历史文献作为文明传承的重要载体,其数字化保护与深度利用一直面临巨大挑战。纸张老化、排版复杂、字迹模糊乃至残缺破损等现象,严重制约了大规模、高精度古籍数字化进程。近日,来自中国的研究团队合合信息与华南理工大学文档图像分析识别与理解联合实验室在这一领域取得了一项研究成果------《HisDoc-DETR: Integrating Semantic Learning and Feature Fusion for Historical Document Layout Analysis》
本文将对HisDoc-DETR进行系统深入的解读,一同探究其背后的动机与挑战,剖析其精巧的技术创新,并展望其在文化遗产保护和学术研究中的广阔应用前景。
一、 时代的需求:历史文献版面分析的困境与突破口
1.1、复杂多变的版面结构

历史文献是中华文明的瑰宝,也是记录人类文明发展的重要载体。然而,这些文献通常具有复杂的结构和多样的排版风格,且常因年代久远而出现字迹模糊、纸张破损等现象。这使得对其的数字化和智能化利用面临着一系列独特的、远超现代文档的挑战,与现代文档的标准化排版不同,历史文献的版面结构往往高度复杂且缺乏统一规范,包括但不限于:
- 不规则的文本块:手写或雕版印刷的文本,其行距、字距、对齐方式常有变化。
- 多样化的元素类型:除了文本,还可能包含插图、表格、批注、印章、边框、标题、页眉页脚等多种版面元素,这些元素之间的布局关系错综复杂。
- 稀疏前景特征:由于纸张老化、墨迹褪色、虫蛀、污损等原因,历史文献的图像质量普遍较差,前景信息(如文字、线条)可能非常稀疏,难以提取。

1.2、传统方法的局限性
早期文档版面分析方法主要分为两类,启发式规则方法与深度学习方法。
其中,启发式规则方法通过观察版面特征来制定特定规则,适用于固定格式的文档,但其缺点是劳动密集型,且泛化能力差,难以适应历史文献的多样性。

早期基于深度学习的方法主要集中在FCN、U-Net或YOLOv3 等模型上面,然而,这些方法虽然在相对简单、结构良好且训练数据充足的文档上表现良好,但对于历史文献,特别是文字分布稀疏、背景复杂的手写稿和早期刻本,这种方法的局部感受野特性难以有效捕捉页面中分散元素之间的长距离依赖关系,往往效果不佳。
1.3、DETR带来的新思路
2020年,Facebook提出了一个DETR模型,首次将 Transformer 架构引入目标检测,并实现了一个真正的端到端流程,模型的主要结构如下: 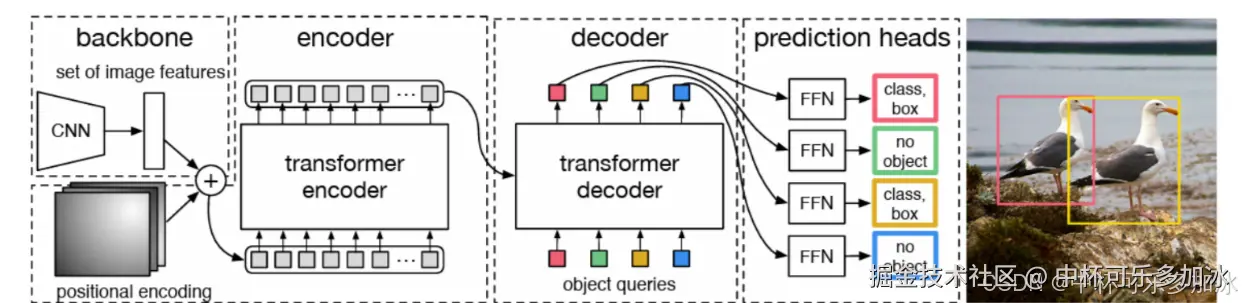
