背景介绍:
从研一刚开始找实习到现在秋招,这一路经历了不少八股拷打,经常被要求手撕一些js基础题,每次面试完后不语,只是默默打开笔记,把被问到的八股/手撕自己整理,方便日后复习。因此,记录了很多手撕题,在此做个分享,有误之处欢迎讨论指正。
下面的几乎每道题都是笔者被大厂问到过的,都是些基础的题目,基础不牢地动山摇,书到用时方恨少啊~。切忌走马观花,务必深刻理解烂熟于心。建议以本文为大纲,自行拓展广度和深度。
面试感悟:
- 手撕题应该理解原理,练习/默写3遍及以上,确保能立即写出来。
- 基础八股在回答时,一个是要说话条理清晰,第二个是回答全面。
基本数据类型
7种原始类型:String, Number, Boolean, Null, Undefined, Symbol, BigInt 引用类型:Object
拓展 - TS的数据类型
基本类型 (如 string, number, boolean,undefined,symbol,bigint)
复合类型 (如 array, tuple, object,enum)
特殊类型 (如 any,unknown, void,never)
类型判断的几种方式?
typeof typeof 判断基础类型和函数,但不能区分对象类型(不能区分Object和Array)。
注意typeof的两个槽点:typeof null === 'object' 和 typeof NaN === 'number'
instanceof a instanceof A用来判断某个实例是否是某个构造函数创造出来的。原理是:这个实例的原型链上,有没有这个构造函数的原型。
Object.prototype.toString.call() Object 原型上的toString方法被xx调用,用来判断xx的类型。
js
//判断基础类型
Object.prototype.toString.call(123); // "[object Number]"
//判断数组
Object.prototype.toString.call([]); //"[object Array]"
//判断其他内置类型
Object.prototype.toString.call(new Map()); //"[object Map]"
Object.prototype.toString.call(/abc/); // "[object RegExp]"Array.isArray() 用来判断是否为数组。 判断数组的3中方式:
Array.isArray(arr)arr instanceof ArrayObject.prototype.toString.call(arg) === '[object Array]'
你用过Symbol和BigInt吗?
Symbol
Symbol是一种ES6引入的、表示独一无二值的第七种基本数据类型,主要用于避免命名冲突,作为对象属性的标识符,以实现唯一标识和支持可定制的属性
特性:使用Symbol用同样字符串构造产生的变量,是不全等的。
js
let k1 = Symbol("KK");
console.log(k1); // Symbol(KK)
typeof(k1); // "symbol"
// 相同参数 Symbol() 返回的值不相等
let k2 = Symbol("KK");
k1 === k2; // false使用场景举例: 1.vue中创建provide/inject使用的key
js
//创建不同key
export const ThemeKey = Symbol('theme')
export const UserKey = Symbol('user')
//父组件
<script setup>
import { provide, ref } from 'vue'
import { ThemeKey, UserKey, UpdateUserKey } from './keys.js'
const theme = ref('dark')
const user = ref({ name: 'Alice', age: 25 })
provide(ThemeKey, theme)
provide(UserKey, user)
</script>
//子组件
<script setup>
import { inject } from 'vue'
import { ThemeKey, UserKey } from './keys.js'
const theme = inject(ThemeKey)
const user = inject(UserKey)
</script>2.apply/call函数的实现中,为了防止污染属性
Bigint
能创建任意大的整数,避免了Number的最大整数限制(2^53-1) 1.创建BigInt::在数字后面添加 n 后缀即可创建BigInt。也可以使用 BigInt() 函数。 2.支持两个BigInt之间的加减乘除、取模% 和 指数**运算
js
const a = 10n;
const b = 5n;
console.log(a + b); // 15n
console.log(a * b); // 50nMap和WeakMap的区别?
Map的key可以是任意值,当key为Object时,当Object没有引用,WeakMap的key-value不会被回收 WeakMap任意key,当key为Object时,当Object没有引用,WeakMap的key-value会被回收
Map和普通对象区别?
1.key的顺序 Map保留了key-value插入的顺序。 普通字面对象遍历顺序没有保证。 2.key的类型 Map的key可以是任意类型(String, Boolean, Number, Symbol等) 普通字面对象的key只能是 String和Symbol(注意:当使用数字做key,实际上是给转成了字符串处理); 3.迭代方式 Map本身是可迭代对象,可以被for of迭代。 普通字面对象本身不可迭代,需要借助Object.keys()来迭代(不包含原型上的key)。(注意:使用for in 可以遍历普通字面对象的所有key,这个key包含了来自原型上的key) 4.序列化 普通字面对象可以被JSON.stringify()序列化 Map无法被JSON.stringify()序列化 5.性能考虑 在涉及频繁增删键值对的场景下,Map 的性能通常优于普通对象
拓展 - for of可以迭代可迭代对象的原理,这个就写在后面了~
浮点数精度 0.1+0.2!=0.3 问题
0.1+0.2 = 0.30000000000000004 。原因解释:这是所有采用IEEE 754标准的浮点数都存在的问题,0.1和0.2在进行计算的时候要转为二进制进行计算,但是0.1和0.2的二进制是无限循环的,那么当计算(加)完成后的数也是无限循环小数,有效位存不下就会"截断"。所以计算结果是一个近似值(会存在一点点误差)。
解决方法1 toFixed(参数表示小数位数)toPrecision(参数表示有效数位数)
js
console.log((0.1 + 0.2).toFixed(1)); // 0.3
console.log((0.1 + 0.2).toPrecision(1)); // 0.3解决方法2 使用mathjs等第三方库,
解决方法3 不使用浮点数,转换成整数计算(用整数表示浮点数)。比如1块4分,比起1.04,可直接使用104。
手撕
instanceof
a instanceof A用来判断某个实例是否是某个构造函数创造出来的。原理是:这个实例的原型链上,有没有这个构造函数的原型。
js
function instanceOf(obj, constructor){
//obj的原型链上,是否存在constructor.prototype
let proto = obj.__proto__
while(proto){
if(proto === constructor.prototype){
return true;
}
proto = proto.__proto__
}
return false
}测试:
js
function A(a){
this.a = a
}
function B(b){
this.b = b
}
// B继承A
B.prototype = Object.create(B.prototype, {
constructor:{
value: B
}
})
const x = new B('hello')
console.log(x instanceof A); //true
console.log(instanceOf(x, A)); //true深拷贝
1.JSON.stringify深拷贝存在的问题
- 序列化会丢失:undefined,symbol,function这些会被忽略
- 序列化过程中Date会变成字符串,RegExp会变成空{}
- 无法处理原型链 (原型链丢失)
- 无法处理循环引用(报错)
循环引用问题举例:
js
const a = {
next: null
}
const b = {
next = a;
}
a.next = b;Ps.后面会有个JSON.stringify的实现(手撕题)哦~
2.深拷贝基础版 - 考虑基础类型、数组、对象和对象的原型链
js
/*
按基础类型、数组、内置对象、对象 4块分类处理
基础类型 - 直接返回
数组 - 遍历deepCopy
内置对象 - 可迭代的就迭代并deepCopy,Date和RegExp就重新new一个
对象 - 创建一个空的新对象(创建时带原型),遍历对象的所有属性并deepCopy,依次挂到新对象上
*/
function deepCopy(obj){
const type = Object.prototype.toString.call(obj) // '[object String]','[object Object]'...
