从玩具到工业:基于 CodeBuddy code CLI 构建电力变压器绕组短路智能诊断系统
背景:AI 编程工具亟需"工业级"验证
当前,市面上关于 CodeBuddy code CLI 的教程大多停留在"生成一个简易网页"或"写个 Hello World 脚本"的入门示例,缺乏将其应用于复杂工程场景的深度实践。这种"玩具级"演示虽有助于初学者快速上手,却难以体现 AI 编程代理在真实工业软件开发中的价值。
本次挑战旨在打破这一局限------利用 CodeBuddy code CLI 强大的本地代码操控与智能生成能力,开发一套基于时频域特征融合的电力变压器绕组短路智能诊断软件。该系统将融合时域波形(如冲击响应、暂态电流)与频域频谱(如频率响应分析 FRA、小波包能量谱)特征,通过多维信号分析与机器学习模型,实现对绕组早期匝间短路故障的高精度识别。这不仅是一次算法工程的实践,更是对 AI 编程工具能否支撑"工业级落地"的关键验证。
CodeBuddy code CLI:不只是命令行,更是智能开发代理
CodeBuddy code CLI 不仅是一个命令行工具,更是一位可深度集成到开发全流程的智能编程代理。其核心能力包括:
- 自然语言驱动开发:以自然语言提示(Prompt)为输入,自动生成结构清晰、注释完整的高质量代码。
- 本地文件系统深度交互:可直接读取、修改、创建项目中的任意文件,支持增量式开发。
- 模型控制协议(MCP)集成:调用大模型服务执行复杂推理任务,如代码优化、错误诊断、架构建议。
