HWC的架构可以清晰地划分为硬件实现层、HAL抽象层、系统框架层 三个主要部分,其核心目标是高效地管理Overlay硬件
总体架构图
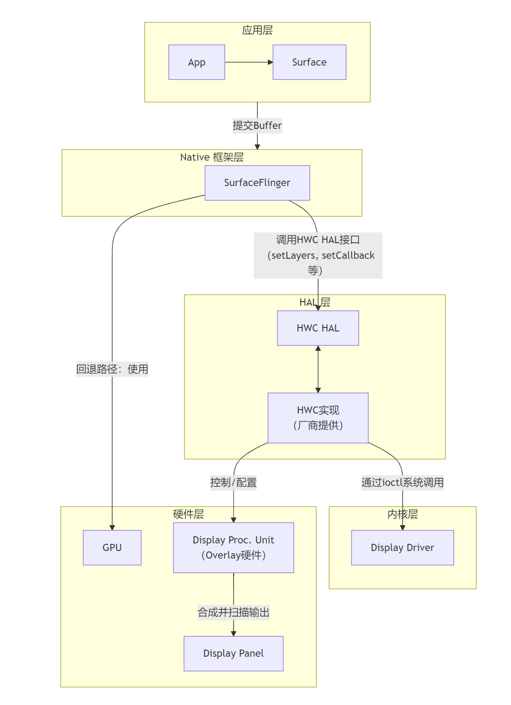
上图清晰地展示了HWC的核心职责:作为SurfaceFlinger和显示硬件之间的"智能调度器"。下面我们逐层解析
1)硬件层
这是HWC能力的基础,主要由SoC(系统级芯片)中的专用硬件模块提供
- 显示处理单元(Display Processing Unit, DPU) :
○ 这是HWC的硬件核心 。它是一个专门为显示合成任务设计的固定功能硬件管道
○ 主要组件包括:
◎ Overlay 硬件层 :这是最关键的概念。DPU内部有多个独立的Overlay引擎 (或称为硬件层)。每个引擎可以独立配置一个图形缓冲区,并指定其在屏幕上的位置、混合模式等。Overlay层的数量是有限的 ,这也是HWC最主要的约束条件
◎ 缩放器(Scaler) :用于对图层进行硬件缩放
◎ 旋转器(Rotator) :用于对图层进行硬件旋转(通常是90度的倍数)
◎ 后处理单元:用于颜色校正、伽马调整等 - GPU :
○ 在HWC架构中,GPU扮演备用角色。当DPU无法处理所有合成请求时(如图层数量过多或效果太复杂),GPU会被SurfaceFlinger用来进行混合合成 - 显示面板(Panel) :
○ 最终的物理输出设备
2)硬件抽象层(HAL)与内核驱动
这是连接软件框架和硬件的桥梁,通常由芯片厂商(如Qualcomm, MediaTek, Samsung)提供
- HWC HAL接口(hwcomposer.h) :
○ AOSP定义了标准的HWC HAL接口(如HIDLIComposer或更新的AIDLIComposer)。这层接口是固定的,确保了SurfaceFlinger可以与不同厂商的HWC实现进行通信
○ 核心接口方法包括 :
◎setLayers(): 将当前帧的所有图层信息(缓冲区句柄、位置、混合模式等)传递给HWC
◎validateDisplay(): (最关键步骤) HWC评估收到的图层,并决定每个图层的合成方式(HWC2::Composition::Device代表用Overlay硬件,HWC2::Composition::Client代表需要GPU合成)
◎presentDisplay(): 执行最终的合成与输出
◎registerCallback(): 接收来自HWC的事件(如VSync信号、热插拔事件) - 厂商HWC实现 :
○ 芯片厂商需要实现上述HAL接口,编写代码来驱动自家的DPU
○ 这部分代码包含了核心算法和策略 ,例如:
◎ 层分配策略 :如何将SurfaceFlinger提交的图层映射到有限的Overlay硬件层上。这是一个复杂的优化问题,需要考虑图层Z-order、大小、位置、是否动画等因素,目标是最大化Overlay利用率,最小化功耗
◎ 内容检测:智能检测图层内容,例如判断一个图层是否是视频、是否在更新等,以做出更好的合成决策 - 显示内核驱动 :
○ 厂商的HWC实现最终会通过ioctl系统调用与内核中的显示驱动(如Qualcomm的MSM DRM/KMS驱动)进行交互
○ 驱动负责将配置信息(如帧缓冲区地址、分辨率、时序等)真正写入硬件寄存器,启动显示流水线
3)系统框架层
- SurfaceFlinger中的HWC客户端 :
○ SurfaceFlinger内部有一个HWComposer对象,它负责加载HWC HAL库并调用其接口
○ 它的工作流程如下:
① 收集图层 :在一帧开始时,收集所有需要显示的Layer
② 调用HWC :调用HWC的setLayers和validateDisplay
③ 决策与回退 :根据HWC返回的合成类型列表,决定哪些图层需要由GPU进行"客户端合成"。如果HWC要求回退,SurfaceFlinger会先用GPU合成一个中间缓冲区
④ 最终提交 :调用HWC的presentDisplay,将控制权交给HWC进行最终的硬件合成和输出
HWC的详细工作流程(与架构对应)
结合上面的架构,一帧的合成流程如下:
- 应用提交 :应用通过GPU渲染将内容填入
GraphicBuffer,并加入队列 - SurfaceFlinger收集:SurfaceFlinger被VSync信号唤醒,从各队列中获取最新的缓冲区,构建图层列表
- 提交给HWC HAL :SurfaceFlinger的
HWComposer调用HAL的setLayers,将图层列表传递给厂商的HWC实现 - HWC决策(核心) :
○ 厂商HWC实现内部的策略引擎 开始工作
○ 它根据当前可用的Overlay硬件资源、图层的属性(格式、变换、Alpha值等),决定最优的分配方案
○ 通过validateDisplay将决策返回给SurfaceFlinger:"图层1、3、4我用Overlay处理(Device),图层2太复杂,你用GPU处理(Client)" - 回退处理(如有需要) :SurfaceFlinger使用GPU,将标记为
Client的图层合成为一个新的中间缓冲区 - 最终呈现 :SurfaceFlinger再次调用
presentDisplay。HWC实现通过内核驱动,配置DPU的各个Overlay层,并触发显示硬件进行扫描输出。如果中间有GPU合成的缓冲区,HWC会将其视为一个普通图层进行处理 - VSync同步:整个流程在VSync信号的协调下进行,以避免撕裂并保证节奏
架构演进与高级特性
现代的HWC(如HWC 2.x及以上)还支持更复杂的特性,这些特性也体现了其架构的先进性:
- 分层合成与帧缓存:允许HWC缓存一些不常变化的图层(如壁纸、状态栏),在后续帧中直接复用,极大节省带宽和功耗
- 虚拟显示:支持投屏、录屏等场景,HWC可以将合成结果输出到多个目标
- 色彩管理:支持广色域、HDR等高级色彩特性,HWC负责正确的色彩空间转换
- 平滑切换:在不同合成策略(如全屏应用切换到多窗口)之间切换时,避免屏幕闪烁
总结
HWC的软硬件架构是一个典型的分工协作、能力协商的范例
- 硬件层(DPU) 提供高效、低功耗的合成能力,但资源有限
- HAL层(厂商实现) 是"大脑",负责最优化地利用有限的硬件资源,其算法质量直接决定了设备的图形性能上限
- 框架层(SurfaceFlinger) 是"指挥官",遵循HAL的决策,并准备好回退方案(GPU合成),保证系统的鲁棒性