目录
1.命令行参数和环境变量
1.1命令行参数
我们在c语言中,main函数是有参数的。只是一般我们不怎么用罢了。
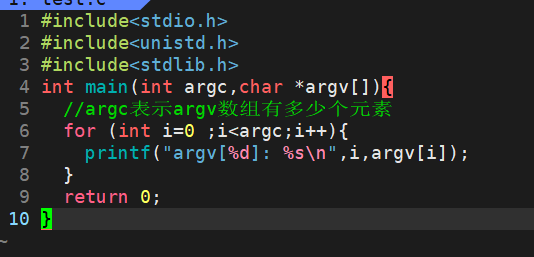
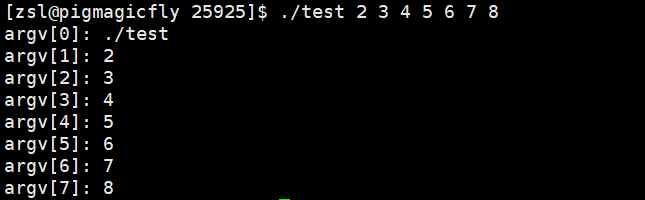
是bash输出的命令行字符串(printf),我们输入的
其实是被bash(scanf)以一个完整的"./test 2 3 4 5 6 7 8"的字符串接受并存到了一个char数组buffer里,然后再将这个字符串里的内容以空格作为分隔符,存入一个char*的数组中(最后一个元素之后存入null)。当bash执行程序的时候,会把数组中有效元素个数传入argc,数组传入argv。
因为最后是null即是0,所以条件里的i<argc可以直接是argvi
为什么要有这样的功能?依靠这个,我们可以为同一个程序设定不同的功能,通过传入不同的内容,(if条件)执行不同的功能。而这个跟我们平时在bash敲得指令,是一样的,大部分指令都是c/c++写的,自然也支持main函数的命令行参数。
比如ls -l,rm -rf等等,都是依托这个实现的。因此指令选项的本质,就是命令行参数,命令行参数是linux指令选项的基础。
大多数语言都支持命令行参数的功能,因为都有这方面的需求。
1.2环境变量概念
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
像是我们装python、git的时候是不是要配置path的系统环境变量。只有配置了变量,我们才能在cmd中执行命令得到正常反馈。
环境变量不是一个,而是一堆,彼此其实没有关系。环境变量一般是系统内置的具有特殊用途的变量。
定义变量的本质,是开辟空间。在程序运行期间也能开辟空间,而操作系统or bash都是用某个语言写的程序,自然也能在运行中开辟空间。
因此系统的环境变量,某种意义上,就是系统自己开辟空间,给他名字和内容即可。
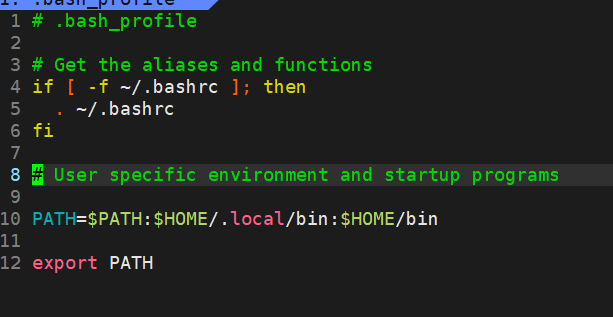
环境变量是os启动之后,从bash从磁盘中每个用户的家目录的.bash_profile中读取的,bash会开辟一块空间,维护跟当前用户相关的环境变量,以便bash可以识别当前用户。形象的理解,就是在公司里,每个人会有个工牌,以便其他人认识你。
可以看到,大部分的环境变量是从用户家目录的bashrc中获取的,当前实际上这个是套了几层的,bashrc里面还会显示从某个文件里获取,这里不多说。
可以看到PATH是这么读的,我们如果想手动添加一个,也可以仿照PATH的格式。
而且也可以把指令直接写入这里,每次登陆后都会自动执行
另外,这也是为什么用户登录后必须先处于家目录,因为bash要先从用户家目录读取环境变量。
1.3常见环境变量
1.3.1PATH
PATH:指定命令的搜索路径
我们应该有注意到,平时运行我们自己创建的可执行程序的时候,要带有路径,比如./name,../name等等。但我们执行linux自带的指令的时候却不需要,是为什么呢,就是因为bash会自动在path中的路径里面找可执行程序 ,比如上面用:分开的一个个路径,在这个路径里面的可执行程序,我们是可以在任何地方直接可执行程序名字的方式来运行该可执行程序。注意,which这个命令就是根据path进行搜索的
那么如何让我们自己的程序也可以直接运行呢?