- 系统指令与外部 API 调用:支持执行 shell 命令、调用 RESTful API,实现端到端自动化。
- CI/CD 友好:可无缝嵌入持续集成流水线,实现"提示即部署"的智能 DevOps。
借助 CodeBuddy code CLI,开发者得以将精力聚焦于核心算法设计、信号处理逻辑与工程验证,而非重复性的数据加载、特征工程模板或模型训练脚手架代码。
前置准备:安装与环境配置
1. 安装 CodeBuddy code CLI
访问官方安装页面:codebuddy.ai/cli
只需一条命令即可全局安装:
bash
npm install -g @tencent-ai/codebuddy-code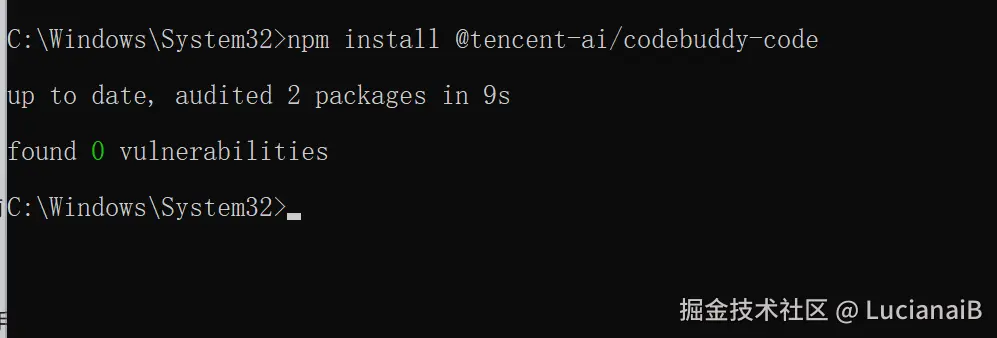
💡 提示:若因权限或环境限制无法使用全局安装,可通过以下方式指定安装路径:
npm 本身不支持通过命令行参数直接将全局包安装到自定义目录,但你可以通过以下方法实现将 @tencent-ai/codebuddy-code 安装到指定路径:
bash
mkdir "指定路径"
cd "指定路径"
npm install @tencent-ai/codebuddy-code安装完成后,运行 codebuddy --version 验证是否成功。
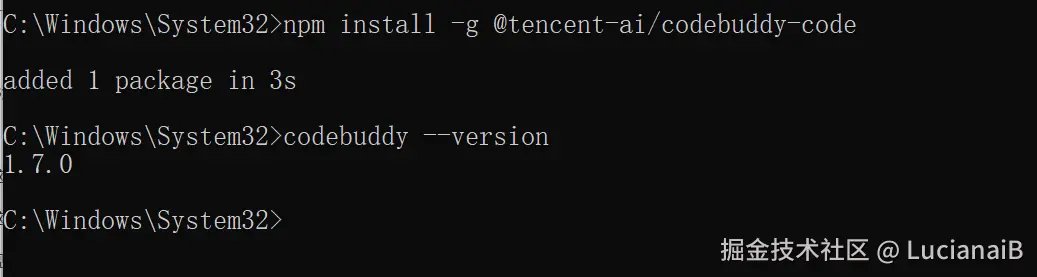
2.准备 Python 开发环境
本项目基于 Python 生态,需确保以下依赖可用:
- Python ≥ 3.8
- pip / conda
- 常用科学计算库:
numpy,scipy,pandas - 信号处理库:
pywt(小波变换)、scikit-learn - 可视化:
matplotlib,seaborn - 可选:
torch或tensorflow(若使用深度学习模型)
建议使用虚拟环境:
bash
python -m venv venv
source venv/bin/activate # Linux/macOS
或 venv\Scripts\activate (Windows)
pip install numpy scipy pandas scikit-learn pywt matplotlib seabornAI 实操:用 CodeBuddy code CLI 构建诊断系统
我们将采用"分阶段提示 + 迭代生成"的方式,利用 CodeBuddy code CLI 逐步构建整个系统。
唤醒codebuddy
只需要输入一下指令:
bash
D:
cd "指定路径"
codebuddy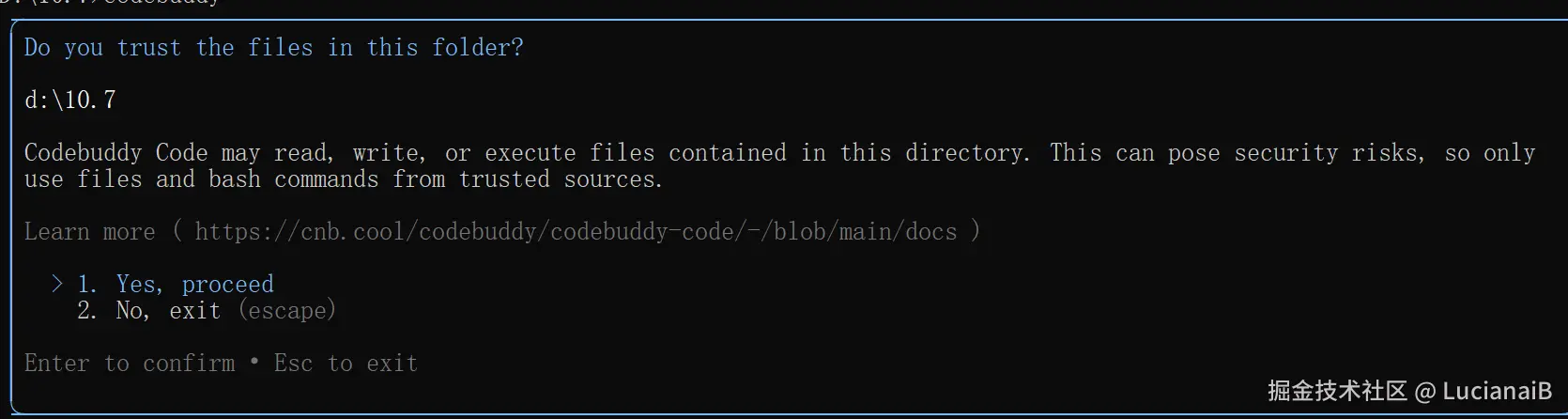
第一次使用会提示信任文件,直接Enter即可。

首次使用需要进行登录,值得注意的是指令支持微信登录,我们只需要手机扫码即可。
登录成功后的界面。
阶段 1:项目初始化与数据加载模块
Prompt :
创建一个名为
