1.前言
2025 年 9 月 24 日云栖大会,阿里巴巴正式开源新一代视觉理解模型 Qwen3-VL。随后在 2025 年 10 月 4 日同步发布了 Qwen3-VL-30B-A3B-Instruct 版本,下面是这个模型的特点。

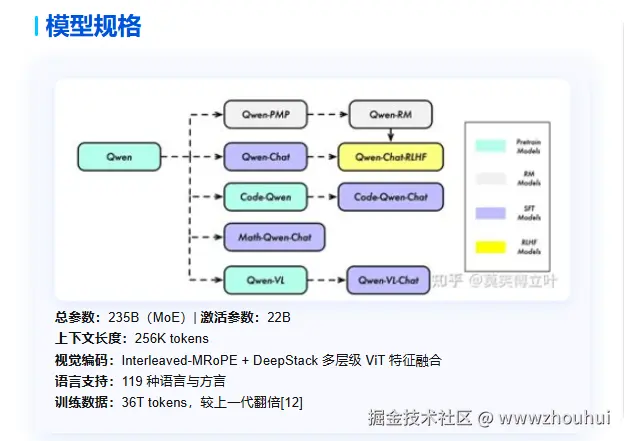
模型规格这块具有如下特点:
应用场景这块如下四个方向:

之前给大家介绍过关于Qwen3-VL的测评介绍。Qwen 3-VL 实测:从图片生代码到视频提字幕,这个多模态模型有多能打?
本期视频给大家做了一个dify工作流,通过该工作流和识别OCR文档识别功能,以及可以实现视频内容的分析和理解。
工作流截图如下:
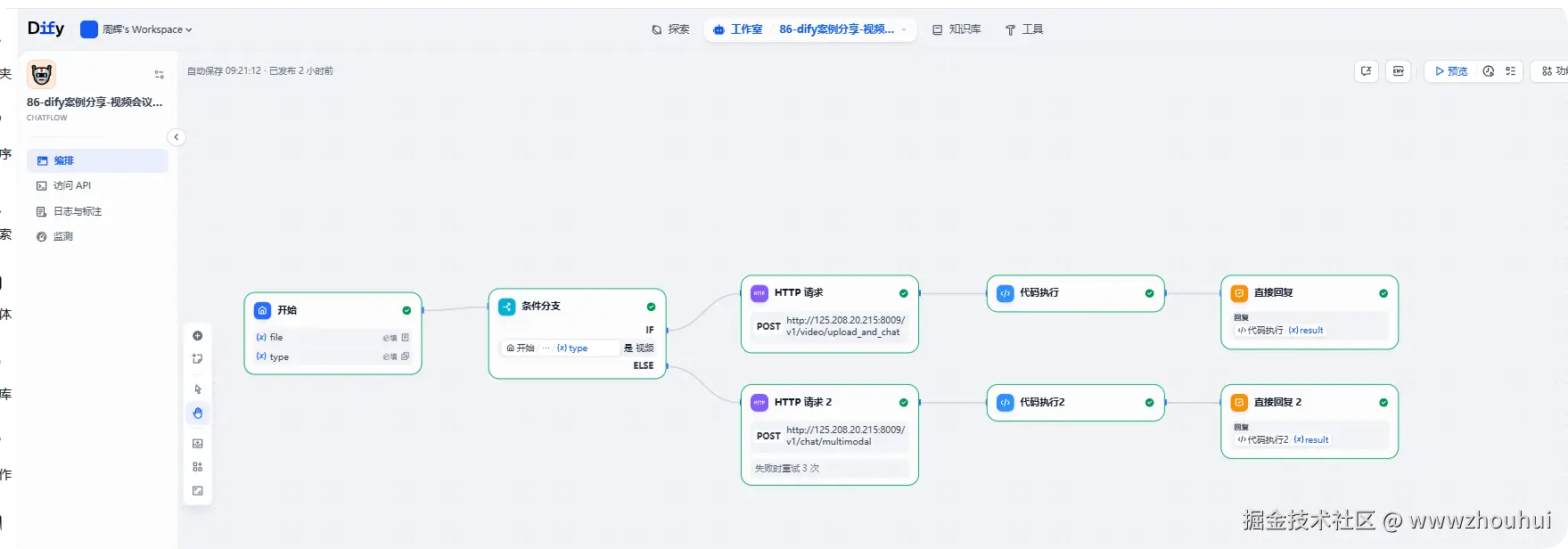
下面简单带大家使用dify工作流介绍一下OCR文档识别功能,以及可以实现视频内容的分析和理解功能介绍。
2.Qwen3-VL测评
OCR文档提取
刚好遇到放假,老师在群里面发了一堆图片、PDF文件等材料信息,我们就拿这个材料信息使用这个模型来识别。

上面是一个国庆节假期作业清单,我们使用这个dify工作流来识别一下。
提示词
shell
请帮我识别这个照片里面的信息,100%识别并输出,只需要提取信息,其他信息不需要。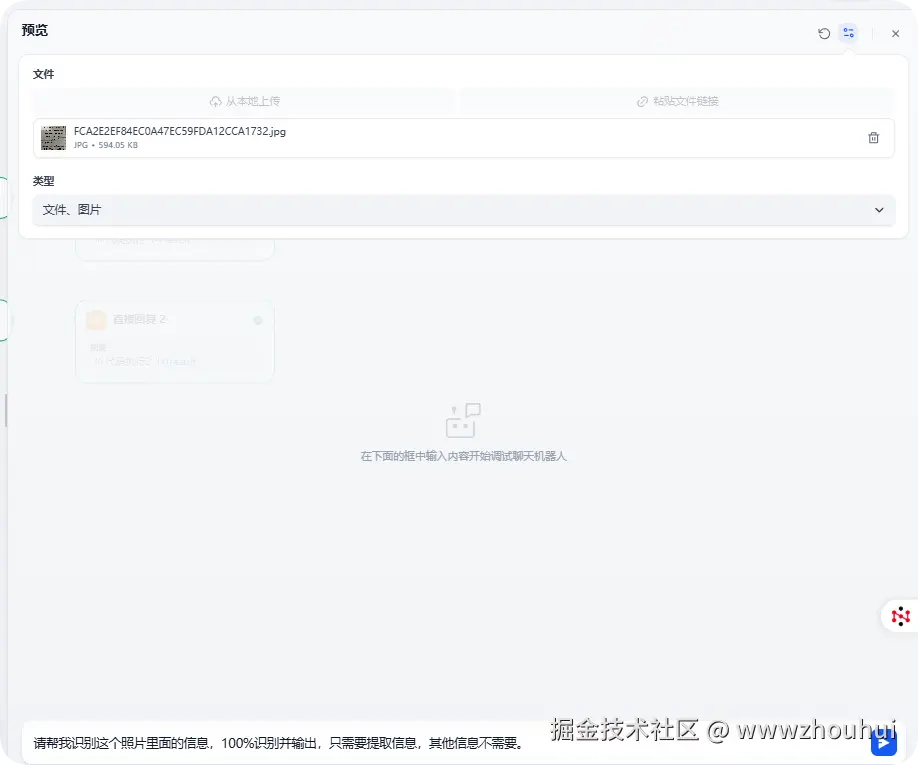
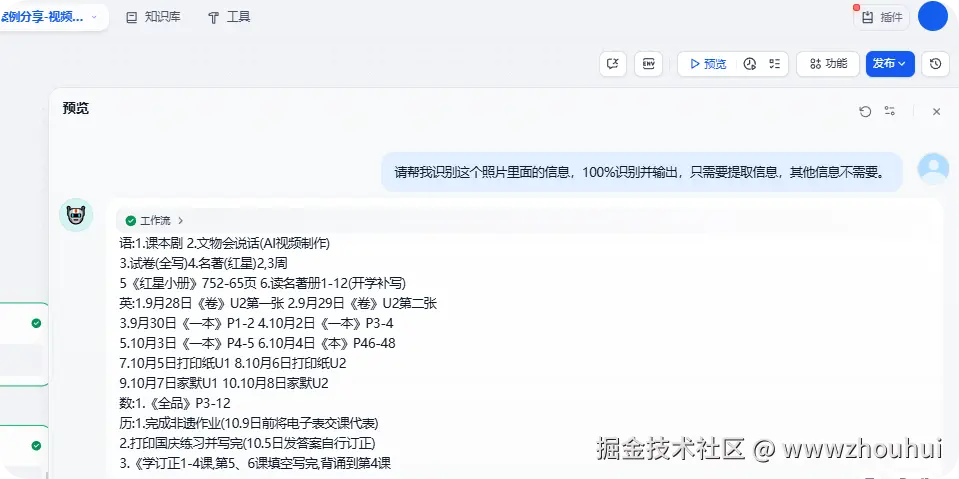