const isPrimitive = /String|Number|Boolean|Null|Undefined|Symbol|BigInt|Function/.test(type)
// 基础类型
if(isPrimitive){
return obj
}else if(type === '[object Array]'){ //数组
return obj.map(item=>deepCopy(item))
}else if(type === '[object Map]'){
const map = new Map()
for(const [k, v] of obj.entries()){
map.set(k, deepCopy(v))
}
return map
}else if(type === '[object WeakMap]'){
const map = new WeakMap()
for(const [k, v] of obj.entries()){
map.set(k, deepCopy(v))
}
return map
}else if(type === '[object Set]' ){
const set = new Set()
for(const item of obj){
set.add(deepCopy(item))
}
return set
}else if(type === '[object WeakSet]'){
const set = new WeakSet()
for(const item of obj){
set.add(deepCopy(item))
}
return set
}else if(type === '[object Date]'){
return new Date(obj)
}else if(type === '[object RegExp]'){
return new RegExp(obj)
}else{ //对象
const ans = Object.create(obj.__proto__) // 考虑原型,以obj.__proto__创建一个新对象
for(const key of Object.keys(obj)){ // for in会把原型上的属性直接拷贝过来,所以用keys()
ans[key] = deepCopy(obj[key])
}
return ans;
}
}测试:
js
const obj = {
name: '疯狂踩坑人',
children: [
{
name: 'God',
children: [{
name: 'Jessie'
}]
},
],
say : function(){
console.log('my name is '+this.name);
},
skills: ["CET-6", "Coding"],
relationship:{
parent: Symbol('parent'),
brothers: Symbol('brothers')
},
}
console.log(deepCopy(obj))3.深拷贝高级版 - 考虑循环引用
js
/*
例. a = {next: a}
用WeakMap记录上层出现过的对象,当某个属性引用到前面出现的对象,说明出现了循环引用,直接从WeakMap返回该对象即可。
*/
function advanceDeepCopy(target){
const wkMap = new WeakMap()
function _deepCopy(obj){
const type = Object.prototype.toString.call(obj)
const isPrimitive = /String|Number|Boolean|Null|Undefined|Symbol|BigInt|Function/.test(type)
// 基础类型
if(isPrimitive){
return obj
}else if(type === '[object Array]'){ //数组
obj.map(item=>_deepCopy(item))
}else if(type === '[object Map]'){
const map = new Map()
for(const [k, v] of obj.entries()){
map.set(k, _deepCopy(v))
}
return map
}else if(type === '[object WeakMap]'){
const map = new WeakMap()
for(const [k, v] of obj.entries()){
map.set(k, _deepCopy(v))
}
return map
}else if(type === '[object Set]' ){
const set = new Set()
for(const item of obj){
set.add(_deepCopy(item))
}
return set
}else if(type === '[object WeakSet]'){
const set = new WeakSet()
for(const item of obj){
set.add(_deepCopy(item))
}
return set
}else if(type === '[object Date]'){
return new Date(obj)
}else if(type === '[object RegExp]'){
return new RegExp(obj)
}else{ //对象。用weakMap记录对象,如果后续要拷贝同一对象,则不要深拷贝,而是直接反返回记录的这个对象
if(wkMap.has(obj)){
return wkMap.get(obj)
}
const ans = Object.create(obj.__proto__) // 考虑原型
wkMap.set(obj, ans)
for(const key of Object.keys(obj)){
ans[key] = _deepCopy(obj[key])
}
return ans;
}
}
return _deepCopy(target)
}原型和原型链
原型链
我觉得这篇文章一文彻底搞懂原型链很清晰的解释了原型链的,可以仔细看看。 这里借用了一下这篇文章的图,如下:
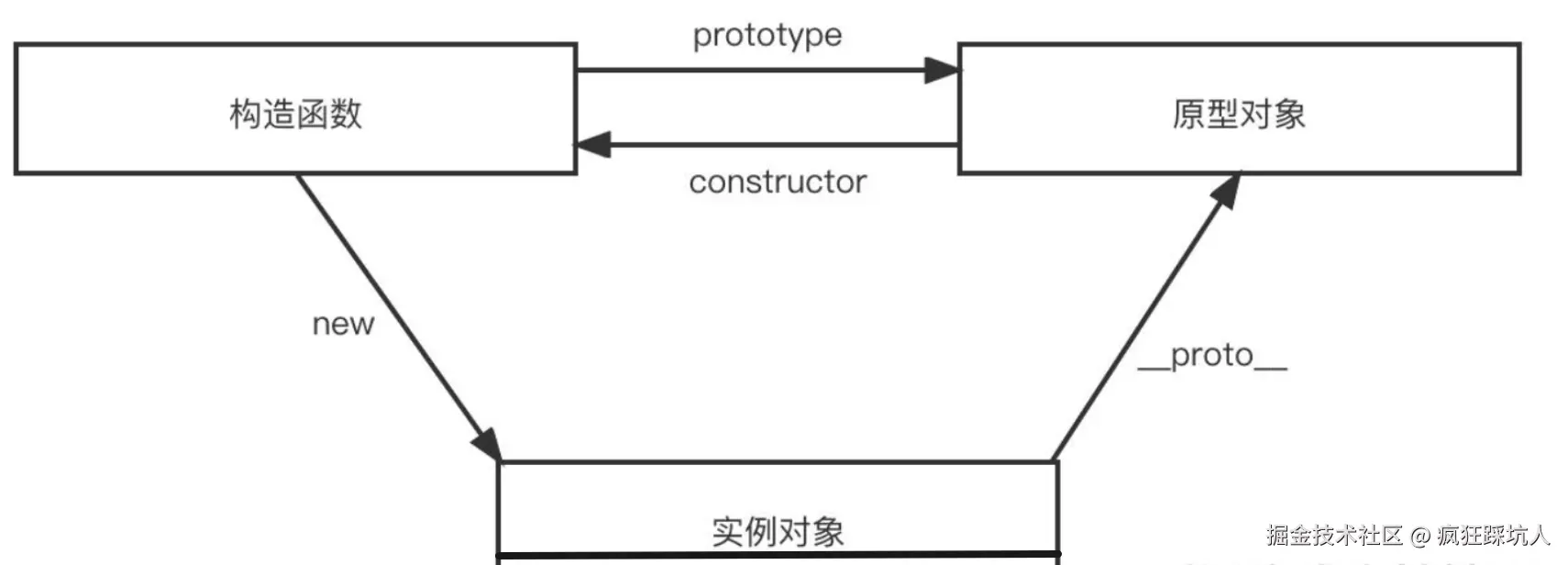
原型链关系对于刚接触的同学会有点绕,所以一定要先建立先验知识,记住下面两点:
- 记住第1点:原型是一个普通对象(是普通对象,就有
__protop__指针) - 记住第2点:函数和普通对象上(默认/自动)都挂载了一个原型(函数通过
prototype指针指向,对象通过私有属性__proto__指向)
如果普通对象是通过某个(构造)函数创建来的,那么它们的原型是同一个。普通对象通过__proto__指向原型,刚才说了原型本身也是一个普通对象,有__proto__,这样就构成了原型链。原型链就是通过__proto__一级级往上找原型形成的链。
下面举一个例子来理解:
js
function A(name){
this.name = name
}
const a = new A('疯狂踩坑人');默认/自动/没有手动修改的情况下,A.prototype(A的原型)是一个Object构建出来的对象,所以此时a的原型链如下: a.__proto__ 指向 {..., __proto__指向{..., __proto__:null} }
打印结果如图: !\[Pasted image 20251001112305.png]
继承
下面将重点介绍4种方式:借用构造函数继承、原型式继承、组合式继承和寄生式组合式继承。 还有另外两种(原型式继承, 寄生式继承)就不贴代码了,自行了解下即可。
1.借用构造函数继承:在子构造方法中调用父构造方法,完成this的属性方法绑定。
js
/*1.构造函数继承*/
function test1(){
function Foo(label){
this.labels = [label]
this.say = function(){
console.log('my name is '+this.name+', a '+this.label+'.');
}
}
function Bar(name, label){
Foo.call(this, label)
this.name = name
}
const b1 = new Bar('疯狂踩坑人', '程序员')
b1.say() // my name is 疯狂踩坑人, labels: 程序员.
}- 优点:创建子类对象可以传参,每个子类实例保留自己独立的属性
- 缺点:方法不能共享(每个实例都有一个独立的say方法)
2.原型链继承:通过原型链,沿用祖先的属性和方法。
js
/*2.原型链继承*/
function test2(){
function Foo(label){
this.labels = [label]
}
Foo.prototype.say = function(){
console.log('my name is '+this.name+', labels: '+String(this.labels)+'.');
}
function Bar(name){
this.name = name;
}
Bar.prototype = new Foo('自由职业');
const b1 = new Bar('疯狂踩坑人');
b1.labels.push('程序员')
const b2 = new Bar('疯狂踩坑人2');
b2.labels.push('程序员2') //
b1.say() // my name is 疯狂踩坑人, labels: 自由职业,程序员,程序员2.
b2.say() // my name is 疯狂踩坑人2, labels: 自由职业,程序员,程序员2.
