1.前言
2025 年 9 月 24 日云栖大会,阿里巴巴正式开源新一代视觉理解模型 Qwen3-VL。随后在 2025 年 10 月 4 日同步发布了 Qwen3-VL-30B-A3B-Instruct 版本,下面是这个模型的特点。

模型规格这块具有如下特点:
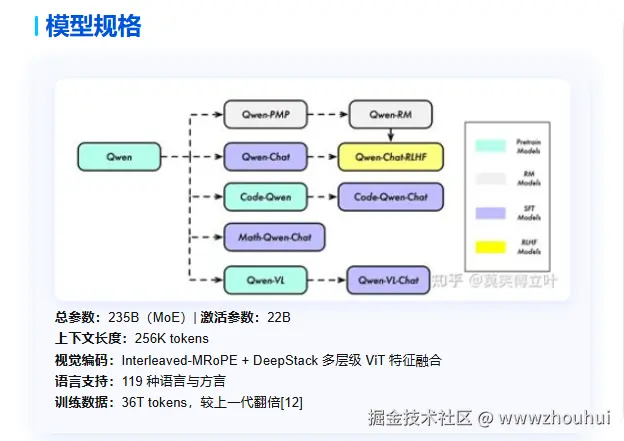
应用场景这块如下四个方向:

前2天给大家介绍过关于使用Qwen3-VL+Dify实现一个基于多模态的工作流的使用。《dify案例分享-Qwen3-VL+Dify:从作业 OCR 到视频字幕,多模态识别工作流一步教,附体验链接》,这个工作流本身是不难的,难的地方就是用到了个Qwen3-VL的接口。接口我前2天也开源了。目前已经上传到github上 今天就带大家手把手教会大家如何部署和使用这个接口。这样除了在dify中使用,也可以利用这接口在其他任何接口中使用。话不多说下面带大家安装部署一下和使用。
2.代码安装部署
安装部署前我们需要在github上下载这个源码。
源码下载
我们可以通过code 下载源码包
也可以使用git clone 源码。输入下面命令
shell
