
书接上回,在上篇文章中:
IEEE关键字搜索结果爬取![]() https://mp.csdn.net/mp_blog/creation/editor/152328482 通过抓包分析,我们获取到了关键字搜索结果中论文的题目以及Adobe PDF阅读器链接。那么本文我们就在此基础上,针对获取到的链接内的PDF内容进行爬取。
https://mp.csdn.net/mp_blog/creation/editor/152328482 通过抓包分析,我们获取到了关键字搜索结果中论文的题目以及Adobe PDF阅读器链接。那么本文我们就在此基础上,针对获取到的链接内的PDF内容进行爬取。
抓包分析
首先运行上篇文章中的完整代码,得到指定关键字查询结果的一些论文标题与下载链接:
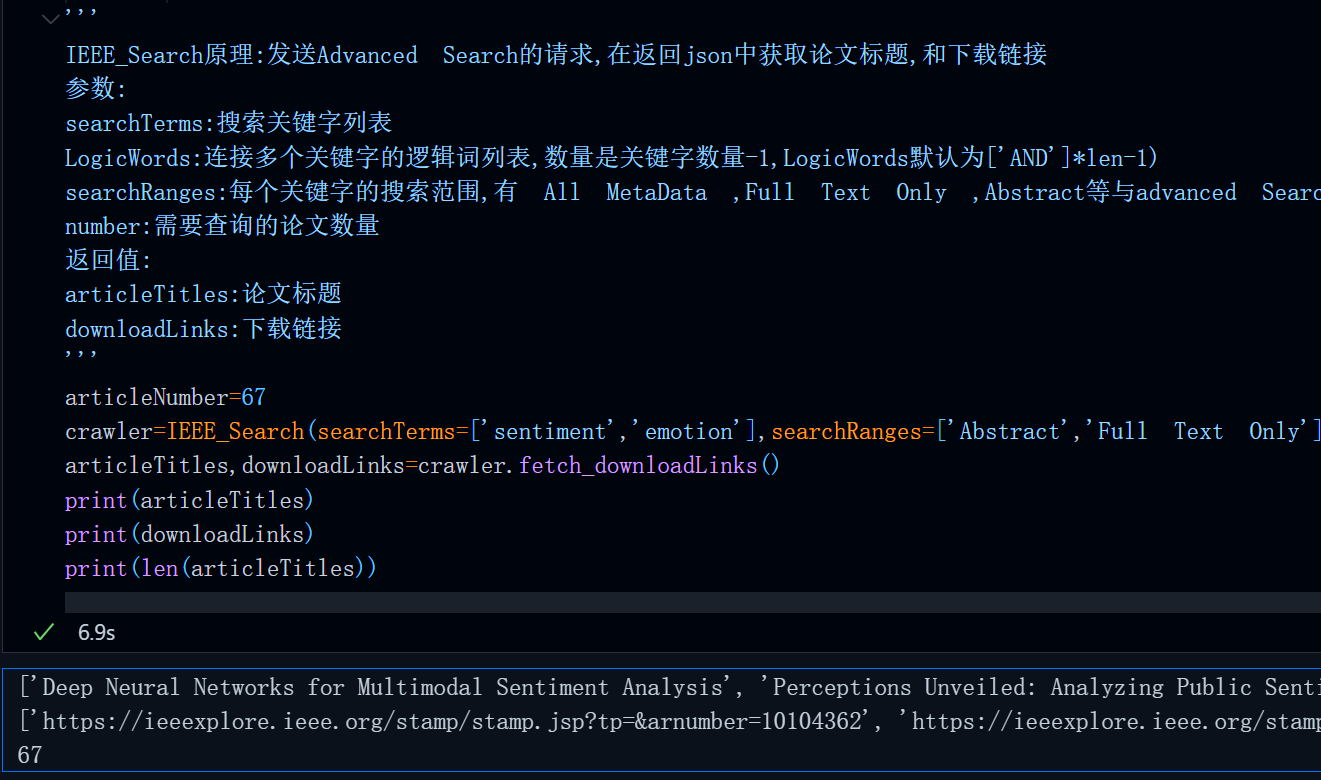
复制任意一个链接,在浏览器中打开:
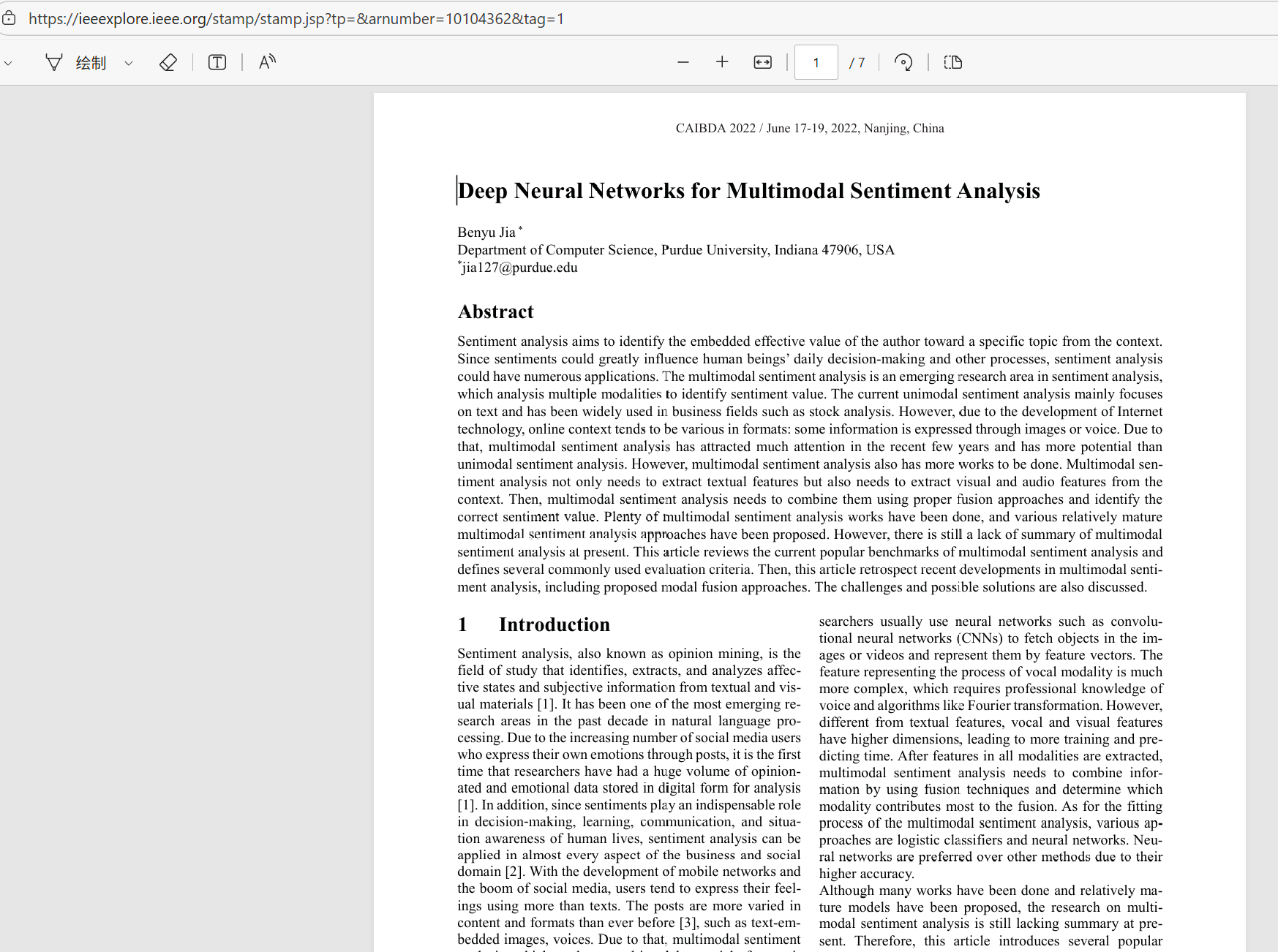
明显这是一个Adobe PDF阅读器界面,这样的阅读器界面中必然会有一个用来将服务器返回的二进制数据渲染为PDF的脚本
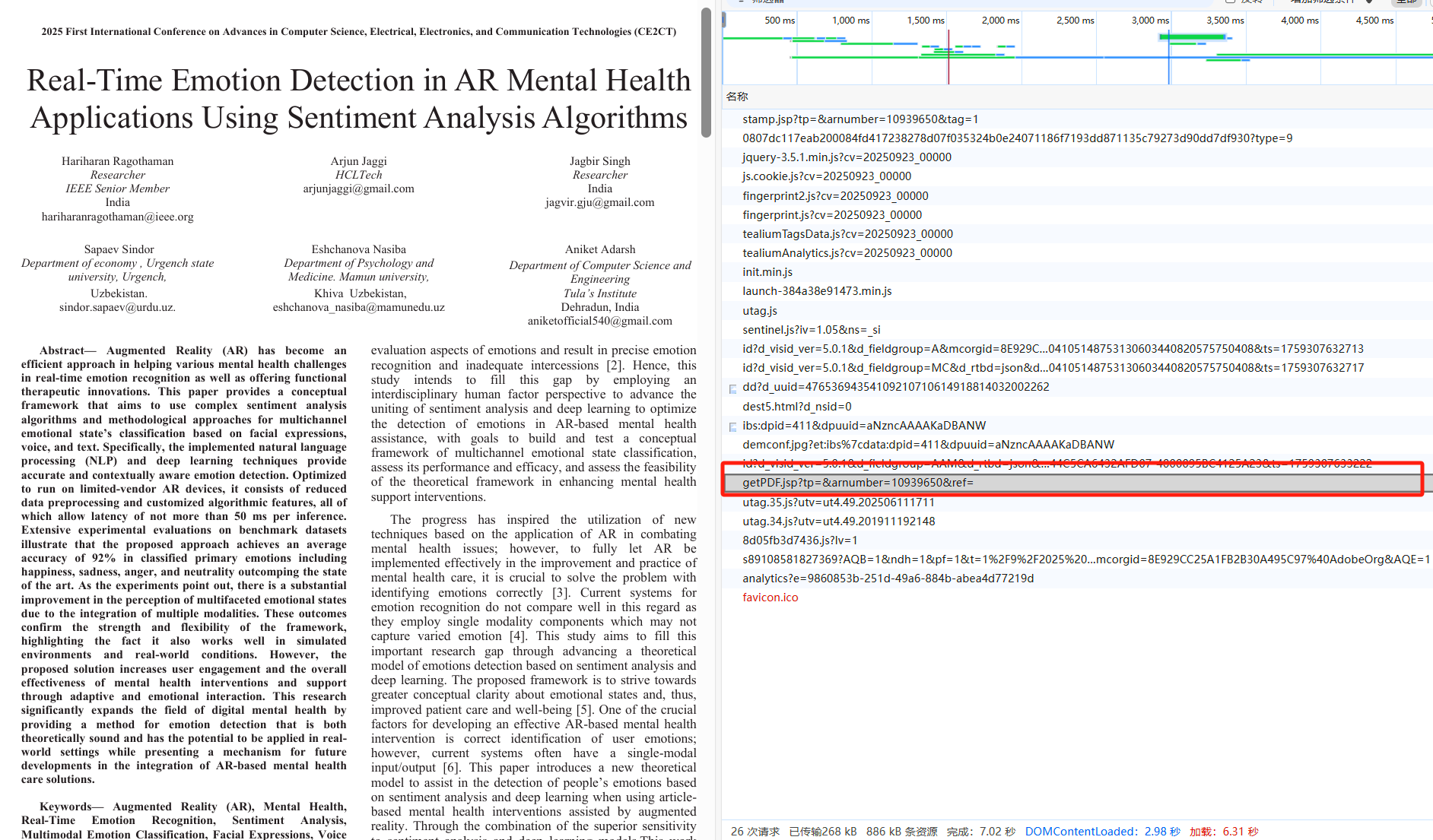
不难发现,这个getPDF.jsp便是用来实现上述操作的,接着来分析一下这个方法的标头和Cookie
Headers分析
标头内容较为固定,按照下方的格式即可:
python
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': 'https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10939650&tag=1',
'sec-fetch-dest': 'iframe',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
}其中,referer是我们在上篇播客中获取到的论文下载链接,回过头看一下负载,发现需要三个参数,分别是tp,arnumber,ref,其中tp与ref为空,这个可能是服务器动态生成的时间戳,ref应该是referer的缩写,考虑到header中已经存在,所以这里被设置为空值。
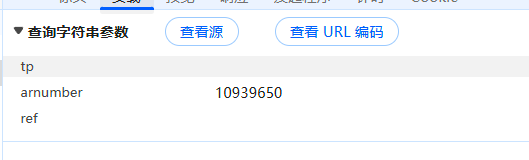
arnumber为下载链接中的数字,可以直接使用正则表达式查找。
cookie分析
