如何解决大文件上传问题
- [1. 概述](#1. 概述)
- [2. 技术方案](#2. 技术方案)
-
- [2.1 好处](#2.1 好处)
- [2.2 前端怎么生成文件分片呢?后端如何合并文件分片呢?](#2.2 前端怎么生成文件分片呢?后端如何合并文件分片呢?)
- [3. 代码](#3. 代码)
-
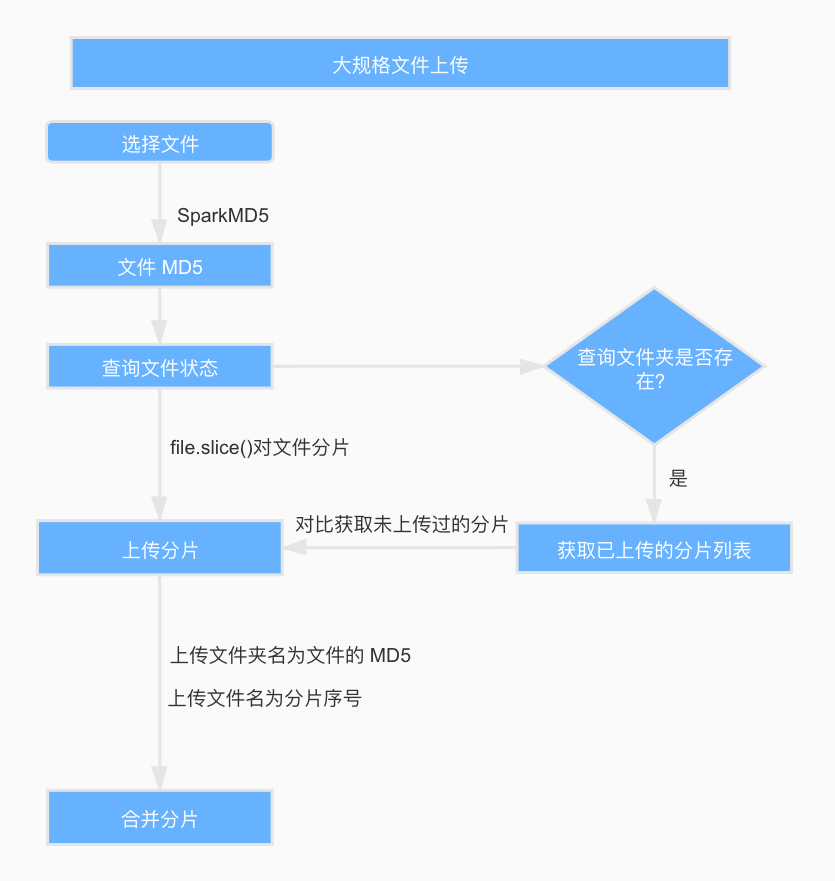
- [3.1 整体思路与流程](#3.1 整体思路与流程)
- [3.2 流程图](#3.2 流程图)
- [3.3 前端代码](#3.3 前端代码)
- [3.4 后端代码](#3.4 后端代码)
- 附录
1. 概述
场景一:上传一个5G大小的视频,如果上传进度到达99%,然后突然网络断了,这个时候你发现需要重新上传,很抓狂,那么如何解决这个问题呢?
答案:分片上传!
