一次超惊险的故障排查经历
- 事件:双十一大促高峰期,核心用户服务集群出现大规模请求超时。
- 影响:"下单成功率"断崖式下跌,基于实时广告流量转化率估算,导致千万级广告费资损,故障被定级为P1。
- 时长:从故障爆发到"止血",耗时15分钟;从故障爆发到"根因定位",耗时约30分钟。
- 根因 :历史代码在一个全局共享的单例中,误用了非线程安全的
HashBiMap,在高并发下被触发竞态,导致其内部链表打环,读操作线程陷入无限循环,耗尽线程池。
大家好,我是老A。
上周我在沸点发起了一轮投票,咨询大家写作方向,大部分同学想看我是如何用arthas定位线上问题的,所以今天这篇文章我就好好讲讲,我是如何用arthas快速定位了线上问题,避免了千万级别的广告费资损的。
之前我说过,有两年我一直在做电商业务,也经常搞大促,常在河边走,哪有不湿鞋。记得有次双十一就差点弄了个P0故障,欲知故障如何,且听我细细道来。
双十一前一周,会进行各种大促保障评审、预案评审以及核心链路压测。前三天开始就要有人整夜的值班,那次双十一我们是负责整点拉新(用增),在能进行用增的各大会场、各种整点的活动(红包雨/秒杀)都放置转化埋点,将拉新做到极致。没成想,那次出的一个故障,差点把我们CTO送走了。。。
第一幕:风暴之眼------沉默的雪崩
时间拉回到2023年11月11号下午13点59分,我们用增小组的核心成员都在双十一作战室里盯盘(盯盘就是看大促期间的各种核心指标,包括核心的应用水位、各种技术指标、业务上的核心交易成功率、用增转化漏斗等等)。
再过一分钟,14点的红包雨活动就会开始,我们的用增埋点将涌入大量流量,完成它的转化使命。
14:00:我们看到用增埋点的流量曲线激增,所有的核心指标都很正常,我们都松了口气,准备接杯咖啡,开启一天的轻松盯盘工作。
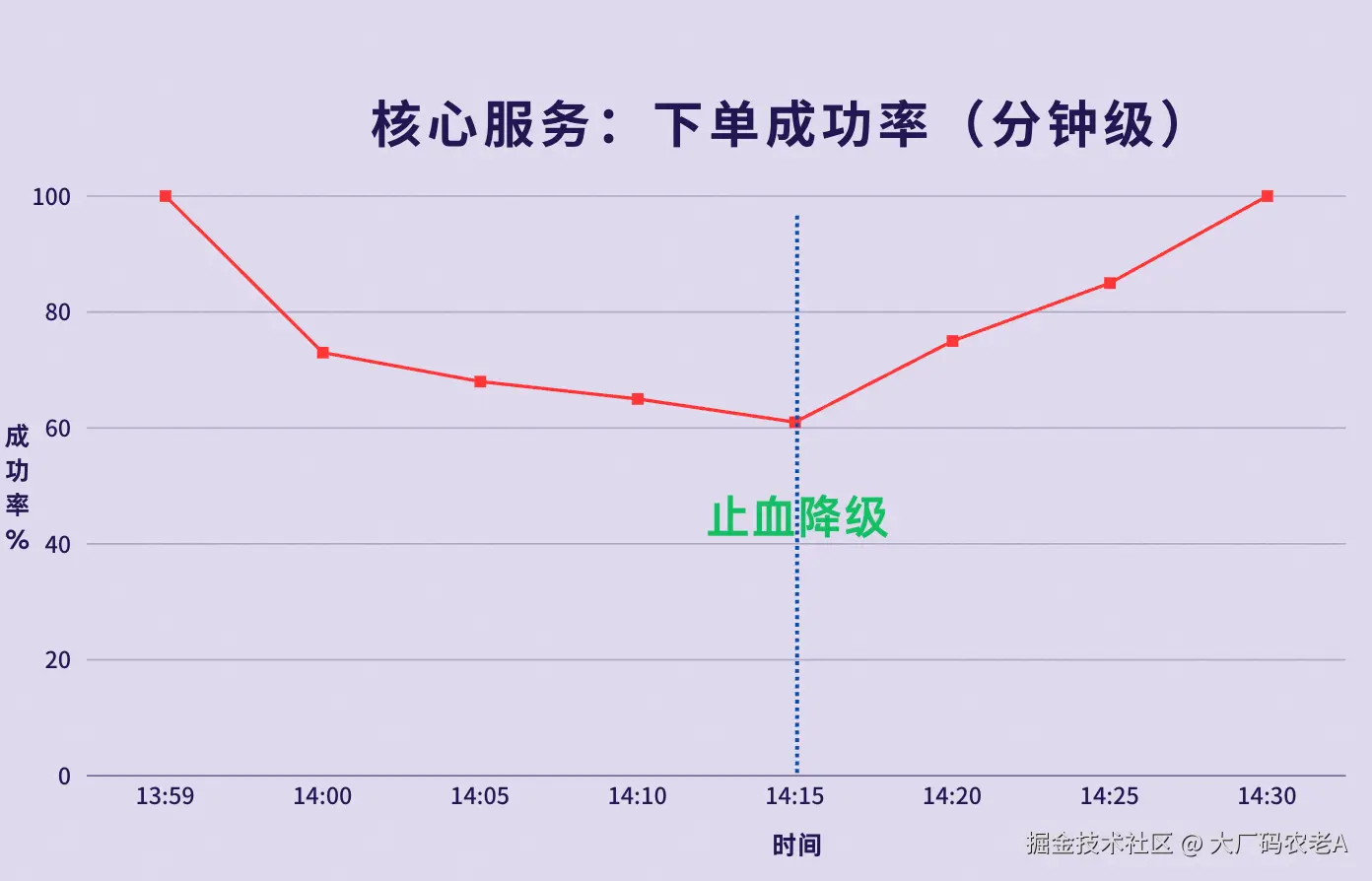
14:01:突然,核心大盘开始闪烁,"下单成功率"断崖式下跌,5分钟内,从99.9%暴跌到70%以下。告警群瞬间爆炸,全是核心交易链路的"调用超时"。卧槽,作战室瞬间炸开锅了。技术Leader王哥(化名)马上开始带我们排查原因。
14:02:P9老板冲进作战室,他没有说话,只是静静地看着大盘上那条触目惊心的下跌曲线。会议室里,空气仿佛都凝固了,只能听到我们团队疯狂敲击键盘的声音。