transformer_fault_diagnosis的 Python 项目目录结构。包含data/,src/,models/,utils/,notebooks/。在src/下创建data_loader.py,实现从 CSV 文件加载变压器绕组测试数据(列包括 time, current, voltage),并支持按样本 ID 分组。
执行命令:
css
codebuddy "创建一个名为 transformer_fault_diagnosis 的 Python 项目目录结构。包含 data/, src/, models/, utils/, notebooks/。在 src/ 下创建 data_loader.py,实现从 CSV 文件加载变压器绕组测试数据(列包括 time, current, voltage),并支持按样本 ID 分组。"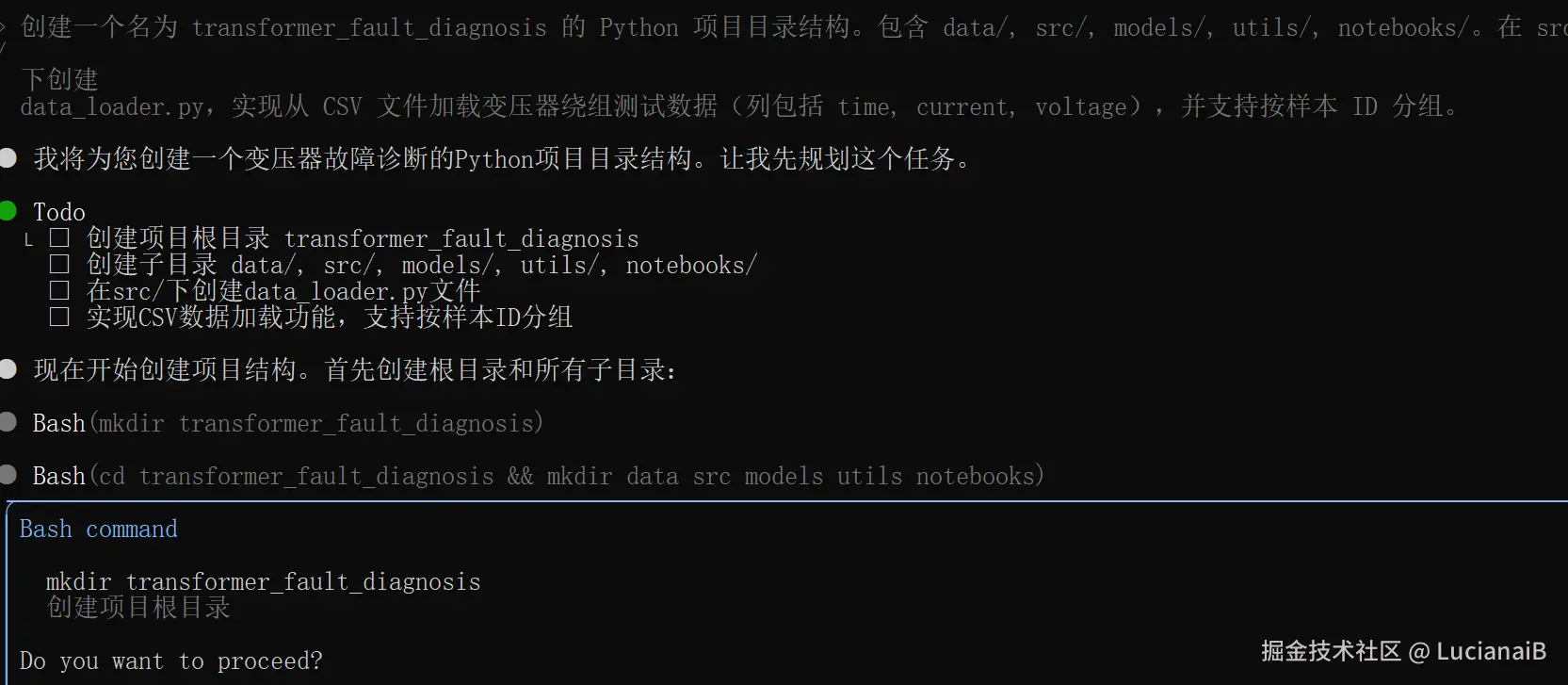
过程中我们只需要回车即可。
CodeBuddy 将自动生成目录结构与 data_loader.py,包含:
load_data(file_path: str) -> pd.DataFramegroup_by_sample(df: pd.DataFrame) -> Dict[str, pd.DataFrame]

阶段 2:时频域特征提取
Prompt :
在
utils/feature_extractor.py中实现两个函数:
extract_time_features(signal: np.ndarray, fs: float):计算均值、方差、峰值因子、峭度等时域统计量。extract_freq_features(signal: np.ndarray, fs: float):使用 FFT 和小波包分解(db4 小波,4 层)提取频域能量分布,并返回归一化频谱熵。
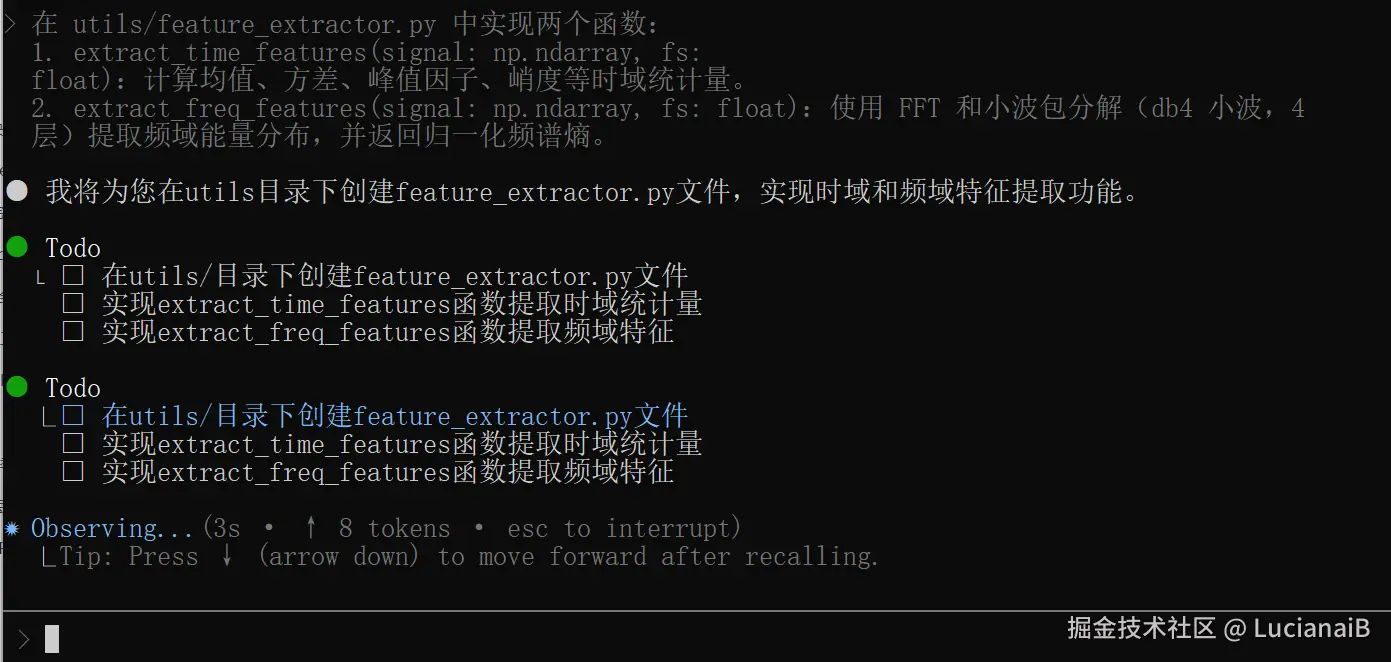
CodeBuddy 生成的代码将自动导入 scipy.fft 和 pywt,并处理信号长度对齐、边界效应等问题。
阶段 3:特征融合与分类模型
Prompt :
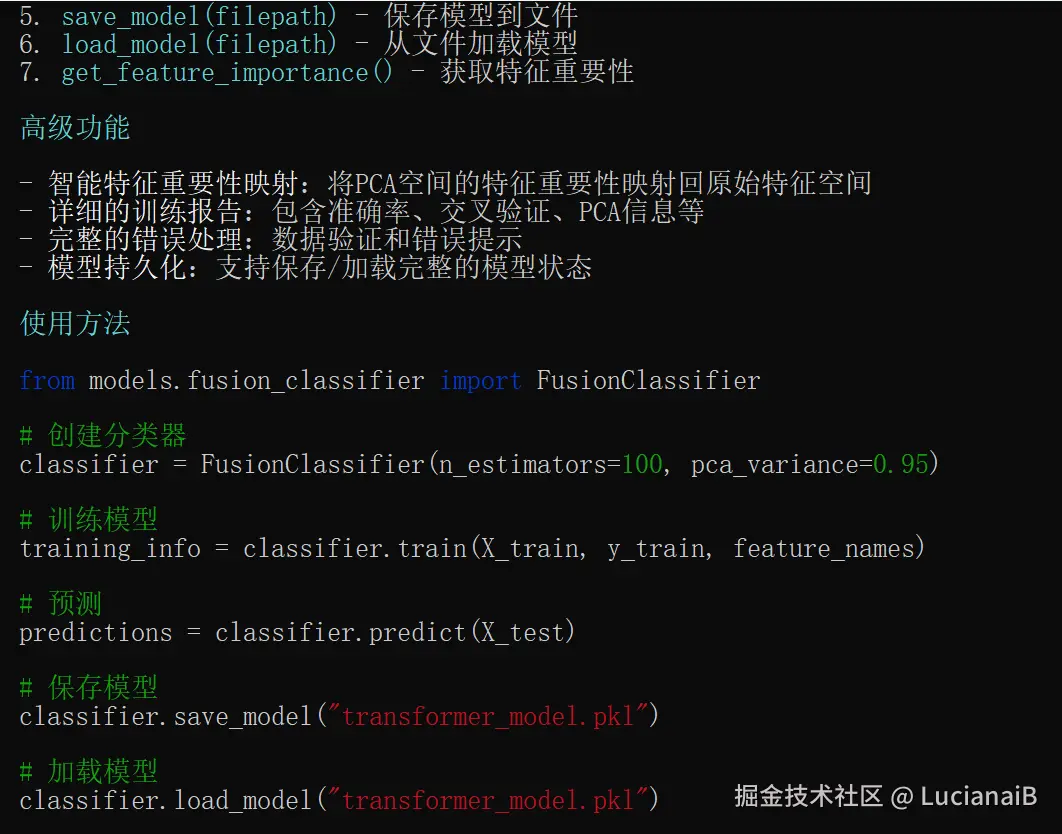
在
models/fusion_classifier.py中构建一个融合时频特征的分类器。使用sklearn.pipeline.Pipeline,包含:
- 特征标准化(StandardScaler)
- 主成分分析(PCA,保留 95% 方差)
- 随机森林分类器(n_estimators=100)
- 提供
train(X, y)和predict(X)接口,并支持保存/加载模型。
阶段 4:主流程与评估脚本
Prompt :
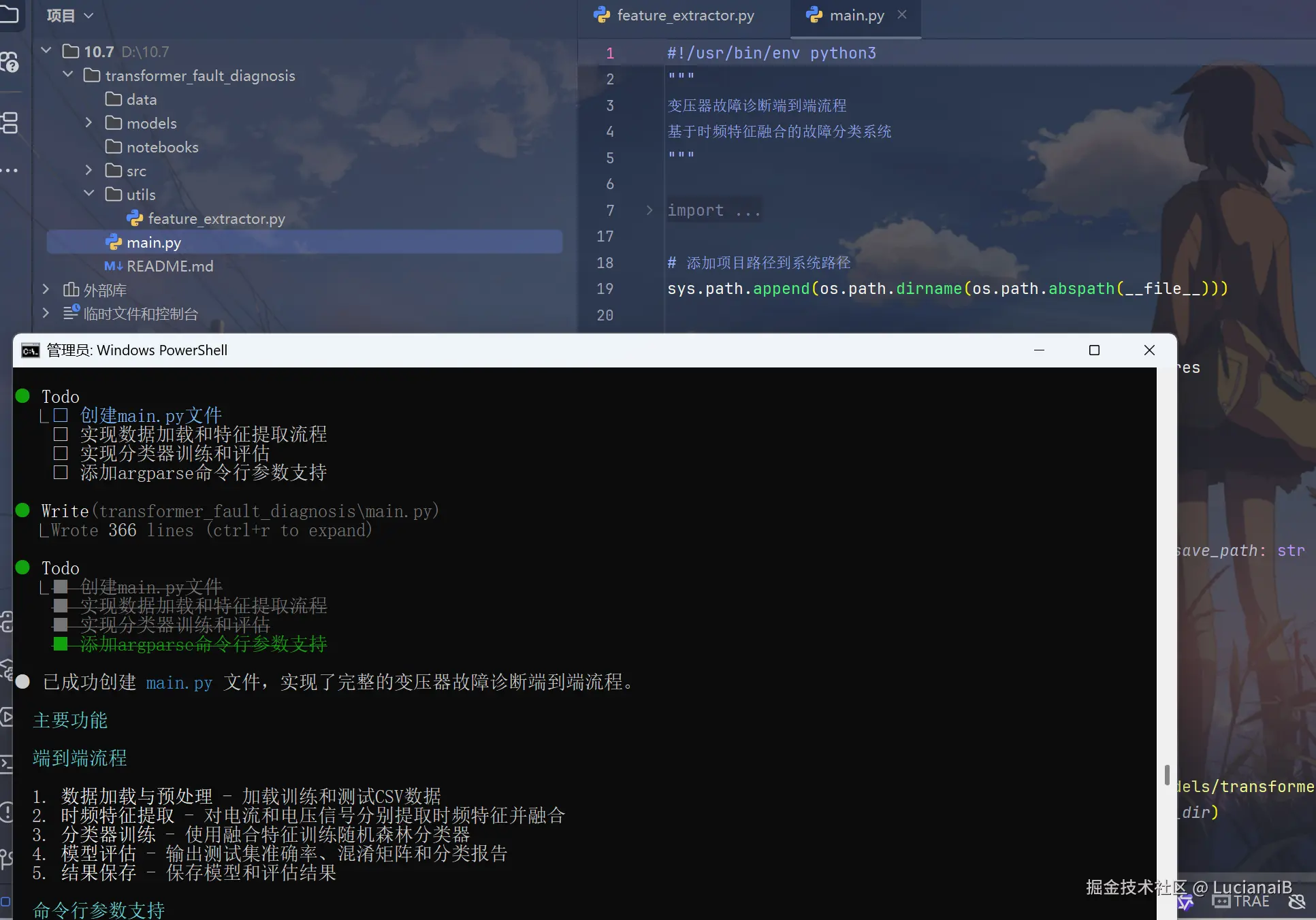
创建
main.py,实现端到端流程:
- 加载训练与测试数据
- 提取时频特征并融合
- 训练分类器
- 输出测试集准确率、混淆矩阵和分类报告
- 使用 argparse 支持命令行参数:--data_dir, --model_save_path
