Hadoop RPC深度解析:分布式通信的核心机制
在分布式系统中,节点间的高效通信是核心需求。Hadoop 作为典型的分布式系统,其内部组件(如 NameNode 与 DataNode、ResourceManager 与 NodeManager)的通信依赖于 Hadoop RPC(Remote Procedure Call,远程过程调用)机制。Hadoop RPC 通过四层架构设计,实现了高效、可靠的跨节点函数调用,本文将深入解析其组成结构、实现原理及核心流程。
Hadoop RPC 的核心目标
在分布式集群中,Hadoop 各组件(如 HDFS 的 NameNode 与 DataNode、YARN 的 ResourceManager 与 NodeManager)需要频繁交互(如心跳检测、元数据同步、任务调度)。Hadoop RPC 的设计目标是:
- 高效性:低延迟、高吞吐量,支持大规模集群的高频通信;
- 可靠性:确保消息不丢失、不损坏,支持异常重试;
- 易用性:屏蔽网络通信细节,让开发者像调用本地函数一样调用远程方法;
- 兼容性:支持跨版本、跨语言(主要是 Java)的通信需求。
Hadoop RPC 的四层架构
Hadoop RPC 采用分层设计,从下到上分为 序列化层 、函数调用层 、网络传输层 和 服务器端处理框架,每层专注于特定功能,共同支撑远程调用流程。

一、序列化层:对象与字节流的转换
序列化层是 RPC 通信的基础,负责将 Java 对象(如方法参数、返回值)转换为可通过网络传输的字节流,以及将接收的字节流反序列化为对象。
核心功能
- 序列化:将方法调用的参数、返回值等结构化对象转为字节流;
- 反序列化:将接收的字节流还原为 Java 对象,供服务器端处理。
Hadoop 序列化机制
Hadoop 未直接使用 Java 原生序列化(效率低、冗余大),而是采用自定义的 Writable 接口 实现高效序列化:
- 所有需要网络传输的对象需实现
Writable接口,重写write(DataOutput out)和readFields(DataInput in)方法; - 相比 Java 原生序列化,Writable 更轻量(无类元数据)、速度更快,适合大数据场景。
示例:自定义 Writable 类
java
public class User implements Writable {
private String name;
private int age;
// 序列化:将对象写入输出流
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
}
// 反序列化:从输入流读取数据还原对象
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.age = in.readInt();
}
// getter/setter 省略
}二、函数调用层:远程方法的定位与执行
函数调用层负责将本地方法调用转换为远程调用请求,并在服务器端定位并执行目标方法,核心依赖 Java 反射机制 和 动态代理。
核心流程
- 客户端代理:客户端通过动态代理生成接口的代理对象,当调用接口方法时,代理对象拦截调用并转为 RPC 请求;
- 方法定位:客户端将 "接口名、方法名、参数类型、参数值" 等信息封装为请求对象;
- 服务器端反射调用:服务器端接收请求后,通过反射找到对应的实现类和方法,执行并返回结果。
动态代理的作用
