一,拷贝构造函数
1.概念:
拷贝构造函数是一种特殊的构造函数,其形参为本类的对象引用。
bash
class 类名
{
public :
类名(形参);//构造函数
类名(const 类名 &对象名);//拷贝构造函数
...
};
类名::类(const 类名 &对象名)//拷贝构造函数的实现
{
函数体
}例如:
cpp
#include <iostream>
using namespace std;
class Node
{
public:
Node(int num = 0);
Node(const Node& n);//拷贝构造函数
~Node();
private:
int m_num;
};
Node::Node(int num)
: m_num(0)
{
cout << " construct:" << endl;
}
// 拷贝构造函数的实现
Node::Node(const Node& n)
{
m_num = n.m_num;
cout << "copy construct:" << endl;
}
Node::~Node()
{
cout << "desconstruct:" << endl;
}
int main()
{
Node n1(12345);
Node n2 = n1;
return 0;
}程序解释:
- 进入 main
Node n1(12345);
编译器发现要用 int 初始化,所以调用 Node(int)。
实际执行:
初始化列表 : m_num(0) 把 m_num 设置成 0(即使传入了 12345)。
打印 " construct:"。
此时:
n1.m_num = 0
- 定义 n2
Node n2 = n1;
编译器看到"用已有对象 n1 初始化新对象 n2",所以调用 拷贝构造函数 Node(const Node&)。
执行过程:
给 n2 分配内存。
调用 Node(const Node& n):
m_num = n.m_num; → 把 n1.m_num 的值复制给 n2.m_num。
打印 "copy construct:"。
此时:
n1.m_num = 0n2.m_num = 0
- main 结束
程序退出前,会按 对象定义的逆序 调用析构函数。
先析构 n2:
desconstruct:
再析构 n1:
desconstruct:
程序最终输出
construct:copy construct:desconstruct:desconstruct:
总结
Node(int) 构造了 n1,但由于写死 m_num(0),所以传入的 12345 被忽略了。
Node(const Node&) 构造了 n2,把 n1.m_num 的值(0)拷贝给了 n2.m_num。
程序退出时,n2、n1 依次析构。
拷贝构造函数要点:
- 拷贝构造函数的函数名与类名相同,它是构造函数的一种重载形式
- 拷贝构造函数要求其形参中必须要有一个当前类的引用类型的类对象
- 拷贝构造函数也没有返回类型。语法:类名(const 类名& 对象名);
- 拷贝构造函数也可以实现重载
- 如果没有显示声明拷贝构造函数,编译器会生成一个默认的拷贝构造函数
二,浅拷贝
类中不包含任何指针成员来管理动态分配的内存时(即没有在构造函数中 new,在析构函数中 delete),通常不需要自己编写拷贝构造函数。
不提供自己的拷贝构造函数时,C++ 编译器会自动生成一个。这个自动生成的拷贝构造函数执行的是所谓的 "按成员拷贝 " (member-wise copy),也常被称为 "浅拷贝" (Shallow Copy)。
工作方式很简单:它只是将源对象的每个成员变量的值,逐一复制到新创建对象的对应成员变量中。
例如:
只包含基本数据类型
cpp
class Point {
public:
Point(int x_val, int y_val) : x(x_val), y(y_val) {}
// 没有自定义拷贝构造函数
// 没有自定义析构函数
private:
int x;
int y;
};
int main() {
Point p1(10, 20);
Point p2 = p1; // 调用编译器生成的拷贝构造函数
// 发生了什么?
