今天咱们要聊一个话题------推理模型和大语言模型的区别。
你们可能听过很多关于 GPT-4 和 DeepSeek V 系列 的讨论,它们作为大语言模型,在 AI 领域占据了非常重要的位置。
那么,什么是推理模型,它和这些大语言模型又有什么不同呢?今天咱们就一起来深入了解一下。
什么是推理模型?
我们来看看什么是推理模型。推理模型的核心在于 多步骤推理,它不仅仅是接收输入并给出答案,而是在输入的基础上,模拟人类的思维过程,进行一系列的逻辑推理。
推理模型的优势是,它能理解复杂任务中的各个层次,逐步推导出合理的结论。
举个例子,推理模型常见的应用包括 数学证明、复杂的逻辑推理、以及 法律文书解读。
这类任务往往不止依赖于简单的数据关联,而需要通过深入分析多种条件,逐步得出结论。
GPT-4 和 DeepSeek V 系列
接下来,咱们说说 GPT-4 和 DeepSeek V 系列 这些大语言模型。像 GPT-4,这类模型是基于 Transformer 架构的大型深度学习模型,专注于自然语言理解和生成。
它们通过对大规模文本数据的预训练,学会了大量的语言模式和语义关系,能够应对多种任务,比如对话生成、文章撰写、语言翻译等。
但是,GPT-4 和 DeepSeek V 系列(比如 V3 和 VL2)并不完全是推理模型。虽然它们能够进行某种程度的推理,但并不是通过多步骤推理的过程,而是依赖于它们在训练数据中学到的模式进行预测和生成。也就是说,它们更像是"通过记忆"进行任务,而不是像推理模型那样,经过逐步分析和推导得出结论。
推理模型与大语言模型的区别:
推理模型强调 CoT、自我批判、RLHF,通用模型强调参数规模、预训练语料、长上下文,这是行业共识。
为了让大家更清楚地理解这两者的区别,我们用直观图来对比一下

拓展: GPT-4o 有一定推理能力,但它不是专项推理模型,没有像 o1 那样内置 CoT 推理链或强化学习推理路径优化。
思维方式的不同
推理模型:推理模型的思维过程是逐步展开的。它根据给定的任务,从多个角度逐一分析信息,依靠推理规则和逻辑步骤推导出结果。例如,推理模型在处理复杂数学问题时,会一步一步验证每一个假设,直到得出最终结论。
大语言模型:大语言模型更多依赖于从海量数据中学习到的统计规律和上下文关联。当你给 GPT-4 一个问题时,它会基于已经学习到的知识生成答案,但它并不是通过逐步推导过程得出的,而是依赖于数据中已经学到的关联规则。
处理复杂任务的能力
推理模型:推理模型的优势在于能够理解并处理复杂的、需要多步骤分析的任务。比如,数学证明、复杂的法律文件分析、深层次的逻辑推理,推理模型能够展示其强大的推理能力。
大语言模型:大语言模型(例如 GPT-4)的优势则体现在其语言生成能力和广泛的应用场景中。虽然它能够生成相关的答案,但在面对多步骤推理问题时,它往往只能做出合乎逻辑的推断,而不是深入推理的过程。
另外训练方式上也有差异
推理模型:推理模型通常在 自监督学习 或 强化学习 的基础上进行训练,强调逻辑链的学习和推理规则的优化。它们通过反复训练,不断提高推理过程的精确度。
大语言模型:大语言模型则通过对大规模语料库的 无监督学习 来训练,学习语言的模式和语法结构。在训练过程中,它们并不专注于推理过程,而是通过生成式任务预测下一个词或句子。
在实际使用中,推理模型的应用主要集中在 数学证明、复杂代码调试、智能决策支持系统等领域。这些任务通常需要模型具备深入的推理能力,逐步分析多个因素并做出决策。
而大语言模型更适合 自然语言生成、文本翻译、对话生成等场景。它们能够在短时间内处理大量的文本生成任务,并提供快速、流畅的语言输出。
选择哪个模型更合适?
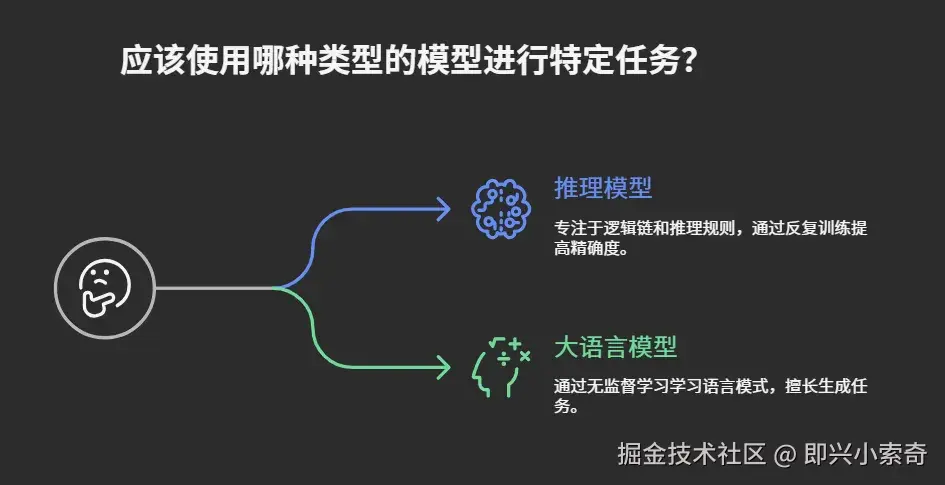
最后,大家可能想知道,面对这些模型,我们该如何选择呢?其实,选择模型的关键在于 你的任务需求:
如果你需要处理 多步骤推理 和 复杂分析,例如数学问题、深层次法律文件解读等,推理模型是最合适的选择。
如果你的任务涉及 自然语言生成 或 大规模数据处理,像 GPT-4 这样的 大语言模型 也不错的。