前言
浏览器渲染引擎(如 Blink、Gecko、WebKit)的核心任务,是将 HTML、CSS、JavaScript 等静态资源转化为屏幕上可交互的视觉界面。这一过程并非单一步骤,而是分为资源加载、HTML 解析、CSS 解析、样式计算、布局、绘制、合成七大连贯阶段,各阶段既相互独立又存在依赖关系,部分阶段还会因动态交互(如 JS 修改)触发重复执行。社区中有很多讲这些详细流程解析的文章,这里面想了解的同学去自行搜下,这里面不在阐述。我们下面先来看
导航与文档提交(渲染前准备)
从用户输入 URL 到渲染进程开始解析 HTML 的过程称为 "导航",关键步骤包括:
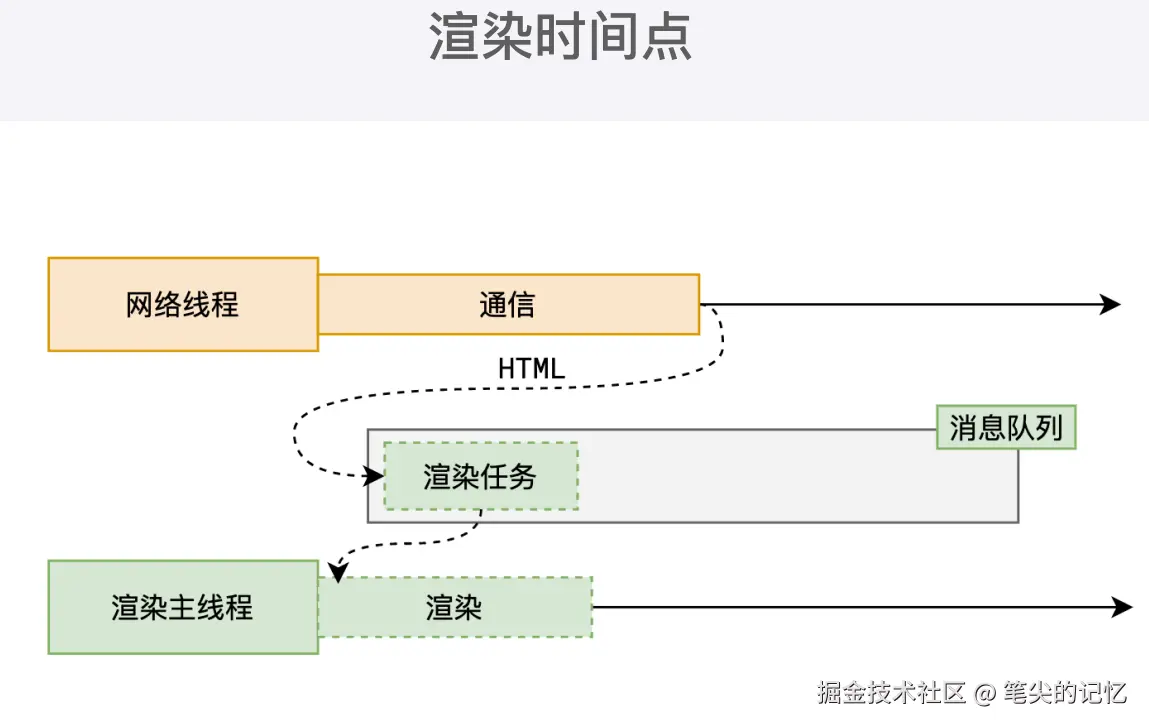
- 浏览器进程接收 URL 并转发给网络进程,发起 HTTP 请求。
- 网络进程解析响应头,若为
text/html类型则通知浏览器进程创建渲染进程。 - 渲染进程与网络进程建立数据管道,接收 HTML 数据流(边加载边解析,类似于管道流)。
- 渲染进程向浏览器进程确认 "文档提交",浏览器进程更新地址栏、历史记录等状态。
