前言
在日常学习和工作中,经常需要将 Markdown 笔记导出为 PDF 进行分享或存档,但现有的在线编辑器功能受限,浏览器打印样式丢失,截图工具清晰度差。因此,开发了一个本地 Markdown 笔记应用 + PDF 后端服务,支持多种中英文字体、暗黑/明亮主题切换、实时预览和语法高亮,通过前端准备自包含 HTML + 后端 Puppeteer 渲染的方式,实现高质量、样式保真的 PDF 导出功能,满足个人笔记管理和分享的需求。
本文内容包括:常见方案比较、为什么选择「前端准备 HTML + 后端 Puppeteer 渲染」、具体实现(包含内联 CSS、字体、图片、分页、CORS、调试与生产注意项)。
一、把网页导成 PDF 容易遇到的问题
很多人以为:把页面截屏或直接用浏览器打印就行。但真正要把排版一致、清晰、可分页的 PDF 做好,会碰到很多问题:
- 截图(html2canvas)清晰度差:这是把 DOM 渲成 bitmap,再把 bitmap 放进 PDF → 放大就模糊。
- 样式丢失/不一致:许多样式(@font-face、外链 CSS、变量)在服务器端渲染或截图时无法正常加载。
- 分页问题 :页面 CSS 可能把内容限定为一屏(比如
height:100vh; display:flex; overflow:hidden),导致所有内容被强制压在一页。 - 跨域 / 网络访问问题:后端渲染时可能没有外网权限去拉 Google Fonts / CDN 资源。
- 字体不生效:客户端通过 CSS 变量或 JS 动态注入字体,但当你把 HTML 发到后端时,后端不识别这些运行时变量。
- CORS / devServer 代理 / IPv6:前端请求后端时可能出现 404 或跨域错误,尤其在开发环境(不同端口)下。
结论:要做「高保真、可分页、服务器生成的 PDF」,推荐的稳健方案是 前端负责把要渲染的 HTML + 样式准备好(尽可能自包含)→ 发给后端(Puppeteer/Headless Chrome)渲染成 PDF。
二、常见方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| html2canvas + jsPDF(纯前端截图) | 易用、无后端 | 清晰度及样式一致性差,长页/分页差,资源限制 |
| wkhtmltopdf | 稳定、可命令行 | 基于旧版 WebKit,CSS 支持/现代特性差 |
| Puppeteer(Headless Chrome) | 高保真、支持现代 CSS/JS、分页、header/footer | 需要后端环境,部署/资源成本高 |
| 前端生成静态 HTML → 后端 Puppeteer 渲染(推荐) | 灵活、最好还原度、能控制资源 | 需处理资源内联、跨域、安全问题 |
三、核心原理(为什么要这么做)
- 后端渲染的好处 :Headless Chrome 会把 HTML 当成浏览器渲染页来处理,支持复杂 CSS(flex/grid/自定义变量)、打印样式、@font-face、JS(如果允许)等,生成 PDF 时可开启
printBackground来保留背景色/图片。 - 为什么要前端"准备"HTML:浏览器端能方便读取 computed style、将图片/字体转换为 data URI、提取相对路径的 CSS 内容。把这些工作做在前端,后端只负责渲染和生成 PDF,能最小化后端对外网/文件系统的依赖。
- 为什么要内联样式/字体 :避免后端渲染时找不到相对路径资源(特别是打包后的
dist),以及避免跨域导致资源加载失败(从而导致字体、图标、样式缺失)。
四、实现要点
下面给出一个可实战的流程,并贴上关键代码块(前端 + 后端)。每段代码后我都会解释为什么这样写、可能的坑与解决方案。
我们的项目采用前后端分离架构:
bendibiji/
├── src/ # 前端代码
│ ├── index.html # 主页面
│ ├── index.js # 入口文件
│ ├── scripts/ # 模块化脚本
│ │ ├── app.js # 主应用逻辑
│ │ ├── modules/ # 功能模块
│ │ │ ├── exporter.js # PDF导出核心
│ │ │ ├── theme.js # 主题和字体管理
│ │ │ ├── title.js # 标题处理
│ │ │ └── ...