什么是分片上传呢? 简单来说就是先将文件切分成多个文件分片(如下图),然后再上传这些小的文件分片。
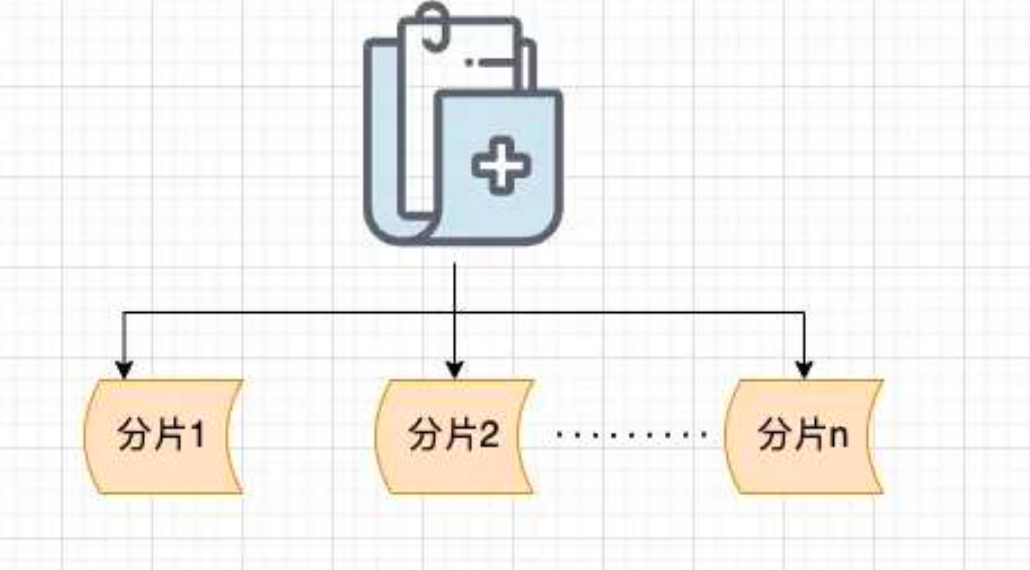
前端发送所有文件分片之后,服务端将这些文件分片进行合并即可,这样就得到一个完整的文件。
2. 技术方案
大致的流程如下:
- 生成要上传文件的唯一标识(如SHA-256);
- 将需要上传的文件按照一定的分割规则,分割成相同大小的分片;
- 初始化一个分片上传任务,返回本次分片上传的唯一标识;
- 每个分片在发送前,客户端会计算其哈希值(如SHA-256),并将这个哈希值与分片一起发送给服务端;
- 按照一定的策略(串行或并行)发送各个分片;
- 服务器接收到分片后,会重新计算分片的哈希值,并与客户端发送的哈希值进行比对;
- 如果哈希值匹配,则认为该分片有效,服务器会存储该分片并等待其他分片的到来;如果哈希值不匹配,服务器会通知客户端重新发送该分片;
- 所有分片发送完成后,服务端会根据判断数据上传是否完整。如果数据完整,服务端则进行分片的合成,以得到原始文件。
- 再计算合并后的文件的唯一标识,两者进行对比,一致则说明没问题。
2.1 好处
使用分片上传主要有下面2点好处:
- 断点续传:上传文件中途暂停或失败(比如遇到网络问题)之后,不需要重新上传,只需要上传那些未成功上传的文件分片即可。所以,分片上传是断点续传的基础。
- 多线程上传:我们可以通过多线程同时对一个文件的多个文件分片进行上传,这样的话就大大加快的文件上传的速度。
2.2 前端怎么生成文件分片呢?后端如何合并文件分片呢?
