背景
许多用户在日志查询方面已经积累了一定的使用习惯,尤其是习惯于使用某些查询语法进行高效检索。现在,日志数据全面接入观测云并通过 DataKit 进行采集,用户最关心的问题是:能否通过 DQL 实现以往熟悉的查询方式,甚至更进一步提升效率?答案是肯定的,DQL 不仅具备高度灵活性,还能提供更强大的日志处理能力。下面我们通过一个脱敏后的真实案例,逐步演示如何利用 DQL 高效解析和统计日志。
示例日志
一行典型的业务日志(已脱敏):
json
{
"timestamp": "2025-06-10 11:09:06.558",
"level": "INFO",
"thread": "XXXXXXXXXXXXXXXXXXXXXX6",
"mdc": {
"traceId": "f961xxxxd4ab8",
"spanId": "96b41dxxxxxx5111c",
"x-st-correlation": "XXXXXXXXXXXXXXXXXX23"
},
"message": "User :aaaabbbdd is rate limited",
"context": "default"
}需求分析
用户常见的查询需求可概括为以下几步:
- 从日志中提取特定信息(如 userid:aaaabbdd)
- 对提取出的信息进行数量统计
- 对统计结果进行排序
以往在某些查询平台中,用户可能会编写类似以下的语句(语法仅为示意):
csharp
_index=tier3_app_auth _source=aaa _sourceCategory=prod "is rate limited" | parse ""message":"User :* is rate limited"" as userId | count by userId | sort by _count desc as you can see the log is "User : is rate limited".接下来我们将展示如何通过 DQL 实现相同甚至更优的效果。
DQL 实现
为了清晰体现从解析到统计的完整流程,我们分两步实现:
Step1:提取 userid
通过 DQL 的 regexp_extract() 函数,使用正则表达式从 message 字段中提取 userid:
csharp
# explain
L('日志索引')::`日志来源`:(regexp_extract(message,'正则表达式', 1) as m1)
# DQL
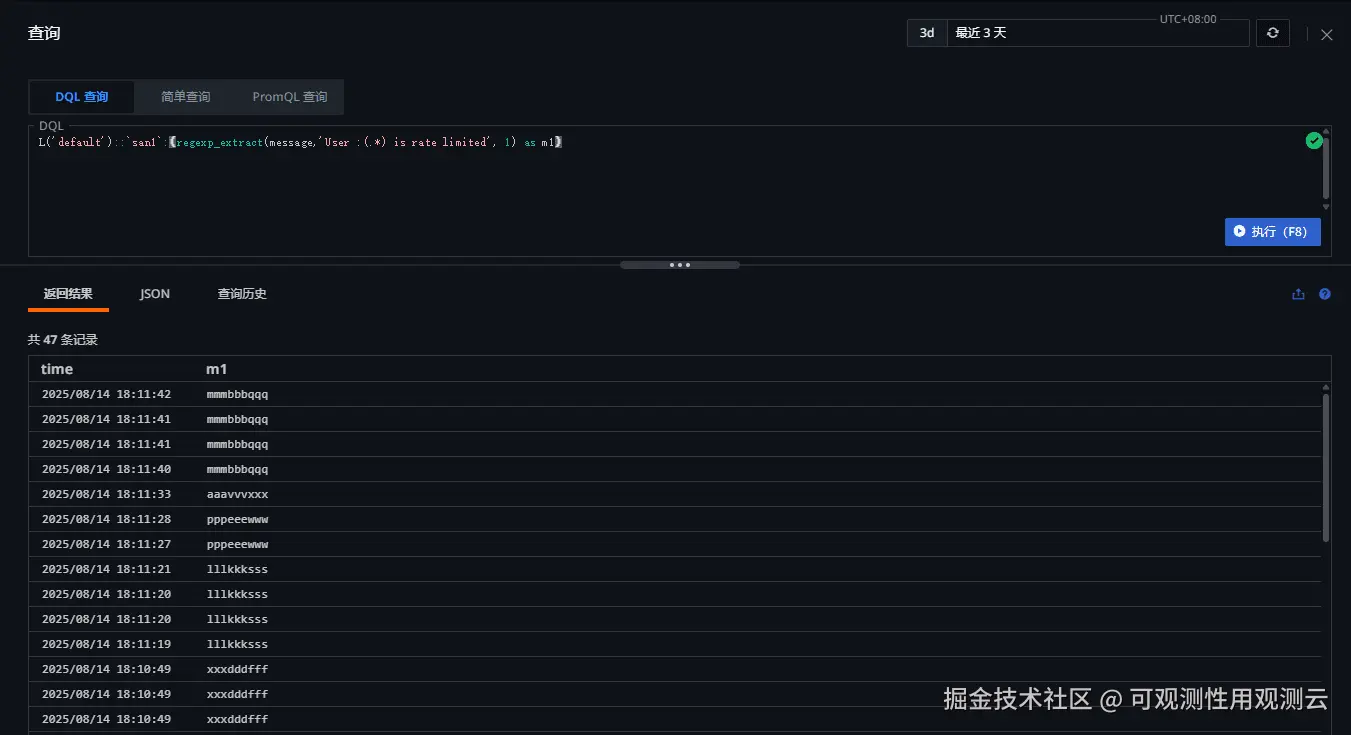
L('default')::`san1`:(regexp_extract(message,'User :(.*) is rate limited', 1) as m1)该语句执行后返回提取出的 ml 字段,即 userid。