git clone https://github.com/wwwzhouhui/qwen3-reverse我这里就介绍第二个方法git clone
通过上面的命令我们完成源码的下载。
配置环境变量
接下来我们需要使用到代码中遇到的一些配置文件。这里主要是.env 里面三个值QWEN_COOKIES、QWEN_AUTH_TOKEN、VALID_TOKENS
用下面命令复制.env文件
bash
cp .env.example .env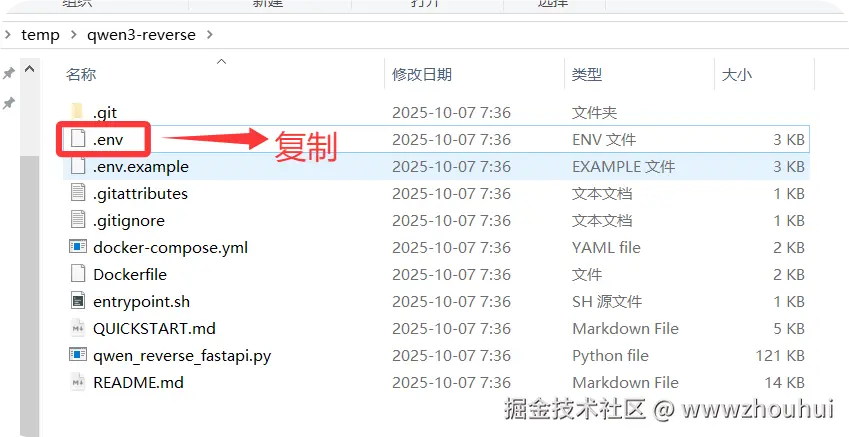
获取 QWEN_COOKIES:
- 访问 chat.qwen.ai 并登录
- 打开 F12 → Network 标签页
- 发送一条消息
- 找到
chat/completions请求 - 复制 Request Headers 中的完整 Cookie 值
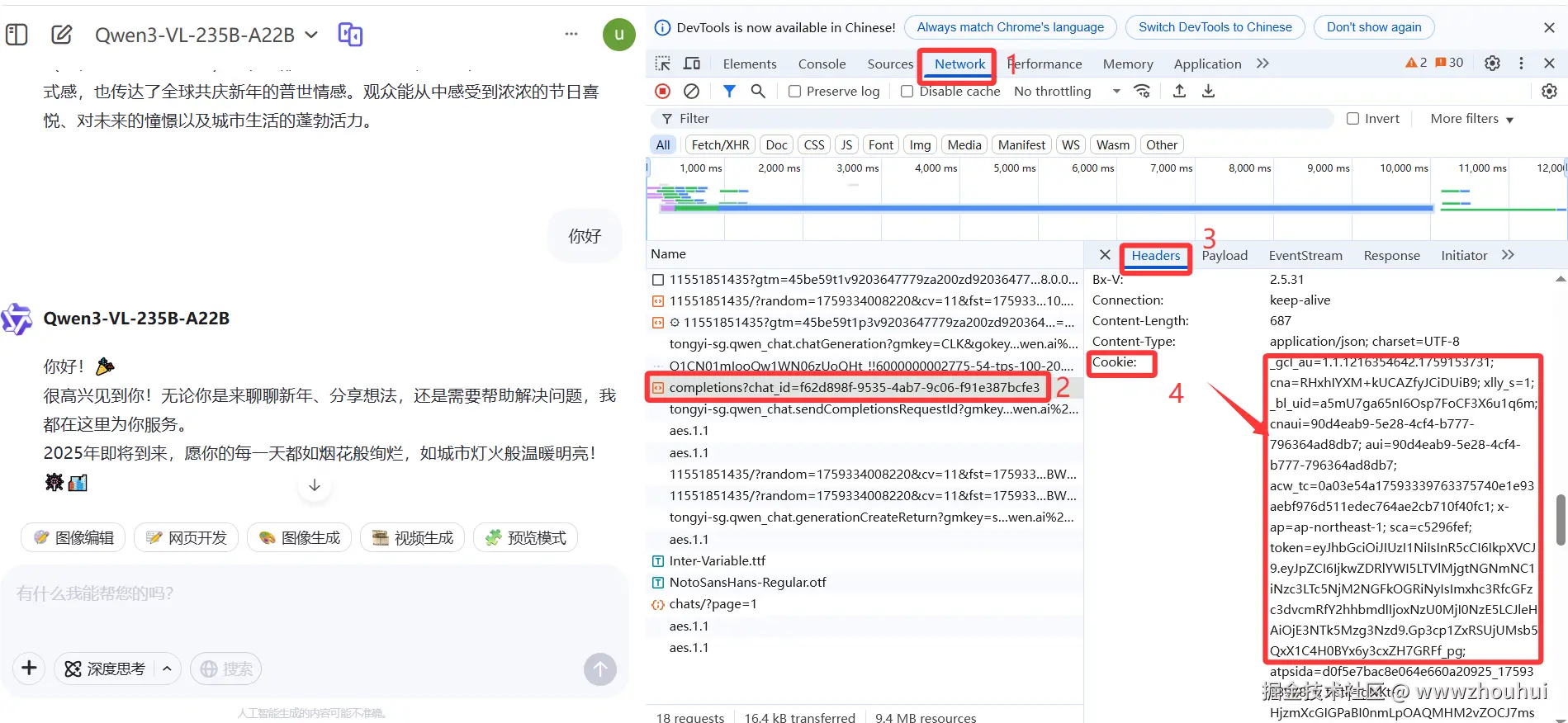
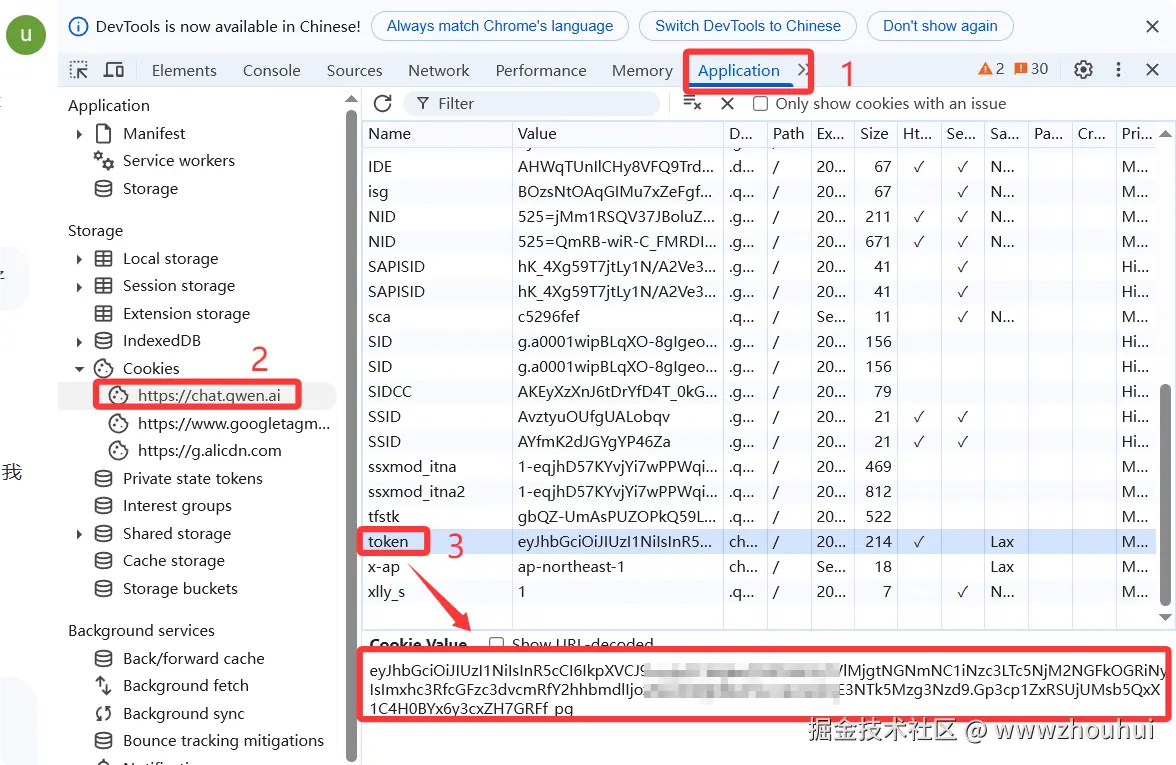
获取 QWEN_AUTH_TOKEN
如果您仍希望单独设置token:
① 进入chat.qwen.ai ,并登录您的账号
