在上篇文章我们介绍了
Google ML Kit体态识别模型。 今天我们就来介绍如何使用模型在 Flutter 项目中实现运动动作检测! 本文将展示篮球动作检测+拍球计数这一个demo,向大家展示运动识别的基本流程。
🏀🏀🏀 man!
最终效果图如下
核心思路
实现分为五个步骤:
- 视频加载与播放:使用
VideoPlayerController播放视频,并可通过慢速播放增加识别精度。 - 帧图像提取:利用
VideoThumbnail获取视频帧图像,降低分辨率以提高处理速度。 - 姿态识别:使用
PoseDetector检测人体关键点,尤其关注左右手腕的 Y 坐标。 - 骨骼可视化:使用
CustomPainter将关键点绘制在视频上,便于调试与展示。 - 动作识别与计数:通过左右手腕的上下运动判断一次拍球动作,并累加
计数。
思路实现
1️⃣ 视频加载与播放
使用 VideoPlayerController 加载本地或网络视频文件,进行播放。
dart
_controller = VideoPlayerController.file(File(videoPath))
..initialize().then((_) {
_controller.setPlaybackSpeed(0.5); // 慢速播放
_controller.play();
_analyzeVideoFrames();
});❗在本文的 demo 中,我们通过慢速播放视频进行动作识别,这样可以显著提高识别的精准度。但在实际生产环境中,如果想要实现实时动作识别,使用摄像头会更加高效。下面我们将进一步说明原因:
1.视频动作识别中,帧处理的
瓶颈:
读取视频帧需要解码:尤其是 mp4、mov 等压缩视频,每帧都需要
解码,比较耗时。生成缩略图:我们现在是通过
VideoThumbnail.thumbnailFile生成 JPEG 文件再做识别,会引入 I/O 操作的开销。
ML Kit Pose Detector处理帧也需要一定时间,尤其是每帧都生成新文件。2.相机流的优势
直接获取未压缩图像:Camera 或 CameraX/Camera2 获取的 Image 是原始像素数据,无需写入文件。
连续帧处理:可以直接用 InputImage.fromBytes 或 fromCameraImage 传给 ML Kit,更快。
避免I/O:不需要磁盘操作,只在内存里处理。
3.Flutter + 视频的限制
- Flutter 的
VideoPlayer只是渲染视频画面,没有提供逐帧访问 API。- 使用
VideoThumbnail生成帧,质量又压缩、还要写磁盘 → 速度慢。- 如果视频分辨率高或帧率高,处理会明显
掉帧。
2️⃣ 帧图像提取
从视频中提取指定时间点的缩略帧,并保存为 JPEG 图片。缩小分辨率和降低质量可以加快帧生成速度,便于后续使用 ML Kit 进行人体姿态识别。
dart
final thumbPath = await VideoThumbnail.thumbnailFile(
video: videoPath, // 视频文件路径
thumbnailPath: framePath, // 输出帧图片路径
imageFormat: ImageFormat.JPEG, // 图像格式为 JPEG
timeMs: posMs, // 指定时间点(毫秒)截取帧
quality: 50, // 图像质量 0-100,降低质量可提高生成速度
maxHeight: 480, // 最大高度,缩小分辨率减少计算量
maxWidth: 640, // 最大宽度
);3️⃣ 姿态识别
初始化谷歌 ML Kit Pose Detector 模型,进行姿态识别,返回结果 poses。
poses 是一个 List,每个 Pose 包含多个 PoseLandmark,比如手腕、肘部、膝盖等关键点坐标(x、y、z):
- X:关键点在图像
水平方向的位置(像素或归一化值)。 - Y:关键点在图像
垂直方向的位置(像素或归一化值)。 - Z:关键点在摄像头前后的
深度位置(通常是相对值,用于表示关键点离摄像头的远近)。
dart
// 初始化 Pose Detector
final _poseDetector = PoseDetector(
options: PoseDetectorOptions(mode: PoseDetectionMode.stream),
);
// 体态识别,得到关键点坐标
final poses = await _poseDetector.processImage(InputImage.fromFile(File(thumbPath)));❓Pose Detector
stream模式 vssingle image模式:
- PoseDetectionMode.stream:适合处理视频流或连续帧,保持模型在内存中常驻,提高
实时性能。- PoseDetectionMode.singleImage:适合
一次性图片识别,每次调用都会初始化模型,适用于静态图片。⭐所以
stream模式 更适合我们这种情况 逐帧分析视频或摄像头输入!