渲染进程渲染阶段(DOM→图层树)
- 主线程核心渲染阶段(DOM→图层树)
-
构建 DOM 树 :HTML 解析器将字节流转换为 Token,再组装为 DOM 树(忽略非法标签,保证容错性)。解析时维护 Token 栈来确定节点父子关系,例如
<div>生成 StartTag Token 压栈,对应</div>EndTag Token 出栈。 -
样式计算 :将 CSS 样式表转换为标准化的 styleSheets(如将
bold转为font-weight:700),结合 CSS 继承 / 层叠规则,计算每个 DOM 节点的最终样式(包括浏览器默认样式)。 -
布局阶段 :创建只包含可见节点的布局树(如
display:none节点被排除),计算节点的位置、尺寸等几何信息,例如根据width:50%和父节点宽度计算实际像素值。 -
分层与图层树生成:为提升渲染效率,渲染引擎会将布局树拆分为多个图层,满足以下条件的节点会被单独分层:
- 拥有层叠上下文属性(如
position:absolute、z-index、opacity)。 - 需要剪裁的节点(如
overflow:auto)。 - 包含 CSS 滤镜、3D 变换的节点。
- 拥有层叠上下文属性(如
- 合成线程渲染阶段(图层→屏幕显示)
- 绘制列表生成:主线程为每个图层生成绘制指令(如 "绘制矩形"" 绘制文字 "),类似" 绘画步骤说明书 "。
- 图块划分与光栅化:合成线程将图层划分为 1024×1024 或 256×256 的图块,优先处理视口附近的图块;光栅化线程池将图块转换为位图(GPU 加速时利用 GPU 进程并行处理)。
- 页面合成与显示 :合成线程向浏览器进程发送
DrawQuad命令,浏览器进程根据指令将位图合成最终页面,通过显卡显示到屏幕上。
各阶段分析
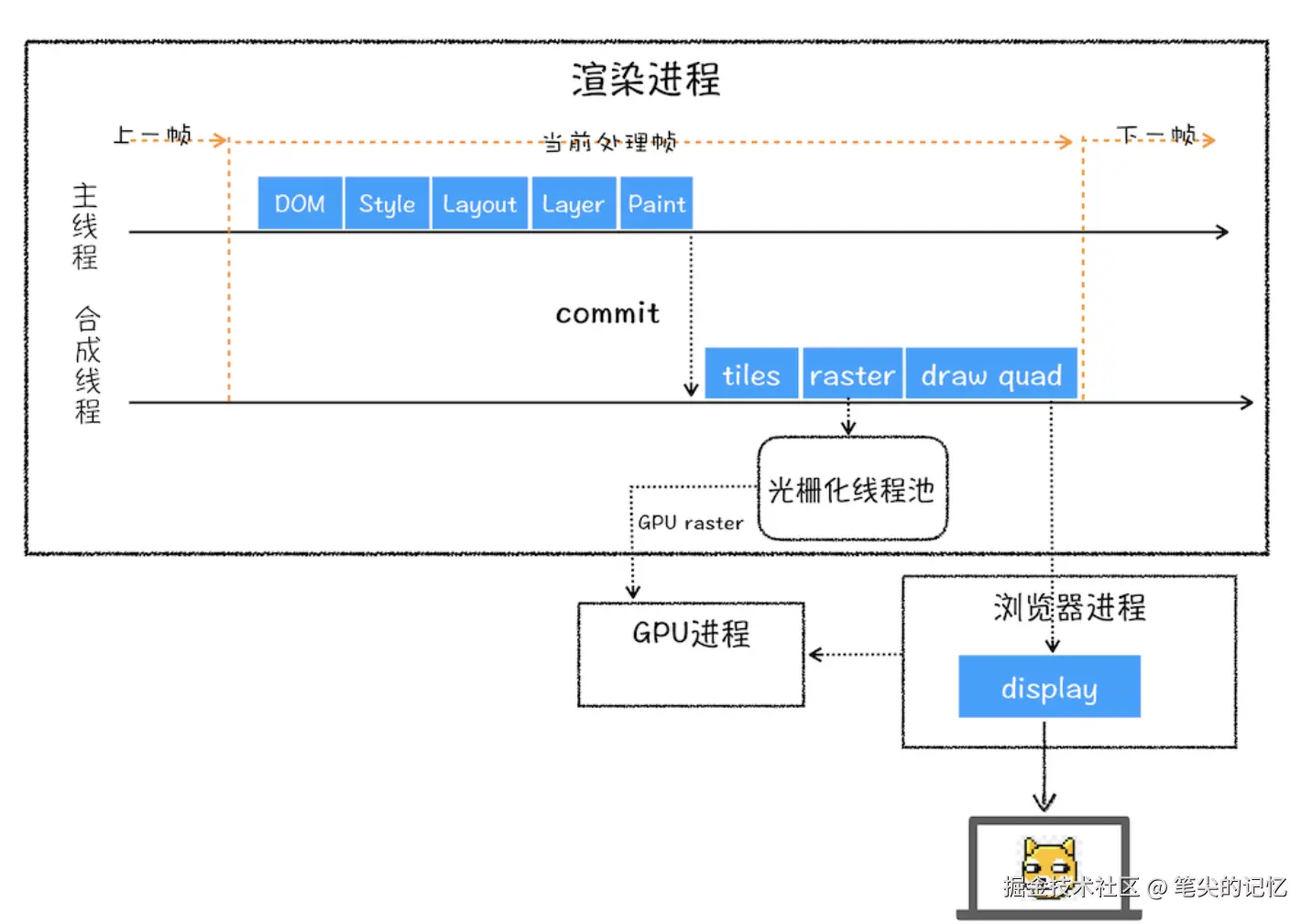
渲染进程在开始解析页面的时候,创建了一个主线程和一个合成线程,主线程负责解析HTML、CSS、JavaScript,也就是说构建dom树和js引擎线程在很多情况下是同一个线程,看到这里的朋友一定想到了,社区中经常说的js线程和ui线程是互斥的,不会同时运行,那么到底是怎么回事呢。