OK 这样一个手抄作业本就通过简单OCR识别提取出来了。方便我们打印(去除手写部分信息)
发票提取
接下来我们在找一张发票,让它提取发票票面信息。
原发票票面信息

我的提示词
shell
请提取这张照片的内容,其中内容格式'机器编号'、'发票代码'、'发票号码'、'开票日期'、'校 验 码'、'购买方名称'、'购买方纳税人识别号'、'购买方地 址、电 话'、'开户行及账号'、'货物或应税劳务、服务名称'、'规格型号'、'单 位'、'数 量'、'单 价'、'金 额'、'税率'、'税 额'、'价税合计(大写)'、'价税合计(小写)'、'销售方名称'、'销售方纳税人识别号'、'销售方地 址、电 话'、'销售方地 址、电 话'、'开户行及账号'、'备注'、'收款人'、'复核'、'开票人' 字段返回信息,返回的结果信息以json格式返回dify返回信息
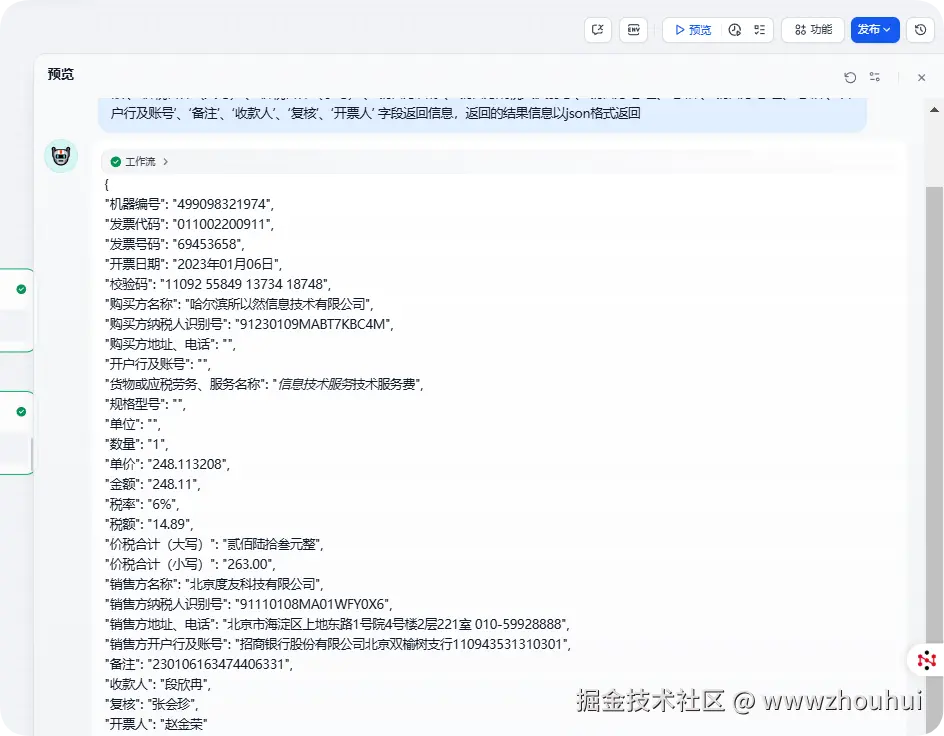
也是非常轻松的100%识别发票的票面信息。我记得去年使用qwen2.5-vl-72b多模态模型这个发票还不能做到100%的识别。
视频提取
接下来我们上传一个视频,让它识别出视频的内容。这个我们在平时会用到,比如上传一个音视频笔记,让他总结一下音视频里面的内容,这样我们就可以节约很多时间了。只需要了解视频的精华部分的信息即可。大大提供我们学习和工作的效率。

我这里给它上传一个我1月份做的一个AI生成的短视频,让它识别里面的内容。
提示词如下:
请帮我识别视频里面有什么内容?
