主题:推理范式转移、智能体工程化与全球算力新格局
1. 绪论:从概率预测到逻辑推理的跨越
2025年,人工智能领域经历了一场深刻的范式转移,其震荡波及了技术架构、应用开发、商业模式乃至地缘政治格局。
- 2023年(寒武纪大爆发): 标志着生成式 AI 进入公众视野。
- 2024年(迷茫探索期): 充斥着对全能 AI 助手的过度承诺与失望。
- 2025年(落地元年): 被明确定义为**推理(Reasoning)与智能体(Agents)**真正落地的元年。
这一年的技术叙事不再仅仅围绕参数量的盲目扩张(Scaling Laws 的简单延续),而是转向了**推理算力(Inference Compute)**的深度挖掘与有效利用。OpenAI 的 o1 和 o3 系列、DeepSeek 的 R1 以及 Google 的 Gemini 3 共同确立了"慢思考"(System 2 Thinking)系统的核心价值。这种被称为 RLVR(Reinforcement Learning from Verifiable Rewards,基于可验证奖励的强化学习) 的技术路线,使得模型在回答问题前能够进行思维链(Chain of Thought, CoT)的自我博弈与验证,从而在根本上解决了数学、编码和复杂逻辑领域的诸多痛点,将 AI 从一个"概率性的文本生成器"升维为一个"具备逻辑验证能力的推理引擎"。
与此同时,全球 AI 产业的格局发生了剧变。长期以来的单极霸权------OpenAI 的绝对统治地位------在 2025 年被彻底打破。Google 凭借其深厚的工程底蕴、Gemini 3 的卓越性能以及独有的 TPU 基础设施强势回归;而以 DeepSeek、Qwen 为代表的中国开源模型在性能上追平甚至反超了西方顶尖闭源模型,彻底打破了"算力封锁"下的技术停滞迷思,确立了开源生态在全球 AI 版图中的关键地位。
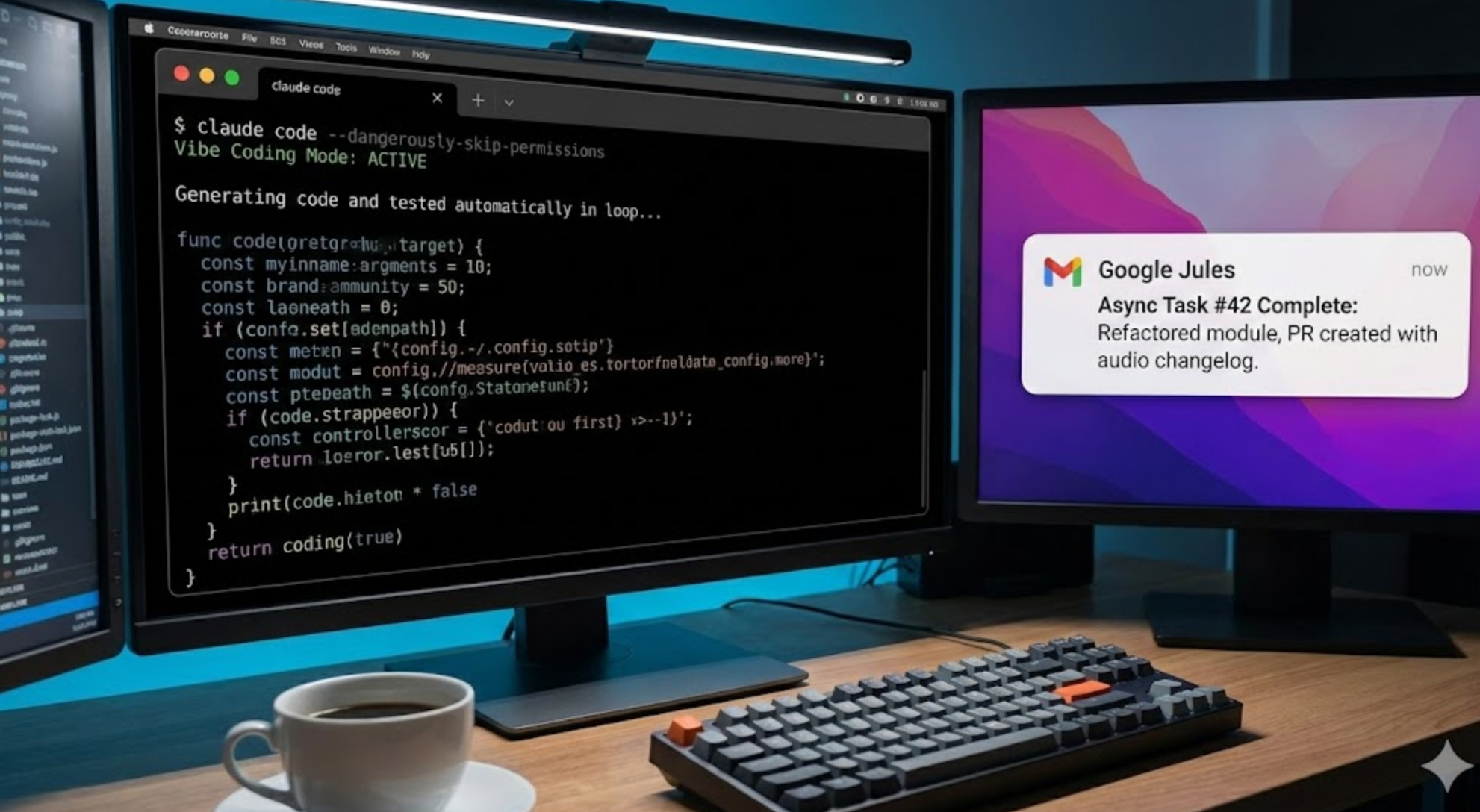
在应用层,虽然通用的"全能神级助手"(God-mode Agents)尚未实现,但专注于垂直领域的异步智能体(Asynchronous Agents)------尤其是编码智能体(Coding Agents)------取得了巨大的商业成功。Claude Code 和 Google Jules 的出现,重新定义了人机协作的编程模式,催生了**"Vibe Coding"(氛围编程)**这一全新的开发范式,使得软件工程从"编写代码"转向了"意图管理"。
然而,技术的指数级进步也伴随着新的系统性风险。Simon Willison 提出的**"致命三连"(The Lethal Trifecta)揭示了智能体安全架构中的深层漏洞; "Slopsquatting"(垃圾代码抢注)成为利用 AI 幻觉进行供应链攻击的新形态;而数据中心的能源消耗引发了全球范围内的环境反弹(Data Center Backlash)**,甚至导致了立法层面的暂停与限制,物理世界的资源约束首次成为制约数字智能扩张的硬边界。
本报告将基于 2025 年的技术进展,深入剖析上述领域的演变轨迹、底层技术原理及其对未来数字经济的深远影响。
2. 推理模型的崛起:RLVR 与测试时算力革命
2025 年最大的技术突破在于模型训练范式的根本性转移:从单纯追求更大的预训练语料库(Pre-training Scaling),转向利用强化学习(RL)来提升模型的推理能力,即**"推理扩展"(Inference Scaling)**。这一趋势的核心在于通过消耗更多的"思考时间"(Test-time Compute)来换取更高的输出质量。
