金仓数据库(KingbaseES)作为一款靠谱的国产关系型数据库,在政府、金融这些领域应用广泛。接下来,我就详细跟大家说说怎么用Python搭建连接KingbaseES的API接口,把用户信息的CRUD(创建、查询、更新、删除)操作都实现了,帮咱们开发者快速上手金仓数据库的Python开发。
一、环境准备
开始之前,咱们得把需要的环境和依赖都准备好,具体有这些:
- 已经安装好的KingbaseES数据库(这篇文章里用的是默认端口54321)
- Python 3.6及以上版本的环境
- 几个必需的Python库:
- Flask:用来搭建API服务的工具
- psycopg2:连接金仓数据库的Python驱动
安装这些依赖库也很简单,直接在命令行里输入下面这行命令就行:
bash
pip install flask psycopg2-binary二、项目结构设计
咱们打算创建一个单独的Python文件,名字就叫KingbaseApi.py,这个文件里要包含以下几个核心功能:
- 数据库连接的配置信息
- 获取数据库连接的函数
- 初始化表结构的接口
- 操作用户信息的CRUD接口
- 启动这个应用的入口
三、完整代码实现与详解
3.1 导入必要的库
python
from flask import Flask, jsonify, request
import psycopg2
import psycopg2.extras as extras这里导入的几个库,各自有不同的用处:
Flask:主要用来创建Web应用和API接口psycopg2:作为连接金仓数据库的Python驱动,负责数据库的连接和各种操作psycopg2.extras:能提供一些额外的游标类型,比如DictCursor,用它能直接返回字典类型的查询结果,后续处理数据会方便很多
3.2 初始化Flask应用和数据库配置
python
app = Flask(__name__)
DB_CFG = dict(
host="127.0.0.1",
port=54321, # 金仓默认常见端口
dbname="TEST",
user="system",
password="jcsjk520.",
connect_timeout=5,
)这部分代码主要做了两件事:
- 初始化一个Flask应用实例,后面的API接口都要基于这个实例来创建
