目录
文章目录
- 目录
- Megatron-LM
- 软件架构
- 安装部署
- 准备数据集
- 训练主脚本
- 训练配置脚本
- 执行训练
- 持续观测
- 导出模型
- [监控 TFLOPS](#监控 TFLOPS)
- [持续预训练(Continual Pretraining)](#持续预训练(Continual Pretraining))
- [Megatron-LM & LLaMA-Factory](#Megatron-LM & LLaMA-Factory)
- [Megatron-LM & DeepSpeed](#Megatron-LM & DeepSpeed)
- 参考文档
Megatron-LM
Megatron-LM 最初于 2019 年发布,是由 NVIDIA 开发的 Transformer 大模型高效训练框架。它专为数千亿甚至数万亿参数的模型二设计,具有高度可扩展性和灵活的并行策略。Megatron-LM 已经成为许多大语言模型预训练任务的首选框架。
软件架构
- Megatron-LM:研究导向的训练框架和示例。
- Megatron-Core:模块化的核心库,提供可组合的函数接口。
bash
┌─────────────────────────────────────────────────────────────┐
│ 应用层 (Application Layer) │
├─────────────────────────────────────────────────────────────┤
│ pretrain_gpt.py │ pretrain_bert.py │ pretrain_t5.py │
├─────────────────────────────────────────────────────────────┤
│ Megatron-LM 训练框架层 │
├─────────────────────────────────────────────────────────────┤
│ training/ │ checkpointing/ │ arguments.py │
├─────────────────────────────────────────────────────────────┤
│ Megatron-Core 核心层 │
├─────────────────────────────────────────────────────────────┤
│ models/ │ transformer/ │ parallel_state/ │
├─────────────────────────────────────────────────────────────┤
│ 底层优化层 (Optimization Layer) │
├─────────────────────────────────────────────────────────────┤
│ CUDA Kernels │ NCCL Communication │ Memory Management│
└─────────────────────────────────────────────────────────────┘安装部署
安装 PyTorch:使用 NVIDIA 的官方镜像,里面安装了训练框架所需要的大部分软件库:
- CUDA 12.6+:一定需要使用 CUDA12,Flash Attention 库目前只支持 CUDA12。使用 CUDA13 会导致 Flash Attention 用不了。
- PyTorch 2.6+
- NCCL 集合通讯库
- OpenMPI 消息传递接口库
- cuDNN CUDA 深度神经网络库
- Transformer Engine:FP8 混合精度支持
- Flash Attention:高效注意力机制
- Python 3.11
- 基础 Python 包:transformers、datasets、accelerate、tensorboard、wandb 等
bash
$ docker pull nvcr.io/nvidia/pytorch:25.03-py3
$ cd workspace
$ docker run -d --network=host --restart=always --name=megatron-dev \
--gpus=all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v "$PWD":/workspace -w /workspace \
nvcr.io/nvidia/pytorch:25.03-py3 \
tail -f /dev/null
$ docker exec -it -u root megatron-dev bash注意,多机训练的时候,启动容器时不能指定 --net host,会导致 NCCL 通信时报错。
安装 Megatron-LM:
bash
# 1. 进入工作目录
cd /workspace
# 2. 克隆 Megatron-LM 仓库(仅需执行一次)
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
# 3. 检出到推荐的稳定版本
git checkout "core_r0.12.0"
pip install -e .
# 4. 将 megatron 路径添加到 python path
echo 'export PYTHONPATH="/workspace/Megatron-LM:$PYTHONPATH"' >> ~/.bashrc
source ~/.bashrc环境检查:
bash
# 检查 GPU
$ nvidia-smi
# 检查 CUDA
$ nvcc --version
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0
# 检查 PyTorch 和 CUDA 兼容性
$ python -c "import torch; print(f'PyTorch: {torch.__version__}, CUDA: {torch.version.cuda}, GPU Available: {torch.cuda.is_available()}')"
PyTorch: 2.7.0a0+7c8ec84dab.nv25.03, CUDA: 12.8, GPU Available: True
# 检查 Megatron-LM
$ python -c "import megatron; print('Megatron-LM imported successfully')"
Megatron-LM imported successfully准备数据集
下载数据集:支持 txt、json、jsonl 等格式。
python
from datasets import load_dataset
train_data = load_dataset('codeparrot/codeparrot-clean-train', split='train')
train_data.to_json("codeparrot_data.json", lines=True)下载词汇表和合并表:
bash
# 创建目录(若不存在)
mkdir -p /workspace/tokenizers/GPT2_tokenizer/
# 下载官方 GPT2 vocab.json
curl -o /workspace/tokenizers/GPT2_tokenizer/vocab.json https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json
# 下载官方 merges.txt(确保配套)
curl -o /workspace/tokenizers/GPT2_tokenizer/merges.txt https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt
# 验证下载后的文件
python -c "
import json
with open('/workspace/tokenizers/GPT2_tokenizer/vocab.json', 'r') as f:
json.load(f)
print('✅ 官方 vocab.json 格式验证通过')
"数据预处理:Megatron-LM 提供了 preprocess_data.py 预处理脚本,将原始文本数据转换为 Megatron-LM 所需的 token 化二进制格式,支持高效加载。脚本使用了 HuggingFace transformers 或其他分词器(如 GPT-2 的 BPE)对文本进行分词。预处理后会生成二进制文件(如 my_dataset_text_document),用于训练。
bash
python tools/preprocess_data.py \
--input /workspace/codeparrot/codeparrot_data.json \
--output-prefix /workspace/codeparrot/ \
--vocab-file /workspace/tokenizers/GPT2_tokenizer/vocab.json \
--merge-file /workspace/tokenizers/GPT2_tokenizer/merges.txt \
--tokenizer-type GPT2BPETokenizer \
--dataset-impl mmap \
--json-keys content \
--append-eod \
--workers 32- --input:输入文本文件。
- --vocab-file 和 --merge-file:分词器的词汇表和合并规则(可从 Hugging Face 下载)。
- --dataset-impl mmap:使用内存映射格式,适合大数据集。
- --workers:并行处理的工作线程数。
- --append-eod:在每个文本块末尾添加结束标记(End Of Document)。
训练主脚本
pretrain_gpt.py 是 Megatron-LM 的主要训练脚本,负责配置模型、加载数据、执行前向和反向传播、优化参数以及管理分布式训练。支持一下配置参数:
模型结构:Megatron-LM 默认支持 GPT、BERT、T5 等模型。以 GPT 为例,模型参数包括。
- --num-layers:Transformer 层数。
- --hidden-size:隐藏层维度。
- --num-attention-heads:注意力头数。
- --seq-length:最大序列长度。
- --max-position-embeddings:序列长度和位置嵌入长度。
一个小型 GPT-2 模型的结构配置如下:
bash
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--seq-length 1024并行策略:
- --tensor-model-parallel-size:张量并行的 GPU 数(每个节点的 GPU 数需整除此值)。
- --pipeline-model-parallel-size:流水线并行的阶段数。
- --num-gpus-per-node:每个节点的 GPU 数。
- --world-size:总 GPU 数(节点数 × 每节点 GPU 数)。
示例:8 个 GPU,4 张量并行,2 流水线并行:
bash
--tensor-model-parallel-size 4 \
--pipeline-model-parallel-size 2训练超参数:
- --micro-batch-size:每个 GPU 的批次大小(受内存限制)。
- --global-batch-size:全局批次大小(所有 GPU 的总和)。
- --weight-decay 0.1:权重衰减系数。
- --clip-grad 1.0:梯度裁剪阈值。
- --lr 0.00015:学习率
- --min-lr 1.0e-5:最小学习率
- --lr-decay-style cosine:余弦退火
- --lr-decay-iters 2000
- --lr-warmup-iters 32000:预热步骤
- --adam-beta1 和 --adam-beta2:Adam 优化器的参数。
- --fp16:启用半精度训练。
- --bf16:启用半精度训练。
bash
--micro-batch-size 4 \
--global-batch-size 64 \
--lr 1.5e-4 \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--fp16训练流程控制:
- --train-iters:总训练步数。
- --data-path:预处理数据集的路径。
- --save 和 --load:检查点保存和加载路径。
- --log-interval 100:日志间隔。
- --save-interval 10000:Checkpoint 间隔。
- --eval-interval:评估间隔。
- --distributed-backend:分布式训练的后端,通常使用 NCCL。
单节点训练示例:
bash
python -m torch.distributed.launch --nproc_per_node 8 pretrain_gpt.py \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--seq-length 1024 \
--tensor-model-parallel-size 4 \
--pipeline-model-parallel-size 2 \
--micro-batch-size 4 \
--global-batch-size 64 \
--lr 1.5e-4 \
--train-iters 100000 \
--data-path /data/my_dataset_text_document \
--vocab-file gpt2-vocab.json \
--merge-file gpt2-merges.txt \
--save /checkpoints/gpt_model \
--load /checkpoints/gpt_model \
--fp16 \
--tensorboard-dir /logs/tensorboard多节点训练示例:使用 torch.distributed.launch 或 SLURM 调度器。
bash
export MASTER_ADDR=<主节点 IP>
export MASTER_PORT=6000
export WORLD_SIZE=16 # 总 GPU 数
export NODE_RANK=<当前节点 ID>
export GPUS_PER_NODE=8
python -m torch.distributed.launch --nproc_per_node 8 \
--nnodes $WORLD_SIZE \
--node_rank $NODE_RANK \ # 在每个节点上运行相同的命令,需要修改 --node-rank
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT \
pretrain_gpt.py \
<其他参数同上>训练配置脚本
训练主程序通过使用 bash 脚本组装环境变量,使其在 Kubernetes 等容器环境中可以灵活的被控制。
bash
# 禁用 Dynamo/Inductor,使用 eager 模式
export TORCH_COMPILE_DISABLE=1
export TORCHINDUCTOR_DISABLE=1
export TORCH_DYNAMO_DISABLE=1
GPUS_PER_NODE=1
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE
--nnodes $NNODES
--node_rank $NODE_RANK
--master_addr $MASTER_ADDR
--master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/gpt2
VOCAB_FILE=/workspace/tokenizers/GPT2_tokenizer/vocab.json
MERGE_FILE=/workspace/tokenizers/GPT2_tokenizer/merges.txt
DATA_PATH=/workspace/codeparrot/codeparrot_content_document
GPT_ARGS="--num-layers 12
--hidden-size 768
--num-attention-heads 12
--seq-length 1024
--max-position-embeddings 1024
--micro-batch-size 12
--global-batch-size 192
--lr 0.0005
--train-iters 150000
--lr-decay-iters 150000
--lr-decay-style cosine
--lr-warmup-iters 2000
--weight-decay .1
--adam-beta2 .999
--fp16
--log-interval 10
--save-interval 2000
--eval-interval 200
--eval-iters 10
--train-iters 400"
TENSORBOARD_ARGS="--tensorboard-dir experiments/gpt2/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS执行训练
执行日志:
bash
$ bash train.sh
/usr/local/lib/python3.12/dist-packages/modelopt/torch/utils/import_utils.py:31: UserWarning: Failed to import apex plugin due to: AttributeError("module 'transformers.modeling_utils' has no attribute 'Conv1D'"). You may ignore this warning if you do not need this plugin.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/modelopt/torch/utils/import_utils.py:31: UserWarning: Failed to import huggingface plugin due to: AttributeError("module 'transformers.modeling_utils' has no attribute 'Conv1D'"). You may ignore this warning if you do not need this plugin.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/modelopt/torch/utils/import_utils.py:31: UserWarning: Failed to import megatron plugin due to: AttributeError("module 'transformers.modeling_utils' has no attribute 'Conv1D'"). You may ignore this warning if you do not need this plugin.
warnings.warn(
using world size: 1, data-parallel size: 1, context-parallel size: 1, hierarchical context-parallel sizes: Nonetensor-model-parallel size: 1, encoder-tensor-model-parallel size: 0, pipeline-model-parallel size: 1, encoder-pipeline-model-parallel size: 0
Number of virtual stages per pipeline stage: None
WARNING: Setting args.check_for_nan_in_loss_and_grad to False since dynamic loss scaling is being used
using torch.float16 for parameters ...