过了一分钟,他用一种不带任何情绪、但极其清晰的声音,对我的Leader说:"老王,按照公司故障标准,分钟级成功量下跌超30%,就直接触发P1。" 他指了指屏幕上已经跌破70%的成功率曲线。"现在已经P1了,15分钟内如果不能止血,就上升到P0故障。10分钟内我要定位原因,15分钟内我要止血,做不到你就直接去跟总裁解释吧。你也知道,大促每分钟的站外流量广告费,100万不止。"
详细时间线与排查过程
14:02 - 第一轮排查:信息"矛盾",陷入僵局
系统水位监控: 我们首先排查了集群整体的CPU、内存、网络、QPS大盘平均指标,发现无明显异常。
我立刻意识到,集群平均指标可能会稀释掉单点问题,随即立刻下钻到单机监控,果然发现有少数几个节点的CPU使用率出现尖刺。(跟SRE沟通确认后,发现在部署该服务的50个Pod中,有3个CPU负载达到了100%,占比6%,尚未对集群整体CPU造成明显冲击,但已经足以拖垮上游链路)。
所以我紧接着立刻去看了线程池监控,果然--tomcat工作线程池中忙碌线程占比100% ,线程池已耗尽!但是,Web入口的QPS曲线并未归零,只是略有下降!
老A点评:为什么线程池满了,QPS没归零?
这是Tomcat架构的一个典型特征。处理业务逻辑的worker线程池满了,但处理健康检查或部分简单请求的acceptor线程池还正常,导致了QPS看似平稳的假象。
14:10 - 第二轮排查:jstack的"误诊"
发现单点CPU打满,SRE的同学立刻对其中一台高CPU的"嫌疑机器",执行了 jstack,连续拉取了3份线程Dump。与此同时,GC日志(通过jstat)和APM的链路监控也都没有发现明显异常,所有线索都指向了应用内部。
Dump结果显示,大量业务线程处于 RUNNABLE状态,堆栈都指向HashBiMap.seekByKey,但没有任何死锁迹象。
老A点评:
jstack只能拍下一张静态快照。它对于【死锁】很敏感,但对于【死循环】或【活锁】这种RUNNABLE状态的软故障,它只能告诉我们线程在干什么,却无法告诉我们为什么一直在这里干。我们根据这份Dump,初步判断为"Guava某个方法有性能瓶颈",但无法解释为何会拖垮整个线程池(后来发现这里的判断是错误的)。
14:15 - 止血:业务降级
10分钟的止血DDL马上就要到了,根因依然不明。老王立刻做出决策:通过配置中心,将刚刚上线的【新用户首次下单送红包】功能,进行业务降级。因为这是最大、也是唯一的变量。
"血"暂时止住了。下单成功率开始缓慢回升。
老A说:为什么恢复是"缓慢"的?