- 定义一个叫
DB_CFG的字典,里面存的都是数据库连接的配置信息,像数据库的地址、端口、数据库名、用户名、密码这些,后面连接数据库的时候直接用就行
3.3 数据库连接函数
python
def get_conn():
return psycopg2.connect(**DB_CFG)咱们把获取数据库连接的功能封装成了一个函数,叫get_conn。用的时候,直接调用这个函数,它会把DB_CFG字典里的参数解包,传给psycopg2.connect()方法,然后返回一个数据库连接。这样后面每次需要连接数据库,不用重复写一堆配置代码,省事多了。
3.4 表结构初始化接口
python
@app.route('/user/schema', methods=['POST'])
def init_schema():
sql = """
create table if not exists t_user(
id serial primary key,
name varchar(64) not null,
balance numeric(12,2) default 0,
created_at timestamp default current_timestamp
);
"""
with get_conn() as conn, conn.cursor() as cur:
cur.execute(sql)
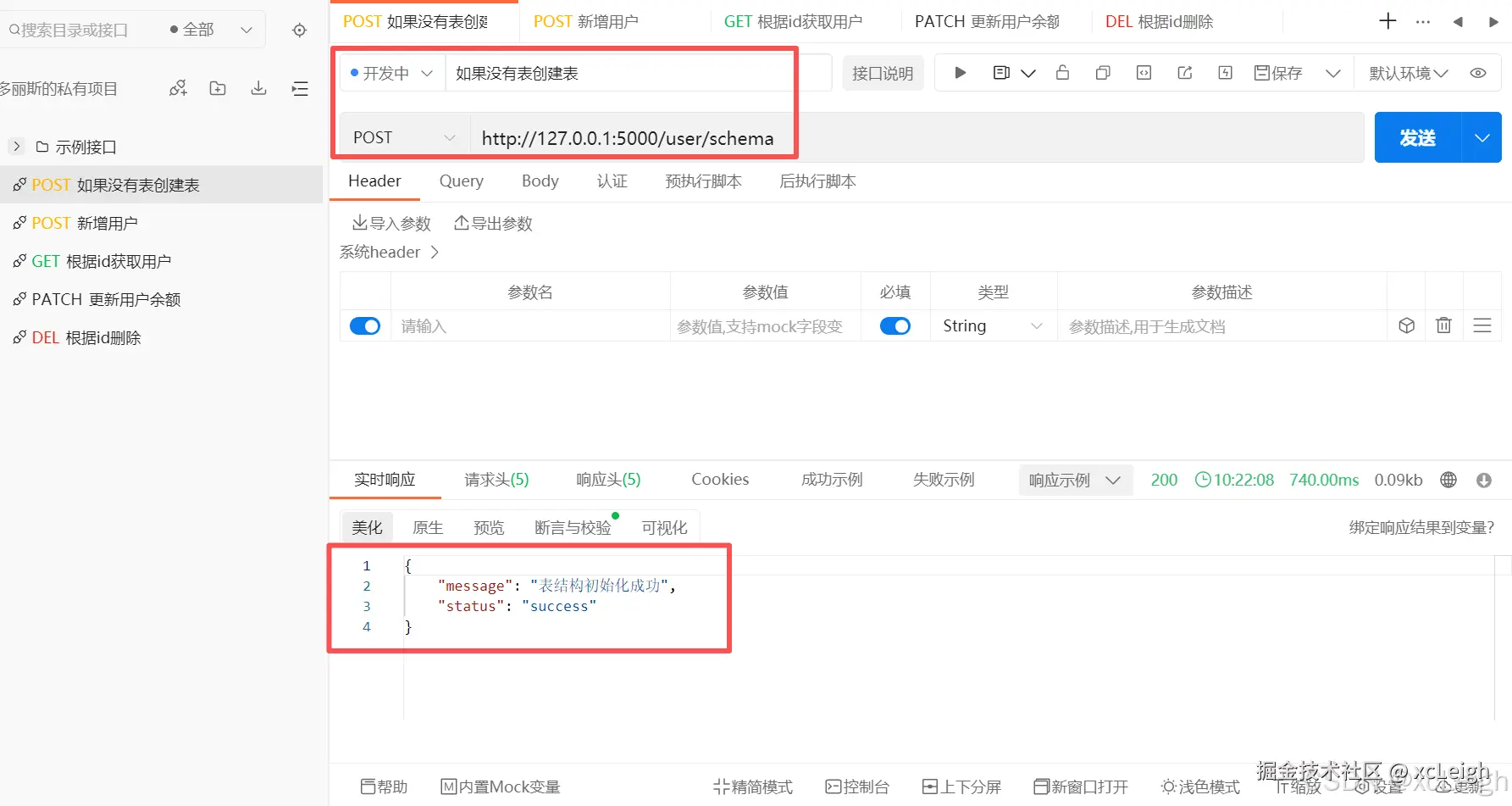
return jsonify({'status': 'success', 'message': '表结构初始化成功'}), 200接口调用效果:
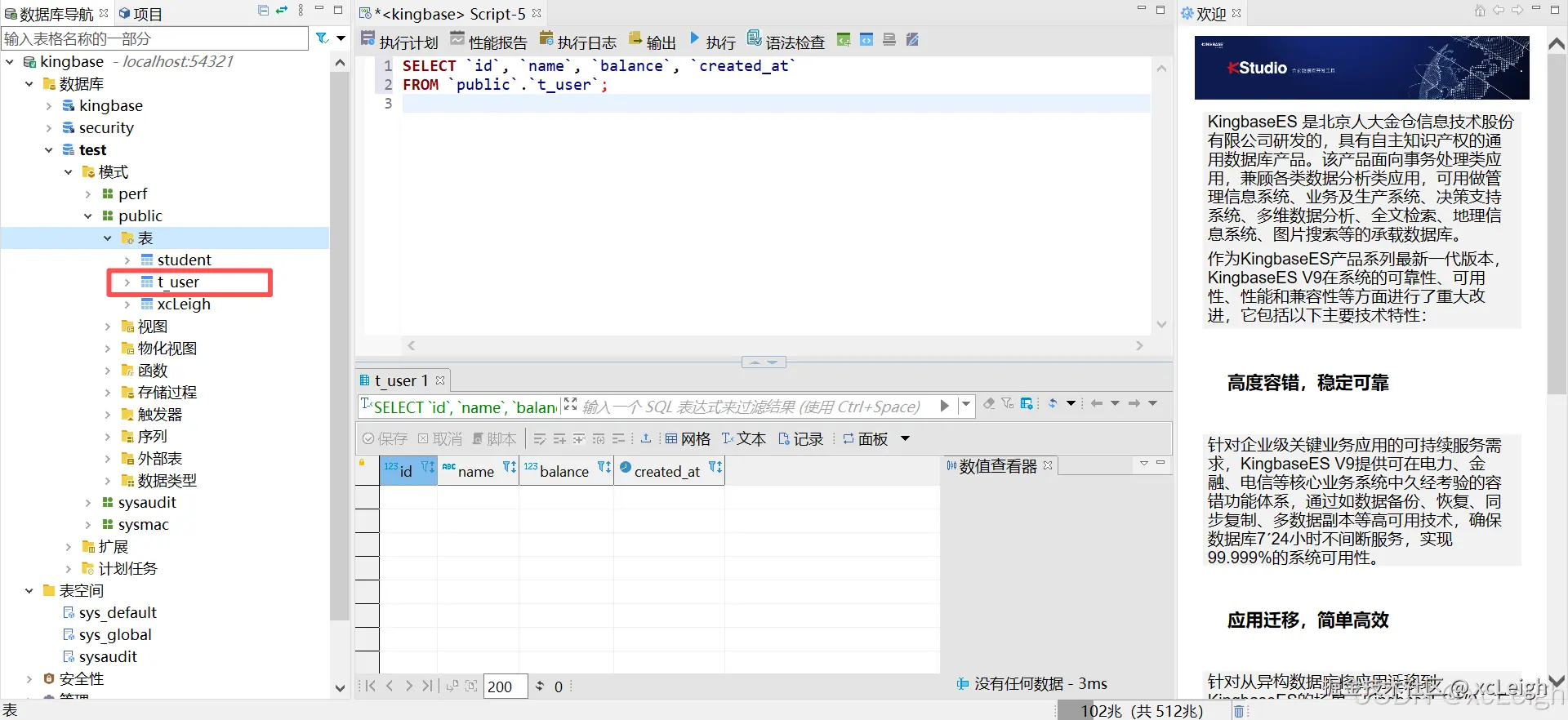
数据库表变化:
这个接口的路径是/user/schema,用的是POST方法,主要功能就是创建用户表t_user。咱们来看看这个表的结构:
id:自增的主键,用来唯一标识每个用户name:用户名,这个字段是不能空的,毕竟没用户名可不行balance:用户的余额,默认值设为0,要是没特意填余额,就默认是0created_at:记录用户创建的时间,默认是当前的时间戳,不用手动填
