在自然语言处理和计算机视觉领域,模型规模的扩大已经催生了无数突破,但强化学习(RL)领域的类似进展却一直难以实现。大多数RL研究仍在使用2-5层的浅层网络架构,而如今的LLaMA和Stable Diffusion等模型早已拥有数百层。
NeurIPS 2025最佳论文奖由普林斯顿大学与OpenAI的合作研究,他们成功将RL网络深度扩展至1024层,在自监督强化学习任务上实现了性能2-50倍的提升。这项研究不仅证明了深度scaling对RL的有效性,还观察到了与模型规模相关的"突现现象"------当网络达到特定深度阈值时,智能体会突然学会全新的技能和行为模式。

项目代码:
wang-kevin3290.github.io/scaling-crl...
论文链接:
这项工作的主要贡献是展示了一种将这些构建模块集成到单个RL方法中的方法,表现出强大的可扩展性:
- 经验可扩展性:我们观察到显著的性能提升,在一半的环境中超过20倍,并且优于其他标准的目标条件基线方法。这些性能增益对应于随着规模扩大而出现的定性上不同的策略。
- 网络架构中的深度扩展:虽然许多先前的RL工作主要关注增加网络宽度,但他们通常在扩展深度时报告有限甚至负回报。相比之下,我们的方法解锁了沿深度轴扩展的能力,产生的性能改进超过了仅扩展宽度所带来的改进。
- 经验分析:我们对扩展方法中的关键组件进行了广泛分析,揭示了关键因素并提供了新的见解。
实验
- 实验设置