动态代理(Proxy 类)是函数调用层的核心,它让客户端无需感知远程通信细节:
- 客户端调用的是代理对象的方法,而非直接调用远程服务器;
- 代理对象负责将方法调用转为 RPC 请求(序列化参数 → 网络传输 → 等待响应 → 反序列化结果)。
三、网络传输层:基于 TCP/IP 的可靠通信
网络传输层负责在客户端与服务器端之间建立 TCP 连接,传输序列化后的字节流,确保数据可靠送达。
核心功能
- 连接管理:客户端与服务器端建立和维护 TCP 连接;
- 数据传输:发送序列化后的请求字节流,接收服务器端返回的响应字节流;
- 异常处理:处理连接超时、断连等网络异常,支持重试机制。
Hadoop RPC 传输特点
- 基于 TCP 协议:TCP 提供可靠的字节流传输,保证数据不丢失、不重复、按序到达;
- 短连接 vs 长连接:Hadoop 内部 RPC 多采用长连接(如 DataNode 与 NameNode 的心跳通信),减少连接建立开销;
- 请求 - 响应模式:客户端发送请求后阻塞等待响应,服务器端处理后返回结果。
四、服务器端处理框架:高效处理并发请求
服务器端处理框架负责接收并处理客户端的 RPC 请求,采用 Reactor 事件驱动模型 实现高并发处理,避免传统多线程模型的资源浪费。
Reactor 模型核心组件
Reactor 模型通过 "事件循环 + 线程池" 实现高效并发:
- 反应器(Reactor):单线程负责监听网络事件(如连接请求、数据可读),将事件分发到对应的处理器;
- 处理器(Handler):负责具体的请求处理(如反序列化、反射调用方法),通常由线程池执行,避免阻塞反应器;
- 线程池:多线程并行处理请求,提升服务器端吞吐量。
Hadoop RPC 服务器端流程
- Reactor 监听端口,接收客户端连接请求并建立 TCP 连接;
- 当客户端发送数据时,Reactor 触发 "数据可读" 事件,将连接交给 Handler 处理;
- Handler 从连接中读取字节流,反序列化为请求对象;
- 通过反射调用目标方法,获取返回结果并序列化;
- 将序列化后的响应通过 TCP 连接返回给客户端。
Hadoop RPC 完整调用流程
以 DataNode 向 NameNode 发送心跳请求(sendHeartbeat 方法)为例,完整流程如下:
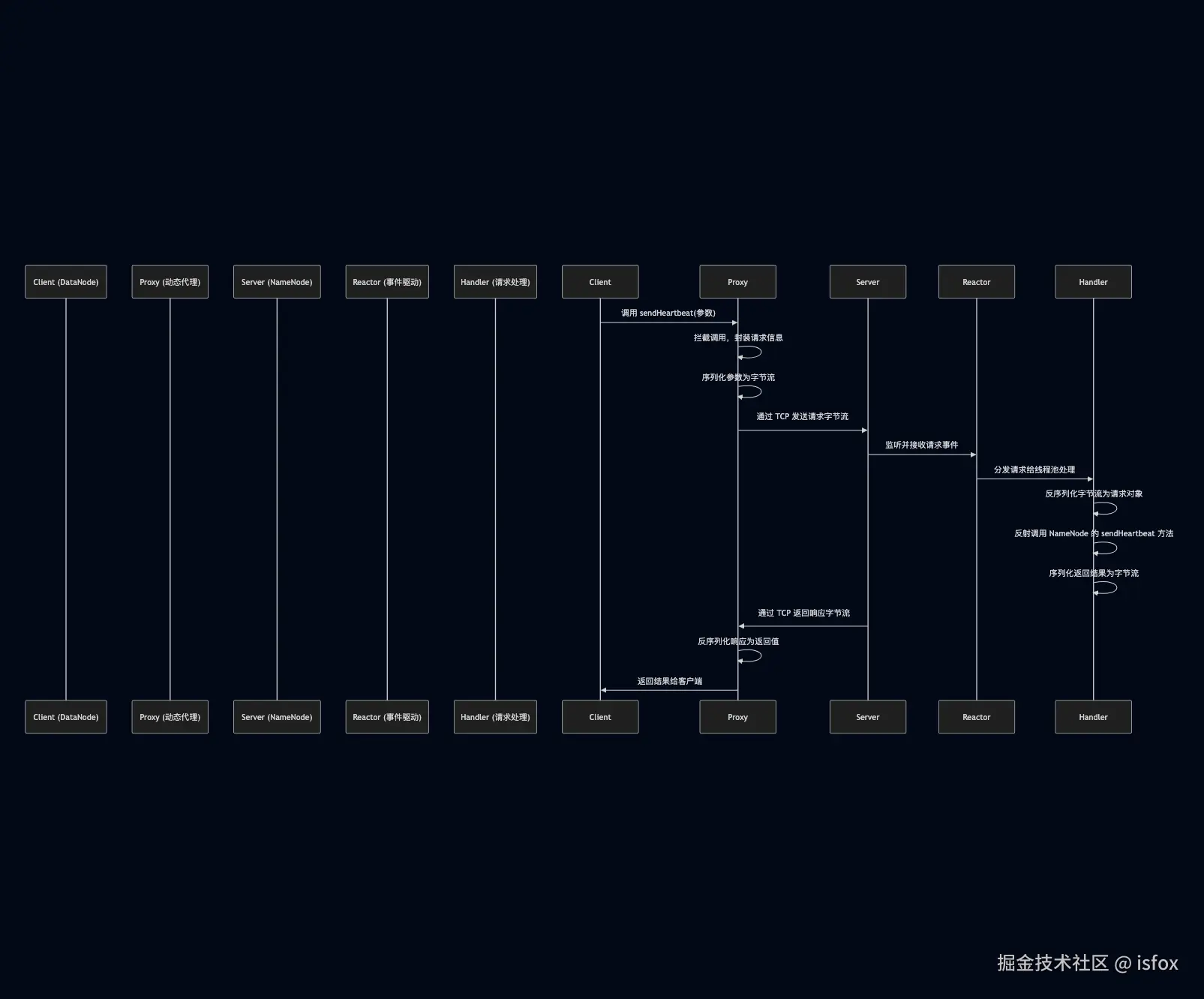
Hadoop RPC 的关键特性
- 高效性
- 自定义 Writable 序列化减少数据冗余;
- Reactor 模型和线程池提升服务器端并发处理能力;
- 长连接减少 TCP 握手开销。
- 可靠性
- 基于 TCP 协议保证数据传输可靠性;
- 支持请求重试机制(如客户端断连后重新发送);
- 服务器端方法调用异常时返回错误码,客户端可根据错误重试。
- 易用性
- 动态代理屏蔽远程通信细节,开发者只需定义接口和实现类;
- 封装了连接管理、序列化、网络传输等底层逻辑。
实际应用:Hadoop 组件中的 RPC 通信
Hadoop 各组件间的交互几乎都依赖 RPC:
- HDFS:NameNode 与 DataNode 通过 RPC 通信(心跳、块报告、数据块操作);
- YARN:ResourceManager 与 NodeManager 通过 RPC 交换资源信息和任务状态;
- MapReduce:ApplicationMaster 与 ResourceManager、TaskTracker 之间的任务调度通信。
参考文献