│ │ └── styles/
│ └── images/
└── pdf-server/ # 后端PDF服务
├── server.js # Express服务器
└── package.json # 依赖配置4.1 前端:把要渲染的页面准备成「自包含」HTML
目标:
- 把 preview 内容包进一个容器;
- 把页面用到的相对 CSS 文件内容
fetch()出来并内联(并处理 CSS 里url(...)引用); - 保留外部 CDN 链接(可选)或把字体/资源也内联成 base64;
- 将运行时的 CSS 变量(比如
--font-body)的 computed values 写入最终 HTML,避免后端无法读取变量值; - 覆盖掉影响分页的样式(比如
height:100vh,overflow:hidden,display:flex),以便 Puppeteer 正常分页。
关键实现(带注释):
javascript
// helpers
async function fetchTextSafe(url) {
try {
const res = await fetch(url);
if (!res.ok) throw new Error(`HTTP ${res.status}`);
return await res.text();
} catch (e) {
console.warn('[fetchTextSafe] failed', url, e);
return null;
}
}
async function fetchAsDataURL(url) {
// 把图片或字体资源转成 data:... base64 URI
try {
const res = await fetch(url);
const blob = await res.blob();
return await new Promise((resolve) => {
const reader = new FileReader();
reader.onloadend = () => resolve(reader.result);
reader.readAsDataURL(blob);
});
} catch (e) {
console.warn('[fetchAsDataURL] failed', url, e);
return null;
}
}
// 用于把 CSS 里的相对 url(...) 替换成 data:URI(需要额外 fetch)
async function inlineCssResources(cssText, baseUrl) {
// 匹配 url(...) 中非 data 非 http 的路径
const urlRegex = /url\((['"]?)(?!data:|https?:|\/\/)([^'")]+)\1\)/g;
const tasks = [];
const replacements = new Map();
let m;
while ((m = urlRegex.exec(cssText)) !== null) {
const relPath = m[2];
if (replacements.has(relPath)) continue;
const abs = new URL(relPath, baseUrl).toString();
tasks.push((async () => {
const data = await fetchAsDataURL(abs);
if (data) replacements.set(relPath, data);
})());
}
await Promise.all(tasks);
// do replacement
return cssText.replace(urlRegex, (match, q, p1) => {
const data = replacements.get(p1);
if (data) return `url("${data}")`;
return match;
});
}
export async function getHTMLWithInlineCSS({ title = '导出 PDF' } = {}) {
// 1) 复制内容
const contentEl = document.querySelector('#previewContent'); // 你项目里实际元素
const container = document.createElement('div');
container.id = 'pdf-container';
container.innerHTML = contentEl.innerHTML;
// 2) 读取字体设置(computed)
const docStyle = getComputedStyle(document.documentElement);
const bodyFont = docStyle.getPropertyValue('--font-body').trim() || '"Inter", sans-serif';
const codeFont = docStyle.getPropertyValue('--font-code').trim() || '"JetBrains Mono", monospace';
// 3) 处理 <link rel="stylesheet">