------------------------ arguments ------------------------
account_for_embedding_in_pipeline_split ......... False
account_for_loss_in_pipeline_split .............. False
accumulate_allreduce_grads_in_fp32 .............. False
adam_beta1 ...................................... 0.9
adam_beta2 ...................................... 0.999
adam_eps ........................................ 1e-08
add_bias_linear ................................. True
add_position_embedding .......................... True
add_qkv_bias .................................... True
adlr_autoresume ................................. False
adlr_autoresume_interval ........................ 1000
align_grad_reduce ............................... True
align_param_gather .............................. False
app_tag_run_name ................................ None
app_tag_run_version ............................. 0.0.0
apply_layernorm_1p .............................. False
apply_query_key_layer_scaling ................... False
apply_residual_connection_post_layernorm ........ False
apply_rope_fusion ............................... False
async_save ...................................... None
async_tensor_model_parallel_allreduce ........... True
attention_backend ............................... AttnBackend.auto
attention_dropout ............................... 0.1
attention_softmax_in_fp32 ....................... False
auto_detect_ckpt_format ......................... False
barrier_with_L1_time ............................ True
bert_binary_head ................................ True
bert_embedder_type .............................. megatron
bert_load ....................................... None
bf16 ............................................ False
bias_dropout_fusion ............................. True
bias_gelu_fusion ................................ True
bias_swiglu_fusion .............................. True
biencoder_projection_dim ........................ 0
biencoder_shared_query_context_model ............ False
block_data_path ................................. None
calc_ft_timeouts ................................ False
calculate_per_token_loss ........................ False
check_for_large_grads ........................... False
check_for_nan_in_loss_and_grad .................. False
check_for_spiky_loss ............................ False
check_weight_hash_across_dp_replicas_interval ... None
ckpt_assume_constant_structure .................. False
ckpt_convert_format ............................. None
ckpt_convert_save ............................... None
ckpt_convert_update_legacy_dist_opt_format ...... False
ckpt_format ..................................... torch_dist
ckpt_fully_parallel_load ........................ False
ckpt_fully_parallel_save ........................ True
ckpt_fully_parallel_save_deprecated ............. False
ckpt_step ....................................... None
classes_fraction ................................ 1.0
clip_grad ....................................... 1.0
clone_scatter_output_in_embedding ............... True
config_logger_dir ...............................
consumed_train_samples .......................... 0
consumed_valid_samples .......................... 0
context_parallel_size ........................... 1
cp_comm_type .................................... ['p2p']
create_attention_mask_in_dataloader ............. True
cross_entropy_fusion_impl ....................... native
cross_entropy_loss_fusion ....................... False
cuda_graph_scope ................................ full
cuda_graph_warmup_steps ......................... 3
data_args_path .................................. None
data_cache_path ................................. None
data_parallel_random_init ....................... False
data_parallel_sharding_strategy ................. no_shard
data_parallel_size .............................. 1
data_path ....................................... ['/workspace/codeparrot/codeparrot_content_document']
data_per_class_fraction ......................... 1.0
data_sharding ................................... True
dataloader_type ................................. single
ddp_average_in_collective ....................... False
ddp_bucket_size ................................. None
ddp_num_buckets ................................. None
ddp_pad_buckets_for_high_nccl_busbw ............. False
decoder_first_pipeline_num_layers ............... None
decoder_last_pipeline_num_layers ................ None
decoder_num_layers .............................. None
decoder_seq_length .............................. None
decoupled_lr .................................... None
decoupled_min_lr ................................ None
decrease_batch_size_if_needed ................... False
defer_embedding_wgrad_compute ................... False
deprecated_use_mcore_models ..................... False
deterministic_mode .............................. False
dino_bottleneck_size ............................ 256
dino_freeze_last_layer .......................... 1
dino_head_hidden_size ........................... 2048
dino_local_crops_number ......................... 10
dino_local_img_size ............................. 96
dino_norm_last_layer ............................ False
dino_teacher_temp ............................... 0.07
dino_warmup_teacher_temp ........................ 0.04
dino_warmup_teacher_temp_epochs ................. 30
disable_bf16_reduced_precision_matmul ........... False
disable_straggler_on_startup .................... False
dist_ckpt_format_deprecated ..................... None
dist_ckpt_strictness ............................ assume_ok_unexpected
distribute_saved_activations .................... False
distributed_backend ............................. nccl
distributed_timeout_minutes ..................... 10
embedding_path .................................. None
empty_unused_memory_level ....................... 0
enable_cuda_graph ............................... False
enable_ft_package ............................... False
enable_gloo_process_groups ...................... True
enable_one_logger ............................... True
encoder_num_layers .............................. 12
encoder_pipeline_model_parallel_size ............ 0
encoder_seq_length .............................. 1024
encoder_tensor_model_parallel_size .............. 0
end_weight_decay ................................ 0.1
eod_mask_loss ................................... False
error_injection_rate ............................ 0
error_injection_type ............................ transient_error
eval_interval ................................... 200
eval_iters ...................................... 10
evidence_data_path .............................. None
exit_duration_in_mins ........................... None
exit_interval ................................... None
exit_on_missing_checkpoint ...................... False
exit_signal_handler ............................. False
exp_avg_dtype ................................... torch.float32
exp_avg_sq_dtype ................................ torch.float32
expert_model_parallel_size ...................... 1
expert_tensor_parallel_size ..................... 1
external_cuda_graph ............................. False
ffn_hidden_size ................................. 3072
finetune ........................................ False
first_last_layers_bf16 .......................... False
flash_decode .................................... False
fp16 ............................................ True
fp16_lm_cross_entropy ........................... False
fp32_residual_connection ........................ False
fp8 ............................................. None
fp8_amax_compute_algo ........................... most_recent
fp8_amax_history_len ............................ 1
fp8_interval .................................... 1
fp8_margin ...................................... 0
fp8_param_gather ................................ False
fp8_recipe ...................................... delayed
fp8_wgrad ....................................... True
global_batch_size ............................... 192
grad_reduce_in_bf16 ............................. False
gradient_accumulation_fusion .................... True
gradient_reduce_div_fusion ...................... True
group_query_attention ........................... False
head_lr_mult .................................... 1.0
heterogeneous_layers_config_encoded_json ........ None
heterogeneous_layers_config_path ................ None
hidden_dropout .................................. 0.1
hidden_size ..................................... 768
hierarchical_context_parallel_sizes ............. None
hybrid_attention_ratio .......................... 0.0
hybrid_mlp_ratio ................................ 0.0
hybrid_override_pattern ......................... None
hysteresis ...................................... 2
ict_head_size ................................... None
ict_load ........................................ None
img_h ........................................... 224
img_w ........................................... 224
indexer_batch_size .............................. 128
indexer_log_interval ............................ 1000
inference_batch_times_seqlen_threshold .......... -1
inference_dynamic_batching ...................... False
inference_dynamic_batching_buffer_guaranteed_fraction 0.2
inference_dynamic_batching_buffer_overflow_factor None
inference_dynamic_batching_buffer_size_gb ....... 40.0
inference_dynamic_batching_max_requests_override None
inference_dynamic_batching_max_tokens_override .. None
inference_max_batch_size ........................ 8
inference_max_seq_length ........................ 2560
inference_rng_tracker ........................... False
init_method_std ................................. 0.02
init_method_xavier_uniform ...................... False
init_model_with_meta_device ..................... False
initial_loss_scale .............................. 4294967296
is_hybrid_model ................................. False
iter_per_epoch .................................. 1250
iterations_to_skip .............................. []
keep_fp8_transpose_cache_when_using_custom_fsdp . False
kv_channels ..................................... 64
kv_lora_rank .................................... 32
lazy_mpu_init ................................... None
load ............................................ /workspace/Megatron-LM/experiments/gpt2
local_rank ...................................... 0
log_interval .................................... 10
log_loss_scale_to_tensorboard ................... True
log_memory_to_tensorboard ....................... False
log_num_zeros_in_grad ........................... False
log_params_norm ................................. False
log_progress .................................... False
log_straggler ................................... False
log_throughput .................................. False
log_timers_to_tensorboard ....................... False
log_validation_ppl_to_tensorboard ............... False
log_world_size_to_tensorboard ................... False
logging_level ................................... None
loss_scale ...................................... None
loss_scale_window ............................... 1000
lr .............................................. 0.0005
lr_decay_iters .................................. 150000
lr_decay_samples ................................ None
lr_decay_style .................................. cosine
lr_warmup_fraction .............................. None
lr_warmup_init .................................. 0.0
lr_warmup_iters ................................. 2000
lr_warmup_samples ............................... 0
lr_wsd_decay_iters .............................. None
lr_wsd_decay_samples ............................ None
lr_wsd_decay_style .............................. exponential
main_grads_dtype ................................ torch.float32
main_params_dtype ............................... torch.float32
make_vocab_size_divisible_by .................... 128
mamba_head_dim .................................. 64
mamba_num_groups ................................ 8
mamba_state_dim ................................. 128
manual_gc ....................................... False
manual_gc_eval .................................. True
manual_gc_interval .............................. 0
mask_factor ..................................... 1.0
mask_prob ....................................... 0.15
mask_type ....................................... random
masked_softmax_fusion ........................... True
max_position_embeddings ......................... 1024
max_tokens_to_oom ............................... 12000
memory_snapshot_path ............................ snapshot.pickle
merge_file ...................................... /workspace/tokenizers/GPT2_tokenizer/merges.txt
micro_batch_size ................................ 12
microbatch_group_size_per_vp_stage .............. None
min_loss_scale .................................. 1.0
min_lr .......................................... 0.0
mmap_bin_files .................................. True
mock_data ....................................... False
moe_aux_loss_coeff .............................. 0.0
moe_enable_deepep ............................... False
moe_expert_capacity_factor ...................... None
moe_extended_tp ................................. False
