在今天的文章中,我来详细描述如上在 Elasticsearch 中使用推理端点,并展示进行语义搜索的。更多阅读,请参阅 "Elasticsearch:Semantic text 字段类型"。在本次展示中,我讲使用 Elastic Stack 9.1.4 版本来进行展示。
安装
Elasticsearch 及 Kibana
如果你还没有安装好你自己的 Elasticsearch 及 Kibana,那么请参考如下的文章来进行安装:
在安装的时候,请参考 Elastic Stack 8.x/9.x 的安装指南来进行。在本次安装中,我将使用 Elastic Stack 9.1.2 来进行展示。
首次安装 Elasticsearch 的时候,我们可以看到如下的画面:
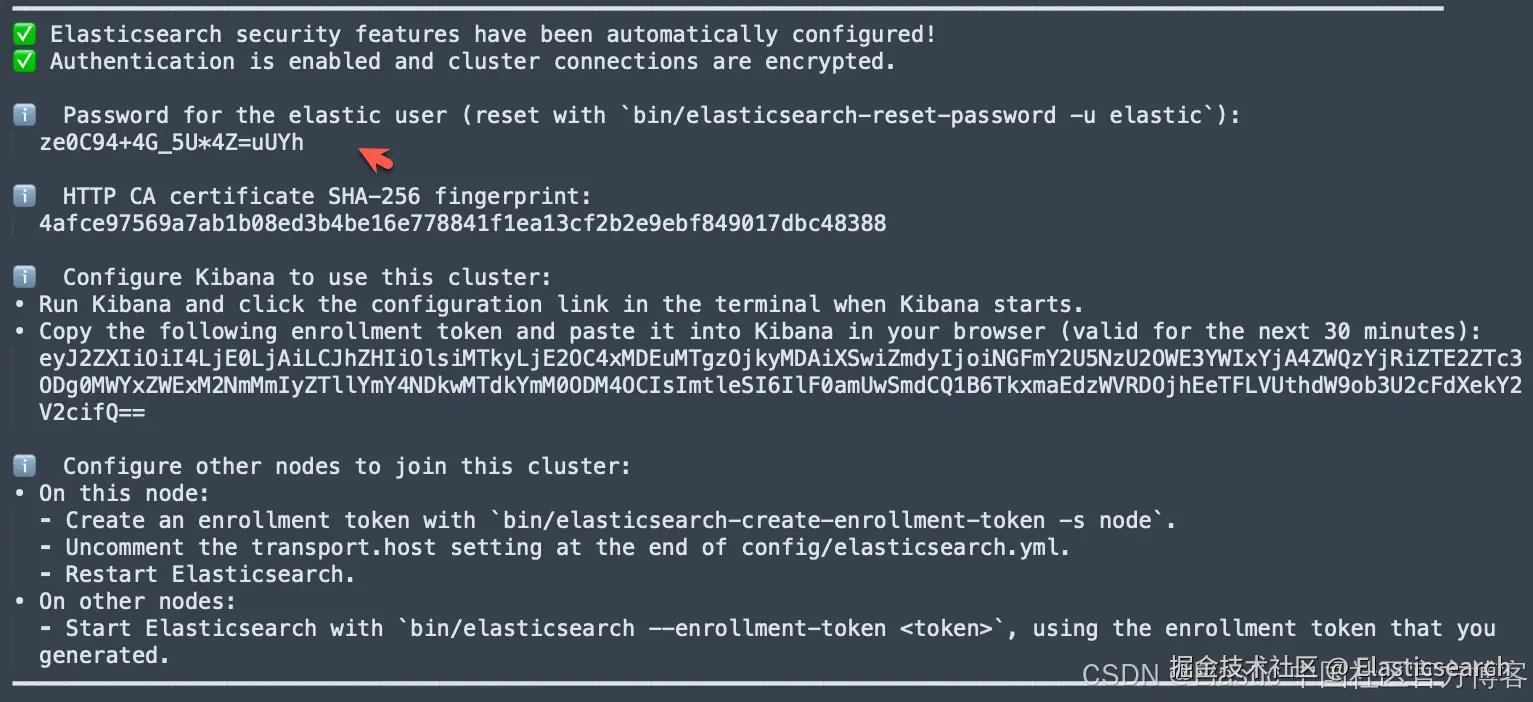
我们按照上面的链接把 Elasticsearch 及 Kibana 安装好。
下周 ELSER 及 E5 模型
在我们如下的练习中,我们将下载 Elastic 自带的模型:ELSER(稀疏向量) 及 E5(密集向量)。由于这两个嵌入模型是安装在 Elasticsearch 的机器学习节点上的,我们需要启动白金试用。特别值得指出的是:如果你不使用 Elasticsearch 机器学习节点来向量化你的语料,那么你不必启动白金试用。你可以在 Python 代码里实现数据的向量化,或者使用第三方的端点来进行向量化,而只把 Elasticsearch 当做一个向量数据库来使用!
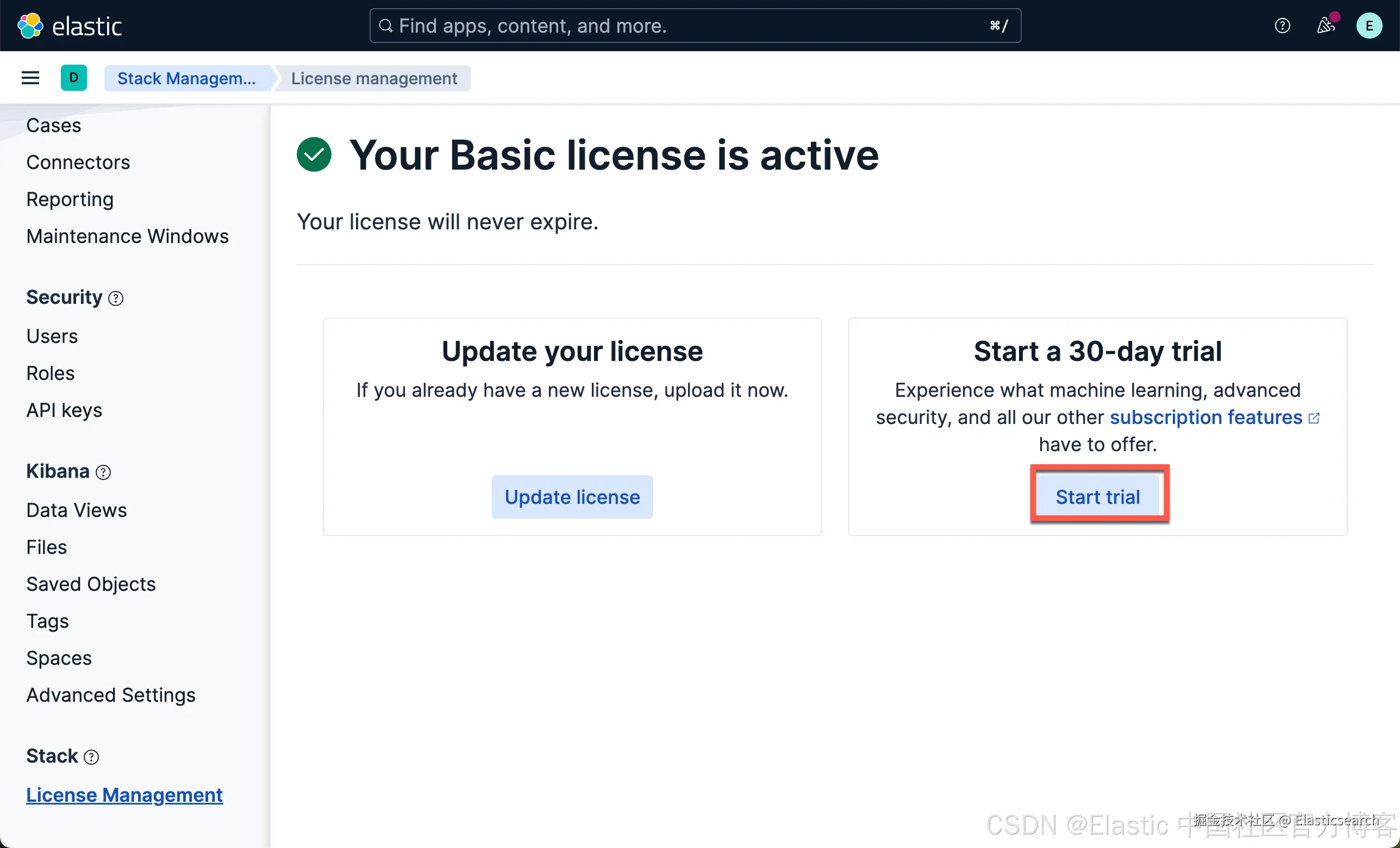
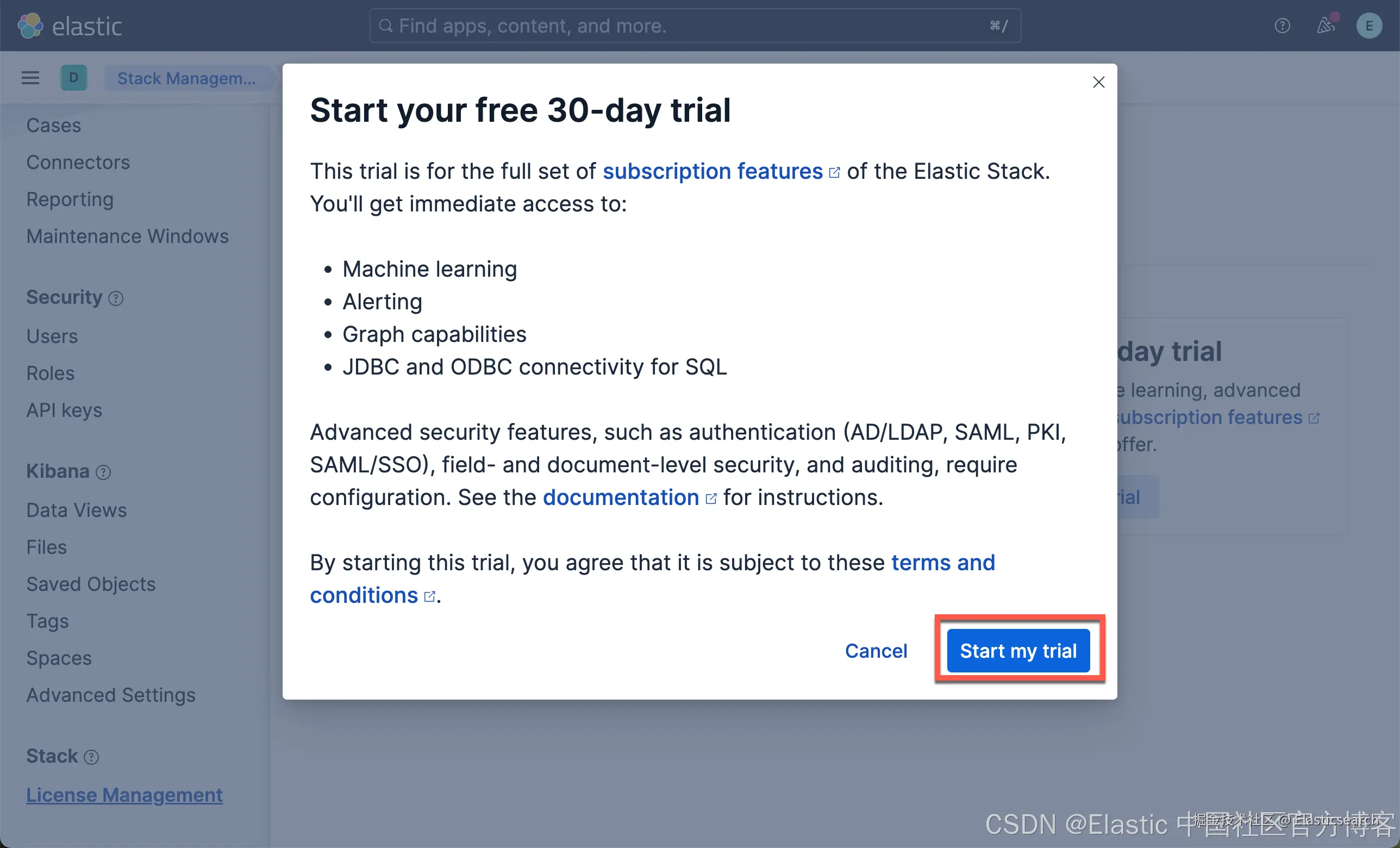
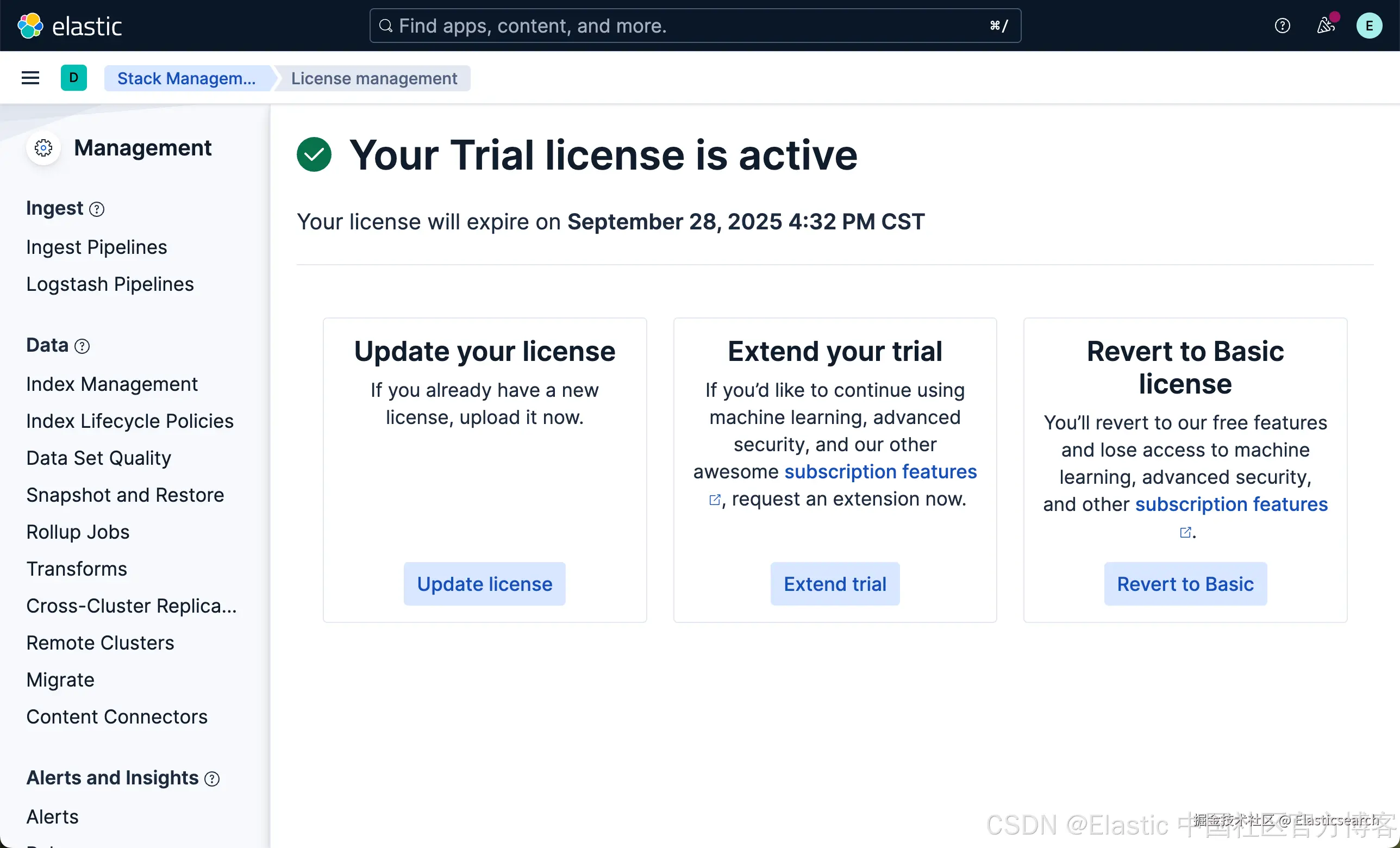
这样我们就启动了白金试用。
我们现在下载 ELSER 及 E5 嵌入模型:
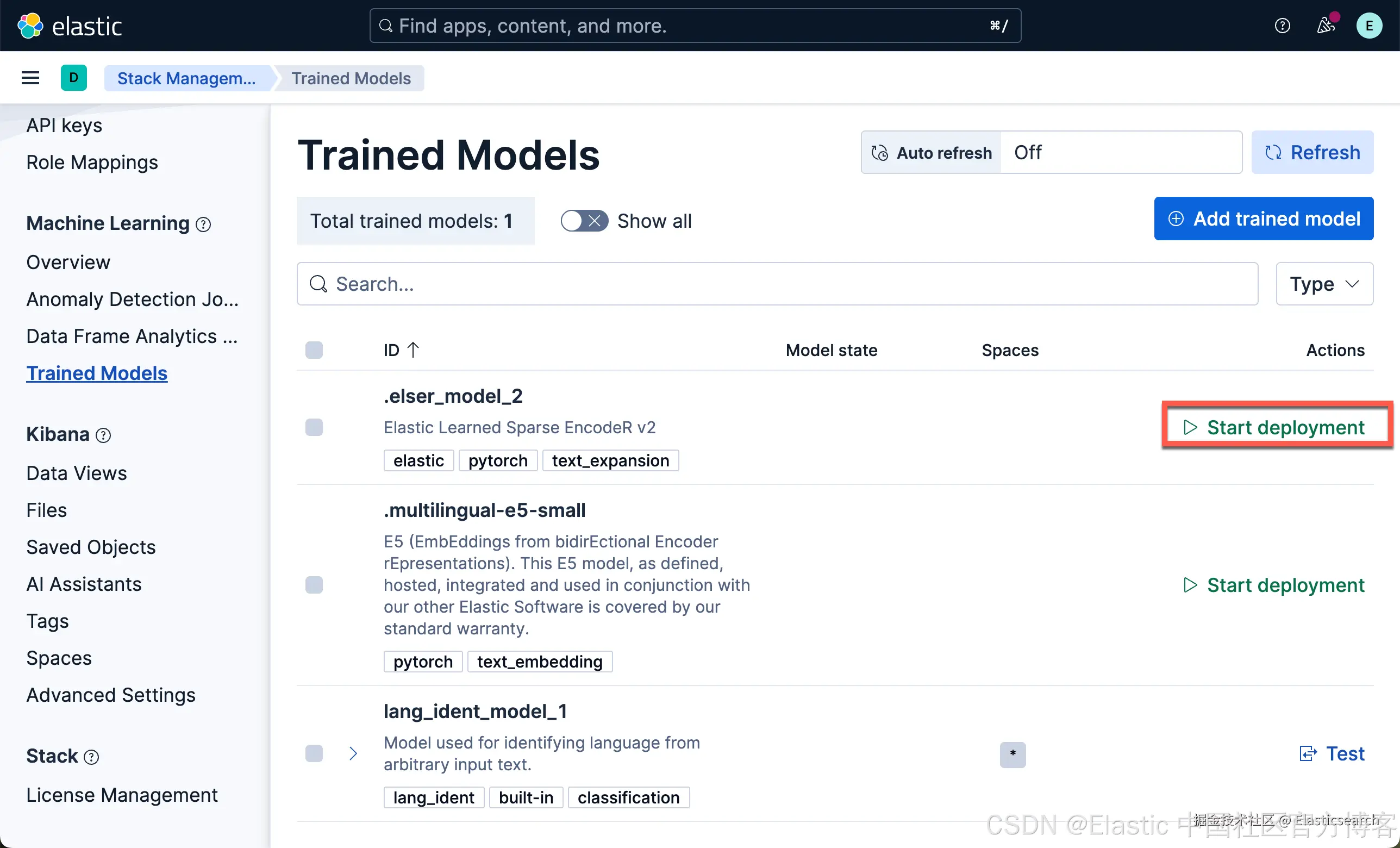
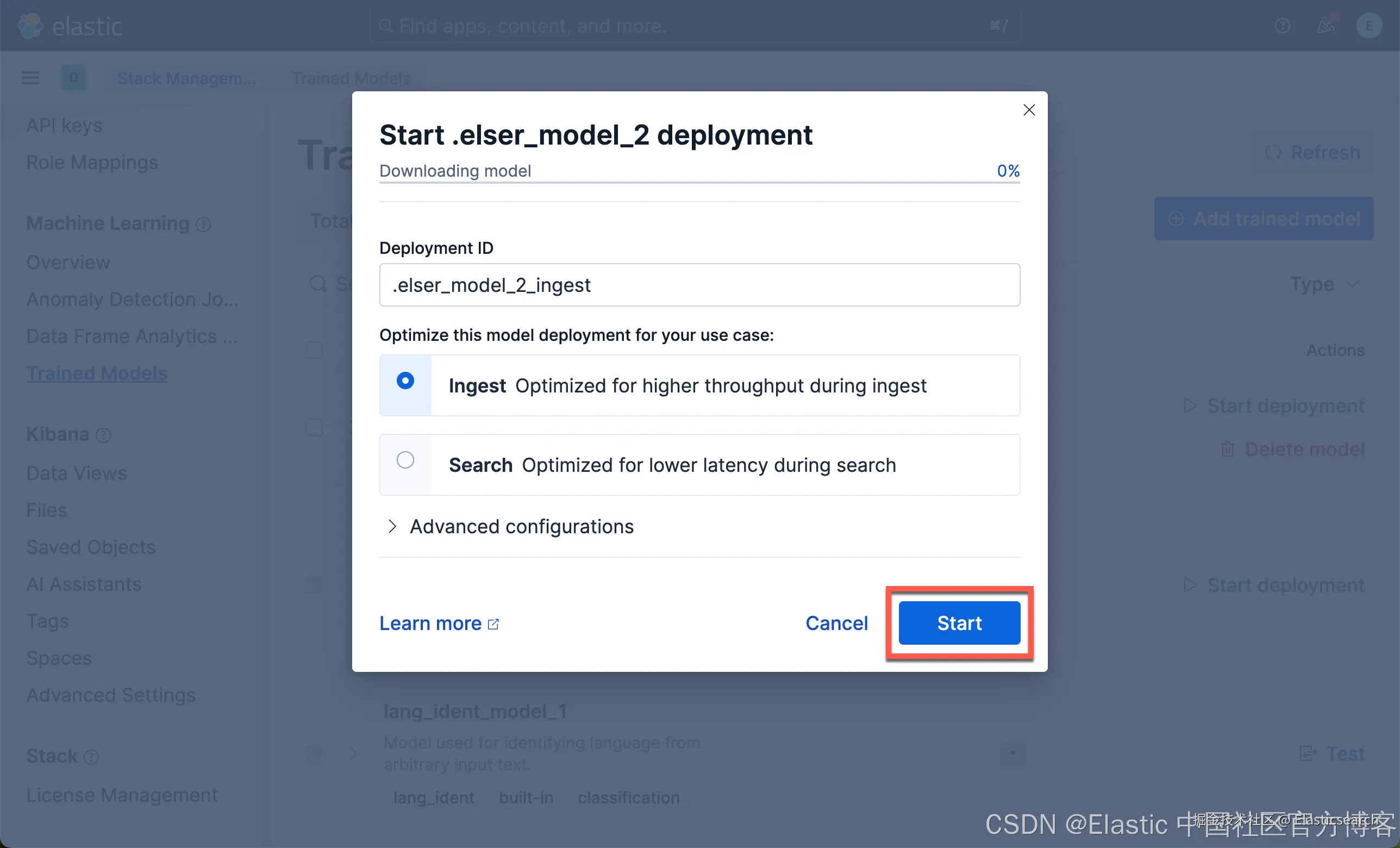
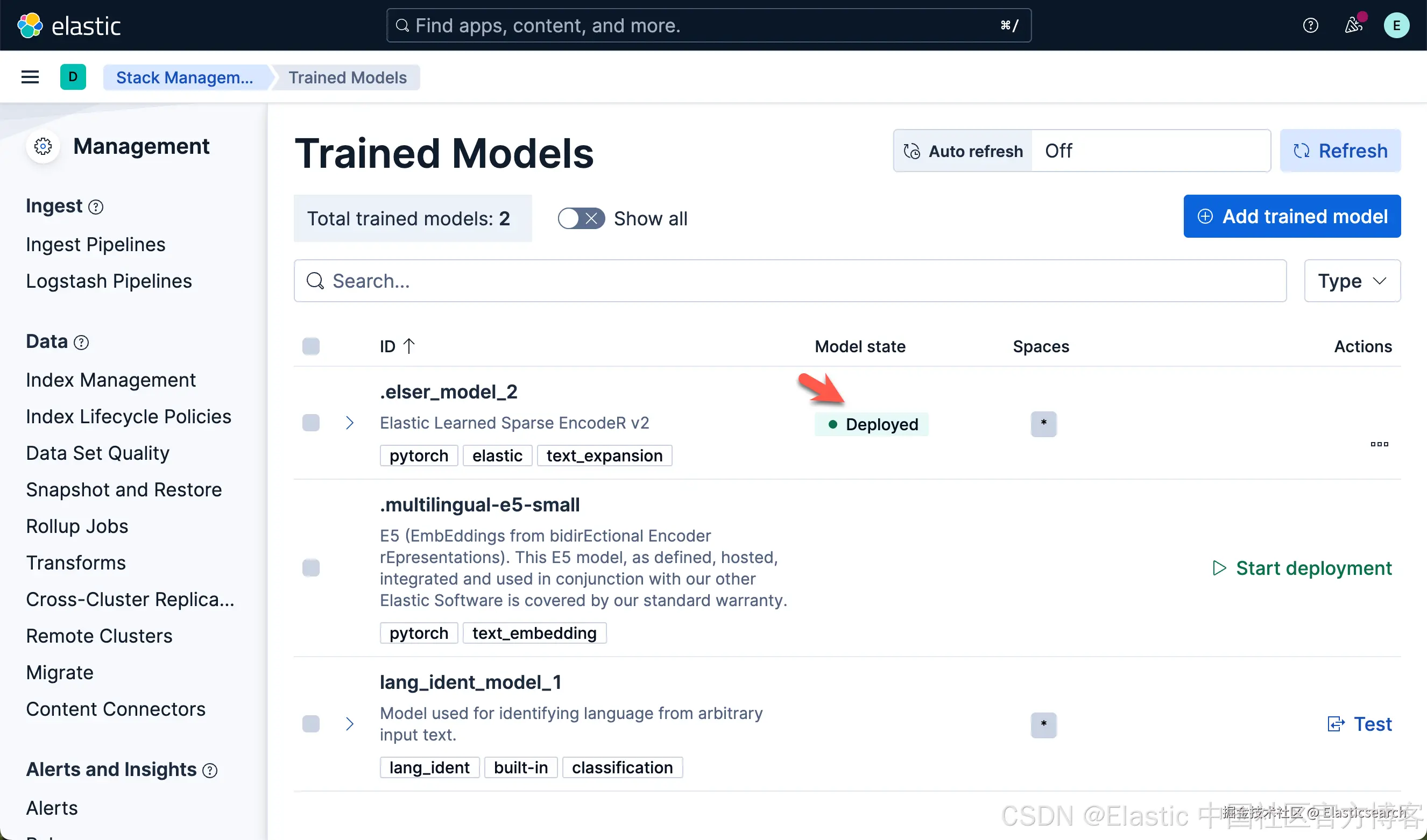
我们按照同样的方法来部署 E5 模型:
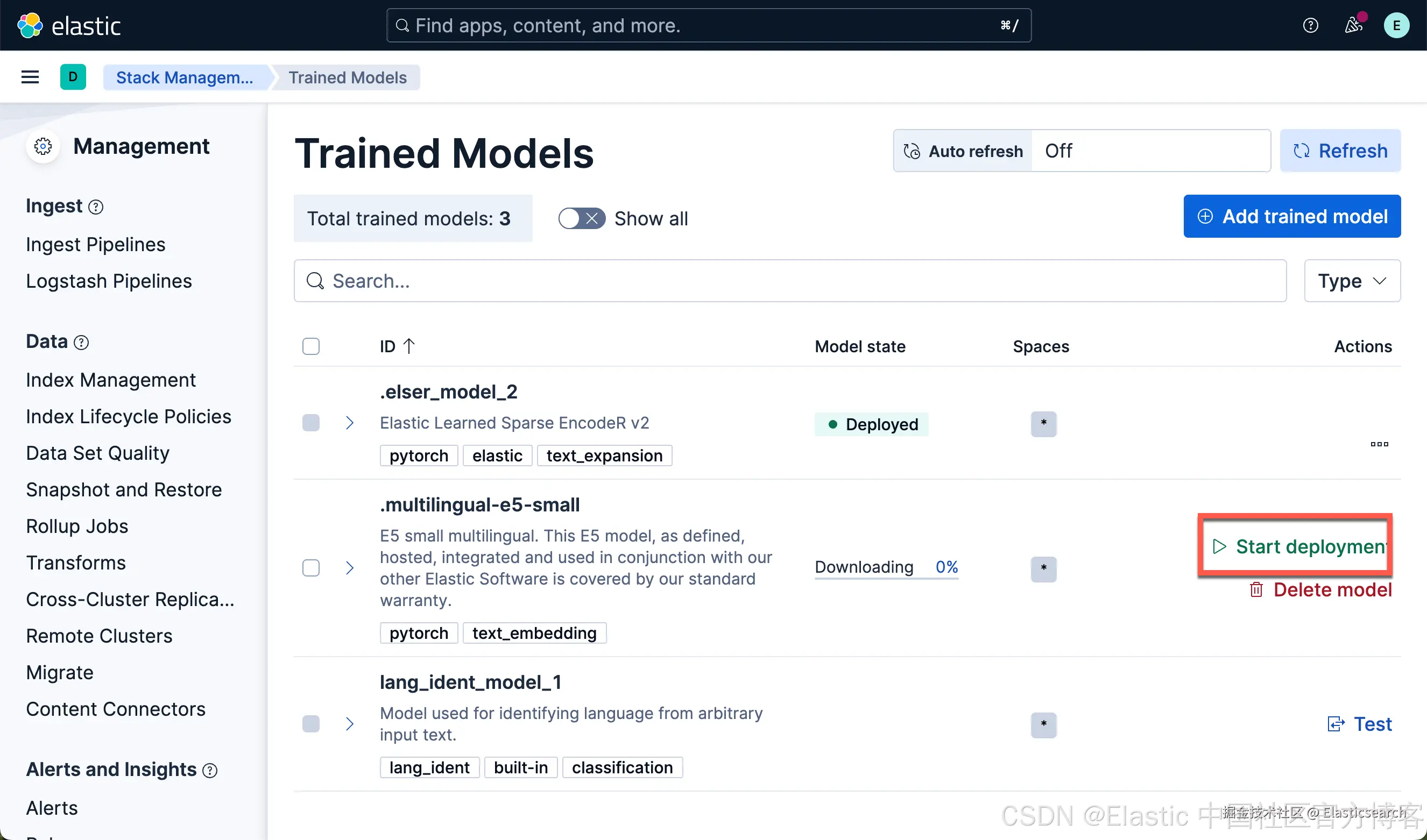
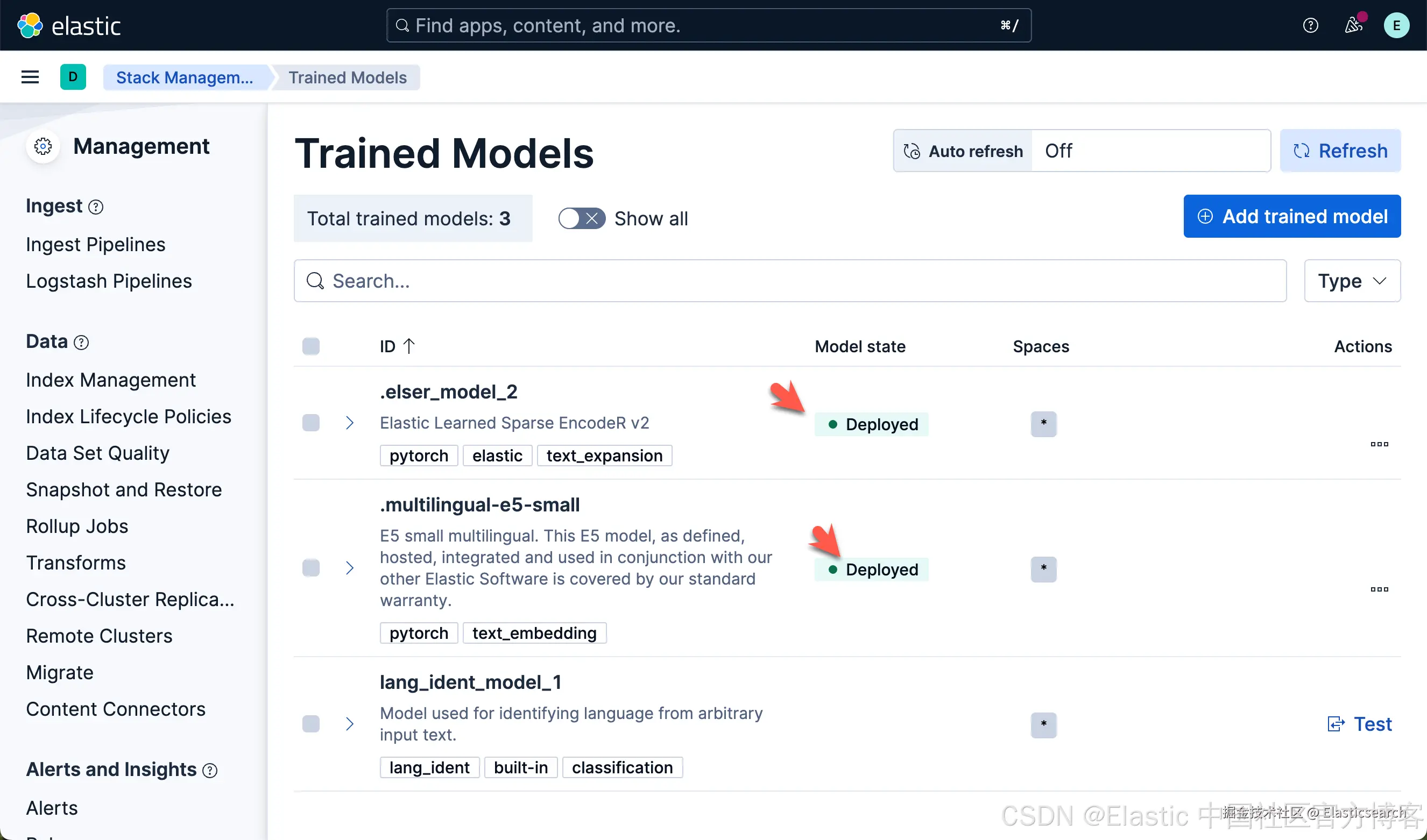
