¶
专门针对 Markdown 文档优化的切片方法。
示例 Markdown 文本:
# RAG框架
LlamaIndex是一个强大的RAG框架。
## 特点
- 提供多种文档处理方式
- 支持向量检索
- 使用简单方便
### 详细说明
用户可以根据需求选择合适的方法。Markdown切片会根据标题层级进行智能分割:
切片1: "# RAG框架\nLlamaIndex是一个强大的RAG框架。"
切片2: "## 特点\n- 提供多种文档处理方式\n- 支持向量检索\n- 使用简单方便"
切片3: "### 详细说明\n用户可以根据需求选择合适的方法。"
python
markdown_splitter = MarkdownNodeParser()
evaluate_splitter(markdown_splitter, documents, question, ground_truth, "Markdown")
在实际应用中,选择切片方法时不必过于纠结,你可以这样思考:
- 如果你刚开始接触RAG,建议先使用默认的句子切片方法,它在大多数场景下都能提价不错效果
- 当你发现检索结果不够理想时,可以尝试:
- 处理长文档且需要保持上下文?试试句子窗口切片
- 文档逻辑性强、内容专业?语义切片可能会有帮助
- 模型总是报Token超限?Token切片可以帮你精确控制
- 处理Markdown文档?别忘了有专门的Markdow切片
没有最好的切片方法,只有最适合你场景的方法。你可以尝试不同的切片方法,观察Ragas评估结果,找到最适合你的需求的方案。学习的过程就是不断尝试和调整的过程!
切片向量化与存储阶段
文档切片后,你还需要对其建立索引,以便后续检索。一个常见的方案使用嵌入(Embedding)模型将切片向量化,并存储到到向量数据库中。
在这一阶段,你需要选择合适的Embedding模型以及向量数据库,这对于提升检索效果至关重要
了解Embedding与向量化
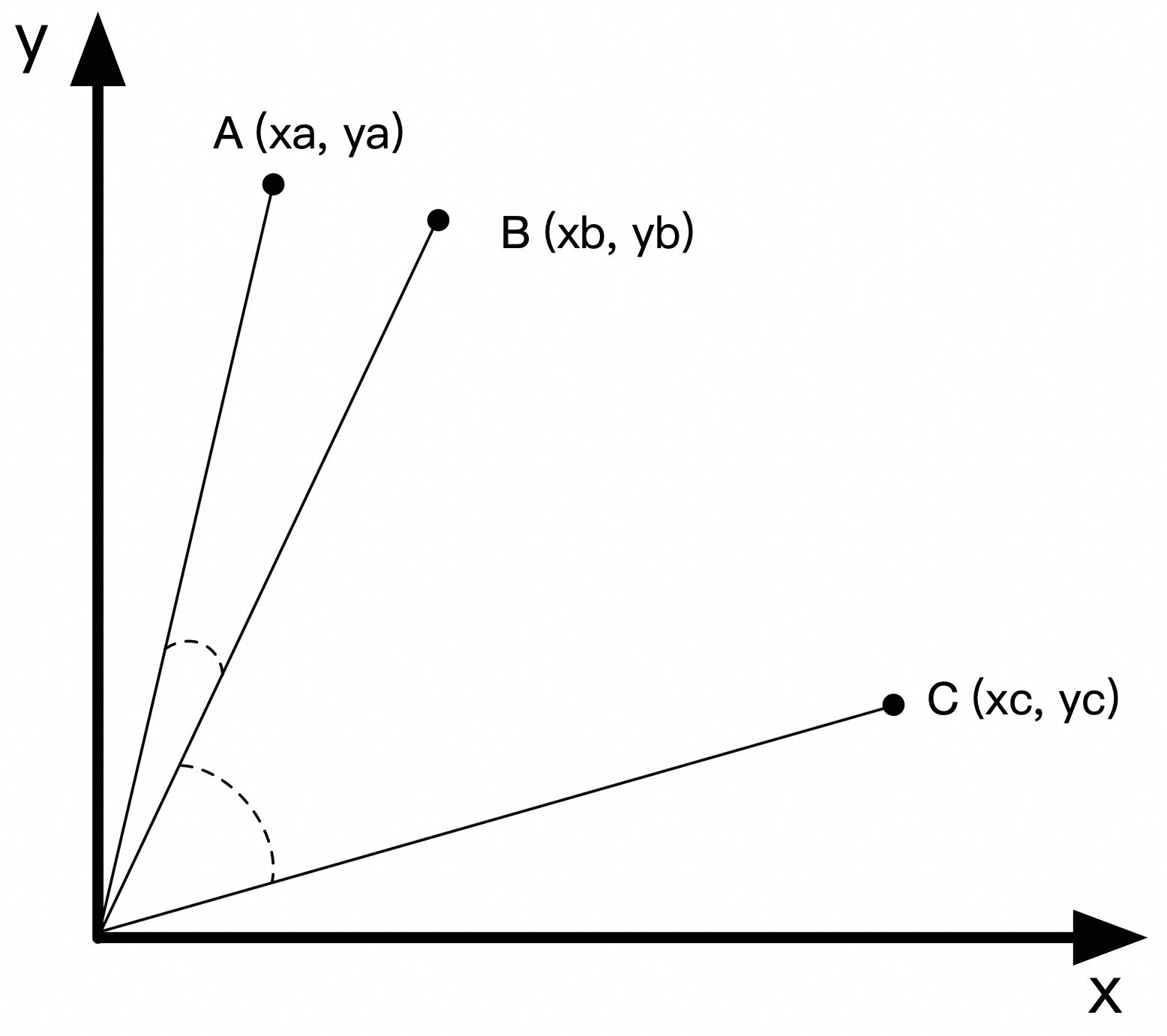
Embedding模型可以将文本转换为高维向量,用于表示文本语义,相似的文本会映射到相近的向量上,检索时可以根据问题的向量找到相似度高的文档切片。
平面坐标系中的有向线段是2维向量。例如,从原点(0,0)到A(xa,ya)的有向线段可以称为向量A。向量A与向量B之前的夹角越小,也就意味着其相似度越高。
python
import numpy as np
def cosine_similarity(a, b):
"""余弦相似度"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 示例向量
a = np.array([0.2, 0.8])
b = np.array([0.3, 0.7])
c = np.array([0.8, 0.2])
print(f"A 与 B 的余弦相似度: {cosine_similarity(a, b)}")
print(f"B 与 C 的余弦相似度: {cosine_similarity(b, c)}")
python
A 与 B 的余弦相似度: 0.987241120712647
B 与 C 的余弦相似度: 0.6050832675335579选择合适的Embedding模型
不同的Embedding模型对相同的几段文字进行计算时,得到的向量可能会完全不同。通常越新的Embedding模型,其表现越好。例如前文中使用的是阿里云百炼上提供的text-embedding-v2。如果换成更新的版本text-embedding-v3你会发现即使不去做前面的优化,检索效果也会有一定的提升。
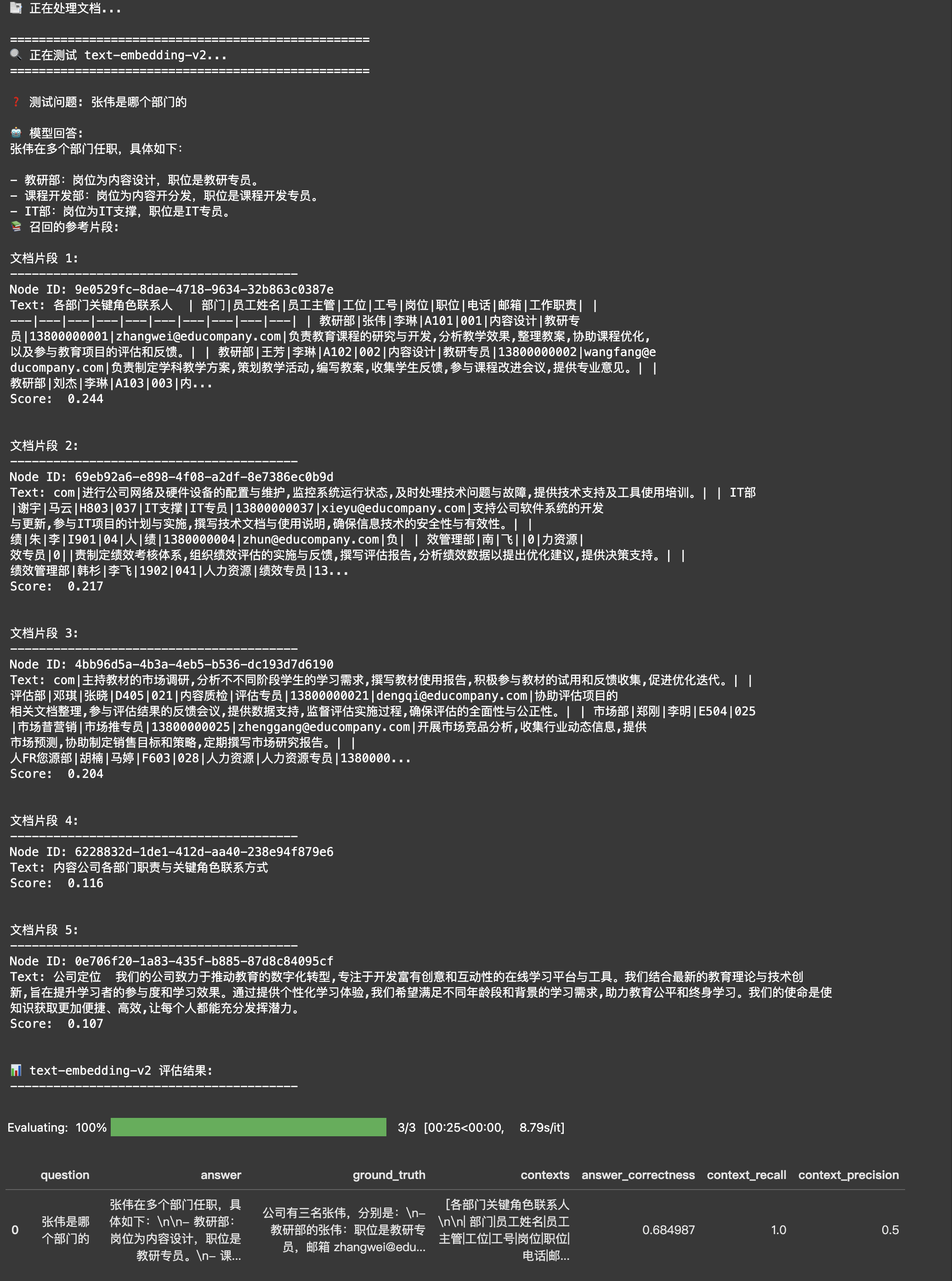
比如运行下面的代码可以看到,不同版本的Embedding模型,对于【张伟是哪个部门的】这个问题和不同文档切片的相似度也是不同的。
python
def compare_embeddings(query, chunks, embedding_models):
"""比较不同嵌入模型的文本相似度
Args:
query: 查询文本
chunks: 待比较的文本片段列表
embedding_models: 嵌入模型字典,格式为 {模型名称: 模型实例}
"""
# 打印输入文本
print(f"查询: {query}")
for i, chunk in enumerate(chunks, 1):