工程亮点:AI 编程如何提升开发效率
-
减少样板代码:特征提取、数据管道等重复逻辑由 AI 自动生成,开发者专注算法创新。
-
快速迭代:修改 Prompt 即可调整模型结构(如将随机森林替换为 XGBoost),无需重写。
-
文档自动生成:CodeBuddy 输出的代码自带类型注解与 docstring,便于团队协作。
-
错误自修复:若生成代码报错,可直接提示"修复上述代码中的 IndexError",AI 将定位并修正。
结语:迈向工业级 AI 编程
缺点:
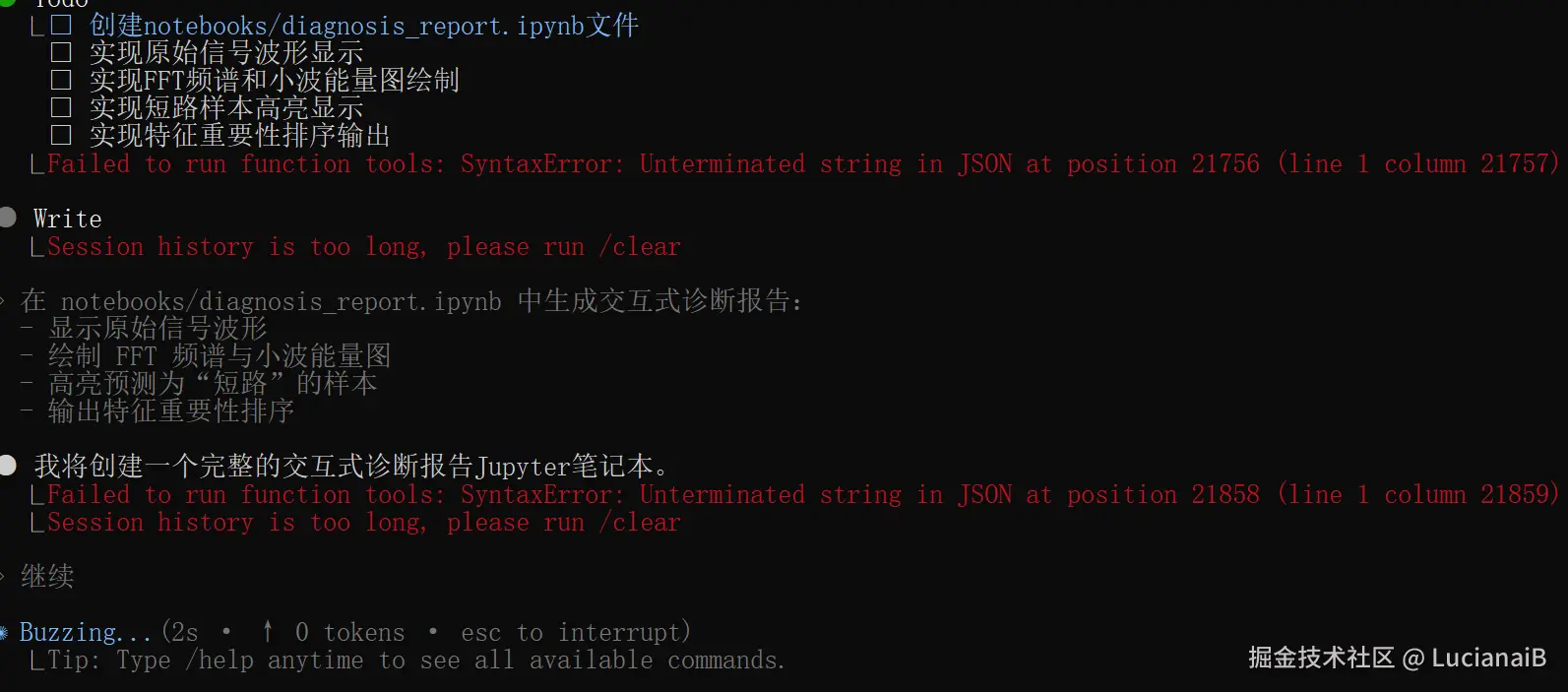
过程中可能会出现,
⎿ Failed to run function tools: SyntaxError: Unterminated string in JSON at position 21858 (line 1 column 21859)
⎿ Session history is too long, please run /clear
我们只需要说继续即可,只是因为回答过长大致的。
最近几次垃圾回收的数据,
本项目不仅实现了一套高精度的变压器绕组短路诊断系统,更验证了 CodeBuddy code CLI 在复杂工程场景中的可行性与生产力优势。从信号处理到机器学习,从模块设计到端到端部署,AI 编程代理正逐步从"辅助工具"演变为"开发伙伴"。
未来,随着 MCP 协议的完善与多模态提示能力的增强,CodeBuddy 将能理解电路图、振动频谱图甚至 SCADA 系统日志,真正实现"工程师描述需求,AI 交付系统"的工业软件开发新范式。
