本内容是对 RustConf Chian 2025系列演讲中 迈向易用的Rust 内容的翻译与整理。推荐点击链接观看原视频。
你好,我住在温哥华。今天我要谈的是学习 Rust 的难点、Rust 工具链的现状、语言可能的演进路径、现有机制,以及我将提出的一个可用于演进 Rust 语言的潜在新增机制。
先简单介绍一下我自己。我从 2015 年开始使用 Rust,2016 年开始为项目做贡献,2017 年起成为 Rust 编译器团队成员。我的主要关注点是让语言和工具链尽可能易用,让工具链能以人类的方式与人沟通,而不仅仅是以编译器工程师的方式。这转化为我在诊断信息方面投入了大量精力。

很多人在考虑是否用 Rust 做项目或开始学习 Rust 时都会问我:Rust 究竟有多容易上手?这个问题比看起来复杂,因为它背后还有更基础的问题。Rust 到底要让什么变得容易?让某件事更容易,可能会使另一件事变得更难。还要问:对谁来说容易?你期望的用户是谁?为资深工程师设计的语言,与为初学者设计的语言,需求非常不同。Scratch、Python、Java 的目标都不一样。最后,还得问:是否应该"容易"?这是个有点古怪的问题,但如果为了"容易"而牺牲了你项目的其他目标,可能反而会把你带到一个并不想去的地方。

要正确回答这些问题,你必须理解语言的目标,并且知道 Rust 是什么,这样才能判断"Rust 是否容易使用"。Rust 是一个灵活的系统编程语言,能够表达类似于更动态语言的高级概念。这句引言经常被提起,今天早些时候你也看过:"Rust 是一门让每个人都能构建可靠且高效软件的语言。"我们都知道什么是编程语言,不需要展开。"赋能"(empowering)意味着语言的主要目标之一是让人们能做成事,我们要确保每一位用户都能完成任务。"每个人"(everyone)这个词没有限定,我们不把自己限制于某类用户,我们希望无论背景、领域、经验水平,都能支持。当然,我们永远不可能在所有方面都做到"属于每个人",但我们可以朝这个方向努力。接下来是"构建可靠且高效的软件"。这与"每个人"的目标存在间接冲突。为了可靠与高效,Rust 所做的许多设计与"易学性"、与"易重构性"直接冲突。这就是我想讨论的问题的一部分。
Rust 对自己施加了一些限制:它需要无处不在地运行。在我看来,Rust 的潜在使用范围极广:你可以写跑在微控制器上的代码,也可以写跑在浏览器里的代码,几乎涵盖两者之间的所有场景。能做到这一点的语言非常少。但如果有某个语言特性会妨碍这种灵活性,我们就无法拥有它。Rust 占据了非常特定的定位:AOT(提前编译)、无 GC、保证内存安全,同时采纳了许多现代语言的设计敏感性。其他语言都会在上述某一点上做权衡,这是有理由的。满足这些点意味着你必须承担额外的复杂性。对我们而言,这是值得的。

因为 Rust 专注于性能、可靠性、生产力,任何不符合这些明确目标的潜在特性都会被拒绝。那些会阻碍从其他语言(比如 Swift)迁移者入门的设计,如果对这些目标有明确收益,仍可能被采纳;同时我们会尽可能采取缓解措施,提高其易用性。Rust 有个我认为应该更常被讨论的核心精神:它是一门"契约"的语言。

举个例子:在 Rust 中表达泛型有两种方式。其一是类型参数,经单态化处理---也就是对传入的每个具体类型,编译器都会生成一份独立函数,最终二进制里会有对应类型数量的代码副本。其二是 trait object(dyn trait),通过 vtable 指针间接调用,带来另一组权衡:二进制可能更小、代码复杂度可能降低,但会有性能成本。根据你做的事,你可能会选择其一或其二。对比 Java:在语义上"万物皆 trait object",经由 vtable 间接调用。但 Java 有 JVM 和 JIT,会插装代码,观察哪些泛型重复出现,然后执行等效于前者的单态化以提速。复杂性被转移到实现侧(JVM 工程师承担),语言本身则较少暴露表达力。这只是一个例子,展示 Rust 如何把并非对所有人都"有用"的复杂性暴露出来。Rust 可能让人产生误解:复杂性始终存在。你可以写看起来很高层的代码,甚至把一段 Python 代码几乎逐字翻译也能跑通,但语言与语义的复杂性一直都在。一旦偏离"易路",你就会直面"难点"。例如闭包在外观上类似其他语言,但一旦涉及借用并尝试执行或传递闭包,你可能立刻遭遇借用检查器错误,且在不重写代码结构的情况下难以甚至无法解决。这就是当你违反了代码中表达的契约时会发生的事。