其实现在的浏览器在解析html文档之前,会先创建一个预解析线程,扫描页面的js和css文件,为了不阻塞dom,就开启一个新线程去协调下载js和css资源,这里面js和css在有些情况下会阻塞dom树的构建,后续会再写一篇文章去分析,这里面先不做分析。
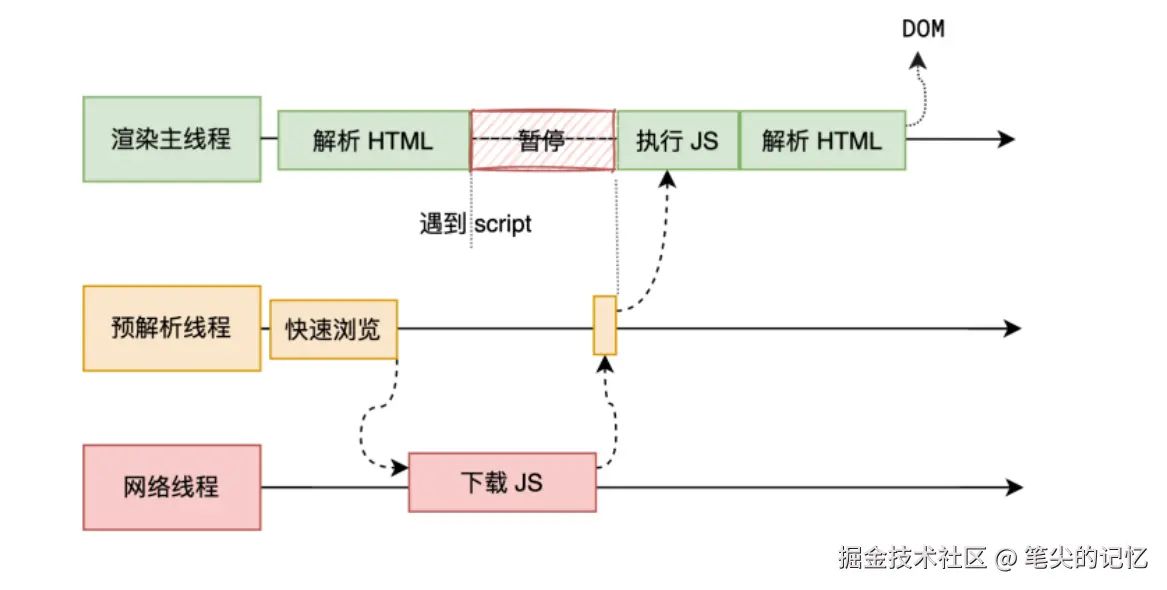
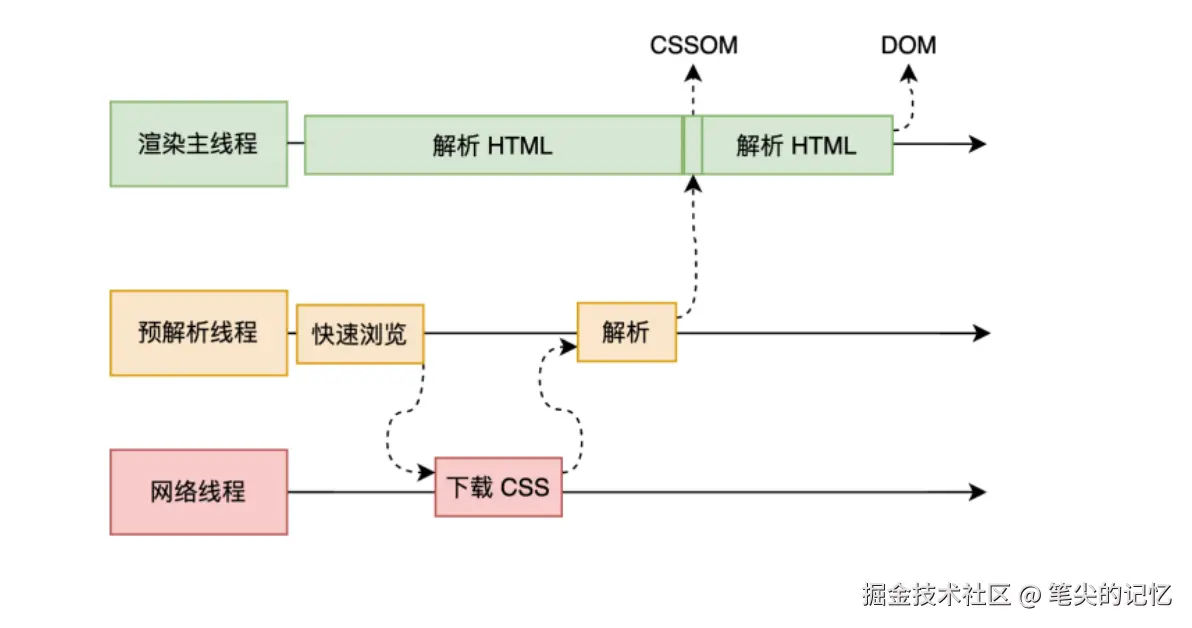
浏览器在解析文档页面时,主线程主要负责的是构建DOM树、样式计算、布局阶段、分层与图层树生成、分层与图层树生成;合成线程主要负责绘制列表生成、图块划分与光栅化、页面合成与显示,下面这张图是每个阶段工作的流水线,现在我们知道JS执行和Piant都是在主线程中,是同一个线程,在同一个线程中相互阻塞,Paint阶段不是字面意思去绘制,而是生成每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来,提交给合成线程,然后合成线程去做后续操作,最后是页面的呈现。
这里面我们看下前一篇文章结尾的两个问题就比较好回答了
- JS操作DOM非常耗费性能?