代码里用了with语句来管理数据库连接和游标,这样不用手动去关闭连接和游标,它会自动处理,能避免资源泄露的问题。执行完创建表的SQL语句后,就返回一个"表结构初始化成功"的信息,状态码是200,代表操作成功。
3.5 创建用户接口(新增操作)
python
@app.route('/user', methods=['POST'])
def create_user():
data = request.get_json()
if not data or 'name' not in data:
return jsonify({'status': 'error', 'message': '缺少用户名'}), 400
name = data['name']
balance = data.get('balance', 0.0)
try:
sql = "insert into t_user(name, balance) values (%s, %s) returning id;"
with get_conn() as conn, conn.cursor() as cur:
cur.execute(sql, (name, balance))
user_id = cur.fetchone()[0]
return jsonify({
'status': 'success',
'data': {'user_id': user_id}
}), 201
except Exception as e:
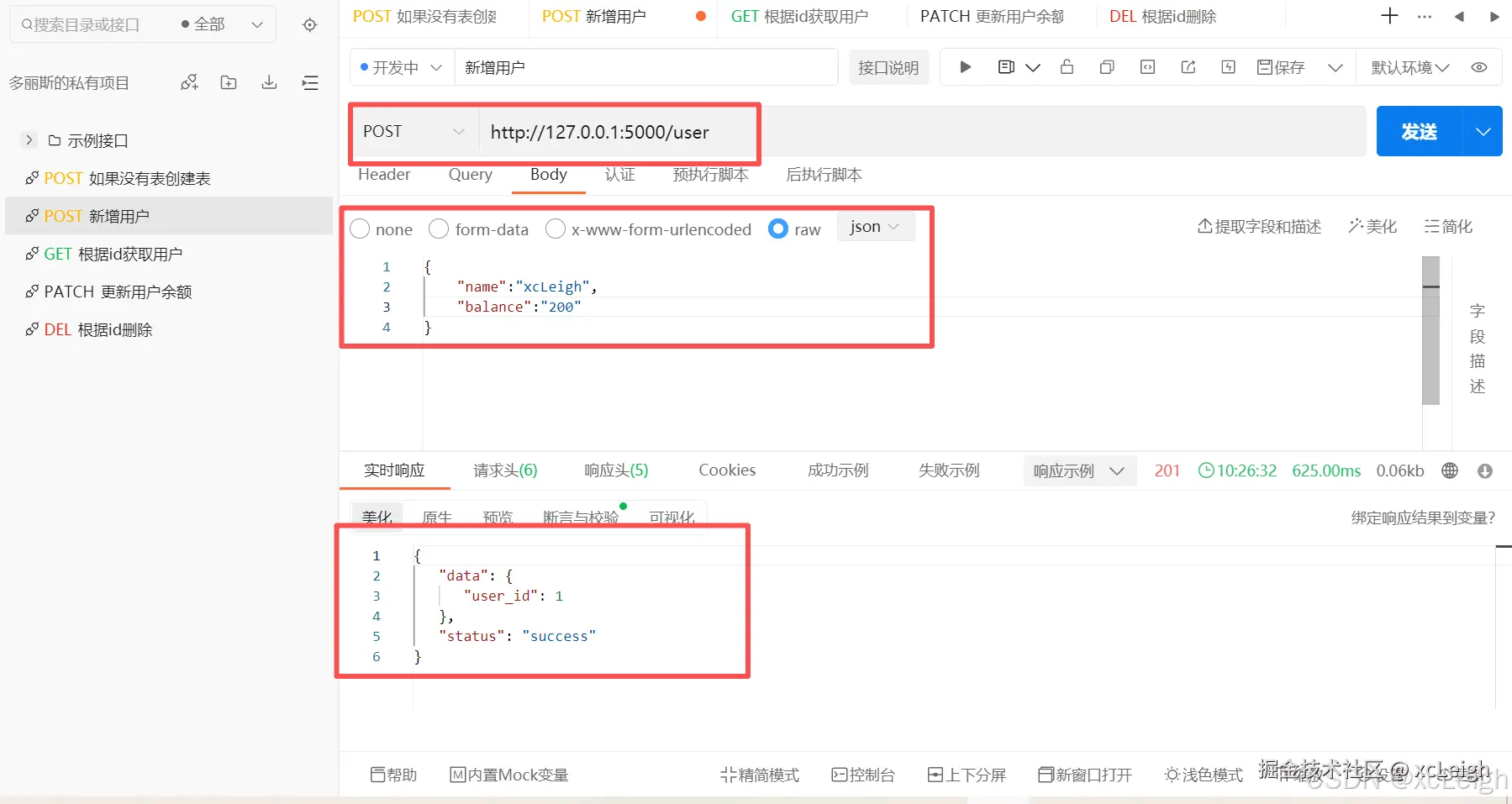
return jsonify({'status': 'error', 'message': str(e)}), 500接口调用效果:
数据库表变化:
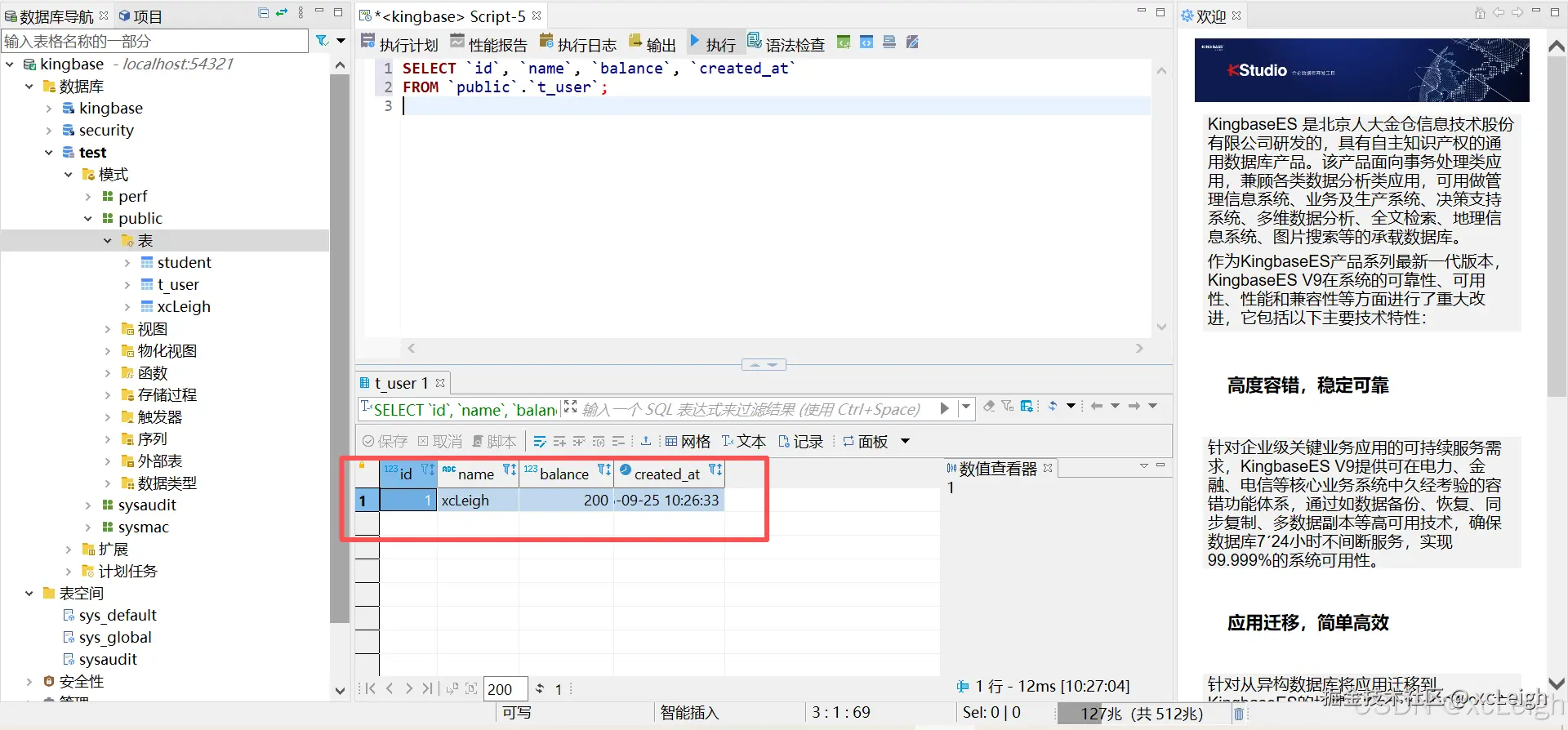 这个创建用户的接口,路径是
这个创建用户的接口,路径是/user,用的也是POST方法,主要就是接收JSON格式的数据,然后新增一个用户。
它的逻辑是这样的:
- 先获取请求里的JSON数据,然后检查一下,要是没有数据,或者数据里没有"name"(用户名)这个字段,就返回"缺少用户名"的错误信息,状态码是400,代表请求参数有问题。
- 从数据里提取出用户名,至于余额,要是数据里没填,就默认设为0.0。
- 接着执行插入数据的SQL语句,这里有个小技巧,用