当前语言状态比 2015 年 5 月 1.0 发布时好太多了。当时甚至不能链式调用方法。一些因其他特性而"理应存在"的特性后来被补上,比如关联常量:常量在 1.0 里有,但 trait 里的常量没有,很快就补齐了。这种演进持续进行中。顺带一提,Rust 的易用性不只是语言本身,还包括文档、工具链、库,以及编译器诊断是否可读可懂。正如所说,语言状态不是静止的:我们前进、改进。时间推移带来更多文档、更多以易用性为导向的库、更好的诊断与语言演化。今天学 Rust 的体验,会比一年后学 Rust 更难一些。

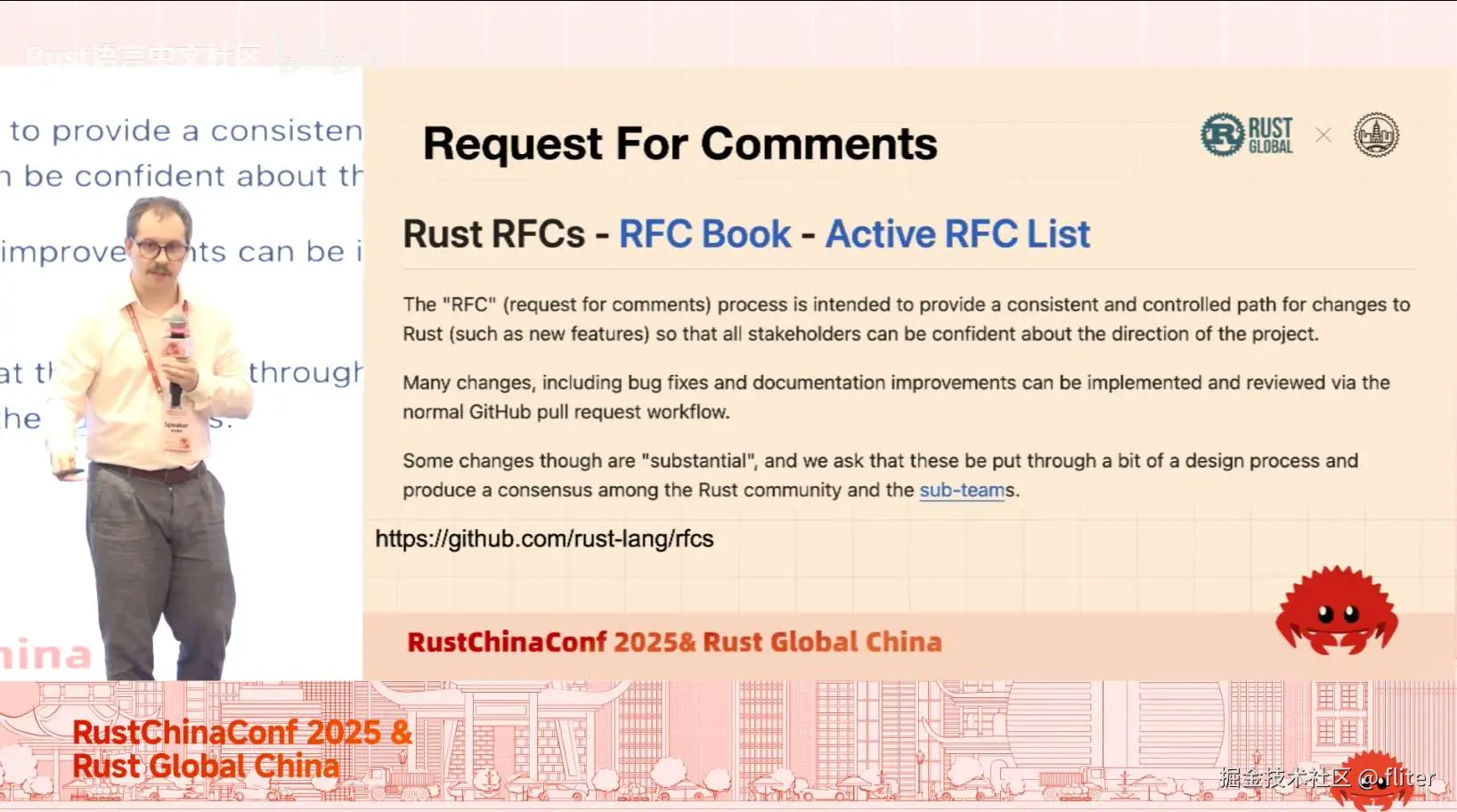
关于语言如何演进,机制多样:我们有 RFC 流程(请求评议),有模板和一系列章节,说明特性是什么、为什么需要、纳入语言的代价、如何教授该特性、考虑过但放弃的设计等。这个流程至今带着我们前进,也会继续存在并带我们走向未来,但它非常聚焦于"具体特性"。我们还有 MCP(重大变更提案),更偏战术层面,用于重构编译器或修改某个特性的底层行为,只要不产生用户可见影响。还有之前提到的"项目目标"(project goals),我会稍微展开。它们最终都会汇聚成 nightly 特性,并最终通过 RFC 稳定。我们有一个仓库存放所有发布过的 RFC,有模板可循。但这一切并非从那里开始,它从你开始。Rust 的特性不会凭空出现,必须有人提出需求,我们才会考虑和讨论。举个例子:项目成员 Copsol 发现一个特性可以让"newtype 模式"(不展开,挺简单)更易用。他不是从写 RFC 开始的,而是先与他人交流、吸收反馈,写成自己的文字,然后发成博客,再发一个 pre-RFC(非正式的"我有个想法")到 internals 论坛供大家讨论。经过一轮轮交流后,他提交了 RFC,被接受,如今已实现。这个过程不是只有项目成员才能做。只要你有具体用例,就可以推动。最终由语言团队、编译器团队等项目团队讨论并决定是否契合。



