TL;DR
- 场景:本地/云主机快速跑通 Elasticsearch 的索引创建、插入、查询、更新、搜索。
- 结论:按 REST 规范与正确端点即可稳定返回;注意版本差异与安全默认项(8.x)。
- 产出:一套可复制的最小可用流程 常见错误速查卡。


ES简单使用
创建索引
创建 wzk_blog01 索引
shell
http://h121.wzk.icu:9200/wzk_blog01/?pertty返回结果如下:
shell
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "wzk_blog01"
}对应的截图如下图所示: 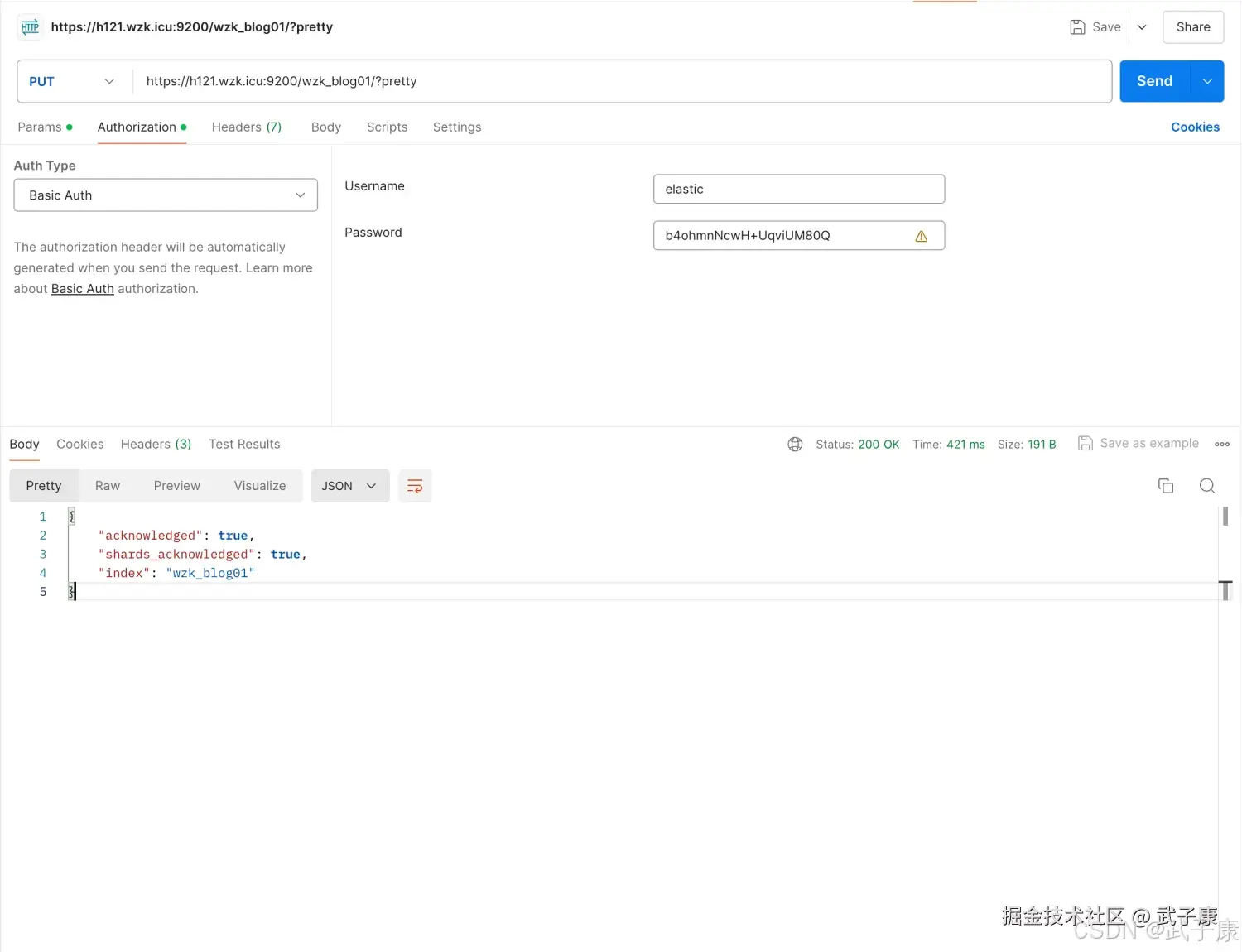
插入文档
shell
http://h121.wzk.icu:9200/wzk_blog01/_doc/1?pretty
{"id": "1", "title": "What is lucene"}
https://h121.wzk.icu:9200/wzk_blog01/_doc/1?pretty
{"id": "1", "title": "What is wzk icu"}
https://h121.wzk.icu:9200/wzk_blog01/_doc/1?pretty
{"id": "1", "title": "Apache Spark is a unified analytics engine for large-scale data processing"}返回结果如下:
shell
{
"_index": "wzk_blog01",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}查询文档
shell
http://h121.wzk.icu:9200/wzk_blog01/_doc/_search/1?pretty返回结果如下:
json
{
"_index": "wzk_blog01",
"_id": "1",
"_version": 3,
