第一章:K8S介绍及部署
Kubernetes介绍

kubernetes(k8s)是2015年由Google公司基于Go语言编写的一款开源的容器集群编排系统,用于自动化容器的部署、扩缩容和管理;
kubernetes(k8s)是基于Google内部的Borg系统的特征开发的一个版本,集成了Borg系统大部分优势;
官方地址:Kubernetes.io
代码托管平台:github.com/Kubernetes
kubernetes具备的功能
- 自我修复:k8s可以监控容器的运行状况,并在发现容器出现异常时自动重启故障实例;
- 弹性伸缩:k8s可以根据资源的使用情况自动地调整容器的副本数。例如,在高峰时段,k8s可以自动增加容器的副本数以应对更多的流量;而在低峰时段,k8s可以减少应用的副本数,节省资源;
- 资源限额:k8s允许指定每个容器所需的CPU和内存资源,能够更好的管理容器的资源使用量;
- 滚动升级:k8s可以在不中断服务的情况下滚动升级应用版本,确保在整个过程中仍有足够的实例在提供服务;
- 负载均衡:k8s可以根据应用的负载情况自动分配流量,确保各个实例之间的负载均衡,避免某些实例过载导致的性能下降;
- 服务发现:k8s可以自动发现应用的实例,并为它们分配一个统一的访问地址。这样,用户只需要知道这个统一的地址,就可以访问到应用的任意实例,而无需关心具体的实例信息;
- 存储管理:k8s可以自动管理应用的存储资源,为应用提供持久化的数据存储。这样,在应用实例发生变化时,用户数据仍能保持一致,确保数据的持久性;
- 密钥与配置管理:Kubernetes 允许你存储和管理敏感信息,例如:密码、令牌、证书、ssh密钥等信息进行统一管理,并共享给多个容器复用;
kubernetes集群角色
k8s集群需要建⽴在多个节点上,将多个节点组建成一个集群,然后进⾏统⼀管理,但是在k8s集群内部,这些节点⼜被划分成了两类⻆⾊:
- 一类⻆⾊为主节点,叫Master,负责集群的所有管理工作,和协调集群中运行的容器应用;
- ⼀类⻆⾊为⼯作节点,叫Node,负责运行集群中所有用户的容器应用, 执行实际的工作负载 ;
Master管理节点组件:
- API Server:作为集群的控制中心,处理外部和内部通信,接收用户请求并处理集群内部组件之间的通信;
- Scheduler:负责将待部署的 Pods 分配到合适的 Node 节点上,根据资源需求、策略和约束等因素进行调度;
- Controller Manager:管理集群中的各种控制器,例如 Deployment、ReplicaSet、Node 控制器等,管理集群中的各种资源;
- etcd:作为集群的数据存储,保存集群的配置信息和状态信息;
Node工作节点组件:
- Kubelet:负责与 Master 节点通信,并根据 Master 节点的调度决策来创建、更新和删除 Pod,同时维护 Node 节点上的容器状态;
- 容器运行时(如 Docker、containerd 等):负责运行和管理容器,提供容器生命周期管理功能。例如:创建、更新、删除容器等;
- Kube-proxy:负责为集群内的服务实现网络代理和负载均衡,确保服务的访问性;
非必须的集群插件:
- DNS服务:严格意义上的必须插件,在k8s中,很多功能都需要用到DNS服务,例如:服务发现、负载均衡、有状态应用的访问等;
- Dashboard: 是k8s集群的Web管理界面;
- 资源监控:例如metrics-server监视器,用于监控集群中资源利用率;
kubernetes集群类型
- 一主多从集群:由一台Master管理节点和多台Node工作节点组成,生产环境下Master节点存在单点故障的风险,适合学习和测试环境使用;
- 多主多从集群:由多台Master管理节点和多Node工作节点组成,安全性高,适合生产环境使用;
kubernetes集群规划
| 主机IP | 主机名 | 主机配置 | 角色 |
|---|---|---|---|
| 192.168.200.10 | master01 | 2C/4G | 管理节点 |
| 192.168.200.20 | master02 | 2C/4G | 管理节点 |
| 192.168.200.30 | master03 | 2C/4G | 管理节点 |
| 192.168.200.40 | node01 | 2C/4G | 工作节点 |
| 192.168.200.50 | node02 | 2C/4G | 工作节点 |
| 192.168.200.60 | ha1 | 1C/2G | LB |
| 192.168.200.70 | ha2 | 1C/2G | LB |
| 192.168.200.100 | / | / | VIP(虚拟IP) |
集群前期环境准备
修改每个节点主机名
shell
hostnamectl set-hostname master01
hostnamectl set-hostname master02
hostnamectl set-hostname master03
hostnamectl set-hostname worker01
hostnamectl set-hostname ha01
hostnamectl set-hostname ha02配置集群之间本地解析,集群在初始化时需要能够解析主机名
master01执行
shell
echo "192.168.200.10 master01" >> /etc/hosts
echo "192.168.200.20 master02" >> /etc/hosts
echo "192.168.200.30 master03" >> /etc/hosts
echo "192.168.200.40 node01" >> /etc/hosts
echo "192.168.200.50 node02" >> /etc/hosts每个节点执行初始化脚本
shell
[root@master01 ~]# cat init.sh
#!/bin/bash
echo "=====系统环境初始化脚本====="
sleep 3
echo "---->>> 关闭防火墙与SELINUX <<<----"
sleep 3
systemctl stop firewalld
systemctl disable firewalld &> /dev/null
setenforce 0
sed -i '/SELINUX/{s/enforcing/disabled/}' /etc/selinux/config
echo "---->>> 设置时区并同步时间 <<<----"
sleep 3
timedatectl set-timezone Asia/Shanghai
yum -y install chrony
systemctl start chronyd
systemctl enable chronyd
echo "---->>> 设置系统最大打开文件数 <<<----"
sleep 3