② 打开 F12 开发者工具
③ 在顶端找到标签页"Applications/应用"
④ 在左侧找到"Local Storage/本地存储",打开下拉菜单
⑤ 找到 chat.qwen.ai 并进入
⑥ 在右侧找到"token"的值,整段复制,该值即为
QWEN_AUTH_TOKEN
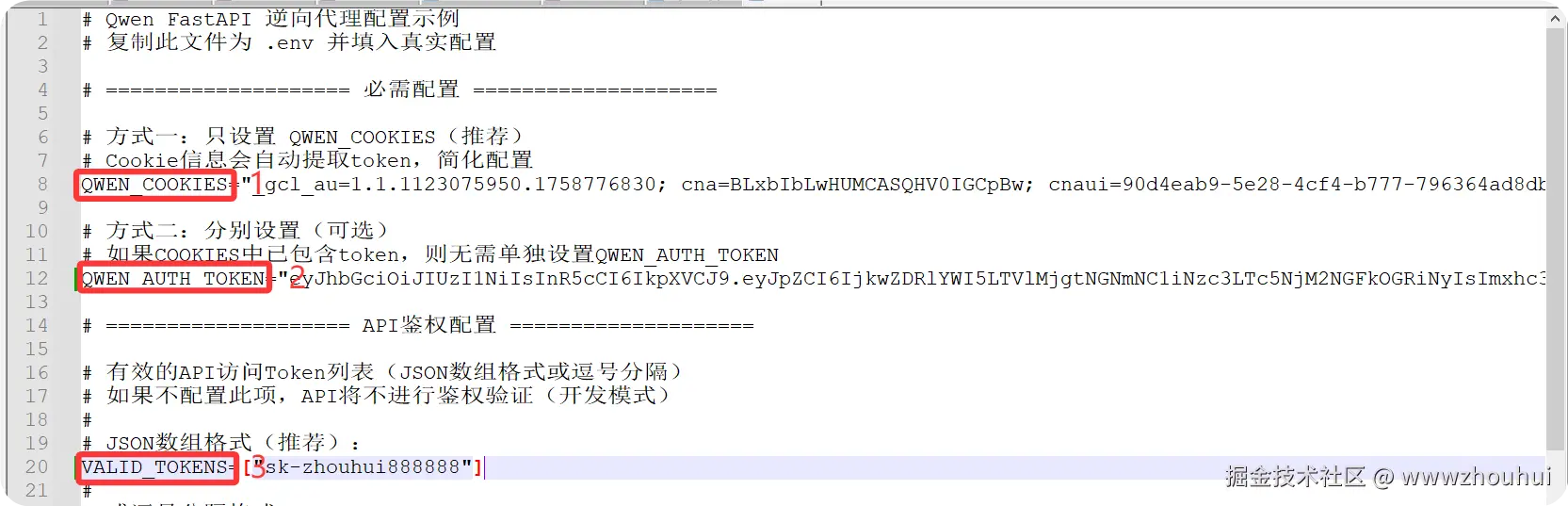
VALID_TOKENS 这个值是我们自定义的。修改后的.env 内容如下
程序依赖包安装(可选)
接下来我们需要安装一下python 程序依赖包,执行下面命令
shell
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/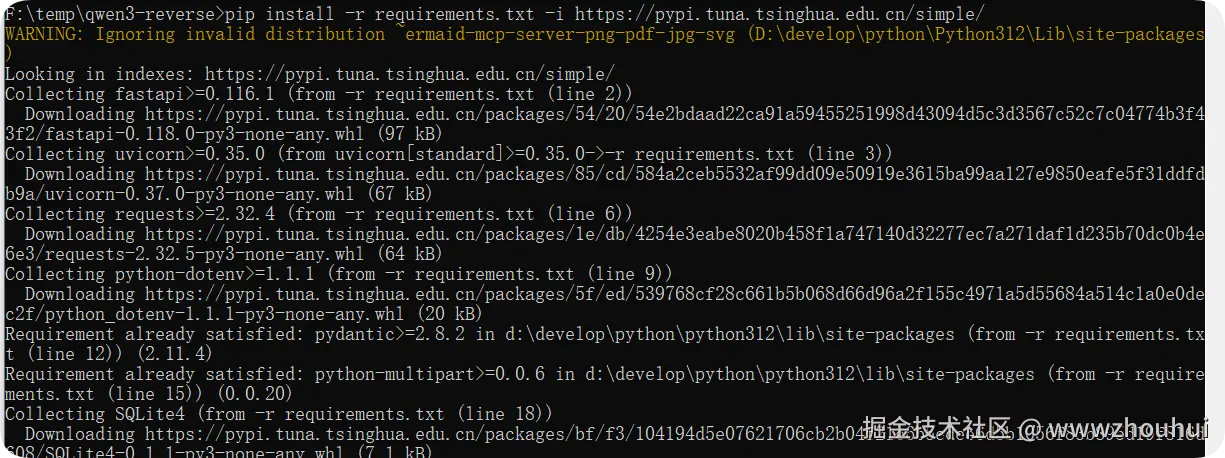
启动程序(可选)
下面我们就可以使用python 启动这个程序了。(关于python运行环境安装这里就不做详细展开,不会的小伙伴可以自己搜索)
在启动之前我们需要创建一个db文件夹。
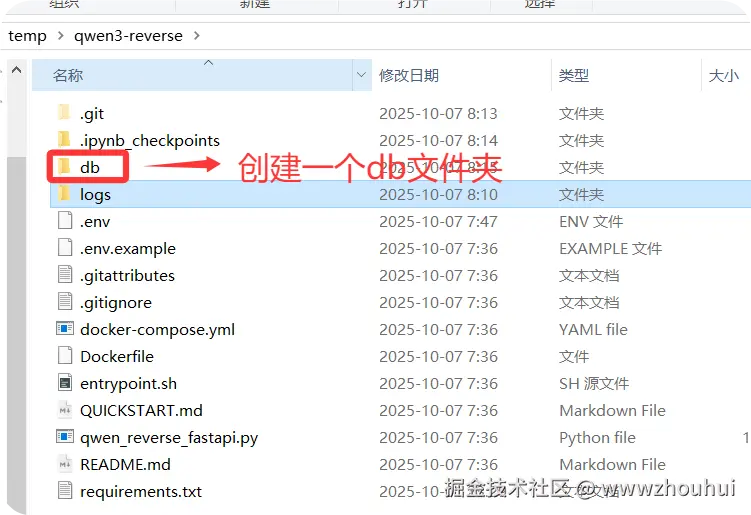