moe_ffn_hidden_size ............................. 3072
moe_grouped_gemm ................................ False
moe_input_jitter_eps ............................ None
moe_layer_freq .................................. 1
moe_layer_recompute ............................. False
moe_pad_expert_input_to_capacity ................ False
moe_per_layer_logging ........................... False
moe_permute_fusion .............................. False
moe_router_bias_update_rate ..................... 0.001
moe_router_dtype ................................ None
moe_router_enable_expert_bias ................... False
moe_router_group_topk ........................... None
moe_router_load_balancing_type .................. aux_loss
moe_router_num_groups ........................... None
moe_router_pre_softmax .......................... False
moe_router_score_function ....................... softmax
moe_router_topk ................................. 2
moe_router_topk_scaling_factor .................. None
moe_shared_expert_intermediate_size ............. None
moe_shared_expert_overlap ....................... False
moe_token_dispatcher_type ....................... allgather
moe_token_drop_policy ........................... probs
moe_use_legacy_grouped_gemm ..................... False
moe_use_upcycling ............................... False
moe_z_loss_coeff ................................ None
mrope_section ................................... None
mscale .......................................... 1.0
mscale_all_dim .................................. 1.0
mtp_loss_scaling_factor ......................... 0.1
mtp_num_layers .................................. None
multi_latent_attention .......................... False
nccl_communicator_config_path ................... None
no_load_optim ................................... None
no_load_rng ..................................... None
no_persist_layer_norm ........................... False
no_save_optim ................................... None
no_save_rng ..................................... None
non_persistent_ckpt_type ........................ None
non_persistent_global_ckpt_dir .................. None
non_persistent_local_ckpt_algo .................. fully_parallel
non_persistent_local_ckpt_dir ................... None
non_persistent_save_interval .................... None
norm_epsilon .................................... 1e-05
normalization ................................... LayerNorm
num_attention_heads ............................. 12
num_channels .................................... 3
num_classes ..................................... 1000
num_dataset_builder_threads ..................... 1
num_distributed_optimizer_instances ............. 1
num_experts ..................................... None
num_layers ...................................... 12
num_layers_at_end_in_bf16 ....................... 1
num_layers_at_start_in_bf16 ..................... 1
num_layers_per_virtual_pipeline_stage ........... None
num_query_groups ................................ 1
num_virtual_stages_per_pipeline_rank ............ None
num_workers ..................................... 2
one_logger_async ................................ False
one_logger_project .............................. megatron-lm
one_logger_run_name ............................. None
onnx_safe ....................................... None
openai_gelu ..................................... False
optimizer ....................................... adam
optimizer_cpu_offload ........................... False
optimizer_offload_fraction ...................... 1.0
output_bert_embeddings .......................... False
overlap_cpu_optimizer_d2h_h2d ................... False
overlap_grad_reduce ............................. False
overlap_p2p_comm ................................ False
overlap_p2p_comm_warmup_flush ................... False
overlap_param_gather ............................ False
overlap_param_gather_with_optimizer_step ........ False
override_opt_param_scheduler .................... False
params_dtype .................................... torch.float16
patch_dim ....................................... 16
per_split_data_args_path ........................ None
perform_initialization .......................... True
pin_cpu_grads ................................... True
pin_cpu_params .................................. True
pipeline_model_parallel_comm_backend ............ None
pipeline_model_parallel_size .................... 1
pipeline_model_parallel_split_rank .............. None
position_embedding_type ......................... learned_absolute
pretrained_checkpoint ........................... None
profile ......................................... False
profile_ranks ................................... [0]
profile_step_end ................................ 12
profile_step_start .............................. 10
q_lora_rank ..................................... None
qk_head_dim ..................................... 128
qk_layernorm .................................... False
qk_pos_emb_head_dim ............................. 64
query_in_block_prob ............................. 0.1
rampup_batch_size ............................... None
rank ............................................ 0
recompute_granularity ........................... None
recompute_method ................................ None
recompute_modules ............................... None
recompute_num_layers ............................ None
record_memory_history ........................... False
relative_attention_max_distance ................. 128
relative_attention_num_buckets .................. 32
replication ..................................... False
replication_factor .............................. 2
replication_jump ................................ None
rerun_mode ...................................... disabled
reset_attention_mask ............................ False
reset_position_ids .............................. False
result_rejected_tracker_filename ................ None
retriever_report_topk_accuracies ................ []
retriever_score_scaling ......................... False
retriever_seq_length ............................ 256
retro_add_retriever ............................. False
retro_attention_gate ............................ 1
retro_cyclic_train_iters ........................ None
retro_encoder_attention_dropout ................. 0.1
retro_encoder_hidden_dropout .................... 0.1
retro_encoder_layers ............................ 2
retro_num_neighbors ............................. 2
retro_num_retrieved_chunks ...................... 2
retro_project_dir ............................... None
retro_verify_neighbor_count ..................... True
rope_scaling_factor ............................. 8.0
rotary_base ..................................... 10000
rotary_interleaved .............................. False
rotary_percent .................................. 1.0
rotary_scaling_factor ........................... 1.0
rotary_seq_len_interpolation_factor ............. None
run_workload_inspector_server ................... False
s3_cache_path ................................... None
sample_rate ..................................... 1.0
save ............................................ /workspace/Megatron-LM/experiments/gpt2
save_interval ................................... 2000
scatter_gather_tensors_in_pipeline .............. True
seed ............................................ 1234
seq_length ...................................... 1024
sequence_parallel ............................... False
sgd_momentum .................................... 0.9
short_seq_prob .................................. 0.1
skip_train ...................................... False
skipped_train_samples ........................... 0
spec ............................................ None
split ........................................... 900,90,10
squared_relu .................................... False
start_weight_decay .............................. 0.1
straggler_ctrlr_port ............................ 65535
straggler_minmax_count .......................... 1
suggested_communication_unit_size ............... None
swiglu .......................................... False
swin_backbone_type .............................. tiny
te_rng_tracker .................................. False
tensor_model_parallel_size ...................... 1
tensorboard_dir ................................. experiments/gpt2/tensorboard
tensorboard_log_interval ........................ 1
tensorboard_queue_size .......................... 1000
test_data_path .................................. None
test_mode ....................................... False
tiktoken_num_special_tokens ..................... 1000
tiktoken_pattern ................................ None
tiktoken_special_tokens ......................... None
timing_log_level ................................ 0
timing_log_option ............................... minmax
titles_data_path ................................ None
tokenizer_model ................................. None
tokenizer_type .................................. GPT2BPETokenizer
tp_comm_bootstrap_backend ....................... nccl
tp_comm_bulk_dgrad .............................. True
tp_comm_bulk_wgrad .............................. True
tp_comm_overlap ................................. False
tp_comm_overlap_ag .............................. True
tp_comm_overlap_cfg ............................. None
tp_comm_overlap_rs .............................. True
tp_comm_overlap_rs_dgrad ........................ False
tp_comm_split_ag ................................ True
tp_comm_split_rs ................................ True
train_data_path ................................. None
train_iters ..................................... 400
train_samples ................................... None
train_sync_interval ............................. None
transformer_impl ................................ transformer_engine
transformer_pipeline_model_parallel_size ........ 1
untie_embeddings_and_output_weights ............. False
use_checkpoint_args ............................. False
use_checkpoint_opt_param_scheduler .............. False
use_cpu_initialization .......................... None
use_custom_fsdp ................................. False
use_dist_ckpt ................................... True
use_dist_ckpt_deprecated ........................ False
use_distributed_optimizer ....................... False
use_flash_attn .................................. False
use_legacy_models ............................... False
use_mp_args_from_checkpoint_args ................ False
use_one_sent_docs ............................... False
use_persistent_ckpt_worker ...................... False
use_precision_aware_optimizer ................... False
use_pytorch_profiler ............................ False
use_ring_exchange_p2p ........................... False
use_rope_scaling ................................ False
use_rotary_position_embeddings .................. False
use_tokenizer_model_from_checkpoint_args ........ True
use_torch_fsdp2 ................................. False
use_torch_optimizer_for_cpu_offload ............. False
use_tp_pp_dp_mapping ............................ False
v_head_dim ...................................... 128
valid_data_path ................................. None
variable_seq_lengths ............................ False
virtual_pipeline_model_parallel_size ............ None
vision_backbone_type ............................ vit
vision_pretraining .............................. False
vision_pretraining_type ......................... classify
vocab_extra_ids ................................. 0
vocab_file ...................................... /workspace/tokenizers/GPT2_tokenizer/vocab.json
vocab_size ...................................... None
wandb_exp_name ..................................
wandb_project ...................................
wandb_save_dir ..................................
weight_decay .................................... 0.1
weight_decay_incr_style ......................... constant
wgrad_deferral_limit ............................ 0
world_size ...................................... 1
yaml_cfg ........................................ None
-------------------- end of arguments ---------------------
> building GPT2BPETokenizer tokenizer ...
> padded vocab (size: 50257) with 47 dummy tokens (new size: 50304)
> setting tensorboard ...
WARNING: one_logger package is required to enable e2e metrics tracking. please go to https://confluence.nvidia.com/display/MLWFO/Package+Repositories for details to install it
[WARNING | megatron.core.rerun_state_machine]: RerunStateMachine initialized in mode RerunMode.DISABLED
> initializing torch distributed ...
> initialized tensor model parallel with size 1
> initialized pipeline model parallel with size 1
> setting random seeds to 1234 ...
> compiling dataset index builder ...
make: Entering directory '/workspace/Megatron-LM/megatron/core/datasets'
make: Nothing to be done for 'default'.
make: Leaving directory '/workspace/Megatron-LM/megatron/core/datasets'
>>> done with dataset index builder. Compilation time: 0.151 seconds
> compiling and loading fused kernels ...
[rank0]:[W109 23:21:23.749969031 ProcessGroupNCCL.cpp:4782] [PG ID 0 PG GUID 0 Rank 0] using GPU 0 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id.
