一、项目简介
Video-subtitle-extractor(简称 VSE)是一款免费开源的视频硬字幕提取工具,它能够从视频文件中识别并提取硬编码字幕,并自动生成对应的 SRT 外挂字幕文件。VSE 支持多达 87 种语言的字幕提取,涵盖常见的简体中文、英文、日文、韩文、阿拉伯文、繁体中文、法文、德文、俄文、西班牙文、葡萄牙文、意大利文等,能够满足全球不同用户的多样化需求。同时,它还提供了快速、自动、精准三种提取模式,以适应不同场景下对速度和准确性的要求。原帖链接:https://github.com/YaoFANGUK/video-subtitle-extractor。
二、使用教程
1、复制链接https://github.com/YaoFANGUK/video-subtitle-extractor到浏览器进行访问。
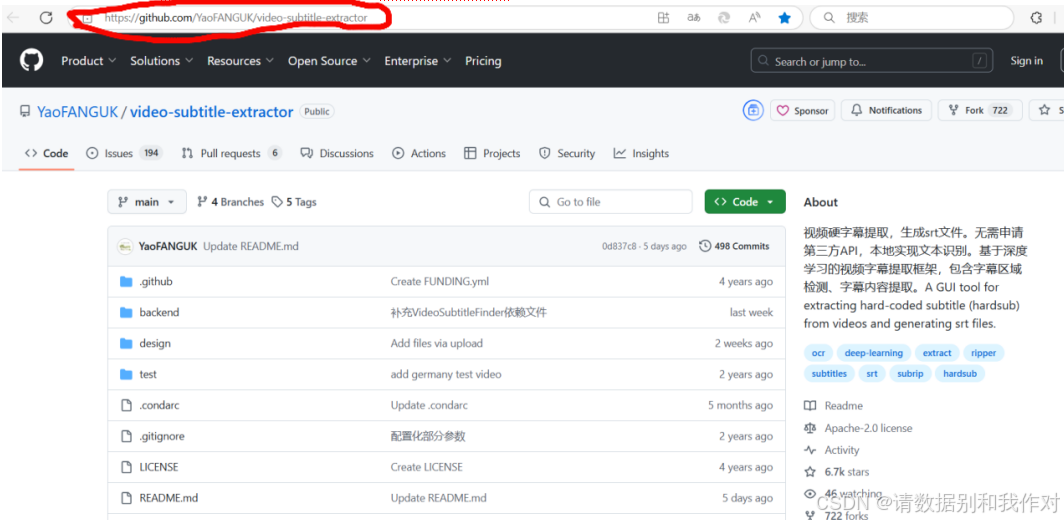
2、下滑找到"下载地址",根据自己电脑系统配置下载合适的压缩包(注意:GPU版本需要电脑有Nvidia显卡,安装路径不能出现中文和空格),这里下载的是Windows 绿色版本v2.0.0(CPU)。
3、将下载后的压缩包进行解压,得到如下文件夹。
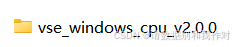
4、打开文件夹vse,找到"gui.exe"并双击打开。
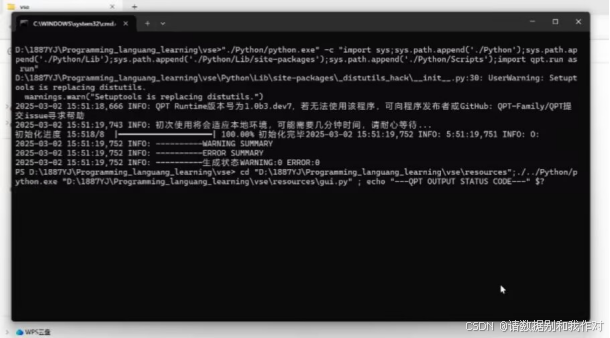
5、打开后,电脑会弹出以下界面,识别本地环境,查看文件夹中文件是否完整等。
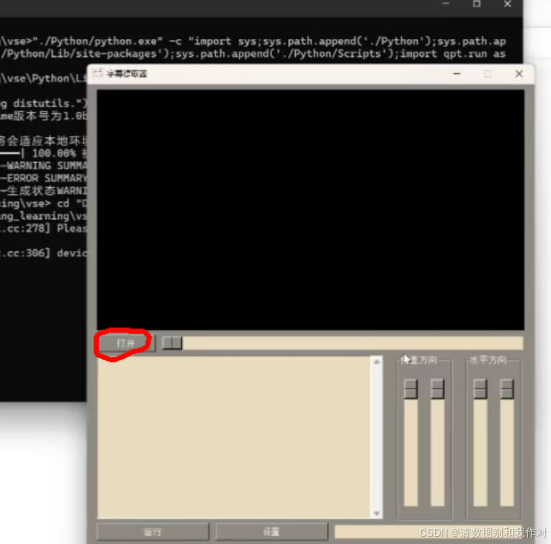
6、接着会弹出字幕提取界面。首先点击打开,在电脑中选择需要进行字幕提取的视频文件并打开。
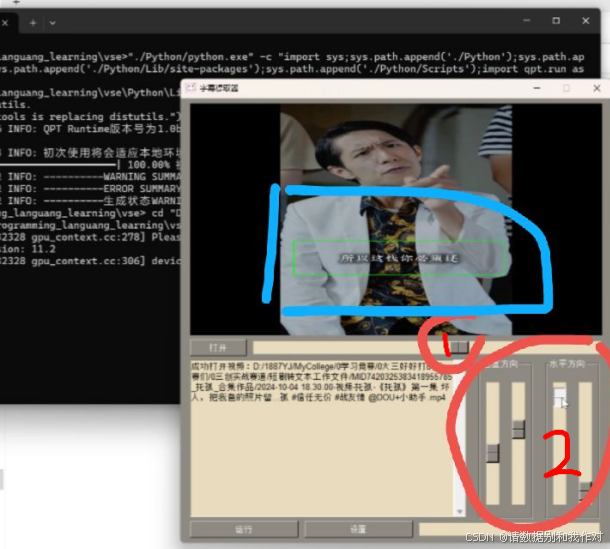
7、选择的视频就会出现在字幕提取页面的视频框中,然后我们需要拖动红色圈1(即进度条),查看字幕位置,并确保蓝色圈中的绿色方框能够完全框住字幕,如果出现字幕在绿色方框外,那么我们就可以拖到红色圈2来调整绿色方框的大小及位置。