returning id能把刚创建的用户ID返回回来,这样咱们就知道新用户的ID是多少了。 - 为了防止出现意外情况,代码外面包了个
try-except块,要是执行过程中出了错,就返回错误信息和500状态码,500代表服务器端出了问题;要是没出错,就返回成功的信息,还有新用户的ID,状态码是201,代表资源创建成功。
3.6 获取用户接口(查询操作)
python
@app.route('/user/<int:user_id>', methods=['GET'])
def get_user(user_id):
try:
sql = "select id, name, balance, created_at from t_user where id=%s;"
with get_conn() as conn, conn.cursor(cursor_factory=extras.DictCursor) as cur:
cur.execute(sql, (user_id,))
row = cur.fetchone()
if not row:
return jsonify({'status': 'error', 'message': '用户不存在'}), 404
return jsonify({
'status': 'success',
'data': dict(row)
}), 200
except Exception as e:
return jsonify({'status': 'error', 'message': str(e)}), 500接口调用效果:
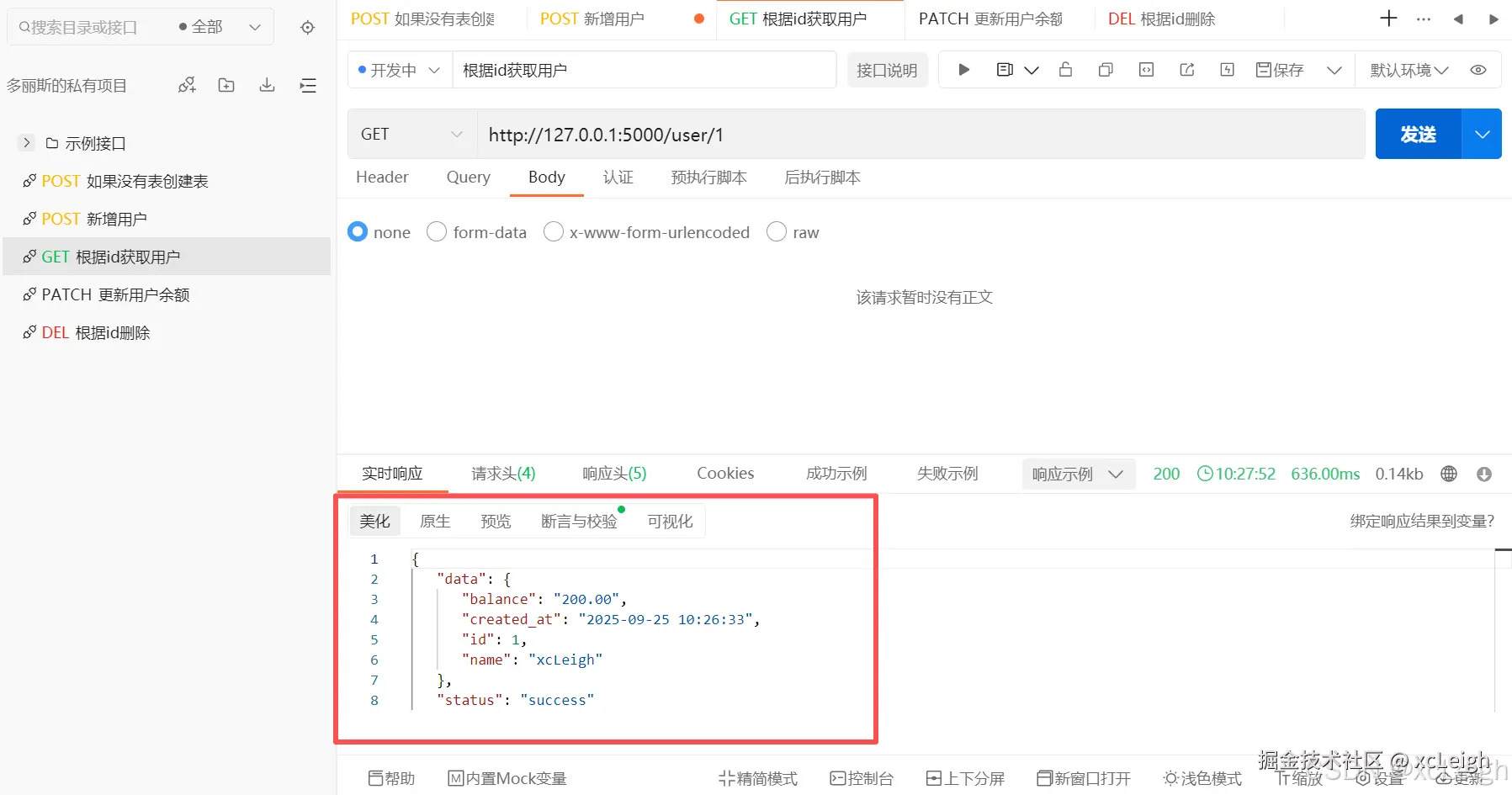
这个查询用户的接口,路径是/user/<int:user_id>,用的是GET方法,顾名思义,就是根据用户ID来查询用户的信息。
它有个很方便的地方,就是用了extras.DictCursor这个游标,这样查询出来的结果能直接转换成字典,后面转成JSON返回给前端的时候,就不用再手动处理数据格式了,省了不少事。
查询的时候,先执行SQL语句,然后看有没有查询到结果。要是没查到,就返回"用户不存在"的信息,状态码是404,代表找不到对应的资源;要是查到了,就把结果转成字典,返回成功信息和用户数据,状态码是200。
3.7 更新用户余额接口(修改操作)
python