print(f"文本 {i}: {chunk}")
# 计算并显示每个模型的相似度结果
for model_name, model in embedding_models.items():
print(f"\n{'='*20} {model_name} {'='*20}")
query_embedding = (model.get_query_embedding(query) if hasattr(model, 'get_query_embedding')
else model.get_text_embedding(query))
for i, chunk in enumerate(chunks, 1):
chunk_embedding = model.get_text_embedding(chunk)
similarity = cosine_similarity(query_embedding, chunk_embedding)
print(f"查询与文本 {i} 的相似度: {similarity:.4f}")
# 准备测试数据
query = "张伟是哪个部门的"
chunks = [
"核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034 qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布",
"组织公司活动的前期准备与后期评估,确保公司各项⼯作的顺利进⾏。 IT部 张伟 ⻢云 H802 036 IT⽀撑 IT专员 13800000036 zhangwei036@educompany.com 进⾏公司⽹络及硬件设备的配置"
]
# 定义要测试的嵌入模型
embedding_models = {
"text-embedding-v2": DashScopeEmbedding(model_name="text-embedding-v2"),
"text-embedding-v3": DashScopeEmbedding(model_name="text-embedding-v3")
}
# 执行比较
compare_embeddings(query, chunks, embedding_models)
python
查询: 张伟是哪个部门的
文本 1: 核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034 qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布
文本 2: 组织公司活动的前期准备与后期评估,确保公司各项⼯作的顺利进⾏。 IT部 张伟 ⻢云 H802 036 IT⽀撑 IT专员 13800000036 zhangwei036@educompany.com 进⾏公司⽹络及硬件设备的配置
==================== text-embedding-v2 ====================
查询与文本 1 的相似度: 0.3692
查询与文本 2 的相似度: 0.2580
==================== text-embedding-v3 ====================
查询与文本 1 的相似度: 0.4946
查询与文本 2 的相似度: 0.5603除了通过相似度对比来评估不同Embedding模型的效果,你可以从实际应用的角度来评测。下面你将使用使用Ragas评测工具来对比text-embedding-v2和text-embedding-v3两个模型在RAG系统中的实际表现。
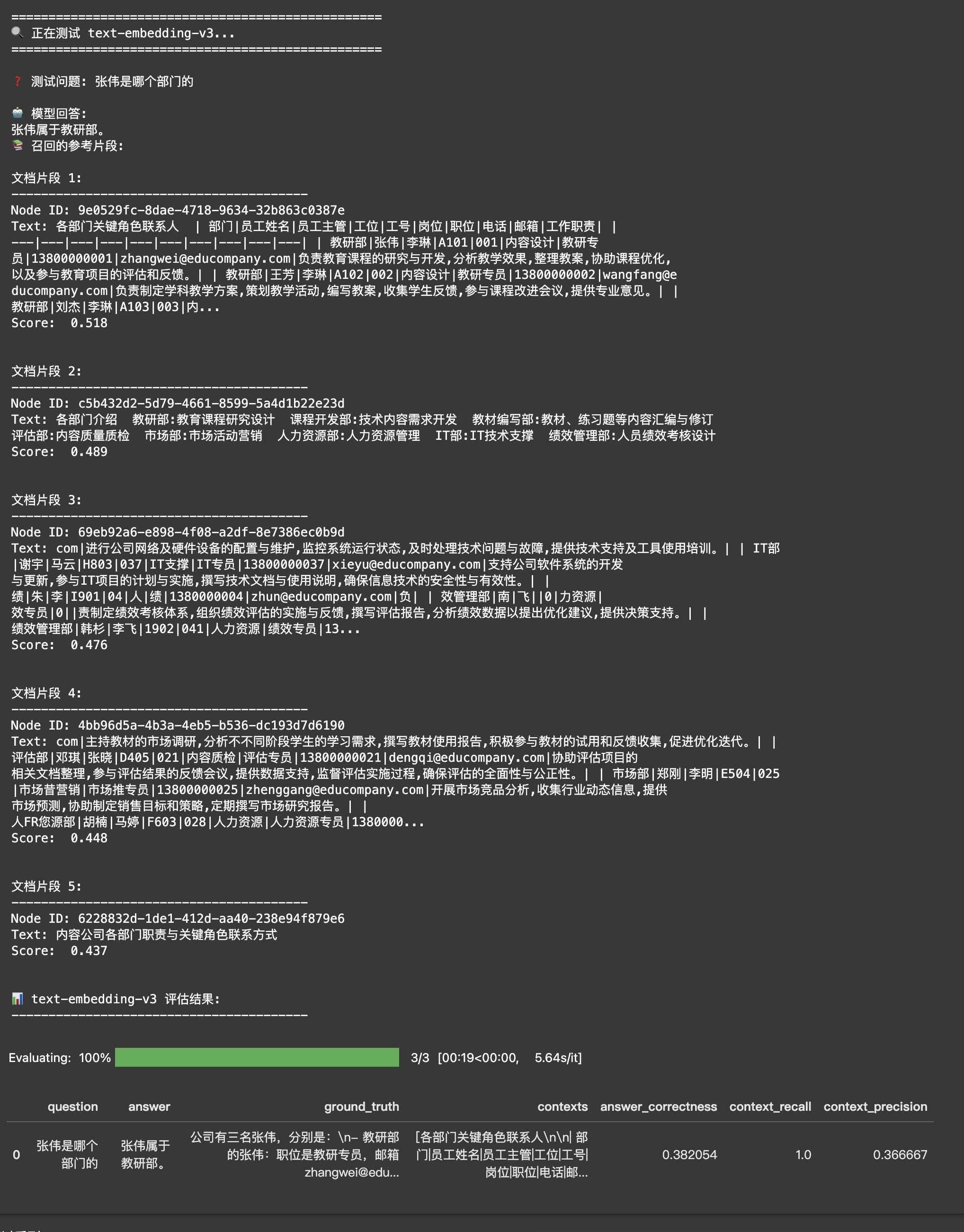
通过运行以下代码,你可以清晰地看到在相同的RAG策略下,text-embedding-v3模型的整体效果要优化text-embedding-v2。
python
def compare_embedding_models(documents, question, ground_truth, sentence_splitter):
"""比较不同嵌入模型在RAG中的表现
Args:
documents: 文档列表
question: 查询问题
ground_truth: 标准答案
sentence_splitter: 文本分割器
"""
# 文档分割
print("📑 正在处理文档...")