我们可以看到上面的两个模型都已经部署好了。如果你想部署其它的模型,可以参考文章 "Elasticsearch:如何部署 NLP:文本嵌入和向量搜索" 使用 eland 来上传模型。
我们可以通过如下的命令来查看已经创建好的 inference endpoints:
bash
`GET _inference/_all`AI写代码
bash
`
1. {
2. "endpoints": [
3. {
4. "inference_id": ".elser-2-elasticsearch",
5. "task_type": "sparse_embedding",
6. "service": "elasticsearch",
7. "service_settings": {
8. "num_allocations": 0,
9. "num_threads": 1,
10. "model_id": ".elser_model_2",
11. "adaptive_allocations": {
12. "enabled": true,
13. "min_number_of_allocations": 0,
14. "max_number_of_allocations": 32
15. }
16. },
17. "chunking_settings": {
18. "strategy": "sentence",
19. "max_chunk_size": 250,
20. "sentence_overlap": 1
21. }
22. },
23. {
24. "inference_id": ".multilingual-e5-small-elasticsearch",
25. "task_type": "text_embedding",
26. "service": "elasticsearch",
27. "service_settings": {
28. "num_threads": 1,
29. "model_id": ".multilingual-e5-small",
30. "adaptive_allocations": {
31. "enabled": true,
32. "min_number_of_allocations": 0,
33. "max_number_of_allocations": 32
34. }
35. },
36. "chunking_settings": {
37. "strategy": "sentence",
38. "max_chunk_size": 250,