@app.route('/user/<int:user_id>/balance', methods=['PATCH'])
def update_balance(user_id):
data = request.get_json()
if 'delta' not in data:
return jsonify({'status': 'error', 'message': '缺少余额变动值'}), 400
try:
delta = float(data['delta'])
sql = "update t_user set balance = balance + %s where id=%s;"
with get_conn() as conn, conn.cursor() as cur:
cur.execute(sql, (delta, user_id))
if cur.rowcount == 0:
return jsonify({'status': 'error', 'message': '用户不存在'}), 404
return jsonify({
'status': 'success',
'message': '余额更新成功'
}), 200
except ValueError:
return jsonify({'status': 'error', 'message': '余额变动值必须为数字'}), 400
except Exception as e:
return jsonify({'status': 'error', 'message': str(e)}), 500接口调用效果:
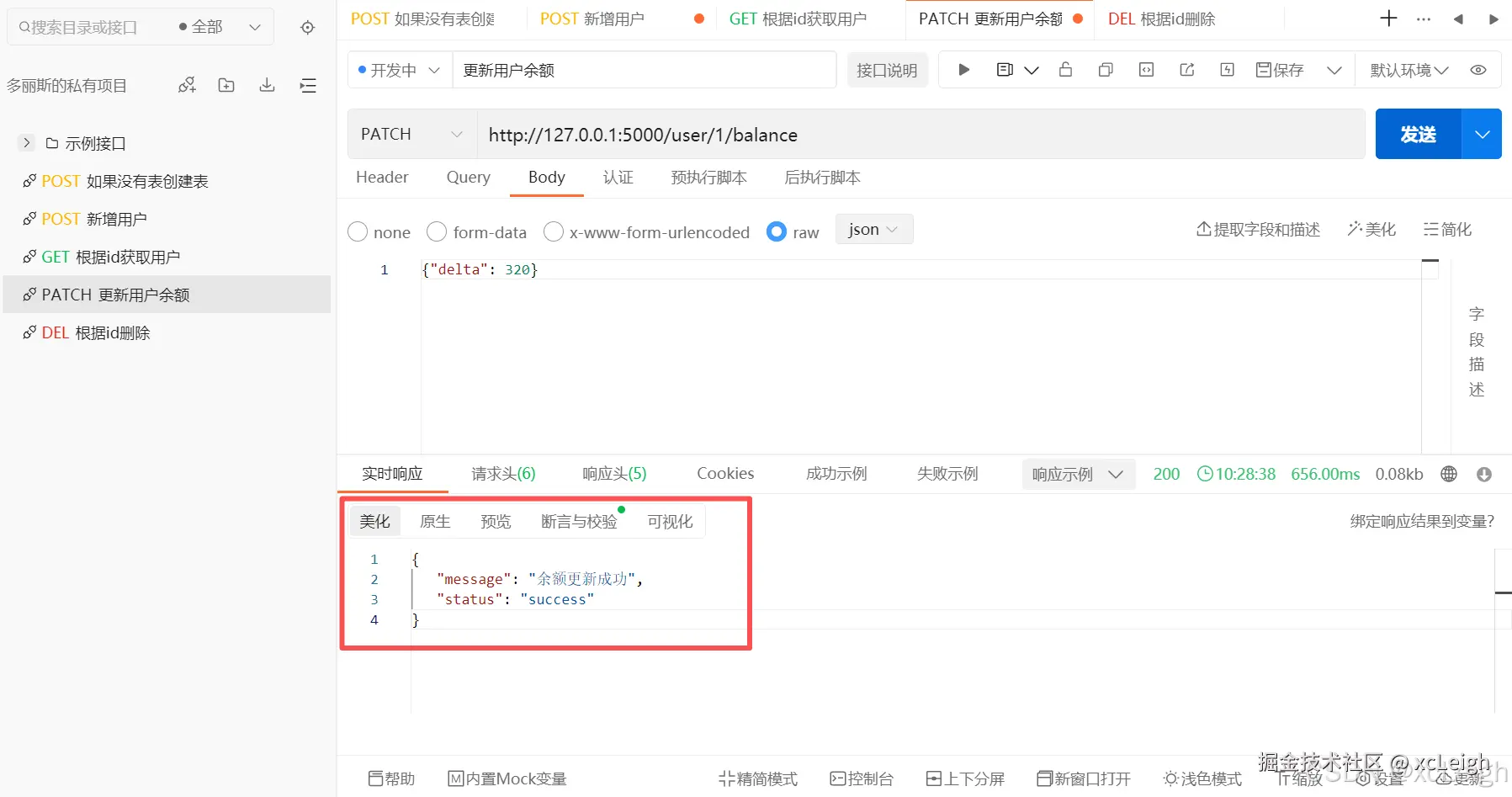
数据库表变化:
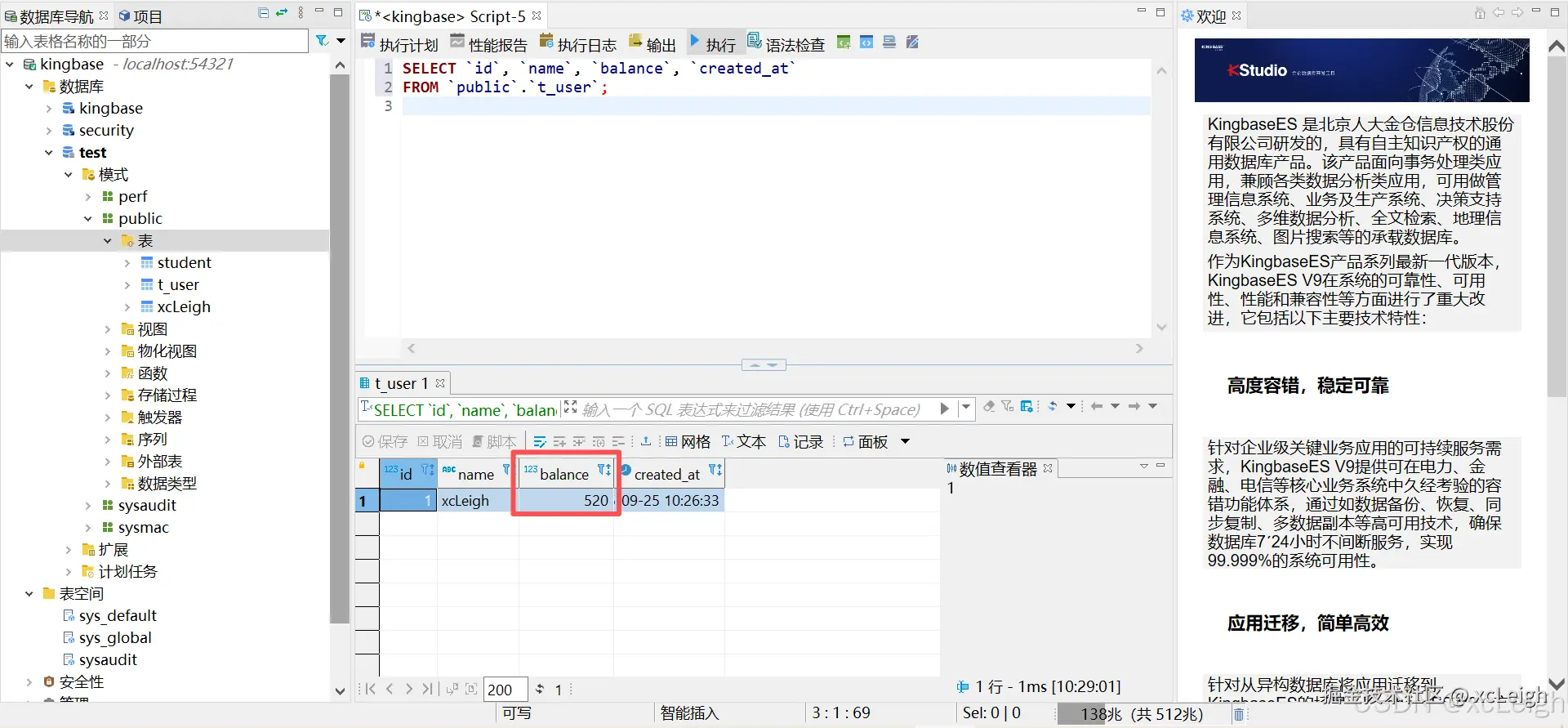 这个更新用户余额的接口,路径是
这个更新用户余额的接口,路径是/user/<int:user_id>/balance,用的是PATCH方法,主要用来修改用户的余额,不管是增加还是减少都能用。
它的逻辑也很清晰:
- 首先检查请求数据里有没有"delta"(余额变动值)这个字段,要是没有,就返回错误信息,状态码400。
- 然后把"delta"转换成浮点型,要是转换失败,比如填的不是数字,就返回"余额变动值必须为数字"的错误,状态码也是400。