nodes = sentence_splitter.get_nodes_from_documents(documents)
# 定义要测试的嵌入模型配置
embedding_models = {
"text-embedding-v2": DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
),
"text-embedding-v3": DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3,
embed_batch_size=6,
embed_input_length=8192
)
}
# 测试每个模型
for model_name, embed_model in embedding_models.items():
print(f"\n{'='*50}")
print(f"🔍 正在测试 {model_name}...")
print(f"{'='*50}")
# 构建索引和查询引擎
index = VectorStoreIndex(nodes, embed_model=embed_model)
query_engine = index.as_query_engine(streaming=True, similarity_top_k=5)
# 执行查询
print(f"\n❓ 测试问题: {question}")
print("\n🤖 模型回答:")
response = query_engine.query(question)
response.print_response_stream()
# 显示召回的文档片段
print(f"\n📚 召回的参考片段:")
for i, node in enumerate(response.source_nodes, 1):
print(f"\n文档片段 {i}:")
print("-" * 40)
print(node)
# 评估结果
print(f"\n📊 {model_name} 评估结果:")
print("-" * 40)
evaluation_score = evaluate_result(question, response, ground_truth)
display(evaluation_score)
# 准备测试数据
documents = SimpleDirectoryReader('./docs/2_5').load_data()
sentence_splitter = SentenceSplitter(
chunk_size=1000,
chunk_overlap=200,
)
# 执行比较
compare_embedding_models(
documents=documents,
question=question,
ground_truth=ground_truth,
sentence_splitter=sentence_splitter
)
你可以看到:
- 新版本的Embedding模型通常能带来更好的效果(如text-embedding-v3比v2表现更好)
- 在实践中,单纯升级Embedding模型就可能显著提升检索质量
- 建议你首先尝试最新的text-embedding-v3模型,它在大多数任务上都能取得不错的效果。同时可以持续关注DashscopeEmbedding新模型的进展,根据实际需求选择升级到性能更好的版本。
选择合适的向量数据库
在构建RAG应用时,你有多种向量存储方案可以选择,从简单到复杂依次是:
内存向量存储
最简单的方式是使用LlamaIndex内置的内存向量存储。只需安装llama-index包无需额外配置,就能快速开发和测试RAG应用。
python
在这里插入代码片优点是快速上手,适合开发测试;缺点是数据无法持久化,且受限于内存大小。
本地向量数据库
当数据量增大时,可以使用开源的向量数据库,如Milvus、Qdrant等。这些数据库提供了数据持久化和高效检索能力。
优点是功能完整、可控性强;缺点是需要自行部署维护。
云服务向量存储
对于生产环境,推荐使用云服务提供的向量存储能力。阿里云提供了多种选择:
- 向量检索服务(DashVector):按量付费、自动扩容,适合快速启动项目。
- 向量检索服务Milvus版:兼容开源Milvus,便于迁移已有应用
- 已有数据库的向量能力:如果已使用阿里云数据库(RDS、PolarDB等)
云服务的优势在于:
- 无需关注运维,自动扩容
- 提供完善的监控和管理工具
- 按量付费,成本可控
- 支持向量+标量的混合检索,提升检索准确性
选择建议:
- 开发测试时使用内存向量存储
- 小规模应用可以使用本地向量数据库
- 生产环境推荐使用云服务,可根据具体需求选择合适的服务类型
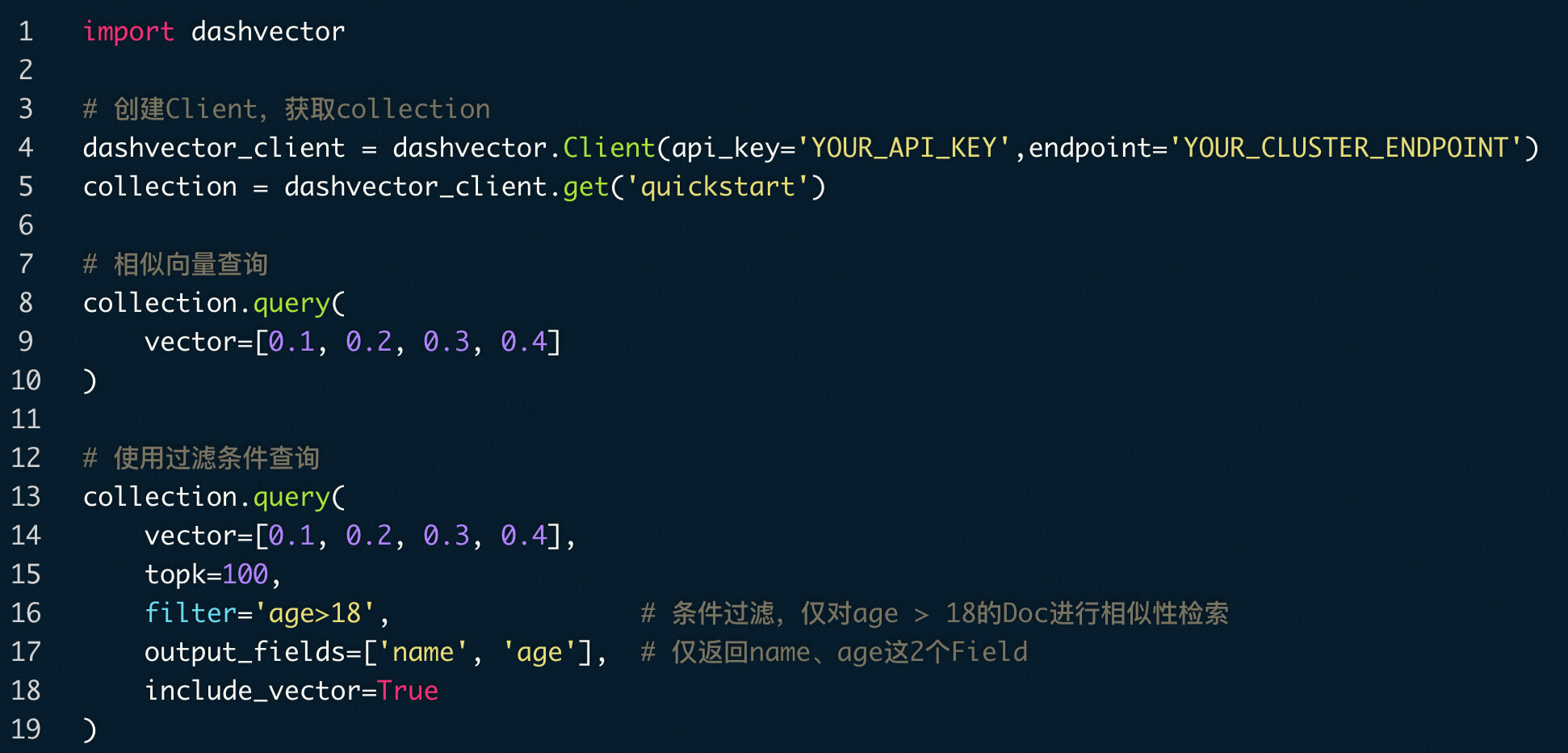 DashVector 中支持 age、name 等标签过滤 + 向量相似度检索
DashVector 中支持 age、name 等标签过滤 + 向量相似度检索
检索召回阶段
检索阶段会遇到的主要问题就是,很难从众多文档切片中,找出和用户问题最相关、且包含正确答案信息的片段。
从切入时机来看,可以将解法分为两磊类:
- 在执行检索前,很多用户问题描述是不完整、甚至有歧义的,你需要想办法还原用户真实意图、以便提升检索效果。
- 在执行检索后,你可能会发现存在一些无关的信息,需要想办法减少无关信息,避免干扰下一步的答案生成。
| 时机 | 改进策略 | 示例 |
|---|---|---|
| 检索前 | 问题改写 | 「附近有好吃的餐厅吗?」=> 「请推荐我附近的几家评价较高的餐厅」 |
| 检索前 | 问题扩写 通过增加更多信息,让检索结果更全面 | 「张伟是哪个部门的?」=> 「张伟是哪个部门的?他的联系方式、职责范围、工作目标是什么?」 |
| 检索前 | 基于用户画像扩展上下文 结合用户信息、行为等数据扩写问题 | 内容工程师提问「工作注意事项」=> 「内容工程师有哪些工作注意事项」 项目经理提问「工作注意事项」=> 「项目经理有哪些工作注意事项」 |
| 检索前 | 提取标签 提取标签,用于后续标签过滤+向量相似度检索 | 「内容工程师有哪些工作注意事项」=> * 标签过滤:{"岗位": "内容工程师"} * 向量检索:「内容工程师有哪些工作注意事项」 |
| 检索前 | 反问用户 | 「工作职责是什么」=> 大模型反问:「请问你想了解哪个岗位的工作职责」 实现反问的提示词可以参考: 10分钟构建能主动提问的智能导购 |
| 检索前 | 思考并规划多次检索 | 「张伟不在,可以找谁」 => 大模型思考规划: => task_1:张伟的职责是什么, task_2:${task_1_result}职责的人有谁 => 按顺序执行多次检索 |
| 检索前 | ... | ... |
| 检索后 | 重排序 ReRank + 过滤 多数向量数据库会考虑效率,牺牲一定精确度,召回的切片中可能有一些实际相关性不够高 | chunk1、chunk2...、chunk10 => chunk 2、chunk4、chunk5 |
| 检索后 | 滑动窗口检索 在检索到一个切片后,补充前后相邻的若干个切片。这样做的原因是:相邻切片之间往往存在语义联系,仅看单个切片可能会丢失重要信息。 滑动窗口检索确保了不会因为过度切分而丢失文本间的语义连接。 | 常见的实现是句子滑动窗口,你可以用下方的简化形式来理解: 假设原始文本为:ABCDEFG(每个字母代表一个句子) 当检索到切片:D 补充相邻切片后:BCDEF(前后各取2个切片) 这里的BC和EF是D的上下文。比如: * BC可能包含解释D的背景信息 * EF可能包含D的后续发展或结果 * 这些上下文信息能帮助你更准确地理解D的完整含义 通过召回这些相关的上下文切片,你可以提高检索结果的准确性和完整性。 |
| 检索后 | ... | ... |
问题改写
🤔为什么需要问题改写?