python qwen_reverse_fastapi.py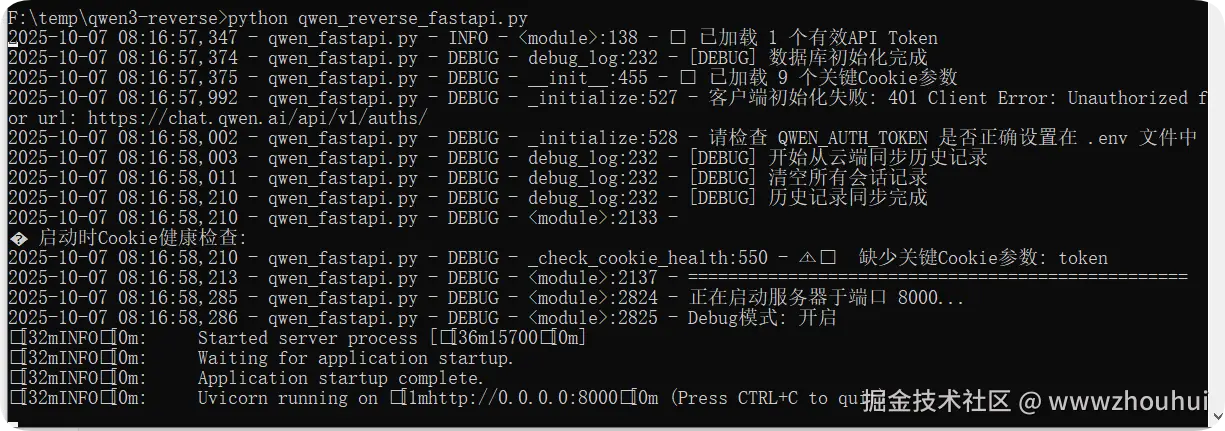
看到命令行窗口出现 http://0.0.0.0:8000说明服务启动完成。
docker方式部署
有的小伙伴觉的源码部署麻烦,我们这里也提供docker 部署方案。
使用下面命令
shell
# 下载镜像包
docker pull wwwzhouhui569/qwen_reverse_fastapi:latest
# 运行镜像
docker run -d \
--name qwen_reverse_fastapi_proxy \
-p 8000:8000 \
-v $(pwd)/logs:/app/logs \
-v $(pwd)/db:/app/db \
-e QWEN_COOKIES="your_cookies_here" \
-e QWEN_AUTH_TOKEN="your_auth_token_here" \
-e VALID_TOKENS="your_valid_token_here" \
--restart unless-stopped \