if ! grep "* soft nofile 65535" /etc/security/limits.conf &>/dev/null; then
cat >> /etc/security/limits.conf << EOF
* soft nofile 65535 #软限制
* hard nofile 65535 #硬限制
EOF
fi
echo "---->>> 系统内核优化 <<<----"
sleep 3
cat >> /etc/sysctl.conf << EOF
net.ipv4.tcp_syncookies = 1 #防范SYN洪水攻击,0为关闭
net.ipv4.tcp_max_tw_buckets = 20480 #此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死
net.ipv4.tcp_max_syn_backlog = 20480 #表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数
net.core.netdev_max_backlog = 262144 #每个网络接口 接受数据包的速率比内核处理这些包的速率快时,允许发送到队列的数据包的最大数目
net.ipv4.tcp_fin_timeout = 20 #FIN-WAIT-2状态的超时时间,避免内核崩溃
EOF
echo "---->>> 减少SWAP使用 <<<----"
sleep 3
echo "0" > /proc/sys/vm/swappiness
echo "---->>> 安装系统性能分析工具及其他 <<<----"
sleep 3
yum install -y wget tar unzip vim net-tools lrzsz epel-release用ansible批量管理工具
master01执行
shell
[root@master01 ~]# yum -y install ansible
[root@master01 ~]# cat /etc/ansible/hosts
[k8s] #名称随意起
192.168.200.10 #管理节点的ip
192.168.200.20
192.168.200.30
192.168.200.40
192.168.200.50
[root@master01 ~]# ansible k8s --list-host #列出管理的主机
hosts (5):
192.168.200.10
192.168.200.20
192.168.200.30
192.168.200.40
192.168.200.50配置免密
shell
[root@master01 ~]# ssh-keygen
[root@master01 ~]# ssh-copy-id 192.168.200.10
[root@master01 ~]# ssh-copy-id 192.168.200.20
[root@master01 ~]# ssh-copy-id 192.168.200.30
[root@master01 ~]# ssh-copy-id 192.168.200.40
[root@master01 ~]# ssh-copy-id 192.168.200.50用ansible执行本地解析
master01执行
shell
[root@master01 ~]# ansible k8s -m copy -a 'src=/etc/hosts dest=/etc/'
# -m 选择copy模块 -a参数 src选择文件 dest选择接受文件的目录 执行k8s里面的所有主机
[root@master01 ~]# ansible k8s -m copy -a 'src=/etc/hosts dest=/etc/'
192.168.200.10 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"checksum": "e8836e2fe5404ba12491595dd0904b4c869c1ed4",
"dest": "/etc/hosts",
"gid": 0,
"group": "root",
"mode": "0644",
"owner": "root",
"path": "/etc/hosts",
"secontext": "system_u:object_r:net_conf_t:s0",
"size": 274,
"state": "file",
"uid": 0
}
192.168.200.50 | CHANGED => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": true,
"checksum": "e8836e2fe5404ba12491595dd0904b4c869c1ed4",
"dest": "/etc/hosts",
"gid": 0,
"group": "root",
"md5sum": "c532db26adb0483e719c187fc45f21cb",
"mode": "0644",
"owner": "root",
"secontext": "system_u:object_r:net_conf_t:s0",
"size": 274,
"src": "/root/.ansible/tmp/ansible-tmp-1768062456.2526422-14531-271850656325293/source",
"state": "file",
"uid": 0
}
192.168.200.20 | CHANGED => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": true,
"checksum": "e8836e2fe5404ba12491595dd0904b4c869c1ed4",
"dest": "/etc/hosts",
"gid": 0,
"group": "root",
"md5sum": "c532db26adb0483e719c187fc45f21cb",
"mode": "0644",
"owner": "root",
"secontext": "system_u:object_r:net_conf_t:s0",
"size": 274,
"src": "/root/.ansible/tmp/ansible-tmp-1768062456.2326186-14527-234479680227272/source",
"state": "file",
"uid": 0
}
192.168.200.30 | CHANGED => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": true,
"checksum": "e8836e2fe5404ba12491595dd0904b4c869c1ed4",