想象一下你在搜索"找张伟"或者"张伟 部门"这样的关键词。看似简单,但对于RAG系统来说,这样零散的搜索词可能不太好回答。因为在真实场景中,可能存在多个叫张伟的同事,而且用户输入的关键词往往过于简单,缺少必要的上下文信息。
✨问题改写能带来什么?
问题改写就像是帮助系统更好地理解用户意思。比如当你问"找张伟"时,系统可以把问题改写为更完整的形式,比如"请告诉我公司中所有叫张伟的员工及其所在部门"。这样的改写不仅能提高检索的准确性,还能让回答更加全面。
接下来,你可以通过实际案例来体验不同的问题改写策略。在这个案例中,你将使用以下配置:
- 文档:Markdown格式
- 切片:默认句子切片策略
- 模型:text-embedding-v3
- 存储:默认向量存储
python
# 配置嵌入模型
Settings.embed_model = DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3,
embed_batch_size=6,
embed_input_length=8192
)
# 加载文档
documents = SimpleDirectoryReader('./docs/2_5').load_data()
# 配置文档分割器
sentence_splitter = SentenceSplitter(
chunk_size=1000,
chunk_overlap=200,
)
# 文档分割
sentence_nodes = sentence_splitter.get_nodes_from_documents(documents)
# 构建索引
sentence_index = VectorStoreIndex(sentence_nodes, embed_model=Settings.embed_model)【常规方法:不改写问题,直接检索】
在你尝试问题改写之前,先看看直接使用原始问题进行检索的效果。这样的对比能让你更直观地感受问题改写带来的提升:
python
# 创建查询引擎
query_engine = sentence_index.as_query_engine(
streaming=True,
similarity_top_k=5
)
# 执行查询
print(f"❓ 用户问题: {question}\n")
streaming_response = query_engine.query(question)
print("\n💭 AI回答:")
print("-" * 40)
streaming_response.print_response_stream()
print("\n")
# 显示参考文档
print("\n📚 参考依据:")
print("-" * 40)
for i, node in enumerate(streaming_response.source_nodes, 1):
print(f"\n文档片段 {i}:")
print(f"相关度得分: {node.score:.4f}")
print("-" * 30)
print(node.text)
# 评估结果
print("\n📊 回答质量评估:")
print("-" * 40)
evaluation_score = evaluate_result(question, streaming_response, ground_truth)
display(evaluation_score)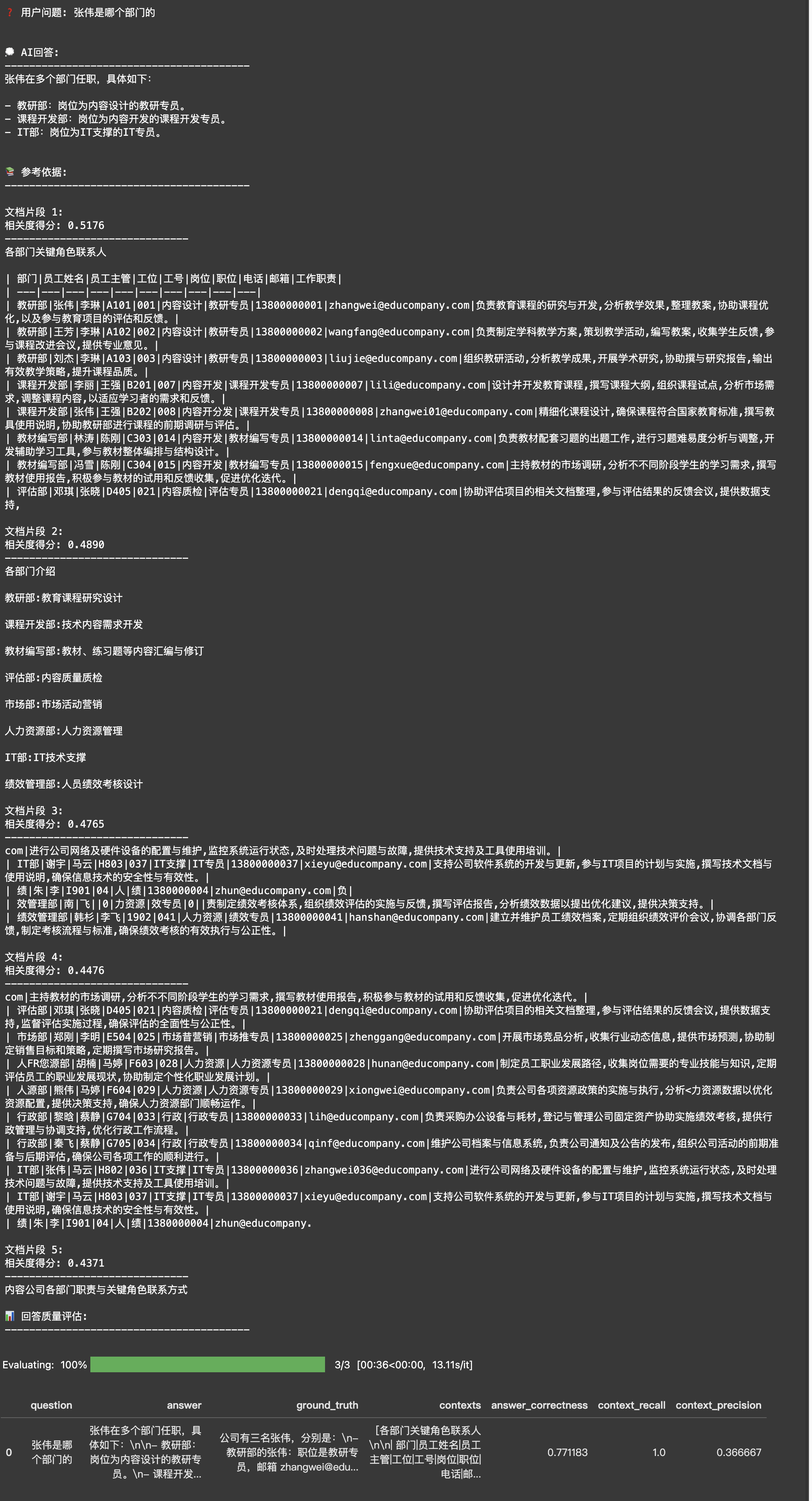
运行完这段代码,你可能会发现结果不太理想。虽然系统召回了5个相关片段,但并没有找到所有"张伟"的信息。这是为什么呢?