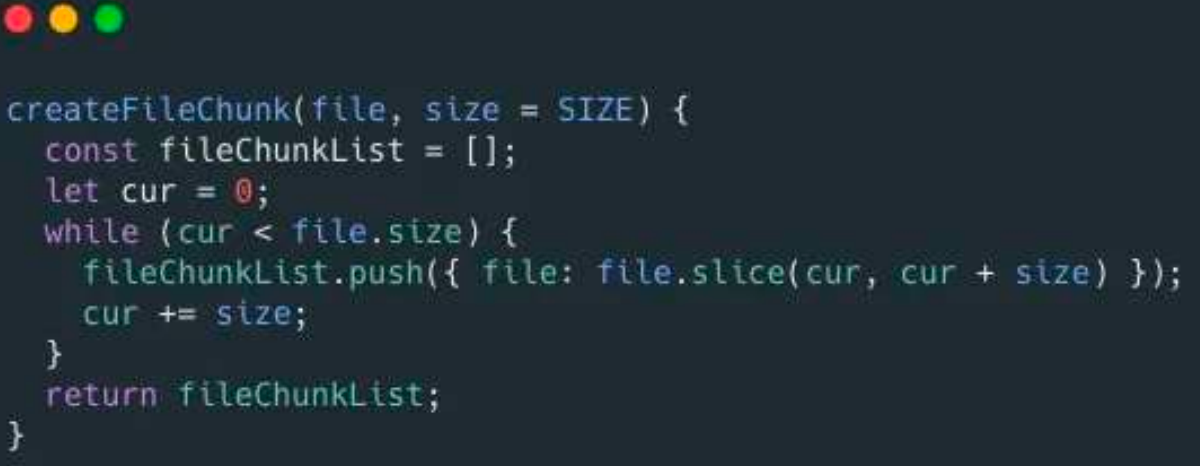
前端可以通过 Blob.slice()方法来对文件进行切割(File 对象是继承 Blob 对象的,因此 File对象也有 slice()方法)。
生成文件切片的示例代码如下:
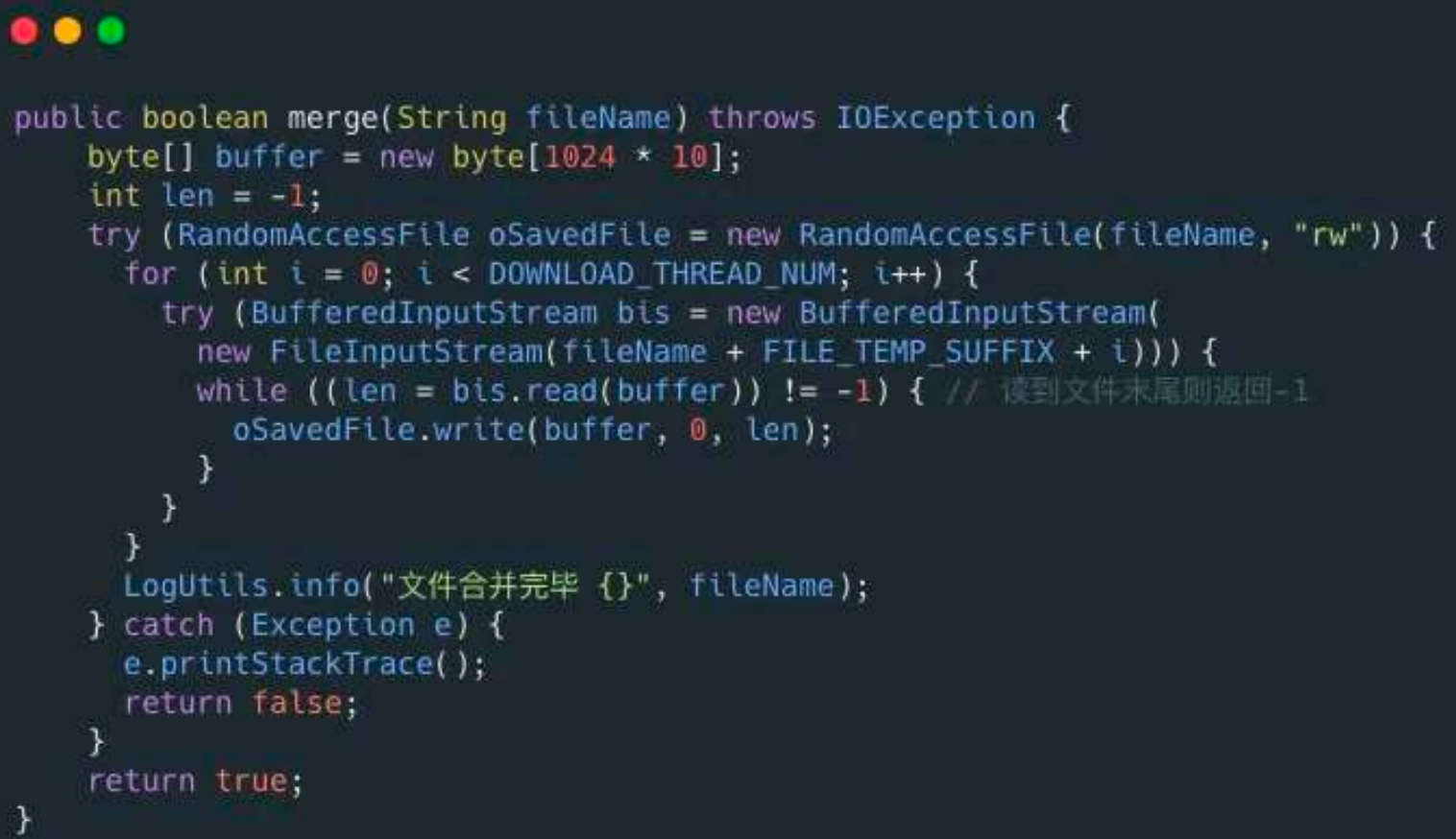
RandomAccessFile 类可以帮助我们合并文件分片,示例代码如下:
3. 代码
3.1 整体思路与流程
核心目标
- 支持大文件上传(数百 MB / GB 级别)。
- 支持断点续传,避免重复上传已完成的分片。
- 保证文件完整性(分片与文件级哈希校验)。
- 并行上传以提高上传速度。
整体流程
-
文件唯一标识
- 客户端计算文件 SHA-256(可用于断点续传和完整性校验)。
-
初始化上传任务
- 客户端请求服务器创建 uploadId。
- 服务端在 Redis 或数据库记录任务信息(文件名、文件大小、已上传分片)。
-
分片上传
- 客户端将文件按固定大小切片(4MB ~ 8MB)。
- 计算每个分片 SHA-256。
- 客户端请求服务端缺失分片列表,只上传未完成分片。
- 上传分片时,服务端校验分片哈希并保存到临时目录。
- 成功上传后,更新 Redis 中已上传分片状态。
-
分片合并
- 所有分片上传完成后,客户端请求服务端合并。
- 服务端按序号合并分片,并计算完整文件哈希与客户端 hash 比对。
- 合并成功后,删除临时分片和 Redis 记录。
3.2 流程图
bash
+---------------------+ +--------------------+
| 客户端 | | 服务端 |
+---------------------+ +--------------------+
| |
|---> 计算文件 SHA-256 ------>|
| |
|---> 初始化上传任务 -------->|
| 返回 uploadId |
| |
|<-- 请求缺失分片列表 -------|
| |
|---> 上传分片(chunk+hash)->|
| |
|<-- 分片上传结果 success ----|
| |
...(循环上传缺失分片)...
| |
|---> 请求合并分片 ---------->|
| |
|<-- 合并完成,返回文件路径 --|
| |3.3 前端代码
javascript
<template>
<div>
<input type="file" @change="handleFileChange" />
<button @click="uploadFile">上传文件</button>
<div v-if="progress >= 0">上传进度:{{ progress }}%</div>
</div>
</template>
<script>
import SparkMD5 from 'spark-md5'; // 用于快速计算文件或分片 hash
export default {
data() {
return {
file: null,
progress: -1,
chunkSize: 4 * 1024 * 1024, // 4MB分片
uploadId: null,
};
},
methods: {
handleFileChange(e) {
this.file = e.target.files[0];
},
// 计算文件或分片 SHA-256
async calculateFileHash(file) {
return new Promise((resolve, reject) => {
const chunkSize = 4 * 1024 * 1024;
const chunks = Math.ceil(file.size / chunkSize);
let currentChunk = 0;
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
fileReader.onload = e => {
spark.append(e.target.result);
currentChunk++;
if (currentChunk < chunks) {