// p2.x = p1.x; (p2.x 被设为 10)
// p2.y = p1.y; (p2.y 被设为 20)
}包含其他行为良好的类对象(如 std::string)
cpp
#include <string>
#include <iostream>
class Person {
public:
Person(const std::string& name_val, int age_val)
: name(name_val), age(age_val) {}
private:
std::string name; // string 内部管理着动态内存
int age;
};
int main() {
Person person1("Alice", 30);
Person person2 = person1; // 调用编译器生成的拷贝构造函数
}对于类类型(比如 std::string),则调用它们自己的拷贝构造函数。
std::string 是一个类,它内部管理着动态内存(通常存储字符数组)。
标准库为它定义了 拷贝构造函数,确保在拷贝时会重新分配内存,并把原字符串的内容拷贝过去。
所以在 Person 的拷贝构造中:
name 调用了 std::string 的拷贝构造函数(深拷贝字符串内容)。
age 是一个 int,直接按值复制即可。
关键点在于,std::string 这个类本身已经被设计得非常好。它的内部虽然有指针和动态内存,但它有自己的深拷贝构造函数。所以,当编译器为 Person 类生成拷贝构造函数并执行 person2.name = person1.name; 时,std::string 的深拷贝逻辑被触发,为 person2.name 分配了新的内存,并把 person1.name 的内容复制过去。
浅拷贝图示
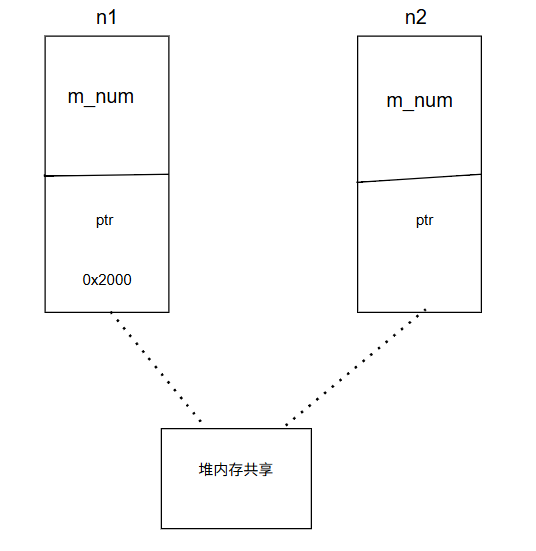
解释
n1 和 n2 是两个独立的对象(各自有 m_num 和 ptr)。
m_num 拷贝时是直接赋值。
如果拷贝构造函数只是**"浅拷贝** "(即直接 ptr = n.ptr),那么 n1.ptr 和 n2.ptr 会指向同一块堆内存。
好处:速度快。
坏处:两个对象析构时会 重复释放 同一块内存,出错。
如果对 n1 进行浅拷贝来创建 n2,会发生以下情况:
n2.m_num 会被赋值为 n1.m_num 的值。
n2.ptr 会被赋值为 n1.ptr 的值。也就是说,n2.ptr 也会指向 0x2000。
现在,n1 和 n2 的 ptr 指向了同一块内存。这会导致灾难性的后果:
-
双重释放 (Double Free):当 n2 的生命周期结束时,它的析构函数被调用,会 delete 地址 0x2000 的内存。
-
随后,当 n1 的生命周期结束时,它的析构函数也会被调用,它会再次尝试 delete 已经被释放的地址 0x2000。
-
对同一块内存释放两次是未定义行为,通常会导致程序崩溃。
如果拷贝构造函数实现了"深拷贝"(重新 new 一份内存,把内容复制过去),那么 n1.ptr 和 n2.ptr 会指向不同的堆内存块,互不干扰。
三,深拷贝
如图所示
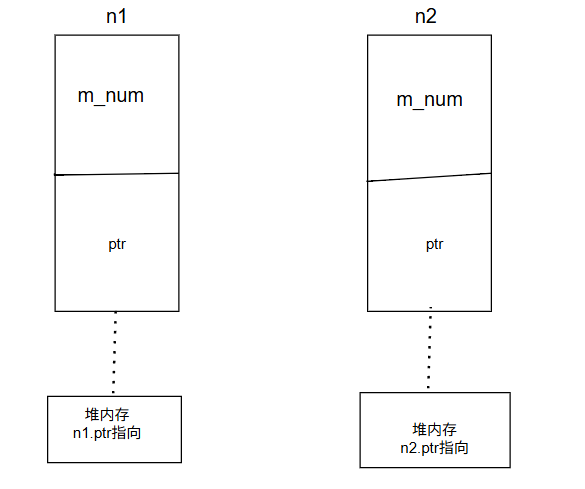
要实现深拷贝,你必须自己编写拷贝构造函数:
-
分配新内存: 在为 n2 执行拷贝构造时,应该为 n2.ptr 使用 new 分配一块全新的内存。
-
**复制内容:**然后,将 n1.ptr 所指向内存中的内容,复制到 n2.ptr 新分配的内存中。
这样一来,n1 和 n2 就各自拥有独立的内存块。当它们各自的析构函数被调用时,它们会安全地释放各自的内存,不会互相干扰,从而避免了双重释放的错误。
示例代码:
cpp
#include <iostream>
using namespace std;
// 节点类的定义
class Node
{
public:
// 构造函数 (带默认参数)
Node(int num = 0);
// 拷贝构造函数
Node(const Node& n);
