JVM的垃圾回收主要在堆中进行,中存放着几乎所有的对象实例,垃圾回收器在对堆进行垃圾回收前,首先要判断这些对象哪些还存活,哪些已经"死去".判断对象是否已"死"有如下几种算法:
死亡对象的判断方法
引用计数算法
引⽤计数描述的算法为:给对象增加⼀个引⽤计数器,每当有⼀个地⽅引⽤它时,计数器就+1;当引⽤失效时,计数器就-1.任何时刻计数器为0的对象就是不能再被使⽤的,即对象已"死".
例如:
java
public class Test {
public static void main(String[] args) {
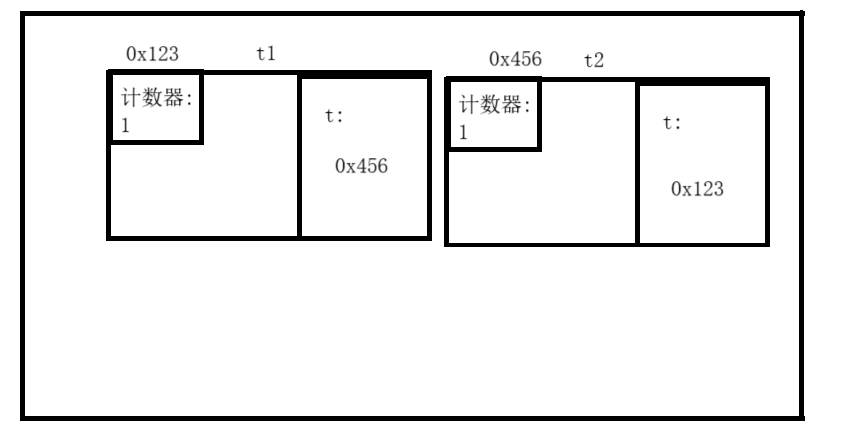
//对于这两个new出的Test对象,我们称为t1与t2
Test a = new Test();
Test b = new Test();
//在这里由于a引用了t1,b引用了t2,所以t1与t2的计数器都为1.
a = null;
//将a设为null后,a不再引用t1,t1的计数器减1变为0.视为t1已死
b = null;
//将b设为null后,b不再引用t2,t2的计数器减1变为0.视为t2已死
}
}但是,计数算法存在一个问题:循环引用问题.
java
public class Test {
Test t;
public static void main(String[] args) {
//对于这两个new出的Test对象,我们称为t1与t2
Test a = new Test();
Test b = new Test();
//在这里由于a引用了t1,b引用了t2,所以t1与t2的计数器都为1.
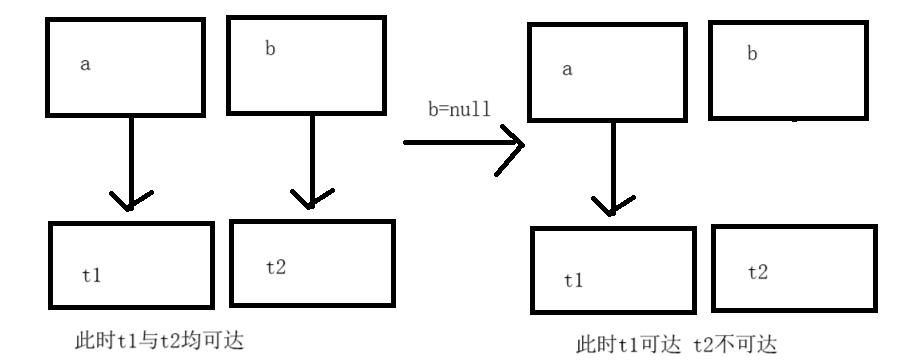
a.t = b;
b.t = a;
//这里t1.t对t2进行了引用,t2.t对t1进行了引用.因此t1与t2的计数器都为2
a = null;
b = null;
//将a与b都设为null后,a与b不再引用t1与t2.
//但是t1.t仍在引用t2,t2.t仍在引用t1.此时t1与t2的计数器都为1.不视为已死
}
}
这样两个对象相互引用,导致这两个对象实际已经死亡但是计数器为1,仍视为未死亡.
所以JVM没有使用计数算法来判断对象是否死亡.
可达性分析算法
此算法的核⼼思想为:通过⼀系列对象作为起始点,从这些节点开始向下搜索,搜索⾛过的路径称之为"引⽤链",当⼀个对象到起点没有任何的引⽤链相连时,证明此对象是不可⽤的.这个过程实际就是在"遍历".
可作为起点的对象有:虚拟机栈中引用的对象,元数据区中静态引用的对象/常量引用的对象,本地方法栈中引用的对象.
