做电商系统的同学,大概率都遇到过这样的窘境:随着业务增长,订单表数据量突破亿级,原本毫秒级的查询突然变成 "秒级加载",高峰期写入还会频繁超时,甚至备份一次数据要等 3 个小时 ------ 这时候,"分库分表" 就从 "可选优化" 变成了 "生存必需"。
今天这篇文章,我会结合真实电商订单场景,带你搞懂分库分表的核心逻辑:从 "为什么要做" 到 "具体怎么做",再到 "落地避坑",全程用案例说话,新手也能轻松理解。
一、先搞懂:为什么非要分库分表?
在讲技术之前,我们先明确一个前提:分库分表不是 "银弹",而是 "对症药"。只有当你的系统遇到以下问题时,才需要考虑它。
以电商订单系统为例:
- 数据量爆炸:日均 100 万订单,1 年下来订单表(order)数据量达到 3.6 亿条,远超 MySQL 单表最优阈值(通常建议单表≤5000 万条);
- 查询变慢:用户查 "近 3 个月订单" 时,SQL 扫描行数过亿,索引失效,原本 100ms 的查询变成 2 秒 +;
写入瓶颈:大促期间,单库每秒接收 2000 + 写入请求,IO 使用率飙升到 90%,频繁出现 "写入超时"; - 运维灾难:单表备份一次要 3 小时,万一数据库故障,恢复数据需要半天,业务根本扛不住。
这些问题的核心原因只有一个:单一数据库 / 表承载了超出其能力的压力。而分库分表的本质,就是通过 "拆分" 将压力分散到多个节点,就像把 "一袋 100 斤的米" 分成 10 袋 10 斤的,搬运起来自然更轻松。
二、分库分表到底是什么?先理清两个核心概念
很多人会把 "分库" 和 "分表" 混为一谈,其实它们是两个不同维度的拆分,通常需要结合使用。
- 分库(Database Sharding):拆数据库
把原本一个数据库实例,拆成多个独立的数据库实例。比如把 "订单库(db_order)" 拆成db_order_0、db_order_1、db_order_2、db_order_3四个实例,每个实例只存 25% 的订单数据。
作用:解决 "单库资源瓶颈",比如单库连接数上限、IO 带宽不足等问题。 - 分表(Table Sharding):拆数据表
把原本一个大表,拆成多个结构完全相同的小表。比如把order表按月份拆成order_202301、order_202302、...、order_202312,每个表只存 1 个月的订单。
作用:解决 "单表数据量过大" 的问题,提升查询和写入效率。 - 常见的两种拆分策略
拆分不是 "随便拆",需要根据业务场景选择策略。最常用的是以下两种:
(1)垂直拆分:按 "业务 / 字段" 拆
垂直拆分的核心是 "按功能划分",就像把公司按 "销售部、技术部、人事部" 拆分一样。
垂直分库 :按业务模块拆库。比如电商系统中,把 "用户模块(user、user_address)" 放到db_user库,"订单模块(order、order_item)" 放到db_order库,"商品模块(product)" 放到db_product库。
适用场景:业务模块边界清晰,不同模块访问频率差异大(比如订单库读写频繁,用户库读多写少)。
垂直分表 :按字段重要性拆表。比如user表中,把 "用户 ID、姓名、手机号"(高频访问)拆到user_base表,把 "用户简介、注册 IP"(低频访问)拆到user_extend表。
适用场景:单表字段过多(比如 100 + 字段),部分字段访问频率低。
(2)水平拆分:按 "数据行" 拆
水平拆分是解决 "大数据量" 最核心的策略,它把同一表中的数据行,按规则分散到多个子表中(子表结构完全相同)。
比如订单表按 "用户 ID 哈希" 拆分:user_id % 4 = 0的订单放到db_order_0,user_id % 4 = 1的放到db_order_1,以此类推。
常见的水平拆分规则(选对规则 = 成功一半):
| 规则类型 | 核心逻辑 | 适用场景 | 示例 |
|---|---|---|---|
| 哈希拆分 | 按分片键哈希值分配 | 需均匀分散数据,比如 "查某用户的所有订单" | user_id % 4 |
| 范围拆分 | 按分片键范围分配 | 需按范围查询,比如 "查近 3 个月订单" | 按create_time分月份 |
| 枚举拆分 | 按分片键固定值分配 | 分片键值少且固定,比如 "按地区分单" | 地区 = 北京、上海、广州 |
三、实战:电商订单系统分库分表落地方案
光说理论不够,我们结合电商订单场景,看一个完整的落地案例。
- 确定目标
单表数据量控制在 1000 万以内;
高频查询(如 "某用户的订单")耗时≤50ms;
支持水平扩展,后续用户增长时能快速加节点。 - 选择拆分策略
