本文介绍了 GitHub 性能工程团队对 CPU 性能的评估,研究了 CPU 性能如何随着利用率的增加而下降,以及与容量的关系。原文:Breaking down CPU speed: How utilization impacts performance

简介 ⛵
GitHub 性能工程团队定期进行实验,观察系统在不同负载下的运行情况。这些实验中有一个明显模式,即 CPU 利用率对系统性能有着重大影响。我们发现,随着 CPU 利用率上升,会导致延迟增加,这为我们优化系统性能提供了机会。解决这一挑战使我们能够保持性能水平,减少对额外机器的需求,从而最终提升整体效能。
尽管我们已经认识到较高的 CPU 利用率与延迟增加之间存在关联,但仍看到进一步探究不同阶段具体阈值及其影响的可能。由于采用不同 CPU 系列的多种实例类型,我们着重研究了每种 CPU 模型的独特性能特征。这种更深入的了解使我们能够做出更明智、基于数据的决策,从而能够更高效、更有信心的配置基础设施。
怀着这些目标,我们开启了新的探索与试验之旅,以期探寻这些深刻见解。
实验设置 🧰
要为这类实验收集准确数据并非易事,需要从尽可能接近实际生产环境的工作负载中收集数据,同时还要记录系统在不同负载阶段的表现情况。由于不同工作负载的 CPU 使用模式各不相同,我们主要关注旗舰工作负载。然而,增加负载可能会引入细微的性能差异,因此我们的目标是尽量减少对用户的影响。
幸运的是,一年前,性能工程团队开发了能够满足这些要求的环境,代号为"大独角兽碰撞器"(LUC,Large Unicorn Collider)。该环境运行在 Kubernetes 集群的一小部分区域中,与旗舰工作负载具有相同架构和配置,还具备可灵活部署在专用机器上的特性,能够避免与其他工作负载产生干扰。通常,LUC 环境处于闲置状态,但在需要时,可以将少量可调节流量导向它。激活或停用这种流量仅需几秒钟,使我们能够迅速应对性能方面的问题。
为了准确评估 CPU 利用率的影响,我们首先向运行在在专用机器上的 LUC Kubernetes 服务容器发送部分生产流量来建立基准,从而为我们提供了用于比较的参考标准。重要的是,LUC 服务容器处理的请求数在整个实验过程中保持不变,从而确保随着时间推移,CPU 负载保持稳定。