即使关闭了新功能开关,那些已经陷入死循环的线程也不会立即释放,需要等待Tomcat的worker线程超时或被健康检查机制异常替换后才能被清理,因此恢复并非瞬时完成。
14:20 - Arthas登场
虽然止血了,但是问题根因还没找到,我对老王说:"Guava只是猜测,但我们不能靠猜。刚刚的jstack看不出具体的问题是啥,我很怀疑那几个线程死循环了。直接用arthas看看这几个线程的实时CPU消耗吧。"
第二幕:绝境亮剑------Arthas的降魔三式
在获得SRE和运维的紧急授权,并评估了Attach操作可能带来的微小性能抖动风险、确认当前系统状态尚能承受后,我直接在问题服务器上挂载了Arthas。
第一式:thread命令,找到"案发现场"
14:25 - thread -n 3
我执行了 thread -n 3。屏幕上,那几个RUNNABLE的线程(堆栈信息与jstack一致),CPU占用率赫然是100%!但这只是找到了"案发现场",并没有找到"作案手法"。
php
//【脱敏后示例】
[arthas@12345]$ thread -n 3
"biz-thread-1" prio=5 tid=0x00007f8c9a0b8000 state=RUNNABLE cpu_usage=99.99%
at com.google.common.collect.HashBiMap.seekByKey(HashBiMap.java:159)
at com.google.common.collect.HashBiMap.put(HashBiMap.java:109)
at com.example.service.UserCacheManager.syncUserCache(UserCacheManager.java:88)
at com.example.controller.NewUserController.handleNewUser(NewUserController.java:45)
...
"biz-thread-2" prio=5 tid=0x00007f8c9a0b9800 state=RUNNABLE cpu_usage=99.98%
at com.google.common.collect.HashBiMap.seekByKey(HashBiMap.java:159)
at com.google.common.collect.HashBiMap.get(HashBiMap.java:99)
at com.example.service.OrderServiceImpl.checkUserCache(OrderServiceImpl.java:112)
at com.example.service.OrderServiceImpl.createOrder(OrderServiceImpl.java:76)
...
"main" prio=5 tid=0x00007f8d1c009000 state=TIMED_WAITING cpu_usage=0.01%
...第二式:jad 与 stack,还原"作案手法"
14:26 - jad & stack
拿到了thread和stack的输出后,我心里反而咯噔一下,知道这事儿麻烦了。
为什么?
jstack报告里,所有线程都处于RUNNABLE状态,而不是BLOCKED,这意味着没有线程在等待锁,它们都在"疯狂地空转",这比死锁更难排查。
看到堆栈顶部的HashBiMap.seekByKey时,我的"并发PTSD"犯了------一个非线程安全的集合类 + 高CPU的RUNNABLE线程,这两个特征组合在一起,几乎可以确定问题出在了并发上。
我的初步推论是:这个HashBiMap的内部数据结构,在高并发写入下,已经被破坏了。 极大概率,是它内部用于解决哈希冲突的链表,被打成了环,导致任何读这个环的线程,都陷入了无限循环。
为了验证这个推论,我立刻用jad --classLoader [hash]指定类加载器,反编译了调用HashBiMap的xxxManager ,确认了它是一个没有加锁的、静态的、非线程安全的缓存实例,也就是说它内部是使用链表法来解决哈希冲突。
接着用stack com.xxx.service.xxxManager putUser,清晰地看到,所有触发写入操作的源头,都来自于被我们刚刚降级的【新用户首次下单送红包】功能。
所有证据都指向了同一个结论,但我还缺少最后一点证据。我需要在P9面前,拿出无可辩驳的铁证。
第三式:tt & ognl,找到铁证
第一步,tt时光隧道保留现场
14:28 - tt & ognl
先用 tt命令,捕获一次xxxManager.syncUserCache方法的调用现场。
bash
# -t 表示记录,-n 1 表示只记录一次,防止内存爆炸
tt -t com.xxx.service.xxxManager syncUserCache -n 1这个命令的作用是把整个JVM在那一瞬间的状态给冻结并保存了下来。 记录的INDEX是1001。
第二步,ognl深入内存,定位循环引用
