URL解析

URI: URL + URN
- URI统一资源标识符
- URL统一资源定位符
- URN统一资源名称
传输协议
- HTTP 超文本传输协议
- HTTPS HTTP + SSL(加密证书),相比于HTTP更加安全
- FTP 文件的传输,例如:FPT上传工具、FTP资源共享
域名:服务器有一个外网IP,基于外网IP找到服务器,域名就是给这个外网IP一个好记忆的名字
端口号:区分同一台服务器上的不同服务或项目
- 取值范围:0~65535
- 默认值:HTTP >80 HTTPS->443 FTP->21
编码问题:如果URL地址中出现中文或特殊符号,会乱码,需要客户端编码,服务端再解码
- encodeURI / decodeURI 对整个URL编码
- encodeURIComponent / decodeURICompoent 对参数编码
缓存检查
缓存位置
- 虚拟内存(内存条):页面关闭,存储的东西消失 Memory Cache
- 物理内存(硬盘):持久存储 Disk Cache
打开网页,未查找到依次查找顺序 内存 -> 硬盘 ->发送网络请求
强刷新(Ctrl + F5):不使用缓存,发送请求头部带有 Cache-control: no-cache
关于静态资源文件的缓存有两种:强缓存、协商缓存(nginx配置)
- 无论哪种都是服务器设置规则,客户端浏览器自动配合完成
- 一般项目中,强缓存、协商缓存都会设置【也可以设置一个】,强缓存失效的情况下,再走协商缓存机制
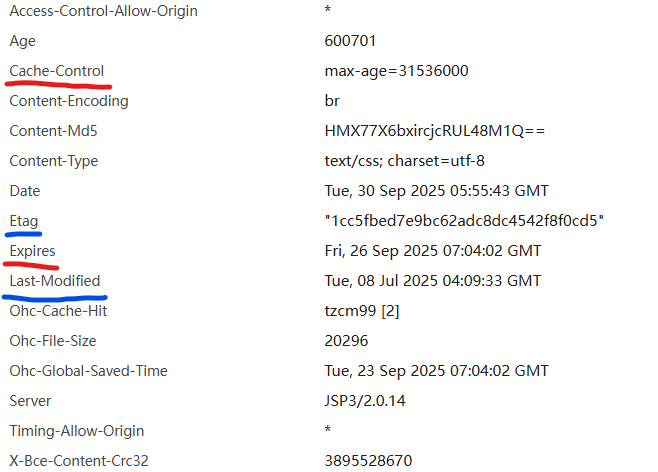
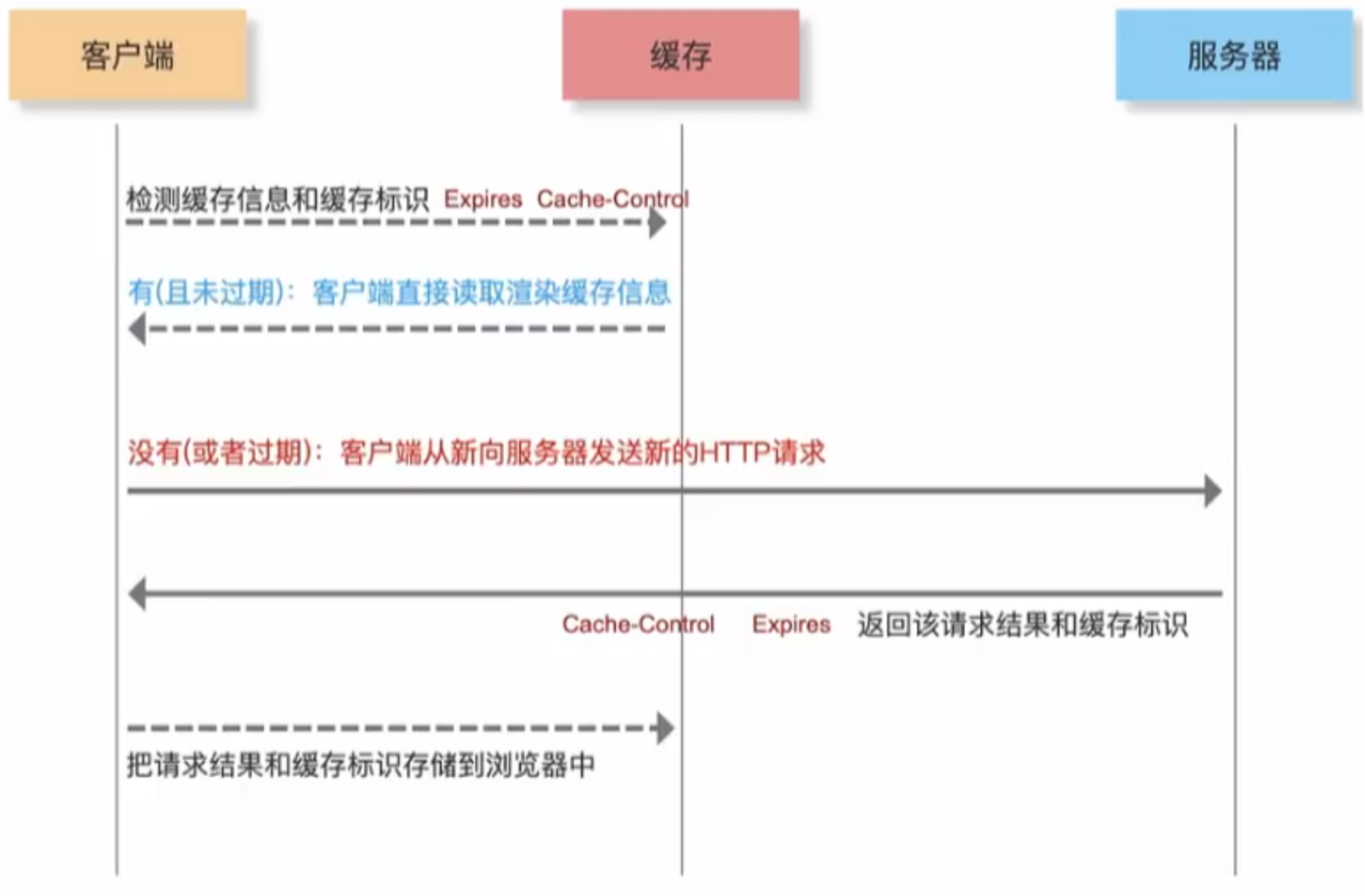
强缓存:Cache-Control(HTTP/1.1 优先级高 相对过期时间)、Expires(HTTP/1.0 绝对过期时间)服务器设置的响应头信息
不管从服务器取,还是缓存中读取,HTTP状态码都是200
如果本地缓存生效,但是服务器更新了整个资源,如何保证客户端可以获取最新的?
答:HTML页面资源绝对不做强缓存,因为它是页面渲染的入口,所有其他资源也是在渲染解析HTML代码的时候,再去请求的。前端 通过webpack打包生产的css和js可以设置哈希或者时间戳,更新后就会重新请求。