python
cookies = {
'osano_consentmanager_uuid': 'c41cc576-38ed-4e7c-af9e-344cc7a3ac94',
'osano_consentmanager': 'DCV7eFQtKBjMPx5r3rfaByUMCLNHPCjwsHegzITEie-k2jMn4eLGp1LxJIVI6fHhPW2GMXwF7XTuKj1eG44bjDAY7oojmCYrhXVoGOOOZoyTs2tOTtm1KjsPv6tbZsIo0_SGc_j6JQ7ZmLsqYkkQiZeqZQgLWrkj6J6ygEbzGvQdyLF_AqnMdadJwD-ZDR_WJtefFiADpMmMKusxjsGavubihkEHlb1sJppEFaDVHFxhh5mLiwbouKm6Psblci9dYUwu3O3fK_c849SMkKWmkAfqVUFKs4eqeneSnrsjWnQQvwnqcsir1EXQXC2owHi7gvN9X1R6dy0=',
'AMCV_8E929CC25A1FB2B30A495C97%40AdobeOrg': '0%7CMCMID%7C48251904105148753130603440820575750408',
's_ecid': 'MCMID%7C48251904105148753130603440820575750408',
'hum_ieee_visitor': '571de201-d325-40f7-bc0c-7ebbfe0e8be4',
'hum_ieee_synced': 'true',
's_fid': '5A2EAC0ACD763018-3A7FC63021FAB60B',
'LT': 'XPLLG_XPL_2023_SUB_Xplore_Popup',
'cf_clearance': 'WC9OWnfrwhYTz_8Ko3ZjFjMgM_3WEIB7VJEMaht4DxM-1755780906-1.2.1.1-4NfjbvDvdkdERNyz9zy_5a1sznCBy3yfH_Gdhugm_lWcrNTA50oKzYIbnlVDIFQ7v2mVvgRNfEaUTmq0xS9UOo3axJh4QFn7jx16UnRLxCIoJqnnpO3nR.ry1geHKmxGvfeLIksSf_MhQfBSLoM0RF7zevTz47FF928TpW_9Ci5mQvB.jUN_LSrDf3N2qEwimLgCGT2Y91CkvdSBT4xWT8cp5ukiDooRZPnFRJvHMyg',