loadNext();
} else {
resolve(spark.end()); // 返回 hash
}
};
fileReader.onerror = () => reject('文件读取错误');
function loadNext() {
const start = currentChunk * chunkSize;
const end = Math.min(start + chunkSize, file.size);
fileReader.readAsArrayBuffer(file.slice(start, end));
}
loadNext();
});
},
async uploadFile() {
if (!this.file) return alert('请选择文件');
// 1️⃣ 计算文件 hash
const fileHash = await this.calculateFileHash(this.file);
// 2️⃣ 初始化上传任务
const initResp = await fetch('/upload/init', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ fileName: this.file.name, fileSize: this.file.size, fileHash }),
});
const initData = await initResp.json();
this.uploadId = initData.uploadId;
const totalChunks = Math.ceil(this.file.size / this.chunkSize);
// 3️⃣ 获取未上传分片列表(断点续传)
const missingResp = await fetch(`/upload/missing?uploadId=${this.uploadId}&totalChunks=${totalChunks}`);
const missingChunks = (await missingResp.json()).missingChunks;
// 4️⃣ 上传分片
let uploaded = totalChunks - missingChunks.length;
const uploadChunk = async (index) => {
const start = index * this.chunkSize;
const end = Math.min(start + this.chunkSize, this.file.size);
const chunk = this.file.slice(start, end);
const chunkHash = await this.calculateFileHash(chunk);
const formData = new FormData();
formData.append('uploadId', this.uploadId);
formData.append('chunkIndex', index);
formData.append('chunkHash', chunkHash);
formData.append('chunk', chunk);
const resp = await fetch('/upload/chunk', { method: 'POST', body: formData });
const data = await resp.json();
if (!data.success) {
// 重试逻辑
await uploadChunk(index);
} else {
uploaded++;
this.progress = Math.floor((uploaded / totalChunks) * 100);
}
};
// 并行上传
const concurrency = 3;
const queue = missingChunks.map(i => async () => await uploadChunk(i));
const parallel = async (tasks, limit = concurrency) => {
