文章目录
- 介绍
- 工作原理
- 问题:如何处理hash碰撞?
- 应用
-
- [1. 缓存系统:防止缓存穿透](#1. 缓存系统:防止缓存穿透)
- [2. 数据库优化:减少磁盘 I/O](#2. 数据库优化:减少磁盘 I/O)
- [3. 网络爬虫:去重 URL](#3. 网络爬虫:去重 URL)
- [4. 垃圾邮件过滤](#4. 垃圾邮件过滤)
- 应用图解
- [最佳实践:Bloom Filter](#最佳实践:Bloom Filter)
-
- [1. 底层存储:Redis 的 String 或 Hash 结构](#1. 底层存储:Redis 的 String 或 Hash 结构)
- [2. 哈希函数:MurmurHash3](#2. 哈希函数:MurmurHash3)
- [3. 原子性保障:Lua 脚本](#3. 原子性保障:Lua 脚本)
- 小结
介绍
- 在处理海量数据时,如何快速判断一个元素是否存在于一个巨大的集合中?
- 如果,使用 HashSet、HashMap ,当数据量达到数亿甚至上百亿时,这些方法会消耗巨大的内存,性能急剧下降。
这时,布隆过滤器(Bloom Filter)闪亮登场。
- 空间效率极高
- 概率型数据结构(probabilistic data structure)
作用:
- 用于判断一个元素是否可能在一个集合中。
工作原理
流传的经典名句:不存在一定不存在,存在那不一定存在。
- 不允许漏报(False Negative):有就是有,一个不能少。