'fp': 'e480574091da96ecfce9ba8c917bfdb2',
'kndctr_8E929CC25A1FB2B30A495C97_AdobeOrg_identity': 'CiY0ODI1MTkwNDEwNTE0ODc1MzEzMDYwMzQ0MDgyMDU3NTc1MDQwOFIRCKnAsr%2DLMxgBKgRTR1AzMAPwAfamlJqRMw%3D%3D',
'AWSALBAPP-1': '_remove_',
'AWSALBAPP-2': '_remove_',
'AWSALBAPP-3': '_remove_',
'WLSESSION': '3053679114.47873.0000',
'__gads': 'ID=b1bcc932e0cea102:T=1743089753:RT=1759306972:S=ALNI_Maq7Goim-vglWowerW9VQtuRFTxFQ',
'__gpi': 'UID=000010777f845d20:T=1743089753:RT=1759306972:S=ALNI_MYGA1k5g2Um-bzV5ze_PtqIAxxoRw',
'__eoi': 'ID=2fe3a211e78d8aa6:T=1758939004:RT=1759306972:S=AA-AfjYgyZ9bublbtzibs9GPTd-N',
'ERIGHTS': 'SwxxH7T1v1VLEAI8R4bnCHIx2BwxxgEgU1rz*ZIA8XpjgY5xxJbPkPVnix2FIwx3Dx3D-18x2dx2FIQ1dGZOuPf5LthtmT9LBAx3Dx3DmCrkU2DAUWcdsgAgO3iUKQx3Dx3D-Bx2B6Gx2BH9dz1lKd1m1Cx2BWTLQx3Dx3D-PHj1uIXuNf5L22d8rb2R2wx3Dx3D',
'TS016349ac': '01f15fc87caa2dc02198adb0ce4b0266f3a204a16cb3f127709c965ef7d8645a14425e6c3269b103978c8aad0e57a8867f9994018b',
'JSESSIONID': '3DEE3EC74CD7A94589311B5A61301C25',
'ipList': 'xxx',
'AMCVS_8E929CC25A1FB2B30A495C97%40AdobeOrg': '1',