2.1 RLVR:基于可验证奖励的强化学习机制
技术原理与核心机制
RLVR(Reinforcement Learning from Verifiable Rewards)已成为 2025 年高性能推理模型的核心驱动力。与传统的 RLHF 依赖人类标注员的主观打分不同,RLVR 利用客观、可自动验证的结果作为奖励信号,实现了模型能力的自我进化。
RLVR 的工作机制可以概括为以下几个关键环节:
- 客观奖励信号的构建: 在数学证明、代码生成、逻辑谜题等领域,利用答案的二元性(True/False)或程序化验证结果。例如,代码通过所有单元测试即获得正奖励(+1)。这种信号的客观性消除了人类反馈中的噪声和偏见。
- 自我博弈与策略优化(Self-Play & Policy Optimization): 通过 PPO 或 GRPO 等算法,模型在训练过程中不断生成解题路径。模型不仅学习"标准答案",更在探索通往答案的"路径空间"。这种机制允许模型在数以亿计的试错中涌现出人类未曾明确教导的高级策略。
- 思维链(Chain of Thought)的自发涌现: 在 RLVR 的强验证压力下,模型自发演化出了将复杂问题拆解为子步骤、进行自我纠错(Self-Correction)、回溯尝试(Backtracking)等策略。这种行为模式与人类的"慢思考"(System 2)过程高度相似。
从封闭域到开放域的挑战与突破
早期的 RLVR 主要局限于具有"基本真理"的领域(如数学和代码)。2025 年的前沿研究(如 Qwen-30B-A3B)开始致力于打破这一局限,通过引入基于规则的评分标准(Rubrics)将推理能力扩展到创意写作、人文社科等开放式任务。此外,RLPR 等无验证器框架也在尝试利用模型自身对参考答案的令牌概率作为奖励信号。
2.2 主流推理模型架构深度解析
2025 年的模型竞技场中,几大巨头通过不同的技术路径实现了推理能力的跃升。
OpenAI o-series (o1, o3):推理时代的开创者
- 地位: 定义了"推理模型"赛道,随后推出 o3-mini 和 o4-mini 优化了延迟与成本。
- 性能: 在 MATH、Codeforces 等基准测试刷新纪录。o3 Pro 在复杂数学证明上的准确率达到 85%(传统模型为 65%)。
- 时间换智能: 引入显式的"思考时间",模型在后台进行长达数秒至数分钟的运算与自我验证。市场验证了用户愿意为高质量、无幻觉的答案等待。
DeepSeek R1 与 V3:混合架构与高效计算的巅峰
中国实验室 DeepSeek 在 2025 年表现亮眼,不仅性能追平 OpenAI,更在架构效率上实现了突破。
-
混合思考模式(Hybrid Reasoning Architecture):
-
动态路由: 根据 Token 级别线索(如
<think>标签)或查询复杂度,自动决定是否展开深度思维链。 -
效率最大化: 简单问题直接回答(System 1),复杂问题激活推理模块(System 2),大幅提高部署经济性。
-
FP8 训练与 MoE 架构优化:
-
FP8 预训练: 从训练阶段采用 8 位浮点数,结合 NVIDIA H100 原生加速,显存占用减少约 50%。
-
无辅助损失的负载均衡: 创新性去除辅助损失,引入偏差项(Bias Term)动态调整路由,在保证负载均衡的同时最大化模型性能。