// 析构函数
~Node();
private:
int m_num; // 存储一个整数值
int* m_ptr; // 指向动态分配的整数内存的指针
};
// 构造函数的实现
Node::Node(int num)
: m_num(num), m_ptr(NULL) // 使用成员初始化列表初始化 m_num 和 m_ptr
{
// 检查指针是否为空
if (m_ptr == NULL)
{
// 为指针分配一个新的整型内存空间
m_ptr = new int;
}
// 将传入的 num 值存入新分配的内存中
*m_ptr = num;
// 打印构造信息
cout << "construct: " << *m_ptr << endl;
}
// 拷贝构造函数的实现
Node::Node(const Node& n)
: m_ptr(NULL) // 初始化新对象的指针为 NULL
{
// 从源对象 n 拷贝 m_num
m_num = n.m_num;
// 检查新对象的指针是否为空
if (m_ptr == NULL)
{
// 为新对象分配一块独立的内存
m_ptr = new int;
}
// 将源对象指针所指向的 *值* 拷贝到新对象的内存中
// 这被称为"深拷贝"
*m_ptr = *n.m_ptr;
// 打印拷贝构造信息
cout << "copy construct: " << *m_ptr << endl;
}
// 析构函数的实现
Node::~Node()
{
// 释放构造函数或拷贝构造函数中动态分配的内存
if (m_ptr != NULL)
{
cout << "destruct: " << *m_ptr << endl;
delete m_ptr;
m_ptr = NULL;
}
}
// 主函数
int main(int argc, char *argv[])
{
// 1. 创建对象 n1
Node n1(12345);
// 2. 使用 n1 初始化对象 n2
Node n2 = n1;
// 上一行等同于: Node n2(n1);
// 3. main 函数结束
return 0;
}执行步骤:
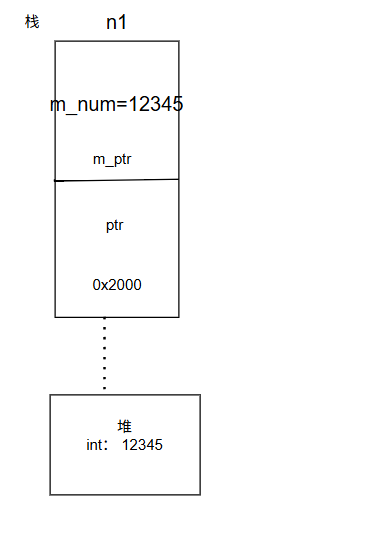
Step 1: 创建 n1
Node n1(12345);
进入 Node::Node(int num):
- m_num = 12345
- m_ptr = NULL(初始化列表赋值)
- 判断 m_ptr == NULL → 成立 → 分配一块新堆内存:m_ptr = new int;
- *m_ptr = num → *m_ptr = 12345
打印:construct: 12345
此时内存示意:
Step 2: 使用 n1 初始化 n2
Node n2 = n1;
进入 Node::Node(const Node& n):
- 初始化列表:m_ptr = NULL
- m_num = n.m_num → m_num = 12345
- 判断 m_ptr == NULL → 成立 → 分配一块新堆内存:m_ptr = new int;
- *m_ptr = *n.m_ptr → *m_ptr = 12345(深拷贝,内容相同,但内存独立)
- 打印:copy construct: 12345
此时内存示意:
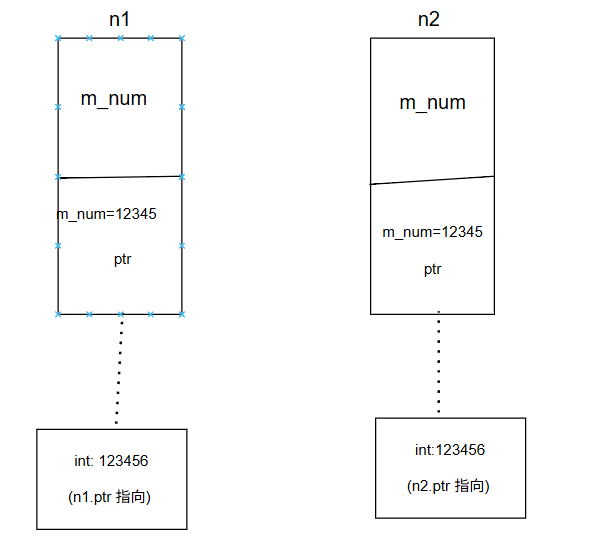
Step 3: main 结束,依次析构
作用域结束,析构顺序是逆序:
先析构 n2
打印:destruct: 12345
释放 n2 的堆内存
再析构 n1
打印:destruct: 12345
释放 n1 的堆内存
最终输出
construct: 12345copy construct: 12345destruct: 12345destruct: 12345
总结:
n1 构造时分配了一块堆内存并存储 12345。
n2 通过 深拷贝 构造,分配了另一块独立的堆内存,也存储 12345。