MCP 更偏内部,你无须太了解,它是项目成员之间就将要重构的事情进行轻量博弈的流程。至于项目目标,Niko 在 2023 年开始公开讨论,它用于表达那些不能整齐落入单一特性里的诉求。项目目标以 6 个月为周期进行组织,我们把目标汇集成主题,当前主题分为四大类,其中两三类都与易用性相关。在主题之下是项目目标,再由项目目标落到 RFC,最终实现。本质上,这是一套我们如何谈论特性、如何谈论语言变更与演进的共同话语体系。这一切最终转化为 nightly 特性。这里不是穷举,只列一些我想提的例子。nightly 特性所处的演进阶段不一:可能实现快好了,即将稳定;也可能我们还不确定当前实现是否正确、语义是否理想,甚至不确定这个特性是否适合语言。我会讲一堆特性,并非都必然进入语言,我只是用它们来探索一些想法。





"在模式中使用引用"(references in patterns):如果你熟悉 Scala,这相当于 unapply,允许对需要解引用才能匹配的指针进行模式匹配。比如我们匹配一个字符串字面量,但枚举变体里是 String。今天你做不到,必须把 match 改写成一串 if let 才能表达同样逻辑。再比如"结构体字段默认值":这已经在 nightly,将来可能稳定,表达"哪些字段必填、哪些可选"。
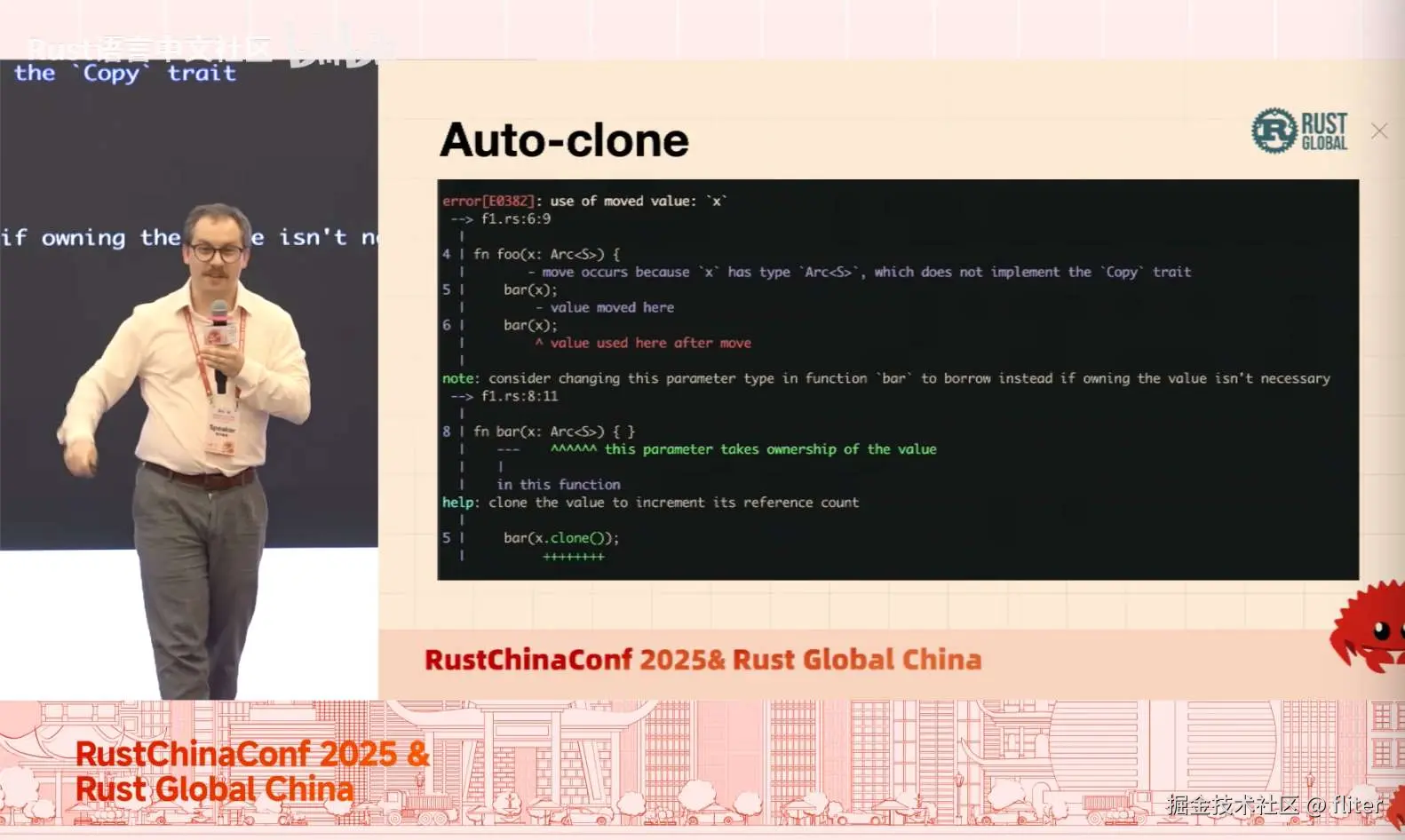

"自动克隆"(auto cloning):看这段代码,今天会不会(通过)编译?当然不会,是 move 错误。因为一旦消费了 Arc,它就不可用。编译器今天会提示你要么改函数签名避免消费,要么 clone。对 Arc 来说,90% 的时候你可能确实想 clone。我们可以让这段代码"自动为你工作"。



"部分 self 借用":很常见,多个字段同时访问,当前无法改变契约来表达而不触发借用检查器的抱怨。"生成器"(generators)等我就略过了,都是同一主题的变体:编译器能做而今天没有做的事情。比如"返回值类型推断":编译器实际上已经会推断,并给你建议"函数体是整数,请写上返回类型"。