第一个方法就是把我们的可执行程序放到path的某一个路径之中即可,这种行为可以理解为安装一个程序。但不推荐这样做,因为我们一般写的程序都不是很好,放入其中可能会污染系统默认的命令池。
第二个方法,那就是增加path的路径。
不小心覆盖了路径,比如PATH=/231 ,只要重新启动系统重新登录即可。

1.3.2PWD
为什么pwd的指令可以输出我们的当前路径呢,原因就是系统有一个PWD的环境变量,会时时刻刻随着我们当前路径的更新而更新,pwd就是把PWD里的内容显示出来而已,我们echo $PWD跟直接pwd是一样的内容。
1.3.3USER
存储我们登录系统的用户名。
1.3.4HOME
HOME:指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
因为这个和USER,我们用不同用户登录后,才会进入不同的家目录。
cd ~也是依靠这个。
1.3.5SHELL
SHELL:当前Shell,它的值通常是/bin/bash。
1.4查看环境变量
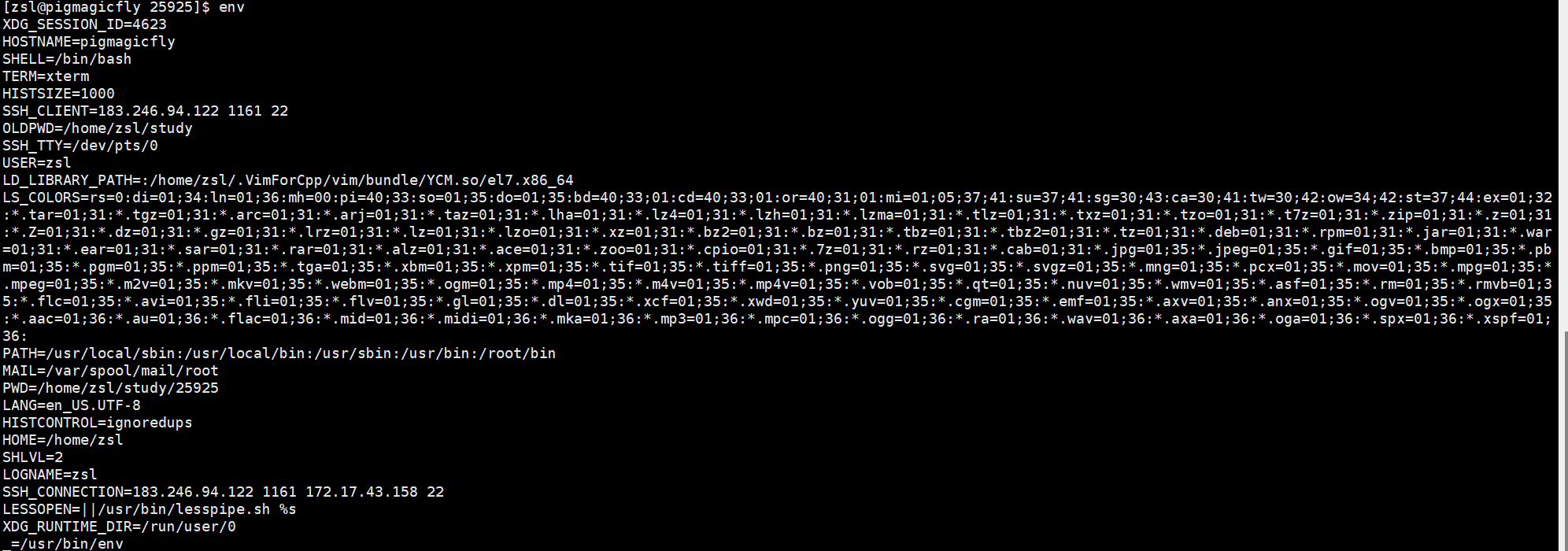
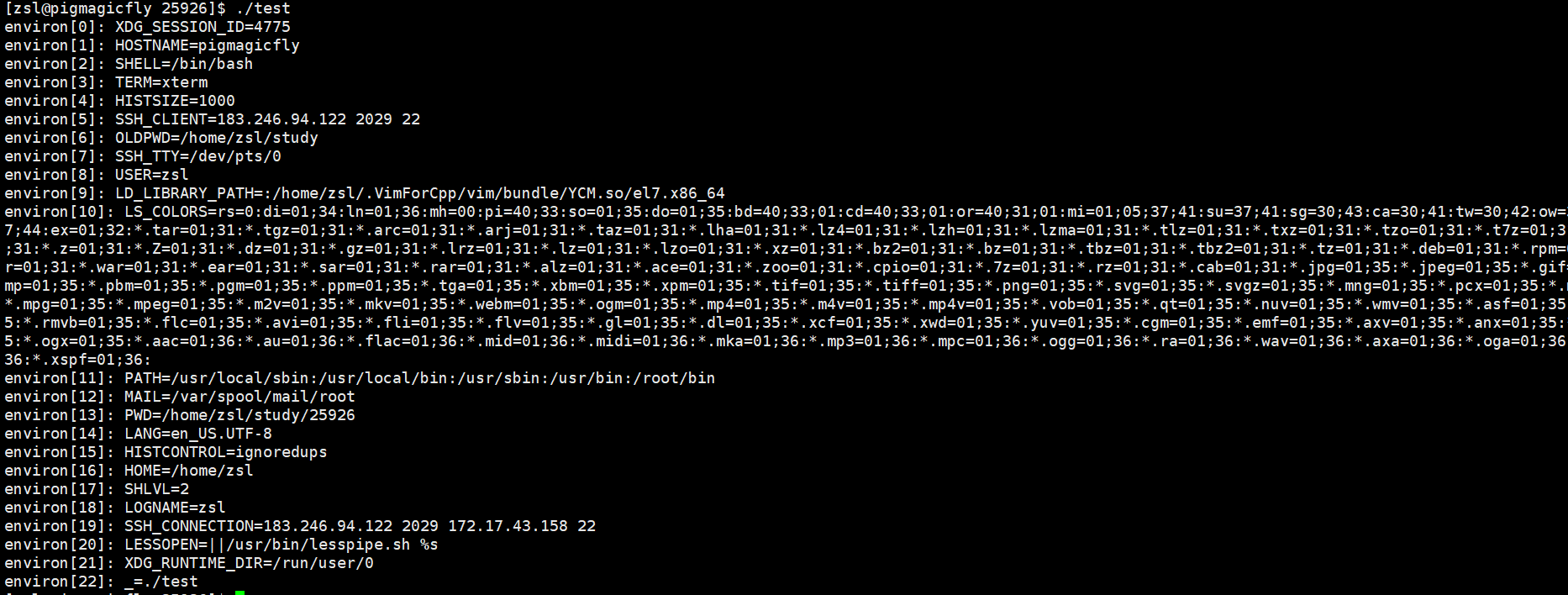
env可以查看所有的环境变量。
像是主机名、终端类型trem,历史指令保存条数HISTSIZE,客户端ip SSH_CLIENT,当前用的终端文件是哪个SSH_TTY,用户名,编码是什么LANG,登录名LONGNAME,
格式:echo $环境变量名称
1.5环境变量相关命令
echo:显示某个环境变量值
export:设置一个新的环境变量
export name=value
本质是将变量导入了bash的环境变量表中。
env:显示所有环境变量
unset:清除环境变量
unset name
set:显示本地定义的shell变量和环境变量
1.6环境变量组织形式及获取环境变量的方法及基本特征。
其实,我们的程序在运行的时候也是会收到环境变量的,比如c/c++的main函数
void main(int argc,char* argv\[\],char * env\[\])
而env,是一个指针数组,里面的每一个元素,都是指向了一个字符串(一个环境变量,比如'HOME=/home/zsl\0'),数组以NULL即结尾
因此,我们也可以在程序中打印出相应的环境变量。
我们的程序运行时,main函数是要接受参数,由bash(可执行程序的父进程,不一定是bash,但基本都是)传参,bash也是个程序,它内部会开辟一块空间,以cahr*\[\]结构的形式存储当前用户的环境变量,传参的时候,会直接把这个数组的首地址传过去。