- 执行更新余额的SQL语句,这里用
balance = balance + %s的方式来更新,要是"delta"是正数,余额就增加;要是负数,余额就减少,很灵活。 - 执行完SQL后,会看
rowcount的值,这个值代表受影响的行数。要是它等于0,说明没找到对应的用户,就返回"用户不存在",状态码404;要是更新成功,就返回"余额更新成功"的信息,状态码200。
3.8 删除用户接口(删除操作)
python
@app.route('/user/<int:user_id>', methods=['DELETE'])
def delete_user(user_id):
try:
sql = "delete from t_user where id=%s;"
with get_conn() as conn, conn.cursor() as cur:
cur.execute(sql, (user_id,))
if cur.rowcount == 0:
return jsonify({'status': 'error', 'message': '用户不存在'}), 404
return jsonify({
'status': 'success',
'message': '用户删除成功'
}), 200
except Exception as e:
return jsonify({'status': 'error', 'message': str(e)}), 500接口调用效果:
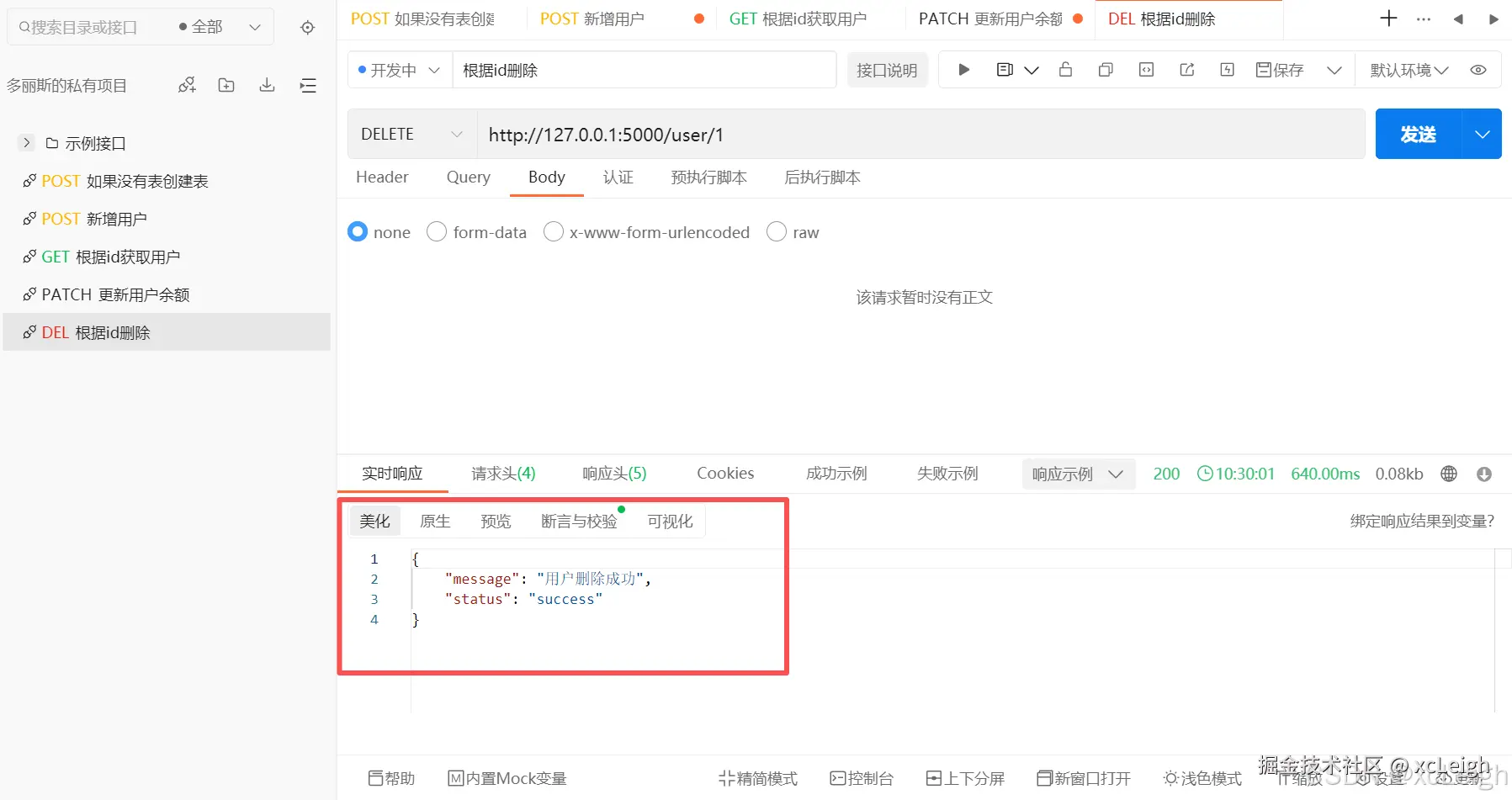
数据库表变化:
 这个删除用户的接口,路径是
这个删除用户的接口,路径是/user/<int:user_id>,用的是DELETE方法,就是根据用户ID把对应的用户删掉。
它的判断逻辑和更新余额接口有点像,也是执行完删除的SQL语句后,看rowcount的值。要是rowcount是0,说明没找到要删的用户,就返回"用户不存在";要是删成功了,就返回"用户删除成功"的信息,状态码200。
3.9 获取所有用户列表接口
python
@app.route('/users', methods=['GET'])
def get_all_users():
try:
sql = "select id, name, balance, created_at from t_user;"