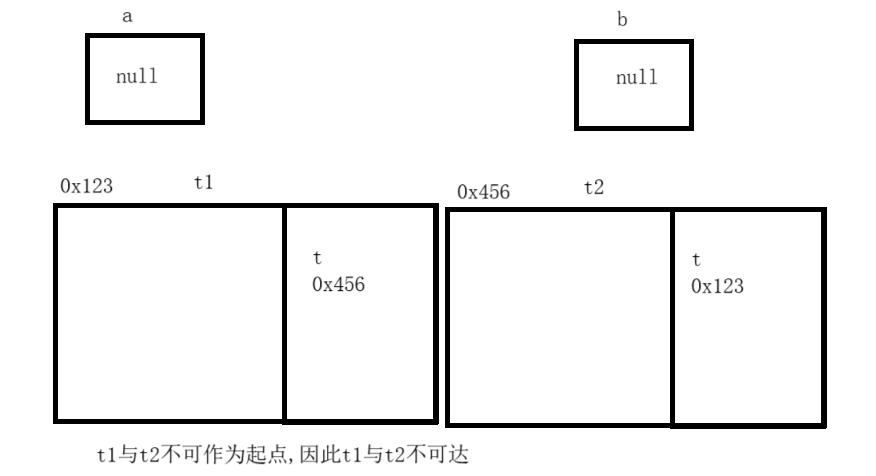
可达性分析可以解决循环引用问题,因为t1与t2不可以作为起点,所以在判断时,认为t1,t2均不可达.
垃圾回收算法
在定位出垃圾后,就要对垃圾进行回收来节省内存空间.
标记清除算法
"标记-清除"算法是最基础的收集算法.算法分为"标记"和"清除"两个阶段:⾸先标记出所有需要回收的对象,在标记完成后统⼀回收所有被标记的对象.
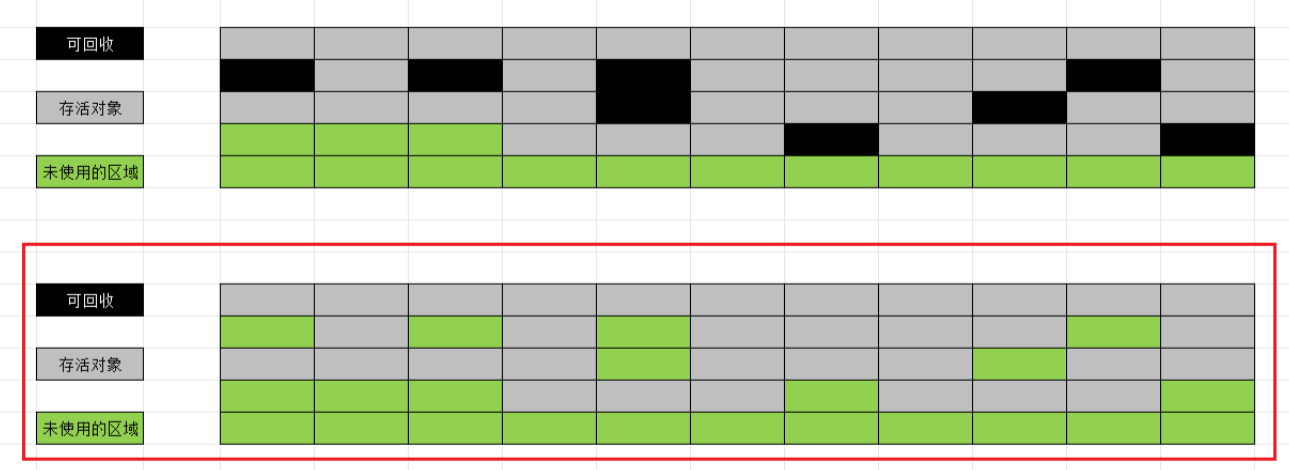
标记回收算法有一个严重的缺点:回收出的内存空间碎片化.过于碎片化的内存空间会阻碍内存的申请.当需要进行较大内存的申请时,内存碎片话会让内存总和虽然够,但是内存分布分散,无法分配出一块大内存.
复制算法
"复制"算法是为了解决"标记-清理"的效率问题.它将可⽤内存按容量划分为大小相等的两块,每次只使⽤其中的⼀块.当这块内存需要进⾏垃圾回收时,会将此区域还存活着的对象复制到另⼀块上⾯,然后再把已经使⽤过的内存区域⼀次清理掉.