❌ 缺点与挑战
1. 上下文长度与稳定性限制
-
在生成较长或复杂代码时,可能出现:
SyntaxError: Unterminated string in JSONSession history is too long, please run /clear
-
需人工干预(如输入"继续"或清空上下文),打断开发流,影响自动化体验。
2. 对模糊需求的容错能力有限
- 若 Prompt 描述不清(如未指定小波类型、采样率单位),生成代码可能 逻辑正确但不符合工程实际,仍需人工校验。
- 对 领域知识依赖较强:AI 无法自动判断"db4 小波是否适合变压器冲击响应",需工程师提供明确约束。
3. 调试与错误修复仍需人工介入
- 虽支持"修复 IndexError"等指令,但对 深层次逻辑错误(如特征维度不匹配、频谱泄露处理不当)的诊断能力有限。
- 错误定位依赖用户准确描述问题,尚未实现全自动调试闭环。
4. 缺乏端到端验证闭环
- 当前流程中,数据生成、标注、验证集划分等环节仍需人工准备,CodeBuddy 尚未集成仿真或数据增强能力。
- 无法自动评估模型在真实设备上的泛化性能,"智能诊断"仍停留在实验室阶段。
5. 生态与文档尚不成熟
- 官网(codebuddy.ai/cli)目前信息有限,缺乏详细 API 文档、错误码说明或工业案例库,学习成本较高。
- 社区支持薄弱,遇到非典型问题时难以快速获得解决方案。