}- 优点:方法共享,不用每个对象都创建一个方法
- 缺点:属性共享,不能在创建子类实例时给父类传参。(后续操作继承的属性时,会影响到所有实例)
3.组合式继承:结合了前面两项的优点 把实例方法都放在原型对象上,通过Child.prototype = new Father(),以实现函数复用。 通过Foo.call(this)继承父类的属性,并保留能传参的优点.
js
/* 组合式继承 */
function test3(){
function Foo(label){
this.labels = [label]
}
Foo.prototype.say = function(){
console.log('my name is '+this.name+', labels: '+String(this.labels)+'.');
}
function Bar(name, label){
Foo.call(this, label)
this.name = name;
}
Bar.prototype = new Foo();
const b1 = new Bar('疯狂踩坑人', '自由职业');
b1.labels.push('程序员')
const b2 = new Bar('疯狂踩坑人2', '自由职业2');
b2.labels.push('程序员2') //
b1.say() // my name is 疯狂踩坑人, labels: 自由职业,程序员.
b2.say() // my name is 疯狂踩坑人2, labels: 自由职业2,程序员2.
}- 优点:属性不共享,相互独立,可以通过传参来初始化。函数复用/共享。
- 缺点:直接用父类构造对象作为原型,这个原型是有一些不必要的属性(浪费内存)。上述代码中就是,子类实例本身有
this.labels,子类的原型上也有labels
4.寄生式组合式继承:主要在组合式的基础上做一个小改动------原型不使用new Foo(),而是使用Object.create(Foo.prototype)
js
function test4(){
// 属性放构造方法里,方法放原型上
function Foo(label){
this.labels = [label]
}
Foo.prototype.say = function(){
console.log('my name is '+this.name+', labels: '+String(this.labels)+'.');
}
function Bar(name, label){
Foo.call(this, label)
this.name = name;
}
Bar.prototype = Object.create(Foo.prototype, {
constructor:{
value: Bar
}
})
// 这样一来,Bar.prototype = {__proto__: Foo.prototype}
const b1 = new Bar('疯狂踩坑人', '自由职业');
b1.labels.push('程序员')
const b2 = new Bar('疯狂踩坑人2', '自由职业2');
b2.labels.push('程序员2') //
b1.say() // my name is 疯狂踩坑人, labels: 自由职业,程序员.
b2.say() // my name is 疯狂踩坑人2, labels: 自由职业2,程序员2.
}这是最完美的继承方案。具备了组合式继承的属性不共享、方法共享的优点,同时解决了它的缺点,令子类的原型上没有多余的属性。
作用域和作用域链
作用域链是指==在JavaScript中,当访问一个变量时,解释器会按照从内到外的顺序查找变量的机制,这个查找的路径就构成了一个链条==。这个链条由当前的作用域开始,然后逐级向上查找,直到全局作用域。 在var变量中,只有functon作用域和全局作用域。下面通过例子来说明作用域链:
js
var x = "global scope";
function checkscope(){
var x = "local scope";
console.log(x); // "local scope"
}
// 在checkscope函数中,先从checkscope函数域中找x变量,发现存在x的声明,就使用函数域的x,不会找到外面的全局x.
js
var x = "global scope";
function checkscope(){
console.log(x); // "global scope"
}
// 在checkscope函数中,先从checkscope函数域中找x变量,发现没有x声明,然后从外面第一层(这里是全局作用域)找到了x的声明,就使用了外面的全局xvar, let, const 区别
var和function存在变量提升,以var举例:
js
function funcTest() {
console.log(arg);
var arg = 2;
}
funcTest();等价于
js
function funcTest() {
var arg; // 变量声明被提升到函数作用域顶部,初始值为 undefined
console.log(arg); // 因此这里输出 undefined
arg = 2; // 赋值操作保留在原位执行
}这样一来var的变量可以先使用,再声明。对于function关键字定义的函数也是如此。
var和let区别一
- var只有funciton作用域和全局作用域
- let则除了funciton作用域和全局作用域,还有块级(
{})作用域
var和let区别二
- var有变量提升,可以先使用后声明。
- let/const也有变量提升,但是由于
暂时性死区,先使用后声明会导致报错。
作用域考题一:
js
// 题1
for(var i=0; i<5; i++){
setTimeout(()=>{
console.log(i);
}, 1000)
}
// 5 5 5 5 5
// 每次迭代,都是一个新的块作用域,每个块作用域都有一个独立的i变量
for(let i=0; i<5; i++){
setTimeout(()=>{
console.log(i);
}, 1000)
}
// 0 1 2 3 4作用域考题二:
js
// 题2
var a = 1;
(() => {
console.log(a);
a = 2;
})();
// 输出 1,查找到全局 a
var a = 1;
(() => {
console.log(a);
var a = 2;
})();
// 输出 undefined,变量声明提升
var a = 1;
(() => {
console.log(a);
let a = 2;
})();
// 输出 报错 闭包
闭包是什么?
一句话说明:闭包是一种编程形式,通过内部函数访问外部函数的变量,从而做到变量复用和避免污染全局变量等作用。 (也可以简单的把这个内部函数称为闭包,一种共识的表示而已)
闭包需要满足的条件:
- 函数嵌套,外面函数内部定义了一个内部函数
- 将内部函数返回
闭包举例:
js
function outer() {
const x = 10;
function inner() {
console.log('inner: ', x);
}
return innner;
}
const fn = outer();
fn(); // inner: 10下面举一个反面例子,不少人会误以为这也是一种闭包:
js
function outer(callback) {
const x = 10;
callback(x);
}
function inner() {
console.log('callback: ', x);
}
outer(inner); // callback: 10这种通过参数将函数传入的方式,闭包的两个条件其实都不满足。其实可以从本质上分析为什么上面这种不是闭包。
首先,关于这个问题还可以进一步深入解释,从词法环境(执行上下文)和垃圾回收的角度去分析。时间充足且有兴趣的同学可以看: 理解 JavaScript 中的执行上下文和执行栈 变量作用域,闭包
然后,这里简单分析下。
| 第一个例子 | 第二个例子 |
|---|---|
| 当执行outer函数时会创建一个词法环境,执行栈将x、inner装入。由于inner函数(闭包)被引用,导致执行栈中的x、inner变量都不会被清理,内存并没有释放。 | 当执行outer函数时会创建一个词法环境,执行栈将x、inner装入。当outer函数结束,outer的词法环境(执行上下文)会被销毁,执行栈中的变量会被清理。 |
手撕柯里化
一句话说明:把一个接收多个参数的函数,转换为一系列接收单个参数的函数,直到参数全部收集才执行计算。
记住两个关键词:收集参数、延迟计算。
下面通过一个例子来认识下柯里化: 编写一个像 sum(a)(b) = a+b 这样工作的 sum 函数。
js
function sum(a, b){
return a+b;
}
function currySum(sum){
return function(a){
return function(b){
return a+b
}
}
}这个currySum函数就被称为"柯里化函数",它返回的函数称为"被柯里化的函数"。看完这个例子,相信聪明的同学看出来了,一个通用型的柯里化函数是应该通过递归来实现的。下面就来手撕一个通用型的柯里化函数吧
实现一个通用的curry函数:
js
function curry(func, initArgs){
const arity = func.length; // func函数的形参数量
initArgs = initArgs || []
return function(...args){
const accArgs = initArgs.concat(args)
if(accArgs.length < arity){
return curry(func, accArgs)
}else {
return func.apply(this, accArgs) //谁调用了包装器,这个func就被谁调用
}
}
}测试:
js
function log(date, importance, info){
console.log(`${date} : ${importance} : ${info}`)
}
// 测试
const curriedLog = curry(log)
const logTool = curriedLog(new Date())
logTool('error', '出错了!')
logTool('warn', '这是警告')
logTool('info', '正常输出')this指向
全局的this(浏览器环境): 1.undefined(严格模式); 2.window(非严格模式)
全局的this(node环境):1.严格模式,undefined; 2.非严格模式, 指向模块自身的导出对象 module.exports
函数的this:
- 普通函数作为对象的方法调用,this指向该对象
- 构造函数调用(new),this指向实例对象
- 全局定义的函数会自动成为window的方法,直接调用相当于window调用,this是window
- 非全局定义的普通函数,通过赋值给全局变量,再调用,this是window
- 箭头函数没有自己的this,指向定义时所在this域
手撕
有三种方法可以改变函数this的指向,需要对这三种方法随时能手撕出来。
| 方法 | 调用时机 | 参数形式 | 返回值 |
|---|---|---|---|
call |
立即执行 | 参数列表 (arg1, arg2, ...) |
原函数的执行结果 |
apply |
立即执行 | 参数数组 ([arg1, arg2, ...]) |
原函数的执行结果 |
bind |
不立即执行,返回新函数 | 参数列表 | 一个永久绑定 this 的新函数 |
apply
js
Function.prototype.apply = function(context, args){
const fn = Symbol('fn')
context[fn] = this
const res = context[fn](...args)
delete context[fn]
return res;
}call
js
Function.prototype.call = function(context, ...args){
const fn = Symbol('fn')
context[fn] = this
const res = context[fn](...args)
delete context[fn]
return res;
}bind
js
// 显式绑定,不管谁调用,函数最终的this绑定的是context
Function.prototype.bind = function(context){
context = context || window
const fn = Symbol('fn')
context[fn] = this
return function (){
// 不是直接指向this()
// 而是改变this的指向,再执行
return context[fn](...arguments)
}
}根据实现代码,提一个小问题:为什么需要用Symbol ?