39. "sentence_overlap": 1
40. }
41. },
42. {
43. "inference_id": ".rerank-v1-elasticsearch",
44. "task_type": "rerank",
45. "service": "elasticsearch",
46. "service_settings": {
47. "num_threads": 1,
48. "model_id": ".rerank-v1",
49. "adaptive_allocations": {
50. "enabled": true,
51. "min_number_of_allocations": 0,
52. "max_number_of_allocations": 32
53. }
54. },
55. "task_settings": {
56. "return_documents": true
57. }
58. }
59. ]
60. }
`AI写代码从上面的输出中,我们可以看到有几个已经被预置的 endpoints。我们可以使用如下的命令来创建我们自己的 endpoint:
bash
`
1. PUT _inference/text_embedding/multilingual_embeddings
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": ".multilingual-e5-small",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码在上面,我们创建了一个叫做 multilingual_embeddings 的 endpoint。如果不是特别要求,我们可以使用系统为我们提供的 .multilingual-e5-small-elasticsearch 端点。
我们可以使用如下的方法来创建一个 ESLER 的 endpoint:
bash
`
1. PUT _inference/sparse_embedding/my-elser-model
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": ".elser_model_2",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码我们可以通过如下的方式来删除一个已经创建好的推理端点:
bash
`DELETE _inference/my-elser-model`AI写代码定义变量
我们可以参考 "Kibana:如何设置变量并应用它们" 来定义变量:
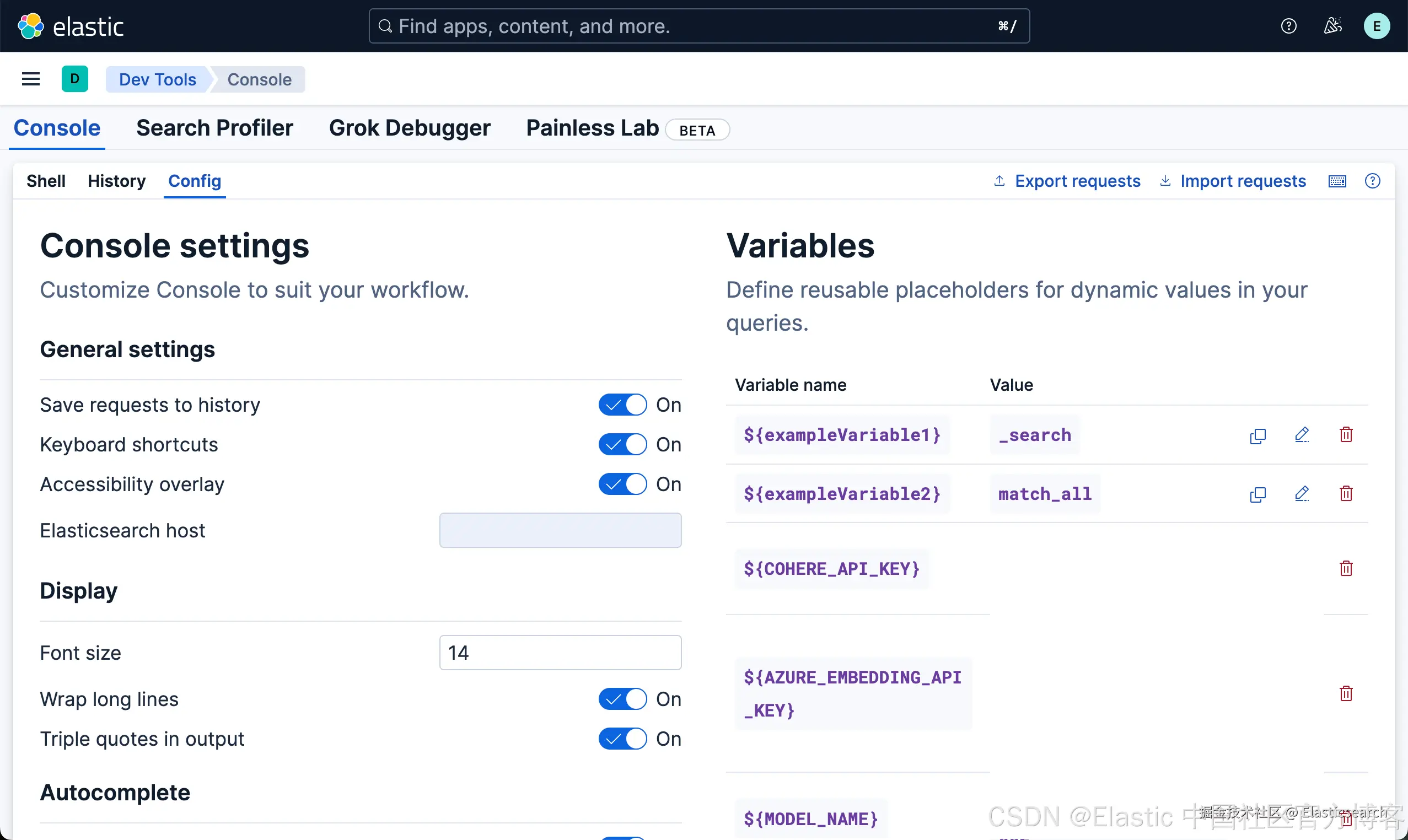
如上所示,我们在 "Config" 中定义如上所示的变量。
默认和自定义 endpoints
你可以在 semantic_text 字段中使用预配置的 endpoints,这对大多数用例很理想,或者创建自定义 endpoints 并在字段映射中引用它们。
展示
ELSER
我们可以按照如下的命令来创建一个叫做 my-elser-model 的 ELSER 推理端点。
bash
`
1. PUT _inference/sparse_embedding/my-elser-model
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": ".elser_model_2",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码运行完上面的命令后,我们可以使用如下的命令来查看:
bash
`GET _inference/_all`AI写代码
bash
`
1. {
2. "endpoints": [
3. {
4. "inference_id": ".elser-2-elasticsearch",
5. "task_type": "sparse_embedding",
6. "service": "elasticsearch",
7. "service_settings": {
8. "num_threads": 1,
9. "model_id": ".elser_model_2",
10. "adaptive_allocations": {
11. "enabled": true,
12. "min_number_of_allocations": 0,
13. "max_number_of_allocations": 32
14. }
15. },
16. "chunking_settings": {
17. "strategy": "sentence",
18. "max_chunk_size": 250,
19. "sentence_overlap": 1
20. }
21. },
22. {
23. "inference_id": ".multilingual-e5-small-elasticsearch",