主要是JS改变DOM会触发浏览器的重排、重绘等,操作不好的话,会导致多次执行从DOM到Paint等子阶段,因而比较耗时。
- JS线程和UI线程是互斥的?它们是两个不同线程?还是? DOM构建和JS执行都是在主线程中执行的,不存在两个线程,这里面两个线程是主线程和合成线程,二者不是互斥关系。
这段流程图清晰展示了开发者操作 DOM/CSS 时,不同属性修改对浏览器渲染性能的影响,核心逻辑可拆解为以下三类场景:
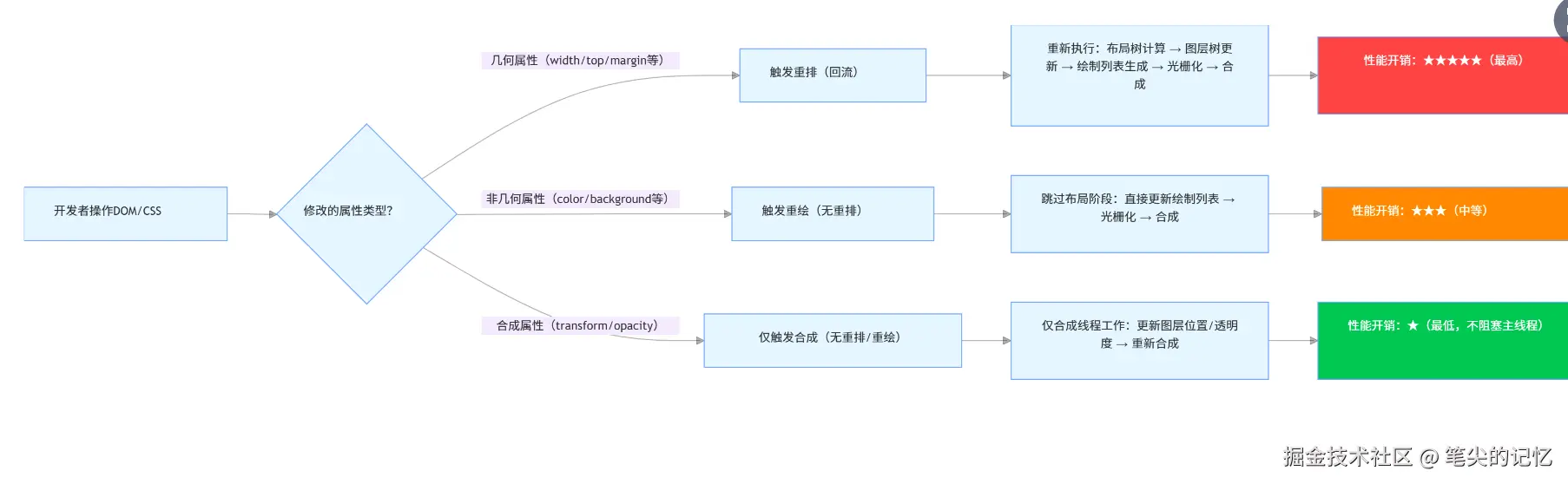
1. 几何属性修改(如 width、top、margin 等)
- 触发行为:重排(回流,Reflow) 。
- 过程:浏览器需重新计算元素的布局树(确定位置、尺寸),随后依次更新图层树、生成绘制列表、执行光栅化,最后完成合成显示。
- 性能开销:★★★★★(最高)。重排会阻塞主线程,若频繁操作,极易导致页面卡顿。
2. 非几何属性修改(如 color、background 等)
- 触发行为:重绘(Repaint,无重排) 。
- 过程:元素几何结构未发生变化,仅需更新 "绘制样式"(如颜色、背景),因此会跳过布局阶段,直接更新绘制列表、执行光栅化,最后合成显示。
- 性能开销:★★★(中等)。比重排更高效,但仍会占用部分主线程资源。
3. 合成属性修改(如 transform、opacity 等)
- 触发行为:仅触发合成(Compositing,无重排 / 重绘) 。
- 过程:利用 GPU 直接对 "图层" 进行操作(如平移、调整透明度),完全由合成线程处理,不会阻塞主线程(JavaScript 可继续执行)。
- 性能开销:★(最低)。这是动画优化的核心手段,例如用
transform替代top实现动画,能大幅提升流畅度。
因此优先使用合成属性(如 transform)实现动态效果,避免频繁修改几何属性,可有效提升渲染性能。
性能优化方案
从上文中可以看出每次 DOM 操作会触发浏览器的重排(回流)或重绘,频繁操作会导致页面卡顿。所以这里面我们从减少操作次数、避免不必要渲染、利用浏览器特性、长任务优化等出发:
减少 DOM 操作次数(核心原则:批量处理)
-
离线操作 DOM避免频繁将 DOM 节点插入 / 修改到文档流中,可先在内存中构建 DOM 片段,完成后一次性插入。ini// 优化前:多次插入DOM,触发多次重排 const list = document.getElementById('list'); for (let i = 0; i < 100; i++) { const li = document.createElement('li'); li.textContent = `Item ${i}`; list.appendChild(li); // 每次appendChild都会触发重排 } // 优化后:使用DocumentFragment批量处理 const fragment = document.createDocumentFragment(); for (let i = 0; i < 100; i++) { const li = document.createElement('li'); li.textContent = `Item ${i}`; fragment.appendChild(li); // 内存中操作,不触发重排 } list.appendChild(fragment); // 仅1次重排 -
合并样式修改避免多次单独修改元素样式,应合并为一次操作(直接修改className或style.cssText)。ini// 优化前:3次样式修改触发3次重排/重绘 const box = document.getElementById('box'); box.style.width = '100px'; box.style.height = '100px'; box.style.backgroundColor = 'red'; // 优化后:1次合并操作,仅1次重排/重绘 box.style.cssText = 'width: 100px; height: 100px; background-color: red;'; // 或通过修改className(推荐,便于维护) box.className = 'box--active'; // CSS中定义.box--active的所有样式
避免不必要的渲染(减少重排 / 重绘范围)
-
脱离文档流操作 DOM对需要频繁修改的元素,先将其脱离文档流(如设置display: none),修改完成后再恢复,避免中间过程的渲染消耗。iniconst container = document.getElementById('container'); // 1. 脱离文档流(触发1次重排) container.style.display = 'none'; // 2. 批量修改(内存中操作,无重排) for (let i = 0; i < 100; i++) { container.appendChild(document.createElement('div')); } // 3. 恢复显示(触发1次重排) container.style.display = 'block';(仅 2 次重排,而非 100+1 次)