let inlineStyles = '';
const links = Array.from(document.querySelectorAll('link[rel="stylesheet"]'));
for (const link of links) {
const href = link.getAttribute('href');
// 绝对 URL(CDN)保留(也可以选择 fetch 并内联)
if (/^https?:\/\//.test(href) || href.startsWith('//')) {
// choose to keep external links (or fetch and inline if you need offline)
inlineStyles += `<link rel="stylesheet" href="${href}">`;
continue;
}
// 相对路径:fetch CSS 内容并内联,同时把 CSS 内的 url(...) 也转成 data URI
const cssText = await fetchTextSafe(href);
if (cssText) {
const baseUrl = new URL(href, location.href).toString();
const processed = await inlineCssResources(cssText, baseUrl);
// 去掉 webpack loader 注释(例如 /*! ... */ )避免注释包含路径破坏HTML
const cleaned = processed.replace(/\/\*![\s\S]*?\*\//g, '');
inlineStyles += `<style>${cleaned}</style>`;
}
}
// 4) 内联页面上的 <style> 标签(例如由js注入的样式)
document.querySelectorAll('style').forEach(s => {
inlineStyles += `<style>${s.innerHTML}</style>`;
});
// 5) 添加打印/分页重置样式(覆盖原页面会影响分页的地方)
const resetStyles = `
<style>
/* 基本重置,确保 Puppeteer 打印时按内容分页 */
:root {
--font-body: ${currentBodyFont} !important;
--font-code: ${currentCodeFont} !important;
}
html {
margin: 0 !important;
padding: 0 !important;
height: 100% !important;
background-color: ${isDarkMode ? '#1e1e2f' : '#ffffff'} !important;
}
body {
margin: 0 !important;
padding: 0 !important;
min-height: 100vh !important;
overflow: visible !important;
line-height: 1.6 !important;
font-family: ${currentBodyFont} !important;
font-size: ${currentFontSize}px !important;
color: ${isDarkMode ? '#e0e0e0' : '#333333'} !important;
background-color: ${isDarkMode ? '#1e1e2f' : '#ffffff'} !important;
writing-mode: horizontal-tb !important;
}
#pdf-container {
width: 100% !important;
page-break-inside: auto !important;
background-color: transparent !important;
min-height: 100vh !important;
box-sizing: border-box !important;
}
/* 修复:允许代码块在页面中间分割 */
pre {
page-break-inside: auto !important;
break-inside: auto !important;
overflow-wrap: break-word !important;
}
/* 添加分页控制 */
@media print {
/* 在分页处添加视觉提示 */
.page-break {
break-before: page !important;
page-break-before: always !important;
}
/* 确保代码块分割后仍然可读 */
pre {
break-inside: auto !important;
page-break-inside: auto !important;
}
}
</style>
`;
// 6) 标题(可选)
const titleHTML = `<h1 style="text-align:center;margin-bottom:20px;">${title}</h1>`;
// 7) 组装最终 HTML