24. "task_type": "text_embedding",
25. "service": "elasticsearch",
26. "service_settings": {
27. "num_threads": 1,
28. "model_id": ".multilingual-e5-small",
29. "adaptive_allocations": {
30. "enabled": true,
31. "min_number_of_allocations": 0,
32. "max_number_of_allocations": 32
33. }
34. },
35. "chunking_settings": {
36. "strategy": "sentence",
37. "max_chunk_size": 250,
38. "sentence_overlap": 1
39. }
40. },
41. {
42. "inference_id": ".rerank-v1-elasticsearch",
43. "task_type": "rerank",
44. "service": "elasticsearch",
45. "service_settings": {
46. "num_threads": 1,
47. "model_id": ".rerank-v1",
48. "adaptive_allocations": {
49. "enabled": true,
50. "min_number_of_allocations": 0,
51. "max_number_of_allocations": 32
52. }
53. },
54. "task_settings": {
55. "return_documents": true
56. }
57. },
58. {
59. "inference_id": "elser-endpoint",
60. "task_type": "sparse_embedding",
61. "service": "elasticsearch",
62. "service_settings": {
63. "num_allocations": 1,
64. "num_threads": 1,
65. "model_id": ".elser_model_2"
66. },
67. "chunking_settings": {
68. "strategy": "sentence",
69. "max_chunk_size": 250,
70. "sentence_overlap": 1
71. }
72. },
73. {
74. "inference_id": "my-elser-model",
75. "task_type": "sparse_embedding",
76. "service": "elasticsearch",
77. "service_settings": {
78. "num_allocations": 1,
79. "num_threads": 1,
80. "model_id": ".elser_model_2"
81. },
82. "chunking_settings": {
83. "strategy": "sentence",
84. "max_chunk_size": 250,
85. "sentence_overlap": 1
86. }
87. }
88. ]
89. }
`AI写代码如上所示,我们可以看到已经创建的 my-elser-model 推理端点。我们也可以采用带有参数的方法来创建推理端点:
bash
`
1. PUT _inference/sparse_embedding/my-elser-model
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "adaptive_allocations": {
6. "enabled": true,
7. "min_number_of_allocations": 1,
8. "max_number_of_allocations": 10
9. },
10. "num_threads": 1,
11. "model_id": ".elser_model_2"
12. }
13. }
`AI写代码我们也可以使用如下的命令来确认推理端点已经被成功创建:
bash
`GET _inference/my-elser-model`AI写代码或者:
bash
`GET _inference/sparse_embedding/my-elser-model`AI写代码
bash
`
1. {
2. "endpoints": [
3. {
4. "inference_id": "my-elser-model",
5. "task_type": "sparse_embedding",
6. "service": "elasticsearch",