- 允许误报(False Positive):狼来了 是可以有的事情。

为什么会导致这种原因?
- 先说结论(图解):
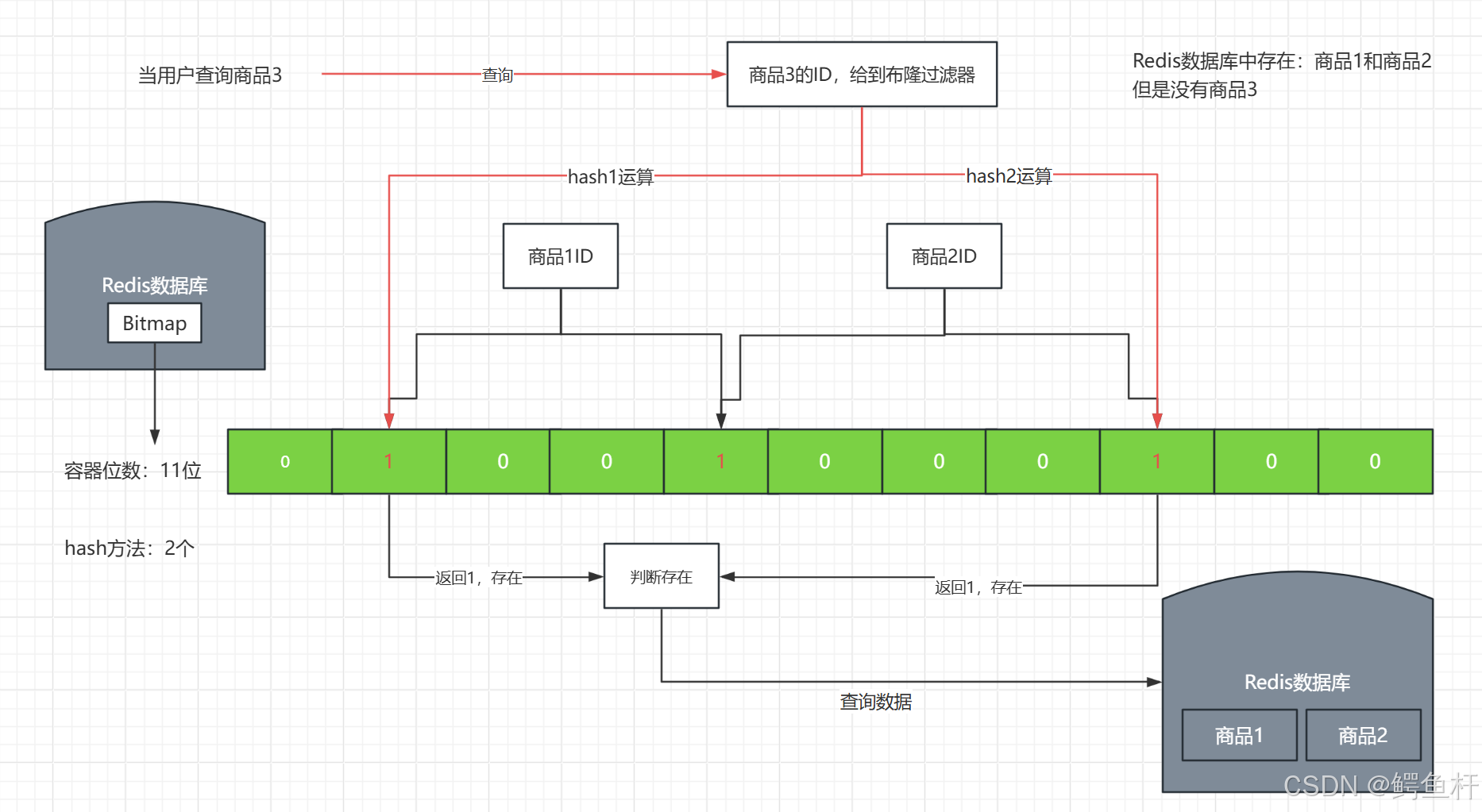
前提:
- 在布隆过滤器中
- 预先将商品1ID和商品2ID,多次hash运算的结果,Redis的Bitmap中相应位:1、4、8 都 置1。
- 巧合的是,当商品3ID经过多次hash运算后,得到的结果,在Bitmap:1、8 置1
- 此时,Bitmap中位置1、8,因为商品1和商品2置为1了。布隆过滤器会判断为存在,进而去数据库中查询数据。
- 实际上,数据库中并没有商品3的数据。
布隆过滤器由两个核心组件构成:
- 一个长度为 m 的位数组(Bit Array):初始所有位为 0。
- redis中的 Bitmap 、Java中 BitSet 等
- k 个独立的哈希函数:每个函数将输入映射到位数组的一个位置
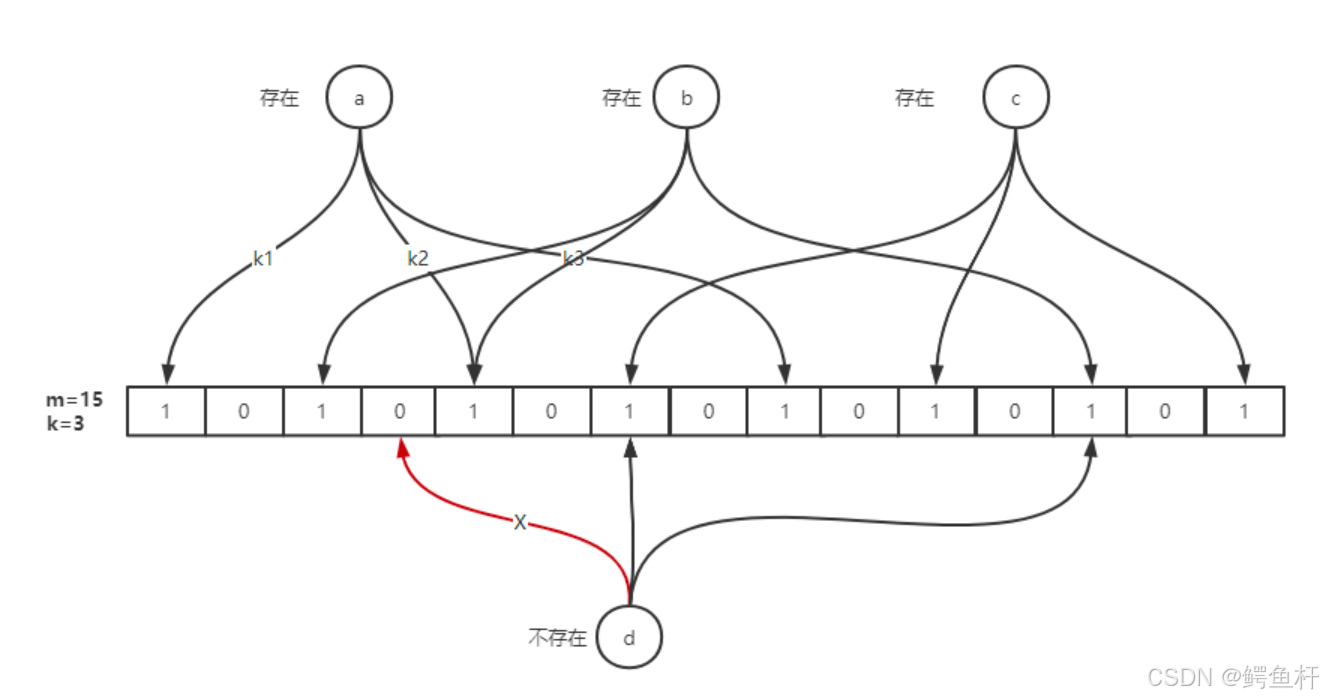
1、添加元素
当向布隆过滤器中添加一个元素时:
- 使用 k 个哈希函数对该元素进行哈希。
- 得到 k 个位置索引。
- 将这 k 个位置的值都设置为 1。
2、查询元素
当查询一个元素是否"可能存在":
- 使用相同的 k 个哈希函数计算其位置。
- 检查这些位置的值:
- 如果所有位置都是 1 → 返回"存在"。
- 如果任一位置是 0 → 返回"一定不存在"。
问题:如何处理hash碰撞?