"dest": "/etc/hosts",
"gid": 0,
"group": "root",
"md5sum": "c532db26adb0483e719c187fc45f21cb",
"mode": "0644",
"owner": "root",
"secontext": "system_u:object_r:net_conf_t:s0",
"size": 274,
"src": "/root/.ansible/tmp/ansible-tmp-1768062456.2361205-14528-134504389252368/source",
"state": "file",
"uid": 0
}
192.168.200.40 | CHANGED => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": true,
"checksum": "e8836e2fe5404ba12491595dd0904b4c869c1ed4",
"dest": "/etc/hosts",
"gid": 0,
"group": "root",
"md5sum": "c532db26adb0483e719c187fc45f21cb",
"mode": "0644",
"owner": "root",
"secontext": "system_u:object_r:net_conf_t:s0",
"size": 274,
"src": "/root/.ansible/tmp/ansible-tmp-1768062456.256709-14529-27504447793147/source",
"state": "file",
"uid": 0
}开启bridge网桥过滤功能master01执行
bridge(桥接) 是 Linux 系统中的一种虚拟网络设备,它充当一个虚拟的交换机,为集群内的容器提供网络通信功能,容器就可以通过这个 bridge 与其他容器或外部网络通信了。
shell
[root@master01 ~]# cat k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
#参数解释
net.bridge.bridge-nf-call-ip6tables = 1 //对网桥上的IPv6数据包通过iptables处理
net.bridge.bridge-nf-call-iptables = 1 //对网桥上的IPv4数据包通过iptables处理
net.ipv4.ip_forward = 1 //开启IPv4路由转发,来实现集群中的容器与外部网络的通信
[root@master01 ~]# ansible k8s -m copy -a 'src=/root/k8s.conf dest=/etc/sysctl.d/'
<!---->
shell
#由于开启bridge功能,需要加载br_netfilter模块来允许在bridge设备上的数据包经过iptables防火墙处理
[root@master01 /]# ansible k8s -m shell -a 'modprobe br_netfilter && lsmod | grep br_netfilter'
192.168.200.30 | CHANGED | rc=0 >>
br_netfilter 36864 0
bridge 417792 1 br_netfilter
192.168.200.50 | CHANGED | rc=0 >>
br_netfilter 36864 0
bridge 417792 1 br_netfilter
192.168.200.20 | CHANGED | rc=0 >>
br_netfilter 36864 0
bridge 417792 1 br_netfilter
192.168.200.40 | CHANGED | rc=0 >>
br_netfilter 36864 0
bridge 417792 1 br_netfilter
192.168.200.10 | CHANGED | rc=0 >>
br_netfilter 36864 0
bridge 417792 1 br_netfilter
#参数解释:
modprobe //命令可以加载内核模块
br_netfilter //模块模块允许在bridge设备上的数据包经过iptables防火墙处理
<!---->
shell
#加载配置文件,使上述配置生效
[root@master01 /]# ansible k8s -m shell -a 'sysctl -p /etc/sysctl.d/k8s.conf'
192.168.200.20 | CHANGED | rc=0 >>
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.200.40 | CHANGED | rc=0 >>
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.200.30 | CHANGED | rc=0 >>
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.200.50 | CHANGED | rc=0 >>
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
192.168.200.10 | CHANGED | rc=0 >>
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
配置ipvs功能master01执行
在k8s中Service有两种代理模式,一种是基于iptables的,一种是基于ipvs,两者对比ipvs负载均衡算法更加的灵活,且带有健康检查的功能,如果想要使用ipvs模式,需要手动载入ipvs模块。
ipset 和 ipvsadm 是两个与网络管理和负载均衡相关的软件包,在k8s代理模式中,提供多种负载均衡算法,如轮询(Round Robin)、最小连接(Least Connection)和加权最小连接(Weighted Least Connection)等;
arduino
[root@master01 /]# ansible k8s -m shell -a 'yum -y install ipset ipvsadm'将需要加载的ipvs相关模块写入到文件中
shgell
[root@master01 ~]# cat ip_vs.conf
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
[root@master01 ~]# ansible k8s -m copy -a 'src=/root/ip_vs.conf dest=/etc/modules-load.d/'
#模块介绍
ip_vs //提供负载均衡的模块,支持多种负载均衡算法,如轮询、最小连接、加权最小连接等