7. "service_settings": {
8. "num_allocations": 1,
9. "num_threads": 1,
10. "model_id": ".elser_model_2"
11. },
12. "chunking_settings": {
13. "strategy": "sentence",
14. "max_chunk_size": 250,
15. "sentence_overlap": 1
16. }
17. }
18. ]
19. }
`AI写代码因为 .elser_model_2 本身的 metadata 数据含有信息表面它是 sparse vector,上面不含 sparse_embedding 路径的 API 接口更加方便简捷。
接下来,我们使用如下的命令来进行测试我们刚才创建的 ELSER 推理端点:
markdown
`
1. POST _inference/sparse_embedding/my-elser-model
2. {
3. "input": "The sky above the port was the color of television tuned to a dead channel."
4. }
`AI写代码上面的命令返回的结果是:
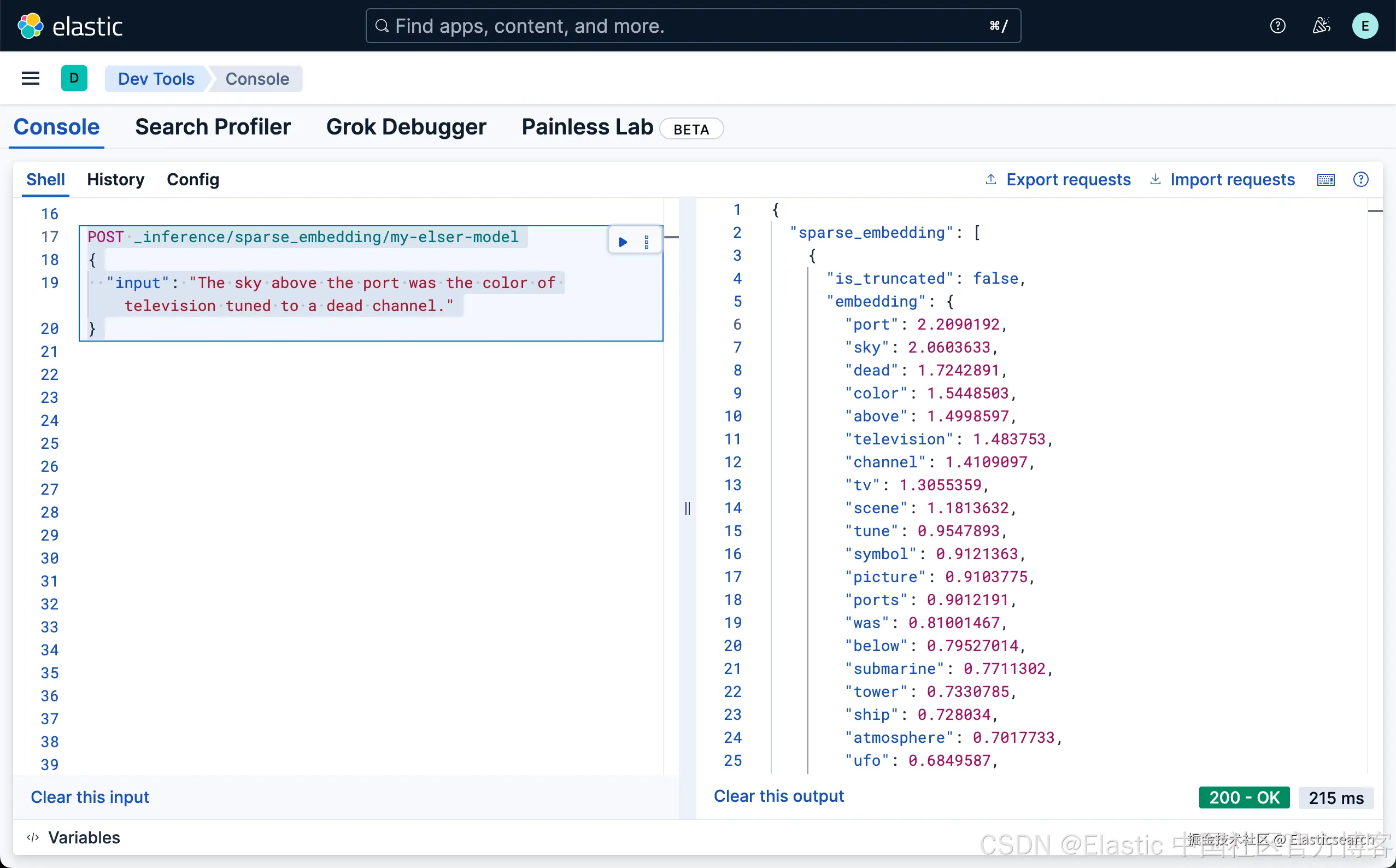
从上面的输出结果,我们可以看出来,ELSER 是通过文本扩展来完成向量的输出,比如 television 通过文字扩展的方法可以联系到 tv,甚至和 channel 也有关联。每个词的关联度,还有一个系数。
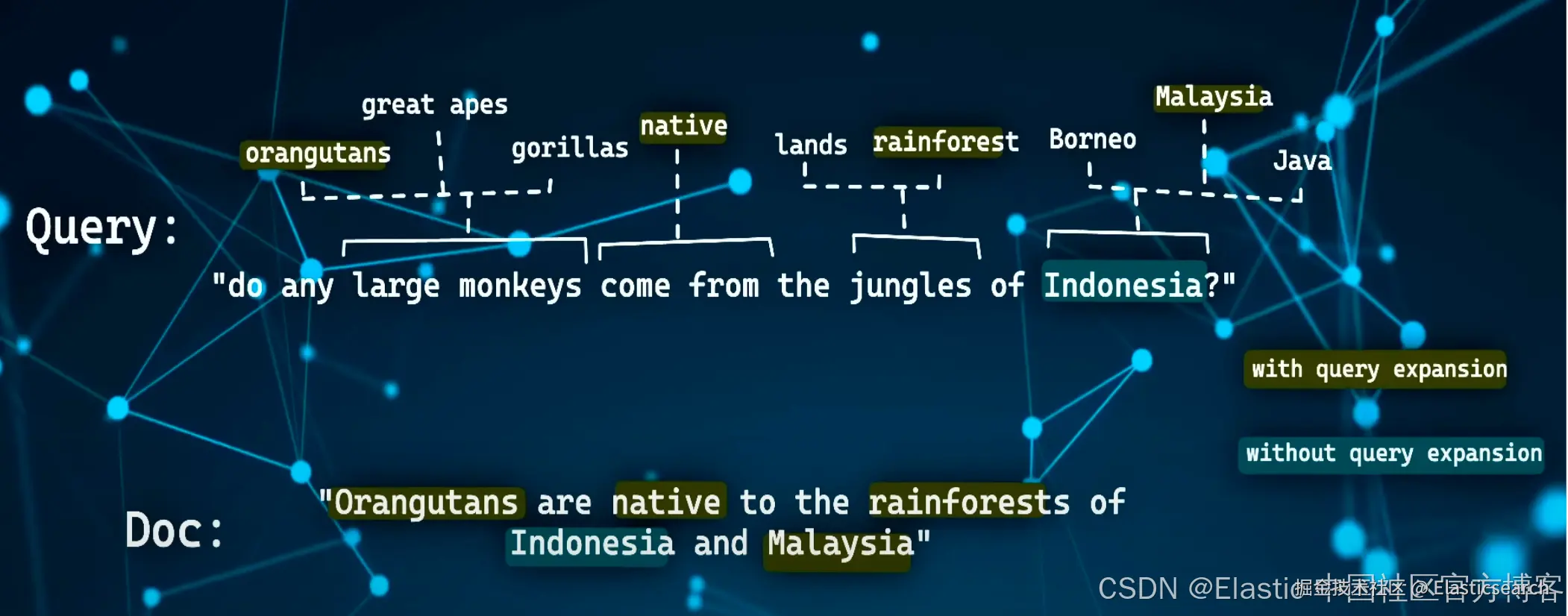
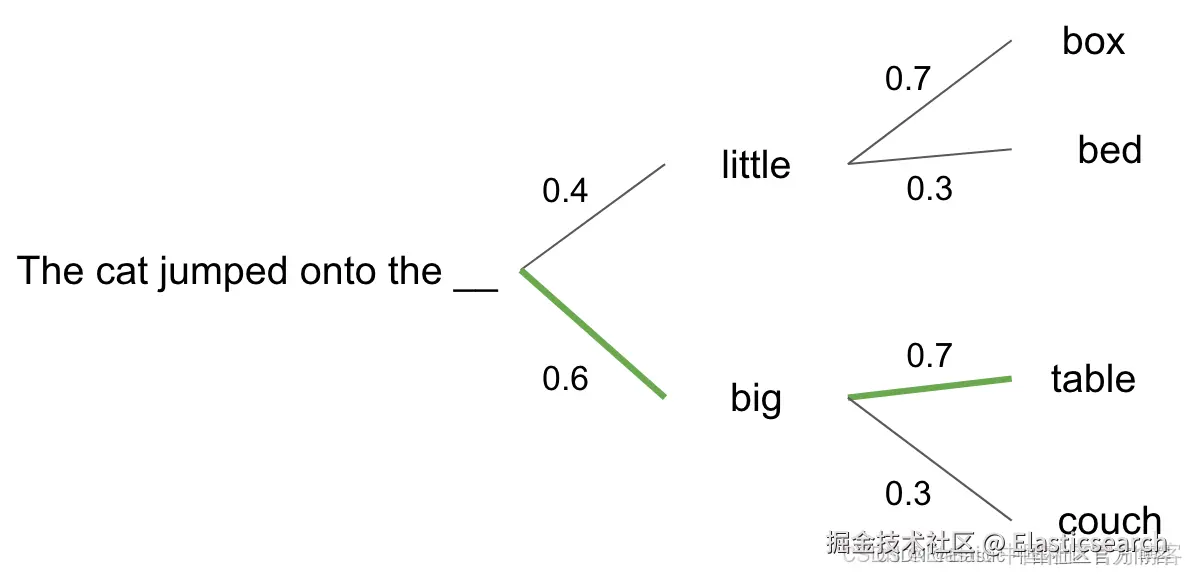
通过这样的文字扩展,我们可以实现文字的语义搜索。为了简便搜索,我们也可以省去路径中的 sparse_embedding:
bash
`
1. POST _inference/my-elser-model
2. {
3. "input": "The sky above the port was the color of television tuned to a dead channel."
4. }
`AI写代码值得注意的是:目前 ELSER 模型针对英文工作的非常好,但是它不适合中文的文章扩展。目前国内的阿里已经支持稀疏向量的嵌入。它不需要针对任何的领域进行微调:开箱即用!