const html = `<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>${title}</title>
${inlineStyles}
${resetStyles}
</head>
<body>
${titleHTML}
${container.outerHTML}
</body>
</html>`;
return html;
}解释 / 注意点:
- 我们把相对 CSS fetch 到前端并内联,且会把 CSS 中引用的相对图片/字体也尝试转换为
data:URI ------ 这一步能让后端无需访问静态文件系统或外网就能完整渲染样式与字体。 cleaned = processed.replace(/\/\*![\s\S]*?\*\//g, ''):Webpack loader 的注释例如/*! *** css ./node_modules/... */会混入 CSS,直接内联到 HTML 可能造成混乱,所以删掉。- 我们从
document.documentElement读取 computed--font-body/--font-code并把字体字符串写进resetStyles,因为 CSS 变量在后端环境中没有运行时上下文。
4.2 前端:发送 HTML 到后端并下载 PDF
javascript
export async function exportToPDF() {
const html = await getHTMLWithInlineCSS({ title: els.pdfTitle.value || 'Markdown笔记导出' });
// 获取当前主题的背景颜色
const currentBgColor = getComputedStyle(document.documentElement).getPropertyValue('--bg').trim() || '#ffffff';
const resp= await fetch('http://127.0.0.1:3000/api/render-pdf', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
html,
backgroundColor: currentBgColor
}),
});
if (!resp.ok) {
const text = await resp.text();
alert('PDF 生成失败: ' + text);
return;
}
const blob = await resp.blob();
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = (els.pdfFilename?.value || 'notes') + '.pdf';
a.click();
URL.revokeObjectURL(url);
}小贴士:
- 我用
127.0.0.1而不是localhost,避免 IPv6[::1]与 IPv4 监听不一致导致的 404 问题。 Content-Type: application/json,body 里直接放 HTML(注意可能很大,后端需要增加bodyParser大小)。
4.3 后端:Express + Puppeteer 渲染 PDF(
关键点:支持 CORS、允许大请求体、以可靠的方式启动 Puppeteer。
javascript
// server.js
import express from 'express';
import bodyParser from 'body-parser';
import puppeteer from 'puppeteer';
import cors from 'cors';
const app = express();
app.use(cors({ origin: '*' }));
app.use(bodyParser.json({ limit: '50mb' }));
app.post('/api/render-pdf', async (req, res) => {
const { html, backgroundColor = '#ffffff', margin = '10mm' } = req.body;
if (!html) return res.status(400).send('No HTML provided');
let browser;
try {
browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
// 创建完整的HTML文档,确保内容正确换行和分页
const fullHtml = `
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
@page {
margin: ${margin};
size: A4;
background-color: ${backgroundColor} !important;
}
html, body {
margin: 0;
padding: 0;
width: 100%;
min-height: 100vh;
font-family: Arial, sans-serif;
}
.content {
min-height: 100vh;
/* 关键:确保内容不会溢出 */
width: 100%;
word-wrap: break-word;