问题就出在提问方式上。当用户问"张伟是哪个部门的"时,这个问题对人来说很好理解,但对大模型来说却缺少了重要的上下文 ------ 公司里不止一个张伟!这就好比你去一个有多个王老师的学校问"王老师在哪个办公室",别人一定会反问你"你说的是哪个王老师呀?"
那么,如果让问题表达得更完整一些会怎样?比如明确说明你想知道"公司里所有叫张伟的同事的部门信息"。接下来,你可以试试用大模型来改写问题,看看效果会不会更好。
【方法一:使用大模型扩充用户问题】
你可以让大模型充当一个问题改写助手。它会帮你简单的问题改写得更加完整和清晰。比如,它不仅会考虑到可能存在个张伟的情况,还会把相关的上下文信息都补充进去。看看具体怎么做:
python
query_gen_str = """\
系统角色设定:
你是一个专业的问题改写助手。你的任务是将用户的原始问题扩充为一个更完整、更全面的问题。
规则:
1. 将可能的歧义、相关概念和上下文信息整合到一个完整的问题中
2. 使用括号对歧义概念进行补充说明
3. 添加关键的限定词和修饰语
4. 确保改写后的问题清晰且语义完整
5. 对于模糊概念,在括号中列举主要可能性
原始问题:
{query}
请生成一个综合的改写问题,确保:
- 包含原始问题的核心意图
- 涵盖可能的歧义解释
- 使用清晰的逻辑关系词连接不同方面
- 必要时使用括号补充说明
输出格式:
[综合改写] - 改写后的问题
"""
query_gen_prompt = PromptTemplate(query_gen_str)
python
def generate_queries(query: str):
response = Settings.llm.predict(
query_gen_prompt, query=query
)
return response
python
# 生成扩展查询
print("\n🔍 原始问题:")
print(f" {question}")
query = generate_queries(question)
print("\n📝 扩展查询:")
print(f" {query}\n")
# 创建查询引擎
query_engine = sentence_index.as_query_engine(
streaming=True,
similarity_top_k=5
)
# 执行查询
response = query_engine.query(query)
print("💭 AI回答:")
print("-" * 40)
response.print_response_stream()
print("\n")
# 显示参考文档
print("\n📚 参考依据:")
print("-" * 40)
for i, node in enumerate(response.source_nodes, 1):
print(f"\n文档片段 {i}:")
print(f"相关度得分: {node.score:.4f}")
print("-" * 30)
print(node.text)
# 评估结果
print("\n📊 回答质量评估:")
print("-" * 40)
evaluation_score = evaluate_result(query, response, ground_truth)
display(evaluation_score)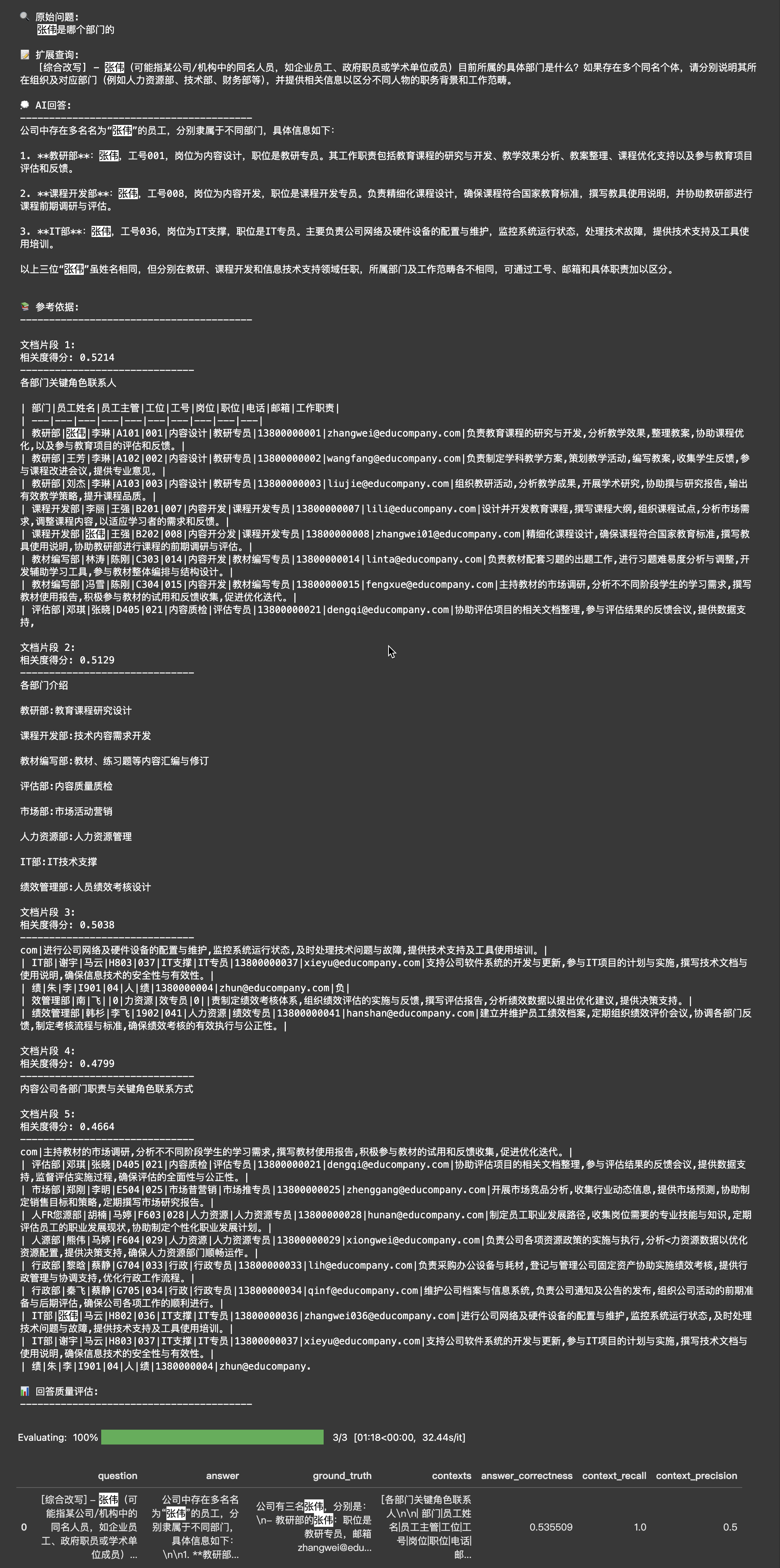
【方法二:将单一查询改写为多步步骤查询】
除了改写问题,你还可以尝试另一种思路:把复杂的问题拆解成简单的步骤。LlamaIndex提供了两个强大的工具来实现这个功能:
- StepDecomposeQuerytransform:这个工具可以帮你把一个复杂问题分解成多个子问题。比如对于"张伟是哪个部门的?",它会先分解为:
- "公司里有几个叫张伟的员工?"
- "这些张伟分别在哪些部门?"
这样可以更全面地获取所有张伟的信息。
- MultiStepQueryEngine:这个查询引擎会按顺序处理这些子问题。它会先获取公司所有张伟的信息,然后再查询每个张伟的部门信息,最终将答案整合成一个完整的回应,告诉用户"公司有三名张伟,分别在教研部、课程开发部和IT部"。
这种方法就像解决数学题一样------把大问题分解成小问题往往更容易得到准确的答案。不过要注意,这种方法会多次调用大模型,所以会消耗更多的token。
python
from llama_index.core.indices.query.query_transform.base import (
StepDecomposeQueryTransform,
)
step_decompose_transform = StepDecomposeQueryTransform(verbose=True)
# set Logging to DEBUG for more detailed outputs
from llama_index.core.query_engine import MultiStepQueryEngine
query_engine = sentence_index.as_query_engine(streaming=True,similarity_top_k=5)
query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform,
index_summary="公司人员信息"
)
print(f"❓ 用户问题: {question}\n")
print("🤖 AI正在进行多步查询...")