整个工作流程可概括为:特征提取 → 特征增强 → 目标查询 → 结果生成。
首先,在特征提取阶段 ,模型利用卷积神经网络(CNN)分析输入图像,将其分解为多个小块(patches),并为每个小块生成一个包含内容和位置信息的数字向量。随后,这些向量进入特征增强阶段 ,通过一个Transformer编码器(Encoder)进行处理,该编码器会融合所有小块的信息,使每个向量都获得对整张图像的全局理解。接下来是目标查询阶段 ,编码器输出的增强特征与一组"对象查询"(Object Queries)一同被送入Transformer解码器(Decoder)。这些"对象查询"可以被看作是模型主动发出的"哪里有物体?"的提问,解码器通过将它们与图像特征进行交互,生成一系列初步的预测框。最后,在生成结果阶段,模型会将这些预测框与图像中的真实物体框进行匹配,并计算它们之间的差异,输出最终的检测结果,精确地标示出图像中物体的类别和位置。
这种设计的最大优势在于利用了Transformer的全局注意力机制,更有效地捕捉了任意两个像素点之间的依赖关系,并理解历史文献中元素间的复杂空间布局。此外,端到端的设计大大简化了流程,使得训练和推理更加高效直接。
正是看到了DETR架构与历史文献版面分析任务的高度契合,HisDoc-DETR 的研究者们以此为基础,构建了一个专门为古籍"量身定制"的分析模型。
二、 HisDoc-DETR核心解析
2.1 整体架构概述
HisDoc-DETR 的整体架构基于 DINO 框架,主要组成部分包括:
- 骨干网络 (Backbone Network):用于从图像中提取多尺度的视觉特征。
- 编码器 (Encoder):接收骨干网络提取的特征,并通过 Transformer 结构进行编码。
- 查询预测与选择模块 (Query Prediction and Selection Module):对潜在目标位置和类别初步预测。
- 解码器 (Decoder):接收编码器输出的特征和查询向量,通过多层 Transformer 结构迭代地细化查询,预测每个版面元素的边界框和类别标签。
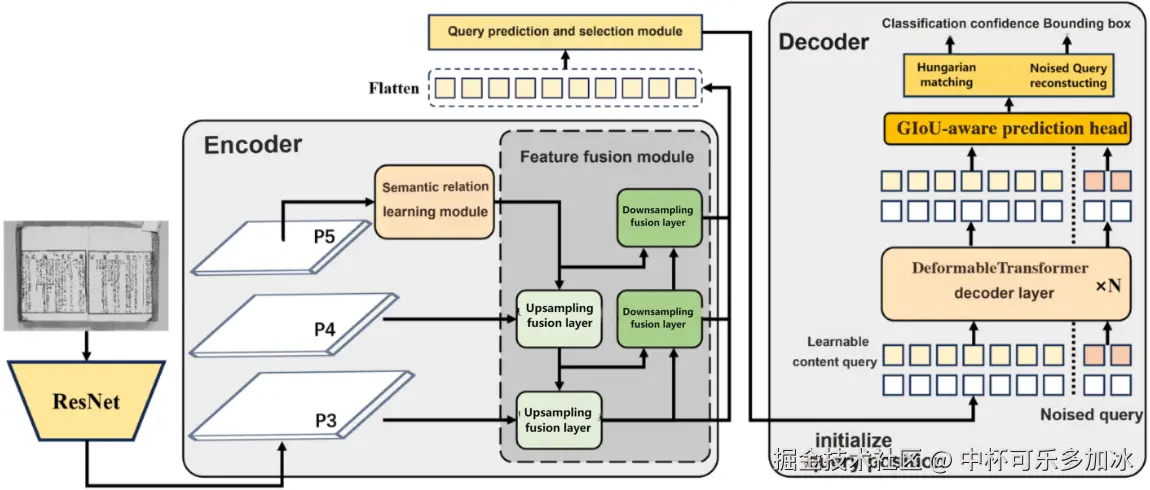
HisDoc-DETR 在解码器的查询输入中,除了可学习的内容查询向量和对应的初始化位置向量外,还包含了 DINO 中用于辅助训练的标签噪声查询向量,这种设计有助于加速模型训练收敛,并提升其对复杂场景的适应性。