结合订单的核心查询场景("查某用户的订单""查某时间段订单"),我们采用 "水平分库 + 水平分表" 的组合方案:
第一步:水平分库(按user_id哈希)
分片键 :user_id(用户 ID)------ 因为 "查某用户的所有订单" 是高频场景,按user_id分库能确保同一用户的订单落在同一库,避免跨库查询;
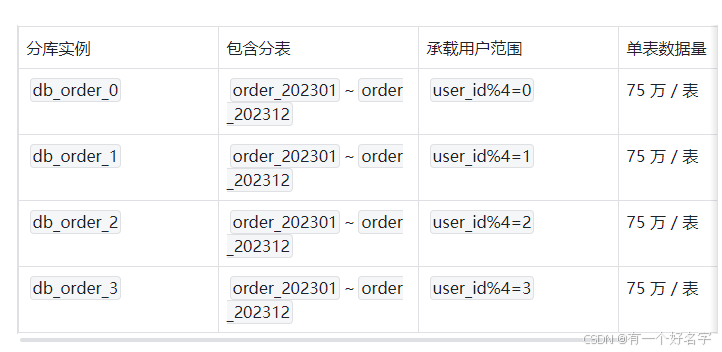
分库规则 :user_id % 4,拆成 4 个分库:db_order_0、db_order_1、db_order_2、db_order_3;
效果:每个分库只存 25% 的用户订单,单库日均写入从 100 万降至 25 万,IO 压力大幅降低。
第二步:水平分表(按create_time范围)
每个分库内的订单表仍有 9000 万数据(1 年),需要进一步分表:
分片键 :create_time(订单创建时间)------ 支持 "查某时间段订单";
分表规则 :按月份分表,表名格式order_yyyyMM(如order_202301存 1 月订单);
效果:每个分表数据量约 75 万(9000 万 / 12 个月),远低于 1000 万阈值,查询效率提升 10 倍以上。 - 最终架构
整个订单系统的存储结构如下(4 个分库,每个分库 12 个分表,共 48 个分表):
- 中间件选型:让分库分表 "无感知"
手动管理分库分表逻辑会非常复杂(比如写 SQL 时要判断往哪个分表插数据),这时候需要中间件来帮我们 "自动路由"。
推荐几个常用中间件:
- Sharding-JDBC:轻量级,嵌入在 Java 应用中,无需额外部署服务,支持 MySQL/Oracle,适合中小团队;
- MyCat:独立服务,支持多语言,功能全面,但需要单独维护,适合大型团队;
- OceanBase:阿里开源的分布式数据库,原生支持分库分表,高可用,但学习成本较高。
我们的订单系统用的是 Sharding-JDBC,只需在配置文件中定义分片规则,开发者写 SQL 时完全不用关心分库分表,中间件会自动完成路由。
四、避坑指南:分库分表最容易踩的 5 个坑
分库分表虽然能解决性能问题,但也会引入新的复杂度,这些坑一定要避开:
- 分片键选不对,一切都白费
这是最常见的坑!比如订单表按order_id哈希分库,而实际高频查询是 "查某用户的订单",就会导致同一用户的订单分散在多个分库,必须跨库查询,性能骤降。
建议:分片键必须是 "高频查询字段",比如订单表选user_id,商品表选category_id。 - 跨分片查询尽量少
比如 "查 2023 年 5 月所有金额> 1000 元的订单",需要遍历 4 个分库的order_202305表,再汇总结果,效率很低。
建议:
尽量避免跨分片查询,设计业务时优先按分片键查询;
必须跨分片的场景,用 "离线汇总表"(比如每天同步各分表数据到汇总表),避免实时跨库。 - 全局 ID 要唯一
每个分表的自增 ID 会重复(比如db_order_0.order_202301和db_order_1.order_202301都有id=1的订单),必须用全局 ID。
推荐方案:雪花算法(Snowflake),生成 64 位唯一 ID,包含时间戳、机器 ID,支持分布式环境。 - 分布式事务要谨慎
分库分表后,一个业务可能涉及多个分库(比如 "创建订单 + 扣减库存",订单在db_order,库存在db_product),会出现分布式事务问题。
建议:
优先用 "最终一致性" 方案(比如 MQ 异步补偿),比强一致性方案(TCC、SAGA)更简单;
能在一个分库内完成的业务,尽量不要跨库。 - 提前规划扩容
比如按user_id%4分库,后续用户量翻倍,需要从 4 个分库扩到 8 个,这时候要避免数据重分布的麻烦。
建议:
分片数用 2 的幂次(如 4、8、16),扩容时可以 "翻倍拆分"(比如 4 库扩 8 库,只需把每个库拆成 2 个,无需迁移所有数据);
时间分表提前创建,比如每年初创建全年的分表(order_202401~order_202412),避免业务运行中创建表导致的卡顿。
五、总结:分库分表的 "取舍之道"
最后,我想强调:分库分表不是 "越拆越好",而是 "适度拆分"。
能不分就不分:如果单表数据量≤1000 万,先优化索引、SQL、读写分离,分库分表是最后一步;
先分表再分库:单表数据量过大时,先水平分表,分表后仍有单库压力,再分库;
业务优先于技术:所有拆分规则都要围绕业务场景,不要为了 "技术炫酷" 而过度设计。
希望这篇文章能帮你搞懂分库分表,下次遇到大数据量瓶颈时,能从容应对。如果有具体场景想交流,欢迎在评论区留言!