我们可以把它变成语言的一部分,但对任何公开 API 来说会是大号"脚枪"(译者注: "big foot gun"是一个比喻,意思是这项技术可能会带来潜在的重大风险或问题,尤其是在公共API(应用程序编程接口)中使用时。可能暗示着这种功能容易被滥用或导致错误)。
同理,更"超前"的是类型参数推断,不再显式写出。你可能会点头说这很糟糕,Rust 不需要这些。你是对的,很多特性 Rust 并不需要,也永远不会发生。但如果我们有一个不被 Rust 既定要求束缚的东西呢?Rust 需要服务从微控制器到 Web 服务、到分布式系统、到前端应用的广泛场景。但这并非从一开始就是注定的。如果我们放宽某些限制,或许能得到一个"本质上 99% 是 Rust"的语言,但对一大类用例来说更易用。名字不重要,随便起。为了表达概念,我暂且称之为"Easy Rust"。


重要的是这个概念,早就被讨论过很多次,我不是第一个,也不会是最后一个。Without Boats (译者注: 知名Rust程序员,有相关公开演讲 RustLatam 2019 - Without Boats: Zero-Cost Async IO) 过去也提过一些想法。我想表达的是我的立场,因为人们说"我想要更容易的 Rust"时,心中所指未必相同。

回到之前的问题:为了什么更容易?给谁更容易?我个人对"Easy Rust"的限制是:它仍然是 Rust,仍与 Rust 互操作;从 crates.io 拿一个 Rust 库就应该能用;它应允许表达在 Rust 中原本很难表达的东西;它必须是"有内容"的。就我个人而言,凡是编译器可以给出建议的错误,都应该在 Easy Rust 中降级为警告,让你继续开发。但它仍然是一门"独立的语言",我们讨论的是 Easy Rust,而不是把 Rust 本身改成这样。比如,编译器可以对返回类型做推断,今天它只是提示;Easy Rust 会直接接受。再举一个我想过的更偏工具链的例子:如果你在跑测试套件,而代码库某处有类型错误,今天所有测试都不会运行,你得先修类型错误。如果工具链能"容忍"这点,先运行所有不涉及该项的测试,最后把测试错误与编译错误一并展示,而不是强迫你先修掉它---这甚至不是语言层面的改变,而是工具链上的改进。


让 Rust 变难的不全是语言本身。还有很多让代码更易用的机制:库的写法、库是否过多 trait 绑定、是否过度复杂、是否有好文档。通过写更易用的库,或利用宏填补一些空白,今天就能改进,无需新语言。但有了新语言,我们可以走得更远。并行存在 Rust 与 Easy Rust,对 Rust 有一个明确好处:为用户提供一条"限制更少"的学习路径;也为重构提供机会。你有一个 Rust 项目,可以把工具链切到"这是 Easy Rust",进行重构、探索 API 变化、打磨最终产物,然后再切回 Rust,处理需要清理的点。

它适用于哪些人?如前所述:重构的人、在学语言的人、在探索 API 长相的人,以及像我们大多数人一样---对性能并不关心的人。如果 Rust 没有 GC,但有枚举与模式匹配---那就是我最喜欢、也是我最常用的 Rust 部分。

当然,"第二种语言"的提案也有问题:它会增加工具链复杂度。如果第二种语言集成进 rustc,就意味着编译器工程师要面对另一种变体。我们已经有处理语言分歧的机制---"版本增量"(edition)系统,但今天的 edition 完全是"基于时间"的。我建议用同一机制来表达:把 Easy Rust 作为一种"为期一年的 Rust 版本增量"。在这一年内,我们提供完整的向后兼容(nightly 特性做不到),但会快速演进这门语言,探索那些我们对纳入 Rust 持谨慎态度的特性。这也让我们能观察 nightly 特性在"野外"的真实使用,及早识别"其实没问题"的东西,或"确实有问题"的东西,再考虑是否纳入 Rust。因为这是"不同语言、不同稳定性保证",我们可以更快、更大胆地演化。
还有其他问题:其他生态也尝试过,"更易用的第二语言"的市场定位会让一些人反感---"我不要辅助轮,我只要真语言"。但这不是二元对立,而是渐变:它既是更快写出高性能代码的一条路,也是通往 Rust 本体的良好上坡道。如前所述,我们已有许多演进机制,但我在此提议增加一门"语言"。


我希望大家参与进来,即便不是为了这门 Easy Rust。参与 RFC 流程,参与 internals 论坛上的讨论,参与 RFC 线程。如果你需要某些特性,请发声。我的时间到了,非常感谢。