wwwzhouhui569/qwen_reverse_fastapi:latest其中QWEN_COOKIES、QWEN_AUTH_TOKEN、VALID_TOKENS值的获取同上面的环境变量配置,这里就不做详细展开。

通过docker 方式同样可以实现程序启动。
输入下面命令查看容器日志
shell
docker logs -f c8be592b3591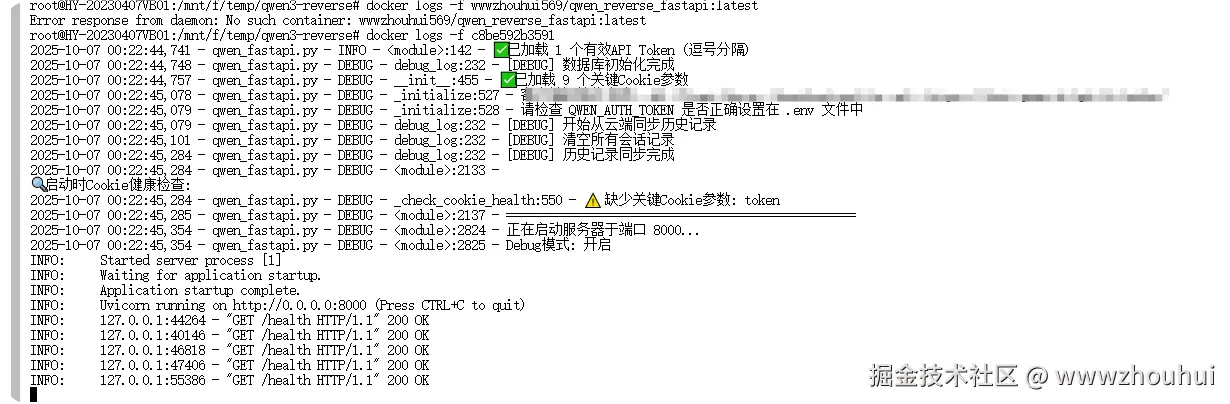
3.使用
接口启动完成后我们就可以在对应的第三方接口中使用了。
Apifox
我们打开Apifox 输入下面curl 命令
shell
curl --location --request POST 'http://localhost:8000/v1/chat/completions' \
--header 'Authorization: Bearer sk-XXXXX' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3",
"messages": [{"role": "user", "content": "你是公司开发的模型"}],
"stream": false