ip_vs_rr //轮询算法的模块(默认算法)
ip_vs_wrr //加权轮询算法的模块,根据后端服务器的权重值转发请求
ip_vs_sh //哈希算法的模块,同一客户端的请求始终被分发到相同的后端服务器,保证会话一致性
nf_conntrack //链接跟踪的模块,用于跟踪一个连接的状态,例如 TCP 握手、数据传输和连接关闭等执行命令来加载模块
shell
[root@master01 ~]# ansible k8s -m shell -a 'systemctl restart systemd-modules-load.service'
192.168.200.20 | CHANGED | rc=0 >>
192.168.200.30 | CHANGED | rc=0 >>
192.168.200.50 | CHANGED | rc=0 >>
192.168.200.40 | CHANGED | rc=0 >>
192.168.200.10 | CHANGED | rc=0 >>
[root@master01 ~]# ansible k8s -m shell -a 'lsmod | grep ip_vs'
192.168.200.50 | CHANGED | rc=0 >>
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 3 nf_nat,nft_ct,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 5 nf_conntrack,nf_nat,nf_tables,xfs,ip_vs
192.168.200.30 | CHANGED | rc=0 >>
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 3 nf_nat,nft_ct,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 5 nf_conntrack,nf_nat,nf_tables,xfs,ip_vs
192.168.200.20 | CHANGED | rc=0 >>
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 3 nf_nat,nft_ct,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 5 nf_conntrack,nf_nat,nf_tables,xfs,ip_vs
192.168.200.40 | CHANGED | rc=0 >>
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 3 nf_nat,nft_ct,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 5 nf_conntrack,nf_nat,nf_tables,xfs,ip_vs
192.168.200.10 | CHANGED | rc=0 >>
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 3 nf_nat,nft_ct,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 5 nf_conntrack,nf_nat,nf_tables,xfs,ip_vs 关闭SWAP分区
master01执行 为了保证 kubelet 正常工作,k8s强制要求禁用,否则集群初始化失败
shell
#临时关闭
[root@master01 ~]# ansible k8s -m shell -a 'swapoff -a'
#永久关闭
[root@master01 ~]# ansible k8s -m shell -a "sed -ri 's/.*swap.*/#&/' /etc/fstab"
192.168.200.30 | CHANGED | rc=0 >>
192.168.200.40 | CHANGED | rc=0 >>
192.168.200.50 | CHANGED | rc=0 >>
192.168.200.20 | CHANGED | rc=0 >>
192.168.200.10 | CHANGED | rc=0 >>
[root@master01 ~]# ansible k8s -m shell -a 'grep ".*swap.*" /etc/fstab'
192.168.200.20 | CHANGED | rc=0 >>
#/dev/mapper/rl_192-swap none swap defaults 0 0
192.168.200.50 | CHANGED | rc=0 >>
#/dev/mapper/rl_192-swap none swap defaults 0 0
192.168.200.40 | CHANGED | rc=0 >>
#/dev/mapper/rl_192-swap none swap defaults 0 0
192.168.200.30 | CHANGED | rc=0 >>
#/dev/mapper/rl_192-swap none swap defaults 0 0
192.168.200.10 | CHANGED | rc=0 >>
#/dev/mapper/rl_192-swap none swap defaults 0 0
检查swap
shell
[root@master01 ~]# ansible k8s -m shell -a 'free -h'
192.168.200.50 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.5Gi 481Mi 2.9Gi 8.0Mi 429Mi 3.1Gi
Swap: 0B 0B 0B
192.168.200.30 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.5Gi 505Mi 2.9Gi 8.0Mi 429Mi 3.0Gi
Swap: 0B 0B 0B
192.168.200.40 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.5Gi 506Mi 2.9Gi 8.0Mi 429Mi 3.0Gi
Swap: 0B 0B 0B
192.168.200.20 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.5Gi 473Mi 2.9Gi 8.0Mi 429Mi 3.1Gi
Swap: 0B 0B 0B
192.168.200.10 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.5Gi 677Mi 2.2Gi 9.0Mi 989Mi 2.9Gi