因为要把函数this挂载到上下文context对象上,但不能污染上下文对象原来的属性,所以用Symbol。
函数
箭头函数和普通函数的区别
箭头函数和普通函数的区别:
- 箭头函数没有this,不能改变this指向 (即无法通过call, apply, bind去显示的改变this)
- 箭头函数没有arguments
- 箭头函数不能作为构造函数 (不能new)
- 箭头函数没有原型
动态函数
API new Function ([arg1[, arg2[, ...argN]],] functionBody) 例子:
js
// 创建一个加法函数。最后一个参数字符串,可以被当做js执行
const add = new Function('a', 'b', 'return a + b');
console.log(add(2, 3)); // 输出: 5new实现
new的过程(5步):
- 创建一个空对象,作为将要返回的对象实例
- 将这个空对象的原型,指向了构造函数的
prototype属性 - 将这个空对象赋值给函数内部的
this关键字 - 开始执行构造函数内部的代码
- 如果构造函数返回一个对象,那么就直接返回该对象,否则返回创建的对象
通过伪代码代码记忆:
js
obj = Object.create(Constructor.prototype) //1,2
const res = Constructor.apply(obj, arguments) //3,4
return typeof res === 'object' ? res : obj; //5数组
数组有哪些方法?
| 方法分类 | 方法名称 | 描述 | 返回值 | 是否改变原数组 | ES版本 |
|---|---|---|---|---|---|
| 添加/删除元素 | push() |
向数组末尾添加一个或多个元素 | 新数组的长度 | 是 | ES5 |
pop() |
删除并返回数组的最后一个元素 | 被删除的元素 | 是 | ES5 | |
unshift() |
向数组开头添加一个或多个元素 | 新数组的长度 | 是 | ES5 | |
shift() |
删除并返回数组的第一个元素 | 被删除的元素 | 是 | ES5 | |
| 数组截取/拼接 | slice() |
返回数组的指定部分(浅拷贝) | 新数组 | 否 | ES5 |
splice() |
在指定位置删除/添加元素 | 被删除元素组成的数组 | 是 | ES5 | |
concat() |
合并两个或多个数组 | 合并后的新数组 | 否 | ES5 | |
| 数组转换 | join() |
将数组元素连接成字符串 | 字符串 | 否 | ES5 |
toString() |
将数组转换为字符串 | 字符串 | 否 | ES5 | |
Array.from() |
将类数组对象转换为数组 | 新数组 | 否 | ES6 | |
| 排序/反转 | sort() |
对数组元素进行排序 | 排序后的数组 | 是 | ES5 |
reverse() |
反转数组元素的顺序 | 反转后的数组 | 是 | ES5 | |
| 查找/判断 | indexOf() |
查找元素第一次出现的索引 | 索引值(未找到返回-1) | 否 | ES5 |
lastIndexOf() |
查找元素最后一次出现的索引 | 索引值(未找到返回-1) | 否 | ES5 | |
includes() |
判断数组是否包含某个元素 | 布尔值 | 否 | ES6 | |
find() |
查找第一个符合条件的元素 | 元素值(未找到返回undefined) | 否 | ES6 | |
findIndex() |
查找第一个符合条件的元素索引 | 索引值(未找到返回-1) | 否 | ES6 | |
findLast() |
查找最后一个符合条件的元素 | 元素值(未找到返回undefined) | 否 | ES2023 | |
findLastIndex() |
查找最后一个符合条件的元素索引 | 索引值(未找到返回-1) | 否 | ES2023 | |
| 遍历/迭代 | forEach() |
遍历数组执行回调函数 | undefined | 否 | ES5 |
map() |
对每个元素执行函数并返回新数组 | 新数组 | 否 | ES5 | |
filter() |
过滤符合条件的元素组成新数组 | 新数组 | 否 | ES5 | |
reduce() |
从左到右累加数组元素 | 累加结果 | 否 | ES5 | |
reduceRight() |
从右到左累加数组元素 | 累加结果 | 否 | ES5 | |
| 其他操作 | every() |
检测所有元素是否都满足条件 | 布尔值 | 否 | ES5 |
some() |
检测是否有元素满足条件 | 布尔值 | 否 | ES5 | |
flat() |
将嵌套数组扁平化 | 新数组 | 否 | ES6 | |
flatMap() |
先map后扁平化(深度为1) | 新数组 | 否 | ES6 | |
fill() |
用固定值填充数组元素 | 填充后的数组 | 是 | ES6 |
数组去重的方法?
方式一、使用Set
js
function unique(arr){
Array.from(Set(arr))
}方式二、for双重循环
js
function unique(arr){
const uniqueArr = [];
for (let i = 0; i < arr.length; i++) {
let isUnique = true;
// 检查当前元素是否已在结果数组中
for (let j = 0; j < uniqueArr.length; j++) {
if (arr[i] === uniqueArr[j]) {
isUnique = false;
break;
}
}
if (isUnique) {
uniqueArr.push(arr[i]);
}
}
return uniqueArr;
}方式二、使用filter嵌套循环
js
function unique(arr){
return arr.filter((item, index) => arr.indexOf(item) === index);
}方式一的时间复杂度O(n),另外两个时间复杂度是O(n^2). (Set的插入和查找时间复杂度是O(1),所以能做到第一种方式时间复杂度O(n).)
迭代方式 for in 和 for of的区别?