4️⃣ 骨骼可视化
绘制骨骼图的核心就是坐标映射 + 骨骼连线 + 关键点,其他逻辑(如 padding、缩略图适配)都是辅助保证可视化效果。
dart
// 缩放与坐标映射
final scaleX = w / (maxX - minX);
final scaleY = h / (maxY - minY);
final scale = scaleX < scaleY ? scaleX : scaleY;
final offsetX = (w - (maxX - minX) * scale) / 2 + padding;
final offsetY = (h - (maxY - minY) * scale) / 2 + padding;
Offset toCanvas(PoseLandmark lm) => Offset(
(lm.x - minX) * scale + offsetX,
(lm.y - minY) * scale + offsetY,
);
...
// 绘制骨骼连线
final connectPairs = [
[PoseLandmarkType.leftShoulder, PoseLandmarkType.rightShoulder],
[PoseLandmarkType.leftShoulder, PoseLandmarkType.leftElbow],
[PoseLandmarkType.leftElbow, PoseLandmarkType.leftWrist],
// ...其他关键点连接对
];
for (final pair in connectPairs) {
final lm1 = pose.landmarks[pair[0]];
final lm2 = pose.landmarks[pair[1]];
if (lm1 != null && lm2 != null) {
canvas.drawLine(toCanvas(lm1), toCanvas(lm2), paintLine);
}
}
...
// 绘制关键点
for (var lm in pose.landmarks.values) {
if (lm.type == PoseLandmarkType.leftWrist || lm.type == PoseLandmarkType.rightWrist) {
paintPoint.color = Colors.green;
} else if (lm.type == PoseLandmarkType.leftIndex || lm.type == PoseLandmarkType.rightIndex) {
paintPoint.color = Colors.blue;
} else {
paintPoint.color = Colors.red;
}
canvas.drawCircle(toCanvas(lm), 3, paintPoint);
}骨骼图可以直观显示人体姿态,通过观察骨骼点的相对位置和运动轨迹,帮助我们快速调试动作识别准确性和调整阈值。
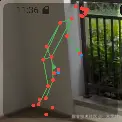

5️⃣ 动作识别与计数
1.动作枚举类
dart
enum HumanAction {
idle,
dribbling,
unknown
}当手腕上下移动时,动作标记为 dribbling。
静止或微小抖动时,动作标记为 idle。
2.计算手腕位移
dart
double leftDiff = leftWristY - previousLeftWristY;
double rightDiff = rightWristY - previousRightWristY;leftDiff 、rightDiff 表示本帧与上一帧手腕纵坐标的差值。
正数 → 手腕向下移动
负数 → 手腕向上移动
3.判断手腕方向(上下运动)
dart
if ((leftDiff + rightDiff) / 2 > wristThreshold) {
wristMovingDown = true;
wristMovingUp = false;
currentAction = HumanAction.dribbling;
} else if ((leftDiff + rightDiff) / 2 < -wristThreshold) {
wristMovingUp = true;
wristMovingDown = false;
currentAction = HumanAction.dribbling;
} else {
currentAction = HumanAction.idle;
}使用左右手平均值,保证双手拍球动作都能被检测到。
阈值 wristThreshold 用来忽略轻微抖动,避免误计。
4. 计数逻辑(下落开始计数,上升完成一次拍球)
dart
if (wristMovingDown && !isCounting) isCounting = true;
if (wristMovingUp && isCounting) {
dribbleCount++;
isCounting = false;
}下落阶段:wristMovingDown && !isCounting → 开始计数
上抬阶段:wristMovingUp && isCounting → 完成一次拍球
防止连续帧误计,多次触发只算一次完整拍球。
5.保存本帧坐标供下一帧计算
dart
previousLeftWristY = leftWristY;
previousRightWristY = rightWristY;
}更新上一帧手腕坐标,为下一帧运动计算做准备。
6️⃣ 总结
通过谷歌 ML Kit Pose Detection 体态识别模型 ,我们可以在视频或摄像头流中实现各种动作识别与计数。
- 核心是要找到每项运动的
关键检测点,千万不要写一长串各种参数之间复杂的判断,那样只会渐行渐远,直到爆炸🤡。 - 同时使用简单防抖逻辑保证计数精确。
- 此方法可扩展到其他动作识别和运动分析场景,欢迎大家踊跃尝试。
7️⃣ 源码
接下来是喜闻乐见的源码环节
👏👏👏持续关注,下期再见🥳🥳🥳