我们所谓的export设置新的环境变量,对于bash而言,就是这个数组多了一个元素罢了
因此bash会维护两张表,一个是命令行参数,一个是环境变量。
同样的,我们发现,环境变量是可以被子进程继承的 !不仅是bash和其子进程。如果我们用fork也开了个子进程,也是会继承下去的,因为父子进程代码共享,数据以写时拷贝的方式各自私有一份。这也叫做环境变量的全局属性 ,即环境变量会被所有的子进程包括孙子进程进行继承!。而且就算某个子进程修改了也无妨,依靠写时拷贝不会影响父进程。依靠这个特性,也可以实现用环境变量来在父子进程间传递信息。
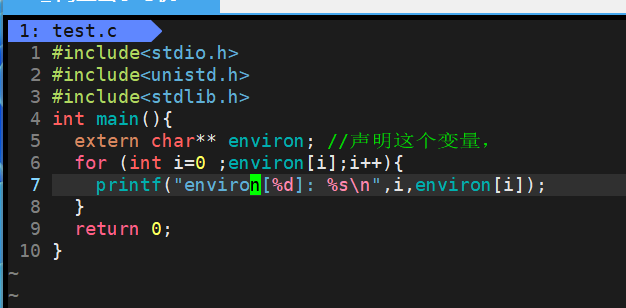
在c语言中,我们还可以用getenv来获取某个环境变量,char* getenv(const char*name)另外,在程序中,我们通过if条件判断当前用户(依靠环境变量)的形式,来手动防止其他人执行程序(除了root之外,没人可以冒充你)这个是最常用的
cpp#include <stdio.h> #include <stdlib.h> int main() { printf("%s\n", getenv("PATH")); return 0; }还有个putenv,后面会说。
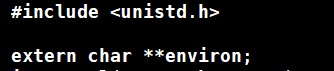
这个是c语言提供的一个变量,可以获取环境变量这张表。
这个变量其实是存在于libc中,没有包含在任何头文件中,所以使用的时候要声明
1.7本地变量
事实上,除了环境变量,还有个本地变量。
这样就可以定义一个本地变量,并且用echo $Magic就可以打印内容。
但是,我们用env是看不到本地变量的。
set:显示本地定义的shell变量和环境变量
即,本地变量只在bash内部有效(echo是可以输出的),不能被子进程继承,不是环境变量。

2.程序地址空间
下面的内容基于32位平台、linux内核2.6
图片源于网络。
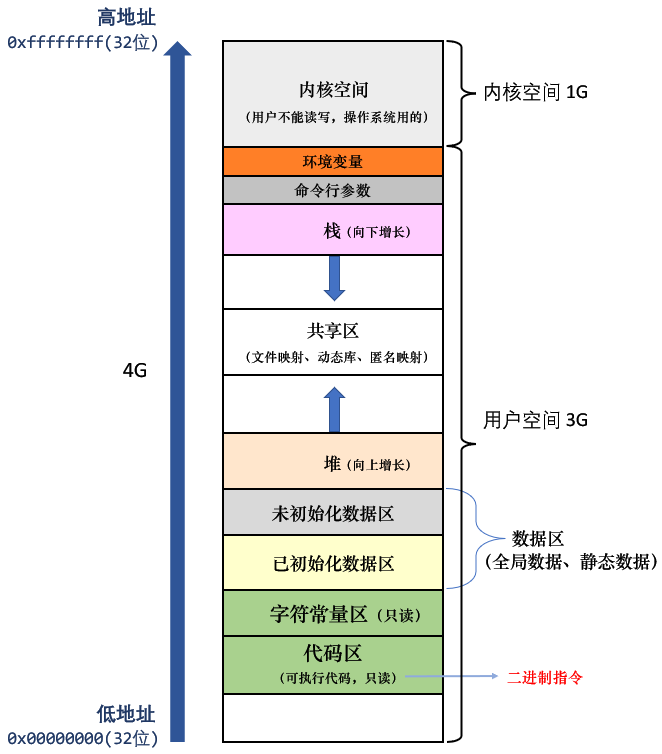
注意,命令行参数的表,环境变量的表,以及表元素指向的字符串,都是栈上部
我们c/c++的static变量,其实就是存在数据区里面,所以不会随着函数调用的结束被释放。
数据区里的内容,在进程运行的期间一直存在。
这个是进程地址空间,具体看后面。
因为是结论,我这里不多赘述,只是放一个简单的验证代码(由网上查询所得)另外,windows环境下地址每次可能都会非常随机(基于安全策略,将地址随机化),不会遵循上面的规则,linux下是遵循的(也有安全策略,做法跟windows不一样)。