>>> done with compiling and loading fused kernels. Compilation time: 0.408 seconds
time to initialize megatron (seconds): 0.954
[after megatron is initialized] datetime: 2026-01-09 23:21:24
building GPT model ...
/workspace/Megatron-LM/megatron/core/models/gpt/gpt_layer_specs.py:94: UserWarning: The fp8 argument in "get_gpt_layer_with_transformer_engine_spec" has been deprecated and will be removed soon. Please update your code accordingly.
warnings.warn(
> number of parameters on (tensor, pipeline) model parallel rank (0, 0): 124475904
WARNING: could not find the metadata file /workspace/Megatron-LM/experiments/gpt2/latest_checkpointed_iteration.txt
will not load any checkpoints and will start from random
(min, max) time across ranks (ms):
load-checkpoint ................................: (0.12, 0.12)
[after model, optimizer, and learning rate scheduler are built] datetime: 2026-01-09 23:21:24
> building train, validation, and test datasets ...
> datasets target sizes (minimum size):
train: 76800
validation: 5760
test: 1920
> building train, validation, and test datasets for GPT ...
> finished creating GPT datasets ...
[after dataloaders are built] datetime: 2026-01-09 23:21:25
done with setup ...
(min, max) time across ranks (ms):
model-and-optimizer-setup ......................: (120.07, 120.07)
train/valid/test-data-iterators-setup ..........: (1306.21, 1306.21)
training ...
Setting rerun_state_machine.current_iteration to 0...
[before the start of training step] datetime: 2026-01-09 23:21:25
[2026-01-09 23:28:50] iteration 20/ 400 | consumed samples: 3840 | elapsed time per iteration (ms): 22225.5 | learning rate: 5.000000E-07 | global batch size: 192 | TFLOPS per GPU: 7.560328 | lm loss: 1.063548E+01 | loss scale: 32768.0 | grad norm: 70.195 | num zeros: 51.0 | number of skipped iterations: 8 | number of nan iterations: 0 |
[2026-01-09 23:32:32] iteration 30/ 400 | consumed samples: 5760 | elapsed time per iteration (ms): 22250.6 | learning rate: 3.000000E-06 | global batch size: 192 | TFLOPS per GPU: 7.551810 | lm loss: 9.529559E+00 | loss scale: 32768.0 | grad norm: 31.496 | num zeros: 56.0 | number of skipped iterations: 0 | number of nan iterations: 0 |
......
successfully saved checkpoint from iteration 400 to /workspace/Megatron-LM/experiments/gpt2 [ t 1/1, p 1/1 ]
[WARNING | megatron.core.rerun_state_machine]: Setting RerunStateMachine mode RerunMode.DISABLED
Evaluating on 1920 samples
Evaluating iter 1/10
Evaluating iter 2/10
Evaluating iter 3/10
Evaluating iter 4/10
Evaluating iter 5/10
Evaluating iter 6/10
Evaluating iter 7/10
Evaluating iter 8/10
Evaluating iter 9/10
Evaluating iter 10/10
(min, max) time across ranks (ms):
evaluate .......................................: (90254.61, 90254.61)
[WARNING | megatron.core.rerun_state_machine]: Setting RerunStateMachine mode RerunMode.DISABLED
[WARNING | megatron.core.rerun_state_machine]: Setting RerunStateMachine mode RerunMode.DISABLED
-----------------------------------------------------------------------------------------------------------------
validation loss at iteration 400 on validation set | lm loss value: 3.175046E+00 | lm loss PPL: 2.392791E+01 |
-----------------------------------------------------------------------------------------------------------------
[WARNING | megatron.core.rerun_state_machine]: Setting RerunStateMachine mode RerunMode.DISABLED
Evaluating on 1920 samples
Evaluating iter 1/10
Evaluating iter 2/10
Evaluating iter 3/10
Evaluating iter 4/10
Evaluating iter 5/10
Evaluating iter 6/10
Evaluating iter 7/10
Evaluating iter 8/10
Evaluating iter 9/10
Evaluating iter 10/10
(min, max) time across ranks (ms):
evaluate .......................................: (90453.96, 90453.96)
[WARNING | megatron.core.rerun_state_machine]: Setting RerunStateMachine mode RerunMode.DISABLED
[WARNING | megatron.core.rerun_state_machine]: Setting RerunStateMachine mode RerunMode.DISABLED
-----------------------------------------------------------------------------------------------------------
validation loss at iteration 400 on test set | lm loss value: 3.180835E+00 | lm loss PPL: 2.406684E+01 |
-----------------------------------------------------------------------------------------------------------
[rank0]:[W110 01:55:31.621007519 ProcessGroupNCCL.cpp:1497] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator()) 持续观测
bash
$ tensorboard --logdir=./experiments/gpt2/tensorboard --port=6006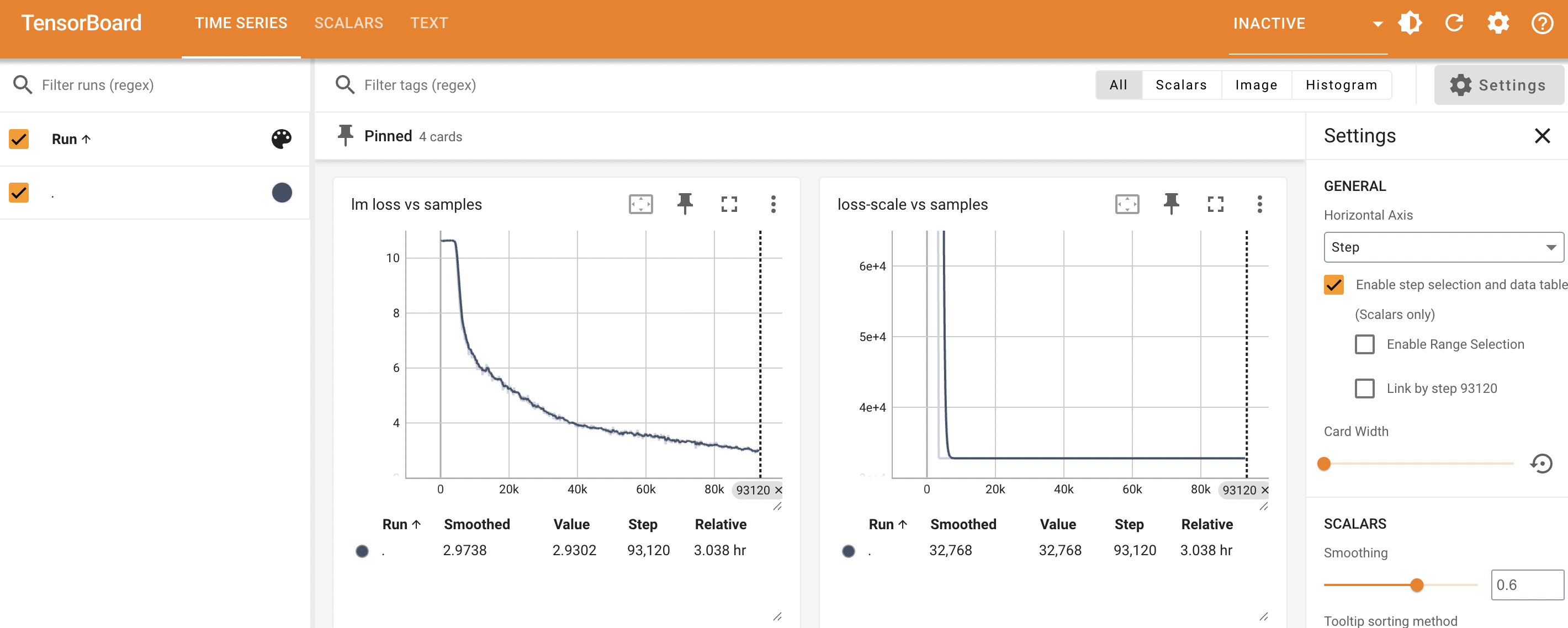
导出模型
训练完成后,可将模型转换为 Hugging Face 格式:
bash
$ python tools/convert_checkpoint_to_hf.py \
--checkpoint-path /workspace/Megatron-LM/experiments/gpt2/ \
--output-path /workspace/Megatron-LM/experiments/hf同样的,Megatron 训练得到的模型权重格式与 Hugging Face 不兼容,需进行转换。
bash
python tools/convert.py \
--checkpoint_path path_to_megatron_model \
--output_path path_to_output_hf_model监控 TFLOPS
Megatron 在 logging 时不会打印 TFLOPS。如果想要直观地观察训练效率,需要手动添加计算 TFLOPS 的代码到 megatron/training/training.py。
python
# ...
log_string += f' global batch size: {batch_size:5d} |'
### 监控 TFLOPS
"""
Compute TFLOPS and report.