"_seq_no": 2,
"_primary_term": 1,
"found": true,
"_source": {
"id": "1",
"title": "Apache Spark is a unified analytics engine for large-scale data processing"
}
}对应截图如下: 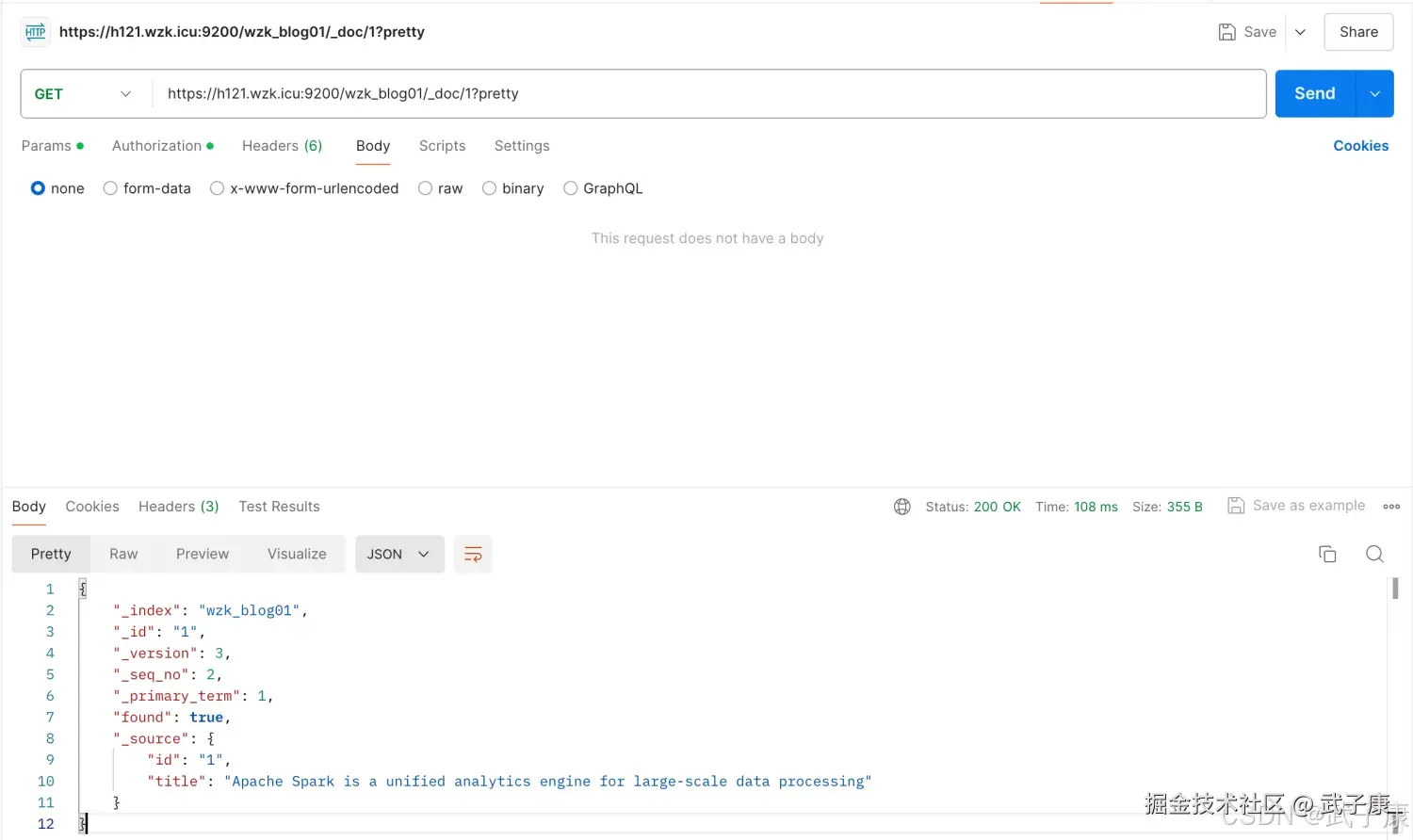
更新文档
shell
http://h121.wzk.icu:9200/wzk_blog01/_doc/1?pretty
{"id": "1", "title": " What is elasticsearch"}返回结果如下:
json
{
"_index": "wzk_blog01",
"_id": "1",
"_version": 4,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}对应截图如下: 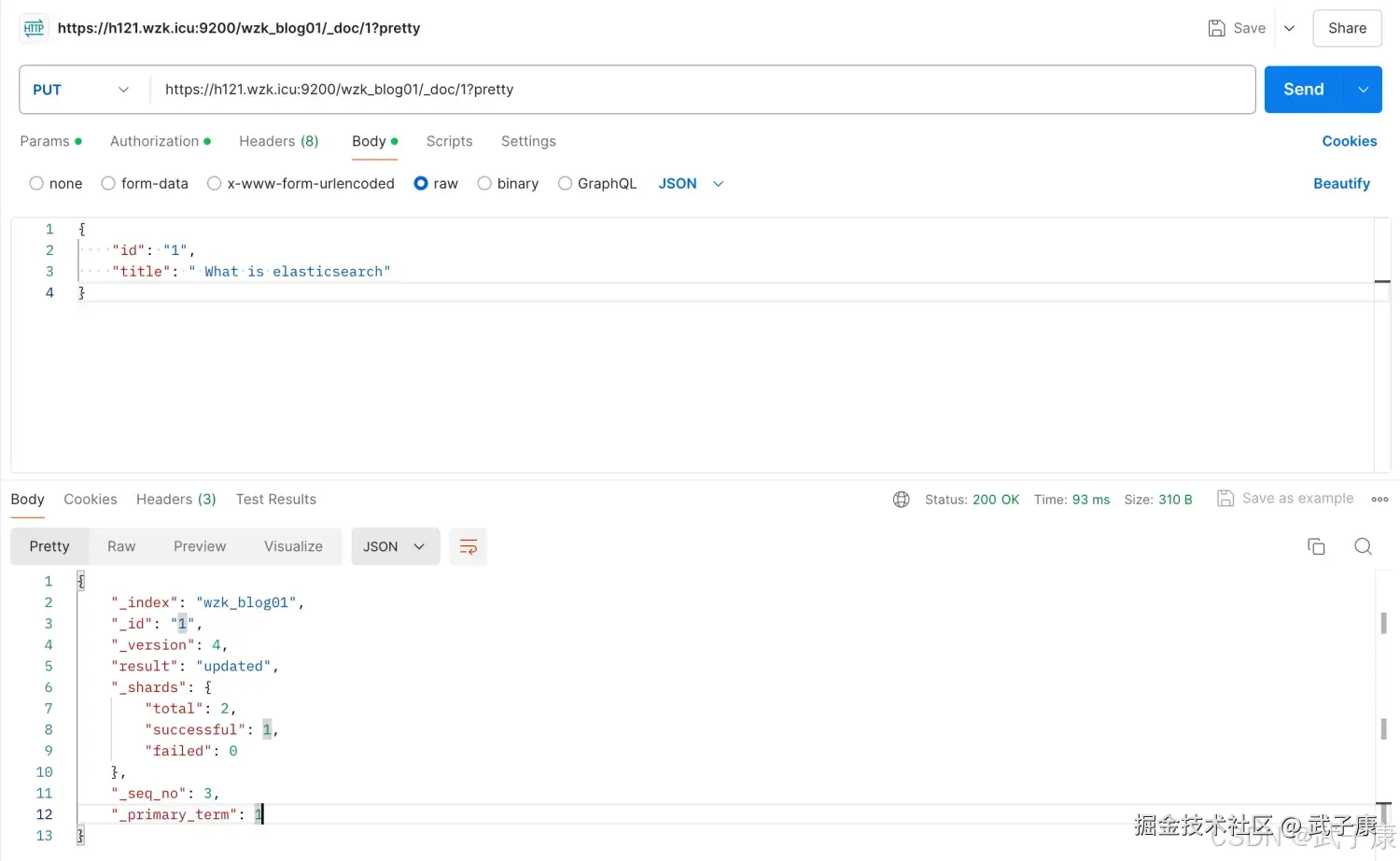
搜索文档
shell
http://h121.wzk.icu:9200/wzk_blog01/_doc/_search?pretty返回结果如下:
json
{
"query": {
"match": {
"title": "What"
}
}
}对应截图如下: 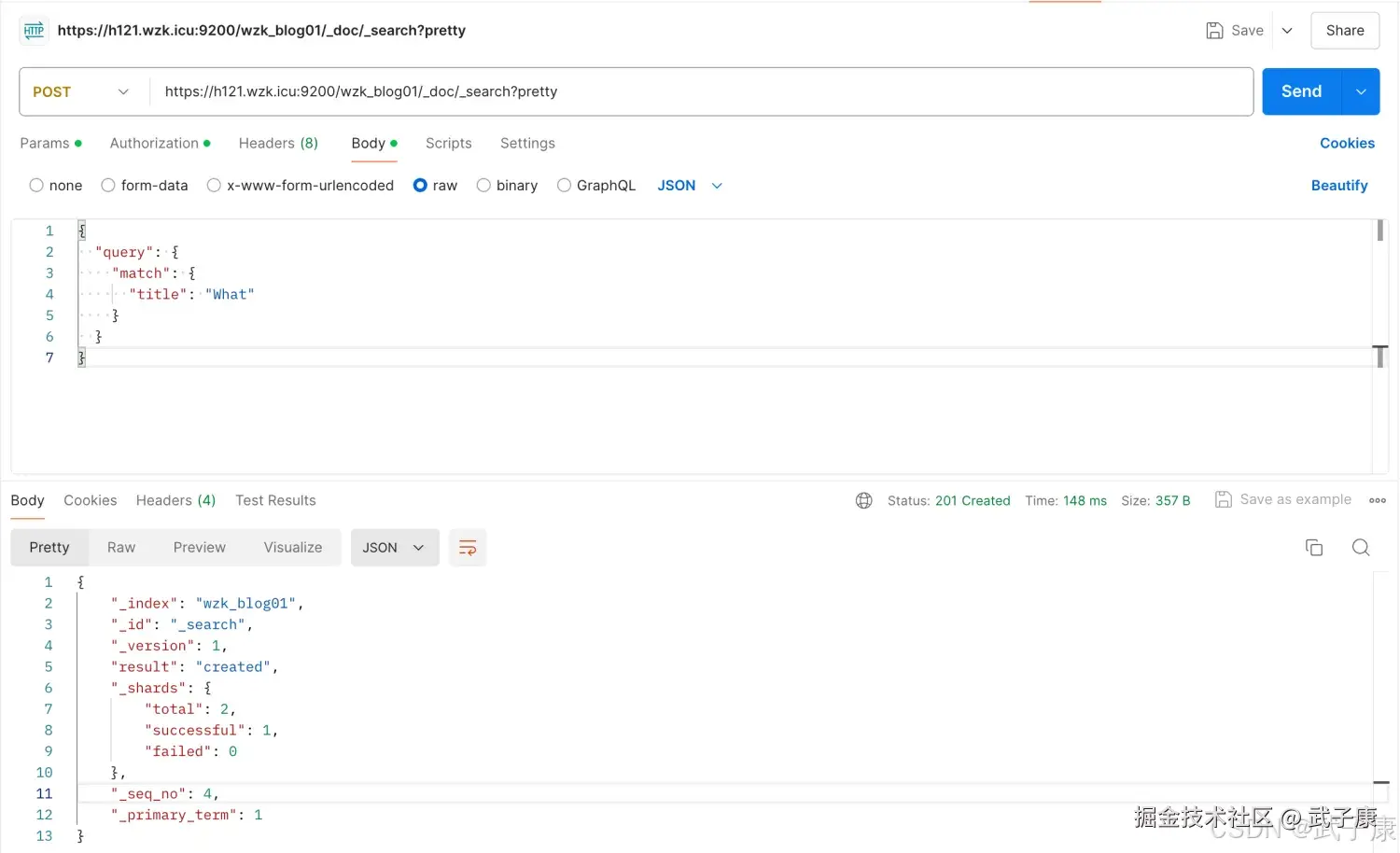
架构与概念
基本简介
Elasticsearch是一个面向文档(document oriented)的分布式搜索和分析引擎,这意味着它能够以文档为单位存储和管理数据。与传统的行式存储不同,Elasticsearch将每个数据实体作为一个完整的JSON文档进行处理和存储。例如,一个商品信息可以作为一个包含名称、价格、描述等字段的完整文档存储。
Elasticsearch的强大之处不仅在于存储文档,更在于它能对文档内容建立高效索引(Index)。它会自动分析文档中的每个字段,建立倒排索引等数据结构,实现近乎实时的搜索能力。比如,当用户搜索"智能手机"时,Elasticsearch可以快速返回所有包含该关键词的商品文档。