cpp#include <stdio.h> #include <unistd.h> #include <stdlib.h> int g_unval; int g_val = 100; int main(int argc, char *argv[], char *env[]) { const char *str = "helloworld"; printf("code addr: %p\n", main); printf("init global addr: %p\n", &g_val); printf("uninit global addr: %p\n", &g_unval); static int test = 10; char *heap_mem = (char*)malloc(10); char *heap_mem1 = (char*)malloc(10); char *heap_mem2 = (char*)malloc(10); char *heap_mem3 = (char*)malloc(10); printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1) printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1) printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1) printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1) printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1) printf("read only string addr: %p\n", str); for(int i = 0 ;i < argc; i++) { printf("argv[%d]: %p\n", i, argv[i]); } for(int i = 0; env[i]; i++) { printf("env[%d]: %p\n", i, env[i]); } return 0; } ------------------------------下面是一次结果 $ ./a.out code addr: 0x40055d init global addr: 0x601034 uninit global addr: 0x601040 heap addr: 0x1791010 heap addr: 0x1791030 heap addr: 0x1791050 heap addr: 0x1791070 test static addr: 0x601038 stack addr: 0x7ffd0f9a4368 stack addr: 0x7ffd0f9a4360 stack addr: 0x7ffd0f9a4358 stack addr: 0x7ffd0f9a4350 read only string addr: 0x400800 argv[0]: 0x7ffd0f9a4811 env[0]: 0x7ffd0f9a4819 env[1]: 0x7ffd0f9a482e env[2]: 0x7ffd0f9a4845 env[3]: 0x7ffd0f9a4850 env[4]: 0x7ffd0f9a4860 env[5]: 0x7ffd0f9a486e env[6]: 0x7ffd0f9a4892 env[7]: 0x7ffd0f9a48a5 env[8]: 0x7ffd0f9a48ae env[9]: 0x7ffd0f9a48f1 env[10]: 0x7ffd0f9a4e8d env[11]: 0x7ffd0f9a4ea6 env[12]: 0x7ffd0f9a4f00 env[13]: 0x7ffd0f9a4f13 env[14]: 0x7ffd0f9a4f24 env[15]: 0x7ffd0f9a4f3b env[16]: 0x7ffd0f9a4f43 env[17]: 0x7ffd0f9a4f52 env[18]: 0x7ffd0f9a4f5e env[19]: 0x7ffd0f9a4f93 env[20]: 0x7ffd0f9a4fb6 env[21]: 0x7ffd0f9a4fd5 env[22]: 0x7ffd0f9a4fdf
2.1虚拟地址
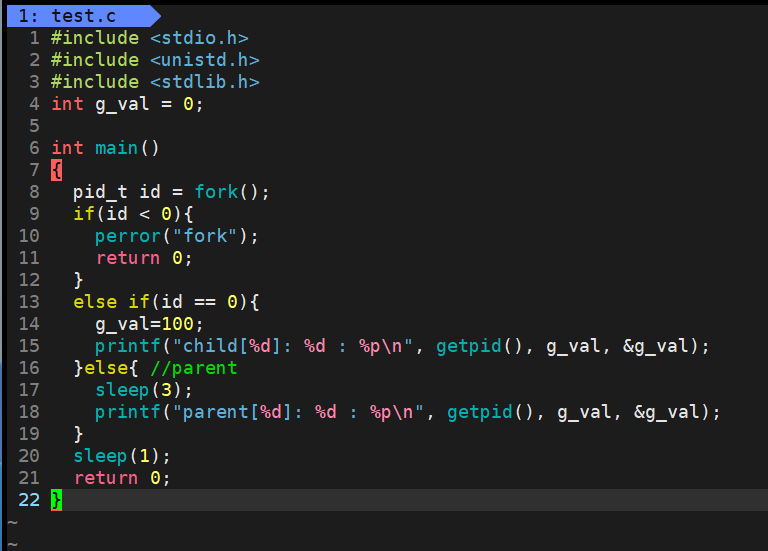
可以发现,父进程和子进程,在发生写时拷贝后,确实会各自存有一份变量,但是问题在于,变量的地址却都是一样的。
变量内容不一样,所以父子进程输出的变量绝对不是同一个变量 ,但地址值是一样的 ,说明,该地址绝对不是物理地址!
在Linux地址下,这种地址叫做虚拟地址/线性地址 ,我们在用C/C++语言所看到的地址,全部都是虚拟地址! 物理地址,用户一概看不到,由OS统一管理
OS必须负责将虚拟地址 转化成 物理地址。

2.2进程地址空间
图片源于网络,再二次加工。
通过页表,将进程地址空间与物理地址空间映射起来。