"""
checkpoint_activations_factor = 4 if args.recompute_granularity is not None else 3
ffn_factor = 2 if args.swiglu else 1
seq_len = args.seq_length
hidden_size = args.hidden_size
ffn_hidden_size = args.ffn_hidden_size
num_layers = args.num_layers
vocab_size = args.padded_vocab_size
flops_per_iteration = \
checkpoint_activations_factor * \
( \
num_layers * \
( \
8 * batch_size * seq_len * hidden_size ** 2 + \
4 * batch_size * seq_len ** 2 * hidden_size + \
2 * batch_size * seq_len * hidden_size * ffn_hidden_size * (ffn_factor + 1)
) + \
( \
2 * batch_size * seq_len * hidden_size * vocab_size \
) \
)
tflops = flops_per_iteration / (elapsed_time_per_iteration * args.world_size * (10**12))
log_string += ' TFLOPS per GPU: {:3f} |'.format(
tflops)
### 监控 TFLOPS
for key in total_loss_dict:
# ...持续预训练(Continual Pretraining)
如果想要基于一个已有的 LLaMA checkpoint 做 continual pretraining,那么需要将 LLaMA 权重转化为 megatron 的格式。Megatron-LM 提供了做格式转换的代码:
bash
# 下载 huggingface 格式的 llama2 checkpoint
$ mkdir -p /workspace/model_ckpts && cd /workspace/model_ckpts
$ wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-ckpts/Llama-2-7b-hf.tgz
$ tar -zxf Llama-2-7b-hf.tgz
$ mv Llama-2-7b-hf llama2-7b-hf
# 将 hf 格式的 checkpoint 转成 megatron 格式,这里需要提前指定 tp、pp 的 size
$ cp -r /workspace/Megatron-LM/tools/checkpoint /workspace/model_ckpts
$ cd /workspace/model_ckpts && mv ./checkpoint ./ckpt_convert
$ python ./ckpt_convert/util.py \
--model-type GPT \
--loader llama2_hf \
--saver megatron \
--target-tensor-parallel-size 2 \
--target-pipeline-parallel-size 1 \
--load-dir ./llama2-7b-hf \
--save-dir ./llama2-7b_hf-to-meg_tp2-pp1 \
--tokenizer-model ./llama2-7b-hf/tokenizer.model \
--megatron-path /workspace/Megatron-LMMegatron-LM & LLaMA-Factory
LLaMA-Factory 的优势在于及其对样的训练范式和及其简单且灵活的配置方式和用户体验,但训练后端对超大规模模型的性能较差。所以 LLaMA-Factory 和 Megatron-LM 的组合可以强强联手。
通过阿里巴巴开源的 MCoreAdapter 项目,就可以将 LLaMA-Factory 和 Megatron-LM "桥接" 起来。
NOTE:LLaMA-Factory 和 Megatron-LM 结合使用的方式并不完善,有许多软件版本依赖问题需要解决,因此需要谨慎选择。
bash
$ cd workspace
$ docker run -d --network=host --restart=always --name=ml-dev \
--gpus=all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v "$PWD":/workspace -w /workspace \
nvcr.io/nvidia/pytorch:25.08-py3 \
tail -f /dev/null
$ docker exec -it -u root ml-dev bash
$ python -c "
import torch
print('=== 恢复验证 ===')
print(f'PyTorch 版本: {torch.__version__}')
print(f'CUDA 可用: {torch.cuda.is_available()}')
print(f'CUDA 编译支持: {torch.backends.cuda.is_built()}')
print(f'GPU 名称: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else "CPU"}')
"
=== 恢复验证 ===
PyTorch 版本: 2.8.0a0+34c6371d24.nv25.08
CUDA 可用: True
CUDA 编译支持: True
GPU 名称: NVIDIA GB10
# 创建配置目录
$ mkdir -p ~/.pip
# 创建配置文件
$ cat > ~/.pip/pip.conf << EOF
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
EOF
$ git clone https://github.com/hiyouga/LlamaFactory.git
$ cd LlamaFactory
$ git checkout v0.9.4
$ pip install -e . --no-deps
$ pip install accelerate==1.11.0 datasets==4.0.0 gradio==5.50.0 modelscope==1.33.0 peft==0.17.1 transformers==4.57.1 trl==0.24.0 tyro==0.8.14
$ pip install omegaconf
$ python -c "
import torch
print('=== 恢复验证 ===')
print(f'PyTorch 版本: {torch.__version__}')
print(f'CUDA 可用: {torch.cuda.is_available()}')
print(f'CUDA 编译支持: {torch.backends.cuda.is_built()}')
print(f'GPU 名称: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else "CPU"}')
"
=== 恢复验证 ===
PyTorch 版本: 2.8.0a0+34c6371d24.nv25.08
CUDA 可用: True
CUDA 编译支持: True
GPU 名称: NVIDIA GB10
$ cd /workspace
$ git clone https://github.com/NVIDIA/Megatron-LM.git
$ cd Megatron-LM
$ git checkout "core_r0.12.0"
$ pip install -e .
$ echo 'export PYTHONPATH="/workspace/Megatron-LM:$PYTHONPATH"' >> ~/.bashrc
$ source ~/.bashrc
$ python -c "
import torch
print('=== 恢复验证 ===')
print(f'PyTorch 版本: {torch.__version__}')
print(f'CUDA 可用: {torch.cuda.is_available()}')
print(f'CUDA 编译支持: {torch.backends.cuda.is_built()}')
print(f'GPU 名称: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else "CPU"}')
"
=== 恢复验证 ===
PyTorch 版本: 2.8.0a0+34c6371d24.nv25.08
CUDA 可用: True
CUDA 编译支持: True
GPU 名称: NVIDIA GB10
$ pip install "git+https://github.com/alibaba/roll.git#subdirectory=mcore_adapter"
$ pip uninstall -y transformer_engine- run_train.py:参考 MCoreAdapter 的 example,修改了 use_mca 参数冲突的问题。
python
import functools
import hashlib
import os
from copy import deepcopy
from dataclasses import dataclass, field
from typing import Any, Dict, Sequence, Tuple
import torch
from filelock import FileLock
from huggingface_hub import snapshot_download
from llamafactory.data import get_dataset, get_template_and_fix_tokenizer
from llamafactory.data.collator import PairwiseDataCollatorWithPadding, SFTDataCollatorWith4DAttentionMask
from llamafactory.hparams import DataArguments, FinetuningArguments, GeneratingArguments, ModelArguments
from llamafactory.model import load_tokenizer
from llamafactory.train.callbacks import SaveProcessorCallback
from llamafactory.train.dpo import run_dpo
from llamafactory.train.pt import run_pt
from llamafactory.train.sft import run_sft
from transformers import DataCollatorForSeq2Seq, HfArgumentParser
from transformers.trainer_callback import TrainerCallback
from mcore_adapter.models import AutoConfig, AutoModel
from mcore_adapter.trainer import DPOTrainer, McaTrainer
from mcore_adapter.trainer.dpo_config import DPOConfig
from mcore_adapter.training_args import Seq2SeqTrainingArguments
def download_model(model_name_or_path: str, local_dir: str = None) -> str:
if os.path.isdir(model_name_or_path):
return model_name_or_path
use_model_scope = os.getenv("USE_MODELSCOPE", "0") == "1"
temp_lock_path = os.path.join(
"~/.cache/mcore_adapter/temp_lock",
f"{hashlib.md5(model_name_or_path.encode()).hexdigest()}.lock",
)
with FileLock(temp_lock_path):
if use_model_scope:
from modelscope.hub.snapshot_download import snapshot_download as ms_snapshot_download
return ms_snapshot_download(model_name_or_path, local_dir=local_dir)
return snapshot_download(model_name_or_path, local_dir=local_dir)
class ProfCallback(TrainerCallback):
def __init__(self, prof):
self.prof = prof
def on_step_end(self, args, state, control, **kwargs):
self.prof.step()
@dataclass
class UseMcaArguments:
enable_mca: bool = field(
default=True,
metadata={"help": "Use MCA training pipeline"} # 只生成 --enable_mca / --enable-mca
)
def get_args() -> Tuple[
Seq2SeqTrainingArguments,
ModelArguments,
DataArguments,
FinetuningArguments,
GeneratingArguments,
UseMcaArguments,
]:
parser = HfArgumentParser((
Seq2SeqTrainingArguments,
ModelArguments,
DataArguments,
FinetuningArguments,
GeneratingArguments,
UseMcaArguments,
))
training_args, model_args, data_args, finetuning_args, generating_args, use_mca_args = parser.parse_args_into_dataclasses()
if not use_mca_args.enable_mca:
from transformers import Seq2SeqTrainingArguments as HFSeq2SeqTrainingArguments
training_args = HFSeq2SeqTrainingArguments(**vars(training_args))
model_args.model_name_or_path = download_model(model_args.model_name_or_path)
return training_args, model_args, data_args, finetuning_args, generating_args, use_mca_args
def data_collator_wrapper(data_collator):
@functools.wraps(data_collator)
def wrapper(features: Sequence[Dict[str, Any]]):
labels_key = [k for k in features[0].keys() if k.endswith("labels")]
input_ids_key = [k for k in features[0].keys() if k.endswith("input_ids")]
for feature in features:
if len(labels_key) == 0: # pt
feature["labels"] = deepcopy(feature["input_ids"])[1:]
for k in labels_key:
feature[k] = feature[k][1:]
for k in input_ids_key:
feature[k] = feature[k][:-1]
for k in ["attention_mask", "position_ids"]:
if k in feature:
feature[k] = feature[k][:-1]
return data_collator(features)
return wrapper
def pt_mca_train(
training_args: Seq2SeqTrainingArguments,
model_args: ModelArguments,
data_args: DataArguments,
finetuning_args: FinetuningArguments,
):
tokenizer_module = load_tokenizer(model_args)
tokenizer = tokenizer_module["tokenizer"]
template = get_template_and_fix_tokenizer(tokenizer, data_args)
model = AutoModel.from_pretrained(model_args.model_name_or_path, training_args)
data_args.cutoff_len += 1
dataset_module = get_dataset(template, model_args, data_args, training_args, stage="pt", **tokenizer_module)
data_args.cutoff_len -= 1
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
pad_to_multiple_of=8,
label_pad_token_id=-100,
)
data_collator = data_collator_wrapper(data_collator)
trainer = McaTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
data_collator=data_collator,
**dataset_module,
)
# with torch.profiler.profile(activities=[torch.profiler.ProfilerActivity.CPU,
# torch.profiler.ProfilerActivity.CUDA],
# schedule=torch.profiler.schedule(skip_first=0, wait=0, warmup=1, active=2, repeat=1),
# on_trace_ready=torch.profiler.tensorboard_trace_handler(f"output_dir_tp2pp1_{training_args.process_index}"),
# profile_memory=True,
# with_stack=True,
# record_shapes=True) as prof:
# trainer.add_callback(ProfCallback(prof=prof))
# trainer.train()
if "processor" in tokenizer_module and tokenizer_module["processor"] is not None:
trainer.add_callback(SaveProcessorCallback(tokenizer_module["processor"]))
trainer.train(training_args.resume_from_checkpoint)
def sft_mca_train(
training_args: Seq2SeqTrainingArguments,
model_args: ModelArguments,
data_args: DataArguments,
finetuning_args: FinetuningArguments,
):
data_args.neat_packing = training_args.sequence_packing = data_args.neat_packing or training_args.sequence_packing
data_args.packing = data_args.neat_packing or data_args.packing
tokenizer_module = load_tokenizer(model_args)
tokenizer = tokenizer_module["tokenizer"]
template = get_template_and_fix_tokenizer(tokenizer, data_args)
model = AutoModel.from_pretrained(model_args.model_name_or_path, training_args)
data_args.cutoff_len += 1
dataset_module = get_dataset(template, model_args, data_args, training_args, stage="sft", **tokenizer_module)
data_args.cutoff_len -= 1
if model.config.hf_model_type in ["qwen2_vl"] and finetuning_args.freeze_vision_tower:
for name, p in model.named_parameters():
if any(name.startswith(k) for k in ["vision_model.blocks", "vision_model.patch_embed"]):
p.requires_grad_(False)
if model.config.hf_model_type in ["qwen2_vl"] and finetuning_args.freeze_multi_modal_projector:
for name, p in model.named_parameters():
if any(name.startswith(k) for k in ["multi_modal_projector"]):
p.requires_grad_(False)
if model.config.hf_model_type in ["qwen2_vl"] and finetuning_args.freeze_language_model:
for name, p in model.named_parameters():
if any(name.startswith(k) for k in ["embedding", "decoder", "output_layer"]):
p.requires_grad_(False)
pad_to_max = training_args.expert_model_parallel_size is not None and training_args.expert_model_parallel_size > 1 and not training_args.variable_seq_lengths
data_collator = SFTDataCollatorWith4DAttentionMask(
template=template,
padding="max_length" if pad_to_max else "longest",
max_length=data_args.cutoff_len if pad_to_max else None,
pad_to_multiple_of=64,
label_pad_token_id=-100,
**tokenizer_module,
)
data_collator = data_collator_wrapper(data_collator)
trainer = McaTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
data_collator=data_collator,
**dataset_module,
)
if "processor" in tokenizer_module and tokenizer_module["processor"] is not None:
trainer.add_callback(SaveProcessorCallback(tokenizer_module["processor"]))
trainer.train(training_args.resume_from_checkpoint)
def dpo_mca_train(
training_args: Seq2SeqTrainingArguments,
model_args: ModelArguments,
data_args: DataArguments,
finetuning_args: FinetuningArguments,
):
tokenizer_module = load_tokenizer(model_args)
tokenizer = tokenizer_module["tokenizer"]
template = get_template_and_fix_tokenizer(tokenizer, data_args)
model = AutoModel.from_pretrained(model_args.model_name_or_path, training_args)
if finetuning_args.use_ref_model:
ref_config = AutoConfig.from_pretrained(model_args.model_name_or_path, training_args)
ref_model = AutoModel.from_config(ref_config)
ref_model.load_state_dict(model.state_dict())
else:
ref_model = None
data_args.cutoff_len += 1
dataset_module = get_dataset(template, model_args, data_args, training_args, stage="rm", **tokenizer_module)
data_args.cutoff_len -= 1
pad_to_max = training_args.expert_model_parallel_size is not None and training_args.expert_model_parallel_size > 1
dpo_config = DPOConfig(
beta=finetuning_args.pref_beta,
pref_loss=finetuning_args.pref_loss,
label_smoothing=finetuning_args.dpo_label_smoothing,
)
data_collator = PairwiseDataCollatorWithPadding(
template=template,
pad_to_multiple_of=64,
padding="max_length" if pad_to_max else "longest",
max_length=data_args.cutoff_len if pad_to_max else None,
label_pad_token_id=-100,
**tokenizer_module,
)
data_collator = data_collator_wrapper(data_collator)
trainer = DPOTrainer(
model=model,
ref_model=ref_model,
args=training_args,
train_config=dpo_config,
tokenizer=tokenizer,
data_collator=data_collator,
**dataset_module,
)
if "processor" in tokenizer_module and tokenizer_module["processor"] is not None:
trainer.add_callback(SaveProcessorCallback(tokenizer_module["processor"]))
trainer.train(training_args.resume_from_checkpoint)
def mca_train(
training_args: Seq2SeqTrainingArguments,
model_args: ModelArguments,
data_args: DataArguments,
finetuning_args: FinetuningArguments,
):
if finetuning_args.stage == "pt":
pt_mca_train(training_args, model_args, data_args, finetuning_args)
elif finetuning_args.stage == "sft":
sft_mca_train(training_args, model_args, data_args, finetuning_args)
elif finetuning_args.stage == "dpo":
dpo_mca_train(training_args, model_args, data_args, finetuning_args)
else:
raise ValueError("Unknown task: {}.".format(finetuning_args.stage))
def llama_factory_train(training_args, model_args, data_args, finetuning_args, generating_args):
data_args.cutoff_len += 1
callbacks = None
if finetuning_args.stage == "pt":
run_pt(model_args, data_args, training_args, finetuning_args, callbacks)
elif finetuning_args.stage == "sft":
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
elif finetuning_args.stage == "dpo":
run_dpo(model_args, data_args, training_args, finetuning_args, callbacks)
else:
raise ValueError("Unknown task: {}.".format(finetuning_args.stage))
def main():
training_args, model_args, data_args, finetuning_args, generating_args, use_mca_args = get_args()
model_args.model_max_length = data_args.cutoff_len
model_args.block_diag_attn = data_args.neat_packing
data_args.packing = data_args.packing if data_args.packing is not None else finetuning_args.stage == "pt"
if use_mca_args.enable_mca:
mca_train(training_args, model_args, data_args, finetuning_args)
else:
llama_factory_train(training_args, model_args, data_args, finetuning_args, generating_args)
if __name__ == "__main__":
main()- train.sh:同样参考 MCoreAdapter 中的示例。USE_MCA 默认为 true,表示启用 MCoreAdapter 优化。
bash
#!/bin/bash
export MEGATRON_USE_TRANSFORMER_ENGINE=False
export CUDA_EXTENSION=0
# Get script directory
workdir=$(cd $(dirname $0); pwd)
parent_dir=$(dirname "$workdir")
# 添加 Megatron-LM 路径(关键)
MEGATRON_PATH="/workspace/Megatron-LM"
export PYTHONPATH="$MEGATRON_PATH/build/lib.linux-aarch64-cpython-312:$MEGATRON_PATH:$PYTHONPATH"
# Default configurations
NPROC_PER_NODE=1
TENSOR_MODEL_PARALLEL_SIZE=1
PIPELINE_MODEL_PARALLEL_SIZE=1
MODEL_NAME="/workspace/Qwen2.5-1.5B-Instruct"
export DISABLE_VERSION_CHECK=1
USE_MCA=true
# Parallel configuration options
mca_options=" \
--tensor_model_parallel_size ${TENSOR_MODEL_PARALLEL_SIZE} \
--sequence_parallel \
--pipeline_model_parallel_size ${PIPELINE_MODEL_PARALLEL_SIZE} \
--use_distributed_optimizer \
--bias_activation_fusion \
--apply_rope_fusion \
--overlap_param_gather \
--overlap_grad_reduce"
llama_factory_options=" \
--deepspeed=${parent_dir}/examples/deepspeed/ds_z3_config.json"
# Training parameters
options=" \
--do_train \
--stage=sft \
--finetuning_type=lora \
--lora_target=all \
--dataset=huanhuan \
--dataset_dir=/workspace/LlamaFactory/data \
--preprocessing_num_workers=8 \
--cutoff_len=1024 \
--template=qwen \
--model_name_or_path=$MODEL_NAME \
--output_dir=./tmp/ \
--per_device_train_batch_size=1 \
--gradient_accumulation_steps=4 \
--calculate_per_token_loss=True \
--max_steps=10 \
--learning_rate=1e-5 \
--max_grad_norm=1.0 \
--logging_steps=1 \
--save_steps=5 \
--lr_scheduler_type=cosine \
--bf16=True \
--num_train_epochs=10.0 \
--overwrite_cache \
--overwrite_output_dir \
--per_device_eval_batch_size=1 \
--warmup_ratio=0.1 \
--val_size=0.1 \
--eval_strategy=no \
--eval_steps=500 \
--max_samples=1000 \
--use_swanlab=false \
--swanlab_project=llamafactory \
--swanlab_run_name=Qwen2.5-1.5B-Instruct \
--swanlab_api_key=G015uugTzA1cFFWpSer8V \
--ddp_timeout=180000000"
# Add options based on USE_MCA
if [ "$USE_MCA" = true ]; then
options="$options $mca_options --enable_mca"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [INFO] MCA optimization enabled"
else
NPROC_PER_NODE=$(($NPROC_PER_NODE / $TENSOR_MODEL_PARALLEL_SIZE / $PIPELINE_MODEL_PARALLEL_SIZE))
options="$options $llama_factory_options --enable_mca=False"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [INFO] DeepSpeed optimization enabled"
fi
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [INFO] Starting single-node training"
torchrun --nproc_per_node=$NPROC_PER_NODE $workdir/run_train.py $options
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [INFO] Training job completed"从训练配置可以看出,绝大多数参数沿用了 LLaMA Factory 原生配置。唯一区别在于使用 Megatron 时无需指定 --deepspeed,而是替换为 Megatron 相关的并行配置项。
如果训练的是 MoE 模型,可额外添加如下 MoE 专用配置:
bash
--moe_grouped_gemm=True # grouped gemm 加速 moe mlp 计算速度
--moe_token_dispatcher_type=alltoall
--expert_model_parallel_size=8
# moe layer 的中间状态显存占用较高,可以加 recompute 来节省显存
--moe_layer_recompute=True
# 以下为非 MoE 配置
# 模型权重过大,通过 pipeline 并行分散模型参数。
# 注意开启 pipeline 并行时 gradient_accumulation_steps 需要是 pp 的倍数,如 8, 16
--pipeline_model_parallel_size=8
--virtual_pipeline_model_parallel_size=6
# Qwen3 235B 有94层,因此 lm-head 和 embedding 也算作一层,凑够 96层
--account_for_loss_in_pipeline_split
--account_for_embedding_in_pipeline_split 执行训练:
bash
$ bash train.sh
[2026-01-10 20:26:06] [INFO] MCA optimization enabled
[2026-01-10 20:26:06] [INFO] Starting single-node training
[WARNING|2026-01-10 20:26:09] llamafactory.extras.misc:154 >> Version checking has been disabled, may lead to unexpected behaviors.
WARNING:megatron.core.utils:fused_indices_to_multihot has reached end of life. Please migrate to a non-experimental function.
[2026-01-10 20:26:12,401] [INFO] [mcore_adapter.models.auto.modeling_auto]: Did not find /workspace/Qwen2.5-1.5B-Instruct/mca_config.json, loading HuggingFace config from /workspace/Qwen2.5-1.5B-Instruct
INFO:mcore_adapter.models.auto.modeling_auto:Did not find /workspace/Qwen2.5-1.5B-Instruct/mca_config.json, loading HuggingFace config from /workspace/Qwen2.5-1.5B-Instruct
[2026-01-10 20:26:12,402] [INFO] [mcore_adapter.models.model_config]: Did not find /workspace/Qwen2.5-1.5B-Instruct/mca_config.json, loading HuggingFace config from /workspace/Qwen2.5-1.5B-Instruct
INFO:mcore_adapter.models.model_config:Did not find /workspace/Qwen2.5-1.5B-Instruct/mca_config.json, loading HuggingFace config from /workspace/Qwen2.5-1.5B-Instruct
[2026-01-10 20:26:12,402] [INFO] [mcore_adapter.initialize]: Initializing mpu on device cuda:0
INFO:mcore_adapter.initialize:Initializing mpu on device cuda:0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[2026-01-10 20:26:12,406] [INFO] [mcore_adapter.initialize]: initialized tensor model parallel with size 1
INFO:mcore_adapter.initialize:initialized tensor model parallel with size 1
[2026-01-10 20:26:12,406] [INFO] [mcore_adapter.initialize]: initialized pipeline model parallel with size 1
INFO:mcore_adapter.initialize:initialized pipeline model parallel with size 1
[2026-01-10 20:26:12,408] [WARNING] [mcore_adapter.models.model_config]: Non-interleaved pipeline parallelism does not support overlapping p2p communication!
