本系列主要旨在帮助初学者学习和巩固Linux系统。也是笔者自己学习Linux的心得体会。

个人主页: 爱装代码的小瓶子
文章系列: Linux
2. C++
文章目录
- [1. 前言:](#1. 前言:)
- [2. 什么是匿名管道:](#2. 什么是匿名管道:)
- [3 匿名管道的使用:](#3 匿名管道的使用:)
-
- [3-1 一切皆文件的思想:](#3-1 一切皆文件的思想:)
-
- [1. 核心思想:一切皆文件](#1. 核心思想:一切皆文件)
- [2. 管道与文件的相似性](#2. 管道与文件的相似性)
- [3. 为何说"迎合了一切皆文件"](#3. 为何说“迎合了一切皆文件”)
- [4. 注意:管道 ≠ 普通文件](#4. 注意:管道 ≠ 普通文件)
- [3-2 实验继续拓展:](#3-2 实验继续拓展:)
-
- [1. 它是"面向字节流"的 (Byte Stream)](#1. 它是“面向字节流”的 (Byte Stream))
- [2. 它是自带"流量控制"的 (Flow Control)](#2. 它是自带“流量控制”的 (Flow Control))
- 总结:
1. 前言:
在上一篇文章中,我们讲述了Linux平台中的动静态库。以及我们是如何制作动静态库的。本篇文章,我们将要讲述Linux下进程的通讯方式。
先来说说,进程之间需要通讯(IPC,Inter-Process Communication)主要有以下几个核心原因:
- 不同进程可能需要访问同一份数据或资源
- 多个进程协作完成一个复杂任务,需要交换中间结果
- 一个进程产生的数据需要传递给另一个进程处理,例如:Shell 命令的管道
cmd1 | cmd2,前一个命令的输出作为后一个的输入 - 进程需要告知其他进程某个事件已发生,例如:子进程结束通知父进程,或进程间的信号机制