子进程会继承父进程的很多内容,其中就包括了页表、进程地址空间(如图中的地址空间,继承就意味着相同的虚拟地址),pcb大部分属性,所以父子进程访问变量地址的时候是一样的,在没发生写时拷贝的时候,访问的物理地址也是一样的。这也是为什么父子进程能够代码共享。
当发生了写时拷贝,会把指向的变量内容复制一份,在物理内存上再开辟一块空间,存相同的值,并且把子进程的页表中变量虚拟地址指向的物理地址修改成这块空间的地址,最后再完成写入。
这也是为什么用一个变量接受fork的返回值,之后可以做到访问同一个变量却获取到了不同的数据。
2.2.1概念
每一个进程,都会存在一个进程地址空间 ,32位平台下,空间范围是0,4GB
操作系统为每个进程,理论上都是划了4gb的进程地址空间给其使用。但事实上,这4gb空间是所有进程一起用的,之所以不会出问题,是因为每个进程不会一下子用那么多空间,而且一旦空间不够用,os也可以选择拒绝,等空间有余地了再给进程,再加上进程的创建结束,即空间的使用上也是有借有还。
形象的理解,那就是银行存款,在我们看来,我们把钱存入了银行,那钱就老老实实的待着银行(并且理论上有多少钱就可以存多少钱,有多少钱就可以取多少钱),但实际上,银行肯定是拿这些钱做别的事情。更形象点其实就是画大饼,每个人都深信这个大饼,且所有人被画的大饼是同一个。
同样的为了让每个进程都深信自己有4gb,且让进程运行顺利,os肯定要对进程地址空间做管理,而如果要管理,遵循先描述,再组织。因此,进程地址空间是数据结构,具体到某个进程,就是特定数据结构的对象。
os会为每个进程创建一个进程地址空间,这些进程地址空间都是某个数据结构对象,这些对象通过链表等等结构链接起来,os只要管理这些结构即可。同样的,每个进程的pcb肯定都会有一个指针指向相对应的进程地址空间。(可以理解为,银行为每个人开的户头)
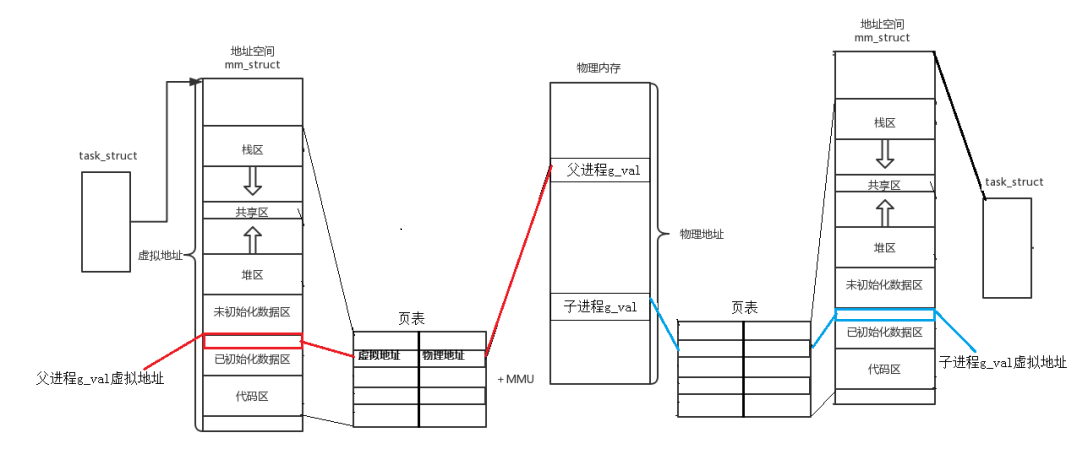
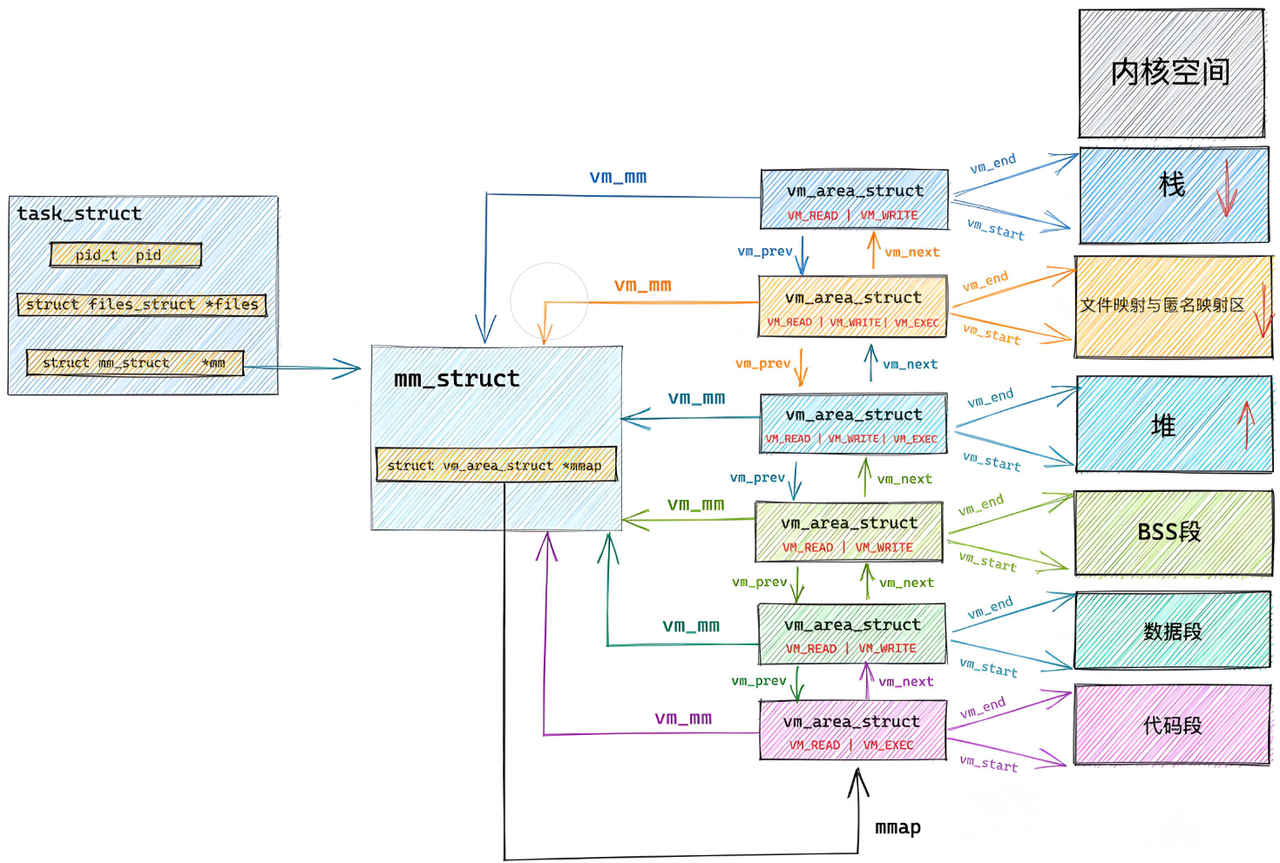
前面说过,进程地址空间,有不同的区域。进程task_struct结构体中有mm_struct这个结构体类型的指针。进程地址空间mm_struct中会存着些各个区域的边界(虚拟地址值)以及其他信息(比如指向页表的虚拟地址pgd)其中边界信息比如start_code,end_code,start_data,end_data等等。依靠这个,可以做到判断是否越界,可以扩大或者缩小区域范围。
注意,进程地址空间,不存储代码和数据,代码和数据实际是存放在物理内存中的。为了能够将虚拟地址和物理地址映射起来,依靠的就是页表。
而转化的过程,是cpu读取到某个虚拟地址,之后在CR3寄存器(存储页表的物理地址 )中找到对应的物理地址,获取到数据。稍微笼统点,是cpu的硬件单元MMU(管理 内存 单元)负责转换。