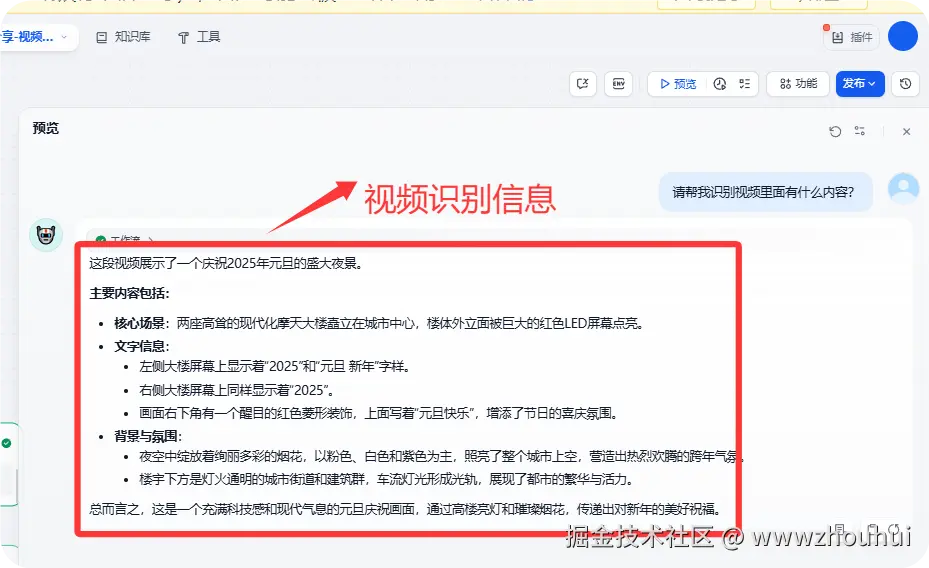
视频提取字幕
接下来我们上传一个视频需要提取这个视频里面的字幕信息,这个也是非常实用的。在短视频制作这块我们有时候需要别人的视频字幕,但是原始字幕文件srt没有,这个时候我们就可以借助qwen3-vl 多模态模型来提取视频里面字幕文件。
视频信息
提示词如下:
请提取视频里面的字幕文件,将字幕文件输出带有时间戳格式的srt格式文件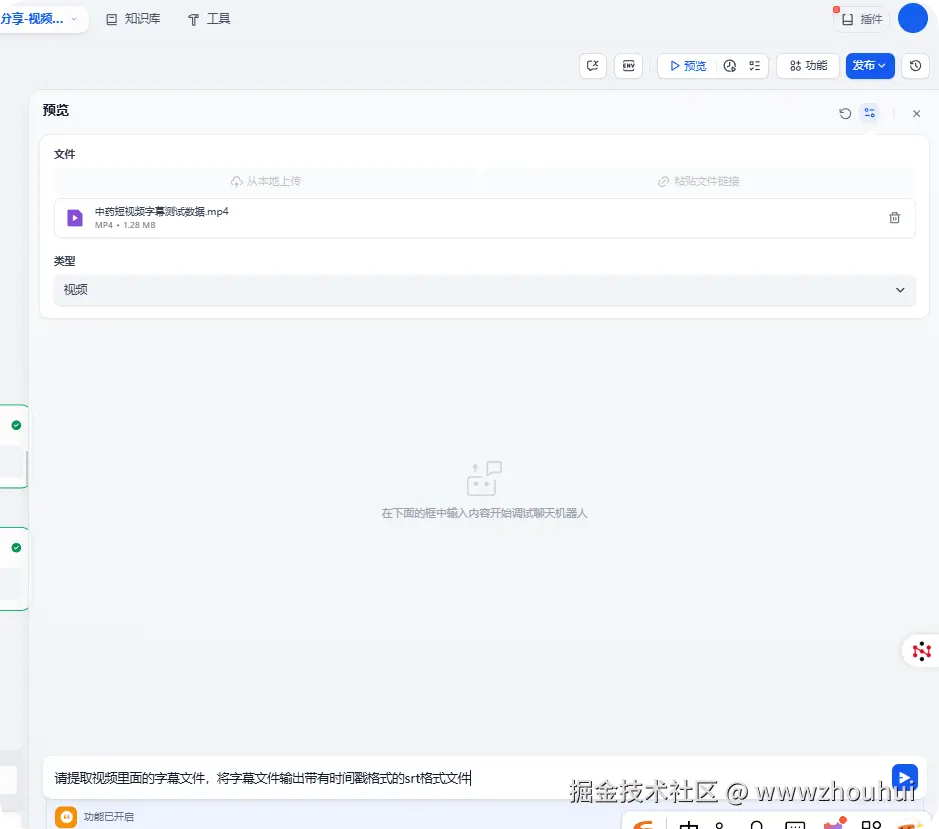
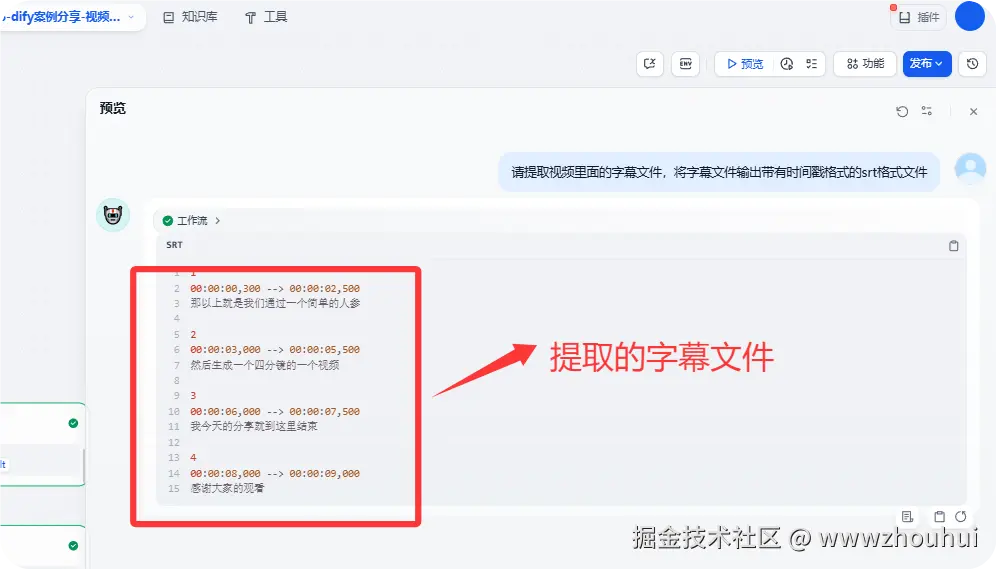
上面显示提取了带有时间戳格式的srt格式文件,当然后面如果想把这个字幕文件直接保存srt格式文件 也是可以的可以借助第三方工具在把文本内容转成.txt格式文件提供下载(感兴趣的小伙伴可以在我上面提供工作流上扩展)
3 工作流制作
那么这个工作流是如何制作的呢?下面给大家介绍这个工作流是如何制作的。