for of 能迭代可迭代对象的原理 JavaScript 中许多内置类型默认就是可迭代的,因为它们都实现了 [Symbol.iterator]方法,例如数组、字符串、Map 和 Set。这也是你能直接用 for...of循环它们的原因。
看定义:
ts
type IteratorFn = () => {
next(): { value: any; done: boolean };
};
type Iterator = {
[Symbol.iterator]: IteratorFn;
};就是可迭代对象有一个属性[Symbol.iterator],它表示一个函数,这个函数返回一个带有next方法的对象。 不知道你见没见过Map.next(),这说明了可迭代对象上可以通过不断调用next方法来遍历。 基于这一点,你可以创建一个对象来实现这种协议,从而变成可迭代的,比如:
js
const myIterable: Iterator = {
[Symbol.iterator]: () => {
let count = 0;
return {
next: () => {
if (count < 3) {
return { value: count++, done: false };
}
return { value: undefined, done: true };
}
};
}
};for in 工作原理 for in是用于遍历对象属性的一种循环机制。它可以遍历对象上除了Symbol外的所有可枚举属性,包括继承的可枚举属性。
js
// 创建一个对象并设置其原型
const proto = { inheritedProp: '来自原型' };
const obj = Object.create(proto);
obj.ownProp = '自身属性';
// 使用 for...in 遍历(会遍历自身和原型链上的可枚举属性)
for (let key in obj) {
console.log(key); // 输出: ownProp, inheritedProp
}```
由于会找原型链上的属性,所以性能不高。通常使用`for of` 遍历`Object.keys()`来替代。
#### 数组乱序的方法
核心思想:遍历数组的每个位置,从该位置后面的元素中随机选择一个和该位置元素交换。
```js
for (var i = 0; i < arr.length; i++) {
const randomIndex = Math.floor(Math.random() * (arr.length - i)) + i;
[arr[i], arr[randomIndex]] = [arr[randomIndex], arr[i]];
}
//测试
var arr = [1,2,3,4,5,6,7,8,9,10];
console.log(arr);随机获取数组的一个元素索引:
const randomIndex = Math.floor(Math.random() * arr.length)
随机获取数组某区间[i,j]的索引:
const randomIndex = Math.floor(Math.random() * (j-i+1)) + i
手撕
reduce
js
Array.prototype.myReduce = function(fn, initialValue) {
var arr = Array.prototype.slice.call(this);
var res, startIndex;
res = initialValue ? initialValue : arr[0]; // 不传默认取数组第一项
startIndex = initialValue ? 0 : 1;
for(var i = startIndex; i < arr.length; i++) {
// 把初始值、当前值、索引、当前数组 传递给调用函数
res = fn.call(null, res, arr[i], i, this);
}
return res;
}
// 测试
const res = [1,2,3].myReduce((pre, cur)=>{
return pre + cur;
})
console.log(res) // 6flat
遍历数组,如果元素是数组,那么递归继续「打平」,返回一个新数组。
js
function flat(arr, n=1){
if(n<1){
return arr; //n<1后不打平了
}
let res = []
for(const item of arr){
if(Array.isArray(item)){
res = res.concat(flat(item, n-1));
}else{
res.push(item)
}
}
return res;
}
// 测试
const arr = [1,2,['ss','hh', ['peace', 'love', null, {name: '疯狂踩坑人'}]], 3]
console.log(flat(arr, 1)); // [ 1, 2, 'ss', 'hh', [ 'peace', 'love', null, { name: '疯狂踩坑人' } ], 3 ]异步Promise
宏任务&微任务以及事件循环
这篇文章由浅入深了解浏览器的事件循环Event Loop可谓是比较详细介绍了事件循环。这里总结下就是:
- 浏览器/JS引擎中有两个队列:宏任务队列、微任务队列,分别用来存放浏览器的两类异步任务------宏任务和微任务。
- 所谓的宏任务和微任务就是一段延后执行的脚本/回调函数,比如
setTimeout(fn, 5)这里的fn将是一个宏任务。 - 浏览器先从微任务队列中取出所有任务执行完,然后从宏任务队列中取出一个宏任务执行。之后总是这样循环:先取出所有微任务,再取一个宏任务执行。构成了事件循环。
下面列举了宏任务和微任务:
宏任务
| # | 任务类型 | 浏览器 | Node |
|---|---|---|---|
| 1 | I/O (请求,读写文件) | ✅ | ✅ |
| 2 | setTimeout | ✅ | ✅ |
| 3 | setInterval | ✅ | ✅ |
| 4 | setImmediate | ❌ | ✅ |
微任务
| # | 任务类型 | 浏览器 | Node |
|---|---|---|---|
| 1 | process.nextTick | ❌ | ✅ |
| 2 | MutationObserver | ✅ | ❌ |
| 3 | IntersectionObserver | ✅ | ❌ |
| 4 | Promise.then/catch/finally | ✅ | ✅ |
Promise规范和原理
请你简单介绍下Promise?
1.介绍创建 :Promise初始化接受一个函数参数,该函数会立即执行。这个参数函数接受两个参数:resolve函数、reject函数。Promise对象有3个状态------pending,fulfilled和rejected,resolve能将状态变成fulfilled,reject能将状态变成rejected。一旦状态从pending变成结果状态,状态就不再改变。
2.介绍then/catch方法:当Promise对象状态变成结果状态,就会调用then的回调方法,then函数接受两个函数参数:成功回调&失败回调;并且返回一个新的Promise,这使得Promise可以链式调用。then返回的这个新的Promise的结果状态取决于上一个Promise的状态和then的两个回调函数的处理。catch方法可以作为错误的兜底处理。
3.介绍静态方法 :Promise.resolve, Promise.reject, Promsie.all, Promise.race, Promise.allSettled
建议时间充足的情况下,都尝试自己实现一个简单的Promise,理解其运行原理,可以参考「硬核JS」图解Promise迷惑行为|运行机制补充或其他资料。
异步输出练习
js
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
});
console.log('script end');
/*
过程分析:
宏任务队列:setTimeout
微任务队列:async1 end, promise2
输出 =======================
script start
async1 start
async2
promise1
script end (到这里,整个脚本结束。下面就是先取所有微任务,再取一个宏任务)
async1 end
promise2
setTimeout
*/手撕
实现delay
实现一个delay函数,等待ms时间后继续执行后面代码。
js
function delay(ms){
return new Promise((resolve)=>{
setTimeout(()=>{
resolve()
}, ms)
})
}
async function test(){
await delay(2000)
console.log('print after ms')
}实现promise的all/race/allSettled
实现all
all接受一个promise数组/可迭代对象,返回一个promise。当数组的所有promise都成功,则结果fulfilled;任一个失败则结果是rejected
js
Promise.all([pa, pb]).then([resA, resB]=>{
// 全部成功
}).catch(e=>{
// 任一个失败
})具体实现:
js
Promise.all = (iterable) => {
return new Promise((resolve, reject) => {
// 处理空迭代对象的情况
if (!iterable || iterable.length === 0 || iterable.size === 0) {
return resolve([]);
}
const len = Array.isArray(iterable) ? iterable.length : iterable.size; // 数组是length, Map是size
const results = Array(len).fill(null);
let successCnt = 0;
// 处理每个promise
iterable.forEach((item, i) => {
Promise.resolve(item).then((res) => {
results[i] = res;
successCnt++;
if (successCnt === len) {
resolve(results);
}
}).catch(e => {
reject(e);
});
});
});
}这里注意,需要用Promise.resolve包裹item,因为item可能不是Promise。(Promise.resolve(item)在item是Promise的时候直接返回item,否则会返回一个内部创建的成功Promise,value是item)
实现race
race接受一个promise数组/可迭代对象,返回一个promise。当数组中任一个promise先成功,则结果fulfilled;任一个先失败则结果是rejected
js
Promise.race([pa, pb]).then(res=>{
// 任一个先成功
}).catch(e=>{
// 任一个先失败
})具体实现:
js
Promise.race = (iterable)=>{
if(!iterable || iterable.length === 0 || iterable.size === 0){
return Promise.reject(new TypeError('Promise.race requires an iterable argument'))
}
// 重点
return new Promise((resolve, reject)=>{
iterable.forEach(item=>{
Promise.resolve(item).then((res)=>{
resolve(res)
}).catch(e=>{
reject(e)
})
})
})
}实现allSettled
- 当参数数组中所有Promise都达到结束状态时才结束promise,并且一定是返回一个成功的Promise
- 失败的promise以
{status:'rejected', reason: r}形式保存到数组,成功的promise以{status:'fulfilled', value: v}的形式保存到数组。
具体实现
js
Promise.allSettled = (iterable)=>{
const len = Array.isArray(iterable) ? iterable.length : (iterable?.size || 0)
const results = Array(len)
let cnt = 0
return new Promise((resolve, reject)=>{
if (!iterable || len === 0) return resolve([])
iterable.forEach((p,i)=>{
Promise.resolve(p).then((val)=>{
results[i] = {status: 'fulfilled', value:val}
cnt++
if(cnt === len)
resolve(results)
}).catch(e=>{
results[i] = {status:'rejected', reason:e}
cnt++
if(cnt === len)
resolve(results)
})
})
})
}
//测试
const p1 = new Promise((resolve, reject)=>{
setTimeout(_=>resolve(1), 2000)
})
const p2 = new Promise((resolve, reject)=>{
setTimeout(_=>reject('bad'), 1000)
})
Promise.allSettled([p1, p2]).then(results=>{
console.log(results);
/*
[
{ status: 'fulfilled', value: 1 },
{ status: 'rejected', reason: 'bad' }
]
*/
})限制异步并发数
方式一: 先运行limit个promise,然后当其中一个promise结束,唤醒下一个promise执行。
js
Promise.limitConcurrency = (urls, request, limit)=>{
if (!urls || !urls.length) return Promise.resolve([]);
return new Promise((resolve)=>{
let idx = 0; //资源序号
const result = Array(urls.length).fill(null)
let finishCnt = 0;
function next(){
if(idx === urls.length){ //调完
return
}
const curIdx = idx; //记录索引快照,用于then后的回调使用
idx++;
request(urls[curIdx]).then((val)=>{
result[curIdx] = {
status:'fulfilled',
value: val
}
console.log({
status:'fulfilled',
value: val
});
}).catch(err=>{
result[curIdx] = {
status:'rejected',
reason: err
}
console.log({
status:'rejected',
reason: err
});
}).finally(()=>{
next()
finishCnt++;
if(finishCnt === urls.length){
resolve(result)
}
})
}
// 先执行limit个,在next内部,当一个promise结束时,再启动下一个。
for(let i=0; i<limit && i<urls.length; i++){
next();
}
})
}测试代码:
jsx
// Mock请求
const request = item=> new Promise((resolve, reject)=>{
setTimeout(()=>{
if(item===2){
reject('error')
}else{
resolve(item)
}
}, 1000)
})
const urls = [1,2,3,4,5] // 请求资源
Promise.limitConcurrency(urls, request, 2).then(results=>{
console.log(results);
})你可以按我下面的思路来记住/默写这个方法
1.先搭建框架,传入多个资源、一个执行资源的异步方法和限制并发数limit. 结果返回一个Promise.