's_cc': 'true',
'xpluserinfo': 'eyJpc0luc3QiOiJ0cnVlIiwiaW5zdE5hbWUiOiJTaGFuZ2hhaSBEaWFuamkgVW5pdmVyc2l0eSIsInByb2R1Y3RzIjoiSUVMfFZERXxOT0tJQSBCRUxMIExBQlN8In0=',
'seqId': '2718872',
'AWSALBAPP-0': 'AAAAAAAAAAChiKqwTLLlKmwHzK8XgMWLFGFU/3fOX/c8Q+gHtKFrwvG3x0IBEu01gku0dMjtqWK+t7H73euwu83WjgMbz57/UsyV1KcgkDBHhAmNskx1lSHC35aWFs1rO4pqhthSdKZsGkxliKtuTbT2ilJjitCP8vTj5ltDylgvvjM+2OjMhtn+VI32DLxfnGB3bt1y5gQzY7pi4djdjw==',
'TSaf720a17029': '0807dc117eab28009279e9fedff710b6acd9929b5f97695641615110f44f7dce794f0428f0e1bd2f58b5927219fb737d',
'TS8b476361027': '0807dc117eab20003f875172c6f02179ace833a997a76b3b0a25091832bfdf85fc1e1f71dfac913e08e881332f113000f94ac4d232d89a230928f392966fa395fac4429d646aeca30eecd3224b2259e812ad9dfea703093376941dfd958ffb9d',
'utag_main': 'v_id:01958dc3fd590014cf3c56427d900507d003007500a83$_sn:47$_se:2$_ss:0$_st:1759309432705$vapi_domain:ieeexplore.ieee.org$ses_id:1759307626973%3Bexp-session$_pn:2%3Bexp-session',