在每次迭代中,解码器输出的特征会经过一个 GIoU 感知预测头 (GIoU-Aware Prediction Head),该预测头输出分类置信度分数和边界框坐标。此预测头也集成在查询预测与选择模块中,用于生成高质量的初始化查询。最终,模型通过算法将预测结果与真实标注进行一对一匹配,计算损失并优化模型参数。
2.2 编码器部分
2.2.1 语义关系学习模块 (Semantic Relationship Learning Module)
历史文献的版面元素之间常存在复杂的长距离依赖关系,比如段落的起始位置可能与前一段的结束位置、甚至页眉或页脚的样式密切相关,而传统卷积神经网络受限于局部感受野,难以有效捕捉此类全局性的长距离依赖。为应对这一问题,HisDoc-DETR引入了基于Transformer架构的语义关系学习模块,显著提升了模型对跨区域语义关联的建模能力。
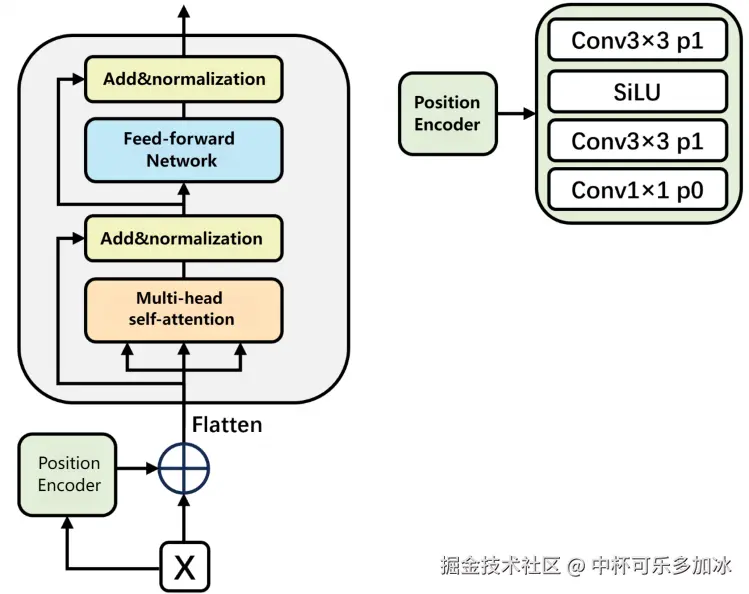
该模块由以下部分组成:
- 位置编码器:包含卷积层和SiLU激活函数,用于为序列中的每个位置提供位置信息。
- 多头自注意力层:Transformer的核心,允许模型同时关注来自不同表示子空间的信息,从而更全面地捕捉复杂的语义关系。通过注意力机制,模型可以动态地为不同区域分配权重,突出与当前处理元素最相关的部分。
- 前馈网络层:对多头自注意力层的输出进行非线性变换,进一步增强特征学习能力。
2.2.2 特征融合模块 (Feature Fusion Module)
在文档版面分析中,高层语义信息和低层细节信息都至关重要,高层特征通常由深层网络提取,具有较强的语义性但空间分辨率较低;低层特征则由浅层网络提取,空间分辨率高但语义性较弱。而如何有效地融合这两种不同层次的特征,是提升检测性能的关键。HisDoc-DETR的双流特征融合模块正是为了解决这一问题而设计。
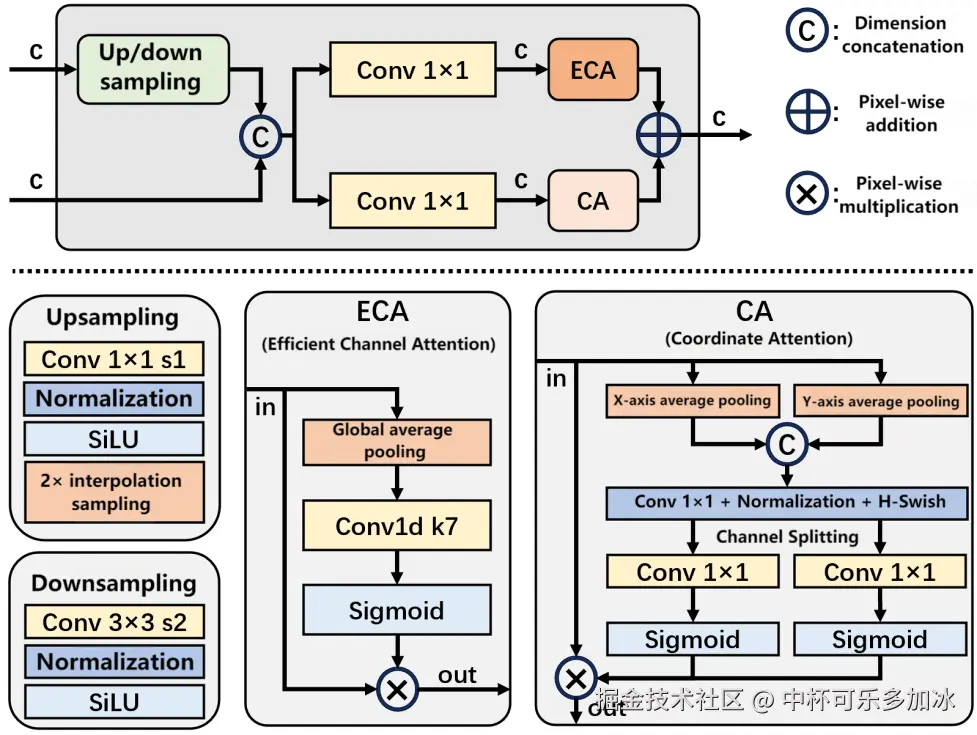
特征融合模块的创新之处在于其精细的注意力融合机制,机制包含以下模块:
- 尺度统一:通过上采样和下采样操作,将相邻层的特征图调整到相同的空间尺寸。
- 粗融合与细融合:首先通过初步的通道拼接实现特征粗融合。在此基础上,模块进一步引入了高效通道注意力(ECA)和坐标注意力(CA)机制。ECA关注特征图中不同通道的重要性,而CA则关注特征图中不同空间位置的重要性。通过学习这些注意力特征图,并进行逐像素相加,实现了高层语义信息与低层细节信息的深度融合,生成了一个充分整合的多尺度特征图。这种精细的融合方式,使得模型在识别不同尺寸和形状的版面元素时更加准确,尤其对于历史文献中可能出现的微小或不规则的元素,能够提供更强的感知能力。