with get_conn() as conn, conn.cursor(cursor_factory=extras.DictCursor) as cur:
cur.execute(sql)
rows = cur.fetchall()
return jsonify({
'status': 'success',
'count': len(rows),
'data': [dict(row) for row in rows]
}), 200
except Exception as e:
return jsonify({'status': 'error', 'message': str(e)}), 500这个获取所有用户列表的接口,路径是/users,用的是GET方法,能把数据库里所有用户的信息都查出来。
查询的时候同样用了extras.DictCursor游标,查询结果是一个列表,里面每个元素都是字典类型的用户数据。返回的时候,除了返回用户列表,还会返回用户的总数,这样前端就能清楚知道一共有多少个用户了,状态码也是200。
3.10 应用启动入口
python
if __name__ == '__main__':
app.run(debug=True)这部分代码是整个应用的启动入口,意思就是当这个Python脚本被直接运行的时候,就会启动Flask应用,而且开启了调试模式。调试模式下,要是代码改了,应用会自动重启,方便咱们开发的时候调试代码。不过要注意,生产环境可不能开调试模式。
四、接口测试方法
启动应用之后,咱们可以用Postman、curl这些工具来测试接口。测试的时候建议按下面这个顺序来,这样能一步步验证每个功能是不是正常的:
- 初始化表结构:
bash
curl -X POST http://127.0.0.1:5000/user/schema- 创建用户:
bash
curl -X POST -H "Content-Type: application/json" -d '{"name":"张三", "balance":100.0}' http://127.0.0.1:5000/user- 查询用户:
bash
curl http://127.0.0.1:5000/user/1- 更新余额:
bash