一旦设定好基准值,就用 stress 工具逐步提高 CPU 利用率,该工具通过运行随机处理任务来人为占用指定数量的 CPU 核心。每个实例类型都有不同数量的 CPU 核心,因此我们相应调整了步骤。然而,所有实例的共同点是总 CPU 利用率。
注意:需要明确的是,这并非与实际生产工作负载进行直接的 1:1 对比。压力测试工具持续执行数学运算,而生产工作负载则包含 I/O 操作和中断,这些操作对系统资源有不同要求。然而,这种方法仍然能为我们提供有关 CPU 在负载情况下运行表现的宝贵见解。
在环境条件已准备就绪、计划也制定完毕后,我们便开始尽可能多的收集数据,以便对影响进行分析。
结果 📃
在实验设置确定之后,我们来分析所收集的数据。如前所述,在不同实例类型上重复这一过程。每个实例类型都表现出不同行为和不同的性能下降阈值。
正如预期那样,随着 CPU 利用率的上升,所有实例类型的 CPU 使用时间均有所增加。下面的图表展示了随着 CPU 利用率的提高,每个请求所消耗的 CPU 时间情况。
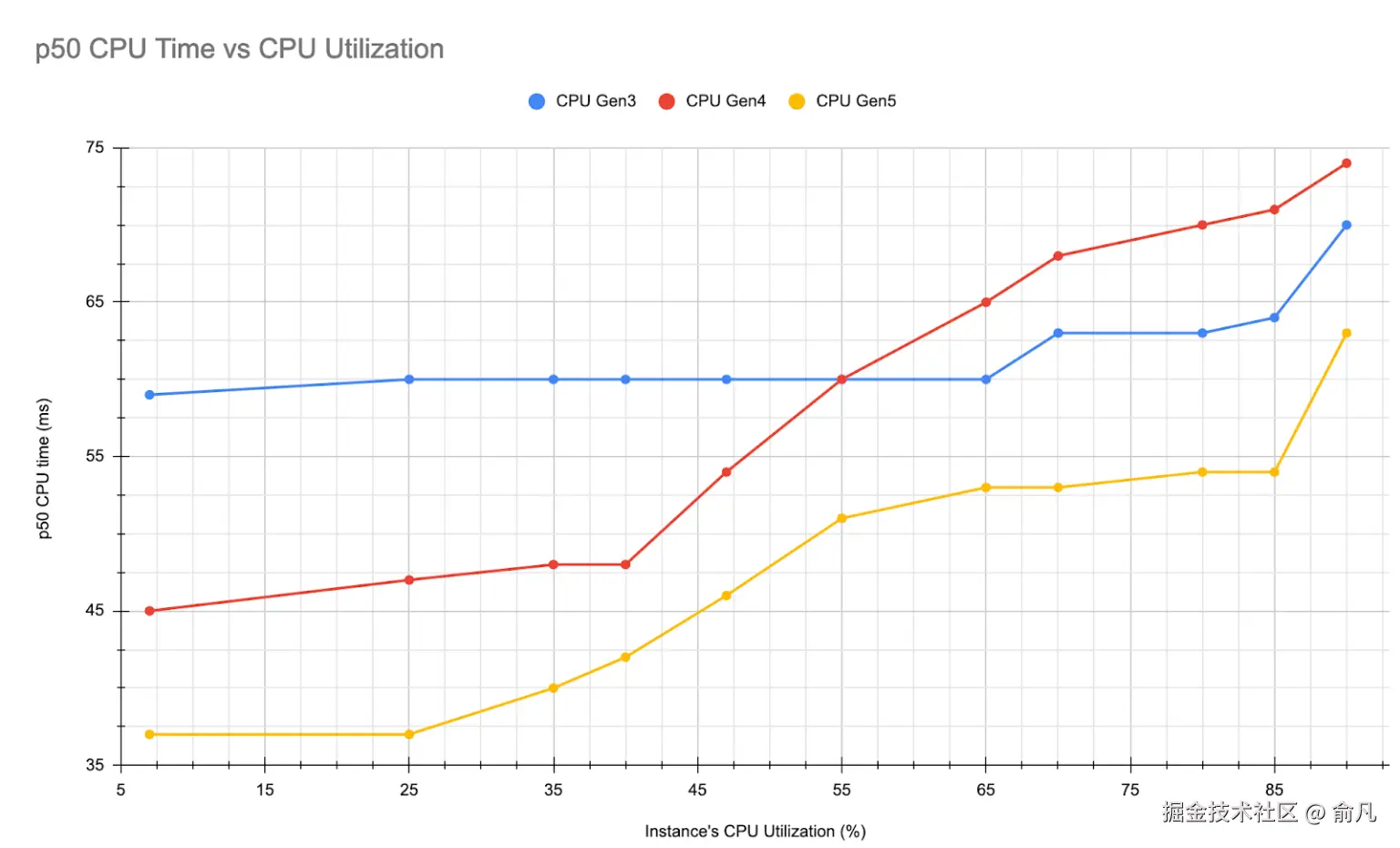
由于 CPU 模型不同,实例类型之间的延迟差异是意料之中的。关注延迟增加的百分比可能会提供更有意义的见解。
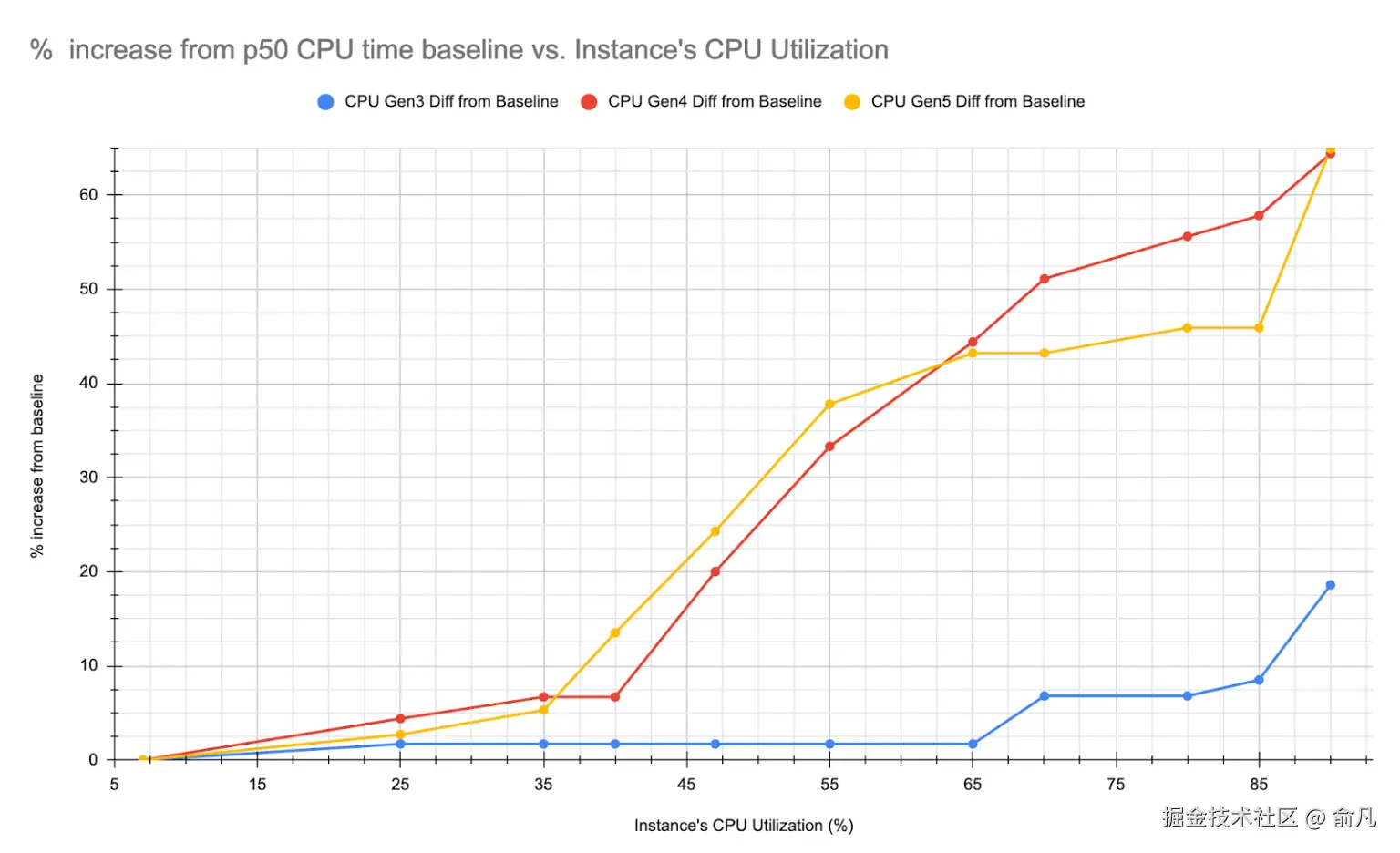
在两幅图表中,有一条线与其他线的偏差较大,显得格外突出。我们稍后将详细探讨这一情况。
Turbo Boost 效果
一个有趣的观察是,随着 CPU 使用率的增加,其频率会发生怎样的变化,这可以归因于 Intel 的 Turbo Boost 技术。由于所有实例都配备了 Intel CPU,因此 Turbo Boost 的效果在所有设备上都十分明显。下图中可以看到 CPU 频率随着 CPU 使用率的增加而降低的情况。红色箭头表示 CPU 的使用率水平。
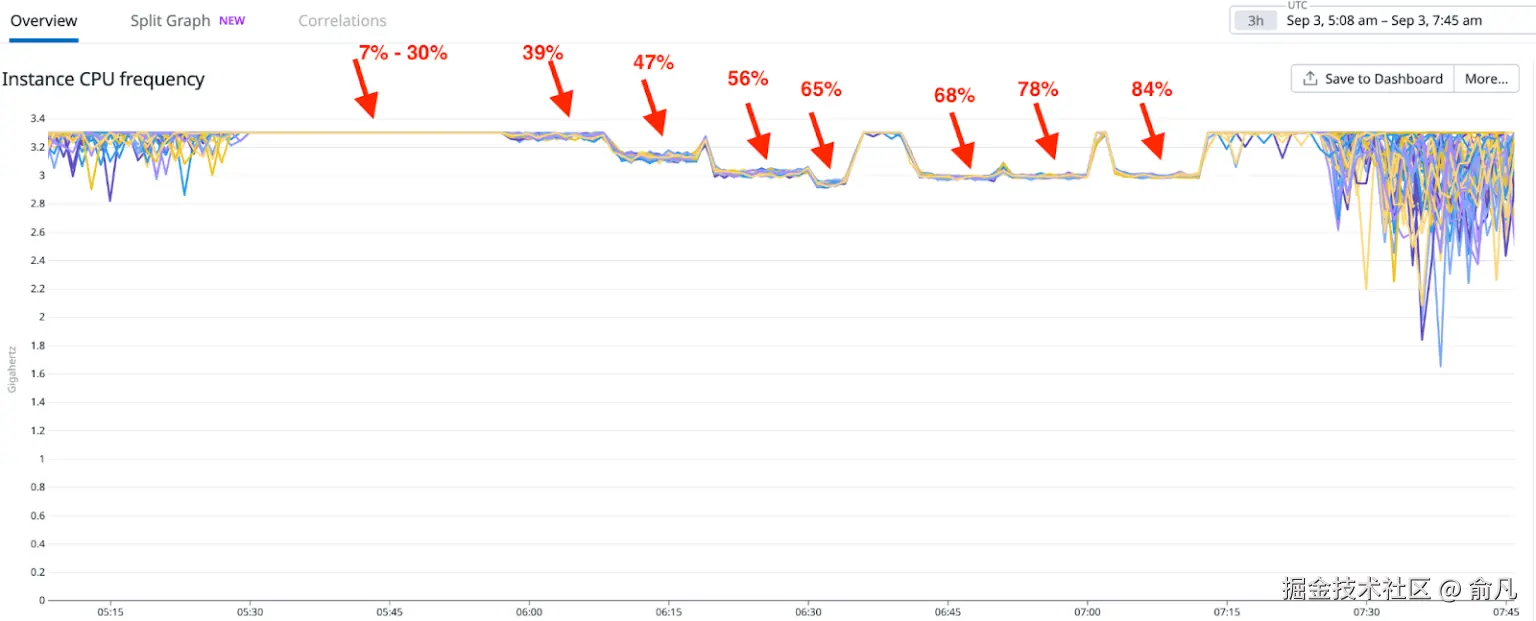
当 CPU 利用率保持在较低水平(约 30% 或更低)时,能够受益于更高的核心频率,从而加快 CPU 运行速度,进而降低整体延迟。