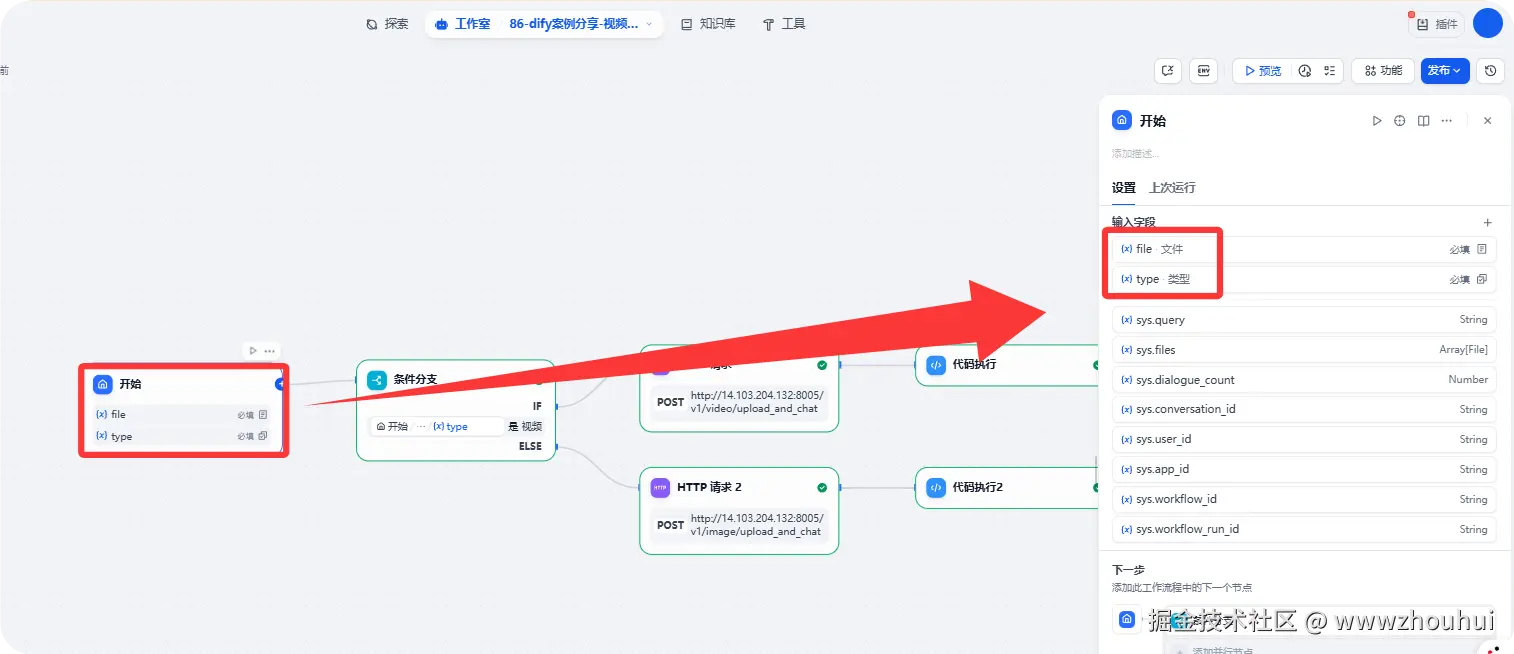
开始
开始节点中我们设置2个参数,一个是file 文件。1个是type 类型。
其中文件配置信息如下:
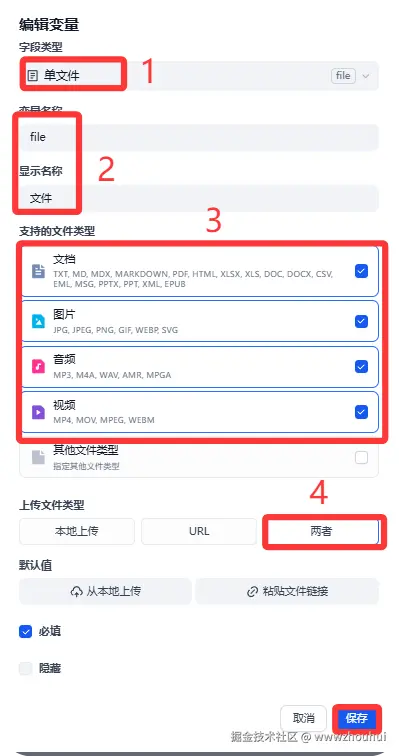
另外的type类型我们这里设置下拉选项1个支持 文件、图片 2 视频
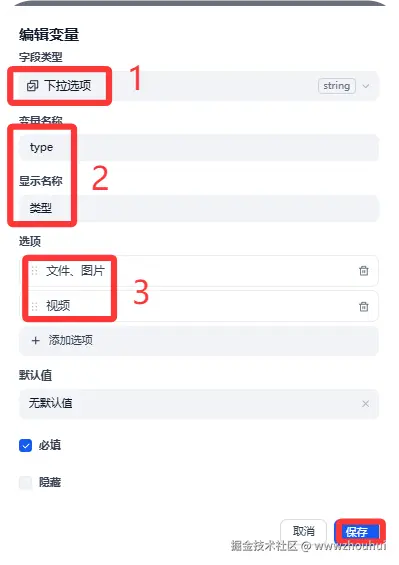
条件分支
这个条件分支主要是通过用户输入的文件类型调用不同的接口。
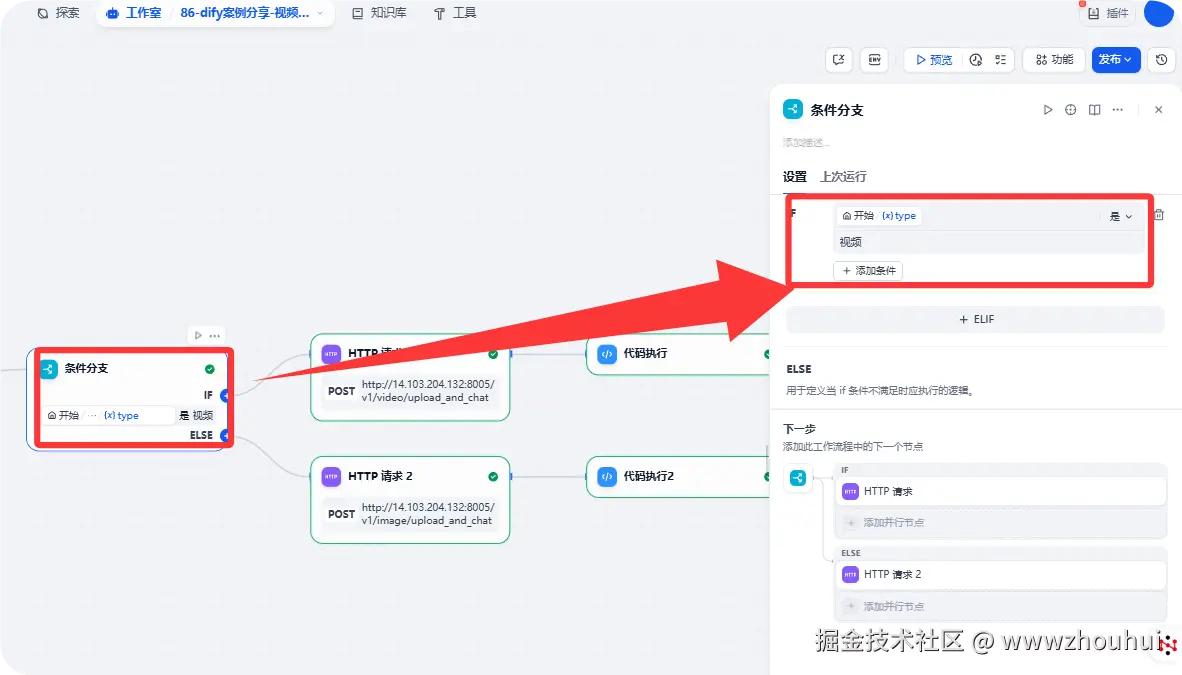
因为这条件就是2个 视频和文件,所以视频type 我们设置视频。这样选择视频的就走上面的接口。剩下走下面的接口。
http请求
这个 http请求有2个其中区别在于接口请求地址和参数的不同。
视频接口请求地址http://14.103.204.132:8005/v1/video/upload_and_chat