-
使用 CSS containment 隔离渲染范围对独立组件设置contain属性,告知浏览器该元素的渲染变化不会影响外部,限制重排 / 重绘范围。css.widget { contain: layout paint size; /* 布局、绘制、尺寸均隔离 */ }layout:内部布局变化不影响外部paint:内部绘制变化不影响外部size:元素尺寸不依赖内部内容
-
避免触发同步布局浏览器会延迟执行布局计算(异步),但读取某些 DOM 属性(如offsetHeight、getBoundingClientRect())会强制触发同步布局,导致性能损耗。ini// 优化前:读取-修改-读取,触发2次布局 const boxes = document.querySelectorAll('.box'); for (let i = 0; i < boxes.length; i++) { boxes[i].style.width = '100px'; const height = boxes[i].offsetHeight; // 强制触发布局 boxes[i].style.height = `${height}px`; } // 优化后:先批量读取,再批量修改(仅1次布局) const heights = []; // 1. 批量读取(触发1次布局) for (let i = 0; i < boxes.length; i++) { heights.push(boxes[i].offsetHeight); } // 2. 批量修改(异步布局) for (let i = 0; i < boxes.length; i++) { boxes[i].style.width = '100px'; boxes[i].style.height = `${heights[i]}px`; }
利用浏览器特性与现代 API
-
使用虚拟列表(Virtual List)处理大数据当列表数据量极大(如 10 万条),只渲染可视区域内的 DOM 节点,滚动时动态替换内容,避免创建大量 DOM。ini// 核心思路:计算可视区域内需要显示的项,仅渲染这些项 function renderVisibleItems(scrollTop, containerHeight) { const itemHeight = 50; const startIndex = Math.floor(scrollTop / itemHeight); const endIndex = startIndex + Math.ceil(containerHeight / itemHeight); // 仅渲染startIndex到endIndex之间的项 list.innerHTML = generateItems(startIndex, endIndex); // 通过padding-top模拟滚动偏移,保持视觉连贯 list.style.paddingTop = `${startIndex * itemHeight}px`; }(常见库:
react-window、vue-virtual-scroller) -
使用 CSS transforms/opacity 实现高性能动画这两个属性仅触发浏览器的 "合成" 阶段(由合成线程处理,不阻塞主线程),避免重排 / 重绘。 .box { transition: transform 0.3s; /* 性能优于transition: left 0.3s / } .box:hover { transform: translateX(100px); / 仅触发合成,无重排 / / 而非 left: 100px(触发重排) */ } -
合理使用will-change提前告知浏览器优化对即将发生动画或频繁变化的元素,通过will-change提示浏览器提前准备优化(如创建独立图层)。css.animated-element { will-change: transform, opacity; /* 告知浏览器这些属性可能变化 */ }(注意:避免滥用,否则会占用过多内存)
JS 长任务的优化方案
- 拆分长任务:将 "大任务" 拆分为 "小任务"
利用 setTimeout 或 requestIdleCallback,将耗时超过 50ms 的逻辑拆分为多个小任务,让主线程有间隙处理其他操作(如用户交互、渲染)。
示例:拆分大规模数组处理
scss
// 优化前:一次性处理 10w 条数据,耗时可能超过 200ms(长任务)
function processBigData(data) {