response = query_engine.query(question)
print("\n📚 参考依据:")
print("-" * 40)
for i, node in enumerate(response.source_nodes, 1):
print(f"\n文档片段 {i}:")
print("-" * 30)
print(node.text)
# 评估结果
print("\n📊 多步查询评估结果:")
print("-" * 40)
evaluation_score = evaluate_result(question, response, ground_truth)
display(evaluation_score)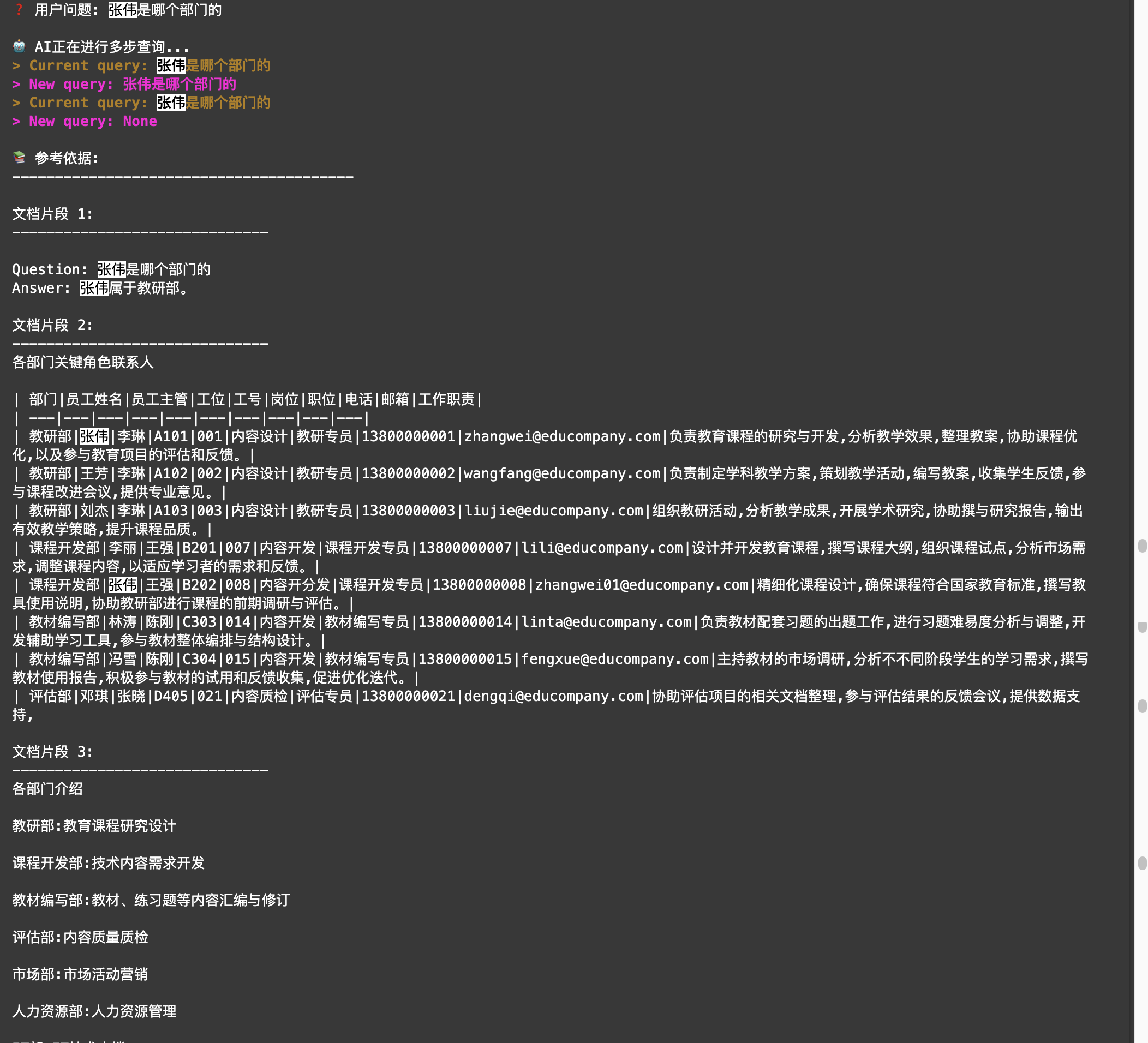
【方法三:用假设文档来增强检索(HyDE)】
前面的方法都是在调整问题本身,现在让我们换个思路:如果我们先假设一个可能的答案来怎样?这就是HyDE(Hypothetical Document Embeddings)方法的独特之处。
它的工作方式很有趣:
- 先让大模型基于问题编一个"假想的答案文档"
- 用这个假想文档来检索真实文档
- 最后用检索到的真实文档来生成实际答案
这就像你在找一本书时,心里已经有了一个大致的内容轮廓,然后用这个轮廓去图书馆匹配相似的书籍。让我们看看具体怎么实现:
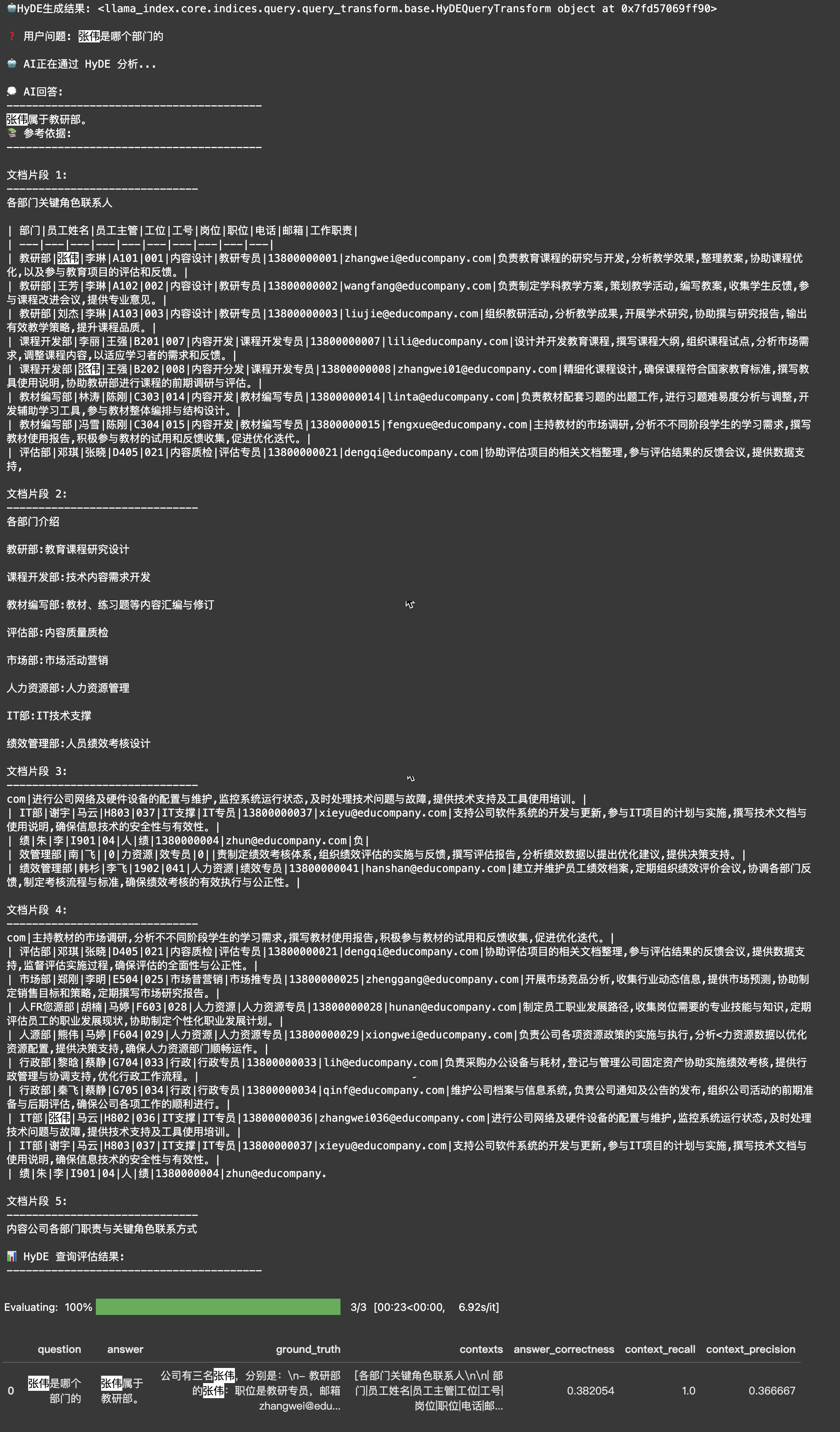
从评测结果可以看到,这种方法确实带来了一些改善。你可能会好奇:系统是如何生成这个"假想文档"的呢?一起来看看这个过程中,AI实际生成了什么内容:
python
query_bundle = hyde(question)
hyde_doc = query_bundle.embedding_strs[0]
print(f"🤖 AI生成的假想文档:\n{hyde_doc}\n")
python
🤖 AI生成的假想文档:
张伟是市场部的经理。他自2018年加入公司以来,一直负责市场推广、品牌建设和客户关系管理等工作。在他的带领下,市场部成功策划并执行了多个大型营销活动,显著提升了公司的市场知名度和产品销量。张伟拥有丰富的市场营销经验,曾在多家知名企业任职,具备敏锐的市场洞察力和出色的团队领导能力。他目前直接向公司副总裁汇报工作,并与其他部门密切协作,推动公司整体战略目标的实现。有趣的是,虽然这个"假想文档"完全是AI编造的,但它的结构和风格与真实的公司员工信息非常相似。LlamaIndex提供了灵活的控制机制来优化这个过程:
HyDEQuerytransform类允许我们通过以下方式精确控制假想文档的生成:
- 自定义LLM:通过llm参数传入不同的大模型配置,可以选择更适合的语言模型来生成假想文档
- 提示词模板:通过hyde_prompt参数自定义提示词模板,精确控制输出的格式和内容
- 查询策略:使用include_original参数决定是否将原始查询与假想文档结合使用
TransformQueryEngine则作为查询引擎的包装器,它会:
- 先调用HyDEQueryTransform生成假想文档
- 使用假想文档进行向量检索
- 最后返回查询结果
这种架构让我们能在不修改底层查询引擎的情况下,通过调整HyDEQueryTransform的参数来优化检索效果。即使假想文档的具体内容可能不够准确,但通过精心设计的配置,它可以非常帮助系统更准确地检索相关信息。
提取标签增强检索
在向量检索的基础上,我们还可以添加标签过滤来提升检索精度。这种方式类似于图书馆既有书名检索,又有分类编号系统,能让检索更精准。
标签提取有两个关键场景:
- 建立索引时,从文档切片中提取结构化标签
- 检索时,从用户问题中提取对应的标签进行过滤
让我们看两个例子来理解如何从不同类型的广西中提取标签:
python
import os
from openai import OpenAI
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
system_message = """你是一个标签提取专家。请从文本中提取结构化信息,并按要求输出标签。
---
【支持的标签类型】
- 人名
- 部门名称
- 职位名称
- 技术领域
- 产品名称
---
【输出要求】
1. 请用 JSON 格式输出,如:[{"key": "部门名称", "value": "教研部"}]
2. 如果某类标签未识别到,则不输出该类
---
待分析文本如下:
"""
def extract_tags(text):