与关系型数据库相比,Elasticsearch有许多相似概念:
- 索引(Index)相当于MySQL中的数据库
- 类型(Type,7.x版本后已移除)类似MySQL的表
- 文档(Document)对应MySQL中的行记录
- 字段(Field)则对应MySQL中的列
例如,在电商系统中:
- 可以创建一个名为"products"的索引
- 每个商品作为一个文档存储
- 文档包含title、price、category等字段
Elasticsearch基于Apache Lucene构建,继承了其强大的全文检索能力,同时通过分布式架构解决了Lucene的单机限制。它支持复杂的查询功能,包括:
- 精确匹配查询
- 范围查询
- 模糊搜索
- 聚合分析
- 地理位置查询等
这使得Elasticsearch不仅适用于传统的搜索场景,也能很好地支持日志分析、商业智能等应用场景。
- 索引(Index):类似的数据放在一个索引,非类似的数据放不同索引,一个索引也可以理解成一个关系型数据
- 类型(type):代表document属于index中的哪个类别(type)也有一种说法一种type就像是数据库的表,比如dept表,user表。需要注意的是,ES每个大版本之间差别很大。
- 映射(mapping):mapping定义了每个字段的类型等信息,相当于关系型数据库中的表结构,常见的数据类型 text、keyword、number、array、range、boolean、date、geo_point、ip 等等类型
Elasticsearch对比传统关系行数据库如下: 
核心概念
索引Index
一个索引就是一个拥有几分相似特征的文档的集合,比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引,一个索引由一个名字来标识(必须全部都是小写字母),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用这个名字,在一个集群中,可以定义任意多的索引。