所有RL实验都使用JaxGCRL代码库,它基于Brax和MJX促进快速在线GCRL实验。使用的具体环境是一系列运动、导航和机器人操作任务,详情见附录B。我们使用稀疏奖励设置,仅当智能体在目标附近时r=1。对于评估,我们测量智能体接近目标的时间步数(共1000步)。当将算法的性能报告为单个数字时,我们计算训练最后五个周期的平均得分。
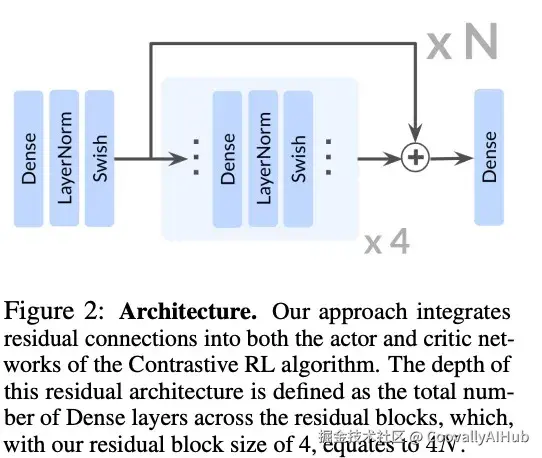
我们采用了ResNet架构中的残差连接,每个残差块由四个重复单元组成,每个单元包括一个全连接层、一个层归一化层和Swish激活函数。我们在残差块的最终激活之后立即应用残差连接,如图2所示。在本文中,我们将网络的深度定义为架构中所有残差块的全连接层总数。
- 对比RL中的深度扩展
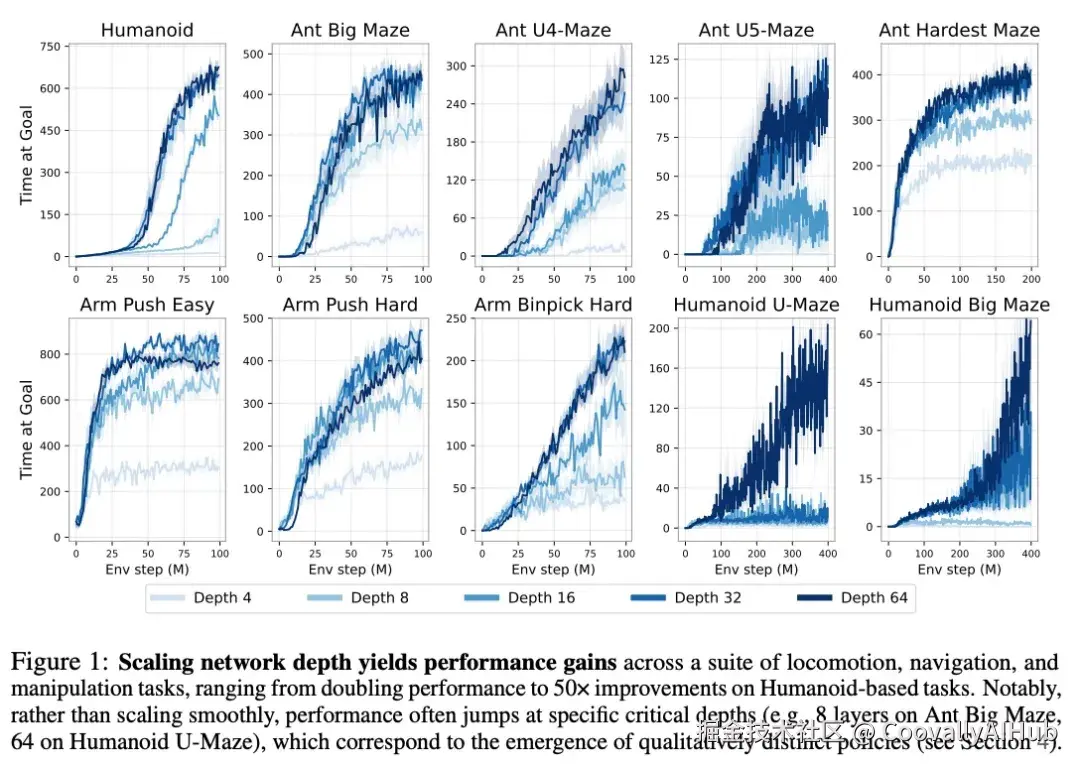
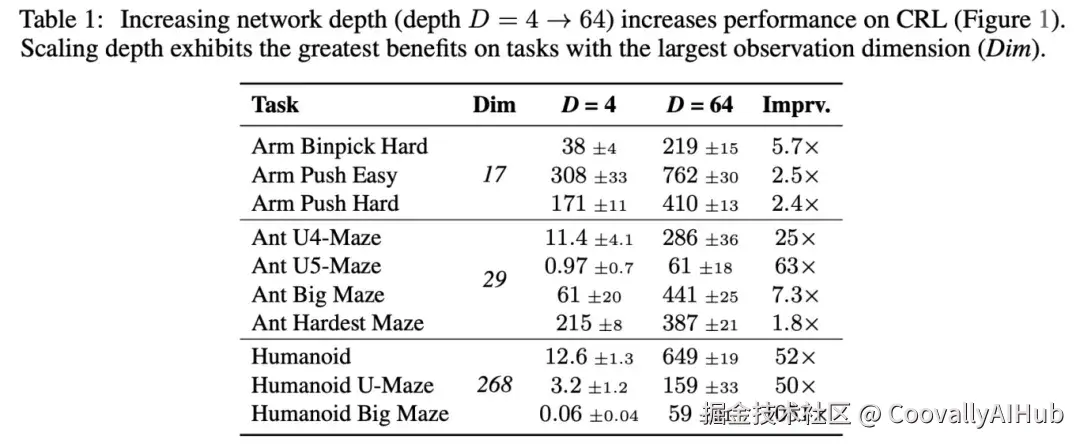
我们首先研究增加网络深度如何提高性能。JaxGCRL基准测试和相关先前工作都使用深度为4的MLP,因此我们将其作为基线。相比之下,我们将研究深度为8、16、32和64的网络。图1中的结果表明,更深的网络在多种运动、导航和操作任务中实现了显著的性能改进。与先前工作中典型的4层模型相比,更深的网络在机器人操作任务中实现了2-5倍的增益,在长视野迷宫任务(如Ant U4-Maze和Ant U5-Maze)中实现了超过20倍的增益,在类人机器人任务中实现了超过50倍的增益。深度达到64的完整性能提升表格在表1中提供。