curl -X PATCH -H "Content-Type: application/json" -d '{"delta":50.0}' http://127.0.0.1:5000/user/1/balance- 查询所有用户:
bash
curl http://127.0.0.1:5000/users- 删除用户:
bash
curl -X DELETE http://127.0.0.1:5000/user/1每一步测试完,都可以看看返回的信息对不对,也可以去数据库里查一下数据有没有按预期变化,这样能及时发现问题。
五、注意事项
在实际开发和使用的时候,有几个点大家一定要注意,不然可能会出问题:
- 要是把应用部署到生产环境,一定要把
debug=True这个调试模式关掉,调试模式下会暴露很多敏感信息,而且也不安全。 - 数据库的配置信息,像用户名、密码这些,可别直接写在代码里,万一代码泄露了,数据库就危险了。建议用环境变量或者专门的配置文件来存这些信息,用的时候再读取。
- 现在代码里的错误处理还比较简单,实际项目中得加更完善的错误处理,还要记录日志,这样出了问题能快速定位原因。
- 对于一些敏感操作,比如删除用户、修改余额这些,不能谁都能操作,得加身份验证和授权机制,只有有权限的人才能操作。
- 要是需要处理大批量的数据操作,比如一次插入很多用户,建议用事务和批量处理的机制,这样能提高效率,也能保证数据的一致性。
- 大家可能也知道,SQL注入是个很危险的问题,不过咱们这篇文章里用的是参数化查询,已经避免了这个风险,实际开发中也一定要用这种方式,别直接拼接SQL语句。
六、总结
📣今天这篇文章,我详细跟大家讲了用Python和Flask框架搭建连接KingbaseES数据库API接口的整个过程,🍀把用户信息的CRUD操作全实现了。从这个例子就能看出来,🍄KingbaseES作为国产数据库,在Python生态里的兼容性特别好,👍咱们直接用成熟的psycopg2驱动就能操作它,不用额外折腾。
🏄♂️ 咱们开发者可以把这个例子当成一个基础模板,然后根据实际的业务需求再扩展更多功能。比如说,💡可以加更复杂的查询条件,比如按用户名模糊查询;也可以给用户数据加更严格的验证,比如用户名不能有特殊字符;还能实现分页查询,毕竟数据多的时候,一次查太多会影响性能。🌞通过这些扩展,就能搭建出更完善、更符合实际需求的数据库API服务了。