类型Type
在一个索引中,你可以定义一种或多种类型,一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型,比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个引擎中,在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。当然,也可以为评论数据定义另一个类型。 高版本ES中逐渐抛弃了Type的概念,会有一个默认的 type:doc。
字段Field
相当于是数据表的字段,对文档根据不同属性的进行的分类标识
映射mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其他就是处理ES里面数据的一些使用规则设置也叫映射,按着最优规则处理数据对性能提高很大,因为才需要建立映射,并且需要思考如何建立映射才能对性能更好。
文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(JavaScript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。 在一个Index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在一个索引之中,文档必须被索引/赋予一个索引的type。
近实时NRT
Elasticsearch是一个接近实时的搜索平台,这意味着,这索引锁一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
Cluster
- 集群(Cluster)一个Elasticsearch集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识。
- 节点(Node):一个Elasticsearch实例就是一个Node,一台机器可以有多个实例,正常使用下每个实例都应该会部署在不同的机器上,Elasticsearch的配置文件中可以通过node.master node.data来设置节点类型
- node.master 表示节点是否具有成为主节点的资格,true代表的有有资格竞选主节点,false代表的是没有资源竞选主节点
- node.data 表示节点是否存储数据
- Node节点组合:主节点+数据节点(Master+Data),即有成为主节点的资格,又存储数据
shell
node.master: true
node.data: true数据节点(data): 节点没有成为主节点的资格,不参与选举,只会存储数据:
shell
node.master: false
node.data: true客户端节点(client): 不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡:
shell
node.master: false
node.data: false- 分片:每个索引由一个或者多个分片,每个分片存储不同的数据,分片可以主分片(primary shard)和复制分片(replica shard),复制分片是主分片的拷贝,默认每个主分片有一个复制分片,每个索引的复制分片的数量可以动态的调整,复制分片从不与它的主分片在同一个节点上。
- 副本:这里指主分片的副本分片(主分片的拷贝)。提高恢复能力,当主分片挂掉的时候,某个复制分片可以变成主分片。提高性能,get和search请求既可以由主分片又可以由复制分片处理
注意:每个索引可以被分成多个分片,一个索引页可以被复制0次(意思是没有复制)或多次,一旦复制了,每个索引有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态的改变复制的数量,但你事后不能改变分片的数量。 默认情况下,Elasticsearch中的每个索引被分片5个和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共10个分片。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| ?pertty 无效/报错 | 参数拼写错误 | 浏览器地址栏/日志 | 改为 ?pretty |