const results = [];
const executing = [];
for (const task of tasks) {
const p = task();
results.push(p);
executing.push(p);
if (executing.length >= limit) {
await Promise.race(executing);
executing.splice(executing.findIndex(e => e === p), 1);
}
}
return Promise.all(results);
};
await parallel(queue);
// 5️⃣ 合并分片
await fetch('/upload/merge', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ uploadId: this.uploadId, fileHash }),
});
alert('上传完成!');
},
},
};
</script>这个前端代码实现了一个 分片上传 + 断点续传 + 并行上传 的文件上传器,主要功能:
- 用户选择文件
- 计算文件或分片的 hash
- 初始化上传任务(生成 uploadId,存储任务信息)
- 获取未上传的分片列表(支持断点续传)
- 并行上传缺失分片,每个分片上传前校验 hash
- 上传完成后调用合并接口,将分片合并成完整文件
- 显示上传进度
swift
文件选择
│
▼
计算文件 Hash
│
▼
初始化上传任务 (/upload/init)
│
▼
获取缺失分片 (/upload/missing)
│
▼
┌───────────────────────────────┐
│ 并行上传缺失分片 (/upload/chunk) │
│ - 分片 Hash 校验 │
│ - 上传成功更新进度 │
└───────────────────────────────┘
│
▼
合并分片 (/upload/merge)
│
▼
上传完成提示1️⃣ 初始化上传任务 (/upload/init)
前端第一次调用 /upload/init,服务端会做三件事:
- 生成唯一 uploadId(标识本次上传任务)
- 创建临时目录存储分片
- 在 Redis 里初始化上传状态
bash
Key: uploadId
Fields:
- fileName: 文件名
- fileHash: 文件 hash
- fileSize: 文件大小
- uploadedChunks: "" ← 空字符串,表示还没有上传任何分片- 这个接口不会返回哪些分片已上传,因为刚开始上传还没有分片成功。
2️⃣ 获取未上传分片 (/upload/missing)
这个接口的作用是 断点续传。
- 前端传 uploadId 和 totalChunks(文件总分片数)
- 服务端从 Redis 中读取 uploadedChunks 字段(已上传分片编号,逗号分隔)
- 然后计算哪些分片 还没有上传:
bash
missingChunks = 0..totalChunks-1 - uploadedChunks第一次上传:
-
Redis uploadedChunks 为空
-
所以 missingChunks 就是 0, 1, 2, 3, ... totalChunks-1,即全量上传
断点续传场景:
-
比如客户端上传了一部分分片,断网后重新调用 /upload/missing
-
Redis 里 uploadedChunks 记录了已上传成功的分片编号
-
/missing 接口就只返回 缺失分片编号,前端只上传缺失分片
3️⃣ 上传分片 (/upload/chunk)
每上传一个分片,前端会:
- 计算分片 hash
- POST 分片到服务端 /upload/chunk
服务端会:
- 保存分片到临时目录
- 校验分片 hash
- 如果成功,将分片编号添加到 Redis uploadedChunks 中
java
上传 chunkIndex=0 成功
Redis: uploadedChunks = "0"
上传 chunkIndex=1 成功
Redis: uploadedChunks = "0,1"4️⃣ 前端如何知道分片上传成功?