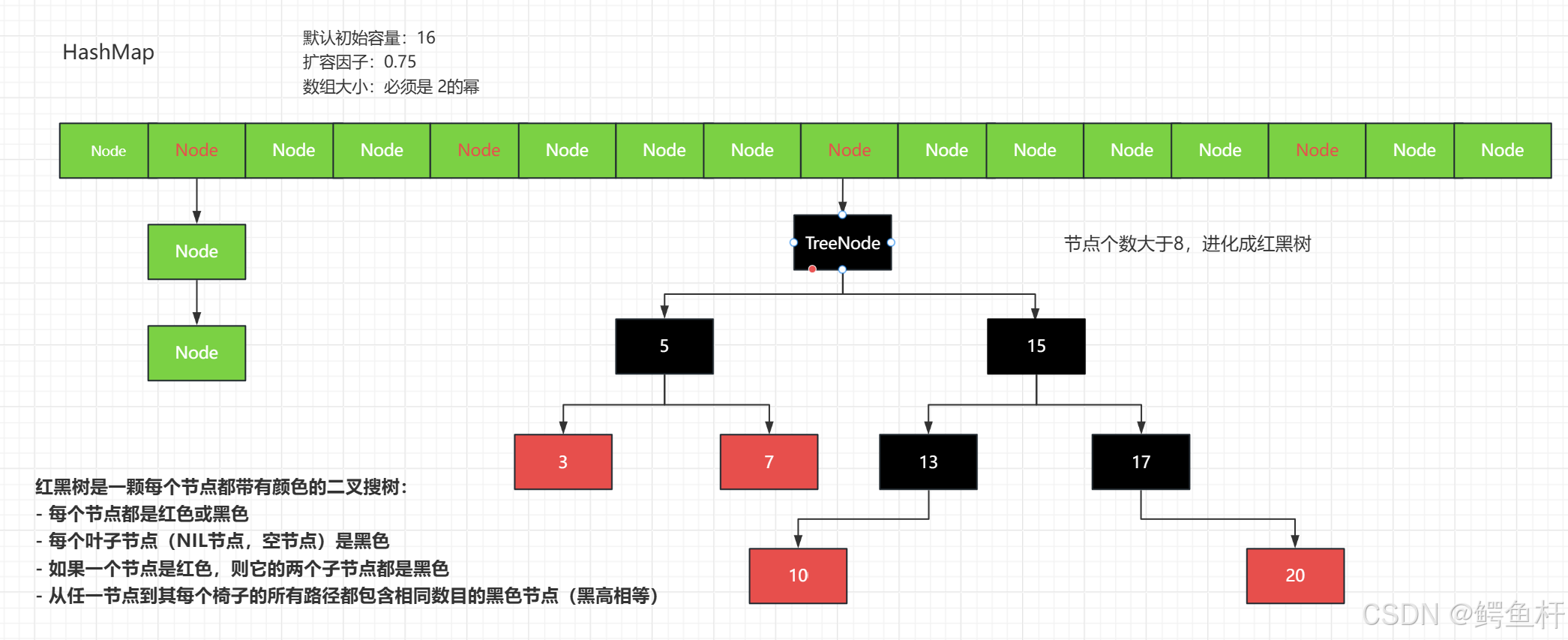
了解Java中HashMap处理哈希碰撞
哈希碰撞:
- 当多个键值对的 hashCode() 计算出的索引位置相同时(即发生哈希碰撞),HashMap 会通过以下机制来存储 和 查找 数据。
- 开放寻址法:碰撞了,找新的位置。(打不过,就跑)
- 拉链法:碰撞了,跟在后面。(打不过,就加入)
反正就是打不过(碰撞了),两种策略去解决。
不过,开放寻址法无法优化 ,当碰撞发生时, 数组 没有空间,
- 无法添加数据。
拉链法 呢,当碰撞发生时, 数组 有无空间无所谓。
- 反正我碰撞了,我就要加入,具体加哪里呢。你拉出个链表,将碰撞的数据放进去。有点子嚣张。
优化:
- 在 JDK 8 之后,HashMap 处理哈希碰撞(Hash Collision)的核心策略是:
- 数组 + 链表 + 红黑树(自平衡的二叉查找树)。
- 阈值(边界值)> 8,且数组长度大于64,才会将链表转为红黑树,高效查询。
- 还采用:尾插入 的方法,不用移动其他节点的指针,相当方便。主要还是向性能看齐。
具体描述,如下图所示:
布隆过滤器如何处理hash碰撞?