协商缓存:哪怕本地有缓存也要去和服务器协商
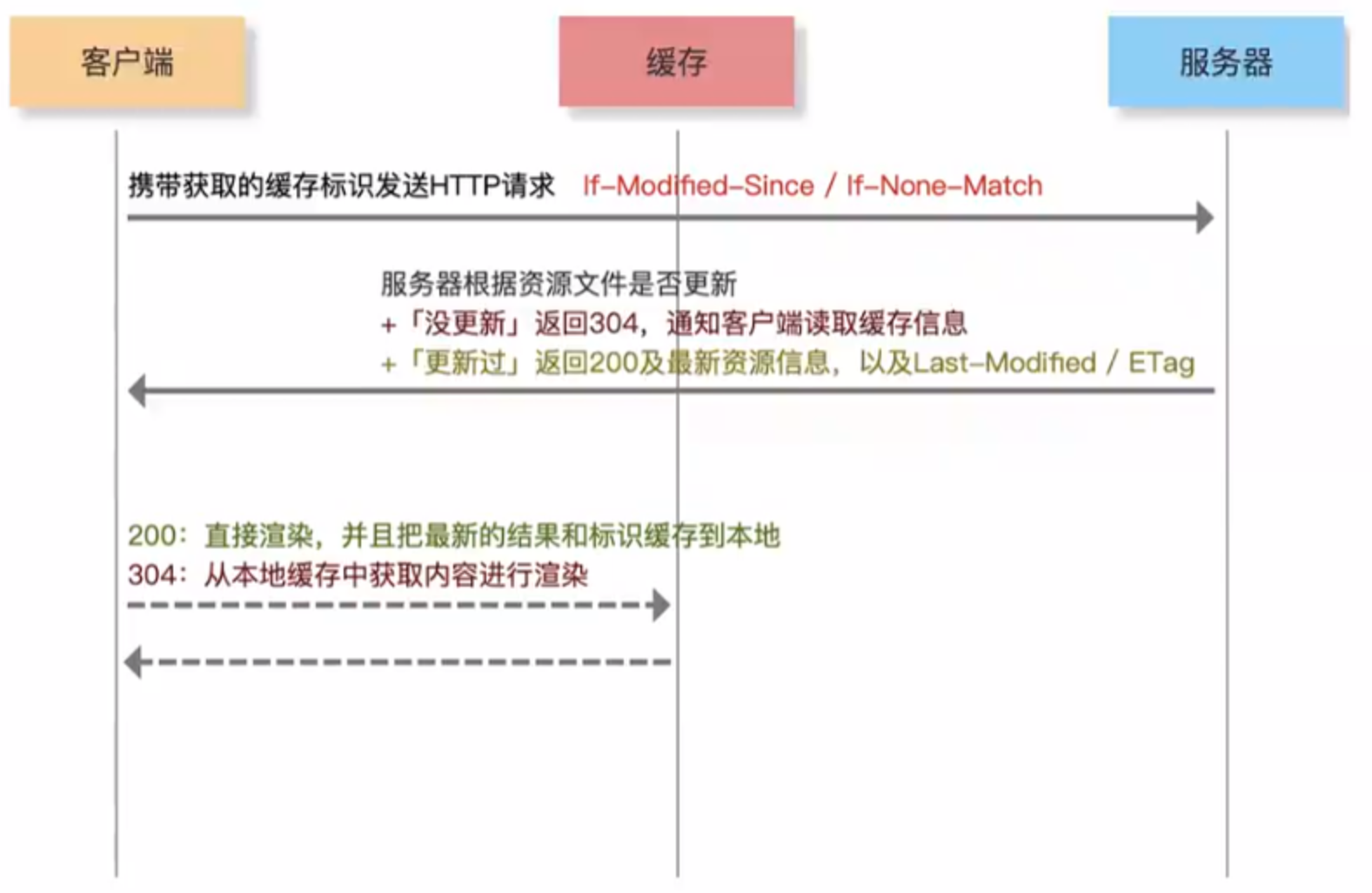
第一次请求页面,本地没有缓存,向服务器发送请求,如果需要设置协商缓存,服务器会在响应头中返回:Last-Modified(记录资源最后一次更新时间)/ ETag(记录资源最后一次更新的标识);客户端浏览器看到标识后,把标识和资源都缓存起来
第二次请求,也会向服务器发送请求,并且在请求头中,基于If-Modified-Since / If-None-Math分别把存储的Last-Modified / ETag值传给服务器;服务器获取标识后,和本地资源(最新更新时间/标识)做对比;
- 如果资源没有更新过,则时间/标识一致,服务器返回304;客户端发现是304后,从本地缓存中获取;
- 如果资源更新了,则时间/标识不一样,服务器返回200和最新内容以及最新的Last-Modified /
ETag;客户端再把最新的信息存储起来