然后,我写下了这段ognl表达式。它的作用,就是进入到我们刚刚冻结的那个xxxManager实例的内存里,直接拿到那个出问题的userCache(也就是HashBiMap),然后暴力遍历它内部的链表结构。
less
# -i 1001 指定刚才tt记录的index
# -x 4 表示结果最多展开4层,让我们能看清内部结构
# -w 表示执行ognl表达式
tt -i 1001 -w '#context=@com.xxx.util.SpringContextUtil@getApplicationContext(), #xxxManager=#context.getBean("xxxManager"), #biMap=#xxxeManager.xxCache, #table=#biMap.table, #entry=#table[15], {#entry.key, #entry.next.key, #entry.next.next.key, #entry.next.next.next.key}' -x 4老A说:这段OGNL到底做了什么
这段命令,实际上是一套组合拳:
#context=@com.xxx.util.SpringContextUtil@...():我们先通过一个能拿到Spring上下文的工具类,拿到了整个应用的ApplicationContext。#xxxManager=#context.getBean("xxxManager"):然后,直接取出了我们想要的那个xxxManager的实例。#biMap=#xxxManager.xxCache, #table=#biMap.table:深入xxxManager内部,拿到了它的私有字段xxCache(那个出问题的HashBiMap),甚至进一步拿到了HashBiMap内部存储数据的私有数组table。#entry=#table[15], ...:我们假设问题出在第15个哈希桶里,直接拿出这个桶的第一个节点(entry),然后暴力打印出它后面三个节点的key。
14:30 命令的返回结果,清晰地打印出了一个循环引用
less// 伪示例 @ArrayList[ @Long[12345], // entry.key @Long[67890], // entry.next.key @Long[12345], // entry.next.next.key @Long[67890], // entry.next.next.next.key ]
铁证如山!逻辑链至此完全闭环。
第三幕:收刀入鞘------从"救火"到"防火"
1. 根因到底是什么?
罪魁祸首,不是Google,而是我们自己。这是一个潜伏了三年的技术债 :一位前辈为了图方便,在一个静态的、全局共享的缓存实例里,误用了非线程安全的HashBiMap,并且还没有加任何锁。
arduino
// xxxManager.java - 导致问题的核心代码(部分截取示意)
// 老A说:Guava官方文档早已明确警告HashBiMap非线程安全, 建议使用Maps.synchronizedBiMap()包装。
public class xxxManager {
// 非线程安全
private static final BiMap<Long, UserInfo> userCache = HashBiMap.create();
// 未加锁写入,高并发下就是定时炸弹
// 多个线程同时调用,在内部扩容时极易发生竞态
public void xxCache(UserInfo newUser) {
userCache.forcePut(newUser.getUserId(), newUser);
}
}大促带来的海量新用户流量,触发高并发写入。在多线程下,HashBiMap内部在进行哈希冲突处理或扩容时,发生了竞态条件,破坏了其内部用于解决哈希冲突的链表结构,最终形成循环引用,导致任何读操作都陷入死循环。
2. 压测为何会失效?
后来我去翻了当时的压测文档,发现压测用的都是存量用户,几乎没有触发高并发的缓存写入场景。而大促开始的瞬间,海量新用户涌入,打开了这个埋了三年的雷。压测,永远无法100%模拟线上的"混沌效应"。
3. 长期改进措施
- 代码修复 :使用
ConcurrentHashMap替换HashBiMap,并重构相关逻辑。 - 流程改进 :在CR流程中,加入
线程安全的专项自动化check list;在静态代码自动化扫描中,增加对非线程安全集合类在单例中使用的检测规则。
老A说:
一个顶级专家的价值,不在于他会用多少工具,而在于他深刻理解每种工具的能力边界。比如知道什么时候
jstack会误诊,什么时候该用Arthas这类工具。
感谢大家的阅读。我是老A,一个只想跟你说点B面真话的师兄。
如果这篇文章让你有了一点点启发,那就是对我最大的肯定。
为了感谢大家的支持,我把这两年在一线大厂面试和带团队中,沉淀下来的所有私房笔记,整理成了一份《大厂码农老A的B面真话手册》。
里面没有市面上千篇一律的八股文,只有一些极其管用的潜规则和避坑指南,希望能帮你少走一些弯路。
关注我的同名公众号【大厂码农老A】,后台回复"B面",就能免费获取。后台回复"arthas"获取史上最全的《大厂arthas实战手册》
最后,如果觉得内容还行,帮忙点个赞、点个在看,让更多需要它的兄弟看到,感谢。