overflow-wrap: break-word;
box-sizing: border-box;
}
/* 确保所有元素都能正确换行 */
* {
box-sizing: border-box;
max-width: 100%;
}
/* 表格和长文本处理 */
table {
width: 100% !important;
table-layout: fixed;
}
td, th {
word-wrap: break-word;
}
/* 代码块和预格式化文本处理 */
pre, code {
white-space: pre-wrap;
word-wrap: break-word;
}
/* 图片不会超出容器 */
img {
max-width: 100%;
height: auto;
}
/* 链接和长URL换行 */
a {
word-wrap: break-word;
}
</style>
</head>
<body>
<div class="content">
${html}
</div>
</body>
</html>
`;
await page.setContent(fullHtml, { waitUntil: 'networkidle0' });
// 等待内容渲染完成
await page.evaluateHandle('document.fonts.ready');
const pdfBuffer = await page.pdf({
format: 'A4',
printBackground: true,
margin: {
top: margin,
right: margin,
bottom: margin,
left: margin
},
omitBackground: false,
displayHeaderFooter: false
});
res.set({
'Content-Type': 'application/pdf',
'Content-Disposition': 'attachment; filename="markdown-notes.pdf"',
'Content-Length': pdfBuffer.length,
});
res.send(pdfBuffer);
} catch (err) {
console.error(err);
res.status(500).send('PDF生成失败: ' + err.message);
} finally {
if (browser) await browser.close();
}
});
app.listen(3000, '0.0.0.0', () => console.log('PDF服务已启动: http://localhost:3000'));注意/建议:
app.listen(3000, '0.0.0.0')能避免 IPv6/localhost 地址问题。page.setJavaScriptEnabled(false):如果你担心收到的 HTML 包含恶意脚本,最好禁用 JS 执行(但会影响某些依赖 client JS 的渲染)。更好的做法是 在前端把需要的脚本运行并把最终静态 HTML 发给后端(即后端不会执行页面内的脚本)。
4.4 效果如图:
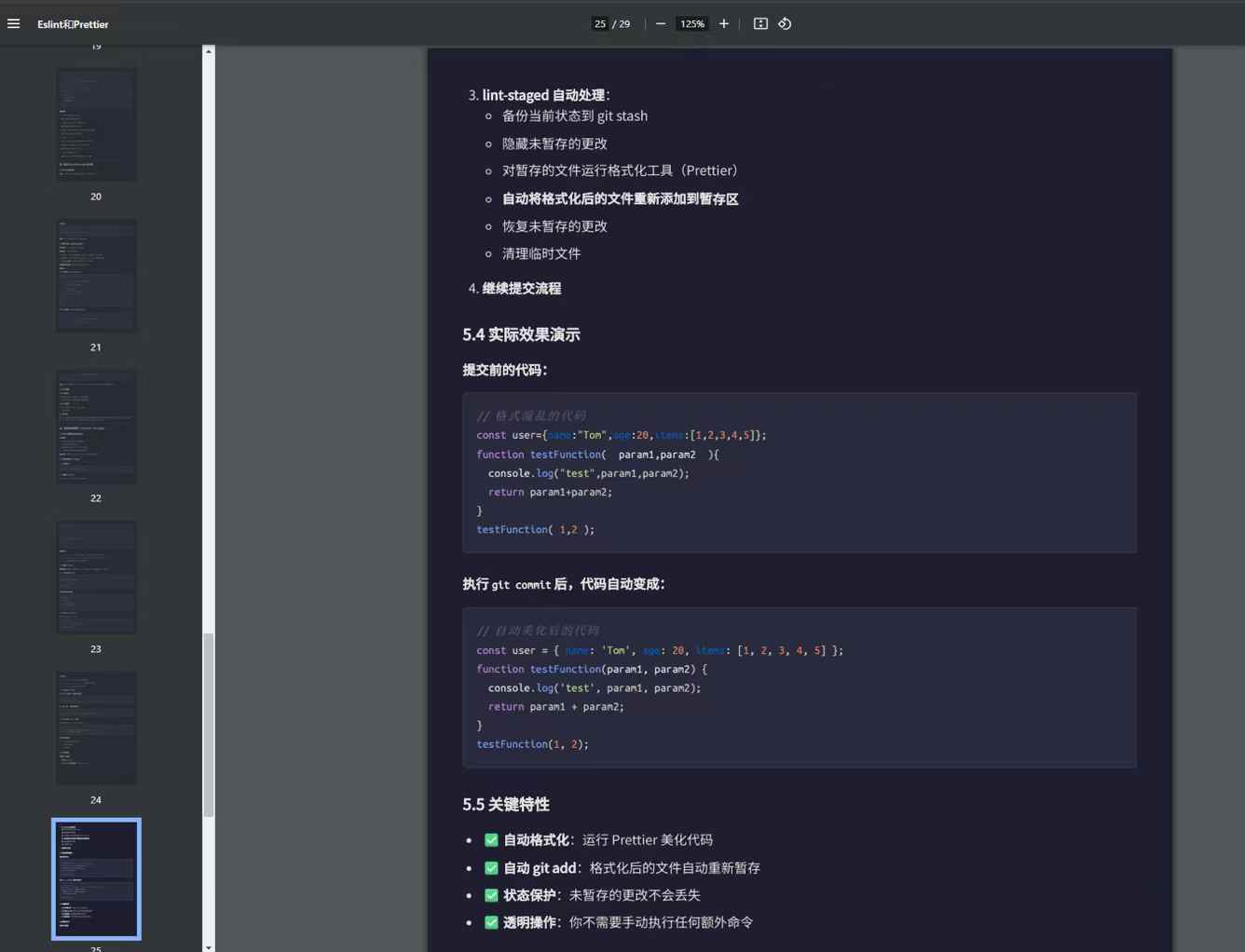
五、常见问题与解决方案
下面是实际项目中最常见的问题与解决办法------把我遇到的坑全罗列,并给出可复制的解决动作。
问题 A:前端请求后端返回 404,但 curl 能成功
原因:
- 跨域/代理问题,或浏览器解析
localhost为::1(IPv6),而 server 只监听 IPv4(127.0.0.1)。
解决: - 后端使用
app.listen(3000, '0.0.0.0'); - 或者前端直接请求
http://127.0.0.1:3000; - 在开发时可以使用 webpack devServer proxy,但生产最好用完整 URL + 后端 CORS。
问题 B:样式不对或全部挤成一页
原因:
- 页面有
height:100vh; overflow:hidden; display:flex,此类样式在打印/生成 PDF 时导致布局异常。
解决: - 在导出 HTML 时通过覆盖 CSS(resetStyles)移除这些属性(
height:auto!important; overflow:visible!important; display:block!important;)。 - 使用
page-break-inside/break-insideCSS 控制分页:pre, table { page-break-inside: avoid; }。
问题 C:Webpack 打包生成的 CSS 带注释(/*! ... */)或 loader 信息混入
原因:
- 在 dev 模式或通过 css-loader/postcss-loader,生成的 CSS 里可能含 loaders 注释与路径。
解决: - 内联前先清理注释:
css = css.replace(/\/\*![\s\S]*?\*\//g, '')。 - 或者直接读取打包输出的
dist/css/main.xxx.css文件来获取纯 CSS,不要依赖页面内<style>那些带 loader 注释的输出。
问题 D:字体没有生效
原因:
- 前端通过 CSS 变量或运行时设置字体,但后端渲染时没有这些变量(或无法访问字体文件 CDN)。
