1、变量
在进行编写支持变量功能的编译器的代码之前,我们先了解一下变量。
(1)、变量的基础理解
变量的概念:变量是计算机存储单元的抽象。变量建模了对存储单元的读写。
与变量所对应的是常量,常量的值是只读的,不会担心值被修改,这个性质非常有利于做优化。
变量因为值是变化的,我们常用 名字、地址、值、类型、作用域、生存期 等属性来分析变量。变量的引入对于前端和后端都引入了复杂性,但又必不可少。
(2)、变量复杂性的体现
语义分析:
• 确认变量是否定义
• 找到最近的定义(shadow)
• 检查运算符的类型操作合法性( + , - , * , / , = )
优化:
• 为了确定变量的值,优化阶段会跑很多分析,比如到达定值分析 ,活跃变量分析等,就是尽可能的在局部确定一个变量的值的范围,当范围确定,那么在局部变量也就变成不可变了,继而可以进行优化。
2、变量表达式编译器的实现s
(1)、测试文件
expr.txt 内容如下:
css
int a = 4, b = 5;
a + b * 3 - 1;(2)、实现框架
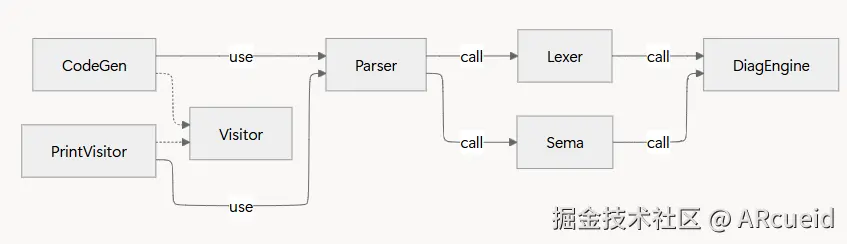
(3)、类型 (CType)
变量的类型 ,可以在文法定义中给出,在编译时就能确定类型。静态类型的语言,在编译期能做更多的优化和类型检测, 对于大型程序来说,静态类型的语言便于维护。
实现代码
我这里先只定义 int 类型
type.h
objectivec
#pragma once
enum class CTypeKind
{
Int
};
class CType
{
public:
CType(CTypeKind type, int size, int align)
: type(type), size(size), align(align)
{
}
static CType* getIntTy();
private:
CTypeKind type; // 种类
int size; // 字节数
int align; // 对齐数
};
objectivec
#include "type.h"
CType *CType::getIntTy()
{
static CType type(CTypeKind::Int, 4, 4);
return &type;
}(4)、作用域 (Scope)
变量中存在一个作用域 的概念,这个作用域相当于这个变量的生命周期,当程序离开了这个域,也就相当于这个变量的生命周期已经结束了。
并且变量的值 / 类型都和作用域有关。所以我们在收集变量定义的时候,要指定变量所在的作用域。变量的作用域在语义分析的时候,起作用。
实现代码
scope.h
c
#pragma once
#include "llvm/ADT/StringMap.h"
#include "llvm/ADT/StringRef.h"
#include "type.h"
#include <vector>
#include <memory>
enum class SymbolKind
{
LocalVariable
};
class Symbol
{
public:
Symbol(SymbolKind kind, CType* ty, llvm::StringRef name): kind(kind), ty(ty), name(name) {}
CType* getTy() { return ty; }
private:
SymbolKind kind;
CType* ty;
llvm::StringRef name;
};
class Env
{
public:
llvm::StringMap<std::shared_ptr<Symbol>> VariableSymbolTable;
};
class Scope
{
public:
Scope();
void EnterScope();
void ExitScope();
void AddVarSymbol(SymbolKind kind, CType* ty, llvm::StringRef name);
std::shared_ptr<Symbol> FindVarSymbol(llvm::StringRef name);
std::shared_ptr<Symbol> FindVarSymbolInCurEnv(llvm::StringRef name);
private:
std::vector<std::shared_ptr<Env>> Envs;
};
arduino
#include "scope.h"
Scope::Scope()
{
Envs.push_back(std::make_shared<Env>());
}
void Scope::EnterScope()
{
Envs.push_back(std::make_shared<Env>());
}
void Scope::ExitScope()
{
Envs.pop_back();
}
void Scope::AddVarSymbol(SymbolKind kind, CType *ty, llvm::StringRef name)
{
auto symbol = std::make_shared<Symbol>(kind, ty, name);
auto env = std::make_shared<Env>();
env->VariableSymbolTable.insert({name, symbol});
Envs.push_back(env);
}
std::shared_ptr<Symbol> Scope::FindVarSymbol(llvm::StringRef name)
{
for (auto it = Envs.rbegin(); it != Envs.rend(); it++)
{
auto &table = (*it)->VariableSymbolTable;
if (table.count(name) > 0)
{
return table[name];
}
}
return nullptr;
}
std::shared_ptr<Symbol> Scope::FindVarSymbolInCurEnv(llvm::StringRef name)
{
auto &table = Envs.back()->VariableSymbolTable;
if (table.count(name) > 0)
return table[name];
return nullptr;
}(5)、语义分析器 (Sema)
对于变量而言,存在变量的声明 ,变量的操作,为了辨别这些类型,需要通过**语义分析器(Sema)**进行识别。
实现代码
sema.h
c
#pragma once
#include "scope.h"
#include "ast.h"
class Sema // 语义分析
{
public:
std::shared_ptr<ASTNode> SemaVariableDeclNode(llvm::StringRef name, CType* ty);