Swap: 0B 0B 0B
Docker环境准备
mastet01主机安装,不包括负载均衡节点
shell
#安装yum-utils创建docker存储库(阿里)
[root@master01 ~]# ansible k8s -m shell -a 'yum install -y yum-utils'
[root@master01 ~]# ansible k8s -m shell -a 'yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo'
<!---->
shell
#安装指定版本并设置启动及开机自启动
[root@master01 yum.repos.d]# ansible k8s -m shell -a 'yum -y install docker-ce-3:20.10.24-3.el9.x86_64 docker-ce-cli-1:20.10.24-3.el9.x86_64'
组件名称 核心作用 通俗理解
docker-ce Docker 核心服务(守护进程 dockerd),负责管理容器、镜像、网络、存储等 「后台服务」(干活的)
docker-ce-cli Docker 命令行客户端,提供 docker run/docker ps 等终端命令配置Cgroup驱动程序
mastet01主机执行 启用Cgroup控制组,用于限制进程的资源使用量,如CPU、内存、磁盘IO等
shell
[root@master01 ~]# ansible k8s -m shell -a 'mkdir /etc/docker'
[root@master01 ~]# cat daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://docker.1ms.run"]
}
#exec-opts:设置 Docker 的 cgroup 驱动为systemd(通常用于和 Kubernetes 的 cgroup 驱动保持一致)
#registry-mirrors:配置 Docker 镜像加速源,提升镜像拉取速度。
[root@master01 ~]# ansible k8s -m copy -a 'src=/root/daemon.json dest=/etc/docker/'
<!---->
shell
#启动服务并设置随机自启
[root@master01 ~]# ansible k8s -m shell -a 'systemctl enable docker --now'
#能同时完成设置开机自启和立即启动服务的快捷指令HAProxy及keepalived部署
此处的haproxy为apiserver提供反向代理,集群的管理请求通过VIP进行接收,haproxy将所有管理请求轮询转发到每个master节点上。
Keepalived为haproxy提供vip(192.168.200.100)在二个haproxy实例之间提供主备,降低当其中一个haproxy失效时对服务的影响。
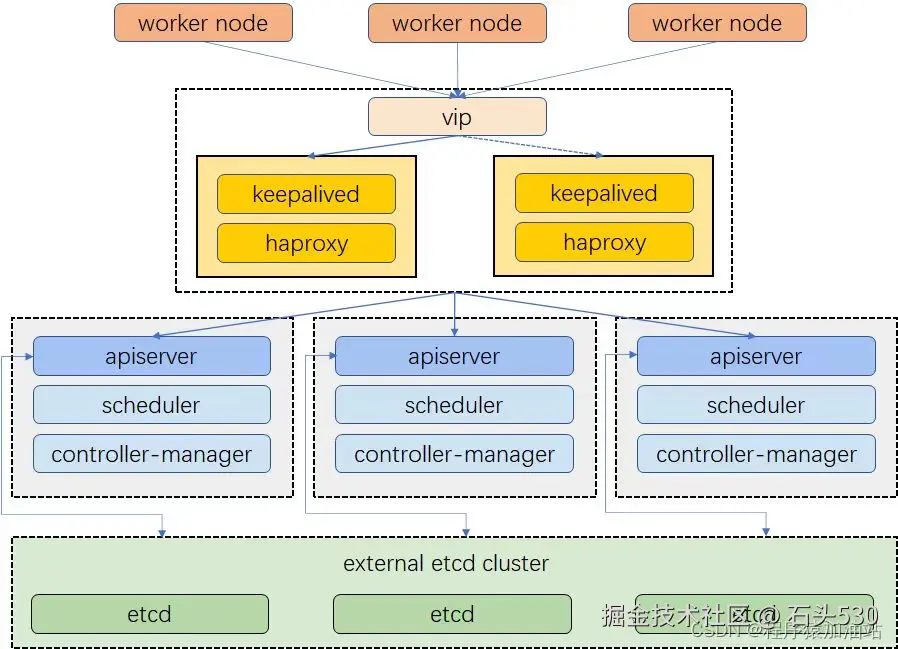
提示:以下操作只需要在master01配置。
csharp
[root@master01 ~]# cat /etc/ansible/hosts
[k8s]
192.168.200.10
192.168.200.20
192.168.200.30
192.168.200.40
192.168.200.50
[lvs]
192.168.200.60
192.168.200.70
#添加新的一组
[root@master01 ~]# ssh-copy-id 192.168.200.60
[root@master01 ~]# ssh-copy-id 192.168.200.70
[root@master01 ~]# ansible lvs --list-host
hosts (2):
192.168.200.60
192.168.200.70
[root@master01 ~]# ansible lvs -m shell -a 'yum -y install haproxy keepalived'haproxy配置文件内容如下
该配置文件内容在ha1与ha2节点保持一致
shell
[root@master01 ~]# cat haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
maxconn 2000 #单个进程最大并发连接数
ulimit-n 16384 #每个进程可以打开的文件数量
log 127.0.0.1 local0 err #日志输出配置
stats timeout 30s #连接socket超时时间
daemon #以守护进程方式运行
# 移除nbproc 1:HAProxy 2.5+不支持该参数
defaults
log global #继承全局日志配置
mode tcp #K8S APIServer用TCP模式,全局统一避免冲突
option dontlognull #不记录空连接日志
timeout connect 5000 #转发请求到后端的超时时间
timeout client 50000 #客户端非活动超时
timeout server 50000 #后端服务器非活动超时
timeout http-request 15s #HTTP请求超时(TCP模式下也兼容)
timeout http-keep-alive 15s #会话保持超时
# 监控HAProxy自身状态(可选,用于查看负载均衡状态)
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor #访问 http://IP:33305/monitor 可查看健康状态
# K8S Master负载均衡前端
frontend k8s-master
bind 0.0.0.0:6443 #仅绑定所有网卡的6443端口,避免重复
mode tcp
option tcplog #tcplog只保留在frontend段
tcp-request inspect-delay 5s
default_backend k8s-master
# K8S Master负载均衡后端
backend k8s-master
mode tcp
# 移除option tcplog:backend段不支持该参数
option tcp-check #TCP层健康检查
balance roundrobin #轮询负载均衡
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server master01 192.168.200.10:6443 check # 替换为你的master节点IP
server master02 192.168.200.20:6443 check # 替换为你的master节点IP
