【置顶必看】k学长的深度宝典
源码、配套笔记&讲解视频,点击文末名片获取
- 研究背景和动机(MnasNet)
我们先回顾一下背景: - 以前的做法(人工 + 理论指标)
- 在 MobileNet、ShuffleNet 之前,网络基本靠 人类专家拍脑袋设计:
- 用什么卷积?
- 每层多少通道?
- 多深?
- 改进方向主要看 FLOPs(理论计算量),但这有个大坑:
- FLOPs 低 ≠ 手机上跑得快。
- 因为硬件(手机 CPU/GPU)有内存访问瓶颈,导致一些理论轻量的模型,实际并不快。
👉 举例:MobileNet v2 FLOPs 比较少,但在手机上推理并没有预期那么快。
如果一味减小网络,速度快了但精度掉太多;如果一味加深网络,精度提高了但速度变慢。
MnasNet 的核心动机就是:
- 用自动化的神经网络结构搜索(NAS)方法,帮我们在"速度---精度"之间找到最优平衡,而且是真正针对具体硬件(比如手机 CPU)来优化的。
- MnasNet 的核心创新
具体方法叫 平台感知的神经架构搜索(Platform-Aware NAS)。
- 它的主要特点:
- 不是人手工设计,而是让 AI(强化学习控制器)自动生成模型结构。
- 不是光看 FLOPs,而是直接在真手机上跑,测出每个候选模型的 真实延迟(Latency)。
- 最后选择 精度高 + 延迟低 的模型,而不是单一优化。
3、MnasNet 的网络结构
传统 NAS(神经网络搜索)就像 在整个工厂里,每一台机器都要重新挑选(卷积方式、卷积核大小、是否加注意力...)。
👉 问题:搜索空间巨大,计算成本爆炸。
🚀 MnasNet 的新思路:分解层次搜索
MnasNet 说:别傻傻地在每个小零件上都重新选,我们 按车间(Block)来分工,让搜索更聪明!
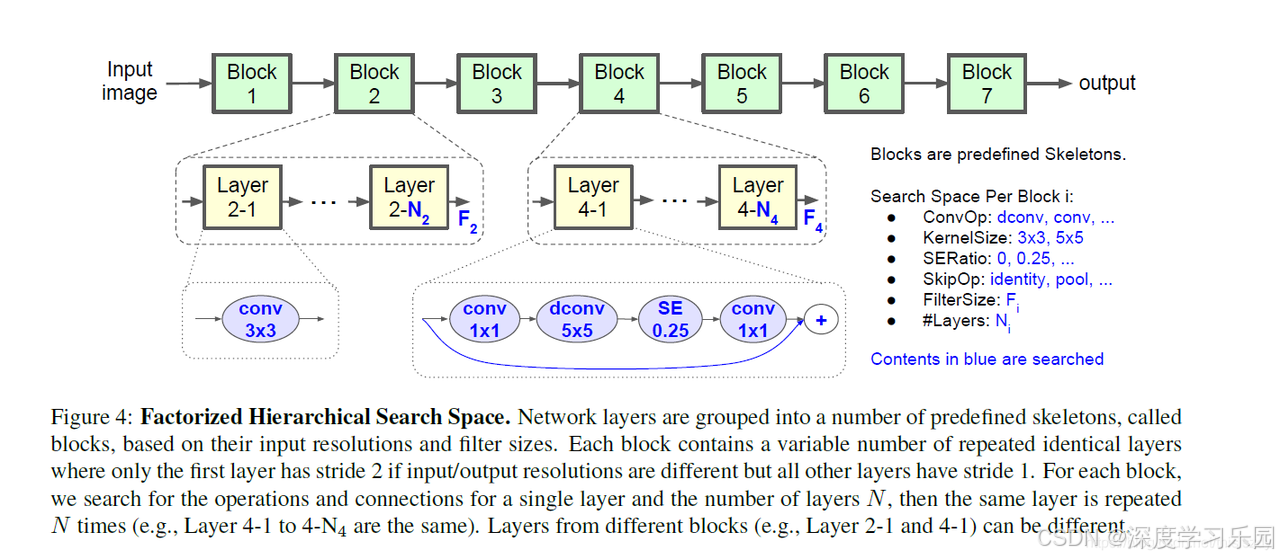
🏭 工厂类比讲解
- 整个网络是一家工厂
工厂一共有 7 个"车间"(Block1 ~ Block7)。
- 早期车间处理的是大尺寸原料(高分辨率图片)。
- 后期车间处理的是精细零件(小分辨率但通道多)。
- 每个车间里有多台一样的机器(Layers)
- 比如 Block4 有 4 台机器(Layer 4-1 ... Layer 4-4)。
- 这些机器都是同一型号,这样整个车间的风格统一,也让搜索问题更简单。
- 如果需要缩小尺寸(stride=2),就让车间里的第一台机器负责"压缩尺寸"。
- 搜索任务:给每个车间选一种机器型号
对于某个车间(比如 Block4),我们要决定:
- 用什么类型的机器?(普通卷积 or 深度卷积 or 倒残差 MBConv)
- 零件刀片多大?(3×3 还是 5×5 卷积核)
- 要不要加个"质检员"?(SE 注意力模块)
- 是否需要旁边开一条捷径?(跳跃连接 identity/pooling)