以下图片和代码来自网络!进程的地址空间的分布情况:
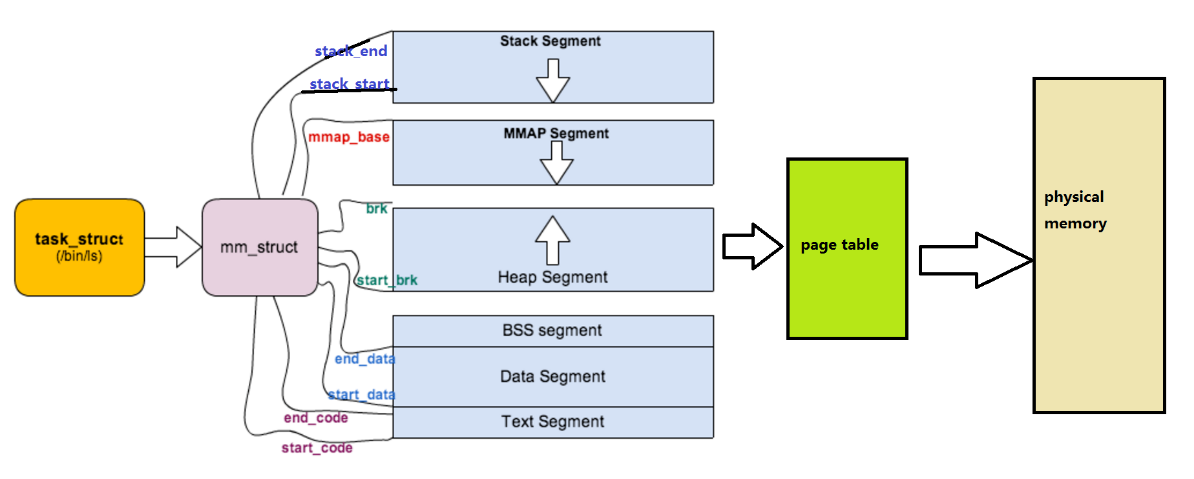
定位 mm_struct 文件所在位置和task_struct 所在路径是一样的,不过他们所在文件是不一样
mm_struct所在的文件是 mm_types.h
cppstruct mm_struct { / *...* / struct vm_area_struct *mmap; /* 指向虚拟区间(VMA)链表 */ struct rb_root mm_rb; /* red_black树 */ unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的大小*/ / *.. .* / // 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。 unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; }虚拟空间的组织方式:
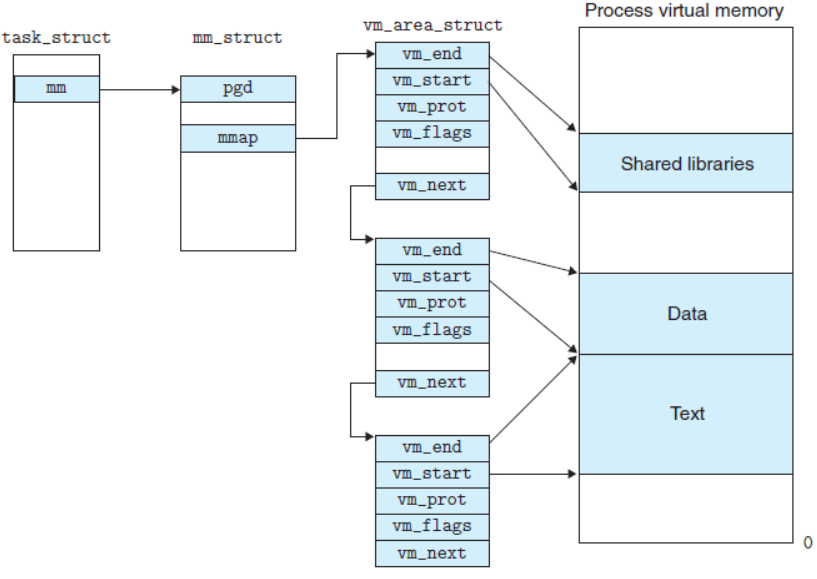
当虚拟区较少时采取单链表,由mmap指针指向这个链表;
当虚拟区间多时采取红黑树进行管理,由mm_rb指向这棵树。
linux内核使用 vm_area_struct 结构来表示一个独立的虚拟内存区域(VMA),由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。上面提到的两种组织方式使用的就是vm_area_struct结构来连接各个VMA,方便进程快速访问。
cppstruct vm_area_struct { unsigned long vm_start;//虚存区起始 unsigned long vm_end; //虚存区结束 struct vm_area_struct *vm_next, *vm_prev; //前后指针 struct rb_node vm_rb; //红黑树中的位置 unsigned long rb_subtree_gap; struct mm_struct *vm_mm; //所属的 mm_struct pgprot_t vm_page_prot; unsigned long vm_flags; //标志位 struct { struct rb_node rb; unsigned long rb_subtree_last; } shared; struct list_head anon_vma_chain; struct