server master03 192.168.200.30:6443 check # 替换为你的master节点IP
[root@master01 ~]# ansible lvs -m copy -a 'src=/root/haproxy.cfg dest=/etc/haproxy/'master01执行 ha1与ha2启动haproxy
shell
[root@master01 ~]# ansible lvs -m shell -a 'systemctl enable haproxy --now'
192.168.200.70 | CHANGED | rc=0 >>
Created symlink /etc/systemd/system/multi-user.target.wants/haproxy.service → /usr/lib/systemd/system/haproxy.service.
192.168.200.60 | CHANGED | rc=0 >>
Created symlink /etc/systemd/system/multi-user.target.wants/haproxy.service → /usr/lib/systemd/system/haproxy.service.k8s-ha1节点keepalived配置文件内容如下
在ha01操作
shell
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_haproxyr {
script "/etc/keepalived/chk_haproxy.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 51
priority 101
advert_int 2
authentication {
auth_type PASS
auth_pass abc123
}
virtual_ipaddress {
192.168.200.100/24
}
track_script {
chk_haproxyr
}
}
配置文件详解
#定义一个自定义脚本,名称为chk_haproxyr
vrrp_scriptchk_haproxyr {
#脚本所在的路径及名称
script "/etc/keepalived/chk_haproxy.sh"
#监控检查的时间间隔,单位秒
interval 5
#健康检车的次数,连续2次健康检查失败,服务器将被标记为不健康
fall 2
#连续健康检查成功的次数,有1次健康检查成功,服务器将被标记为健康
rise 1
}
#配置了一个名为VI_1的VRRP实例组
vrrp_instance VI_1 {
#该节点在VRRP组中的身份,Master节点负责处理请求并拥有虚拟IP地址
state MASTER
#实例绑定的网络接口,实例通过这个网络接口与其他VRRP节点通信,以及虚拟IP地址的绑定
interface ens160
#虚拟的路由ID,范围1到255之间的整数,用于在一个网络中区分不同的VRRP实例组,但是在同一个VRRP组中的节点,该ID要保持一致
virtual_router_id 51
#实例的优先级,范围1到254之间的整数,用于决定在同一个VRRP组中哪个节点将成为Master节点,数字越大优先级越>高
priority 101
#Master节点广播VRRP报文的时间间隔,用于通知其他Backup节点Master节点的存在和状态,在同一个VRRP组中,所有>节点的advert_int参数值必须相同
advert_int 2
#实例之间通信的身份验证机制
authentication {
#PASS为密码验证
auth_type PASS
#此密码必须为1到8个字符,在同一个VRRP组中,所有节点必须使用相同的密码,以确保正确的身份验证和通信
auth_pass abc123
}
#定义虚拟IP地址
virtual_ipaddress {
192.168.200.100/24
}
#引用自定义脚本,名称与上方vrrp_script中定义的名称保持一致
track_script {
chk_haproxyr
}
}
k8s-ha1定义检测haproxy脚本
cat /etc/keepalived/chk_haproxy.sh
#!/bin/bash
JIN=$(ps -C haproxy | grep -v PID | wc -l)
if [ $JIN -eq 0 ];then
systemctl stop keepalived
fi
脚本添加执行权限
chmod +x /etc/keepalived/chk_haproxy.sh
**k8s-ha2节点keepalived配置文件内容如下**
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_haproxyr {
script "/etc/keepalived/chk_haproxy.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BAKUP
interface ens160
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass abc123
}
virtual_ipaddress {
192.168.200.100/24
}
track_script {
chk_haproxyr
}
}k8s-ha2定义检测haproxy脚本
shell
cat /etc/keepalived/chk_haproxy.sh
#!/bin/bash
JIN = $(ps -C haproxy | grep -v PID | wc -l)
if [$JIN -eq 0];then
systemctl stop keepalived
fi脚本添加执行权限
shell
chmod +x /etc/keepalived/chk_haproxy.shk8s-ha1与k8s-ha2节点启动keepalived
shell
systemctl enable keepalived --now 查看集群VIP地址
shell
查看VIP(提示:ifconfig命令查看不到VIP)
[root@k8s-ha1 ~]# ip a k8s集群部署方式
kubernetes集群有多种部署方式,目前常用的部署方式有如下两种:
- kubeadm部署方式:kubeadm是一个快速搭建kubernetes的集群工具
- 二进制包部署方式:从官网下载每个组件的二进制包,依次去安装,部署麻烦
- 其他方式:通过一些开源的工具搭建,例如:sealos
k8s YUM源准备
本实验使用阿里云YUM源
master01执行
shell
[root@master01 ~]# cat k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