- 每台机器能处理多少原料?(通道数)
- 这个车间要放几台机器?(重复次数 N)
- 块内同构、块间异构
- 块内同构:一个车间内机器全都一样 → 好管理,减少搜索空间。
- 块间异构:不同车间可以选不同型号机器 → 早期车间选小卷积,后期车间选大卷积,更灵活。
🧩 图里的意思
- 图上绿色方块(Block1~7)就是车间。
- 黄色小方块(Layer 2-1 ... Layer 2-N₂)表示同一车间里重复的机器。
- 蓝色箭头上的选项(ConvOp、KernelSize、SE Ratio、SkipOp、FilterSize、#Layers)就是我们给工厂配机器时的菜单。
- 底部小蓝框示例(1×1 conv → 5×5 depthwise → SE → 1×1 conv → 残差)就是某个车间最终选中的机器型号。
MnasNet 的"分解层次搜索"就像是:
👉 不再在工厂里的 每一台机器上瞎选,而是 先把工厂划分成车间,再给每个车间统一选好机器型号和数量。 - 块内机器相同 → 节省精力(缩小搜索空间)。
- 不同车间机器可不同 → 保证灵活性(不同阶段处理不同任务)。
🔄 整体流程
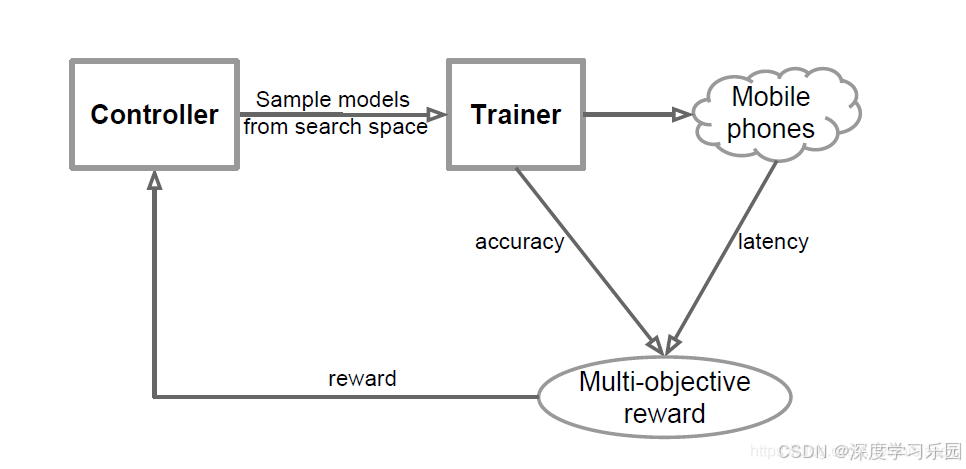
- Controller(控制器) → 经理
- 它的任务就是 从搜索空间里挑选一份候选模型。
- 搜索空间就像"人才市场",有各种可能的神经网络结构(不同卷积、核大小、层数等)。
- Controller 会"抽签"一样,采样出一个模型交给 Trainer。
- Trainer(训练器) → 培训班老师
- 它接收 Controller 提供的候选模型,把它放到数据集上做训练,看看效果。
- 训练后会测试两个关键指标:
- accuracy(准确率):模型识别的对不对。
- latency(延迟):模型在 真实手机上跑的速度。
- Mobile phones(手机硬件) → 真机考核
- MnasNet 强调 平台感知,所以不是只在电脑上测,而是直接把模型丢到手机里,测真实延迟。
- 这样能避免模型"纸面上很快,但手机上很慢"的问题。
- Multi-objective reward(多目标奖励) → 综合打分系统
- 这里就像考核工人的总分,不仅看工作质量(准确率),还要看效率(延迟)。
- 如果模型又准又快 → 奖励高。
- 如果模型虽然准,但很慢 → 奖励低。
- 如果模型快,但不准 → 奖励也低。
- Reward 回传给 Controller(奖惩反馈) → 经理学习
- Controller 根据奖励结果来调整"挑人策略"。
- 就像经理从经验中学会:
- "哦,原来在手机上用 5×5 卷积太慢了,以后少挑。"
- "用 SE 模块虽然稍慢,但精度大幅提升,值得保留。"
- 经过不断循环,Controller 越来越会挑模型,最后找到一个"既准又快"的最佳结构。