| 字段说明 | 示例值 |
|---|---|
| default | 日志索引(Index) |
| san1 | 日志来源(Source) |
| message | 要解析的字段 |
| 1 | 正则里第 1 个捕获组 |
函数 regexp_extract 中对应参数解释如下:
| 非命名参数 | 描述 | 类型 | 是否必填 | 默认值 |
|---|---|---|---|---|
| 字段名称 | 查询的字段 | string | 是 | |
| 正则表达式 | 包含捕获组的正则表达式 | string | 是 | |
| 返回的分组 | 返回的第 n 个分组 | int | 否 | 0(表示匹配整个正则表达式),1(表示匹配正则表达式中第一组,以此类推...) |
查询返回的结果如下(m1列就是日志原文中提取出来的 uesrid):
Step2:统计与排序
接下来我们使用嵌套查询,对上一步提取出的 ml(userid)进行计数和排序:
python
# datasource 数据来源
# target_clause 指定要查询的列
# by-clause 分组依据
# sorder-by-clause 排序查询结果
'''
L::(
__datasource__
):(
__target_clause__
) by-clause
sorder-by-clause
'''
# DQL结构拆解
'''
L::(
L('default')::`san1`:(
regexp_extract(message,'User :(.*) is rate limited', 1) as m1
)
):(
count(`m1`) as c1
) by m1
sorder by c1 desc
'''
# DQL
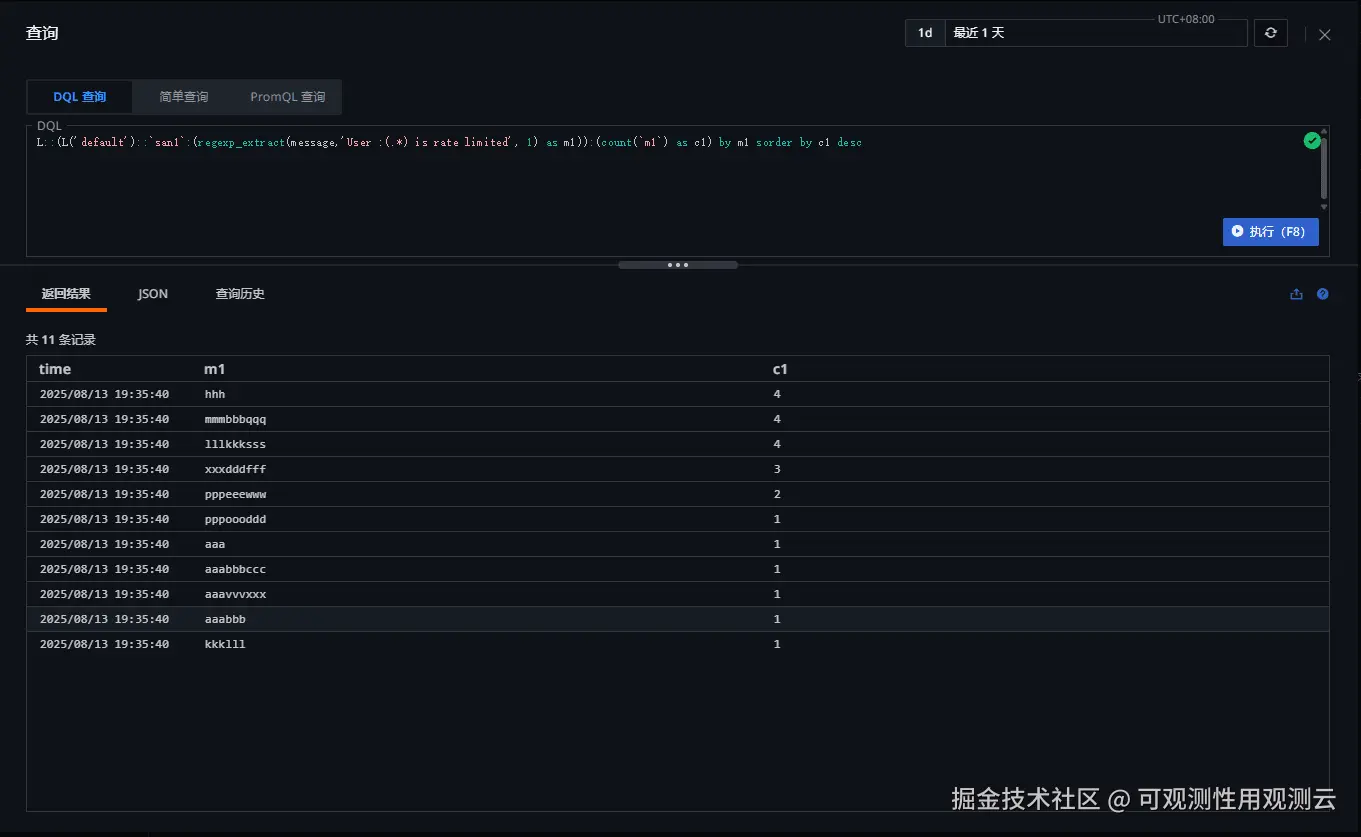
L::(L('default')::`san1`:(regexp_extract(message,'User :(.*) is rate limited', 1) as m1)):(count(`m1`) as c1) by m1 sorder by c1 desc执行结果:
- ml:提取出的 userid
- c1:该 userid 出现的次数
- 结果按 c1 降序排列
总结
通过正则提取 + 嵌套查询的组合,DQL 能够高效完成日志解析、统计和排序等复杂操作。依托观测云的高性能日志处理引擎,即使在大规模数据场景下,查询仍能秒级返回结果。DQL 语法简洁却功能强大,支持用户在不改变原有检索习惯的基础上,进一步提升日志分析效率与灵活性。