- 父进程需要管理子进程的状态和行为
- 通过 IPC 可以监控、同步或终止其他进
由于进程之间是具有独立性的,进程之间是无法之间进行通讯的。我们可以自然而然的想到利用之前的知识点就可以想到一种新的通讯方式:匿名管道。
2. 什么是匿名管道:
想要理解什么是匿名管道,我们就得来回顾一下前面得知识点,父进程是怎么打开一个文件并且写入的:系统先构建一个进程(struct_task),这个 struct_task 里面有files的结构体指针,它指向File table(strcut files_struct),这个文件表里面的fa_array指向不同的文件(struct file),这样我们就找到了不同的文件。
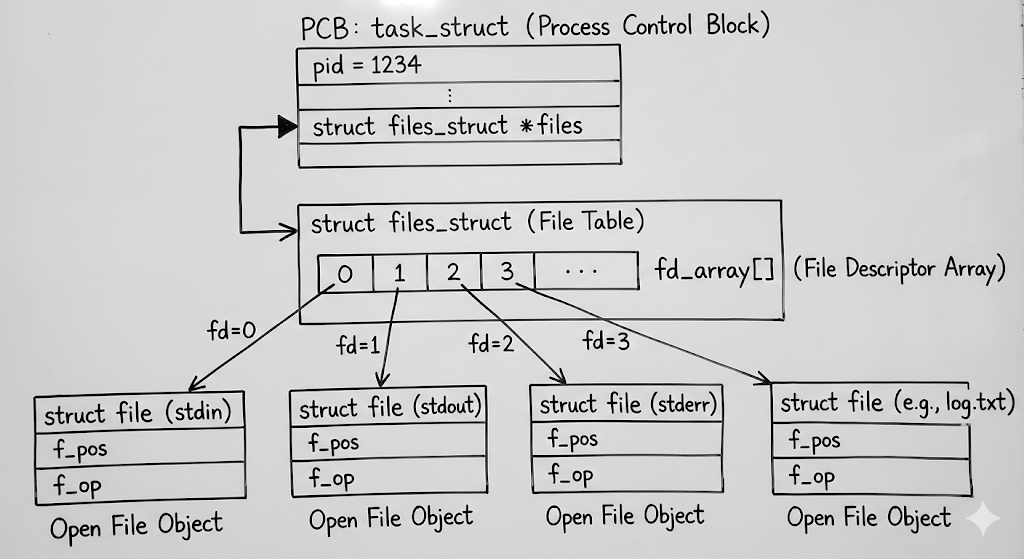
后面再通过 struct file内部的 struct path的结构体成员f_path,这个 struct path 里面 ,包含了一个指向 struct dentry 的指针 。通过这个detry我们就可以找到struct inode.struct inode:这是文件在文件系统中的唯一表示 。它包含了文件的大小、权限、所有者、时间戳,以及最重要的------数据在哪里。
我们已经父进程是怎么打开一个文件的了,我们如果在创建一个子进程,子进程会完成对上面一切的拷贝。那么每个 struct file都有两个指针指向。那么我只要让一个父进程写,子进程读不就可以了。
在这个基础上面,我们就引入了管道,大致就是这么来的,但是和上面也有变化:
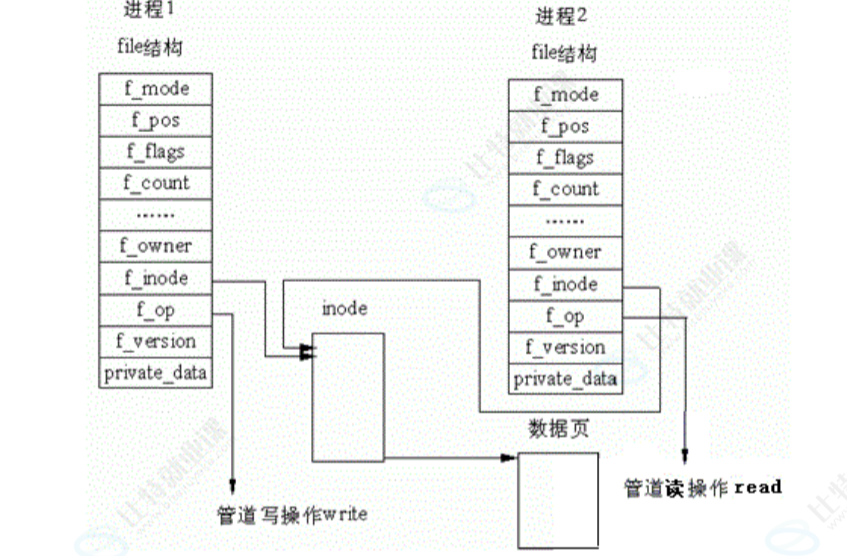
我们再来详细看一下这个变化吧:
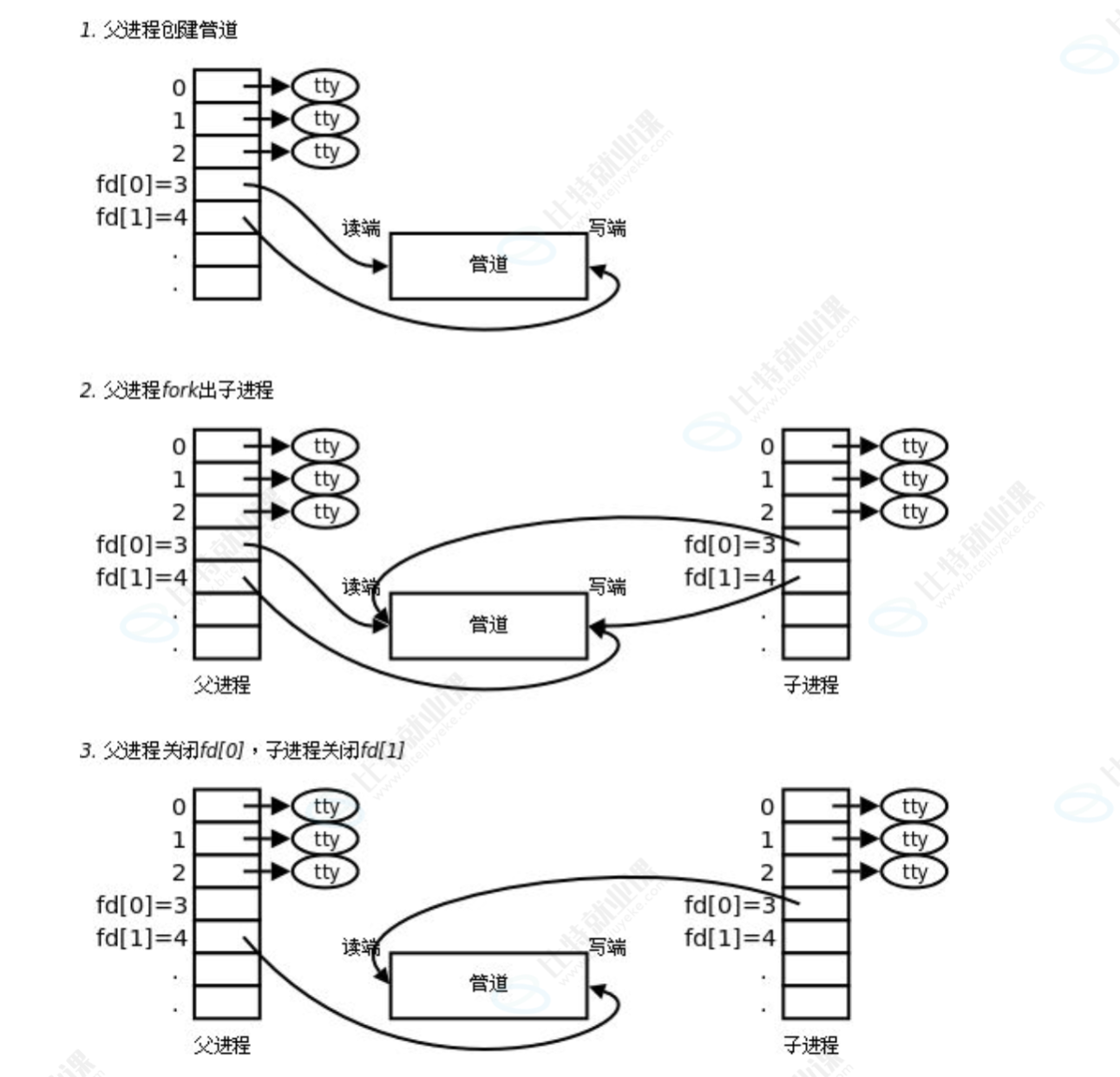
3 匿名管道的使用:
我们在Linux中有一个系统调用:
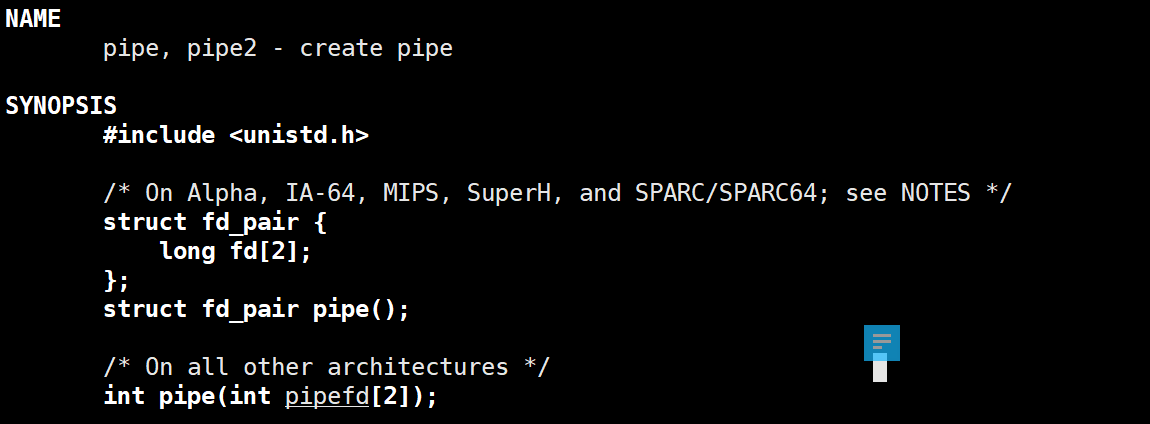
所需头文件就是 #include <unistd.h>。其中我们只要看 pipe,里面传入pipefd,pipefd 是一个包含两个 fd 的数组,代表一个管道的"入口"和"出口"。pipefd:像是一根单向的水管。你必须从一头倒水(写),从另一头接水(读)。
在 Linux C/C++ 编程中,当我们调用
pipe()系统调用时,我们需要传给它一个长度为 2 的整数数组。大家习惯把这个数组命名为pipefd。
pipefd[0](读端): 只能用来读(Read)。它是管道的出口。pipefd[1](写端): 只能用来写(Write)。它是管道的入口。
其中0很像嘴巴,就是读,1很像鼻子。就是写。
我们可以来使用一下:
cpp
#include <iostream>
#include <unistd.h>
int main()
{
int pipefd[2] = {0};
int ret = pipe(pipefd);
if(ret < 0){
std::cerr << "pipe error" << std::endl;
exit(1);
}
std :: cout << "pipefd[0]" << pipefd[0] << std::endl;
std :: cout << "pipefd[0]" << pipefd[1] << std::endl;
return 0;
}我们可以先运行来看看,会出现什么结果:

我们可以看到没有问题,0,1,2已经被占了,的确是3和4.