建议:HTML页面只设置协商缓存,其余的静态资源强缓存和协商缓存都去设置
本地存储方案:受"源"和 "浏览器"的限制
- cookie
- 具备有效期,设置cookie的时候自己设置
- 最多允许4KB内容
- cookie和服务器有猫腻:在非跨域请求下,如果本地有cookie,无论浏览器是否需要,每次发送请求都默认把cookie基于请求头传递给服务器【利:如果需要把cookie传递给服务器比较省心;弊:cookie比较多,每次请求都携带大量的信息进行传递,把请求变慢】
- cookie不稳定:清除历史记录、安全卫士清理垃圾可能会清除掉cookie;浏览器的隐式或者无痕模式不记录cookie
- localStorage
- 持久化存储,除非自己手动删除或者卸载浏览器
- 最多允许5MB内容
- 默认和浏览器没有关系,需要自己手动把它存的信息传递给浏览器
- 相对稳定
- sessionStorage
- 会话存储,页面关闭后存储的信息会消失
- 虚拟内存存储【例如:全局变量、vuex、pinia、redux】
- 页面关闭或者刷新后存储的信息会消失
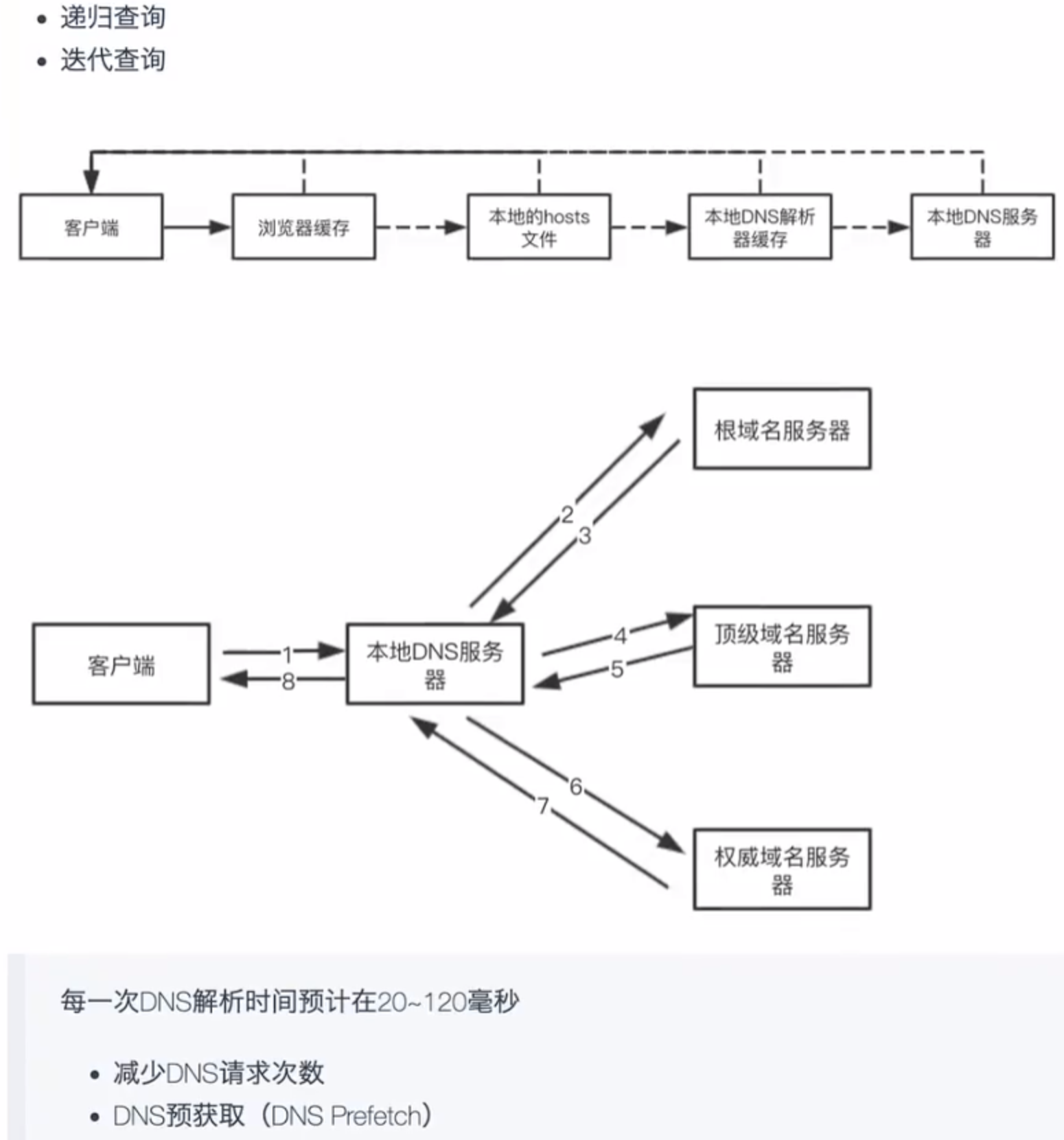
DNS解析【域名解析】
浏览器地址栏输入域名,会去DNS服务器上找到对应的外网IP,然后基于服务器的外网IP找到服务器
DNS解析记录也会有缓存,谷歌浏览器大概记录1min
前端优化:
-
理想情况:减少DNS解析的次数(所有资源尽可能部署到相同服务器的相同服务下)
-
真实情况:我们会把不同资源分到不同服务器部署【Web服务器、图片服务器、数据服务器...】
- 合理利用资源
- 提高并发数
导致域名解析的次数增加,DNS解析需要的时间也会增加
DNS Prefetch:DNS 预解析,利用 link 的异步性,在GUI渲染过程中,同时去解析域名

TCP三次握手
让客户端和服务器端建立一个稳定可靠的传输通道
TCP:稳定可靠,因为经过三次握手确定传输的稳定性,消耗时间久(常规业务)
UDP:快速传输,省略三次握手的步骤,直接进行传输;可能存在丢包的情况(一般用于直播业务)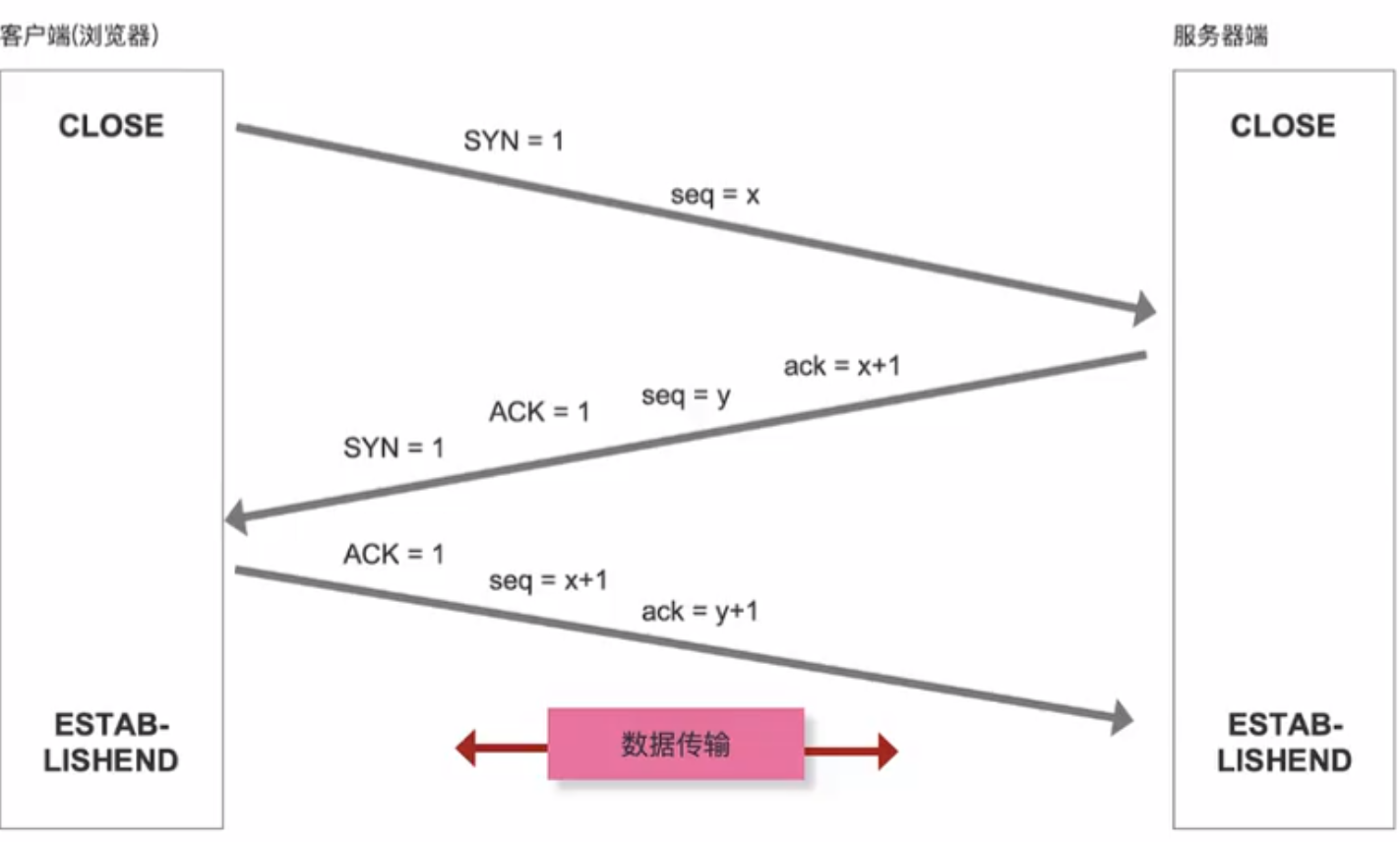