然而,随着对更多 CPU 核心的需求增加以及利用率上升,很可能会达到 CPU 的散热和功率限制,导致频率降低。简而言之,较低的 CPU 利用率会带来更好的性能,而较高的利用率则会导致性能下降。例如,在特定节点上以约 30% 的 CPU 利用率运行的工作负载,其响应时间会比在相同虚拟机中 CPU 利用率超过 50% 时要快。
超线程技术
CPU 频率的变化并非是影响性能变化的唯一因素。我们所有节点都启用了超线程技术,这是一种 Intel 公司开发的技术,能让一个物理 CPU 核心以两个虚拟核心的形式运行。尽管实际上只有一个物理核心,但 Linux 内核会将其识别为两个虚拟 CPU 核心。内核会尝试将 CPU 负载分配在这两个核心之间,旨在让每个物理核心只有一条硬件线程(虚拟核心)处于忙碌状态。这种做法在达到一定 CPU 利用率之前是有效的。超过这个阈值后,我们无法充分利用这两个虚拟 CPU 核心,从而导致性能低于正常运行状态。
找到 CPU 利用率的"黄金比例"
未充分利用的节点会导致数据中心的资源、电力和空间被浪费,而过度利用的节点也会造成效率低下。如上所述,更高的 CPU 利用率会导致性能下降,这可能会让人误以为需要更多资源,从而形成过度配置的循环。对于不遵循异步模式的阻塞型工作负载来说,这个问题尤为突出。随着 CPU 性能下降,每个进程每秒能够处理的任务数量会减少,从而使现有容量变得不足。为了达到最佳平衡(即 CPU 利用率的"黄金比例"),必须确定一个阈值,即 CPU 利用率达到足够高以确保效率,但又不会显著影响性能。努力使节点接近这个阈值,将使我们能够更有效利用现有硬件以及现有软件。
由于已经有实验数据表明 CPU 时间随着利用率的提高而增加的情况,因此可以建立数学模型来确定这个阈值。首先需要确定对于特定使用场景,CPU 时间下降的百分比是可以接受的。这可能取决于用户期望或性能服务级别协议(SLA)。一旦确定了这个阈值,将帮助我们选择仍处于可接受范围内的 CPU 利用率水平。
我们可以绘制出 CPU 利用率与 CPU 运行时间(延迟)的关系图,并找出这个点:
- CPU 使用率已经足够高,足以避免资源闲置浪费。
- CPU 运行时间下降幅度未超过可接受的限度。
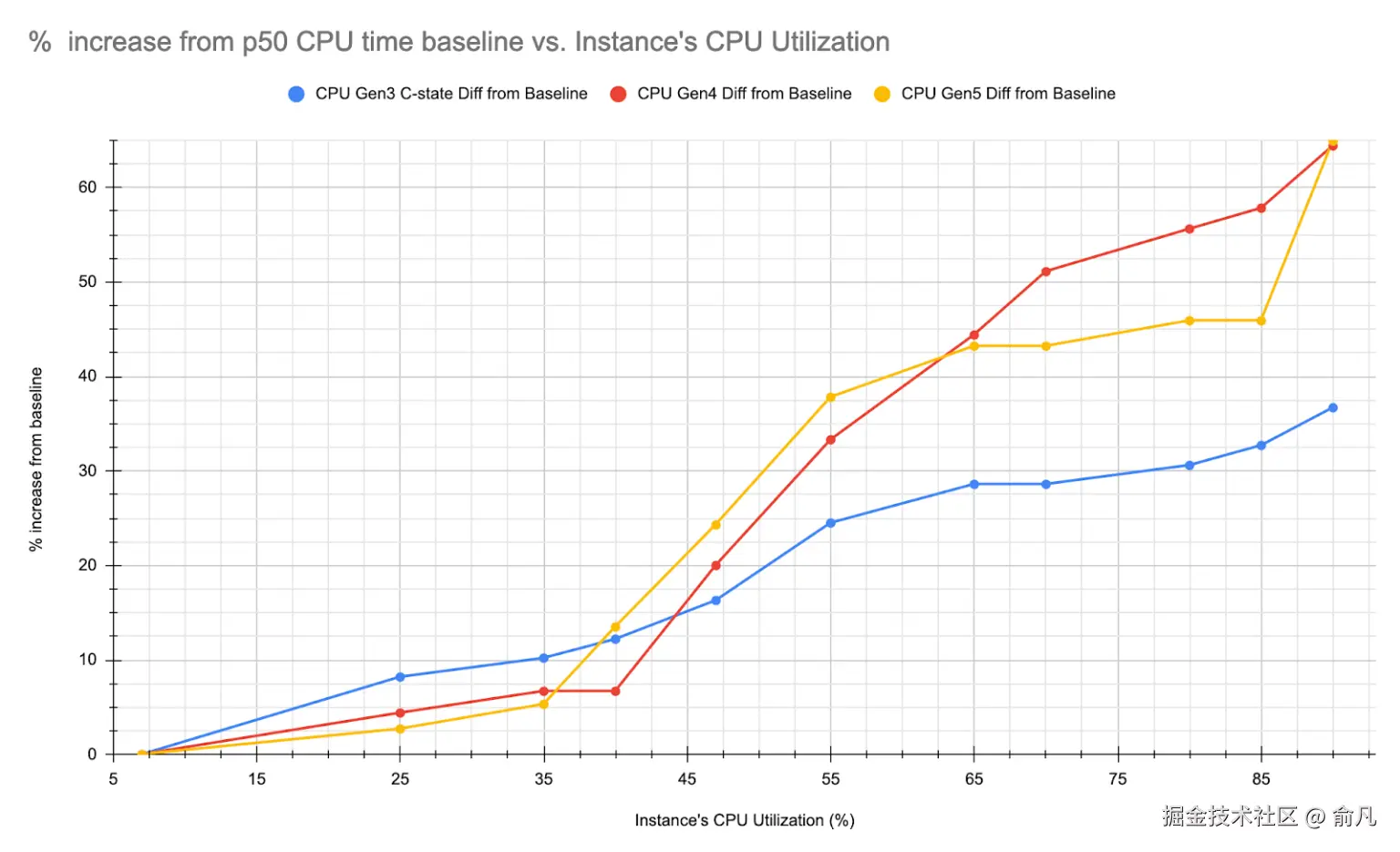