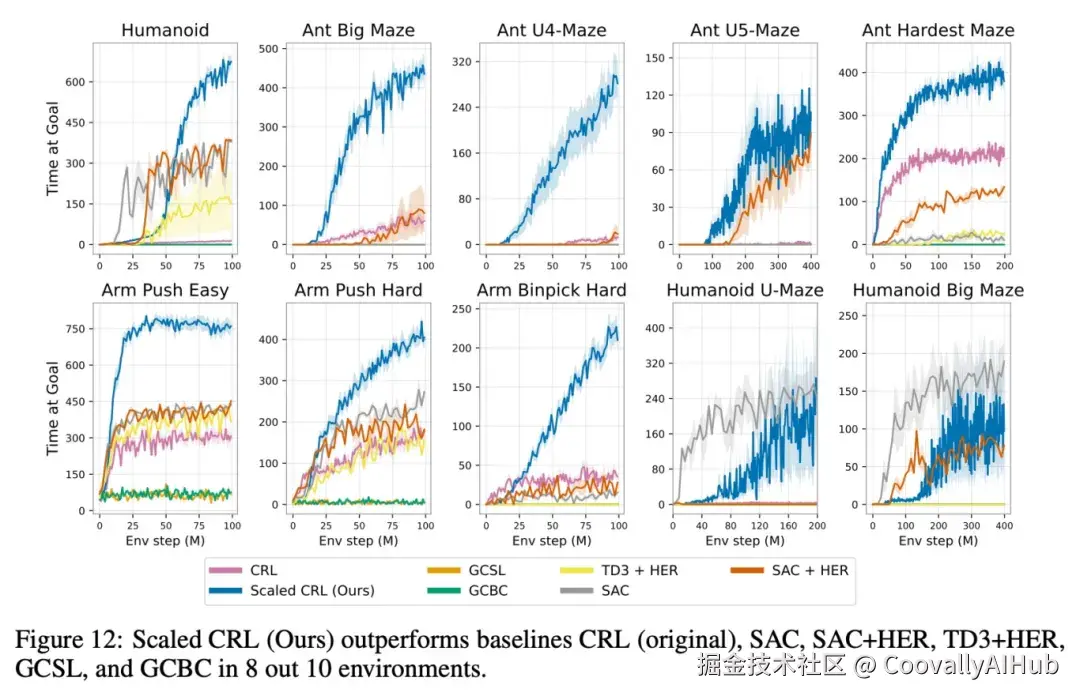
在图12中,我们展示了相同10个环境的结果,但与SAC、SAC+HER、TD3+HER、GCBC和GCSL进行了比较。扩展CRL带来了实质性的性能改进,在10个任务中的8个任务中优于所有其他基线方法。唯一的例外是SAC在Humanoid Maze环境中,早期表现出更高的样本效率;然而,扩展后的CRL最终达到了可比的性能。这些结果强调了扩展CRL算法的深度能够在目标条件强化学习中实现最先进的性能。
- 对CRL扩展重要的因素
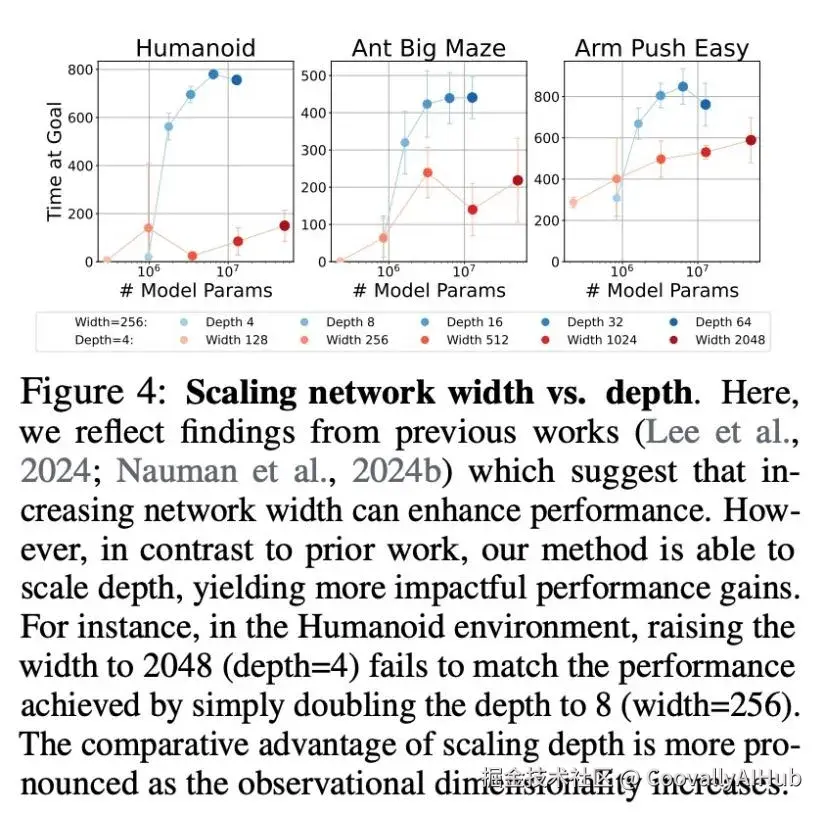
宽度vs深度。过去的文献表明,扩展网络宽度可能是有效的。在图4中,我们发现扩展宽度在我们的实验中也有帮助:更宽的网络(深度保持为4) consistently 优于更窄的网络。然而,深度似乎是一个更有效的扩展轴:仅仅将深度加倍到8(宽度保持为256)在所有三个环境中都优于最宽的网络。深度扩展的优势在Humanoid环境(观察维度268)中最为明显,其次是Ant Big Maze(维度29)和Arm Push Easy(维度17),这表明比较收益可能随着观察维度的增加而增加。另外请注意,参数数量随宽度线性增长,但随深度二次增长。作为比较,一个具有4个MLP层和2048个隐藏单元的网络大约有3500万个参数,而一个深度为32、隐藏单元为256的网络只有大约200万个参数。因此,在固定的FLOP计算预算或特定内存约束下运行时,深度扩展可能是提高网络性能的更计算高效的方法。