'AMCV_8E929CC25A1FB2B30A495C97%40AdobeOrg': '359503849%7CMCMID%7C48251904105148753130603440820575750408%7CMCIDTS%7C20363%7CMCAAMLH-1759912433%7C11%7CMCAAMB-1759912433%7Cj8Odv6LonN4r3an7LhD3WZrU1bUpAkFkkiY1ncBR96t2PTI%7CMCOPTOUT-1759314833s%7CNONE%7CMCSYNCSOP%7C411-20370%7CMCAID%7C344C5CA6432AFD07-4000095BC4125A23%7CvVersion%7C5.0.1',
}整个cookie中唯一有"价值"的只有这些
JSESSIONID,ERIGHTS,Xpluserinfo用来维护登录状态- TS8b476361027,TSaf720a17029,cf_clearance用来反爬虫
其他的cookie像__gads,__gpi,__eoi这些都是谷歌浏览器的广告与定位的API,AMCV是Adobe阅读器的cookie, utag_main是典型的营销与分析Cookie,主要用来统计用户访问次数等信息,在这里可能是为了统计论文下载次数,剩下的cookie绝大多数都是由服务器动态生成直接携带无任何意义。
当然,经过测试,发现,IP在IEEE数据库订阅机构的网段范围内,不携带此cookie也不会影响我们的正常访问这些链接,但是一旦你的ip不在校园网段时,此链接便会重定向至论文简介的界面,点击下载按钮会提示登录。
不在IP网段内被强制重定向
下载单篇论文
下载单篇论文的原理很简单,就是发送请求,将返回的二进制内容保存到pdf文件内,也就是:
python
import os
import re
import requests
import time
def download(folder:str,title:str,download_link:str):
headers={
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': f'{download_link}',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
}
title=re.sub(r'[\\/*?:""<>|]',' ',title)
dst=os.path.join(folder,f'{title}.pdf')
if not os.path.exists(dst):#论文pdf路径不存在,没下载过才发请求