基于上述数据得出的具体例子可以在下图中得到展示。
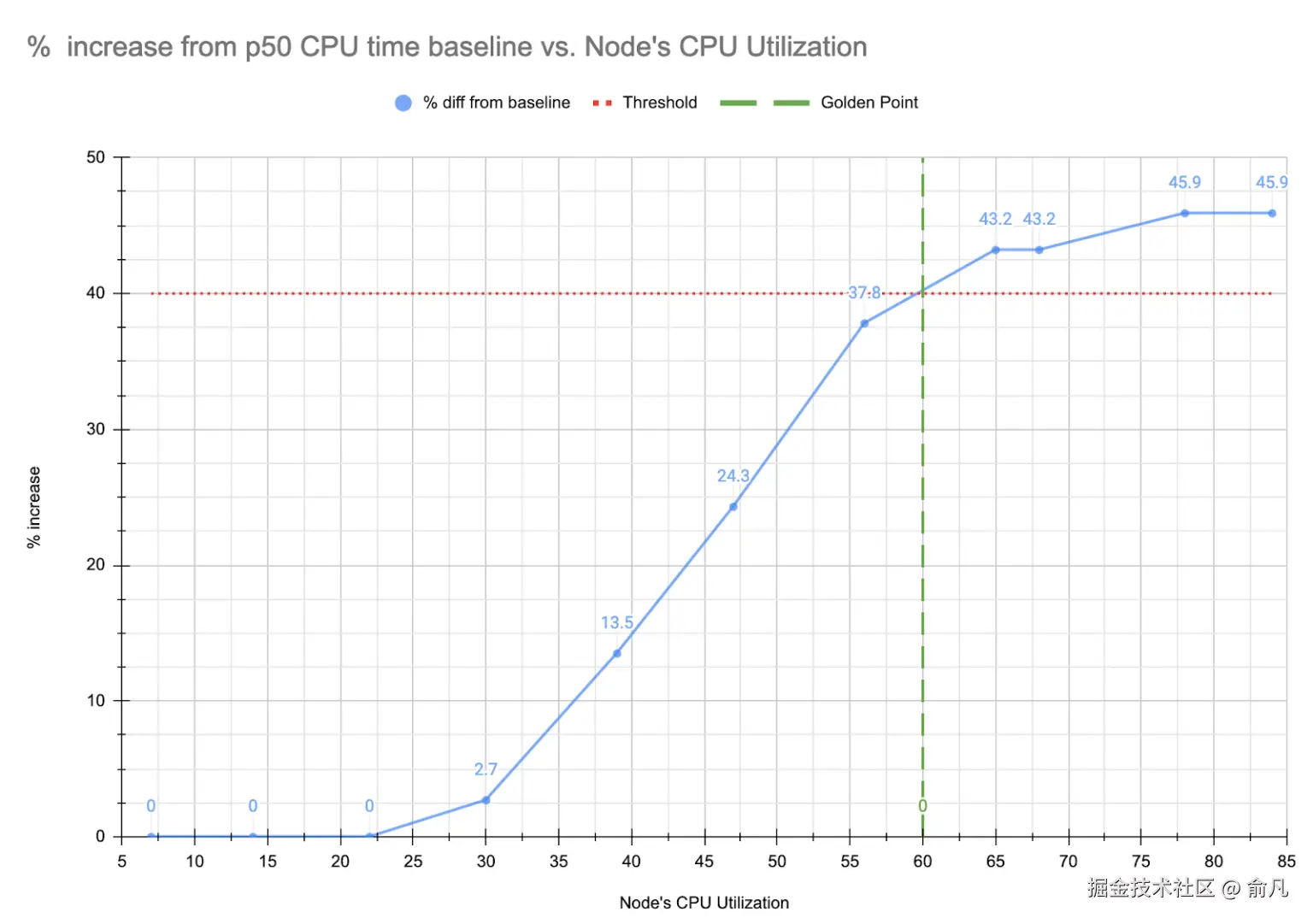
在这个例子中,目标是将 CPU 使用率的下降幅度控制在 40% 以下,这意味着在特定实例中,CPU 利用率应保持在 61% 以上。
异常情况
如前所述,曾出现过一个特定案例,其中包含了部分异常数据点。实验证实了一个已被确认的问题,即某些实例未能达到其宣称的最高 Turbo Boost CPU 频率。相反,我们观察到的 CPU 频率在 CPU 利用率较低时一直低于其宣称的最大值。以下示例中,可以看到一个宣称 Turbo Boost 频率高于 3GHz 的 CPU 系列实例,但它报告的最大 CPU 频率却仅为 2.8GHz。
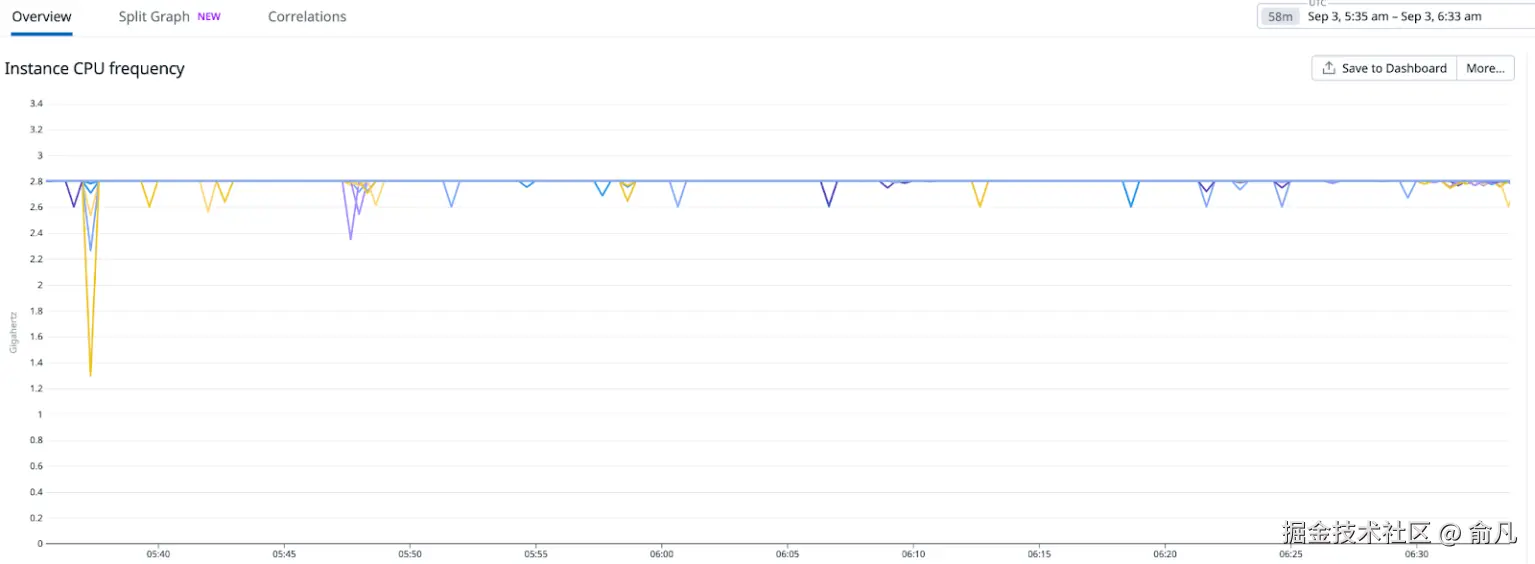
问题是由于 CPU 的 C-state 被禁用所致,使得 CPU 核心即使在未使用的情况下也无法停止运行。因此,这些核心在超频驱动程序看来是"忙碌"状态,从而限制了利用更高 CPU 频率带来的 Turbo Boost 功能的能力。