- /upload/chunk 接口返回 JSON:
bash
{ "success": true }- success = true → 分片上传成功
- success = false → 分片上传失败,需要重传
- 前端同时更新本地上传进度:
bash
uploaded++;
this.progress = Math.floor((uploaded / totalChunks) * 100);- 所以 上传成功的分片信息 主要由两部分保证:
- 服务端 Redis 记录 uploadedChunks
- 每个 /chunk 接口返回的 success
3.4 后端代码
java
@RestController
@RequestMapping("/upload")
public class UploadController {
private final String TEMP_DIR = "upload_tmp/";
private final String FINAL_DIR = "upload_final/";
@Autowired
private StringRedisTemplate redisTemplate;
/** 1.初始化上传任务 */
@PostMapping("/init")
public Map<String, Object> initUpload(@RequestBody Map<String, Object> request) {
// 1️⃣ 从客户端请求中获取文件信息
// 文件名
String fileName = (String) request.get("fileName");
// 文件整体 SHA-256
String fileHash = (String) request.get("fileHash");
// 文件大小(字节)
long fileSize = ((Number) request.get("fileSize")).longValue();
// 2️⃣ 生成本次上传任务的唯一 ID
String uploadId = UUID.randomUUID().toString();
// 3️⃣ 创建临时存放分片的目录
File dir = new File(TEMP_DIR + uploadId);
if (!dir.exists()) dir.mkdirs();
// Redis记录任务信息
redisTemplate.opsForHash().put(uploadId, "fileName", fileName);
redisTemplate.opsForHash().put(uploadId, "fileHash", fileHash);
redisTemplate.opsForHash().put(uploadId, "fileSize", String.valueOf(fileSize));
redisTemplate.opsForHash().put(uploadId, "uploadedChunks", "");
// 返回 uploadId 给客户端,后续上传分片使用
Map<String, Object> resp = new HashMap<>();
resp.put("uploadId", uploadId);
return resp;
}
/** 2.获取未上传分片 */
@GetMapping("/missing")
public Map<String, Object> getMissingChunks(@RequestParam String uploadId,
@RequestParam int totalChunks) {
// 从 Redis Hash 中获取字段 uploadedChunks,表示已成功上传的分片编号(逗号分隔)。
// 示例值可能是 "0,1,2,5",表示 0、1、2、5 分片已经上传。
String uploadedChunksStr = (String) redisTemplate.opsForHash().get(uploadId, "uploadedChunks");
Set<Integer> uploadedChunks = new HashSet<>();
if (uploadedChunksStr != null && !uploadedChunksStr.isEmpty()) {
for (String s : uploadedChunksStr.split(",")) uploadedChunks.add(Integer.parseInt(s));
}
List<Integer> missingChunks = new ArrayList<>();
for (int i = 0; i < totalChunks; i++) {
if (!uploadedChunks.contains(i)) missingChunks.add(i);
}
// 缺失分片列表
Map<String, Object> resp = new HashMap<>();
resp.put("missingChunks", missingChunks);
return resp;
}
/** 3.上传分片 */
@PostMapping("/chunk")
public Map<String, Object> uploadChunk(@RequestParam String uploadId,
@RequestParam int chunkIndex,
@RequestParam String chunkHash,
@RequestParam MultipartFile chunk) throws Exception {
File dir = new File(TEMP_DIR + uploadId);
if (!dir.exists()) dir.mkdirs();
File file = new File(dir, chunkIndex + ".part");
chunk.transferTo(file);
// 校验分片hash
String localHash = DigestUtils.sha256Hex(new FileInputStream(file));