| 创建索引无效 | 用了 GET 访问 /index | 访问方式与返回码 | 改用 PUT /{index}?pretty |
| 插入文档报 405/400 | 用 GET 发送 JSON | 服务器日志/浏览器网络面板 | 用 POST/PUT /{index}/_doc/{id} 并放 JSON 到请求体 |
| /{index}/_doc/_search/1 返回异常 | 端点写错 | 路径 404/400 | 按 ID 查:GET /{index}/_doc/{id};搜索:POST /{index}/_search |
| 搜索无结果 | 把查询 DSL 放到"返回结果"而非请求体 | 抓包/浏览器面板 | 将 DSL 放请求体,POST /_search |
| HTTP/HTTPS 混用或跨域 | 同域名下 http/https 混搭 | 状态码 301/SSL 错误 | 统一协议;若走浏览器,配置 CORS/反代 |
| 401/403 未授权 | 8.x 默认启用安全 | 返回码与 WWW-Authenticate | 启用内置用户/API Key,或在内网/反代鉴权 |
| index_not_found_exception | 索引未创建/名错 | Kibana//_cat/indices | 先 PUT /{index} 再写入;核对小写命名 |
| 版本冲突 version_conflict_engine_exception | 并发更新 | 返回体 _version | 用 _update 或乐观锁带 if_seq_no/if_primary_term |
| 集群 Red/分片分配失败 | 分片/磁盘问题 | /_cluster/health、/_cat/shards | 释放磁盘、修复分片、调整副本数 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解