-
多头潜在注意力(MLA): 通过低秩键值联合压缩,大幅减少 KV Cache 占用,支持 128K+ 上下文窗口。
Google Gemini 3:TPU 加速的多模态推理
- 原生多模态推理: Gemini 3 具备理解视频、音频和图像中复杂逻辑的能力,进入物理世界因果推理范畴(例如分析运动员姿势错误)。
- Flash 版本的性价比: 得益于独有的 TPU 基础设施,Flash 版本在极低延迟下提供了上一代 Pro 级别的推理能力,成为实时应用的首选。
2.3 "鹈鹕骑自行车":多模态推理的非官方图灵测试
2025 年出现了一个标志性的基准测试:"画一只骑自行车的鹈鹕的 SVG 代码"。
- 挑战本质: 要求模型生成 SVG 代码,在代码层面理解几何形状、坐标系统及物理合理性(如鹈鹕长喙的放置、车轮方程)。
- 基准意义: 能够正确生成此图像的模型(如 GPT-5.2 Codex, Gemini 3 Thinking),通常在通用智能和复杂逻辑任务上也表现出色。这成为了验证模型是否具备"世界模型"理解能力的试金石。
3. 智能体革命:从"魔法"回归"功能"的工程化落地
行业共识从"寻找通用的上帝模型"转向了"构建可靠的异步工作流"。
3.1 编码智能体(Coding Agents)的爆发与分化
编码智能体是 2025 年最先实现大规模商业落地的场景。
Claude Code:命令行中的结对程序员
Anthropic 推出的 Claude Code 是运行在 CLI 中的工具,年收入迅速突破 10 亿美元。
- 深度集成: 接管开发者终端,执行 Bash 命令、管理 Git、读取文件系统。
- 项目记忆(Project Memory): 通过
CLAUDE.md文件定义项目规范,实现"项目级长期记忆"。 - 交互模式:
- Default Mode: 每步操作需用户确认。
- Vibe Coding Mode: 开启
--dangerously-skip-permissions,全自动循环执行"修改->测试->修复",极大释放生产力但伴随风险。
Google Jules:云端异步开发的标杆
- 环境隔离: 任务在 Google Cloud 上的安全隔离虚拟机(VM)中运行,而非本地。
- 异步工作流: 后台并行处理任务,完成后提交包含详细变更说明甚至**音频变更日志(Audio Changelog)**的 PR。
- 安全性: 解决了"本地运行不可信代码"的隐患,沙箱机制防止污染本地环境。
3.2 异步智能体生活方式(Parallel Coding Agent Lifestyle)
Simon Willison 描述了开发者角色的根本转变:从"串行编写"转向"并行管理"。
- 任务分发: 每日向多个智能体下发具体编程任务。
- 并行执行: 智能体后台处理繁琐工作。
- 角色转变: 开发者成为"代码审查员"和"系统架构师",一人团队开发复杂系统成为可能。
3.3 Model Context Protocol (MCP):连接万物的标准
Anthropic 推出的 MCP 成为行业事实标准,解决了 AI 与本地数据/工具连接的瓶颈。
-
架构:
-
MCP Host(宿主): AI 应用程序(Claude Desktop, Cursor)。
-
MCP Client(客户端): 负责连接管理。
-
MCP Server(服务器): 数据源提供方,暴露数据(Resources)、动作(Tools)和提示模板(Prompts)。