这个搜索算法就像是: - Controller = 招聘经理:负责挑选候选人(模型结构)。
- Trainer = 培训老师:负责对候选人进行测试(训练+验证)。
- Mobile phone = 真机面试官:直接考察候选人在真实岗位(硬件)上的表现。
- Reward = 总分系统:把准确率和速度综合起来,打分反馈。
- 闭环学习:经理不断从反馈中学习,最终能招到"又能干又高效"的最佳员工(最终模型)。
4、 致命缺陷:搜索开销巨大,效率低
MnasNet 用的是 强化学习(RL)+真实手机延迟测试 的搜索方式。 - 每次 Controller 采样一个模型 → Trainer 要训练、评估精度 → 还要真机跑延迟 → 最后才能打分。
- 这个过程要 成千上万次循环,一次搜索往往需要 几百上千 GPU 天!
5、后续改进方向(怎么解决 MnasNet 的高开销问题)
1️⃣ ProxylessNAS(2019)
- 问题:MnasNet 每次都要真机测试延迟,太耗时。
- 改进:ProxylessNAS 提出了 直接在目标硬件上搜索,但是用了一种 延迟预测模型,不需要每次都跑真机。
- 好处:把搜索效率提升了一个量级,训练更快,硬件友好。
👉 打个比方:MnasNet 是每造一辆赛车都拉到赛道跑一圈;ProxylessNAS 则是先训练一个"赛道模拟器",能预测赛车的速度,这样大大节省时间。
2️⃣ FBNet(Facebook,2019)
- 问题:MnasNet 训练每个候选模型太慢。
- 改进:FBNet 提出 可微分 NAS(Differentiable NAS),直接把搜索问题变成一个 梯度优化问题。
- 核心思想:候选模型不再一个个训练,而是共享参数(weight sharing),用梯度下降来一步到位找到最优结构。
- 好处:搜索效率从几百 GPU 天 → 1 GPU 天就能完成。
👉 打个比方:MnasNet 是"造一辆车就训练一辆车";FBNet 是"造一个车厂,把所有车的零件都放进去,让它们共享零件,只训练一次,就能挑出最好车"。
3️⃣ EfficientNet(Google,2019)
- 问题:MnasNet 搜到的结构是固定的,如果要换大小(比如大模型、小模型),得重新搜索。
- 改进:EfficientNet 提出了 复合缩放法(Compound Scaling),只用一个基础网络(通过类似 MnasNet 搜出来的),再用统一规则同时放大宽度、深度和分辨率。
- 好处:不用每次重新搜索,一次搜索 → 一家子模型(EfficientNet-B0 到 B7)。
👉 打个比方:MnasNet 是"每次都要重新设计车子";EfficientNet 是"设计一辆车的原型,然后通过放大缩小比例,就能得到不同排量的车型(小轿车 → SUV → 卡车)"。