接下来,我们继续深入使用,我们打算利用子进程写入特定的格式的文字,而父进程来完成读取。
先准备什么是子进程函数:ChildWrite函数,主要是利用snprintf完成指定格式的字符串,随后通过系统调用函数写入。
cpp
void ChildWrite(int wfd) {
int cnt = 0;
char buff[1024];
while(true) {
snprintf(buff,sizeof(buff) - 1,"I am child ,my pid:%d,nt:%d",getpid(),cnt++);
write(wfd,buff,strlen(buff));
sleep(1);//写入之后,开始停止一会
}
}当我们把字符写入了管道了,后面我们开始利用父进程来提取进一个字符数组中,记得还需要在结束的位置加上\0。
cpp
void ParentRead(int wfd) {
char buff[1024];
while(true) {
ssize_t n = read(wfd,buff,sizeof(buff) - 1);
if(n > 0) {
buff[n] = 0;
std:: cout << "child say:" << buff << std::endl;
}
else if(n == 0) {
std::cout << "n : " << n << std::endl;
std:: cout << "no input" << std::endl;
break;
}
else {
break;
}
}
}那么主函数就很好处理了:
cpp
int main()
{
int pipefd[2] = {0};
int ret = pipe(pipefd);
if(ret < 0){
std::cerr << "pipe error" << std::endl;
exit(1);
}
// std :: cout << "pipefd[0]" << pipefd[0] << std::endl;
// std :: cout << "pipefd[0]" << pipefd[1] << std::endl;
pid_t id = fork();
if(id == 0) {
//child 进程,这次我们打算使用child来写
close(pipefd[0]);//闭上child 的嘴巴
ChildWrite(pipefd[1]);
close(pipefd[1]);
exit(1);
}
close(pipefd[1]);
ParentRead(pipefd[0]);//父亲来看看写了什么
close(pipefd[0]);
int stutats = 0;
int ret2 = waitpid(id,&stutats,0);
if(ret2 > 0) {
printf("exit code:%d , exit signal:%d", (stutats >> 8) & 0xFF,stutats & 0x7F);
}
return 0;
}运行一下,可以看到结果:
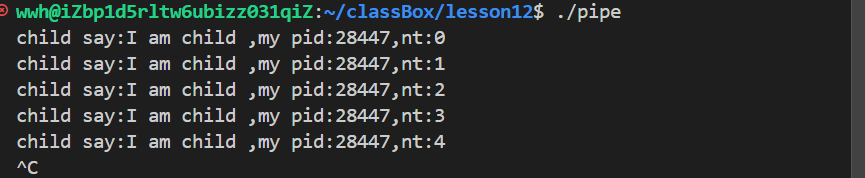
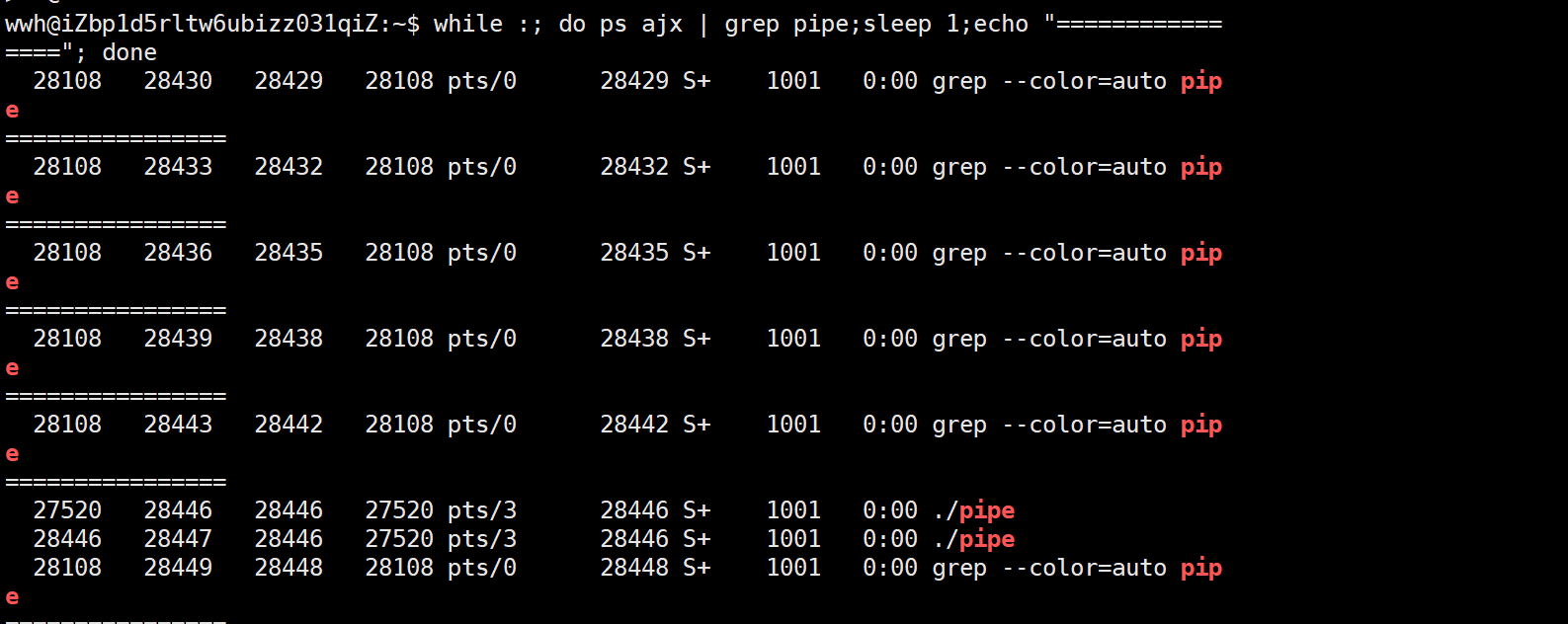
- 看第二行的 PPID (28446) ,它正好等于第一行的 PID (28446)。
- 结论: 进程
28447确实是由进程28446创建的。证明fork()执行成功。
状态分析 (STAT 列 S+): - 你看到的
S+表示 Sleep (睡眠) 状态,且位于前台进程组 (+)。 - 为什么都在睡眠?