js
Promise.limitConcurrency = (urls, request, limit)=>{
if (!urls || !urls.length) return Promise.resolve([]);
return new Promise((resolve)=>{
const result = Array(urls.length).fill(null); //存放结果
})
}2.先假设有一个next方法,用来执行一个promise产生结果。一开始要执行limit次next方法。
js
Promise.limitConcurrency = (urls, request, limit)=>{
if (!urls || !urls.length) return Promise.resolve([]);
return new Promise((resolve)=>{
const result = Array(urls.length).fill(null); //存放结果
//next执行promise和处理结果
function next(){}
//先执行 limit次
for(let i=0; i<limit && i<urls.length; i++){
next();
}
})
}3.完善next方法,当next中的promise结束了,应该唤起下一个next(promise)的执行。并且考虑当所有promise结束,resolve结果.
js
Promise.limitConcurrency = (urls, request, limit)=>{
if (!urls || !urls.length) return Promise.resolve([]);
return new Promise((resolve)=>{
const result = Array(urls.length).fill(null); //存放结果
let idx = 0;
let finishCnt = 0;
//next执行promise和处理结果
function next(){
//记录索引快照,用于then后的回调使用。这一步需要稍微理解下为什么要curIdx。因为request调用后要保存结果到result,不确定当前的异步什么时候结束,而idx在这期间可能是变化了的,所以要保留一个快照。
const curIdx = idx;
idx++;
request(urls[curIdx]).then(()=>{
//...
})
.catch(e=>{})
.finally(()=>{
next(); //唤醒下一次
finishCnt++;
if(finishCnt === urls.length){
resolve(result)
}
})
}
//先执行 limit次
for(let i=0; i<limit && i<urls.length; i++){
next();
}
})
}4.考虑每次promise执行完成结果怎么保存。就是最终版本辣~
js
//自行默写一遍哦~方式二: 使用race的特性,只要有一个成功就结束,这样可以做到有一个完成后添加下一个promise执行。
js
Promise.limitConcurrency = async (urls, request, limit) => {
const executing = [];
const result = Array(urls.length).fill(null)
for (let i=0; i<urls.length; i++) {
const p = request(urls[i]).then((val)=>{
result[i] = {
status:'fulfilled',
value: val
}
console.log({
status:'fulfilled',
value: val
})
}).catch(err=>{
result[i] = {
status:'rejected',
reason: err
}
console.log({
status:'fulfilled',
reason: err
})
}).finally(()=>{
executing.splice(executing.indexOf(p), 1); //完成后删除,让位给下一个promise
});
executing.push(p);
if (executing.length >= limit) { //执行队列达到限制,就race。当其中一个promise完成了就会出队让出位置来。
await Promise.race(executing);
}
}
if(executing.length)
await Promise.all(executing);
return result
} 解释:
1.executing 数组存放执行中的promise。
2.遍历url,构建promise,将promise放入executing。同时每个promise在结束后需要被从executing中移除。
3.当executing达到限制,就race并发,待其中一个完成后继续循环(继续往executing加promise)
4.executing中剩下的用all并发,全部完成后就返回结果。
实现串行请求
有一个资源数组(每个资源可以用来创建Promise),实现一个函数,接受这个数组做到串行执行每个资源promise。
具体来说,有[1,2,3]。像下面这样的就是串行执行了:
js
// 写法一
createPromise(1).then(()=>{
return createPromise(2).then(()=>{})
}).then(()=>{
return createPromise(3).then(()=>{})
})
// 写法二
createPromise(1).then(()=>{
return createPromise(2).then(()=>{
return createPromise(3).then(()=>{
})
})
})辅助代码:
js
const createPromise = (id) => new Promise((solve, reject) =>
setTimeout(() => {
console.log("promise", id);
if(id === 2){
reject('2 error')
}
solve(id);
}, 1000)
);
// 实现queueExecPromise
// 测试
queueExecPromise([1,2,3]);实现方式很多。 按写法一的形式来实现: 前一个promise处理了,能在本次迭代拿到前一个promise。前一个promise的then方法中创建本次的promise.
js
function queueExecPromise(arr){
arr.reduce((prePromise, cur)=>{
return prePromise.then(val=>{
return createPromise(cur)
}).catch(e=>{
return undefined
})
}, Promise.resolve())
}按写法二的形式来实现: 一种递归的实现方式。(其实和并发限制很像,不过limit=1)
js
function queueExecPromise(arr){
function next(){
if(arr.length === 0){
return Promise.resolve()
}
const cur = arr.shift()
return createPromise(cur).then(val=>{
return next()
}).catch(e=>{
return undefined
})
}
return next()
}还可以使用async/await 来实现
js
async function queueExecPromise(arr){
for(const item of arr){
try {
const res = await createPromise(item)
console.log(res)
} catch (e) {
console.log(e)
}
}
}实现一个异步调度器
异步调度器 可以添加任务,然后调用flushQueue方法来刷新所有任务(即执行完成所有任务),并且执行任务有并发限制。
js
class Scheduler {
constructor(limit){
this.limit = limit;
this.queue = [];
}
add(taskFn){
this.queue.push(taskFn)
}
// 执行
flushQueue(){
for(let i=0; i<this.limit; i++){
this.next()
}
}
next(){
if(this.queue.length<=0){
return;
}
const task = this.queue.shift()
if(task){
task().then(res=>{
// console.log(res);
this.next()
}).catch(e=>{
// console.log(e);
this.next();
})
}
}
}测试:
js
//测试
let scheduler = new Scheduler(2);
const addTask = (time, order) => {
const task = () => {
return new Promise((reslove, reject) => {
setTimeout(() => {
console.log(order);
reslove();
}, time);
});
};
scheduler.add(task);
};
addTask(1000, "1");
addTask(500, "2");
addTask(300, "3");
addTask(400, "4");
scheduler.flushQueue();实现一个具有重试功能的request
实现一个request,可以在失败的时候重试,额外有两个参数:
- interval 重试时间间隔(s)
- retry 重试次数(次)
js
async function request(url, options, interval=3, retry=5){
let leftCount = retry
// 闭包+递归实现
const _requestData = (_url, _options)=>{
return fetch(_url, _options).catch((err)=>{
// 失败 => 重试(递归)
if(leftCount > 0){
return new Promise((resolve, reject)=>{ //=========catch返回的promise将取决于这个promise结果==================
setTimeout(()=>{
leftCount--;
console.log('重试...'+(retry-leftCount));
_requestData(_url, _options).then(resolve, reject)
}, interval*1000)
})
}else {
throw err
}
})
}
return _requestData(url, options)
}测试:
js
request('https://www.baidusdf.com',{Method:"POST"}).then(res=>{
console.log(res);
}).catch(err=>{
console.log('出错了!');
console.log(err);
})
/*
重试...1
重试...2
重试...3
重试...4
重试...5
出错了!