解决:
- 在构造 HTML 时直接把
font-family的 computed value 写到html, body中(如示例代码所示)。 - 如果后端无外网权限或要保证离线:把字体文件 base64 内联到 CSS(@font-face + data URI),或者把字体文件放在后端可访问的静态目录并把
<link>指向绝对 URL。 - 若字体是 woff/woff2/ttf,内联到 CSS 示例:
css
@font-face {
font-family: 'MyFont';
src: url('data:font/woff2;base64,AAAB...') format('woff2');
font-weight: 400;
font-style: normal;
}
body { font-family: 'MyFont', sans-serif; }提供一个 node 脚本把字体转换为 base64 的方法(可选):
js
import fs from 'fs';
const buf = fs.readFileSync('./dist/fonts/MyFont.woff2');
const base64 = buf.toString('base64');
console.log(`data:font/woff2;base64,${base64}`);问题 E:图片不显示或报 CORS
原因:
- 图片来自第三方且没有 CORS 允许;Canvas 转 dataURI 会被阻止;Puppeteer 在
page.setContent时如果图片是跨域,可能无法加载。
解决: - 在前端把图片转换为 base64 data URI(通过 fetch blob -> FileReader)并插到
<img src="data:...">; - 或者后端获取图片并送回(后端渲染时自己去拉资源,而不是依赖浏览器)。
六、调试技巧
-
接口 curl vs 浏览器:
- 如果
curl成功而浏览器 404/报错,先检查浏览器控制台 Network → 看请求是否被 Service Worker / devServer 拦截或是否触发 CORS。
- 如果
-
Remote Address 显示
[::1]:- 使用
127.0.0.1可以避免 IPv6 与 IPv4 的监听不一致问题,或者让 server 监听0.0.0.0。
- 使用
-
字体问题:
- 用 developer tools 查看实际 CSS 是否包含
@font-face,或查看网络面板字体文件是否被请求并返回 200。
- 用 developer tools 查看实际 CSS 是否包含
-
样式被压缩成一页:
- 检查页面是否有
height:100vh、display:flex; flex-direction:row、overflow:hidden。在导出的 HTML 中覆盖这些样式。
- 检查页面是否有
-
Webpack 打包 CSS 包含注释:
- 在内联前用正则删除
/*! ... */注释,或直接读取打包后的 CSS 文件而不是页面内联样式。
- 在内联前用正则删除
七、附前端代码高亮功能实现详解
整体流程概述
你的项目是一个Markdown编辑器,用户输入Markdown文本,系统将其转换为带代码高亮的HTML预览。
核心库作用
1. marked.js - Markdown解析器
-
作用: 将Markdown文本转换为HTML
-
转换后: 变成标准的HTML结构
2. highlight.js - 代码高亮库
- 作用: 给代码块添加语法高亮颜色
- 效果: 让代码中的关键字、字符串、注释等显示不同颜色
- 示例 : JavaScript代码中的
function、console等会显示为不同颜色
完整实现步骤
步骤1: 引入库文件
html
<!-- Markdown解析器 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/marked/4.2.12/marked.min.js"></script>
<!-- 代码高亮库 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.7.0/highlight.min.js"></script>
<!-- 高亮样式主题 -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.7.0/styles/github-dark.min.css" />步骤2: 配置marked与highlight.js联动
javascript
marked.setOptions({
highlight: function (code, lang) {
// 如果指定了语言,就用指定语言高亮
if (lang && hljs.getLanguage(lang)) {
return hljs.highlight(code, { language: lang }).value;
}
// 否则自动检测语言
return hljs.highlightAuto(code).value;
},
langPrefix: 'hljs language-', // 给代码块添加CSS类名
breaks: true, // 支持换行
gfm: true // 支持GitHub风格的Markdown
});步骤3: 动态加载语言包(按需加载)