completion = client.chat.completions.create(
model="qwen-turbo",
messages=[
{'role': 'system', 'content': system_message},
{'role': 'user', 'content': text}
],
response_format={"type": "json_object"}
)
return completion.choices[0].message.content
python
# 示例1:人事文档
hr_text = """张明是我们AI研发部的技术主管,他带领团队开发了新一代智能对话平台 ChatMax,在自然语言处理领域有着丰富经验。如果您需要了解项目细节,可以直接联系他。"""
print("人事文档标签提取结果:")
print(extract_tags(hr_text))
# 示例2:技术文档
tech_text = """本论文提出了一种基于深度学习的图像识别算法,在医疗影像分析中取得了突破性进展。该算法已在北京协和医院的CT诊断系统中得到应用。"""
print("\n技术文档标签提取结果:")
print(extract_tags(tech_text))
python
人事文档标签提取结果:
[{"key": "人名", "value": "张明"}, {"key": "部门名称", "value": "AI研发部"}, {"key": "职位名称", "value": "技术主管"}, {"key": "产品名称", "value": "ChatMax"}, {"key": "技术领域", "value": "自然语言处理"}]
技术文档标签提取结果:
[{"key": "技术领域", "value": "深度学习"}, {"key": "部门名称", "value": "北京协和医院"}, {"key": "产品名称", "value": "CT诊断系统"}]当我们建立索引时,可以将这些标签与文档切片一起存储。这样在检索时,比如用户问"张伟是哪个部门的",我们可以:
- 从问题中提取人名标签{"key":"人名",value:"张伟"}
- 先用标签过滤出所有包含"张伟"的文档切片
- 再用向量相似度检索找出最相关的内容
这种"标签过滤+向量检索"的相似方式,能大幅提升检索的准确性。特别是在处理结构化程度较高的企业文档时,这个方法效果更好。
重排序
python
![ -f ./docs/内容公司各部门职责与关键角色联系信息汇总.md ] && rm ./docs/内容公司各部门职责与关键角色联系信息汇总.md && echo "文件已删除。" || echo "文件不存在,无需删除。"- Markdown
Markdown
删除文件后,可以执行下面的代码。可以看到,你设置了从向量数据库中检索召回 3 条相关的文档切片。
从结果上来看,这 3 条切片,事实上不够相关,问答机器人无法正确回答「张伟是哪个部门的」。
python
from llama_index.llms.dashscope import DashScope
from chatbot import rag
python
index = rag.create_index('./docs')
query_engine = index.as_query_engine(
similarity_top_k=3,
streaming=True,
)
python
response = ask("张伟是哪个部门的", query_engine=query_engine)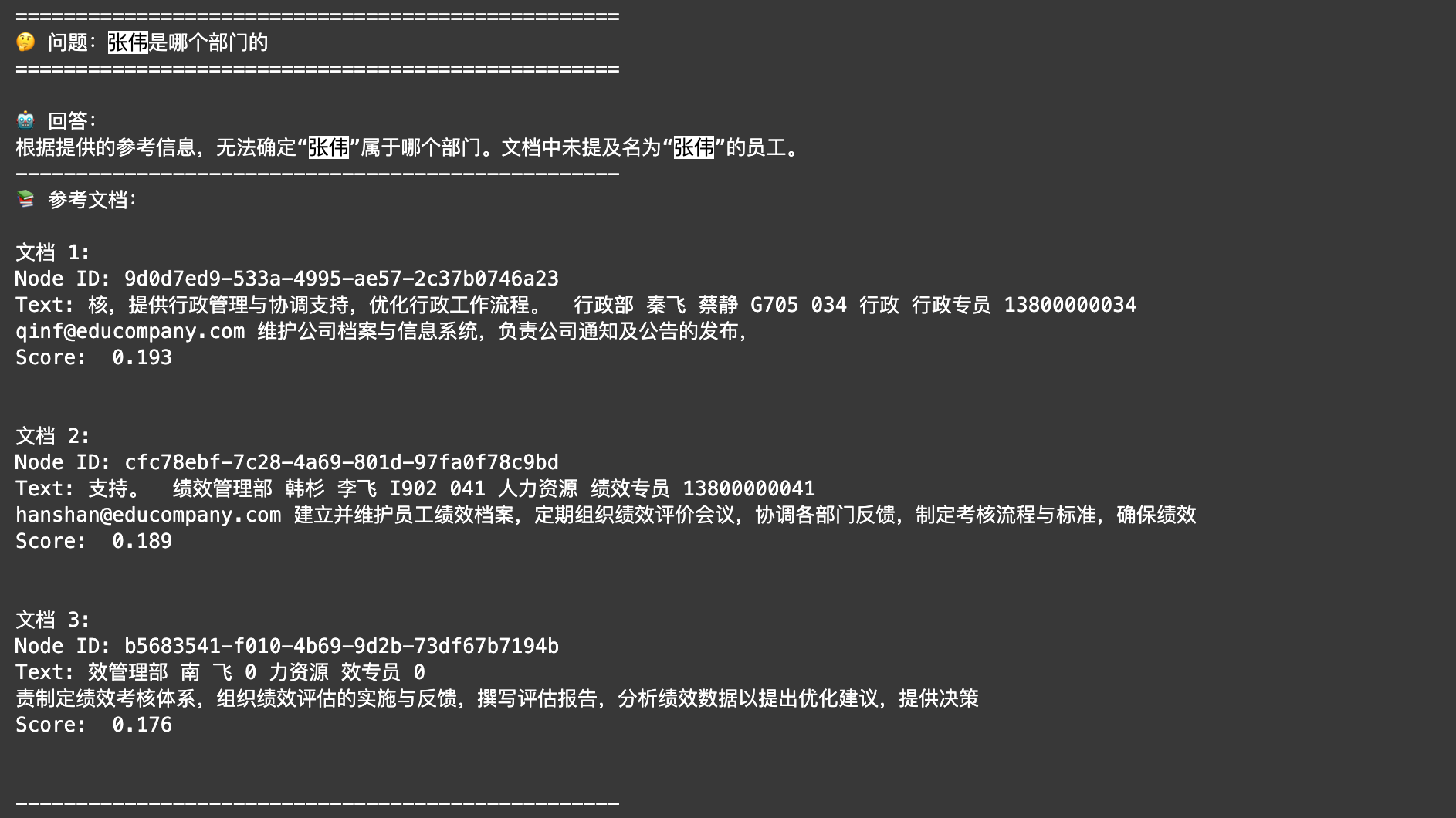
python
display(evaluate_result(question, response, ground_truth))
你可以调整代码,先从向量数据库中检索召回 20 条文档切片,再借助阿里云百炼提供的文本排序模型进行重排序,并且筛选出其中最相关的 3 条参考信息。
运行代码后你可以看到,同样是 3 条参考信息,这次大模型能够准确回答问题了。
python
from llama_index.postprocessor.dashscope_rerank import DashScopeRerank
from llama_index.core.postprocessor import SimilarityPostprocessor
python
query_engine = index.as_query_engine(