本来,布隆过滤器是为了节省空间做大事。如果它要是使用以上的方法,那可就出不了名了。
那它要使用什么办法呢?
- 布隆过滤器一想:既然hash计算一次它容易碰撞重复,那我就多计算几次,最后在将它们的结果汇总判断。
- 多个hash方法计算出多个位置,汇总判断是否存在
- 多个位置都是1,则存在。
- 有一个为0,则不存在。
如何控制误报率?
- 既然一定会产生误报,那如何控制误报率呢?
布隆过滤器的性能取决于三个参数:
n:预计元素数量
m:位数组长度
k:哈希函数数量
在给定 n 和期望误报率 p 时,可通过公式计算最优参数:(知道就可)

Java实现布隆过滤器
java
import java.util.BitSet;
import java.security.MessageDigest;
public class BloomFilter {
private BitSet bitSet; // 位数组,存储0和1
private int size; // 位数组的大小
private int[] seeds = {3, 5, 7, 11, 13}; // 5 个哈希函数的"种子"
// 创建一个长度为 size 的 BitSet,初始所有位都是 false(即 0)。
public BloomFilter(int size) {
this.size = size;
this.bitSet = new BitSet(size);
}
// 添加
public void add(String value) {
// 遍历seeds种子,不同种子产生不同哈希结果
for (int seed : seeds) {
HashFunction hash = new HashFunction(size, seed);
bitSet.set(hash.hash(value), true);
}
}
// 判断一个字符串是否"可能"存在于集合中。
public boolean mightContain(String value) {
for (int seed : seeds) {
HashFunction hash = new HashFunction(size, seed);
if (!bitSet.get(hash.hash(value))) {
return false; // 一定不存在
}
}
return true; // 可能存在
}
// 实现一个简单的哈希函数,将字符串映射到位数组的一个索引上。
static class HashFunction {
private int cap;
private int seed;
public HashFunction(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
//
public int hash(String value) {
int result = 0;
for (int i = 0; i < value.length(); i++) {
// 种子 * 每次遍历的返回值 + 字符串的字符位置
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}应用
1. 缓存系统:防止缓存穿透