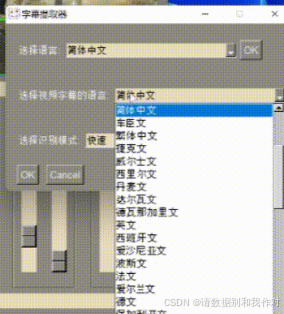
8、当整个视频的字幕均在绿色方框中时,点击下方"设置",选择字幕的语言以及识别模式。其中识别模式包括快速、自动和精准三类,快速模式就是使用轻量模型,快速提取字幕,可能会丢失少量字幕、存在少量错别字;自动模式就是自动判断模型,一般在CPU下使用轻量模型,GPU下使用精准模型,提取字幕速度较慢,可能丢失少量字幕、几乎不存在错别字;精准模式就是使用精准模型,在GPU下逐帧检测,不会丢失字幕,几乎不存在错别字,但速度非常慢。
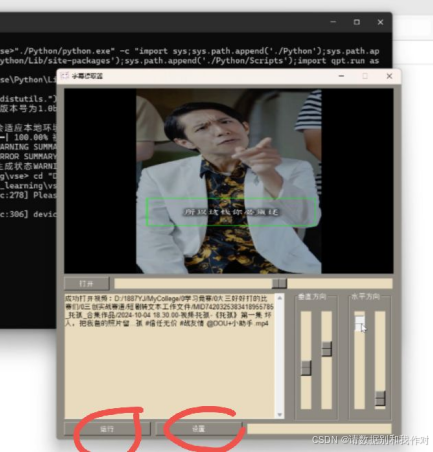
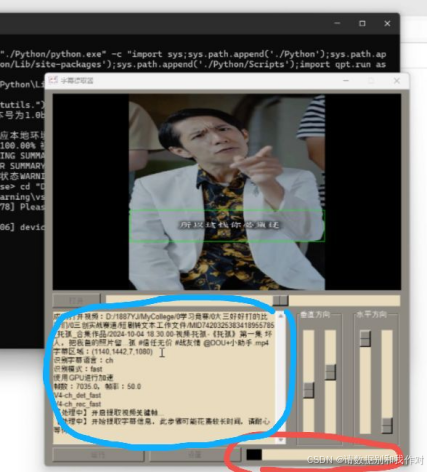
9、当一切设置完成后,就点击下方的"运行",下方蓝色圈中的位置会显示刚刚设置的内容,以及处理进程,而红色圈中的位置则会显示字幕提取的进度。
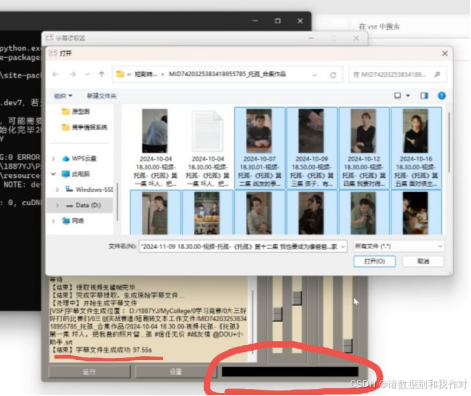
10、当字幕提取完成后,下方进度条黑色拉满,左下方框中也会显示"结束",以及视频字幕提取所用时间。当上一批视频字幕提取完成后,我们还可以继续点击打开,选择更多地视频进行字幕提取,流程与前面相同。
注意:在字幕提取过程中,如果出现报错或者生成的字幕文件为空,这里有4种解决办法,1、检查原视频是否有损伤 2、检查原视频是否有字幕 3、检查字幕位置是否框选正确 4、不批量选择视频,一次只打开一个视频。以上方法尝试后若仍无法解决,则可放弃。
11、该工具进行字幕提取得到的为srt字幕文件,暂时并不支持生成txt文本文件,若想获得txt文本文件,可通过下方代码进行转换。
python
import os
import glob
import shutil
def srt_to_txt(srt_file, txt_file):
with open(srt_file, 'r', encoding='utf-8') as file:
lines = file.readlines()
with open(txt_file, 'w', encoding='utf-8') as file:
for line in lines:
stripped_line = line.strip()
# 忽略空行和看起来像时间戳或序号的行
if not stripped_line or '-->' in stripped_line or stripped_line.isdigit():
continue
file.write(stripped_line + '\n')
def convert_all_srt_in_folder(folder_path, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
srt_files = glob.glob(os.path.join(folder_path, '*.srt')
for srt_file in srt_files:
# 构造输出的TXT文件名(不包含路径)
txt_filename = os.path.splitext(os.path.basename(srt_file))[0] + '.txt'
txt_file = os.path.join(output_folder, txt_filename)
print(f'Converting {srt_file} to {txt_file}')
try:
srt_to_txt(srt_file, txt_file)
print(f'Successfully converted {srt_file}')
except Exception as e:
print(f'Failed to convert {srt_file}: {e}')
input_folder = r'' # 输入文件夹路径
output_folder = r'' # 输出文件夹路径
convert_all_srt_in_folder(input_folder, output_folder)结语
如果大家觉得有帮助,请多多点赞收藏支持一下,谢谢大家。如果遇到什么问题,也非常欢迎大家私信。