📚AI Infra系列文章
随着深度学习模型的参数量从百万级跃升至千亿级,部署和推理的计算、存储、带宽压力急剧增加。尤其在边缘设备和低延迟应用中,庞大的模型不仅占用显存 ,还拖慢推理速度。

模型压缩与加速技术(量化、剪枝、蒸馏等)就是为了解决这个问题:在尽可能保持精度的前提下,降低模型大小和推理延迟。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案:
- 为什么模型压缩后推理速度能显著提升?
- 量化、剪枝、蒸馏之间的核心区别是什么?
- 如何组合多种压缩方法,获得更优的性能/精度平衡?
1. 量化(Quantization)
量化是将模型参数和计算过程从高精度(FP32)映射到低精度(如 INT8、FP16、BF16),减少存储与计算开销。
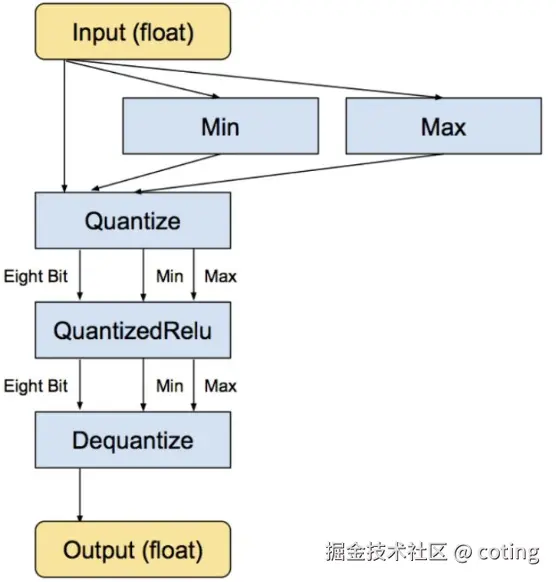
量化可以压缩存储空间 ,FP32 占 4 字节,INT8 仅占 1 字节,理论上体积可减至 1/4。同时可以加速计算,低精度运算能充分利用硬件的 SIMD / Tensor Core,加快推理。
常见方法包括PTQ(**Post-Training Quantization)和QAT(Quantization-Aware Training) **
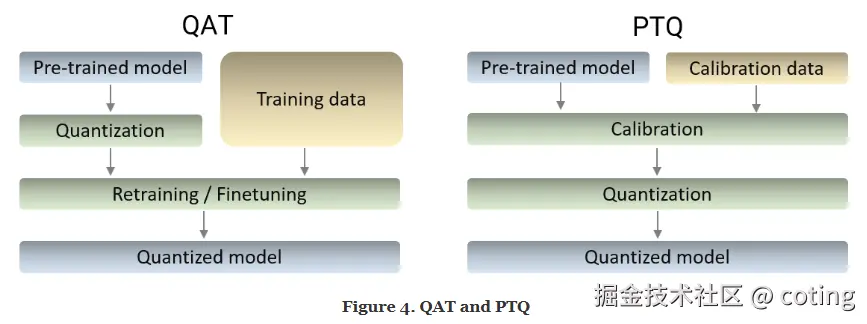
QAT训练过程中模拟量化效果,能够实现较高的精度。PTQ训练后直接量化,无需重新训练,简单但精度下降可能较大。
2. 剪枝(Pruning)
剪枝通过移除模型中冗余或不重要的权重/神经元,减少参数量和计算量。
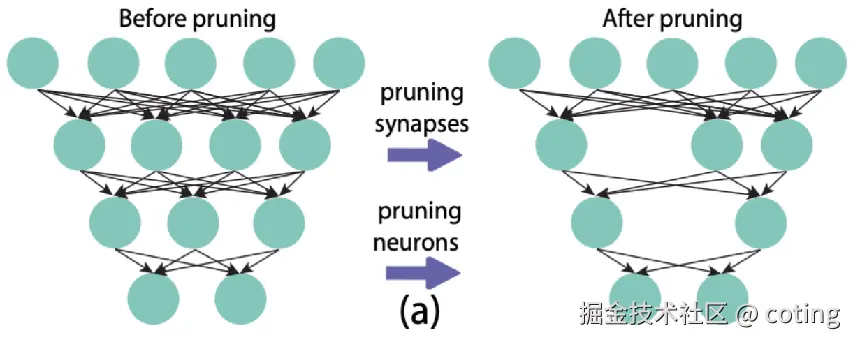
剪枝包括:
- 非结构化剪枝:移除单个权重(稀疏化矩阵),压缩率高但硬件利用率低。
- 结构化剪枝:移除整个通道/卷积核/注意力头,硬件加速友好。
剪枝能直接减少模型参数量和计算量(FLOPs),并且可以与量化结合,进一步压缩。