扩展行动者vs评论家网络。为了研究行动者和评论家网络中扩展的作用,图6展示了三个环境中不同行动者和评论家深度组合的最终性能。先前的工作侧重于扩展评论家网络,发现扩展行动者会降低性能。相比之下,虽然我们确实发现在三个环境中的两个(Humanoid, Arm Push Easy)中扩展评论家影响更大,但我们的方法受益于联合扩展行动者网络,其中一个环境(Ant Big Maze)显示行动者扩展的影响更大。因此,我们的方法表明,扩展行动者和评论家网络可以在提高性能方面发挥互补作用。

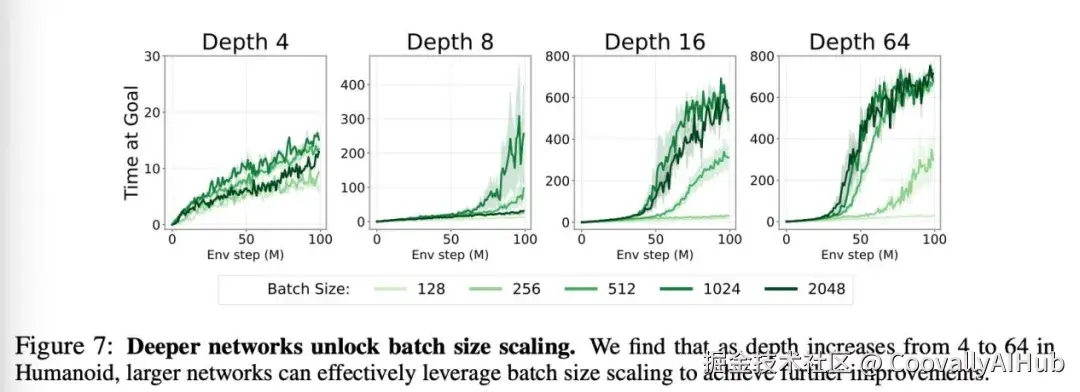
深度网络解锁批大小扩展。放大批大小在机器学习的其他领域已经得到很好的确立。然而,这种方法在强化学习(RL)中并未有效转化,先前的工作甚至报告了对基于值的RL的负面影响。确实,在我们的实验中,仅仅为原始CRL网络增加批大小仅产生边际性能差异(图7,左上角)。
- 部分经验"缝合"能力
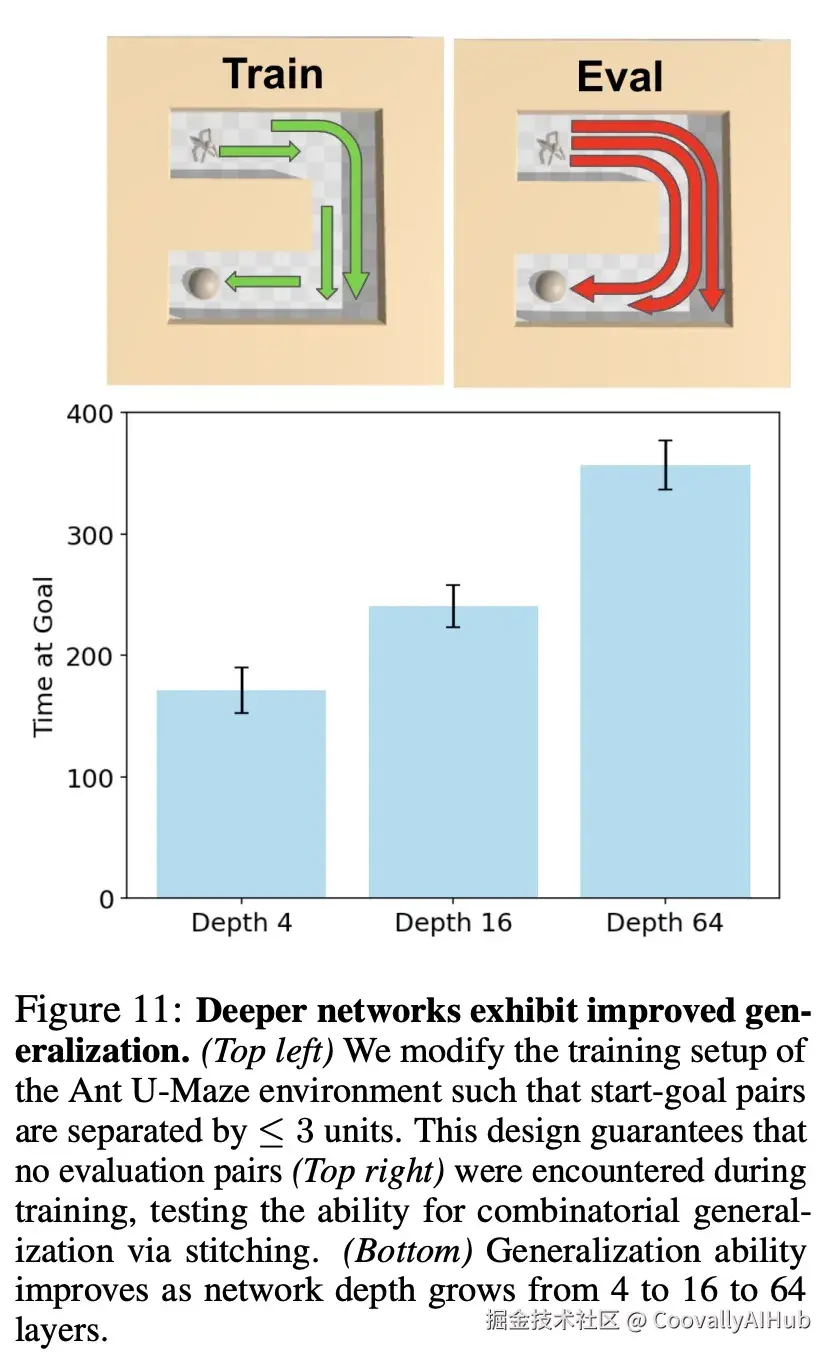
在泛化实验中,训练只使用最多3个单位距离的起始-目标对,但测试要求解决6个单位距离的任务。结果显示,深度4网络泛化能力有限,深度16网络取得中等成功,而深度64网络表现出色,表明更深网络能够将短距离经验"缝合"起来解决长距离任务。
对具身智能的启示
这项NeurIPS最佳论文的研究对正在兴起的具身智能领域具有重要启示:
- 自主技能获取