std::shared_ptr<ASTNode> SemaVariableAccessNode(llvm::StringRef name);
std::shared_ptr<ASTNode> SemaAssignExprNode(std::shared_ptr<ASTNode> left, std::shared_ptr<ASTNode> right);
std::shared_ptr<ASTNode> SemaBinaryExprNode(std::shared_ptr<ASTNode> left, std::shared_ptr<ASTNode> right, OpCode op);
std::shared_ptr<ASTNode> SemaNumberExprNode(int value, CType* ty);
private:
Scope scope;
};
ini
#include "sema.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/Casting.h"
// 符号声明节点
std::shared_ptr<ASTNode> Sema::SemaVariableDeclNode(llvm::StringRef name, CType *ty)
{
auto symbol = scope.FindVarSymbolInCurEnv(name);
if (symbol) // 查找是否重定义
{
llvm::errs() << "redefine name: " << name << "\n";
return nullptr;
}
scope.AddVarSymbol(SymbolKind::LocalVariable, ty, name); // 添加到符号表
auto variableDecl = std::make_shared<VariableDecl>();
variableDecl->name = name;
variableDecl->type = ty;
return variableDecl;
}
std::shared_ptr<ASTNode> Sema::SemaVariableAccessNode(llvm::StringRef name)
{
auto symbol = scope.FindVarSymbol(name);
if (symbol == nullptr)
{
llvm::errs() << "can't use no define variable name: " << name << "\n";
return nullptr;
}
auto varAcc = std::make_shared<VariableAccessExpr>();
varAcc->name = name;
varAcc->type = symbol->getTy();
return varAcc;
}
std::shared_ptr<ASTNode> Sema::SemaAssignExprNode(std::shared_ptr<ASTNode> left, std::shared_ptr<ASTNode> right)
{
if (!left || !right)
{
llvm::errs() << "left or right can't be nullptr!\n";
return nullptr;
}
if (!llvm::isa<VariableAccessExpr>(left.get()))
{
llvm::errs() << "left must be left value!\n";
return nullptr;
}
auto assign = std::make_shared<AssignExpr>();
assign->left = left;
assign->right = right;
return assign;
}
std::shared_ptr<ASTNode> Sema::SemaBinaryExprNode(std::shared_ptr<ASTNode> left, std::shared_ptr<ASTNode> right, OpCode op)
{
auto binaryExpr = std::make_shared<BinaryExpr>();
binaryExpr->left = left;
binaryExpr->right = right;
binaryExpr->op = op;
return binaryExpr;
}
std::shared_ptr<ASTNode> Sema::SemaNumberExprNode(int value, CType* ty)
{
auto factorExpr = std::make_shared<NumberExpr>();
factorExpr->number = value;
factorExpr->type = ty;
return factorExpr;
}(6)、词法分析器 (Lexer)
文法定义
上一篇博客 《LLVM IR 学习手记(一):无量表达式编译器的实现与实践总结》我们知道了无量表达式的文法定义,那么对于变量表达式的文法定义在这里也需要重新了解:
sql
prog : (decl-stmt | expr-stmt)*
decl-stmt : "int" identifier ("," identifier (= expr)?)* ";"
expr-stmt : expr? ";"
expr : assign-expr | add-expr
assign-expr: identifier "=" expr
add-expr : mult-expr (("+" | "-") mult-expr)*
mult-expr : primary-expr (("*" | "/") primary-expr)*
primary-expr : identifier | number | "(" expr ")"
number: ([0-9])+
identifier : (a-zA-Z_)(a-zA-Z0-9_)*实现代码
基于之前无量表达式的词法分析器,我们仅需要添加关于变量表达式的一些新的代码即可。
lexer.h
arduino
#pragma once
#include "llvm/ADT/StringRef.h"
#include "llvm/Support/raw_ostream.h"
#include "type.h"
// char stream -> token
enum class TokenType
{
unknown, // 未知
number, // [0-9]+
indentifier,// 变量
kw_int, // int
plus, // +
minus, // -
star, // *
slash, // /
equal, // =
l_parent, // (
r_parent, // )
semi, // ;
comma, // ,
eof // end of file
};
class Token
{
public:
Token()
{
row = col = -1;
tokenType = TokenType::unknown;
value = -1;
}
void Dump();
public:
int row, col;
TokenType tokenType; // token 的种类
int value;
llvm::StringRef content;
CType *type;
};
class Lexer
{
public:
Lexer(llvm::StringRef sourceCode);
void NextToken(Token& token);
public:
const char * BufPtr;
const char * LineHeadPtr;
const char * BufEnd;
int row;
};
php
#include "lexer.h"
void Token::Dump()
{
llvm::outs() << "{" << content << ", row = " << row << ", col = " << col << "}\n";
}
bool IsWhiteSpace(char ch)
{
return ch == ' ' || ch == '\r' || ch == '\n';
}
bool IsDigit(char ch)
{
return ch >= '0' && ch <= '9';
}
bool IsLetter(char ch)
{
// a-z, A-Z, _
return (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || (ch == '_');
}
Lexer::Lexer(llvm::StringRef sourceCode)
{
BufPtr = sourceCode.begin();
LineHeadPtr = sourceCode.begin();
BufEnd = sourceCode.end();
row = 1;
}
void Lexer::NextToken(Token &token)
{
token.row = row;
// 过滤空格
while (IsWhiteSpace(*BufPtr))
{
if (*BufPtr == '\n')
{
row += 1;
LineHeadPtr = BufPtr + 1;
}
BufPtr++;
}
token.col = BufPtr - LineHeadPtr + 1;
// 判断是否到结尾了
if (BufPtr >= BufEnd)
{
token.tokenType = TokenType::eof;
return;
}
const char* start = BufPtr;
// 判断是否为数字
if (IsDigit(*BufPtr))
{
int len = 0;
int val = 0;
while (IsDigit(*BufPtr))
{
val = val * 10 + *BufPtr++ - '0';
len++;
}
token.value = val;
token.tokenType = TokenType::number;
token.content = llvm::StringRef(start, len);
token.type = CType::getIntTy();
}
else if(IsLetter(*BufPtr)) // 为变量
{
while(IsLetter(*BufPtr) || IsDigit(*BufPtr))
BufPtr++;
token.tokenType = TokenType::indentifier;
token.content = llvm::StringRef(start, BufPtr - start);
if(token.content == "int")
token.tokenType = TokenType::kw_int;
}
else // 为特殊字符
{
switch (*BufPtr)
{
case '+':
token.tokenType = TokenType::plus;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case '-':
token.tokenType = TokenType::minus;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case '*':
token.tokenType = TokenType::star;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case '/':
token.tokenType = TokenType::slash;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case '=':
token.tokenType = TokenType::equal;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case '(':
token.tokenType = TokenType::l_parent;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case ')':
token.tokenType = TokenType::r_parent;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case ';':
token.tokenType = TokenType::semi;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
case ',':
token.tokenType = TokenType::comma;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
default:
token.tokenType = TokenType::unknown;
BufPtr++;
break;
}
}
}测试结果
输出与测试文件一致,验证了 Lexer 的正确性。
(7)、语法分析器 (Parser)
这里代码也与词法分析器的代码同理,只需要在原有的基础上进行修改即可。
实现代码
ast.h
arduino
#pragma once
#include <vector>
#include <memory>
#include "llvm/IR/Value.h"
#include "type.h"
// prog : (expr? ";")*
// expr : term (("+" | "-") term)* ;
// term : factor (("*" | "/") factor)* ;
// factor : number | "(" expr ")" ;
// number: ([0-9])+ ;
