1.对于文件描述符的理解
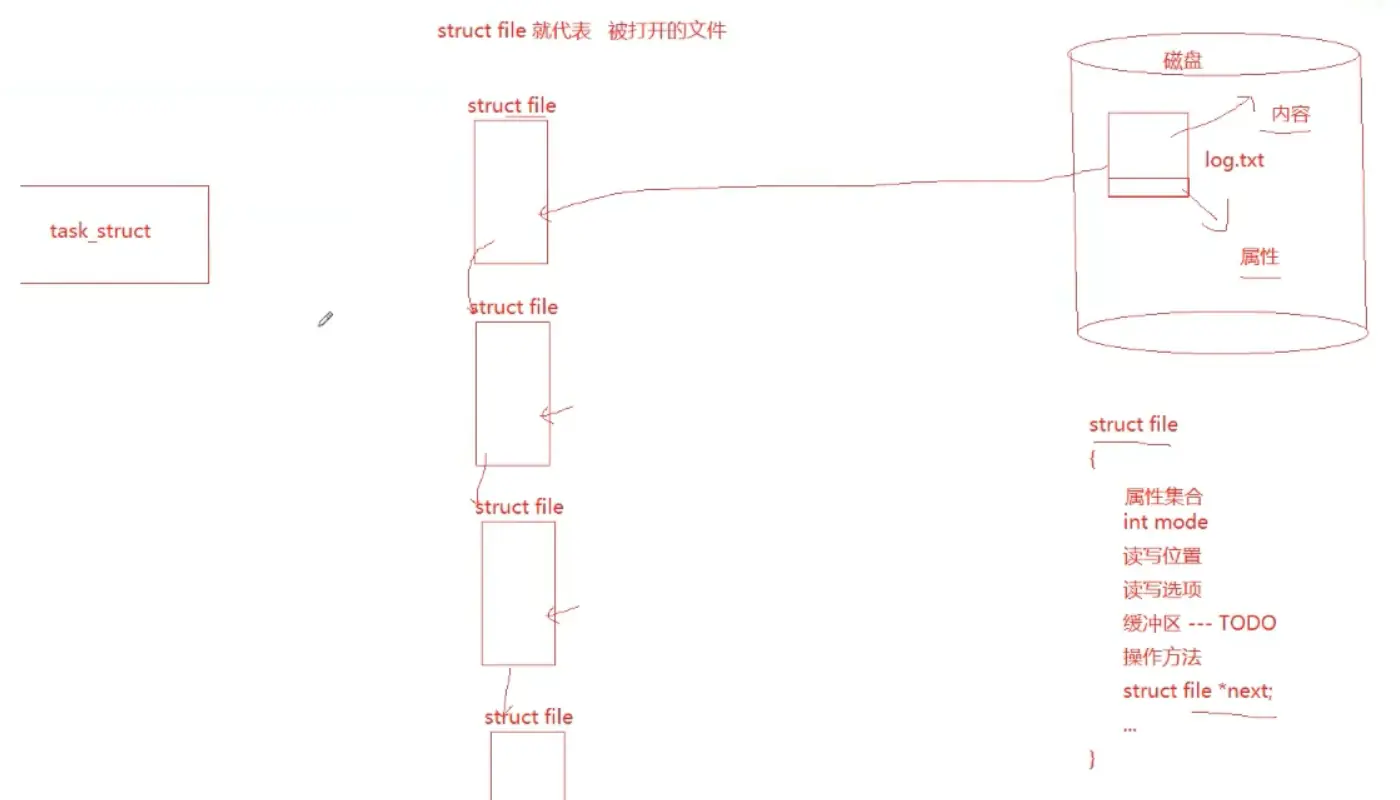
首先我们需要清楚的知道这个磁盘里面的文件是如何组织的,就是下面的这个 struct file,每一个 struct file 对应的都是一个具体的磁盘里面的文件;
task struct 表示的就是我们的进程的 PCB,我们对于文件的操作实际上就是对于这个 struct file 组成的双向链表的增删查改;
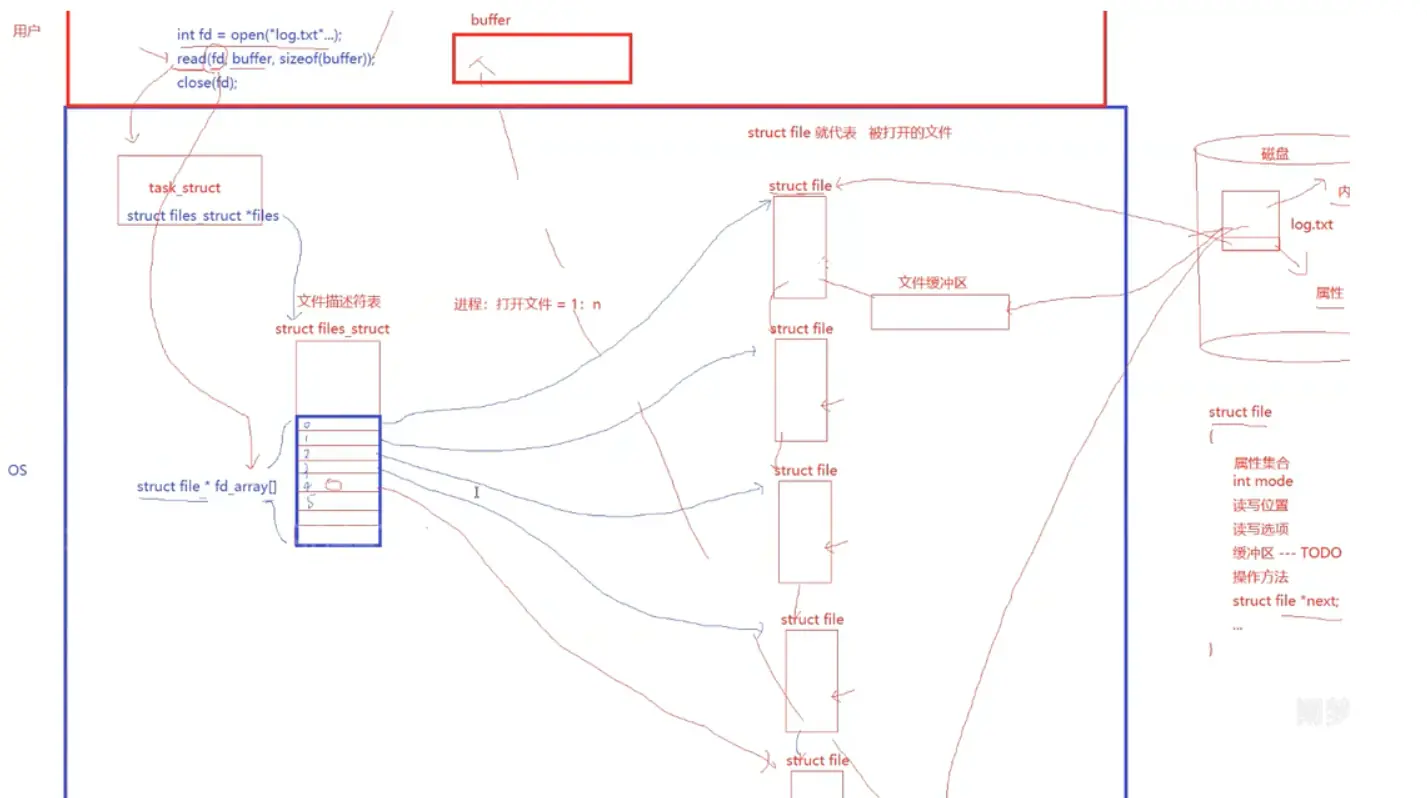
接下来我们需要介绍一下这个文件描述符,以及文件描述符表:
下面的这个是蛋哥上课时候画的一张图:主要是分为这个用户层面,以及我们的操作系统层面进行这个相关的介绍,其中在这个用户层面调用 read 读取文件,这个函数的时候,实际上这个就是拷贝函数,拷贝的就是我们的文件缓冲区里面的内容;
一个进程对应多个文件,一次这个进程操作文件的时候会通过这个文件描述符表进行相关的操作,我们的进程不会直接的对于这个文件进行相关的操作,而是通过文件描述符表对于这个文件进行管理,也就是我们之前说的这个观点:先描述,再组织,这个文件描述符表就是组织的过程,每一个 