- 子进程: 代码里写了
sleep(1),所以它大部分时间在睡。 - 父进程: 代码里写了
read(...)。因为子进程每秒才发一次数据,管道大部分时间是空的,所以父进程被 阻塞 (Blocked) 了,在等待数据到来。这也是一种睡眠状态。
- 子进程: 代码里写了
这次结果也表示:
- 通信成功: 父进程打印出了 "child say: ...",说明它成功从管道读到了子进程写入的数据。
- PID 对应: 这里打印的
pid:28447和上面ps监控到的子进程 PID 完全一致。
3-1 一切皆文件的思想:
我们看到这个代码,是不是也说明Linux下一切都是文件:Linux/Unix 系统中 "一切皆文件" 的哲学思想,它将管道(pipe)视为这一思想的具体体现:
1. 核心思想:一切皆文件
- 在 Linux 中,许多资源(如硬件设备、数据流、网络连接等)都被抽象为 文件描述符(File Descriptor) ,可以通过统一的文件操作接口(如
read()、write()、open()、close())进行读写。 - 管道 也不例外------它本质上是一个内核缓冲区,通过两个文件描述符(一个读端、一个写端)提供给进程使用。
2. 管道与文件的相似性
- 统一的接口 :
- 管道和普通文件一样,通过文件描述符进行读写。
- 例如:
write(fd[1], buf, size)向管道写入,read(fd[0], buf, size)从管道读取。
- 重定向的通用性 :
- Shell 中管道符
|可以将一个进程的输出(stdout)直接连接到另一个进程的输入(stdin)。 - 这与文件重定向(如
>、<)使用相同的底层机制,只是数据源不同(管道是内存缓冲区,文件是磁盘)。
- Shell 中管道符
3. 为何说"迎合了一切皆文件"
-
管道不需要特殊的行为设计------程序员只需用处理文件的思维去操作它。
-
例如,以下代码可能用于文件或管道(仅文件描述符不同):
char buffer[100]; read(fd, buffer, sizeof(buffer)); // 可能是文件,也可能是管道
4. 注意:管道 ≠ 普通文件
- 临时性:管道数据存在于内存,除非使用命名管道(FIFO),否则无持久化存储。
- 单向性:普通文件可随机读写,而匿名管道通常是单向的(一端只读,一端只写)。
- 同步性:管道读写可能阻塞(如无数据时读会等待),而文件读写直接由磁盘驱动。
3-2 实验继续拓展:
刚刚我们的实验让子进程它每次写入都等个1秒钟,父进程会出现一切正常,等每次子进程写入之后,他才会写入,这也体现了,这管道通讯的同步性。