enum class OpCode
{
add,
sub,
mul,
div
};
// 进行声明
class Program;
class Expr;
class VariableDecl;
class VariableAccessExpr;
class BinaryExpr;
class AssignExpr;
class NumberExpr;
// 访问者模式
class Visitor
{
public:
virtual ~Visitor() {}
virtual llvm::Value *VisitProgram(Program *p) = 0;
virtual llvm::Value *VisitVariableDecl(VariableDecl* decl) = 0;
virtual llvm::Value *VisitVariableAccessExpr(VariableAccessExpr* varaccExpr) = 0;
virtual llvm::Value *VisitAssignExpr(AssignExpr* assignExpr) = 0;
virtual llvm::Value *VisitBinaryExpr(BinaryExpr *binaryExpr) = 0;
virtual llvm::Value *VisitNumberExpr(NumberExpr *factorExpr) = 0;
};
// 语法树的公共节点
class ASTNode
{
public:
enum Kind
{
ND_VariableDecl,
ND_BinaryExpr,
ND_NumberExpr,
ND_VariableAccessExpr,
ND_AssignExpr
};
private:
const Kind kind;
public:
ASTNode(Kind kind) : kind(kind) {}
virtual ~ASTNode() {}
virtual llvm::Value *Accept(Visitor *v) { return nullptr; } // 通过虚函数的特性完成分发的功能
const Kind getKind() const { return kind; }
public:
CType *type;
};
// 变量声明节点
class VariableDecl : public ASTNode
{
public:
VariableDecl() : ASTNode(ND_VariableDecl) {}
llvm::Value *Accept(Visitor *v) override
{
return v->VisitVariableDecl(this);
}
static bool classof(const ASTNode *node) // 判断是否能进行指针的强转
{
return node->getKind() == ND_VariableDecl;
}
public:
llvm::StringRef name;
};
// 二元表达式节点
class BinaryExpr : public ASTNode
{
public:
BinaryExpr() : ASTNode(ND_BinaryExpr) {}
llvm::Value *Accept(Visitor *v) override
{
return v->VisitBinaryExpr(this);
}
static bool classof(const ASTNode *node) // 判断是否能进行指针的强转
{
return node->getKind() == ND_BinaryExpr;
}
public:
OpCode op;
std::shared_ptr<ASTNode> left;
std::shared_ptr<ASTNode> right;
};
// 赋值表达式节点
class AssignExpr : public ASTNode
{
public:
AssignExpr() : ASTNode(ND_AssignExpr) {}
llvm::Value *Accept(Visitor *v) override
{
return v->VisitAssignExpr(this);
}
static bool classof(const ASTNode *node) // 判断是否能进行指针的强转
{
return node->getKind() == ND_AssignExpr;
}
public:
std::shared_ptr<ASTNode> left;
std::shared_ptr<ASTNode> right;
};
// 数字表达式节点
class NumberExpr : public ASTNode
{
public:
NumberExpr() : ASTNode(ND_NumberExpr) {}
llvm::Value *Accept(Visitor *v) override
{
return v->VisitNumberExpr(this);
}
static bool classof(const ASTNode *node) // 判断是否能进行指针的强转
{
return node->getKind() == ND_NumberExpr;
}
public:
int number;
};
// 变量访问节点
class VariableAccessExpr : public ASTNode // 变量表达式
{
public:
VariableAccessExpr() : ASTNode(ND_VariableAccessExpr) {}
llvm::Value *Accept(Visitor *v) override
{
return v->VisitVariableAccessExpr(this);
}
static bool classof(const ASTNode *node) // 判断是否能进行指针的强转
{
return node->getKind() == ND_VariableAccessExpr;
}
public:
llvm::StringRef name;
};
// 目标程序
class Program
{
public:
std::vector<std::shared_ptr<ASTNode>> ExprVec;
};访问者模式的实现
为了更好的证明 AST,实现了 PrintVisitor 来进行打印表达式。
printVisitor.h
arduino
#pragma once
#include "ast.h"
#include "parser.h"
class PrintVisitor : public Visitor
{
public:
PrintVisitor(std::shared_ptr<Program> program);
public:
llvm::Value *VisitProgram(Program *p) override;