3. 知识蒸馏(Knowledge Distillation)
知识蒸馏通过让小模型(学生)学习大模型(老师)的输出分布,在更小的模型中复现大模型性能。
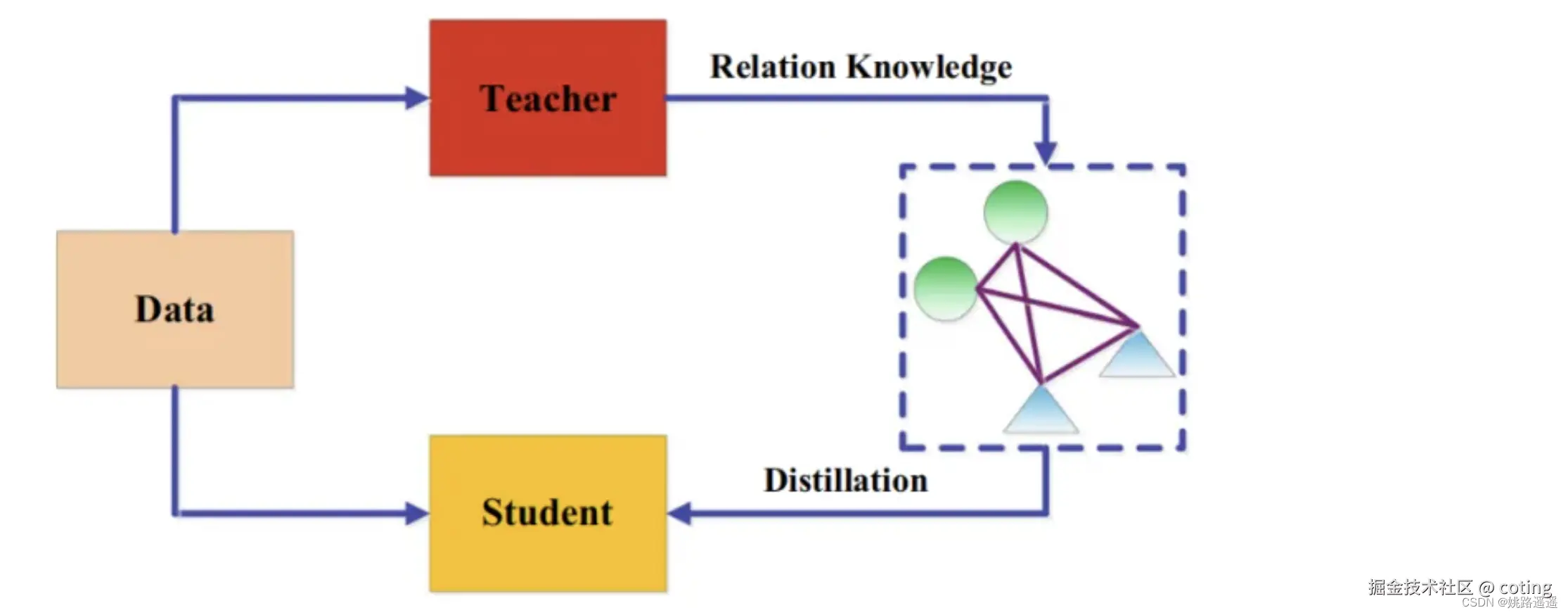
- 老师提供soft labels(概率分布),比one-hot标签包含更多信息。
- 学生模型结构可完全不同,更灵活。
知识蒸馏可以显著减小模型体积,同时保留大部分性能,但是需要额外的蒸馏训练过程。
4. 组合策略
在工业部署中,通常会组合多种方法:
- 剪枝 → 去除冗余结构。
- 量化 → 降低计算精度。
- 蒸馏 → 保留性能。
- 再配合 TensorRT / OpenVINO / TVM 等推理引擎优化。
不同方法对推理加速的影响(以Transformer为例):
| 方法 | 压缩率 | 推理加速 | 精度下降 |
|---|---|---|---|
| INT8 量化 | ~4x | 1.5-3x | 0.5-2% |
| 结构化剪枝 | ~2-4x | 1.5-2.5x | 1-3% |
| 蒸馏 | ~2-6x | 2-4x | 0-2% |
| 组合策略 | ~6-10x | 3-6x | ≤1% |
最后,我们回答一下文章开头提出的问题
- 为什么模型压缩后推理速度能显著提升?
低精度运算减少计算量和内存访问;剪枝减少参数和FLOPs;蒸馏用更小模型直接减少推理步骤。
- 量化、剪枝、蒸馏之间的核心区别是什么?
量化:降低精度;剪枝:移除冗余结构;蒸馏:训练小模型模仿大模型。
- 如何组合多种压缩方法?
先剪枝减少冗余,再量化降低精度,最后通过蒸馏恢复精度,并配合推理引擎获得最佳性能。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting !
以上内容部分参考了 PyTorch/TensorFlow 官方文档与实际部署案例,非常感谢,如有侵权请联系删除。