anon_vma *anon_vma; const struct vm_operations_struct *vm_ops;//vma对应的实际操作 unsigned long vm_pgoff; //文件映射偏移量 struct file * vm_file; //映射的文件 void * vm_private_data; //私有数据 atomic_long_t swap_readahead_info; #ifndef CONFIG_MMU struct vm_region *vm_region; #endif #ifdef CONFIG_NUMA struct mempolicy *vm_policy; /* NUMA policy for the VMA */ #endif struct vm_userfaultfd_ctx vm_userfaultfd_ctx; }__ randomize_layout;
2.2.2为什么要分开物理和虚拟
物理内存 在存储的时候,os都是无序的申请空间的,即物理地址对于同一个程序而言是不连续的,所以为了让进程能够以有序、统一的视角看待内存,依靠页表将物理内存与进程看到的内存分开,进程只需要看到有序的虚拟地址,至于虚拟地址对应的物理地址由页表映射。
因为有地址空间的存在和页表的映射的存在,我们的物理内存中可以对未来的数据进行任意位置的加载!物理内存的分配和进程的管理就可以做到没有关系,进程管理模块和内存管理模块就完成了解耦合。
因为有地址空间的存在,所以我们在C、C++语言上new,malloc空间的时候,其实是在地址
空间上申请的,物理内存可以甚至一个字节都不给你 。而当你真正进行对物理地址空间访问
的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(延迟分配),这是由操作系统自动完成,用户包括进程完全0感知 !!依靠这个可以充分保证内存的使用率,不会空转 。又因为new/malloc的时候不会立刻申请物理内存,所以可以提升类似的代码的执行速度。
当真正访问物理内存的时候,因为页表没有映射关系,会发生缺页中断,直到映射关系建立。
地址空间和页表是OS创建并维护的! 凡是想使用地址空间和页表进行映射,也一定要在OS的监管之下来进行访问 !! 也顺便保护了物理内存中的所有的合法数据 ,包括各个进程以及内核的相关有效数据!拦截非法请求,甚至干掉进程
这也是为什么,linux下,每个程序的虚拟地址区域验证的时候都是非常接近的,因为进程地址空间的虚拟地址唯一的要求就是有序,不需要担心物理内存的问题,只要能通过页表映射到不同的物理内存即可。