llvm::Value *VisitVariableDecl(VariableDecl *decl) override;
llvm::Value *VisitVariableAccessExpr(VariableAccessExpr *varaccExpr) override;
llvm::Value *VisitAssignExpr(AssignExpr *assignExpr) override;
llvm::Value *VisitBinaryExpr(BinaryExpr *binaryExpr) override;
llvm::Value *VisitNumberExpr(NumberExpr *factorExpr) override;
};
rust
#include "printVisitor.h"
PrintVisitor::PrintVisitor(std::shared_ptr<Program> program)
{
VisitProgram(program.get());
}
llvm::Value *PrintVisitor::VisitProgram(Program *p)
{
for (auto &expr : p->ExprVec)
{
expr->Accept(this);
llvm::outs() << "\n";
}
return nullptr;
}
llvm::Value *PrintVisitor::VisitVariableDecl(VariableDecl *decl)
{
if(decl->type == CType::getIntTy())
llvm::outs() << "int " << decl->name;
return nullptr;
}
llvm::Value *PrintVisitor::VisitVariableAccessExpr(VariableAccessExpr *varaccExpr)
{
llvm::outs() << varaccExpr->name;
return nullptr;
}
llvm::Value *PrintVisitor::VisitAssignExpr(AssignExpr *assignExpr)
{
assignExpr->left->Accept(this);
llvm::outs() << " = ";
assignExpr->right->Accept(this);
return nullptr;
}
llvm::Value *PrintVisitor::VisitBinaryExpr(BinaryExpr *binaryExpr)
{
// 后序遍历
binaryExpr->left->Accept(this);
switch (binaryExpr->op)
{
case OpCode::add:
llvm::outs() << " + ";
break;
case OpCode::sub:
llvm::outs() << " - ";
break;
case OpCode::mul:
llvm::outs() << " * ";
break;
case OpCode::div:
llvm::outs() << " / ";
break;
default:
break;
}
binaryExpr->right->Accept(this);
return nullptr;
}
llvm::Value *PrintVisitor::VisitNumberExpr(NumberExpr *factorExpr)
{
llvm::outs() << factorExpr->number;
return nullptr;
}测试结果
输出与测试文件一致,验证了 Parser 的正确性。
(8)、代码生成 (CodeGen)
将生成的抽象语法树 AST 转化成 LLVM IR。
实现代码
codegen.h
arduino
#pragma once
#include "ast.h"
#include "parser.h"
#include "llvm/IR/LLVMContext.h"
#include "llvm/IR/Module.h"
#include "llvm/IR/IRBuilder.h"
#include "llvm/ADT/StringMap.h"
// 通过访问者模式生成代码
class CodeGen : public Visitor
{
public:
CodeGen(std::shared_ptr<Program> program)
{
module = std::make_shared<llvm::Module>("expr", context);
VisitProgram(program.get());
}
public:
llvm::Value *VisitProgram(Program *p) override;
llvm::Value *VisitVariableDecl(VariableDecl *decl) override;
llvm::Value *VisitVariableAccessExpr(VariableAccessExpr *varaccExpr) override;
llvm::Value *VisitAssignExpr(AssignExpr *assignExpr) override;
llvm::Value *VisitBinaryExpr(BinaryExpr *binaryExpr) override;
llvm::Value *VisitNumberExpr(NumberExpr *factorExpr) override;
private:
llvm::LLVMContext context;
llvm::IRBuilder<> irBuilder{context};
std::shared_ptr<llvm::Module> module;
llvm::StringMap<llvm::Value *> varAddrMap;
};
rust
#include "codegen.h"
#include "llvm/IR/Verifier.h"
llvm::Value *CodeGen::VisitProgram(Program *p)
{
// 创建 printf 函数
auto printFunctionType = llvm::FunctionType::get(irBuilder.getInt32Ty(), {irBuilder.getInt8PtrTy()}, true);
auto printFunction = llvm::Function::Create(printFunctionType, llvm::GlobalValue::ExternalLinkage, "printf", module.get());
// 创建 main 函数
auto mainFunctionType = llvm::FunctionType::get(irBuilder.getInt32Ty(), false);