2.3 解码器部分
2.3.1 可变形 Transformer 解码器层 (Deformable Transformer Decoder Layer)
在文档版面分析中,解码器需要高效地从编码器输出的视觉特征中提取并细化目标信息。传统的Transformer交叉注意力机制在处理高分辨率特征图时,计算成本高昂且效率低下。为解决这一挑战,HisDoc-DETR引入了基于Deformable DETR的可变形Transformer解码器层,优化了对版面元素细节的关注与捕获。
解码器由多个可变形 Transformer 解码器层堆叠而成。每个解码器层包含:
- 多头自注意力层:与编码器中的结构类似,用于处理查询向量之间的关系。
- 可变形交叉注意力层:可变形注意力机制通过学习偏移量,仅关注特征图上少量关键采样点,降低了计算复杂度的同时,提高了对目标细节的关注能力。这种机制使得查询向量能够高效捕获编码器输出的视觉特征,并逐步细化对版面元素的预测。
- 前馈网络:用于增强特征的非线性表达能力。
2.3.2 GIoU 感知预测头 (GIoU-Aware Prediction Head)
在历史文献版面分析中,由于元素边界模糊或标注困难,分类置信度与定位精度之间常常存在不平衡。HisDoc-DETR针对这一问题,创新性地提出了GIoU感知预测头,将定位质量直接融入分类置信度,实现更可靠的版面元素识别和定位。GIoU 感知预测头在 HisDoc-DETR 的两个关键阶段发挥作用:
- 查询初始化 :在查询预测与选择模块中,模型预测候选版面目标,并根据其 GIoU 感知分数排序,选择得分最高的
k个作为解码器的初始查询向量,为解码器提供高质量的初始信息。 - 最终预测:每个解码器层输出的更新查询向量,会再次通过 GIoU 感知预测头,预测最终的分类置信度和位置坐标,并取最后一个解码器层的输出作为最终结果。通过设置置信度阈值,模型能够区分前景版面元素和背景。
这种设计有效缓解了历史文献版面分析中定位与分类不平衡的问题,使模型能够更可靠地识别和定位复杂的版面元素。
2.4 实验性能表现
为精确衡量HisDoc-DETR在版面元素检测任务中的表现,文章还在公开中文历史文献版面分析数据集 SCUT-CAB 上进行了严格且丰富实验验证对比,结果显示,HisDoc-DETR在所有关键评估指标上均取得了SOTA。