- seq序号,用来标识从TCP源端向目的发送的字节流,发起方发送数据时对此进行标记
- ack确认序号,只有ACK标志位为1时,确认序号字段才会有效,ack=seq+1
- 标识位
- SYN:发起一个新连接
- ACK:确认序号有效
- RST:重置连接
- FIN:释放一个连接
数据传输
HTTP请求报文:请求头、请求起始行、请求主体
HTTP响应报文:响应头、响应起始行、响应主体
TCP的四次挥手【断开客户端和服务器端的连接通道】
- HTTP/1.1版本开始,默认开启Connection:keep-alive长连接;当前数据传输完成后,建立的通道不会被立即释放,下一次请求,继续基于整个通道传输,减少TCP三握四挥的流程,加快数据传输的速度
- Nginx配置的时候可以设置keep-alive的周期【根据传输的数量或者设置时间】
- 在客户端把信息传递给服务器后,四次挥手就已经开始了
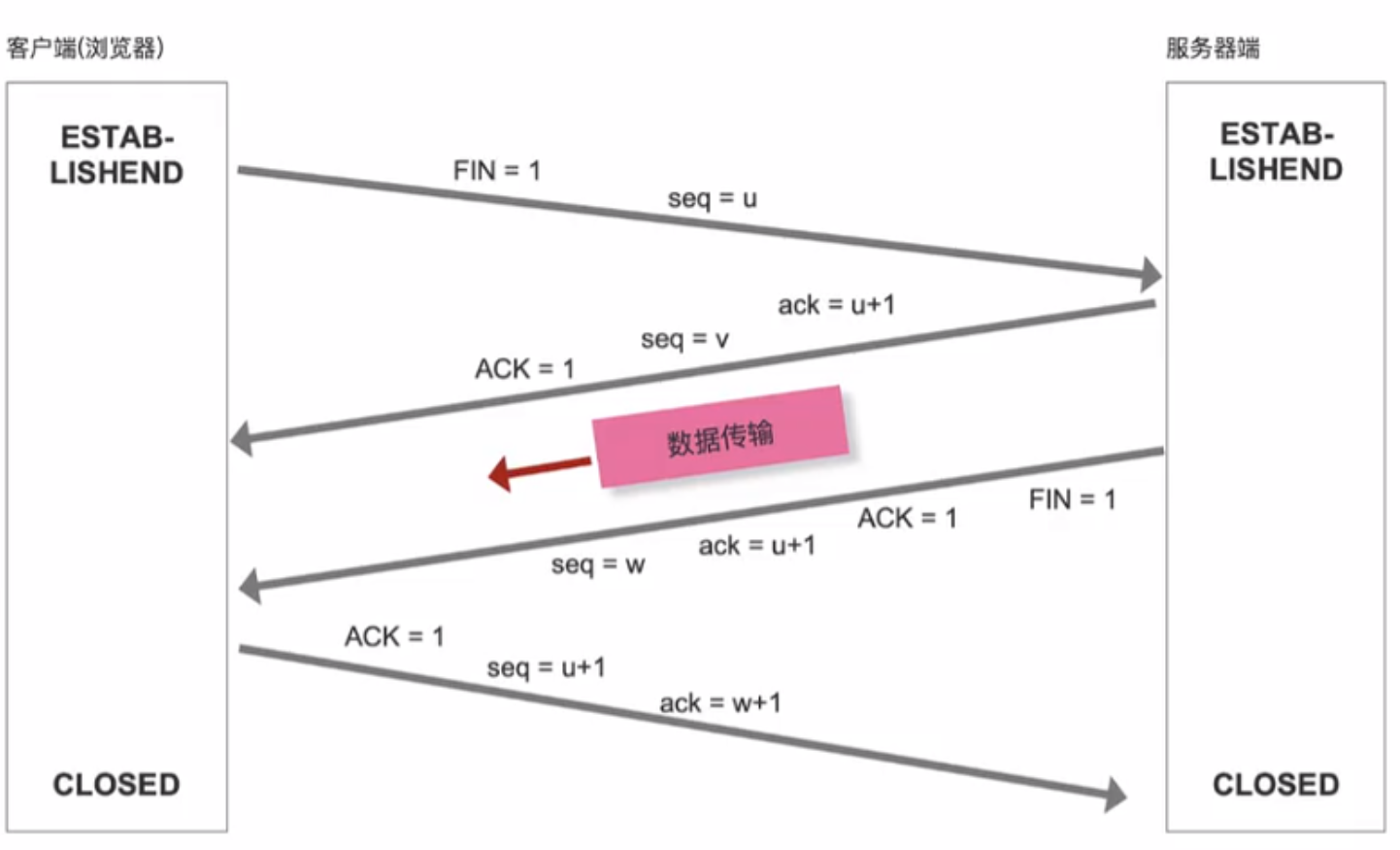
为什么连接的时候时三次握手,关闭的时候却是四次握手?