- 在 Redis 等缓存系统中,如果黑客频繁查询不存在的 key,会导致大量请求打到数据库。
解决方案:优秀实现Redisson中的 Bloom Filter。
- 将所有合法 key 加入布隆过滤器。
- 查询前,先过布隆过滤器:
- 若返回"不存在" → 直接返回,不查数据库。
- 若返回"可能存在" → 查缓存 → 查数据库。
2. 数据库优化:减少磁盘 I/O
- 数据库(如 LevelDB、Cassandra)用布隆过滤器判断某个 key 是否可能存在于某个 SSTable 文件中,避免不必要的磁盘读取。
3. 网络爬虫:去重 URL
- 爬虫在抓取网页时,用布隆过滤器记录已抓取的 URL,避免重复抓取,节省带宽和资源。
4. 垃圾邮件过滤
- 将已知的垃圾邮件地址加入布隆过滤器,快速判断新邮件是否可能是垃圾邮件。
应用图解
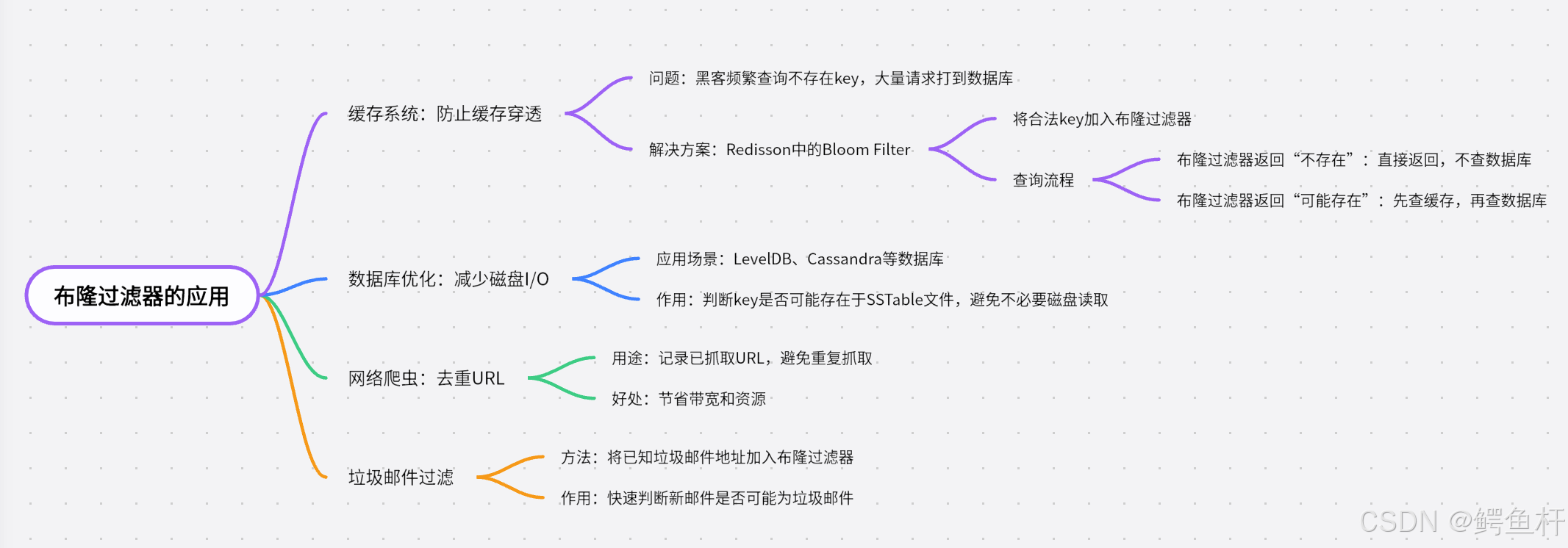
最佳实践:Bloom Filter
Redisson:基于 Redis 的 Java 客户端
- 不仅封装了 Redis 的基本操作,还提供了许多高级分布式数据结构和工具,其中就包括 分布式布隆过滤器(Bloom Filter)。
1. 底层存储:Redis 的 String 或 Hash 结构
Redisson 使用 Redis 的 位图(Bitmap) 功能来模拟布隆过滤器的位数组。
每个布隆过滤器对应一个 Redis Key。
这个 Key 的值是一个大的位数组(bit array),每一位代表一个"槽"。
Redis 的 SETBIT 和 GETBIT 命令用于设置和读取位。
2. 哈希函数:MurmurHash3
Redisson 使用 MurmurHash3 算法作为基础哈希函数。
只需一次计算,即可生成多个不同的哈希值(通过种子偏移)。
高效且分布均匀,适合布隆过滤器场景。
3. 原子性保障:Lua 脚本
所有操作(添加、查询)都通过 Redis 的 Lua 脚本执行,确保原子性。
java
// 可抽取为配置文件
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
// 获取布隆过滤器实例
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("user:exists");
// 初始化:预计100万个用户,允许3%误判率
bloomFilter.tryInit(100000L, 0.03);
// 添加元素
bloomFilter.add("user123");
bloomFilter.add("user456");
// 判断是否存在
boolean mightExist = bloomFilter.contains("user123"); // true
boolean definitelyNotExist = bloomFilter.contains("user999"); // false
redisson.shutdown();小结
- 布隆过滤器是一种用空间换时间 、并接受一定错误率的巧妙设计。
- 它不能告诉你"一定存在",但可以非常高效地告诉你"一定不存在"。
各位再见!这里是 鳄鱼杆的空间 ,钓......鳄鱼的杆儿!
期待下次再会!
愿你的每一次垂钓之旅都能满载而归。