# 先设置一个较大的召回切片数量
similarity_top_k=20,
streaming=True,
node_postprocessors=[
# 在rerank 模型中选择你最终想召回的切片个数,重排模型选择通义实验室的gte-rerank模型
DashScopeRerank(top_n=3, model="gte-rerank"),
# 设置一个相似度阈值,低于该阈值的切片会被过滤掉
SimilarityPostprocessor(similarity_cutoff=0.2)
]
)
python
response = ask("张伟是哪个部门的", query_engine=query_engine)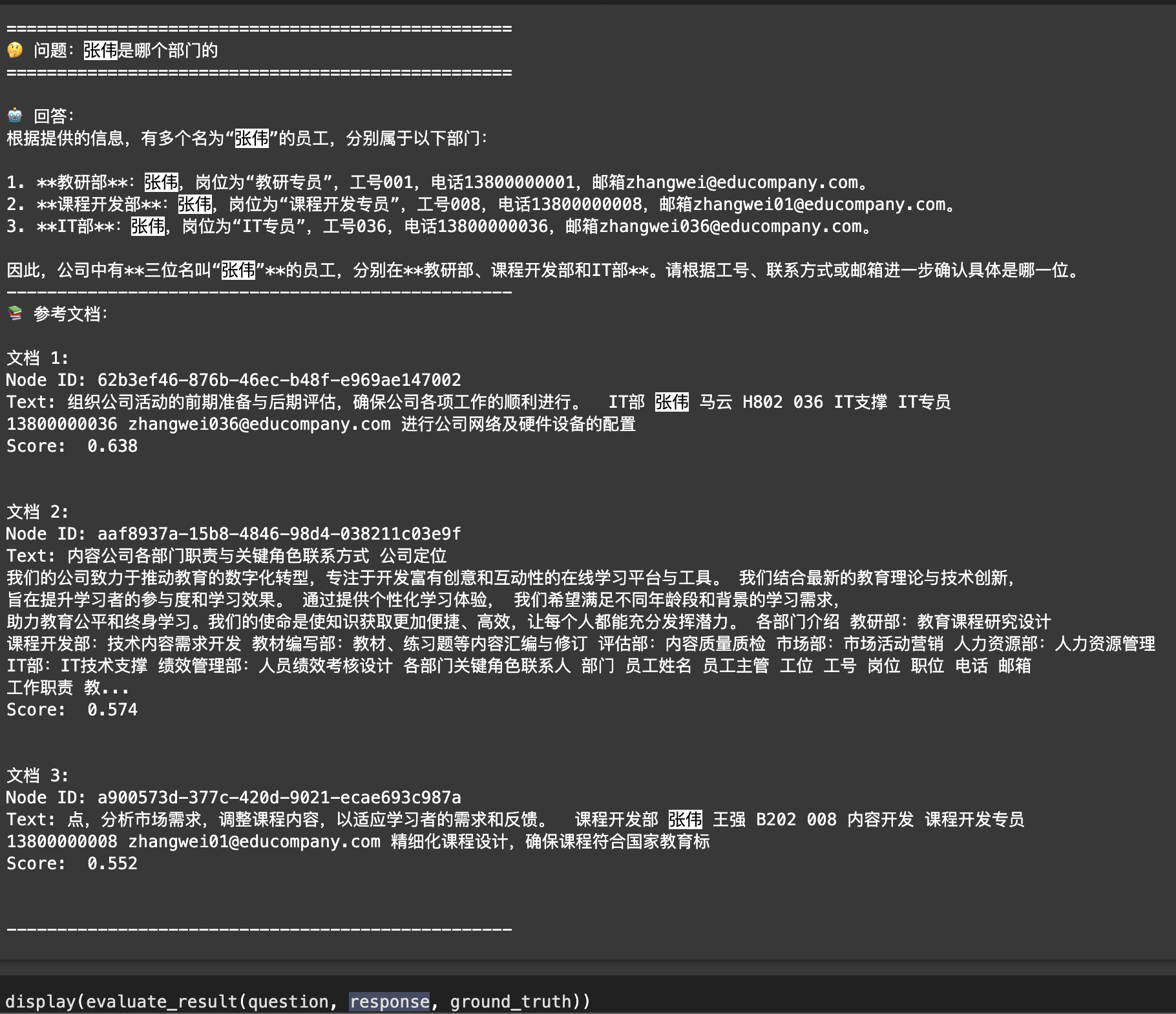
生成答案阶段
现在,大模型会根据你的问题和检索召回的内容,生成最终的答案。然而,这个答案可以还是不及你的预期。你可能会遇到的问题有:
- 没有检索到相关信息,大模型捏造答案。
- 检索到了相关信息,但是大模型没有按照要求生成答案
- 检索到了相关信息,大模型给出了答案,但是你希望AI给出更全面的答案。
为了解决这些问题,你可以从以下角度着手分析与解决:
- 选择合适的大模型
- A.如果只是简单的信息查询总结,小参数量的模型足以满足需求,比如plus-turbo.
- B.如果你希望答疑机器人能完成较为复杂的逻辑推理,建议选择参数量更大、推理能力更强的大模型,比如
- C. 如果你的问题需要查阅大量的文档片段,建议选择上下文长度更大的模型
- D.如果你构建的RAG应用面向一些非通用领域,如法律领域,建议面向特定领域训练的模型
- 充分优化提示词模板,比如:
- A.明确要求不编造答案:大模型可能会产生一些不真实的内容,通常称为幻觉。你可以通过提示词要求大模型:【如果所提供的信息不足以回答问题,请明确告知:"根据现有信息,我无法回答这个问题"切勿编造答案。】,来减少大模型产生幻觉的几率。
- B.添加内容分隔标记:检索召回的文档切片如果随意混杂在提示词里,人也很难看清整个提示词的结构,大模型也会受到干扰。建议将提示词和检索切片明确地分开,以便大模型能够正确地理解你的意图。
- C.根据问题类型调整模板:不同问题的回答范式可能是不同的,你可以借助大模型识别问题类型,然后映射使用不同的提示词模板。比如有些问题,你希望大模型先输出整体框架,然后再输出细节;有些问题你可能希望大模型言简意赅的给出结论。
- 调整大模型的参数,比如:
- A.如果你希望大模型输出在相同的问题下,输出的内容尽可能相同,你可以在每次模型调用时传入相同的seed值。
- B.如果你希望大模型在回答用户问题是不要总是用重复的句子,你可以适当调高presence_penalty值。
- C.如果你希望查询事实性的内容,可以适当降低temperature或top_p值;反之,查询创造性的内容时,可以适当增加它们的值。
- D.如果你需要限制字数(如生成摘要、关键词)、控制成本或减少响应时间的场景,可以适当降低max_tokens的值,但是若max_tokens过小,可能会导致输出截断,反之,需要生成大段文本时,可以提高它的值。
python
from llama_index.llms.openai_like import OpenAILike
from llama_index.core import Settings
import os
python
# 事实查询场景 - 低温度、高确定性
factual_llm = OpenAILike(
model="qwen-plus", # 使用通义千问-Plus模型
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True,
temperature=0.1, # 降低temperature使输出更确定性
max_tokens=512, # 控制输出长度,但是若max_tokens过小,可能会导致输出截断
presence_penalty=0.0, # 默认presence_penalty
seed=42 # 固定seed使输出可重现
)
python
# 创造性场景 - 高温度、更多样化
creative_llm = OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True,
temperature=0.7, # 提高temperature使输出更有创造性
max_tokens=1024, # 允许更长的输出
presence_penalty=0.6 # 提高presence_penalty减少重复
)