javascript
function loadHighlightLanguage(lang) {
// 避免重复加载
if (state.loadedLanguages.has(lang)) return Promise.resolve();
// 动态创建script标签加载特定语言包
const scriptSrc = `https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.7.0/languages/${lang}.min.js`;
return new Promise((resolve, reject) => {
const script = document.createElement('script');
script.src = scriptSrc;
script.onload = () => {
state.loadedLanguages.add(lang);
resolve();
};
script.onerror = () => reject(new Error(`加载语言包失败: ${lang}`));
document.head.appendChild(script);
});
}步骤4: 核心预览更新函数
javascript
async function updatePreview() {
// 1. 获取编辑器中的Markdown文本
let markdownText = els.editor.value;
// 2. 处理自定义颜色语法 ==颜色:文本==
markdownText = markdownText.replace(/==([a-zA-Z#0-9#]+):([\s\S]+?)==/g, function (match, color, text) {
return `<span style="color:${color};">${text}</span>`;
});
// 3. 设置预览区域样式
els.previewContent.style.fontFamily = getComputedStyle(document.documentElement).getPropertyValue('--font-body');
els.previewContent.style.fontSize = state.fontSize + 'px';
// 4. 将Markdown转换为HTML
els.previewContent.innerHTML = marked.parse(markdownText);
// 5. 查找所有代码块
const codeBlocks = els.previewContent.querySelectorAll('pre code');
const langsToLoad = new Set();
// 6. 收集需要加载的编程语言
codeBlocks.forEach(code => {
const classes = code.className.split(/\s+/);
for (const cls of classes) {
if (cls.startsWith('language-')) {
const lang = cls.replace('language-', '');
langsToLoad.add(lang);
}
}
});
// 7. 动态加载需要的语言包
try {
await Promise.all([...langsToLoad].map(loadHighlightLanguage));
} catch (e) {
console.warn(e);
}
// 8. 对每个代码块应用语法高亮
codeBlocks.forEach(code => {
try {
hljs.highlightElement(code);
} catch {}
});
}实际效果演示
用户输入:
markdown
# 我的代码示例
这是一段JavaScript代码:
```javascript
function greet(name) {
console.log(`Hello, ${name}!`);
return `Welcome, ${name}`;
}转换后的效果:
function、console、return等关键字显示为蓝色- 字符串
"Hello, ${name}!"显示为绿色 - 注释显示为灰色
==#ff0000:这是红色文字==显示为红色文字
关键优势
- 按需加载: 只加载实际使用的编程语言包,节省带宽
- 自动检测: 可以自动识别代码语言类型
- 自定义语法: 支持特殊的颜色标记语法
- 性能优化: 避免重复加载,有缓存机制
八、结语:一步步复习要点
如果你要复习或复现这套方案,建议按这个顺序操作并验证:
- 在本地用 puppeteer 做个最简单的渲染:
<h1>hello</h1>→ PDF 成功。 - 把你页面的 HTML 发给后端,确认渲染的样式(注意字体是否生效)。
- 实现 CSS 的内联(先简单把 main.css 的内容 copy 到内联
<style>),再测试。 - 处理
url(...)中的资源(图片/字体)为 data URI。 - 修复分页相关样式(移除
100vh、flex 等)。 - 处理字体(Google Fonts vs 本地自托管);如果要离线,转换为 base64 并
@font-face内联。 - 添加安全校验、鉴权、速率限制。