arnumber=re.search(r'\d+',download_link).group(0)
params={
'tp': '',
'arnumber': f'{arnumber}',
'ref': '',
}
response=requests.get('https://ieeexplore.ieee.org/stampPDF/getPDF.jsp', params=params, headers=headers)
time.sleep(2)
with open(dst,'wb') as f:
f.write(response.content)完整代码
结合上篇文章中的代码,加入下载请求便可以实现关键字搜索论文下载
python
import re
import os
import time
import requests
from requests.adapters import HTTPAdapter
from concurrent.futures import ThreadPoolExecutor
class IEEE_Search():
def __init__(self,searchTerms:list[str],number:int,Year:str='2020_2026_Year',LogicWords:list[str]=[],searchRanges:list[str]=[]):
'''
Args:
searchTerms:所有待搜索的关键字列表
number:返回的url数量
searchRanges:每个关键字的搜索范围列表,有All MetaData,FullText,Abstract等
LogicWords:连接所有关键字的逻辑词构成的列表,AND,OR,NOT
Examples:
```
crawler=IEEE_Search(searchTerms=['sentiment','emotion'],number=200)
articleTitles,downloadLinks=crawler.fetch_downloadLinks()
```
'''
self.searchTerms=searchTerms
self.Year=Year
self.number=number
self.LogicWords=LogicWords
self.searchRanges=searchRanges
if len(self.searchTerms)==0:
raise ValueError(f'没有关键字,无法搜索!')