文件接口请求地址http://14.103.204.132:8005/v1/image/upload_and_chat
其中我们服务端接口做了一个鉴权,增加了一个密码校验。我们可以在env环境变量设置。
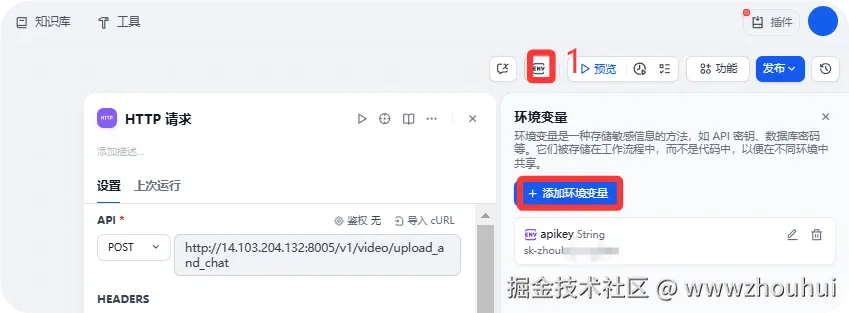
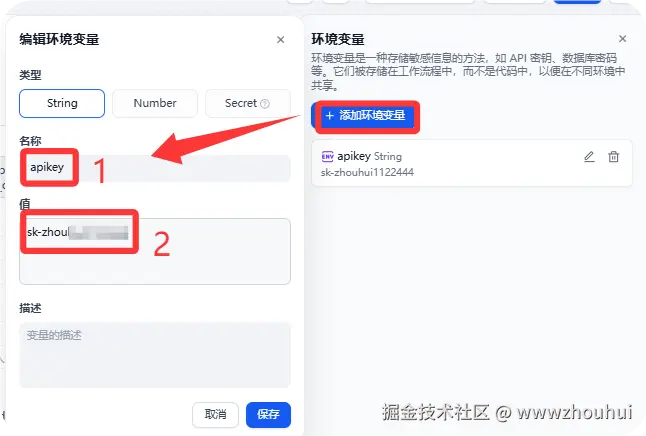
我们定义一个apikey 的参考,这里的值是我自定义的一个APIkey。这块服务端定义,关于这个值服务端后面会讲到。大家可以关注我下期文章,计划下篇文章讲到服务端代码部署和配置,这块我们会提到如何设置。
http请求配置截图如下:
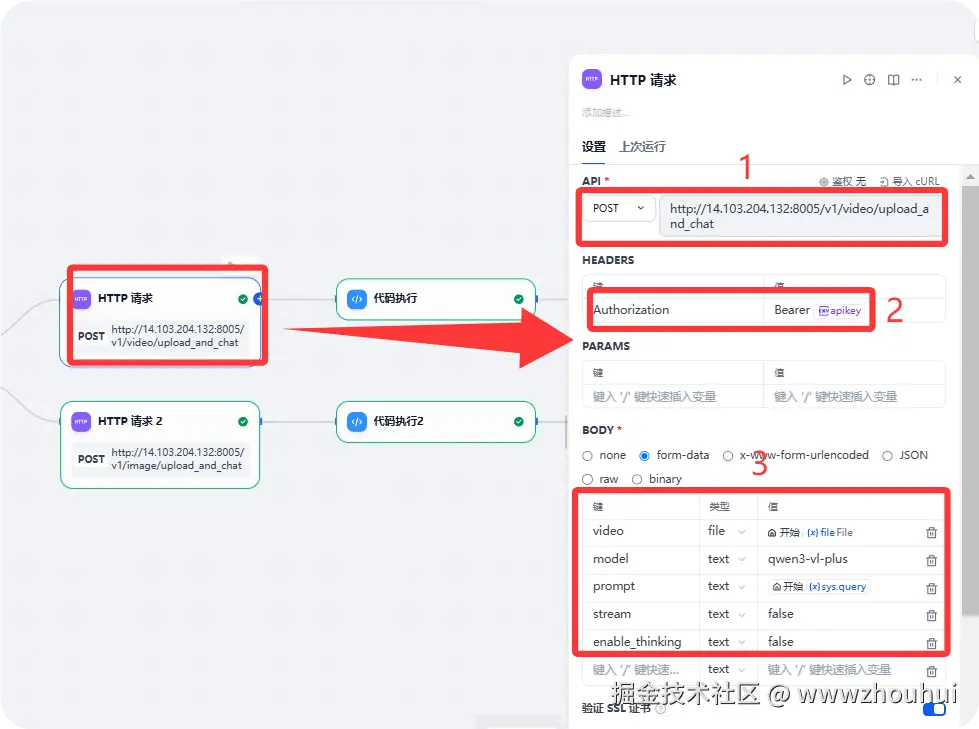
这里我们对body 请求这块做一下解释。请求body 有5个参数。
1.video 用户上传的视频文件。注意文件类型是file .
