在自然语言处理(NLP)的技术版图中,Transformer架构无疑是一座里程碑。它的Encoder(编码器)与Decoder(解码器)模块不仅在机器翻译等任务中协同作战,更衍生出了Encoder-only 的BERT和Decoder-only的GPT这样的"独立王者"。今天,我们就来深度拆解它们的架构、作用,以及BERT和GPT如何各自在"理解"与"生成"的赛道上封神。
一、Transformer:Encoder与Decoder的"双子星"架构
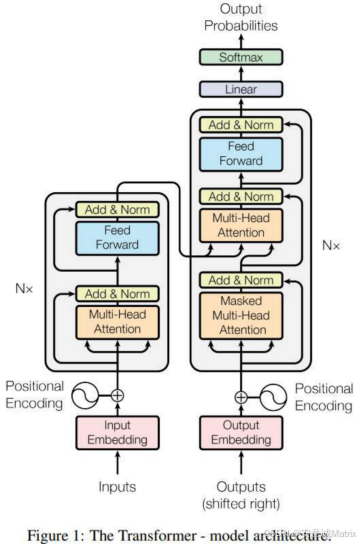
Transformer的原始设计是Encoder-Decoder协同模式(如图所示的经典架构),二者分工明确:
- Encoder(编码器) :负责"理解输入"------通过自注意力机制捕捉输入序列的全局上下文关系,将文本转化为富含语义的特征表示。
- Decoder(解码器) :负责"生成输出"------通过掩码自注意力 (保证自回归)和编码器-解码器注意力(关联输入语义),逐步生成目标序列。
这种协同模式在机器翻译等任务中表现卓越,但后续研究发现:Encoder和Decoder的能力可以"拆分",各自独立支撑起不同类型的NLP任务。
二、Encoder-only:以BERT为代表的"语义理解大师"
1. 架构本质
BERT(Bidirectional Encoder Representations from Transformers)仅由Transformer的Encoder层堆叠而成。它的核心能力是**"双向上下文理解"**------能同时捕捉一个词的"左上文"和"右下文",从而更精准地理解文本语义。
2. 输入与输出
- 输入 :带特殊标记的文本序列,例如:
[CLS] 我 喜欢 自然语言处理 [SEP][CLS]:用于聚合整个序列的语义,支撑文本分类等任务;[SEP]:用于分隔不同句子(如句对任务)。
- 输出 :每个token的上下文嵌入向量 (即包含全局语义的特征表示)。
- 若用于文本分类 (如情感分析),则取
[CLS]位置的向量做分类; - 若用于命名实体识别(如识别"苹果"是公司还是水果),则取每个实体token的向量做识别;
- 若用于语义相似度计算 (如判断两句话是否同义),则取两句话的
[CLS]向量做相似度建模。
- 若用于文本分类 (如情感分析),则取
3. 应用场景
BERT凭借强大的"理解能力",几乎统治了NLP的**"理解类任务":文本分类、命名实体识别、语义角色标注、问答系统(如抽取式问答)等。它输出的是"语义特征"**,而非完整序列,是NLP领域的"语义理解基石模型"。
三、Decoder-only:以GPT为代表的"文本生成王者"
1. 架构本质
GPT(Generative Pre-trained Transformer)仅由Transformer的Decoder层堆叠而成。它的核心能力是**"自回归生成"**------通过"掩码自注意力"确保生成第( n )个token时,只能看到前( n-1 )个已生成的token,从而实现"逐词生成、逻辑连贯"的文本创作。
2. 输入与输出
- 输入 :前缀文本(称为"Prompt",即提示词),例如:
"人工智能的未来" - 输出 :完整的生成序列,例如:
"人工智能的未来充满无限可能,它将重塑医疗、教育、交通等各行各业的运作模式,甚至在艺术创作领域也能与人类并肩探索灵感的边界......"
它通过对每个位置的token做概率预测(Softmax层),最终生成连贯的长文本。
3. 应用场景
GPT凭借强大的"生成能力",在**"生成类任务"中大放异彩:对话系统(如ChatGPT)、文本创作(如小说续写)、代码生成、知识问答(如基于上下文的开放式问答)等。它输出的是"完整序列"**,是NLP领域的"创意生成引擎"。
四、BERT vs GPT:Encoder-only与Decoder-only的巅峰对决
| 维度 | BERT(Encoder-only) | GPT(Decoder-only) |
|---|---|---|
| 核心能力 | 双向上下文理解("我懂了") | 自回归序列生成("我能写") |
| 输入形式 | 带特殊标记的文本序列(含[CLS]/[SEP]) |
前缀提示词(Prompt) |
| 输出形式 | 语义特征向量(用于理解类任务) | 完整生成序列(用于创作类任务) |
| 任务偏向 | 文本分类、命名实体识别、问答(抽取式)等 | 对话生成、文本创作、代码生成、开放式问答等 |
| 架构逻辑 | 无生成能力,专注"理解"输入语义 | 无Encoder依赖,纯靠"自回归"生成输出 |
五、总结:Transformer模块的"拆分与独立"
Transformer的Encoder和Decoder本是协同作战的"双子星",但通过对它们的"拆分"与"专精化训练",催生出了BERT和GPT这样的现象级模型:
- Encoder的"理解能力"让BERT成为NLP理解类任务的标杆;
- Decoder的"生成能力"让GPT成为文本创作类任务的顶流。
这种"模块独立化"的思路,也为AI模型的架构创新提供了启示:无需追求"大而全",聚焦"单点专精"也能打造出影响行业的技术突破。
未来,Encoder与Decoder的潜力或许还会在更多领域(如多模态、强化学习)绽放,让我们持续关注这场由Transformer开启的技术演进之旅。