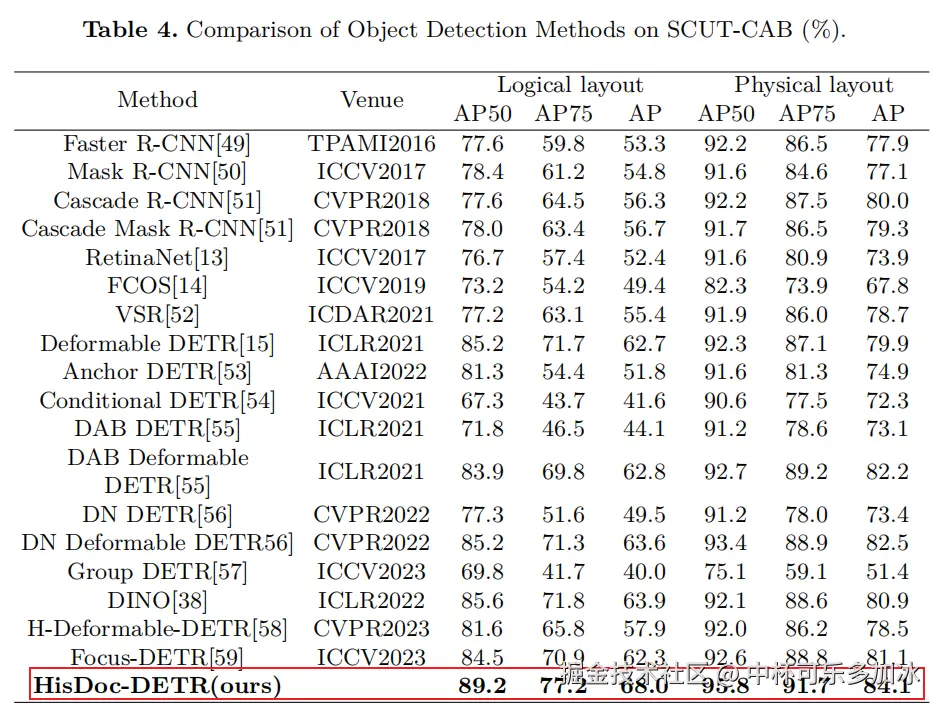
与基线模型DINO相比,HisDoc-DETR在逻辑版面任务上的AP指标实现了4.1%的显著提升,在物理版面任务上也取得了3.2%的性能增益。一系列数据有力地表明了HisDoc-DETR所独创的语义关系学习模块、特征融合模块和GIoU感知预测头在提升历史文献版面分析性能方面的积极且深远的影响。

论文还展示了HisDoc-DETR的可视化检测结果,这些可视化图像清晰地展示模型在历史文档布局分析任务中的卓越性能。对于逻辑布局子集,该模型能够精准区分文本块和图像块,并生成与目标布局高度贴合的边界框;而对于物理布局子集,在面对复杂背景和小字字体的挑战时,模型依然展现了卓越的识别能力与鲁棒性,小文本区域也能被清晰捕捉,实验结果充分显示了其在历史文档处理领域的实际应用价值。
三、 应用场景与价值
HisDoc-DETR 的出现,不仅是技术上的突破,更重要的是其在实际应用中能够产生的深远影响和价值。它为历史文献的数字化、研究和文化传承提供了工具。
3.1 文化遗产保护与数字化归档
全球范围内,大量历史文献因年代久远、保存条件不佳而面临损毁风险。数字化是保护这些文化遗产的关键。然而,简单的图像扫描不足以满足研究需求,更重要的是从图像中提取结构化信息。
HisDoc-DETR 在历史文献版面分析上的高准确性和可靠性,使其成为文化遗产数字化归档的有效工具。它能够:
- 自动化信息提取:精确识别并定位文献中的文本段落、标题、插图、表格、批注等各类版面元素,将非结构化的图像数据转化为结构化的数字信息。
- 提升归档效率:相较于人工标注和整理,HisDoc-DETR 能够大幅提升数字化归档效率,使海量古籍的数字化成为可能。
- 促进数据标准化:通过统一的版面分析标准,有助于建立跨机构、跨地域的历史文献数字资源库,为全球范围内的共享与合作奠定基础。
在文化遗产保护与数字化归档方面,HisDoc-DETR 可以应用到国家图书馆、博物馆等文化机构中,快速处理馆藏古籍的数字化图像,自动生成带有版面结构信息的元数据,丰富数字资源的内涵,确保历史信息的完整性和可检索性。
3.2 助力历史研究与学术创新
对于历史学者而言,获取和分析原始文献是研究工作的核心。HisDoc-DETR 的精确版面分析能力,也能够助力历史学科研究进程,并促进新的研究方法:
- 高效信息检索:学者可根据版面类型(如只检索正文、只检索批注或只检索插图说明)进行更精准的全文检索和内容定位,快速找到所需信息。
- 大规模数据分析 :通过自动化提取的结构化版面数据,学者可进行大规模定量分析,例如:
- 版式演变研究:分析不同历史时期、不同地域文献的版式布局特征,揭示印刷技术、审美观念、阅读习惯的演变规律。

- 内容关联分析:通过识别文本与插图、批注之间的关联,深入理解文献的创作意图和传播过程。
- 知识图谱构建:将版面元素与文本内容相结合,构建更丰富的历史知识图谱,辅助历史事件、人物关系的梳理。
- 辅助校勘与断代:精确的版面信息可为古籍的校勘工作提供辅助,例如识别不同版本之间的版式差异。版式特征也可作为古籍断代研究的重要线索。
在助力历史研究与学术创新方面,HisDoc-DETR 可以使学者能够从繁琐的文献整理工作中解放出来,从而将更多精力投入到思考和创新性研究中,从而推动历史学、文献学、数字人文等学科的发展。
3.3 应对复杂与稀疏特征
HisDoc-DETR 的一个显著优势在于其对复杂和稀疏特征的处理能力。中国历史文献,特别是早期刻本和手稿,其版面布局不规则,文字稀疏,且常伴有虫蛀、墨迹扩散、纸张破损等问题。

HisDoc-DETR 通过其独特的语义关系学习模块和双流特征融合模块,能够:
- 捕捉长距离依赖:克服传统 CNN 局部感受野的限制,有效关联页面中分散的、但语义相关的元素。
- 适应稀疏前景:在复杂背景下,精准识别稀疏的文字和图形元素,减少检测错误。
- 提升鲁棒性:面对不同字体、字号、排版风格,以及一定程度的破损和污渍,依然能保持较高的分析精度。
这种对古籍特有挑战的有效应对,使得 HisDoc-DETR 在处理历史文献时,展现出很高的实用价值。
四、结论
总的来说,HisDoc-DETR 是历史文献版面分析领域的重要进展之一。通过对 Transformer 架构的定制与创新,模型成功处理了复杂、稀疏且多样的历史文献版面挑战。其核心的语义关系学习模块、双流特征融合模块以及 GIoU 感知预测头,共同构建了一个高效、精准且鲁棒的版面分析框架。
当然,技术发展是持续的。HisDoc-DETR 的成功也为未来的研究指明了方向:如何进一步提升模型在极端退化文献(如严重残损、字迹模糊不清)上的表现?如何更好地融合多模态信息(如文本内容、纸张纹理、墨迹特征)以实现更深层次的语义理解?这些都将是未来值得探索的课题。相信随着人工智能技术的不断演进,AI 与人文学科的结合将日益紧密,共同推动新的研究发展。