2.model 这个是接口请求的模型,这块我们用到多模态模型,所以值就写成qwen3-vl-plus
3.prompt 提示词,用户输入的提示词,我们这里用sys.query作为参数
4.stream 是否是流式输出。我们这里设置false
5.enable_thinking 是否思考模式输出。我们这里设置false
关于文件、图片http请求和上面的类似,我们贴一下不一样的地方。
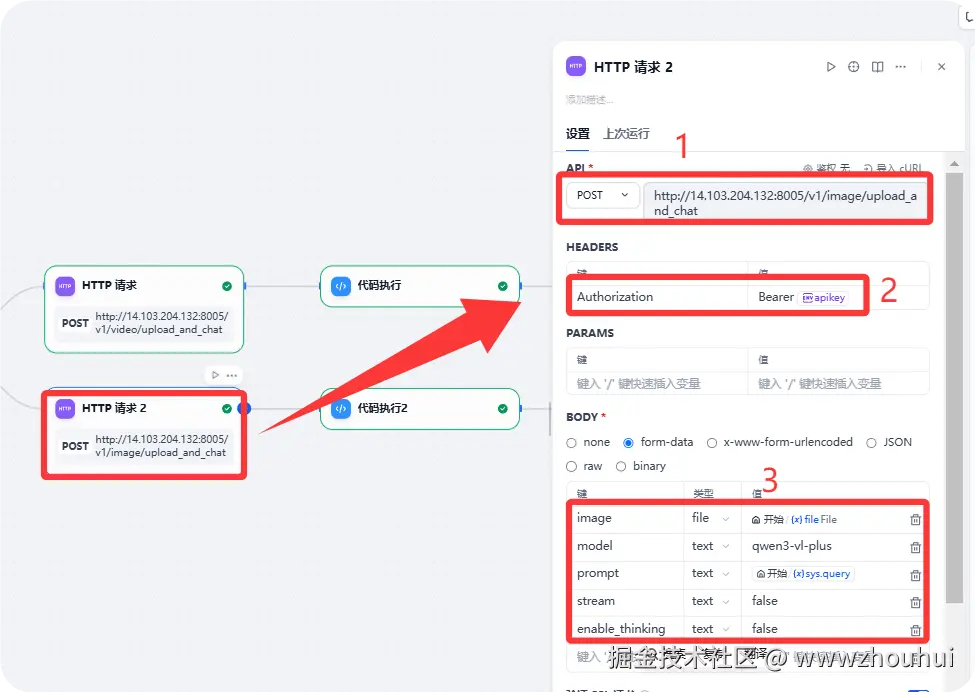
这里我们对body 请求这块做一下解释。请求body 有5个参数。(和上面的类似)
1.image用户上传的文件(支持图片、word 、txt、pdf等)。注意文件类型是file .
2.model 这个是接口请求的模型,这块我们用到多模态模型,所以值就写成qwen3-vl-plus
3.prompt 提示词,用户输入的提示词,我们这里用sys.query作为参数
4.stream 是否是流式输出。我们这里设置false
5.enable_thinking 是否思考模式输出。我们这里设置false
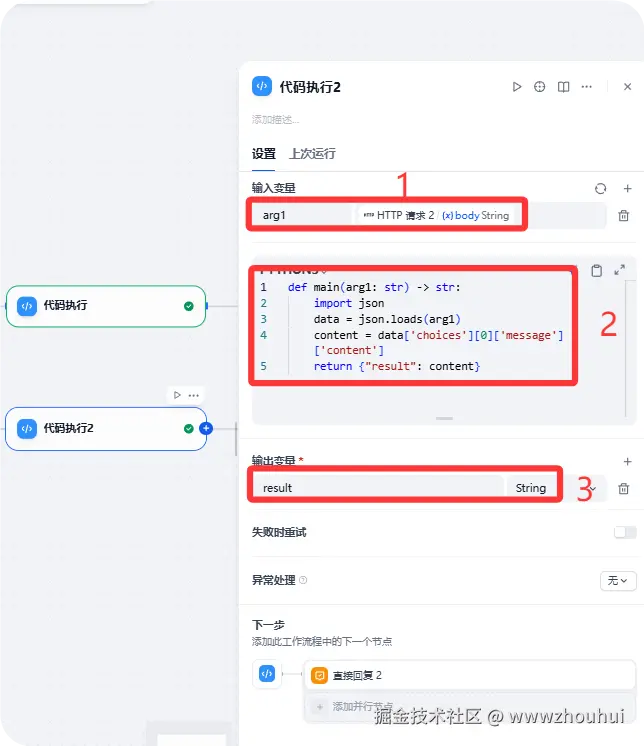
代码执行