TypeError: fetch failed
*/节流防抖
手撕
节流
简单实现:
js
// 节流:每单位时间只执行一次。
// 场景:滚动;收藏/点赞按钮
// 实现:基于时间戳,判断时间差是否大于等于delay,来决定是否执行
function throttle(fn, delay){
let lastTime = 0
return function(){
if(Date.now() - lastTime > delay){
fn.apply(this, arguments)
lastTime = Date.now()
}
}
}Ps.也可以使用setTimeout定时器来实现。
js
function throttle2(fn, delay){
let timer = null
return function(){
if(timer){
return;
}
fn.apply(this, arguments)
timer = setTimeout(()=>{
timer = null;
}, delay)
}
}测试:
js
let cnt = 0
const throttledFn = throttle((x)=>{
console.log(x);
}, 1000)
setInterval(()=>{
throttledFn(cnt)
cnt++
}, 400)进阶要求:保证节流的最后一次调用一定执行。
js
function throttle2(fn, delay){
let timer = null
let lastTimer = null;
return function(){
if(timer){ // 冻结期
if(lastTimer){
clearTimeout(lastTimer)
}
lastTimer = setTimeout(()=>{
lastTimer = null
fn.apply(this, arguments)
}, delay)
return;
}
fn.apply(this, arguments)
timer = setTimeout(()=>{
timer = null;
clearTimeout(lastTimer)
}, delay)
}
}核心思想 :
在冻结期间,设置一个setTimeout定时器(对应lastTimer)触发fn调用,这个定时任务和冻结前的setTimeout(对应timer)的定时任务是互相"竞赛"的。 若timer定时先触发则最后一次就被取消,若lastTimer定时先触发就是最后一次执行。
防抖
简单实现:
js
// 防抖:延迟执行函数,等触发停止了单位时间再执行 (每次触发重新计算延迟时间)
// 场景:搜索输入;调整窗口大小
// 实现: 函数触发后, 延迟单位时间后执行,如果单位时间内触发,则重新计时
function debounce(fn, delay){
let timer = null
return function(){
if(timer){
clearTimeout(timer)
}
timer = setTimeout(()=>{
fn.apply(this, arguments)
}, delay)
}
}测试:
js
let cnt = 0
const debouncedFn = debounce((x)=>{
console.log(x);
}, 1000, true)
setTimeout(()=>{
debouncedFn(cnt)
cnt++
}, 500)
setTimeout(()=>{
debouncedFn(cnt)
cnt++
}, 500)
setTimeout(()=>{
debouncedFn(cnt)
cnt++
}, 1000)订阅发布模式
手撕
常见的问法:"写一个EventBus"、"写一个EventMitter"和"写一个订阅发布/观察者模式"。
js
/*
功能要求:实现on, off, emit, once
*/
// 调度中心/中介: 负责订阅事件、通知事件
function Event(){
this.listeners = {
}
}
// 1.注册/订阅
Event.prototype.on = function(eventName, listener){
if(this.listeners.hasOwnProperty(eventName)){
this.listeners[eventName].push(listener)
}else{
this.listeners[eventName] = [listener]
}
}
// 2.注销
Event.prototype.off = function(eventName, listener){
if(this.listeners.hasOwnProperty(eventName)){
this.listeners[eventName] = this.listeners[eventName].filter(e=>e!==listener)
}
}
// 3.once 一次注册,用完即注销
Event.prototype.once = function(eventName, listener){
const context = this
const fn = function(...args){
context.off(eventName, fn)
listener(...args)
}
this.on(eventName, fn)
}
// 4.通知
Event.prototype.emit = function(eventName, ...args){
if(this.listeners.hasOwnProperty(eventName)){
for(const listener of this.listeners[eventName]){
listener(...args)
}
}
}写订阅发布模式有两个注意点:
- 需要判断是否有该事件,使用hasOwnProperty;
- once注册,不是将listener直接注册,而是注册一个包装函数,用完即注销(这种方式比较优雅)。
另外,有些面试官会提到,可不可以订阅后产生一个ID,后续通过ID取消某个订阅? 解决这个问题,只需要Event维护一个全局的id,然后原来的listeners[eventName]从数组结构,改为对象结构({[id]:callback} , id做key,回调函数做值)。
正则相关
正则基础知识
字符串的方法 1.match方法 string.match(regexp) 匹配到项则返回一个数组,没有则返回null。数组的内容则根据正则是否是g模式有区分。
- 不是g模式:
[0]匹配的完整文本,后续元素表示捕获组(括号()匹配的文本),最后两项分别是index(匹配的字符串的起始位置)、input(原字符串) - 是g模式:返回所有匹配的字符串构成的数组(此时没有捕获组、index和input)
2.replace方法 string.replace(regexp, fn) ,当regexp不是g模式,则只调用一次fn来替换。当regexp是g模式则全局匹配了多少次就会调用多少次fn来替换。举个例子如下:
js
//第二个回调函数fn的参数分别是 匹配的字符串、捕获组、匹配字符串的起始索引和原始字符串引用(和match方法的非g模式是一样的)
export function test(){
const res = "1abc".replace(/(ab)(c)/g, (match, g1, g2, index, intput)=>{
console.log(match) //abc
console.log(g1) //ab
console.log(g2) //c
console.log(index) //1
console.log(intput) //1abc
return '0'
})
console.log(res); //10
}正则对象的方法 1.test方法 regexp.test(string)。测试字符串是否匹配正则,返回Boolean。
2.exec方法 regexp.exec(string)。g模式下,返回结果和match的非g模式几乎一样。不同的是正则对象可以多次调用exec方法,从而不断的匹配下一项(符合全局模式行为),举个例子:
js
export function test(){
const reg = /(ab)(c)/g
const str = "1abc2abc"
const res = reg.exec(str)
const res2 = reg.exec(str)
console.log(res); // [ 'abc', 'ab', 'c', index: 1, input: '1abc2abc', groups: undefined ]
console.log(res2); //[ 'abc', 'ab', 'c', index: 5, input: '1abc2abc', groups: undefined ]
}手撕
千分位
js
function formatPrice(price) {
return String(price).replace(/\B(?=(\d{3})+$)/g, ',');
}
//测试
console.log(formatPrice('888999')); //888,999
console.log(formatPrice('7888999')); //7,888,999
console.log(formatPrice('77888999')); //77,888,999解释:
- 首先
(\d{3})+$匹配3个数字3个数字一组的,并以3个数字结尾。 ?=表示后面的正则内容仅仅是断言(不是实际匹配),换句话说就是仅断言是否能匹配,但不作为最终匹配结果,这样就不会被replace掉。\B表示非单词边界(即前面应该有字符)
插值语法 {{}}匹配
如题:
js
/*
将插值{{}}的内容替换
*/
let str = "我是{{name }},年龄{ {age }},爱好{{ hobby}}";
const obj = {
name:'疯狂踩坑人',
age: 24,
hobby: 'buy'
}代码:
js
function replaceVar(str){
return str.replace(/\{\s*?\{(.*?)\}\s*?\}/g, (matchStr, g1)=>{
return obj[g1.trim()]
})
}
console.log(replaceVar(str)); //我是疯狂踩坑人,年龄24,爱好buyurl的params获取
js
function getUrlQuery(url, key) {
const queryObj = {}
const matches = /.+?\?(.+)/.exec(url)
if(matches){
//matches是数组,从第二个参数开始是捕获分组
if(!matches[1])
return undefined
const hashStartIndex = matches[1].indexOf('#')
const query = hashStartIndex===-1?matches[1]: matches[1].slice(0,hashStartIndex) //去hash
if(query){
const queries = query.split('&')
queries.reduce((acc, item)=> {
const kw = item.split('=')
const key = kw[0].trim()
if(acc[key] === undefined){
acc[key] = kw[1]
}else{
acc[key] = Array.isArray(acc[key]) ? [...acc[key], kw[1]] : [acc[key], kw[1]]
}
return acc
}, queryObj)
}
}
return key ? queryObj[key] : queryObj
}
const query = getUrlQuery('http://www.google.com/search?q=javascript&aqs=chrome.0.0l6j69i60j69i61j69i60.3518j1j7&sourceid=chrome&test=1&test=2#title');
console.log(query);一些API实现
JSON.stringify (wxg经典的一道手撕)
只考虑普通字面对象,如何实现JSON.stringify呢?先了解下一些规则
- 对于对象、数组会递归序列化,使用
{}、[]表示对象和数组边界 - 会丢失:Undefined/Function/Symbol
- 字符串需要
""边界,其他基础数据类型Number/Boolean/Null 等转字符串 举例:
js
const obj = {
name: '疯狂踩坑人',
children: ['good', 'bad', {rank: 1, has: false}],
say: ()=>{
console.log('hhh')
},
x:undefined,
y:null,
z:Symbol(1),
1:1,
}
// 转换后
// {"1":1,"name":"疯狂踩坑人","children":["good","bad",{"rank":1,"has":false}],"y":null}实现:
js
JSON.mystringify = (obj)=>{
const type = typeof obj
if(type === 'object' && obj!==null){ //对象
if(Array.isArray(obj)){
let ans = ''
for(const item of obj){
const value = JSON.mystringify(item)
if(value){
if(ans!==''){
ans += ','
}
ans += value
}
}
return `[${ans}]`
}else{ //简单处理, 其实还要考虑Map, Set
let ans = ''
for(const key of Object.keys(obj)){
const value = JSON.mystringify(obj[key])
if(value){
if(ans!==''){
ans += ','
}
ans += `"${key}":${value}`
}
}
return `{${ans}}`
}
}else if( /undefined|function|symbol/.test(type)){
// 忽略function 、undefined 、symbol
return
}else{
// 基础类型
return type === 'string' ? `"${obj}"` : String(obj)
}
}面试官可能会深挖的点:
1.考虑Map,Set,情况是怎么样的?