服务器端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文
但关闭连接时,当服务器收到FIN报文时,很可能并不会立即关闭连接,所以只能先回复一个ACK报文,告诉客户端:"你发的FIN报文我收到了",只有等服务器端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送,故需要四次握手。
页面渲染
- DOM TREE
- CSSOM TREE
- RENDER TREE
- Layout 【回流/重排】
- 分层
- Painting
扩展知识
性能优化汇总
利用缓存
- 对于静态资源文件实现强缓存和协商缓存(扩展:文件有更新,如何保证及时刷新?)
- 对于不经常更新的接口数据采用本地存储做数据缓存(扩展:cookie/localStorage /vuex|redux 区别?)
DNS优化
- 分服务器部署,增加HTTP并发性(导致DNS解析变慢)
- DNS Prefetch
TCP的三次握手和四次挥手
- Connection:keep-alive
数据传输
- 减少数据传输的大小
- 内容或者数据压缩(webpack等)
- 服务器端一定要开启GZIP压缩(一般能压缩60%左右)
- 大批量数据分批次请求(例如:下拉刷新或者分页,保证首次加载请求数据少)
- 减少页面第一次HTTP请求的渲染的次数
- 资源文件合并处理
- 字体图标
- 雪碧图 CSS-Sprit
- 图片的BASE64
CDN服务器"地域分布式"
采用HTTP2.0
网络优化是前端性能优化的中的重点内容,因为大部分的消耗都发生在网络层,尤其是第一次页面加载,如何减少等待时间很重要"减少白屏的效果和时间"
- LOADDING 人性化体验
- 骨架屏:客户端骨屏 +服务器骨架屏
- 图片延迟加载
HTTP1.0(1996) VS HTTP1.1(1999) VS HTTP2.0(2015)
HTTP1.0和HTTP1.1的一些区别
- 缓存处理,HTTP1.0 中主要使用 Last-Modified,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略: ETag,Cache-Contro...
- 带宽优化及网络连接的使用,HTTP1.1支持断点续传,即返回码是 206(PartialContent)
- 错误通知的管理,在 HTTP1.1 中新增了24个错误状态响应码、如 409(Conflict)表示请求的资源与资源的当前状态发生冲突: 410(Gone)表示服务器上的某个资源被永久性的删除...
- Host头处理,在 HTTP1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的 URL 并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机 (Multi-homed Web Servers),并且它们共享一个 IP 地址。HTTP1.1 的请求消息和响应消息都应支持 Host 头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)
- 长连接,HTTP1.1 中默认开启 Connection:keep-alive,一定程度上弥补了 HTTP1.0 每次请求都要创建连接的缺点
HTTP2.0 和 HTTP1.X 相比的新特性
- 新的二进制格式(Binary Format),HTTP1.x 的解析是基于文本,基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合,基于这种考虑 HTTP2.0 的协议解析决定采用二进制格式,实现方便且健壮
- header 压缩,HTP1.x 的 header 带有大量信息,而且每次都要重复发送,HTTP2.0 使用 encoder 来减少需要传输的 header 大小,通讯双方各自 cache 一份 header fields 表,既避免了重复 header 的传输,又减小了需要传输的大小
- 服务端推送(server push),例如我的网页有一个 style.css 的请求,在客户端收到 style.css 数据的同时,服务端会将 style.css 的文件推送给客户端,当客户端再次尝试获取 style.css 时就可以直接从缓存中获取到,不用再发请求了
- 多路复用(MultiPlexing)
- HTTP/1.0每次请求响应,建立一个TCP连接,用完关闭
- HTTP/1.1「长连接」 若千个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞
- HTTP/2 .0「多路复用」多个请求可同时在一个连接上并行执行,某个请求任务耗时严重,不会影响到其它连接的正常执行