两个对象析构时,分别释放自己的堆内存 → 没有冲突(避免浅拷贝的 double free 问题)。
浅拷贝、深拷贝使用情况
1.浅拷贝只拷贝值,而不拷贝内存。缺省的拷贝构造函数进行的就是浅拷贝
2.深拷贝是连同值和内存一并拷贝,实际上内存是自行申请的,如果构造函数中出现了new或malloc,这种情况下通常要显示书写拷贝构造函数
什么时候会触发拷贝构造函数的调用:
1.当使用一个老对象构造一个新对象时。
2.当形参为普通类对象时(非引用),从实参到形参传递时,就会调用拷贝构造函数
3.如果函数返回类型是类对象时(非引用),也会调用拷贝构造函数
cpp
class A
{
public:
A(){cout << "A" << endl;}
~A(){cout << "~A" << endl;}
A(const A&a){cout << "拷贝构造" << endl;}
void fun(A a)
{
cout << "fun" << endl;
}
A fun1(A&a)
{
cout << "fun1" << endl;
return a;
}
};
int main()
{
A a;
//1.当使用一个老对象构造一个新对象时就会调用拷贝构造函数
//A b = a; //A b(a);
//a.fun(a);
//如果函数有返回值,但是我们没有显示接收时,系统会自动生成一个默认对象,用于接收返回值,这个隐式对象在当前这条语句执行完成后,就会被系统自动回收。
a.fun1(a);
return 0;
}隐式对象:
如果函数有返回值,但是我们没有显示接收时,系统会自动生成一个默认对象用于接收返回值,这个隐式对象,在当前这条语句执行完成后,就会被系统自动回收。
四,this指针
1. this 指针是什么?
this 是 C++ 中的一个关键字,它也是一个指针。在一个类的非静态成员函数中,this 指针指向调用该成员函数的那个对象。
简单来说,当你在程序中写 myObject.myFunction(); 时,编译器在执行 myFunction 的代码时,会自动将 myObject 的内存地址作为 this 指针传递给这个函数。这样,函数内部就能知道是哪个对象在调用它,从而可以访问这个对象的成员变量和成员函数。
this 指针是隐式传递的,你不需要在函数参数中显式地声明它,但可以在函数内部使用它。
2. this 指针的类型
this 指针的类型取决于调用它的对象的类型以及成员函数的属性。
对于一个 ClassName 类型的普通对象,在它的普通成员函数中,this 指针的类型是 ClassName*。
在一个 const 成员函数中(例如 void myFunction() const;),对象本身是不可修改的,因此 this 指针的类型是 const ClassName*。这意味着你不能通过 this 指针来修改对象的成员变量。
在一个 volatile 成员函数中,this 指针的类型是 volatile ClassName*。
示例:
cpp
class MyClass {public:
void regularFunc() {
// 在这里,this 的类型是 MyClass*
}
void constFunc() const {
// 在这里,this 的类型是 const MyClass*
}
};3. 为什么需要 this 指针?
this 指针主要解决了两个核心问题:
问题一:区分同名的成员变量和函数参数
当成员变量和成员函数的参数同名时,函数体内的变量名会默认指向参数。为了明确指定我们要访问的是类的成员变量,就必须使用 this->。
示例:
cpp
#include <iostream>
class Box {private:
double length;
double width;
public:
// 参数名和成员变量名相同
Box(double length, double width) {
// 如果直接写 length = length;
// 这只是把函数参数 length 的值赋给了它自己,成员变量没有被改变!