boolean success = localHash.equalsIgnoreCase(chunkHash);
if (success) {
// 更新 Redis 已上传分片记录
String uploadedChunksStr = (String) redisTemplate.opsForHash().get(uploadId, "uploadedChunks");
Set<String> uploadedSet = new HashSet<>();
if (uploadedChunksStr != null && !uploadedChunksStr.isEmpty())
uploadedSet.addAll(Arrays.asList(uploadedChunksStr.split(",")));
uploadedSet.add(String.valueOf(chunkIndex));
redisTemplate.opsForHash().put(uploadId, "uploadedChunks", String.join(",", uploadedSet));
}
Map<String, Object> resp = new HashMap<>();
resp.put("success", success);
return resp;
}
/** 4.合并分片 */
@PostMapping("/merge")
public Map<String, Object> mergeChunks(@RequestBody Map<String, Object> request) throws Exception {
String uploadId = (String) request.get("uploadId");
String fileHash = (String) request.get("fileHash");
File dir = new File(TEMP_DIR + uploadId);
File[] chunks = dir.listFiles((d, name) -> name.endsWith(".part"));
if (chunks == null || chunks.length == 0) throw new RuntimeException("没有分片");
Arrays.sort(chunks, Comparator.comparingInt(f -> Integer.parseInt(f.getName().replace(".part", ""))));
File finalFile = new File(FINAL_DIR + uploadId + ".dat");
if (!finalFile.getParentFile().exists()) finalFile.getParentFile().mkdirs();
try (FileOutputStream fos = new FileOutputStream(finalFile)) {
for (File chunk : chunks) {
Files.copy(chunk.toPath(), fos);
}
}
// 校验完整文件hash
String mergedHash = DigestUtils.sha256Hex(new FileInputStream(finalFile));
if (!mergedHash.equalsIgnoreCase(fileHash))
throw new RuntimeException("文件合并后hash校验失败");
// 清理临时分片和Redis
for (File chunk : chunks) chunk.delete();
dir.delete();
redisTemplate.delete(uploadId);
Map<String, Object> resp = new HashMap<>();
resp.put("success", true);
resp.put("filePath", finalFile.getAbsolutePath());
return resp;
}
}Redis 存储结构,初始化上传任务
| Key (uploadId) | Type | Field | Value |
|---|---|---|---|
550e8400-e29b-41d4-a716-446655440000 |
Hash | fileName |
"myfile.zip" |
fileHash |
"abc123..." |
||
fileSize |
"104857600" |
||
uploadedChunks |
"" (空,表示还没有分片上传) |
- Key:uploadId(唯一标识一次上传任务)
- Hash Fields:
- fileName:文件名
- fileHash:整个文件的 SHA-256
- fileSize:文件大小
- uploadedChunks:已上传的分片编号,用逗号分隔,初始化为空
3.上传分片代码介绍
- 参数:
- uploadId:上传任务唯一标识,用于找到对应的临时目录和 Redis 信息。
- chunkIndex:分片序号(0、1、2...),用于存储和合并时排序。
- chunkHash:客户端计算的分片 SHA-256,用于校验分片完整性。
- chunk:MultipartFile 分片内容。
步骤解释:
- 从 Redis 获取已上传分片列表 uploadedChunks。
- 转成 Set 存储,方便添加新分片并去重。
- 将当前分片 chunkIndex 添加到 Set。
- 将 Set 再拼成逗号分隔字符串写回 Redis,更新上传状态。
- 这样客户端下次请求 /missing 接口就知道哪些分片已经上传,支持断点续传。
附录
- 撸了个多线程断点续传下载器,我从中学习到了这些知识 https://mp.weixin.qq.com/s/bI5xYq3jUtp-sviKlzHtNg
- 大规格文件的上传优化 https://juejin.cn/post/6844904155086061576