}'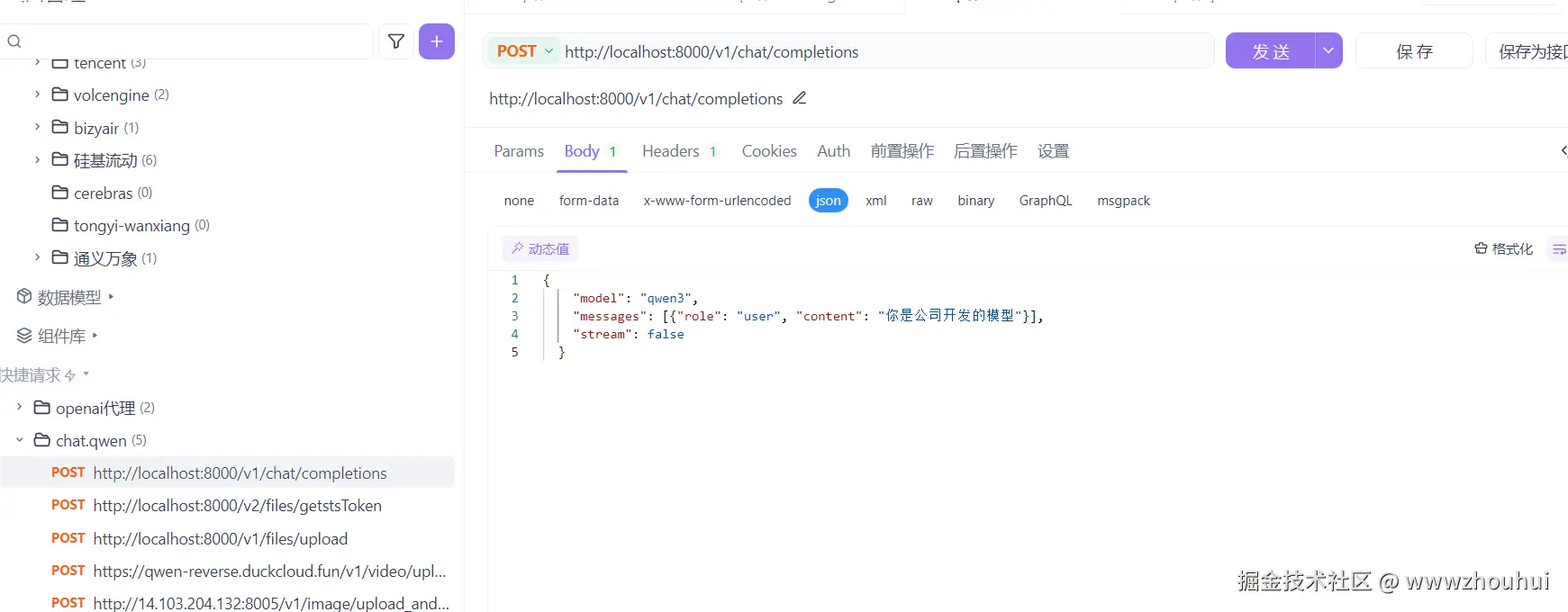
通过点击发送按钮
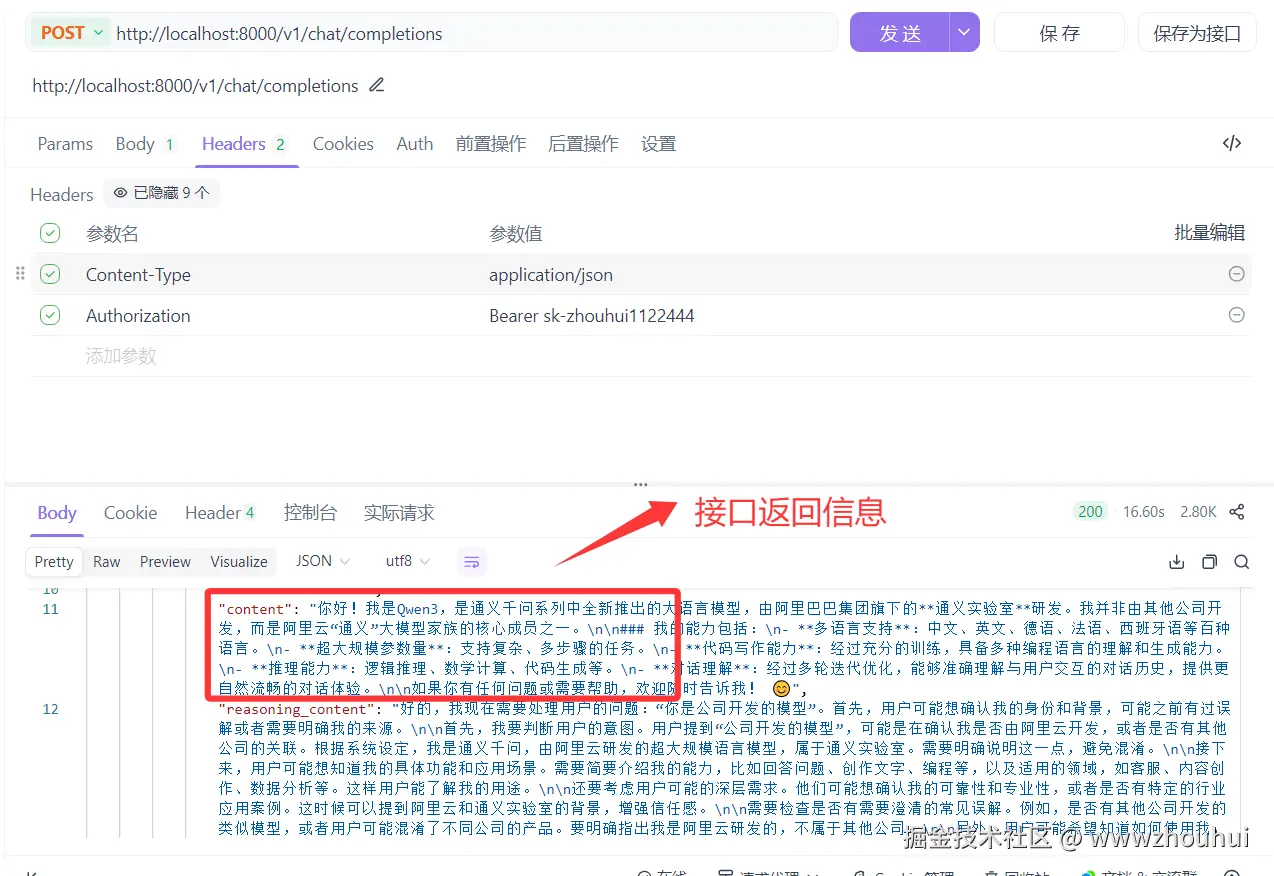
我们在查看一下chat.qwen.ai/ 是否有对应的信息(刷新一下网页)
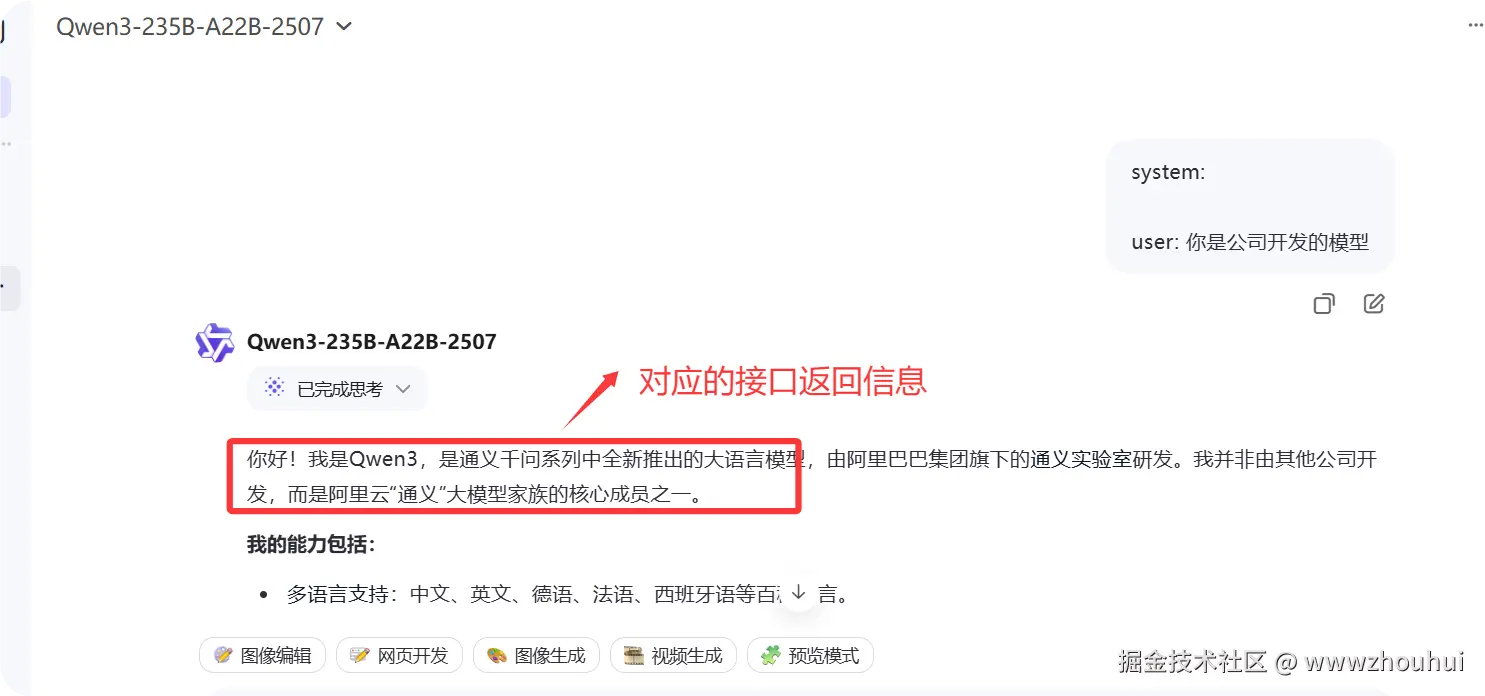
通过上面的方式我们就完成了一个最基本的聊天对话第三方API接口方式调用。后面你可以把这个接口接入到dify、Cherry Studio 等第三方接口应用中使用。
dify应用
前2天给大家部署的dify工作流其实也是用到这个接口。我只是部署在服务器上。部署方式和上面的一样。
这里我们用到了视频上传+聊天一键接口以及文件上传+聊天一键接口。
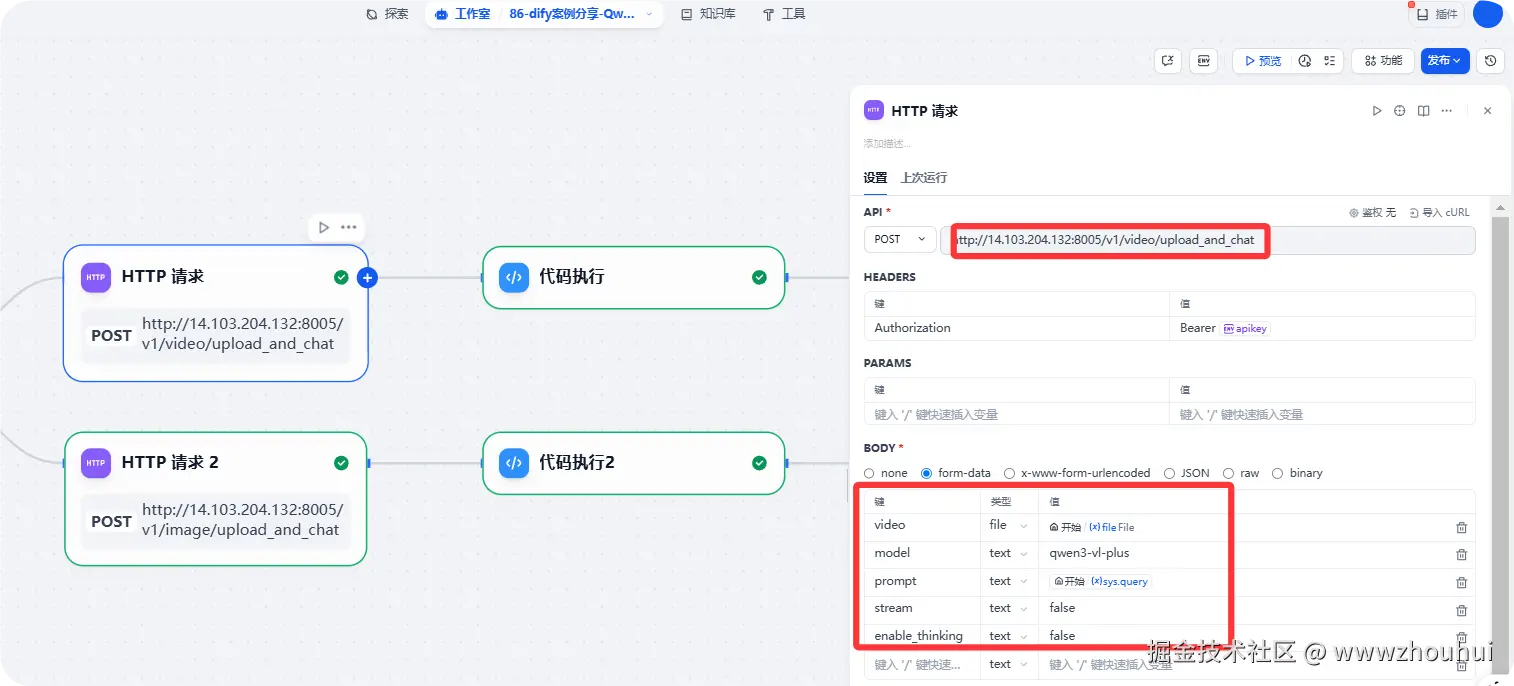
本质上也是基于HTTP请求。你可以理解这个HTTP请求就是上面Apifox 请求一样的。
关于这个API有哪些接口呢?下面给大家贴一下接口清单
| 端点 | 方法 | 说明 | 鉴权 |
|---|---|---|---|
/ |
GET | 服务器信息 | ❌ |
/health |