-
战略意义: 解决了"N x M"集成难题,被视为未来 AI 操作系统的雏形。
4. 全球算力格局:中国开源与西方闭源的博弈
OpenAI 失去绝对领先优势,中国实验室在开源权重模型领域取得统治地位,Google 凭借基础设施复兴。
4.1 OpenAI 的"红色代码"(Code Red)与战略迷茫
- 恐慌性发布: GPT-5.1/5.2 被批评"更笨了"或"过度对齐",Sora 未能如期兑现。
- 战略失焦: 战线过长(消费者、企业、芯片、AGI),导致核心模型迭代放缓。
- 人才流失: 核心人才保留率降至 67%。
4.2 中国模型的崛起:开源生态的统治力
- DeepSeek: V3 和 R1 性能比肩顶尖闭源模型,且推理成本极低,成为全球开发者首选底座。
- Qwen (通义千问): Qwen-Coder 成为开源编程助手的默认模型。
- GLM-4.7: 通用对话质量在全球盲测中位列前茅。
- 战略突围: 通过开源策略打破西方技术封锁,成为全球 AI 基础设施的重要组成部分。
4.3 Google 的复兴:Gemini 3 与 TPU 护城河
- 全线压制: Gemini 3 系列覆盖全场景,Flash 版本在实时交互领域占据绝对优势。
- TPU 护城河: 自研 TPU v5/v6 集群摆脱了对 NVIDIA GPU 的依赖,以极低边际成本提供高性能推理,构建了强大的竞争壁垒。
5. 新安全范式:智能体时代的威胁图谱
5.1 致命三连(The Lethal Trifecta)
Simon Willison 定义了智能体系统的结构性风险,当以下三个条件同时满足时,系统处于极度危险中:
- 访问私有数据(Access to Private Data): 邮件、文档、数据库。
- 接触不可信内容(Exposure to Untrusted Content): 互联网网页、外部邮件。
- 对外通信能力(External Communication/Exfiltration): 发送邮件、HTTP 请求。
- 攻击后果: 攻击者利用**提示注入(Prompt Injection)**即可实施数据窃取。
- 防御困境: 最有效策略是双模型架构(Dual-LLM Architecture),即特权模型与隔离模型分离。
5.2 Slopsquatting:幻觉驱动的供应链攻击
- 机制: 攻击者分析 LLM 生成代码时的幻觉模式(臆造的包名),在包管理器抢注这些名称并上传恶意代码。
- 自动化感染: 开发者或智能体运行 AI 生成的代码时自动中招。
- 防御: 需要行为分析、沙箱安装及 AI 辅助的实时包名验证。
5.3 偏差的常态化(Normalization of Deviance)
开发者习惯在"YOLO 模式"下运行智能体,忽略安全警告,直至灾难发生。安全边界因心态麻木而荡然无存。
6. 软件工程的重构:Vibe Coding 与 Context Rot
6.1 Vibe Coding:凭感觉编程的兴起
- 定义: 开发者不再逐行阅读代码,而是通过自然语言描述意图,运行生成代码看"感觉"(Vibe),循环修复。
- 特征: 源代码变为"中间产物",人类在"意图层"操作。
- 争议: 极大提升原型开发效率,但可能堆积技术债务,制造难以维护的"Slop 代码"。
6.2 Context Rot:长上下文的隐形杀手
- 现象: 随着上下文长度增加,模型提取关键信息的准确率下降。