通过启用 C-state,并在空闲模式下进行优化和节能处理,我们观察到了预期的超频行为。这一改变对测试工作负载所消耗的 CPU 时间产生了立竿见影的影响。下图展示了在调整 C-state 后报告的 CPU 频率和延迟的显著变化。
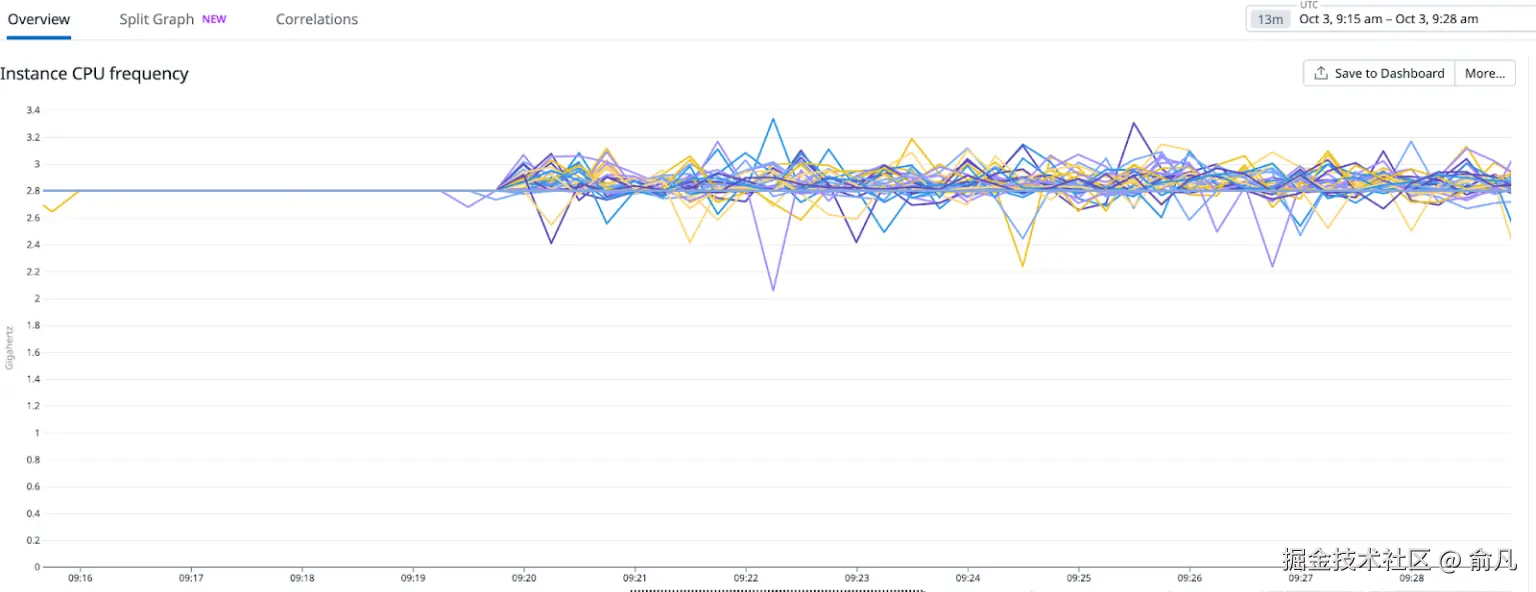
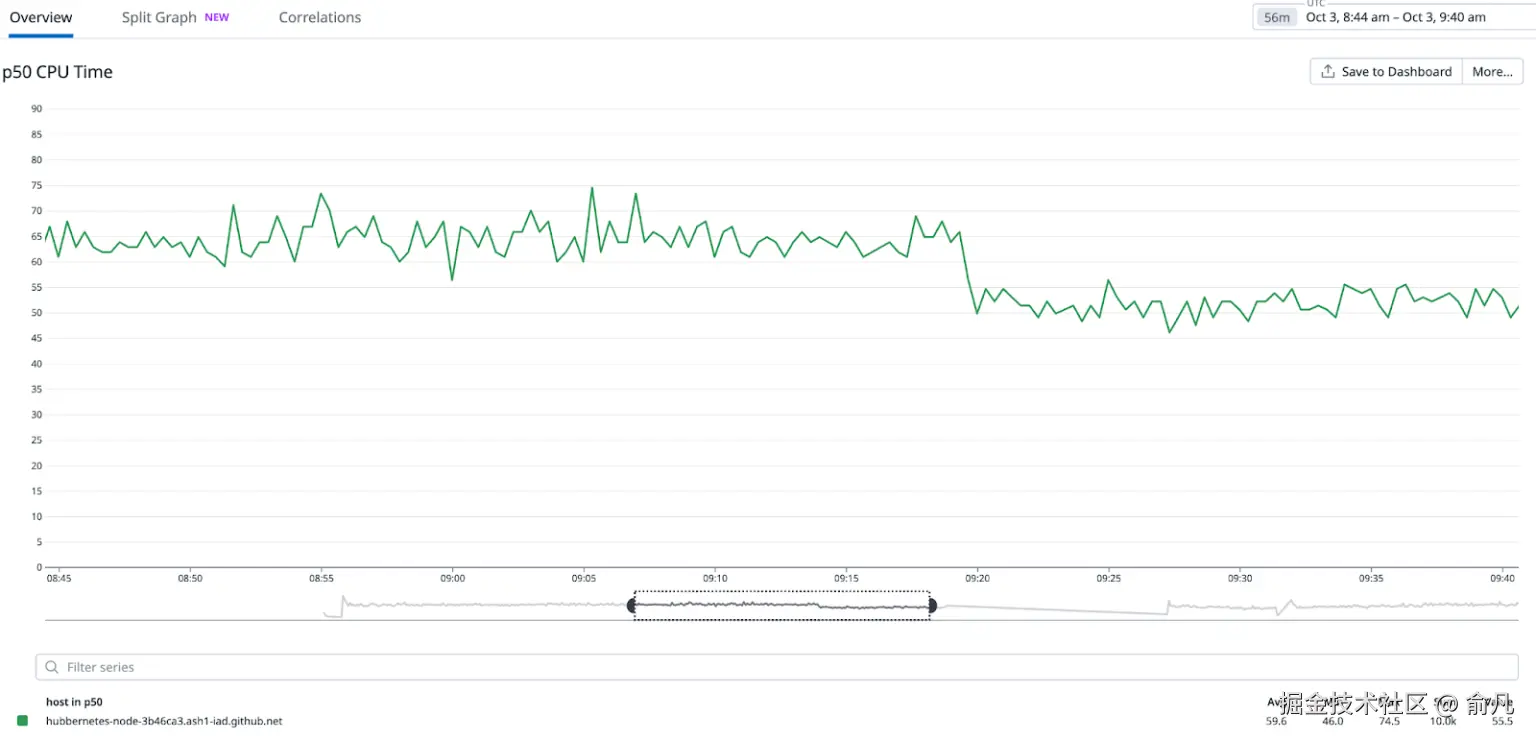
在重新评估 CPU 时间的百分比变化后,观察到所有实例都有类似的行为。
总结
正如预期的那样,我们希望通过利用复杂系统的数据来验证我们的理论。虽然我们证实了在不同 CPU 系列中,随着 CPU 利用率的增加,性能会下降,但通过确定最佳 CPU 利用率阈值,能够更好的在性能和效率之间取得平衡,确保基础设施既经济高效又性能卓越。未来,这些见解将为我们提供有关资源配置策略的信息,并帮助我们最大限度发挥硬件投资的效果。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!