这个代码执行主要的目的是http请求时候对返回的body response进行出来。请求参数arg1 ,值是body string
处理代码如下:
python
def main(arg1: str) -> str:
import json
data = json.loads(arg1)
content = data['choices'][0]['message']['content']
return {"result": content}代码处理返回输入变量result,返回值string
直接回复
这个直接回复就比较简单了,主要就是代理输出返回的result 输出。
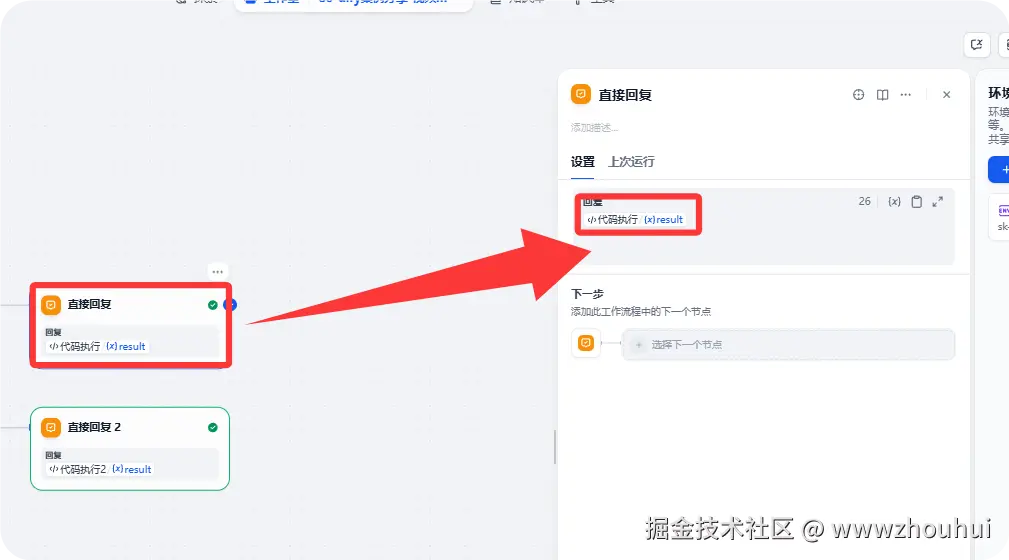
通过以上步骤我们就完成了dify 工作流的制作。
4.常见问题和体验地址
上面提到http请求是一个服务端接口,这个服务端接口只要是调用chat.qwen.ai 来实现的。由于时间关系今天就不详细介绍这块内容了。
由于使用到了视频上传,dify这里需要做一下设置。主要是http请求的超时时间和文件大小配置。目前搭建的服务器资源有限,对文件和视频超过10M以上的可能会出现超时返回错误的问题。大家可以找一个好的服务器或者本地部署这个服务。