如果,我们改变父进程的读取时间,让他每次读取都等个1秒钟,子进程一直写入,我们再看看会怎么样?父进程如下,子进程只需注释sleep(1)即可。
cpp
void ParentRead(int wfd) {
char buff[1024];
while(true) {
ssize_t n = read(wfd,buff,sizeof(buff) - 1);
if(n > 0) {
buff[n] = 0;
std:: cout << "child say:" << buff << std::endl;
sleep(1);
}
else if(n == 0) {
std::cout << "n : " << n << std::endl;
std:: cout << "no input" << std::endl;
break;
}
else {
break;
}
}
}我们发现会有一下现象:
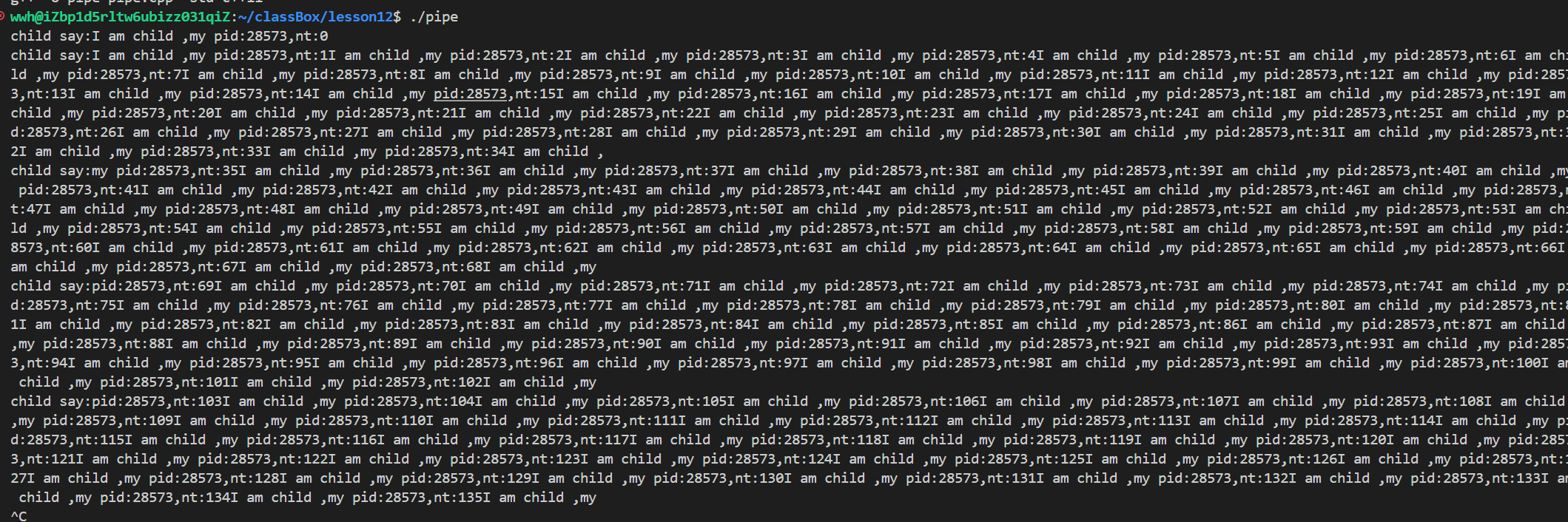
每次1秒钟读出来的都是不一样的。如果子进程写入很多次,那么缓冲区被挤满了,写不进去,子进程是被阻塞的,直到父进程读取,才能释放,子进程才能继续写。
这样也体现了进程之间的管道通讯的同步性和其他的特性:
1. 它是"面向字节流"的 (Byte Stream)
你会发现,父进程读取时,可能一次 read 就读到了子进程写的三四次内容。
- 管道里没有"消息边界"。子进程写了 "Hello" "World",管道里就是 "HelloWorld"。
- 父进程
read(fd, buf, 1024)的意思是:"有多少给我多少,最多给 1024 字节"。如果管道里堆积了 500 字节,它就一次性全拿走。
2. 它是自带"流量控制"的 (Flow Control)
- 同步性的另一面 :
- 读端快,写端慢(上一个实验):读端阻塞,等写端。
- 写端快,读端慢(这个实验):写端写满缓冲区后阻塞,等读端腾位置。
总结:
本文介绍了 Linux 下进程间通信的匿名管道 机制:利用 pipe() 系统调用创建一个单向的内存缓冲区(文件描述符数组 pipefd[2],0 为读端、1 为写端),父子进程通过继承文件描述符实现单向数据传输;管道遵循"一切皆文件"的设计哲学,支持字节流读写、自带流量控制(写满阻塞、为空阻塞),但不保证消息边界,需配合 sleep 或同步机制协调读写节奏,适用于具有亲缘关系的进程间快速、临时的数据交换场景。
感谢各位对本篇文章的支持。谢谢各位点个三连吧!