[root@master01 ~]# ansible k8s -m copy -a 'src=/root/k8s.repo dest=/etc/yum.repos.d/'集群软件安装
安装集群软件,本实验安装k8s 1.23.0版本软件
- kubeadm:用于初始化集群,并配置集群所需的组件并生成对应的安全证书和令牌;
- kubelet:负责与 Master 节点通信,并根据 Master 节点的调度决策来创建、更新和删除 Pod,同时维护 Node 节点上的容器状态;
- kubectl:用于管理k8集群的一个命令行工具;
master01执行,不包括负载均衡节点
shell
#安装指定版本
[root@master01 yum.repos.d]# ansible k8s -m shell -a 'yum install -y kubeadm-1.23.17-0 kubelet-1.23.17-0 kubectl-1.23.17-0 '
#### 配置kubelet
启用Cgroup控制组,用于限制进程的资源使用量,如CPU、内存、磁盘IO等
[root@master01 yum.repos.d]# cat kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
[root@master01 yum.repos.d]# ansible k8s -m copy -a 'src=/etc/yum.repos.d/kubelet dest=/etc/sysconfig/'
<!---->
#设置kubelet为开机自启动即可,集群初始化后自动启动
[root@master01 yum.repos.d]# ansible k8s -m shell -a 'systemctl enable kubelet --now '集群初始化
mastier01执行查看集群所需镜像文件
bash
[root@master01 ~]# kubeadm config images list
#...以下是集群初始化所需的集群组件镜像
v1.27.1; falling back to: stable-1.23
k8s.gcr.io/kube-apiserver:v1.23.17
k8s.gcr.io/kube-controller-manager:v1.23.17
k8s.gcr.io/kube-scheduler:v1.23.17
k8s.gcr.io/kube-proxy:v1.23.17
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6在master01节点初始化集群,需要创建集群初始化配置文件
shell
[root@master01 ~]# kubeadm config print init-defaults > kubeadm-config.yaml配置文件需要修改如下内容
shell
[root@master01 ~]# vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 7t2weq.bjbawausm0jaxury
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.200.10 #根据自己环境修改IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master01 #修改自己master01名称
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 192.168.200.100 #手动添加 在证书中指定的可信IP地址,负载均衡的VIP
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.200.100:6443 #手动添加 负载均衡器的IP,主要让Kubernetes知道生成主节点令牌
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #集群组件镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: v1.23.0 #集群版本
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 #pod网络
serviceSubnet: 10.96.0.0/12 #service网络
scheduler: {}
<!---->
csharp
#初始化集群
[root@master01 ~]# kubeadm init --config /root/kubeadm-config.yaml --upload-certs
### 选项说明:
- init //初始化集群
- --config //基于配置文件初始化
- --upload-certs //将管理节点的证书加密后上传到 `kubeadm-certs` Secret 中,在高可用集群场景下,其他管理节点节点可以从该 Secret 中下载并使用这些证书,而不需要手动拷贝证书到其他管理节点。
perl
提示:如果哪个节点出现问题,可以使用下列命令重置当前节点
kubeadm reset初始化成功后,按照提示执行下边命令
shell
[root@master01 /]# mkdir -p $HOME/.kube
[root@master01 /] sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master01 /] sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master02 /]# mkdir -p $HOME/.kube
[root@master02 /] sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master02 /] sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master03 /]# mkdir -p $HOME/.kube
[root@master03 /] sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master03 /] sudo chown $(id -u):$(id -g) $HOME/.kube/configMaster节点加入集群
提示:按照自己当前集群生成的token在master02、master03节点执行
shell
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.200.100:6443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:ad5821ca12953ac4b1ad45c7778a0de8b62d45fd2125e844e8bde4cffa816179 \