在具身智能应用中,为每个任务设计奖励函数是不现实的。自监督RL使智能体能够通过自主探索获得通用技能,而不需要针对每个任务的精细奖励设计。
- 复杂行为涌现
深层网络催生的emergent behaviors表明,通过scaling可能自然产生解决复杂物理任务所需的基本技能,如平衡、导航和操作等。
- 适应高维空间
具身智能通常涉及高维观察空间(如视觉、本体感觉),而研究表明深度scaling在高维环境中益处更加明显。
- 从交互中学习
与主要依赖现有数据集的监督学习不同,RL方法通过联合优化模型和数据收集过程,解决了"数据从哪里来"的根本问题。
结语
这项NeurIPS 2025最佳论文的研究打破了"强化学习难以从模型规模中受益"的传统观念,证明了深度scaling是自监督RL的强大催化剂。当大多数研究仍在小心翼翼地增加网络宽度时,这项工作勇敢地向深度维度探索,最终获得了丰厚的回报。
获奖意义:该研究荣获NeurIPS最佳论文奖,标志着强化学习scaling研究正式进入主流AI研究视野,为未来大模型时代的RL研究奠定了坚实基础。
对于具身智能领域,这项工作指出了一个有前景的方向:通过自监督RL与深度scaling的结合,可能催生能够通过自主探索获得通用物理理解能力的具身智能体。虽然前路依然漫长,但这无疑是向着能够自行训练大型模型的RL系统迈出的坚实一步。
这项研究不仅提供了具体的技术方案,更重要的是为整个领域的scaling探索打开了新的思路------有时候,突破就隐藏在我们尚未充分探索的维度中。