auto mainFunction = llvm::Function::Create(mainFunctionType, llvm::GlobalValue::ExternalLinkage, "main", module.get());
// 创建 main 函数的基本块
llvm::BasicBlock *entryBlock = llvm::BasicBlock::Create(context, "entry", mainFunction);
// 设置该基本块作为指令的入口
irBuilder.SetInsertPoint(entryBlock);
llvm::Value *lastVal = nullptr;
for (auto expr : p->ExprVec)
lastVal = expr->Accept(this);
irBuilder.CreateCall(printFunction, {irBuilder.CreateGlobalStringPtr("expr value: %d\n"), lastVal});
// 创建返回值
llvm::Value *ret = irBuilder.CreateRet(irBuilder.getInt32(0));
llvm::verifyFunction(*mainFunction);
module->print(llvm::outs(), nullptr);
return ret;
}
llvm::Value *CodeGen::VisitVariableDecl(VariableDecl *decl)
{
llvm::Type *ty = nullptr;
if (decl->type == CType::getIntTy())
ty = irBuilder.getInt32Ty();
llvm::Value *varAddr = irBuilder.CreateAlloca(ty, nullptr, decl->name);
varAddrMap.insert({decl->name, varAddr});
return varAddr;
}
llvm::Value *CodeGen::VisitVariableAccessExpr(VariableAccessExpr *varaccExpr)
{
llvm::Value *varAddr = varAddrMap[varaccExpr->name];
llvm::Type *ty = nullptr;
if (varaccExpr->type == CType::getIntTy())
ty = irBuilder.getInt32Ty();
return irBuilder.CreateLoad(ty, varAddr, varaccExpr->name);
}
llvm::Value *CodeGen::VisitAssignExpr(AssignExpr *assignExpr)
{
VariableAccessExpr *varAccExpr = (VariableAccessExpr *)assignExpr->left.get();
llvm::Value *leftValAddr = varAddrMap[varAccExpr->name];
llvm::Value *rightValue = assignExpr->right->Accept(this);
return irBuilder.CreateStore(rightValue, leftValAddr);
}
llvm::Value *CodeGen::VisitBinaryExpr(BinaryExpr *binaryExpr)
{
auto left = binaryExpr->left->Accept(this);
auto right = binaryExpr->right->Accept(this);
switch (binaryExpr->op)
{
case OpCode::add:
return irBuilder.CreateNSWAdd(left, right, "add"); // CreateNSW... 是防止溢出行为的
case OpCode::sub:
return irBuilder.CreateNSWSub(left, right, "sub");
case OpCode::mul:
return irBuilder.CreateNSWMul(left, right, "mul");
case OpCode::div:
return irBuilder.CreateSDiv(left, right, "div");
default:
break;
}
return nullptr;
}
llvm::Value *CodeGen::VisitNumberExpr(NumberExpr *factorExpr)
{
return irBuilder.getInt32(factorExpr->number);
}测试结果
生成的 IR 正确。
(9)、测试编译器
生成 IR 文件
bash
bin/expr test/expr.txt > test/expr.ll生成的 IR 内容
ini
; ModuleID = 'expr'
source_filename = "expr"
@0 = private unnamed_addr constant [16 x i8] c"expr value: %d\0A\00", align 1
declare i32 @printf(ptr, ...)
define i32 @main() {
entry:
%a = alloca i32, align 4
store i32 4, ptr %a, align 4
%b = alloca i32, align 4
store i32 5, ptr %b, align 4
%a1 = load i32, ptr %a, align 4
%b2 = load i32, ptr %b, align 4
%mul = mul nsw i32 %a1, %b2
%add = add nsw i32 %mul, 4
%sub = sub nsw i32 %add, 3
%a3 = load i32, ptr %a, align 4
%b4 = load i32, ptr %b, align 4
%mul5 = mul nsw i32 %b4, 3
%add6 = add nsw i32 %a3, %mul5
%sub7 = sub nsw i32 %add6, 1
%0 = call i32 (ptr, ...) @printf(ptr @0, i32 %sub7)
ret i32 0
}运行 IR
bash
lli test/expr.ll运行结果
bash
expr value: 18结果正确,验证了整个编译器的正确性和功能性。
总结
本文详细介绍了如何在无量表达式编译器的基础上扩展变量支持功能,涵盖了类型系统、作用域管理、语义分析等关键技术要点。通过完整的实现和测试,展示了如何将包含变量的表达式成功编译为LLVM IR并正确执行。这是LLVM IR学习系列的第二篇,后续将继续探讨更复杂的语言特性和编译技术。