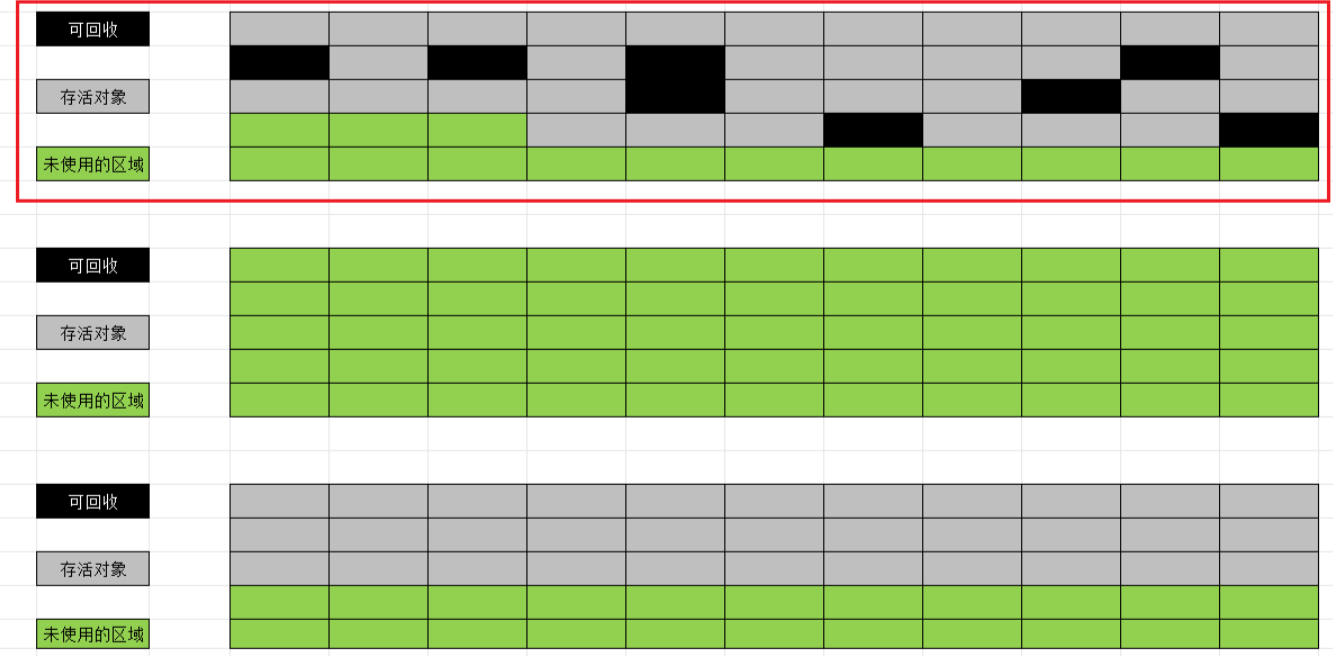
复制算法的缺点:
1.浪费了内存空间
2.当需要复制大量的对象时,会有不小的开销.
标记整理算法
标记过程仍与"标记-清除"过程⼀致,但后续步骤不是直接对可回收对象进⾏清理,⽽是让所有存活对象都向⼀端移动,然后直接清理掉端边界以外的内存.
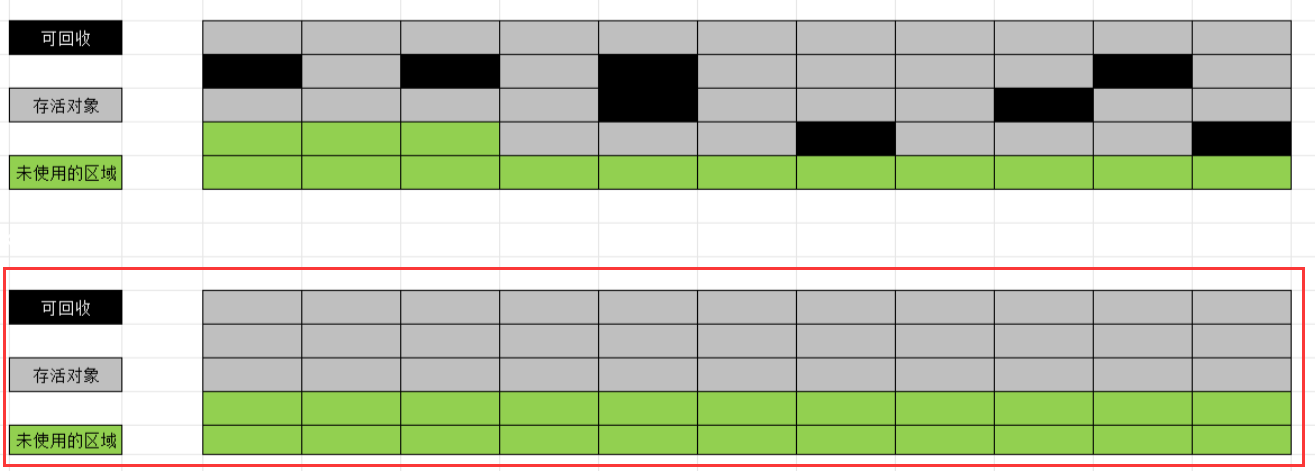
标记整理法的效率较低.
JVM使用的算法
上述三种算法都有各自的优势区间,所以JVM在使用时,将三种算法用在不同区域来让其扬长避短.Java堆中分为新生代区与老生代区,新生代区中的对象产生时间较短,老年代区中的对象较大或产生的时间较长.
新生代区中的对象每次垃圾回收都有⼤批对象死去,只有少量存活.对于小对象且对象数量少时,适合使用复制算法.新生代区分为Eden区与两个幸存区,当扫描到幸存对象后,会将幸存对象送入幸存区,后续进行复制算法的清除,如果一个对象在幸存区存货较长时间那么这个对象就会被送入老年代区.
而老年代区中对象较大且存活率高,没有额外空间来对他进行分配担保,此时就使用标记清楚算法或标记整理算法.并且此时的扫描速度要慢于新生代区中的扫描速度.
