引言
在本系列上一篇文章中,我们回顾了 GPT-1 的设计思路:它基于 Transformer 解码器结构,将"生成式预训练 + 下游任务微调"的范式带入自然语言处理领域,成为后续一系列工作的源头。
2019 年 2 月,OpenAI 发布了 GPT-2。这一次,它不再执迷于这套范式,而是更加专注于模型的零样本(zero-shot)能力。
零样本任务是指模型在大规模数据上进行预训练之后,不再进行微调,直接应用于下游任务。
本文就来看看它具体是怎么做的。
论文标题:Language Models are Unsupervised Multitask Learners

1. 背景
GPT-1 已经证明了"无监督预训练 + 有监督微调"是可行的,但它依然受到两个方面的限制:
- 模型规模有限:1.17 亿参数在当时算不上庞大,很难捕捉复杂的语义规律。
- 训练语料不足:仅使用 BooksCorpus 数据,覆盖面偏窄,导致泛化性不足。
随着计算资源与数据获取能力的提升,一个自然的想法是:如果把模型做得更大,并且用更大规模、更广覆盖的语料训练,能否让模型直接学到跨任务的能力?
GPT-2 的核心探索正是这一点。它将 GPT-1 的思路"简单粗暴"地放大:更多层数、更多参数、更长上下文、更大数据,从而展现出强大的零样本泛化能力。
2. 模型设计
2.1 模型架构
- 结构:和 GPT-1 框架一致,即 Transformer 的 Decoder 部分。
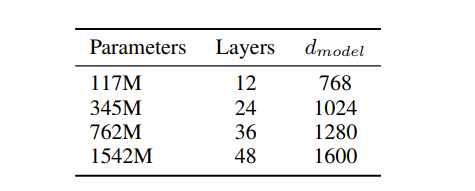
GPT-2 主要有以下四种参数量版本的模型。
-
最大模型配置:
- 层数:48 层
- 隐藏维度:1600
- 注意力头数:25
- 总参数量:15 亿(1.5B)
- 最大上下文长度:1024 token
相比 BERT-LARGE,GPT-2 参数量提升了4倍。
2.2 训练数据
- 数据来源:WebText。通过抓取 Reddit 上被高质量链接指向的网页,去掉维基百科等常见语料,得到约 800 万网页,40GB 文本。
- 数据特点:覆盖面更广,包含新闻、小说、代码、对话等多种体裁,比 GPT-1 的 BooksCorpus 更丰富。
2.3 训练目标与策略
-
目标函数:和 GPT-1 一样。
-
给定一个序列的前文,预测下一个 token 的概率:
L=∑ilogP(ui∣ui−k,...,ui−1;Θ) L = \sum_i \log P(u_i | u_{i-k}, \dots, u_{i-1}; \Theta) L=i∑logP(ui∣ui−k,...,ui−1;Θ)
-
GPT-2 在论文中主要强调其零样本能力:在下游任务上,不再需要特定的监督微调,而是通过**任务描述(prompt)**直接驱动模型输出结果。
不同下游任务的方式如下表所示:
| 任务类别 | 数据集 / 实验 | 原始任务形式 | GPT-2 的零样本做法(Prompt 化) |
|---|---|---|---|
| 语言建模填空 | CBT (Children's Book Test) | 给定上下文 + 填空,候选词列表 | 把候选词分别代入句子,计算完整句子的概率,选最大概率的作为答案 |
| 长文本预测 | LAMBADA | 给定长上下文,预测最后一个词 | 直接用 LM 预测最后一个词的概率,选最高的 |
| 常识推理 | Winograd Schema Challenge | 判断代词指代 | 构造两种候选句子(不同指代替换),计算整体句子的概率,选择更合理的句子 |
| 阅读理解 | CoQA | 给定文档、对话历史、问题,输出答案 | 输入串为 [文档 + QA 历史 + 新问题],让模型直接生成答案 |
| 摘要生成 | Reddit/TL;DR | 给定文章,写出摘要 | 在文章后面加提示 "TL;DR:",让模型生成摘要 |
| 机器翻译 | WMT-14 En→Fr 等 | 翻译句子 | 构造少量示例 prompt,例如:English: The dog is happy. French:,让模型继续生成翻译 |
| 事实问答 | Natural Questions | 给定问题,输出事实答案 | 构造 Q&A 格式 prompt,例如: Q: Who wrote Harry Potter? A: J.K. Rowling Q: What is the capital of France? A: Paris 再加新问题,让模型生成答案 |
注:论文里没有详细写每个任务prompt具体是怎么设计的,上表中的 prompt 为 使用 GPT-5 产生的内容推断。
3. 实验与结果
GPT-2 在多个任务上进行了实验,具体如下:
3.1 Language Modeling(语言建模基准)
- 作者首先在多个标准语言建模数据集上,用零样本方式评估模型的迁移能力(即模型本身没在这些数据上训练/微调,只用模型原生能力预测)。
- 在多个数据集(如 WikiText-2、LAMBADA、CBT、enwik8 等)上,GPT-2 模型常常取得较大幅度的 perplexity(困惑度)下降。
- 尤其在较小 / 长依赖任务(如 LAMBADA、CBT)上,大模型优势显著。
- 实验还分析了训练 / 测试数据之间的重叠(n-gram 重叠),以判断模型是否仅靠"记忆"获益。
3.2 Children's Book Test(儿童书籍完形填空测试)
- CBT 是一种 cloze 测试,目标是预测被掩盖句子中的某个词(从若干选项中选择)。
- 模型对每个候选词计算整个句子的概率,选最大概率的那个作为答案。
- 实验发现,随着模型规模增加,正确率逐步提升,且接近人类水平(在部分词类上甚至超过前人)------这说明模型在室内语言推断 / 上下文建模方面能力强。
3.3 LAMBADA(长文本预测)
- LAMBADA 是一个测试长距离上下文依赖任务:句子的最后一个词要求模型知道前 50 个词的上下文才能预测。
- GPT-2 在 LAMBADA 上大幅提升准确率,并降低 perplexity。
- 作者还观察到许多错误预测仍是合理的生成(但不是严格的目标词),说明模型生成能力较强。
3.4 Winograd Schema Challenge(常识推理 / 指代消解)
- Winograd 是一种经典指代消解题,用微妙的语言差异测试模型是否具备常识推理能力。
- GPT-2 在该任务上也有显著提升(比之前方法高出几个百分点),尽管样本数量少,任务难度大。
3.5 Reading Comprehension(阅读理解 / CoQA)
- 在 CoQA 数据集(对话式问答 + 文档上下文)上,将文档 + 对话历史 + 问题作为 prompt 条件,模型直接生成答案。
- GPT-2 在这种零样本方式下取得约 55 F1 分数,这与某些监督系统相近,且超过了若干未专门训练的基线模型。
3.6 Summarization(摘要生成)
- 给定一篇文章,在其后加上 "TL;DR:" 提示,让模型生成摘要。
- 为控制生成质量,使用 top-k 随机采样(k = 2)并生成 100 个 token,从中选前三句话作为摘要。
- 虽然在 ROUGE 指标上仍落后于专门训练的摘要模型,但 GPT-2 生成的摘要在语义流畅性和主题一致性方面已有可用性。
- 实验还表明,如果移除 task 提示 ("TL;DR:"),性能会显著下降,说明提示在诱导行为中至关重要。
3.7 Translation(翻译)
- 尽管训练语料主要是英语网页,模型在 prompt 中被诱导去做英→法翻译(给出若干样例对,然后"English: ... = French:")
- 在 WMT-14 英法数据集上,GPT-2 达到约 5 BLEU(用最基础方式)表现,尽管不及专门的机器翻译模型,但超越部分无监督翻译基线。
- 有意思的是,尽管 WebText 已过滤掉多数非英语网页,模型仍从语料中学到了一部分多语种提示 / 翻译能力。
3.8 Question Answering(事实问答 / 自然问题集)
- 在 Natural Questions 数据集上,用提示 + 若干 QA 示例作为上下文,让模型直接生成短答案。
- GPT-2 在 exact-match 指标下答对约 4.1% 的问题,比最小模型高出许多。
- 对它最有信心的 1% 回答中,准确率达 63.1%。
- 实验还展示了最有信心的 30 个答案示例,证明模型确实蕴含了一些事实性知识。
4. 讨论
4.1 零样本泛化能力
GPT-2 表明 不需要针对任务微调,直接通过提示词就能完成多任务。
这预示着语言模型已经具备了"通用任务接口"的雏形,为后续"大力出奇迹"的 GPT-3 的奠定了基础。
4.2 安全与伦理问题
OpenAI 选择 不公开完整 GPT-2 模型(仅发布小规模版本),原因在于其生成文本过于逼真,担心被用于虚假新闻、垃圾信息等恶意场景。这也是第一次将"大模型安全性"带入公众讨论。
总结
当 OpenAI 发现 GPT-1 在一些数据集上的性能被 Google 的 BERT 打败后,没有通过 GPT-2 进行反击和刷点对比,而是另辟蹊径,从零样本的角度去思考全新的问题。
虽然 GPT-2 在模型层面没有什么新变化,但意义还是很大的,说明不需要微调,模型也能做的很好,通过这个思路,可以将很多数据直接加上特定的 prompt 就直接利用起来,而不需要单独为特定任务进行标注,这也是大语言模型后续能够"穷尽一切网络语料"的根本原因。