struct file 就是对于我们的磁盘上面的具体的文件进行描述的过程;
因此,我们的这个文件描述符表对应文件的 struct file,每一个 struct file 对应的都是一个文件的缓冲区,我们用户对于这个文件的相关操作,都需要我们的操作系统吧文件从磁盘加载到这个内核空间里面去,调用 read 函数,实际上就是把这个问价内容放到缓冲区,read 函数直接拷贝这个文件缓冲区里面的内容,实现从内核到用户空间的这个跨越的过程;
因此,我们上面说这个 read 函数,实际上就是拷贝函数,实现了从操作系统内核(里面的文件缓冲区)到我们的用户层(里面的 Buffer)的一次拷贝的过程;
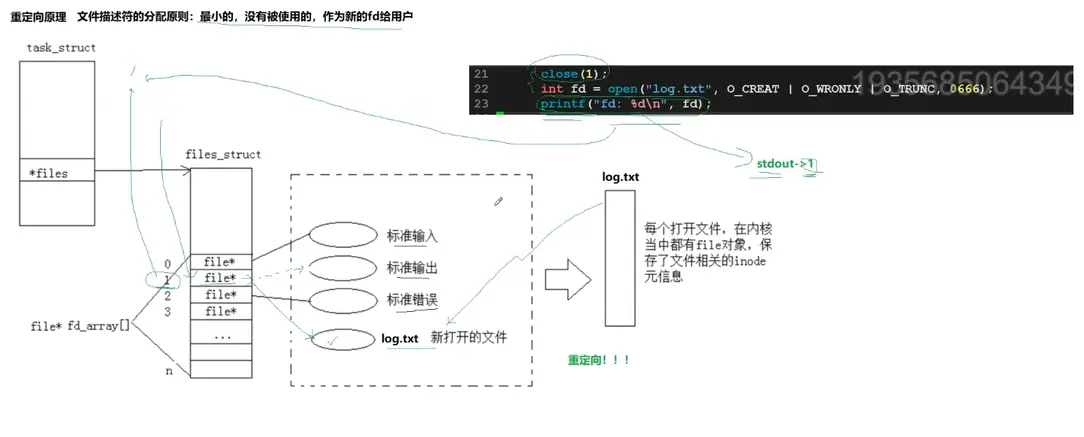
2.关于重定向
重定向的基本原理就是需要满足我们的文件描述符的相关的分配的规则:最小的,没有被使用的文件描述符才会分配给我们的用户;
针对于下面的这个图片的右上角的三行代码,这个实际上就可以对于我们的这个重定向的过程进行验证:
1)每一个进程的这个 PCB 也就是 task_struct 都有一个 files,这个指向的就是我们的文件描述符表,文件描述符表里面的 012 分别指向的就是我们的标准输入,标准输出,以及我们的标准错误;
2)当我们的关闭这个 1 文件描述符的时候,这个时候 1 就是所有的文件描述符里面的下标最小的那一个
3)我们的 txt 分配到的文件描述符就是所有的里面的最小的哪一个,也就是我们的 1,因此这个时候的 1 指向的不是我们的标准输出了,而是 txt 文件;
4)所以我们的代码的 23 行打印的时候,这个内容不会打印到这个控制台上面去,而是写入我们的 txt 文件里面去
5)这个过程是在内核里面发生的,也就是狸猫换太子,我们的上层用户只认这个文件描述符表里面 1,但是这个 1 的指向已经发生变化,指向的不是标准输出,而是 txt 文件,因此这个内容就写入到了这个 txt 文件里面去;
6)如果不关闭这个 1,这个时候原本 1 指向的还是我们的标准输出,正常情况下的打印还是会打印到这个控制台,因为是标准输出嘛;