// 使用 this 指针来明确指定左边的是成员变量
this->length = length;
this->width = width;
}
void printDimensions() {
std::cout << "Length: " << this->length << ", Width: " << this->width << std::endl;
}
};
int main() {
Box b(10.0, 5.0);
b.printDimensions(); // 输出: Length: 10, Width: 5
return 0;
}在这个例子中,构造函数 Box(double length, double width) 使用 this->length = length; 来将参数 length 的值赋给类的成员变量 length。
问题二:返回对象自身的引用或指针
有时候,我们希望一个成员函数执行完后,能够返回调用它的那个对象本身,以便进行链式调用 (Method Chaining)。
示例:链式调用
cpp
#include <iostream>
class Calculator {private:
int value;
public:
Calculator(int v) : value(v) {}
// add 函数返回当前对象的引用 (Calculator&)
Calculator& add(int num) {
this->value += num;
return *this; // 返回 this 指针所指向的对象本身
}
// subtract 函数也返回当前对象的引用
Calculator& subtract(int num) {
this->value -= num;
return *this; // 返回 this 指针所指向的对象本身
}
void printValue() {
std::cout << "Current Value: " << this->value << std::endl;
}
};
int main() {
Calculator calc(10);
// 进行链式调用
calc.add(5).subtract(3).add(8);
calc.printValue(); // 输出: Current Value: 20
return 0;
}在 add 和 subtract 函数中,return *this; 返回了调用该函数的对象(calc)的引用。这使得我们可以在一行代码中连续调用多个方法,因为 calc.add(5) 的执行结果就是 calc 对象本身,然后可以继续对其调用 .subtract(3),以此类推。
4. this 指针的关键特性总结
隐式存在:this 指针是所有非静态成员函数的隐含参数。
无法修改:this 指针本身是一个常量指针(rvalue),你不能给 this 赋一个新的地址值。例如,this = &someOtherObject; 这样的代码是编译不通过的。
非静态:this 指针不能在静态成员函数中使用。因为静态成员函数不与任何特定的对象实例关联,它属于整个类。当调用静态函数时,没有对象实例,因此也就不存在 this 指针。
指向当前对象:它永远指向当前正在调用成员函数的那个对象实例。
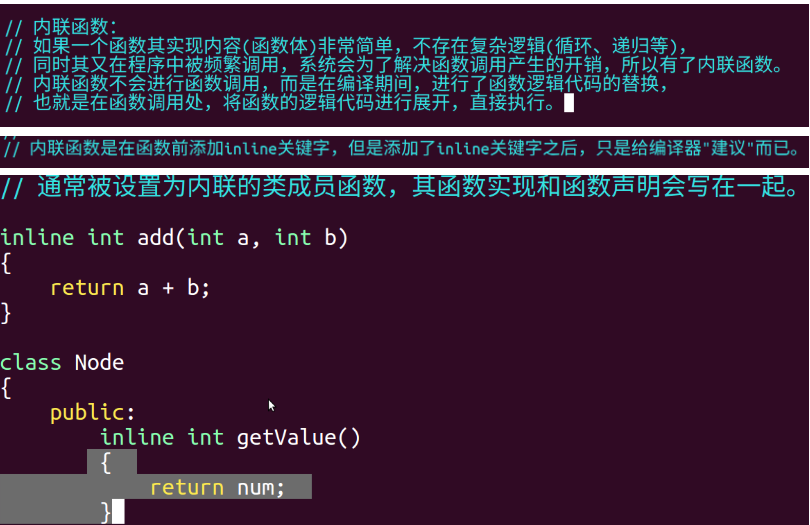
五,内联函数
在 C++ 编程中,我们无时无刻不在与函数打交道。函数帮助我们组织代码、实现复用,是模块化编程的基石。但你是否想过,每一次函数调用背后,都存在着一定的性能开销?当一个功能简单的函数被成千上万次调用时,这些开销累积起来,就可能成为程序的性能瓶颈。
为了解决这个问题,C++ 引入了内联函数 (Inline Function) 机制。
1.函数调用的"隐形成本"
深入了解内联函数之前,先要明白一个常规函数调用会发生什么。大致来说,CPU 会执行以下步骤:
- 参数压栈:将函数所需的参数按顺序压入调用栈。
- 保存返回地址:将当前指令的下一条指令地址压栈,以便函数执行完毕后能正确返回。
- 跳转:程序执行流跳转到函数的内存地址。
- 执行函数体:执行函数内部的代码。
- 返回:函数执行完毕,从栈中取出返回地址,程序跳转回去。
- 清栈:清理本次函数调用在栈上使用的空间。
对于大多数函数而言,这点开销微不足道。但如果一个函数极其简单(比如只返回一个变量),并且在一个紧凑的循环中被调用上百万次,那么函数调用本身的开销就可能超过了函数体执行的开销。这显然是得不偿失的。
2.内联函数如何"力挽狂澜"?