WARNING:mcore_adapter.models.model_config:Non-interleaved pipeline parallelism does not support overlapping p2p communication!
[2026-01-10 20:26:12,408] [WARNING] [mcore_adapter.models.model_config]: When tensor parallelism is not used, cannot use sequence parallelism!
WARNING:mcore_adapter.models.model_config:When tensor parallelism is not used, cannot use sequence parallelism!
[2026-01-10 20:26:12,808] [INFO] [mcore_adapter.models.model_factory]: number of parameters on (tensor, pipeline, expert) model parallel rank (0, 0, 0): 1543714304
INFO:mcore_adapter.models.model_factory:number of parameters on (tensor, pipeline, expert) model parallel rank (0, 0, 0): 1543714304
[2026-01-10 20:26:19,453] [INFO] [mcore_adapter.models.model_factory]: End loading, cost: 7.052s
INFO:mcore_adapter.models.model_factory:End loading, cost: 7.052s
[INFO|2026-01-10 20:26:19] llamafactory.data.loader:143 >> Loading dataset huanhuan.json...
Converting format of dataset (num_proc=8): 2000 examples [00:00, 3046.03 examples/s]
Running tokenizer on dataset (num_proc=8): 1800 examples [00:01, 847.92 examples/s]
training example:
input_ids:
[151644, 8948, 198, 2610, 525, 1207, 16948, 11, 3465, 553, 54364, 14817, 13, 1446, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 101541, 99582, 17340, 30440, 32376, 102167, 100522, 21894, 99921, 99314, 99314, 11319, 151645, 198, 151644, 77091, 198, 121332, 114835, 36556, 18830, 31991, 36589, 1773, 102242, 29826, 3837, 42140, 99757, 118672, 100290, 121332, 114835, 49238, 99455, 1773, 151645, 198]
inputs:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
莞贵人可否愿意陪本宫走走?<|im_end|>
<|im_start|>assistant
嫔妾正有此意。今日事,多谢娘娘替嫔妾解围。<|im_end|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 121332, 114835, 36556, 18830, 31991, 36589, 1773, 102242, 29826, 3837, 42140, 99757, 118672, 100290, 121332, 114835, 49238, 99455, 1773, 151645, 198]
labels:
嫔妾正有此意。今日事,多谢娘娘替嫔妾解围。<|im_end|>
Running tokenizer on dataset (num_proc=8): 200 examples [00:01, 96.30 examples/s]
eval example:
input_ids:
[151644, 8948, 198, 2610, 525, 1207, 16948, 11, 3465, 553, 54364, 14817, 13, 1446, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 56568, 114238, 3837, 100446, 100512, 100457, 59532, 3837, 58514, 20412, 107558, 47764, 9370, 1773, 151645, 198, 151644, 77091, 198, 99405, 99364, 99405, 100003, 3837, 97706, 101476, 102777, 99767, 101913, 100457, 1773, 151645, 198]
inputs:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
你听听,牙尖嘴利,必是跟你学的。<|im_end|>
<|im_start|>assistant
吃便吃吧,还堵不上皇上的嘴。<|im_end|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 99405, 99364, 99405, 100003, 3837, 97706, 101476, 102777, 99767, 101913, 100457, 1773, 151645, 198]
labels:
吃便吃吧,还堵不上皇上的嘴。<|im_end|>
/usr/local/lib/python3.12/dist-packages/mcore_adapter/trainer/trainer.py:86: FutureWarning: `tokenizer` is deprecated and will be removed in version 5.0.0 for `McaTrainer.__init__`. Use `processing_class` instead.
super().__init__(
[2026-01-10 20:26:23,453] [WARNING] [mcore_adapter.trainer.trainer]: Currently, train dataloader drop_last must be set to True!
WARNING:mcore_adapter.trainer.trainer:Currently, train dataloader drop_last must be set to True!
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: ***** Running training *****
INFO:mcore_adapter.trainer.trainer:***** Running training *****
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: Num examples = 900
INFO:mcore_adapter.trainer.trainer: Num examples = 900
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: Num Epochs = 1
INFO:mcore_adapter.trainer.trainer: Num Epochs = 1
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: Instantaneous batch size per device = 1
INFO:mcore_adapter.trainer.trainer: Instantaneous batch size per device = 1
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: Total train batch size (w. parallel, distributed & accumulation) = 4
INFO:mcore_adapter.trainer.trainer: Total train batch size (w. parallel, distributed & accumulation) = 4
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: Gradient Accumulation steps = 4
INFO:mcore_adapter.trainer.trainer: Gradient Accumulation steps = 4
[2026-01-10 20:26:23,894] [INFO] [mcore_adapter.trainer.trainer]: Total optimization steps = 10
INFO:mcore_adapter.trainer.trainer: Total optimization steps = 10
[2026-01-10 20:26:23,895] [INFO] [mcore_adapter.trainer.trainer]: Number of trainable parameters = 1,543,714,304
INFO:mcore_adapter.trainer.trainer: Number of trainable parameters = 1,543,714,304
0%| | 0/10 [00:00<?, ?it/s]WARNING:megatron.core.rerun_state_machine:Implicit initialization of Rerun State Machine!
WARNING:megatron.core.rerun_state_machine:RerunStateMachine initialized in mode RerunMode.DISABLED
{'loss': 4.7063, 'grad_norm': 66.86548559655049, 'learning_rate': 1e-05, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.0}
{'loss': 4.0349, 'grad_norm': 54.123890361027264, 'learning_rate': 9.698463103929542e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.01}
{'loss': 4.3632, 'grad_norm': 55.03302453129848, 'learning_rate': 8.83022221559489e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.01}
{'loss': 3.6685, 'grad_norm': 59.47196235740523, 'learning_rate': 7.500000000000001e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.02}
{'loss': 3.6322, 'grad_norm': 38.13660812010227, 'learning_rate': 5.8682408883346535e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.02}
50%|███████████████████████████████████████████████████████████████████████████████████ | 5/10 [00:07<00:06, 1.31s/it][2026-01-10 20:26:35,126] [INFO] [mcore_adapter.checkpointing]: Saving model checkpoint to ./tmp/checkpoint-5/iter_0000001/mp_rank_00/model_optim_rng.pt
INFO:mcore_adapter.checkpointing:Saving model checkpoint to ./tmp/checkpoint-5/iter_0000001/mp_rank_00/model_optim_rng.pt
WARNING:megatron.core.dist_checkpointing.mapping:ShardedTensor.prepend_axis_num greater than 0 is deprecated. In Megatron-Core this can be prevented by setting sharded_state_dict metadata['singleton_local_shards'] to True.
WARNING:megatron.core.optimizer.distrib_optimizer:DistributedOptimizer.sharded_state_dict parameter `sharding_type` is deprecated and will be removed. Use `metadata["distrib_optim_sharding_type"] instead`.
WARNING:megatron.core.dist_checkpointing.mapping:ShardedTensor.flattened_range is deprecated. Use latest DistributedOptimizer formats.
WARNING:megatron.core.dist_checkpointing.serialization:Overwriting old incomplete / corrupted checkpoint...
[WARNING|2026-01-10 20:26:37] llamafactory.extras.misc:154 >> Version checking has been disabled, may lead to unexpected behaviors.
WARNING:megatron.core.utils:fused_indices_to_multihot has reached end of life. Please migrate to a non-experimental function.
{'loss': 2.9508, 'grad_norm': 30.647371054285593, 'learning_rate': 4.131759111665349e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.03}
{'loss': 3.8122, 'grad_norm': 30.385772427496804, 'learning_rate': 2.5000000000000015e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.03}
{'loss': 3.0334, 'grad_norm': 24.65027603087717, 'learning_rate': 1.1697777844051105e-06, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.04}
{'loss': 3.4188, 'grad_norm': 31.30333729462803, 'learning_rate': 3.015368960704584e-07, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.04}
{'loss': 3.3374, 'grad_norm': 34.26579243575143, 'learning_rate': 0.0, 'skipped_iter': 0, 'num_zeros_in_grad': 0, 'epoch': 0.04}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:35<00:00, 2.98s/it][2026-01-10 20:27:03,259] [INFO] [mcore_adapter.checkpointing]: Saving model checkpoint to ./tmp/checkpoint-10/iter_0000001/mp_rank_00/model_optim_rng.pt
INFO:mcore_adapter.checkpointing:Saving model checkpoint to ./tmp/checkpoint-10/iter_0000001/mp_rank_00/model_optim_rng.pt
WARNING:megatron.core.optimizer.distrib_optimizer:DistributedOptimizer.sharded_state_dict parameter `sharding_type` is deprecated and will be removed. Use `metadata["distrib_optim_sharding_type"] instead`.
WARNING:megatron.core.dist_checkpointing.serialization:Overwriting old incomplete / corrupted checkpoint...