超时问题可以在看开源项目github.com/wwwzhouhui/...
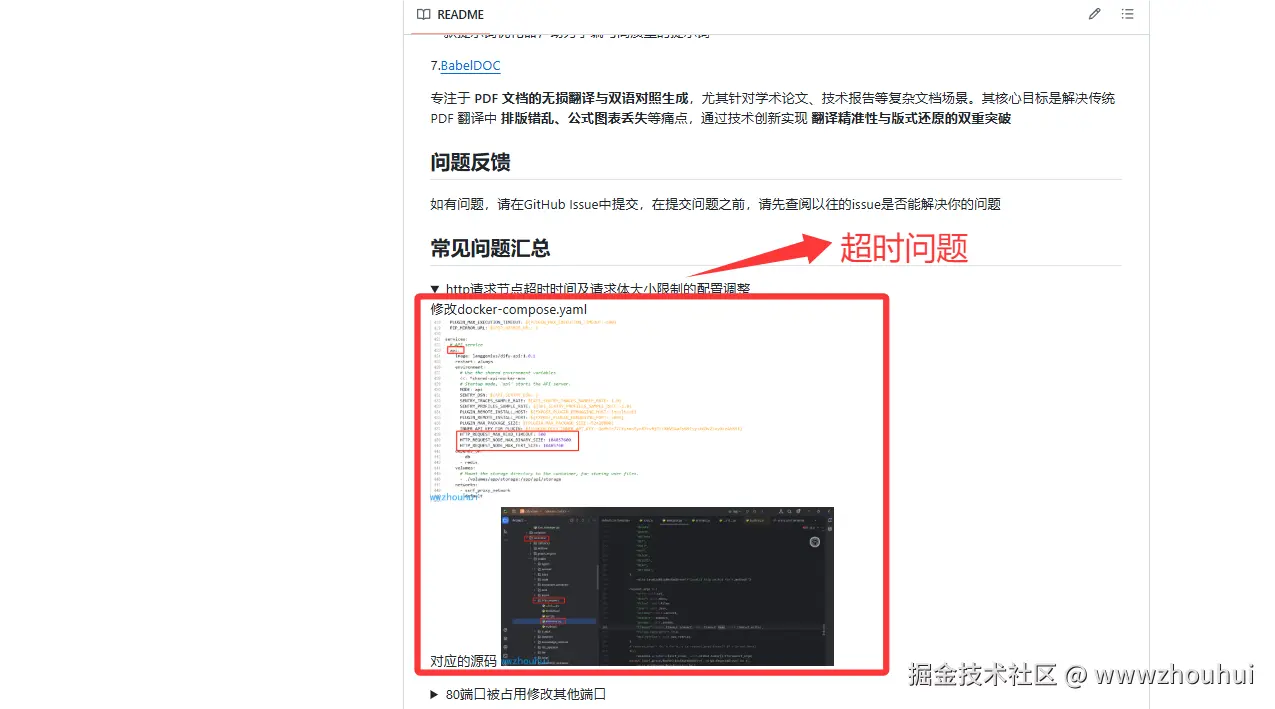
http请求节点超时时间及请求体大小限制的配置调整
修改docker-compose.yaml
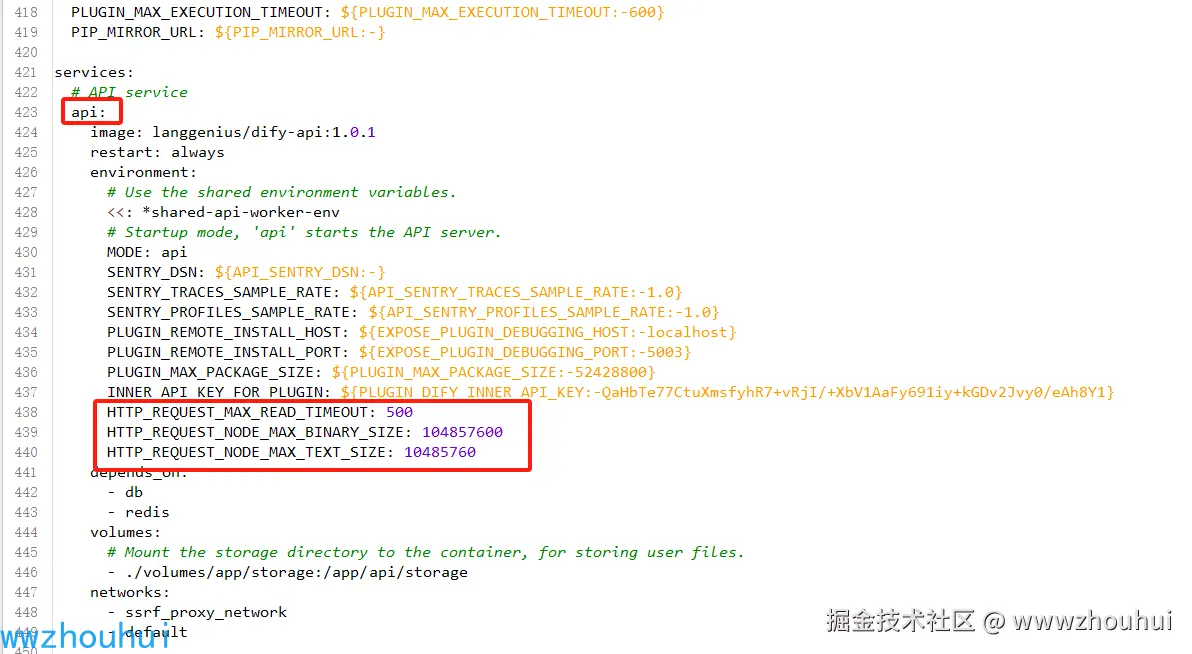
对应的源码
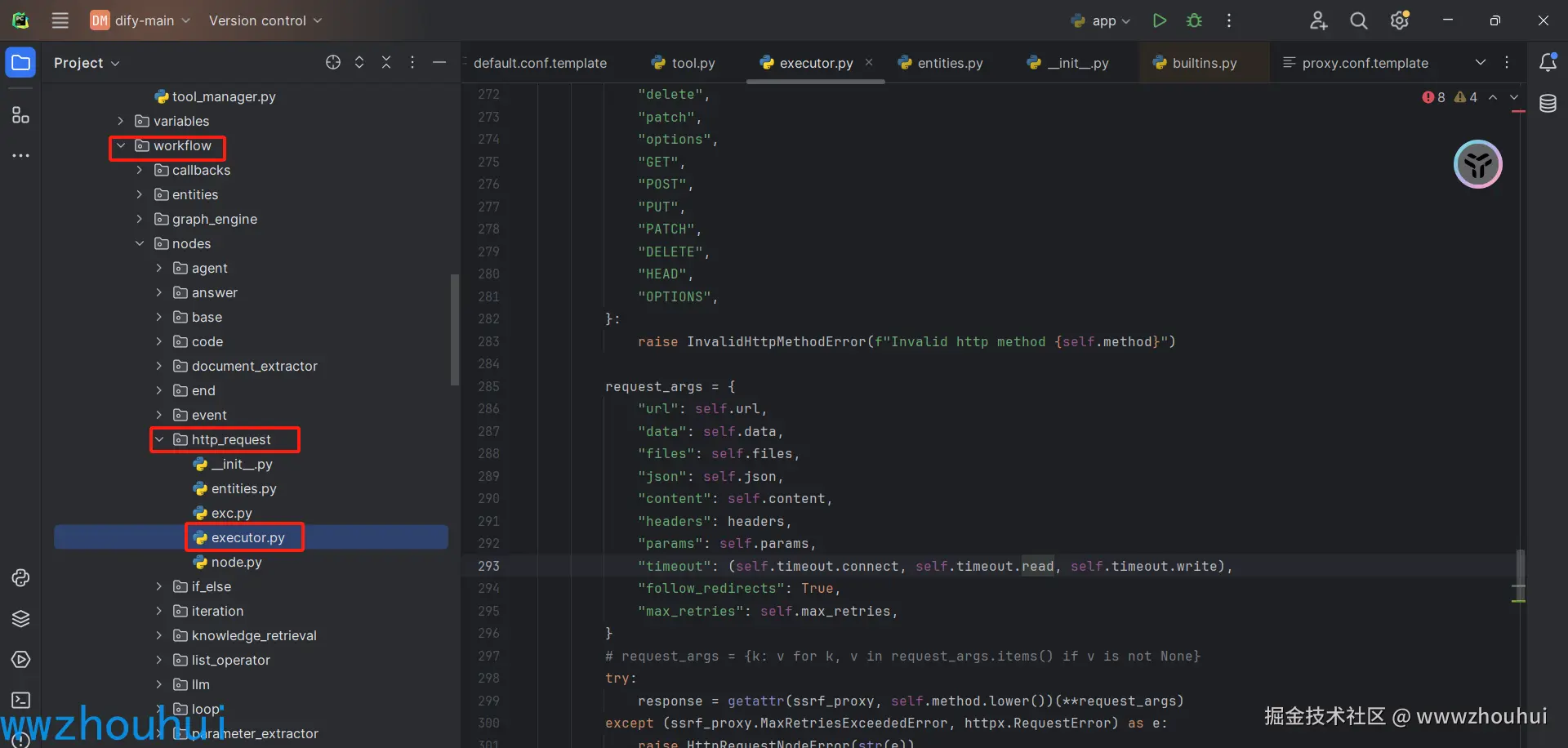
另外项目的体验地址
工作流地址:dify.duckcloud.fun/chat/YpsknR...
5.总结
今天主要带大家了解并实现了基于 Dify 工作流构建 Qwen3-VL 多模态处理工具的完整流程,该流程以阿里巴巴开源的 Qwen3-VL 模型为核心,结合 Dify 工作流的可视化编排优势与自定义服务端接口的支持,形成了一套从图片、文档到视频内容的识别与分析解决方案,涵盖 OCR 文档提取、发票信息识别、视频内容分析及字幕提取等实用功能。
感兴趣的小伙伴可以通过文中提供的 Dify 工作流体验地址直接试用,也可以参考工作流配置进行自定义扩展开发。今天的分享就到这里结束了,我们下一篇文章见。