--control-plane --certificate-key 0f610864572c5ddf6a4107bca972e8ccfae394d81f7658353c55b3d3a0c3dd7f
```
#### 工作节点加入集群
提示:按照自己当前集群生成的token在worker01、worker02节点执行
```shell
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.200.100:6443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:ad5821ca12953ac4b1ad45c7778a0de8b62d45fd2125e844e8bde4cffa816179
部署Calico网络
Calico 和 Flannel 是两种流行的 k8s 网络插件,它们都为集群中的 Pod 提供网络功能。然而,它们在实现方式和功能上有一些重要区别:
网络模型的区别:
- Calico 使用 BGP(边界网关协议)作为其底层网络模型。它利用 BGP 为每个 Pod 分配一个唯一的 IP 地址,并在集群内部进行路由。Calico 支持网络策略,可以对流量进行精细控制,允许或拒绝特定的通信。
- Flannel 则采用了一个简化的覆盖网络模型。它为每个节点分配一个 IP 地址子网,然后在这些子网之间建立覆盖网络。Flannel 将 Pod 的数据包封装到一个更大的网络数据包中,并在节点之间进行转发。Flannel 更注重简单和易用性,不提供与 Calico 类似的网络策略功能。
性能的区别:
- 由于 Calico 使用 BGP 进行路由,其性能通常优于 Flannel。Calico 可以实现直接的 Pod 到 Pod 通信,而无需在节点之间进行额外的封装和解封装操作。这使得 Calico 在大型或高度动态的集群中具有更好的性能。
- Flannel 的覆盖网络模型会导致额外的封装和解封装开销,从而影响网络性能。对于较小的集群或对性能要求不高的场景,这可能并不是一个严重的问题。
在k8s-master01节点安装Calico网络即可
sql
#下载calico文件
wget https://raw.githubusercontent.com/projectcalico/calico/v3.24.1/manifests/calico.yaml
#创建calico网络
kubectl apply -f calico.yaml
#查看calico的Pod状态是否为Running
kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-66966888c4-whdkj 1/1 Running 0 101s
calico-node-f4ghp 1/1 Running 0 101s
calico-node-sj88q 1/1 Running 0 101s
calico-node-vnj7f 1/1 Running 0 101s
calico-node-vwnw4 1/1 Running 0 101s验证集群可用性
sql
#查看所有的节点
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 10m v1.23.17
master02 Ready control-plane,master 8m37s v1.23.17
master03 Ready control-plane,master 8m33s v1.23.17
node01 Ready <none> 8m37s v1.23.17
node02 Ready <none> 7m51s v1.23.17
查看kubernetes集群pod运行情况
sql
[root@master01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-smp62 1/1 Running 0 13m
coredns-558bd4d5db-zcmp5 1/1 Running 0 13m
etcd-master01 1/1 Running 0 14m
etcd-master02 1/1 Running 0 3m10s
etcd-master03 1/1 Running 0 115s
kube-apiserver-master01 1/1 Running 0 14m
kube-apiserver-master02 1/1 Running 0 3m13s
kube-apiserver-master03 1/1 Running 0 116s
kube-controller-manager-master01 1/1 Running 1 13m
kube-controller-manager-master02 1/1 Running 0 3m13s
kube-controller-manager-master03 1/1 Running 0 116s
kube-proxy-629zl 1/1 Running 0 2m17s
kube-proxy-85qn8 1/1 Running 0 3m15s
kube-proxy-fhqzt 1/1 Running 0 13m
kube-proxy-jdxbd 1/1 Running 0 3m40s
kube-proxy-ks97x 1/1 Running 0 4m3s
kube-scheduler-master01 1/1 Running 1 13m
kube-scheduler-master02 1/1 Running 0 3m13s
kube-scheduler-master03 1/1 Running 0 115s
部署Nginx程序测试
perl
#部署nginx程序(提前将镜像导入到worker01、worker02节点)
[root@master01 ~]# kubectl create deployment nginx --image=choujiang_ngx:v1
#开放端口
[root@master01 ~]# kubectl expose deployment nginx --port=80 --type=NodePort
#查看pod状态
[root@master01 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-696649f6f9-j8zbj 1/1 Running 0 2m1s
#查看service状态
[root@master01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13m
nginx NodePort 10.97.7.109 <none> 80:31787/TCP 14s
#浏览器访问测试
http://192.168.200.10:31787/