内联函数的核心思想非常直观:在编译期间,将函数的代码逻辑直接"复制粘贴"到调用它的地方。
它就像是编译器帮你做了一次"代码替换"。这样一来,程序运行时就不再需要进行函数跳转,而是直接执行嵌入的代码。
这是一种典型的"以空间换时间"的优化策略。
优点:消除了函数调用的开销,提高了执行效率。
缺点:如果函数体较大,会导致最终生成的可执行文件体积增大,可能会因为指令缓存(Instruction Cache)命中率下降而反而降低性能。
如上图所示,通过在函数 add 前添加 inline 关键字,我们向编译器提出了一个内联请求。
3.inline 关键字:这仅仅是一个"建议"
很多初学者会误以为,只要给函数加上 inline 关键字,它就一定会变成内联函数。但图片中的注释一针见血地指出了真相:
添加了 inline 关键字之后,只是给编译器"**建议"**而已。
inline 并不是一个强制命令,而是一个对编译器的请求或建议。编译器作为代码优化的专家,会自行判断这个建议是否合理。如果编译器认为内联该函数能够带来性能提升,它就会采纳;反之,则会忽略这个 inline 关键字,并将其当作一个普通函数来处理。
编译器通常会拒绝内联哪些函数?
- 函数体过于庞大或复杂:包含循环、递归、大量的 switch 语句等。
- 函数地址被取用:如果程序中有获取函数地址的操作(如函数指针),编译器通常不会内联它。
编译器自身的优化策略:不同的编译器、不同的优化级别,其内联策略都会有所不同。
所以,我们应该相信编译器的智慧。我们的任务是提出合理的建议,而不是试图去命令它。
4.内联函数与类的紧密结合
在 C++ 中,内联函数与类(class)的结合非常紧密,这是一种常见且优雅的实践。
一个重要的规则是:在类的定义内部实现的成员函数,会被编译器自动视为内联函数,无论你是否显式添加 inline 关键字。
在上面的 Node 类中,getValue() 函数的整个实现都写在了 class 的大括号内。因此,它是一个隐式内联 (Implicit Inline) 函数。这对于那些功能简单的成员函数(如 Getters, Setters)来说,是一种非常方便和推荐的写法。
当然,你也可以在类的外部定义成员函数,并显式地将其声明为 inline。但需要注意,内联函数的定义通常需要放在头文件(.h 或 .hpp)中,以确保所有包含该头文件的源文件都能获得函数的完整定义,从而正确地进行代码替换。
5.内联函数使用指南
总结一下内联函数的使用场景和最佳实践。
推荐使用 inline 的场景:
- 函数体小:代码行数少,逻辑简单,没有复杂的分支、循环或递归。
- 频繁调用:函数在性能关键路径上被大量调用,尤其是在循环内部。
- 类的存取函数:用于读取或设置私有成员变量的简单 Getters 和 Setters。
应该避免使用 inline 的场景:
- 函数体庞大或包含复杂逻辑。
- 函数包含递归调用。
- 不要盲目地将所有函数都声明为 inline,这很可能导致代码膨胀,性能不升反降。
结语
内联函数是 C++ 提供的一个强大的性能优化工具,但它并非万能灵药。正确理解其"代码替换"的本质和"编译器建议"的特性,并在合适的场景(小而频繁)下使用它,才能真正发挥其价值。
记住,代码的清晰性和可维护性通常是第一位的。在没有性能瓶颈的情况下,无需过度优化。当性能分析工具(Profiler)告诉你某个小函数的调用开销是瓶颈时,再考虑使用 inline 也不迟。
内联函数与c的宏函数有什么不同:
1、宏函数是在编译阶段处理,是纯字符串替换;内联函数是运行阶段处理,是函数逻辑替换; 2、宏函数无法调试; 内联函数可以调试;
3、宏函数没有返回值; 内联函数有返回值;
4、宏函数不能访问类成员; 内联函数可以访问类成员;