GET | 健康检查 | ❌ |
/docs |
GET | Swagger UI 文档 | ❌ |
/v1/models |
GET | 列出可用模型 | ❌ |
/v1/chat/completions |
POST | 聊天补全(兼容OpenAI) | ✅ |
/v1/chat/multimodal |
POST | 多模态对话(图片) | ✅ |
/v1/files/upload |
POST | 文件上传 | ✅ |
/v1/image/upload_and_chat |
POST | 图片上传+对话(一体化) | ✅ |
/v1/video/upload_and_chat |
POST | 视频上传+对话(一体化) | ✅ |
/v2/files/getstsToken |
POST | 获取OSS授权Token | ❌ |
考虑到接口健康检查以及简单的接口验证测试。所以鉴权值做了部分。详细接口请求可以看我开源项目README.md 文档

通过上面的方式我们就完成了接口的部署以及如何使用这个接口,是不是也非常的简单。
3.总结
今天主要带大家了解并实现了 Qwen3-VL 接口的部署与使用完整流程,该流程以阿里巴巴开源的 Qwen3-VL 模型为核心,通过 github 开源项目提供的逆向工程方案,结合 FastAPI 框架的接口服务能力,形成了一套从本地部署到多场景调用的实用化解决方案。
通过这套实践方案,用户能够低成本使用 Qwen3-VL 的多模态能力 ------ 借助两种部署方式(源码部署和 Docker 部署)的灵活选择,无需复杂的模型训练和环境配置,就能快速搭建兼容 OpenAI 格式的接口服务,无论是基础的文本对话、图片理解,还是文件上传、视频分析,都能通过标准化的 API 请求完成,极大降低了开发者集成 Qwen3-VL 能力的技术门槛。在实际验证中,该接口能够稳定响应多样化的调用需求,有效解决了 Qwen3-VL 在第三方平台集成中的适配问题。同时,接口具备良好的扩展性 ------ 小伙伴们可以基于此接口扩展更多实用功能,如办公场景的多格式文档解析、教育领域的图文结合答疑、电商行业的商品图片智能分析等,进一步丰富 Qwen3-VL 模型在实际业务场景中的应用价值。
感兴趣的小伙伴可以通过文中提供的 github 项目地址获取源码,根据需求选择合适的部署方式进行实践。今天的分享就到这里结束了,我们下一篇文章见。