Map和Set对象会被处理为空对象{}。
2.循环依赖了,怎么处理?
使用一个WeakSet来记录已访问过的对象,如果遇到了访问过的,说明循环依赖了,抛出错误
parseInt
leetcode有一道类似的题 字符串转换整数 (atoi)
这里实现一个简单版本(一个正整数字符串 转 数字类型,忽略第二个参数,就按10进制来). 比如:"42" -> 42
代码:
js
function parseInt(str){
const baseCode = "0".charCodeAt(0)
let ans = 0;
for(let i=0; i<str.length; i++){
const curCode = str.charCodeAt(i)
const num = curCode - baseCode
ans *= 10;
ans += num;
}
return ans;
}
// 测试
console.log(parseInt("123")); //123
console.log(parseInt("042")); //42这里是有一点技巧的:
- 利用ASCII码做减法,算出字符的数值
- 从左到有遍历,每次对ans先乘10,一方面完成权重增加,另一方面有效处理了前导0。
trim
这是字符串的trim方法,作用:删除两端的空格。
js
function trim(str){
let i=0, j=str.length-1;
while(i<=j && str[i]===' '){
i++;
}
while(i<=j && str[j]===' '){
j--;
}
return str.substring(i, j+1)
}
// 测试
console.log(trim("x ab c d 1 ") + '_end');
console.log(trim(" x ab c d 1") + '_end');
console.log(trim(" x ab c d 1 ") + '_end');lodash.get
js
function get(obj, str, defaultVal=undefined){
const strType = typeof str
let path = []
if(strType === 'string'){
path = str.split('.')
}else if(Array.isArray(str)){
path = str
}else{
return defaultVal
}
let i=0;
let parent = obj
while(i<path.length ){
const type = typeof parent[path[i]]
if(type === 'object' && type !== null){ //继续搜
parent = parent[path[i]]
i++;
}else{
return parent[path[i]]===undefined ? defaultVal: parent[path[i]]
}
}
return parent;
}测试:
js
const _ = {
get
}
const object = {
a: {
b: {
c: 3
}
}
};
console.log(_.get(object, 'a.b.c')); // 输出: 3
console.log(_.get(object, 'a.b.x', 'default')); // 输出: 'default'
console.log(_.get(object, ['a', 'b'])); // { c: 3 }
console.log(_.get(object, ['a', 'b', 'c'])); // 输出: 3递归/迭代 思想
1.路径命名转树(字节面)
js
// 将arr转为output的形式
const arr = ['A', 'A.B', 'A.B.C', 'A.C', 'A.C.D', 'E', 'E.F', 'E.G', 'E.G.H']
const output = [
{
name: 'A',
children: [
{
name: 'B',
children: [
{
name: 'C',
children: []
}
]
},
{
name: 'C',
children: [
{
name: 'D',
children: []
}
]
}
]
},
{
name: 'E',
children: [
{
name: 'F',
children: []
},
{
name: 'G',
children: [
{
name: 'H',
children: []
}
]
}
]
}
]实现思路:路径字符串转数组,然后沿数组一级级找(没找到就创建节点挂载到主体上,找到节点则作为新主主体)。
js
function transform(arr){
const root = {children:[]}; //顶级节点
// 根据path一级级往下找,插入到root中
const _insert = (path)=>{
let cur = root;
for(const item of path){
const newCur = cur.children.find(child=>child.name === item);
if(newCur){ //找到节点,直接更新主体
cur = newCur
}else{ //没找到节点,创建节点,挂载到主体上
const s = {name: item, children:[]}
cur.children.push(s)
cur = s;
}
}
}
for(const item of arr){
//1.转数组
const names = item.split('.')
//2.沿数组找,插入
_insert(names)
}
return root.children;
}2.解析DOM属性(美团面)
html
<div>
<span>
<a>网址1</a>
</span>
<span>
<a>网址2</a>
<a>网址3</a>
</span>
</div>已知一个DOM结构如上,转换为下面的JSON格式
js
{
tag: 'DIV',
children: [
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] }
]
},
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] },
{ tag: 'A', children: [] }
]
}
]
}实现代码:
js
function dom2json(domTree){
const json = {}
if(typeof domTree === 'object' && domTree !== null){
json.tag = domTree.tagName
json.children = domTree.childNodes.map(child => dom2json(child))
}
return json;
}3.对象的key驼峰化命名(腾讯面)
js
// 输入
const input = {
err_msg:'hhh',
my_real_data: {
list: ['item1', {list_children: []}]
},
count: 13,
errors: [{field:'name', error_msg:'xx'}]
}
// 输出
{
errMsg: 'hhh',
myRealData: { list: [ 'item1', listChildren:[] ] },
count: 13,
errors: [ { field: 'name', errorMsg: 'xx' } ]
}实现代码:
js
function transformKey(key){
return key.replace(/_([a-z])/g, (matchStr, g1)=>{
return g1.toUpperCase();
})
}
function transformObj(obj){
const type = typeof obj;
// 对象
if(type === 'object' && type!==null){
if(Array.isArray(obj)){
return obj.map(item=>transformObj(item))
}else{
let newObj = {}
for(const key of Object.keys(obj)){
const newKey = transformKey(key)
// console.log(newKey);
newObj[newKey] = transformObj(obj[key])
}
return newObj
}
}else{// 基础数据类型
return obj;
}
}4.扁平数组转嵌套数组/Tree(猿辅导面)
js
//输入
const data = [
{id:1, name:'a', pid: 0},
{id:2, name:'bb', pid: 6},
{id:3, name:'cc', pid: 5},
{id:4, name:'dd', pid: 3},
{id:5, name:'ee', pid: 6},
{id:6, name:'ff', pid: 0},
]
//转换结果
{
"id": 0,
"children": [
{
"id": 1,
"name": "a",
"pid": 0
},
{
"id": 6,
"name": "ff",
"pid": 0,
"children": [
{
"id": 2,
"name": "bb",
"pid": 6
},
{
"id": 5,
"name": "ee",
"pid": 6,
"children": [
{
"id": 3,
"name": "cc",
"pid": 5,
"children": [
{
"id": 4,
"name": "dd",
"pid": 3
}
]
}
]
}
]
}
]
}实现代码:
js
function buildTree(arr){
// [pid]:nodes , pid为key记录节点
const map = new Map();
arr.forEach(item=>{
if(map.has(item.pid)){
map.set(item.pid, map.get(item.pid).concat(item))
}else{
map.set(item.pid, [item])
}
})
// root = {id:0, children:[]}
// 含义:找到每个节点的children
function _dfs(nodes){
for(const node of nodes){
if(map.has(node.id)){
node.children = map.get(node.id);
_dfs(node.children)
}
}
}
const root = {id:0}
_dfs([root])
return root
}排序算法
手撕
快速排序
可以去试试这道leetcode 排序数组
ts
function partition(nums: number[], i:number, j:number){
const idx = Math.floor(Math.random()*(j+1-i)) + i;
[nums[i], nums[idx]] = [nums[idx], nums[i]];
const x = nums[i];
while(i<j){
while(i<j && nums[j]>=x){
j--;
}
nums[i] = nums[j]
while(i<j && nums[i]<=x){
i++
}
nums[j] = nums[i]
}
nums[i] = x;
return i;
}
function quickSort(nums: number[], i:number, j:number) {
if(i<j){
const mid = partition(nums, i, j)
quickSort(nums, i, mid-1)
quickSort(nums, mid+1, j)
}
}
function sortArray(nums: number[]): number[] {
quickSort(nums, 0, nums.length-1)
return nums;
};快排应该是比较经常被问到的了,建议10min内能写完代码。并且能分析时间复杂度。