if not self.searchRanges:
self.searchRanges=['All Metadata']*len(self.searchTerms)
if not self.LogicWords:
self.LogicWords=['AND']*(len(self.searchTerms)-1)
self.session=self.setup_session()
self.queryText=self.get_queryText()
print(self.queryText)
self.downloadLinks=[]
self.articleTitles=[]
def setup_session(self):
session=requests.Session()
adapter=HTTPAdapter(
pool_connections=10,
pool_maxsize=35,
max_retries=3,
pool_block=False)
session.max_redirects=5
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
def get_queryText(self):
self.LogicWords.append('')
queryText=''
for searchTerm,searchRange,logicword in zip(self.searchTerms,self.searchRanges,self.LogicWords):
queryText+=f'("{searchRange}":{searchTerm}) {logicword} '
return queryText
def parse_json(self,response:requests.Response):
downloadLinks=[]
articleTitles=[]
json=response.json()
if response.status_code==200 and 'records' in json.keys():
for article in json['records']:
articleTitles.append(article['articleTitle'])
downloadLinks.append(rf'https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber={re.search(r'\d+',article['documentLink']).group(0)}')
return articleTitles,downloadLinks
def fetch_downloadLink(self,json_data):
headers={
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
'origin': 'https://ieeexplore.ieee.org',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://ieeexplore.ieee.org/Xplore/home.jsp',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
'x-security-request': 'required',
}
response=self.session.post('https://ieeexplore.ieee.org/rest/search',headers=headers, json=json_data)
articleTitles,downloadLinks=self.parse_json(response)
return articleTitles,downloadLinks
def fetch_downloadLinks(self):
headers={
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
'origin': 'https://ieeexplore.ieee.org',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://ieeexplore.ieee.org/Xplore/home.jsp',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
'x-security-request': 'required',
}
payload={
'action': 'search',
'newsearch': True,
'matchBoolean': True,
'queryText': f'{self.queryText}',
'ranges': [
f'{self.Year}',
],
'highlight': True,
'returnFacets': [
'ALL',
],
'returnType': 'SEARCH',
'matchPubs': True,
}
response=self.session.post('https://ieeexplore.ieee.org/rest/search', headers=headers, json=payload)
articleTitles,downloadLinks=self.parse_json(response)
self.downloadLinks.extend(downloadLinks)
self.articleTitles.extend(articleTitles)
pages=self.number//25+1
for i in range(2,pages+1):
payload['pageNumber']=str(i)
response=self.session.post('https://ieeexplore.ieee.org/rest/search', headers=headers, json=payload)
articleTitles,downloadLinks=self.parse_json(response)
self.downloadLinks.extend(downloadLinks)
self.articleTitles.extend(articleTitles)
self.articleTitles=self.articleTitles[:self.number]
self.downloadLinks=self.downloadLinks[:self.number]
return self.articleTitles,self.downloadLinks
def download(folder:str,title:str,download_link:str):
headers={
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': f'{download_link}',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
}
title=re.sub(r'[\\/*?:""<>|]',' ',title)
dst=os.path.join(folder,f'{title}.pdf')
if not os.path.exists(dst):#论文pdf路径不存在,没下载过才发请求
arnumber=re.search(r'\d+',download_link).group(0)
params={
'tp': '',
'arnumber': f'{arnumber}',
'ref': '',
}
response=requests.get('https://ieeexplore.ieee.org/stampPDF/getPDF.jsp', params=params, headers=headers)
time.sleep(2)
with open(dst,'wb') as f:
f.write(response.content)
def auto_download(folder,titles,downloadLinks):
os.makedirs(folder,exist_ok=True)
folders=[folder]*len(titles)
args_list=list(zip(folders,titles,downloadLinks))
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(lambda args:download(*args),args_list)
'''
IEEE_Search原理:发送Advanced Search的请求,在返回json中获取论文标题,和下载链接
参数:
searchTerms:搜索关键字列表
LogicWords:连接多个关键字的逻辑词列表,数量是关键字数量-1,LogicWords默认为['AND']*len-1)
searchRanges:每个关键字的搜索范围,有 All MetaData ,Full Text Only ,Abstract等与advanced Search中一致,默认全部为All MetaData
number:需要查询的论文数量
返回值:
articleTitles:论文标题
downloadLinks:下载链接
'''
folder=r"E:\Desktop\IEEE关键字论文下载"
articleNumber=67
crawler=IEEE_Search(searchTerms=['sentiment','emotion'],searchRanges=['Abstract','Full Text Only'],Year='2020_2026_Year',number=articleNumber)
articleTitles,downloadLinks=crawler.fetch_downloadLinks()
print(articleTitles)
print(downloadLinks)
print(len(articleTitles))
auto_download()运行效果:
总结:

以上便是本文所有内容,如果对你有用,还请一键三连支持一下博主😁