data.forEach((item) => {
// 复杂处理逻辑(如数据格式化、过滤)
item.formatted = formatItem(item);
});
}
processBigData(largeData); // largeData 是 10w 条数据的数组
// 优化后:拆分为每次处理 100 条,利用 setTimeout 让出主线程
function processDataInChunks(data, chunkSize = 100) {
let index = 0;
// 处理单个"小任务"
function processChunk() {
const end = Math.min(index + chunkSize, data.length);
for (; index < end; index++) {
data[index].formatted = formatItem(data[index]);
}
// 若未处理完,下一轮事件循环继续处理
if (index < data.length) {
setTimeout(processChunk, 0); // 0ms 延迟让主线程优先处理其他任务
}
}
processChunk();
}
processDataInChunks(largeData);进阶方案:使用 requestIdleCallback若任务非紧急(如日志上报、非关键数据处理),可利用 requestIdleCallback 在主线程空闲时执行,完全不影响用户交互:
javascript
scss
requestIdleCallback((deadline) => {
// deadline.timeRemaining():当前空闲时间(ms)
while (deadline.timeRemaining() > 0) {
// 执行小任务(如处理一条数据)
if (index < data.length) {
data[index].formatted = formatItem(data[index]);
index++;
} else {
break;
}
}
// 若未处理完,下一次空闲时继续
if (index < data.length) {
requestIdleCallback(arguments.callee);
}
});- 避免高频事件触发长任务:防抖与节流
scroll、resize、input 等高频事件,若回调函数耗时较长,会频繁触发长任务。需通过 防抖(Debounce) 或 节流(Throttle) 减少执行次数
javascript
// 节流函数:50ms 内仅执行一次回调
function throttle(fn, delay = 50) {
let lastTime = 0;
return function (...args) {
const now = Date.now();
if (now - lastTime > delay) {
fn.apply(this, args);
lastTime = now;
}
};
}
// 优化前:滚动时频繁执行,可能触发长任务
window.addEventListener('scroll', handleScroll);
// 优化后:50ms 内仅执行一次,减少长任务概率
window.addEventListener('scroll', throttle(handleScroll));- 利用 Web Workers:转移计算密集型任务
对于纯计算密集型任务(如大文件加密、复杂数学计算、大规模数据排序),可使用 Web Workers 将任务转移到后台线程执行,完全不阻塞主线程。
示例:Web Workers 处理复杂计算
javascript
ini
// 主线程代码
const worker = new Worker('compute-worker.js');
// 向 Worker 发送数据
worker.postMessage(largeData);
// 接收 Worker 的计算结果
worker.onmessage = (e) => {
console.log('计算完成,结果:', e.data);
};
// compute-worker.js(Worker 线程代码)
self.onmessage = (e) => {
const largeData = e.data;
// 执行耗时计算(如排序 10w 条数据)
const result = largeData.sort((a, b) => a.value - b.value);
// 向主线程发送结果
self.postMessage(result);
};总结
渲染引擎的每个阶段流水线执行,理解每个阶段的细节,是写出高性能前端代码的关键 ------ 只有知其然且知其所以然,才能在实际开发中规避渲染瓶颈,打造流畅的用户体验。