- 原理: 中间迷失(Lost in the Middle)与对干扰项的敏感。
- 应对: 重新引入上下文工程,包括上下文压缩(/compact)、分层检索和信息重排。
7. 基础设施与环境:物理世界的反击
7.1 数据中心遭到抵制(Data Center Backlash)
- 资源消耗: 单个数据中心日耗水数百万加仑;弗吉尼亚州数据中心消耗全州 26% 电力。
- 反弹: 社区抗议(NIMBY)阻碍项目建设;立法层面出现暂停呼吁(如伯尼·桑德斯),巨头扩建受阻。
7.2 200美元订阅制的常态化与精英化
- Pro Max 时代: 高级推理服务(o1, Gemini 3 Thinking)成本高昂,推动订阅费从 20 涨至 200。
- 数字鸿沟: 顶尖 AI 能力从"普惠技术"转变为"精英特权",加剧生产力分层。
8. 结论与展望:迈向 2026
2025 年,AI 从"技术奇迹"着陆为"生产力工具"。
- 技术: RLVR 证明"慢思考"优于"多读书"。
- 应用: 智能体落地,Vibe Coding 改变编程,MCP 统一连接。
- 格局: 中美双极竞争,开源繁荣。
- 挑战: 安全与物理资源成为最大瓶颈。
展望 2026:
- 推理模型的摩尔定律: 成本年降 10 倍,"慢思考"成为默认选项。
- OS 级别的智能体集成: MCP 演化为底层标准协议。
- 算力与能源深度绑定: 自建电厂或革命性算法效率突破(如 1-bit LLM)。
2025年,AI 失去了它的神秘光环,但获得了改变世界的真实重量。
表 1:2025年主流模型与智能体综合对比
| 类别 | 产品/模型 | 开发商 | 核心技术/架构 | 关键特性与优势 | 典型应用场景 |
|---|---|---|---|---|---|
| 推理模型 | o1 / o3 | OpenAI | RLVR, CoT 自我博弈 | 极高的逻辑准确率,支持长时间思考,但延迟较高 | 数学证明,复杂算法设计,科学研究 |
| R1 / V3 | DeepSeek | MoE, MLA, FP8 训练, 混合思考模式 | 开源权重,极致的推理成本(API价格极低),中文能力强 | 私有化部署,高频推理任务,成本敏感型应用 | |
| Gemini 3 | 原生多模态, TPU 优化 | 原生多模态推理(视频/音频理解),Flash 版本兼顾速度与智能 | 实时视频分析,语音助手,长文档多模态理解 | ||
| 编码智能体 | Claude Code | Anthropic | CLI 深度集成, Client-side Context | 接管终端,本地项目记忆 (CLAUDE.md),支持 Vibe Coding 模式 | 命令行重度用户,本地脚本开发,复杂重构 |
| Jules | Cloud VM, Server-side Context | 异步执行,环境隔离(安全沙箱),GitHub 深度集成,音频日志 | 团队协作开发,后台任务处理,遗留代码维护 | ||
| 开源模型 | Qwen-2.5 | Alibaba | Dense/MoE 多尺寸 | 强大的代码生成能力 (Qwen-Coder),多语言支持 | 编程助手底座,企业内部知识库 |
| GLM-4.7 | Zhipu AI | GLM 架构 | 优异的通用对话质量,社区盲测高分 | 通用聊天机器人,中文内容生成 |
(本报告基于2026年1月的视角,回顾总结了2025年的行业动态与技术进展)