{'train_runtime': 49.4091, 'train_samples_per_second': 0.81, 'train_steps_per_second': 0.202, 'train_loss': 3.6957550048828125, 'epoch': 0.04}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:48<00:00, 4.90s/it]
[rank0]:[W110 20:27:15.111666085 ProcessGroupNCCL.cpp:1538] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator())
[2026-01-10 20:27:19] [INFO] Training job completedMCoreAdapter 框架支持在保存时直接输出为 HF 格式,只需启用 --save_hf_model=True。但该选项会增加 checkpoint 保存耗时并占用额外显存。若训练完成后再转换,可直接使用项目提供的转换脚本。
与其他 Adapter 框架集成 Megatron 的方式不同,MCoreAdapter 支持直接加载 Hugging Face 格式的原始模型进行 Megatron 训练,无需预先将 HF 模型转换为 Megatron 格式,极大简化了使用流程。
错误记录: RuntimeError: found NaN in local grad norm 是模型训练过程中的数值不稳定问题(梯度爆炸 / NaN)。NaN(非数值)出现在梯度归一化步骤,常见诱因:
- 学习率过高:大模型(千亿 / 百亿参数)用默认学习率易导致梯度爆炸;
- 权重初始化 / 数据异常:训练数据含非法值(NaN/Inf),或模型权重初始化异常;
- 混合精度训练问题:FP16 精度下数值溢出,未开启梯度裁剪;
- 分布式训练配置 :单卡训练但启用了数据并行(DDP),导致梯度同步异常。
解决:使用 BF16 代替 FP16 后解决。
bash
[rank0]: Traceback (most recent call last):
[rank0]: File "/workspace/ml/run_train.py", line 286, in <module>
[rank0]: main()
[rank0]: File "/workspace/ml/run_train.py", line 281, in main
[rank0]: mca_train(training_args, model_args, data_args, finetuning_args)
[rank0]: File "/workspace/ml/run_train.py", line 253, in mca_train
[rank0]: sft_mca_train(training_args, model_args, data_args, finetuning_args)
[rank0]: File "/workspace/ml/run_train.py", line 193, in sft_mca_train
[rank0]: trainer.train(training_args.resume_from_checkpoint)
[rank0]: File "/usr/local/lib/python3.12/dist-packages/transformers/trainer.py", line 2325, in train
[rank0]: return inner_training_loop(
[rank0]: ^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/usr/local/lib/python3.12/dist-packages/mcore_adapter/trainer/trainer.py", line 815, in _inner_training_loop
[rank0]: tr_loss_step, metrics_tensors, skipped_iter, grad_norm, num_zeros_in_grad = self.training_step(
[rank0]: ^^^^^^^^^^^^^^^^^^^
[rank0]: File "/usr/local/lib/python3.12/dist-packages/mcore_adapter/trainer/trainer.py", line 414, in training_step
[rank0]: metrics_tensors: List[Dict[str, Tensor]] = self.forward_backward_func(
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/pipeline_parallel/schedules.py", line 634, in forward_backward_no_pipelining
[rank0]: backward_step(input_tensor, output_tensor, output_tensor_grad, model_type, config)
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/pipeline_parallel/schedules.py", line 466, in backward_step
[rank0]: custom_backward(output_tensor[0], output_tensor_grad[0])
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/pipeline_parallel/schedules.py", line 170, in custom_backward
[rank0]: Variable._execution_engine.run_backward(
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/distributed/distributed_data_parallel.py", line 469, in hook
[rank0]: self.param_to_bucket_group[param].register_grad_ready(param)
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/distributed/param_and_grad_buffer.py", line 486, in register_grad_ready
[rank0]: self.start_grad_sync()
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/distributed/param_and_grad_buffer.py", line 333, in start_grad_sync
[rank0]: self.check_grads(
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/distributed/param_and_grad_buffer.py", line 185, in check_grads
[rank0]: rerun_state_machine.validate_result(
[rank0]: File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/rerun_state_machine.py", line 505, in validate_result
[rank0]: raise RuntimeError(full_message)
[rank0]: RuntimeError: Rank 0, node spark-84b8, device 0, iteration -1: Unexpected result nan (message='found NaN in local grad norm for bucket #0 in backward pass before data-parallel communication collective')
0%| | 0/10 [00:04<?, ?it/s]
[rank0]:[W110 20:09:57.956818619 ProcessGroupNCCL.cpp:1538] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator())查看 Checkpoint:
bash
$ ll ./tmp/checkpoint-10/
-rw-r--r-- 1 root root 605 Jan 10 20:45 added_tokens.json
-rw-r--r-- 1 root root 2507 Jan 10 20:45 chat_template.jinja
drwxr-xr-x 4 root root 4096 Jan 10 20:16 iter_0000001/
-rw-r--r-- 1 root root 1 Jan 10 20:45 latest_checkpointed_iteration.txt
-rw-r--r-- 1 root root 8286 Jan 10 20:45 mca_config.json
-rw-r--r-- 1 root root 1671853 Jan 10 20:45 merges.txt
-rw-r--r-- 1 root root 15535 Jan 10 20:45 rng_state.pth
-rw-r--r-- 1 root root 1529 Jan 10 20:45 scheduler.pt
-rw-r--r-- 1 root root 613 Jan 10 20:45 special_tokens_map.json
-rw-r--r-- 1 root root 11421896 Jan 10 20:45 tokenizer.json
-rw-r--r-- 1 root root 4713 Jan 10 20:45 tokenizer_config.json
-rw-r--r-- 1 root root 3009 Jan 10 20:45 trainer_state.json
-rw-r--r-- 1 root root 7377 Jan 10 20:45 training_args.bin
-rw-r--r-- 1 root root 2776833 Jan 10 20:45 vocab.json错误记录 :aarch64 + GB10 + Python 3.12,属于 TE 官方 "非主流适配场景",预编译包缺失、源码编译需深度定制,调试成本极高,完全没必要。TE 仅提供 activation_recompute_forward(激活重计算)和随机数优化,我们添加的替代函数完全能满足基础训练需求,唯一区别是显存占用略高(约 5-10%),不影响训练流程 / 结果。显然 transformer_engine 没有适配 GB10 架构。
解决:卸载掉 transformer_engine 包,这个包用于显存优化,影响不大。
bash
[WARNING|2026-01-10 17:28:03] llamafactory.extras.misc:154 >> Version checking has been disabled, may lead to unexpected behaviors.
Traceback (most recent call last):
File "/workspace/ml/run_train.py", line 22, in <module>
from mcore_adapter.models import AutoConfig, AutoModel
File "/usr/local/lib/python3.12/dist-packages/mcore_adapter/__init__.py", line 1, in <module>
from .models import McaGPTModel, McaModelConfig
File "/usr/local/lib/python3.12/dist-packages/mcore_adapter/models/__init__.py", line 1, in <module>
from . import (
File "/usr/local/lib/python3.12/dist-packages/mcore_adapter/models/deepseek_v3/__init__.py", line 2, in <module>
from megatron.core import mpu
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/__init__.py", line 3, in <module>
import megatron.core.tensor_parallel
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/tensor_parallel/__init__.py", line 4, in <module>
from .layers import (
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/tensor_parallel/layers.py", line 32, in <module>
from ..transformer.utils import make_sharded_tensors_for_checkpoint
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/transformer/__init__.py", line 6, in <module>
from .transformer_layer import TransformerLayer, TransformerLayerSubmodules
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/transformer/transformer_layer.py", line 18, in <module>
from megatron.core.transformer.cuda_graphs import CudaGraphManager, is_graph_capturing
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/transformer/cuda_graphs.py", line 19, in <module>
from megatron.core.tensor_parallel.random import (
File "/workspace/Megatron-LM/build/lib.linux-aarch64-cpython-312/megatron/core/tensor_parallel/random.py", line 27, in <module>
from transformer_engine.pytorch.distributed import activation_recompute_forward
File "/usr/local/lib/python3.12/dist-packages/transformer_engine/pytorch/__init__.py", line 26, in <module>
load_framework_extension("torch")
File "/usr/local/lib/python3.12/dist-packages/transformer_engine/common/__init__.py", line 168, in load_framework_extension
solib = importlib.util.module_from_spec(spec)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ImportError: /usr/local/lib/python3.12/dist-packages/transformer_engine/transformer_engine_torch.cpython-312-aarch64-linux-gnu.so: undefined symbol: _ZN3c104cuda20getCurrentCUDAStreamEa错误记录 :没有 torchaudio 模块,
解决:把 import torchaudio 注释掉,因为本次使用用不到多模态。
Megatron-LM & DeepSpeed
DeepSpeed 的核心技术是 ZeRO 技术,它可以克服数据并行和模型并行的局限性,同时实现两者的优点,它是将模型划分为状态参数、梯度、优化器状态来降低内存冗余,提升显存利用率。
- 高效性:能够充分利用硬件资源实现高吞吐和可扩展性。
- 有效性:高精度、快速收敛、低成本。
- 易于使用:提高开发生产力。
Megatron-LM 是 NVIDIA 开发的大模型加速框架,对 NVIDIA 训练卡适配更好,训练速度通常比 DeepSpeed 快 20%-30%。核心优化技术包括:
- 多并行技术组合:利用 PTD-P 技术,结合了流水线、张量和数据并行;
- 优化张量并行:Megatron 就是要把 Masked Multi-Head Self Attention 和 Feed Forward 都进行切分以并行化,利用 Transformer 网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现;
- 流水线并行优化:传统的流水线并行通常会在一个设备上放置几个模块,通过在计算和通信之间取得平衡来提高效率。
DeepSpeed 框架在训练时会损失 10%-30% 的算力,尤其是数据量在 TB 级别的时候更加明显,所以如果数据量很大,那么还是推荐使用 Megatron-LM 框架。
然后,也可以将 Megatron-LM 和 DeepSpeed 组合使用,它们通常的协同方式如下:
- Megatron-LM 处理 TP 和 PP: 它提供函数和模块来定义具有张量并行层(例如 ColumnParallelLinear,RowParallelLinear)的模型结构,并管理跨阶段的流水线调度。首先初始化 Megatron-LM 以设置 TP 和 PP rank 所需的进程组。
- DeepSpeed 封装 Megatron-LM 模型: DeepSpeed 在 Megatron-LM 模型设置之后初始化。它将 Megatron 定义的模型(其中已包含 TP/PP 逻辑)作为输入。然后,DeepSpeed 通常使用 ZeRO 将其 DP 逻辑应用于数据并行维度。DeepSpeed 引擎在 DP Group 内管理优化器、梯度累积和通信,同时遵循 Megatron-LM 建立的底层 TP/PP 结构。
详见 Megatron-DeepSpeed 项目:https://github.com/deepspeedai/Megatron-DeepSpeed
值得注意的是,结合框架会增加复杂性,例如:
- 配置: 管理 DeepSpeed 和 Megatron-LM 的配置文件和命令行参数需要细致考量,以确保兼容性和正确性。了解哪个框架控制哪个方面(例如,优化器状态分片与张量分片)很重要。
- 调试: 在混合设置中调试问题可能具有挑战性,因为问题可能源于 DP、TP、PP、ZeRO、激活检查点或底层硬件/通信库(NCCL)之间的相互作用。
- 通信: 不同通信模式(DP 梯度的 AllReduce,TP 的 AllReduce/点对点,PP 的点对点)之间的协同需要高效的网络基础设施(例如,节点内 TP 的 NVLink,节点间 DP/PP 的 InfiniBand/RoCE)。
- 兼容性: 确保 DeepSpeed、Megatron-LM、PyTorch 以及 CUDA/NCCL 库的版本兼容。这些框架快速迭代。
另一方面要注意的,随着 Megatron-LM 的成熟,逐渐也支持了 DeepSpeed ZeRO,所以 DeepSpeed 和 Megatron-LM 结合使用的情况实际上不多见。
参考文档
https://mp.weixin.qq.com/s/R1PKTDu8gGpmEKDX8wuQLA
https://docs.infini-ai.com/posts/megatron-llama3-training-guide.html