Cohere
我们可以使用如下的方式来创建一个 Cohere 嵌入推理端点:
bash
`
1. PUT _inference/text_embedding/cohere_embeddings
2. {
3. "service": "cohere",
4. "service_settings": {
5. "api_key": "${COHERE_API_KEY}",
6. "model_id": "embed-english-light-v3.0",
7. "embedding_type": "byte"
8. }
9. }
`AI写代码在上面,我们定义了 embedding_type 为 byte,也就是 8-bit。这也是一种标量量化。
我们可以使用如下的方式来获取 embedding:
bash
`
1. POST _inference/text_embedding/cohere_embeddings
2. {
3. "input": "The sky above the port was the color of television tuned to a dead channel.",
4. "task_settings": {
5. "input_type": "ingest"
6. }
7. }
`AI写代码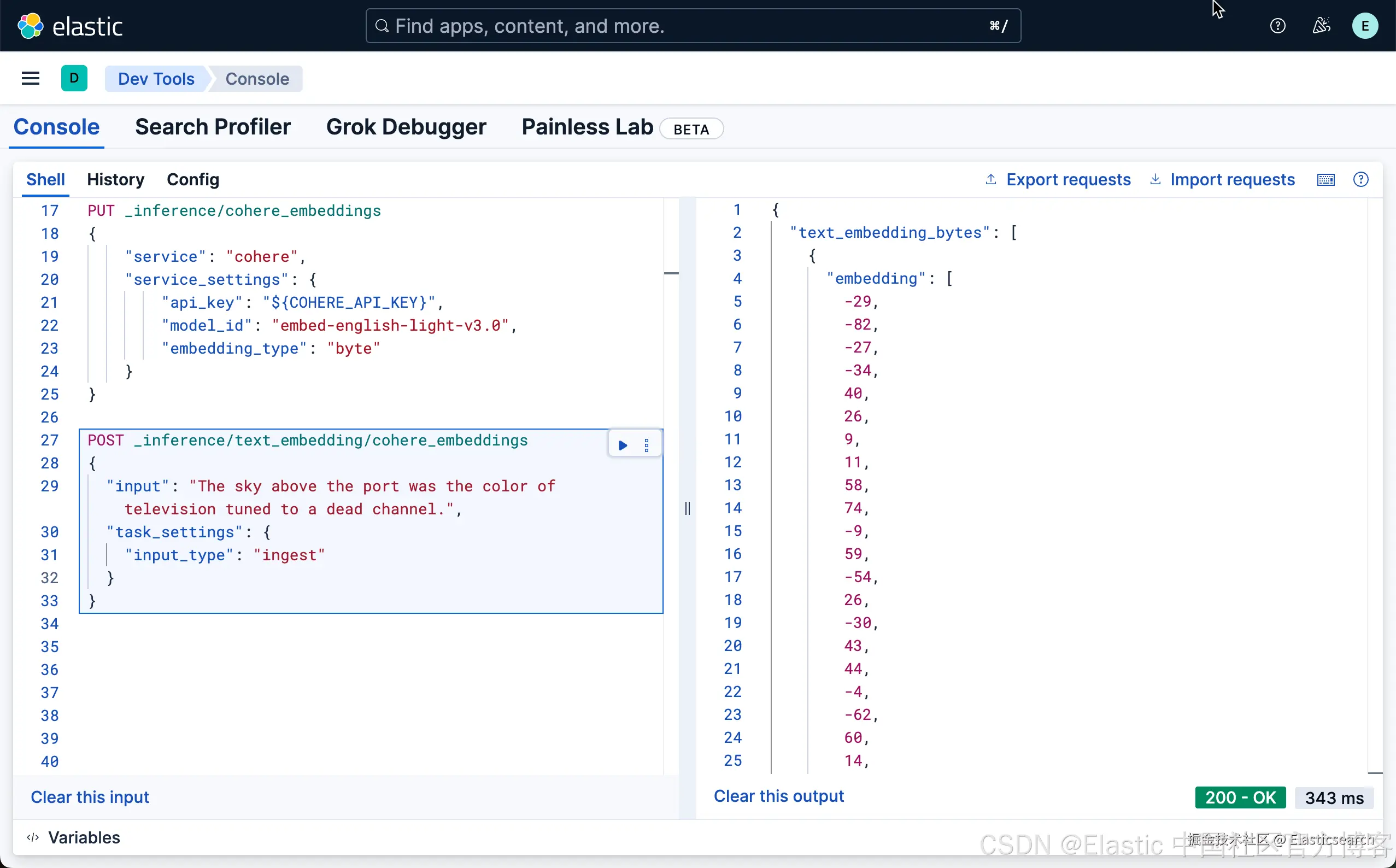
我们可以看到一个 byte 的输出。我们也可以使用如下的方式来获取:
bash
`
1. POST _inference/cohere_embeddings
2. {
3. "input": "The sky above the port was the color of television tuned to a dead channel.",
4. "task_settings": {
5. "input_type": "ingest"
6. }
7. }
`AI写代码在上面,我们省去了路径中的 text_embedding,这是因为 model_id 的元数据里本身就含有这个信息。
Azure OpenAI
我们可以参考之前的文章俩创建 Azure OpenAI 的账号及嵌入模型:
bash
`
1. PUT _inference/text_embedding/azure_openai_embeddings
2. {
3. "service": "azureopenai",
4. "service_settings": {
5. "api_key": "${AZURE_EMBEDDING_API_KEY}",
6. "resource_name": "ada-embeddings1",
7. "deployment_id": "${MODEL_NAME}",
8. "api_version": "2023-05-15"
9. }
10. }
`AI写代码一旦创建成功,我们可以使用如下的命令来创建 Aure OpenAI 的嵌入:
bash
`
1. POST _inference/azure_openai_embeddings
2. {
3. "input": "The sky above the port was the color of television tuned to a dead channel."
4. }
`AI写代码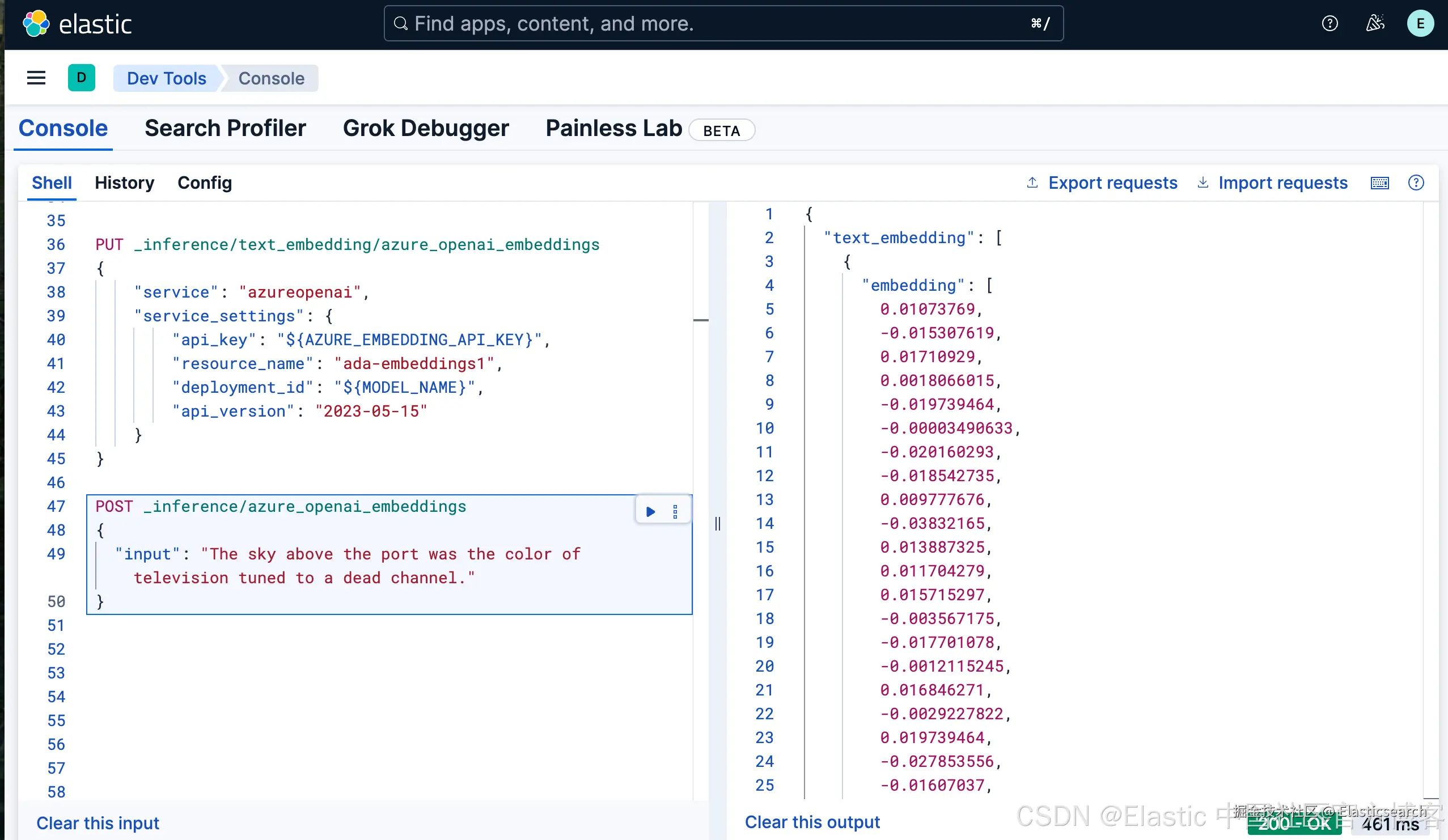
我们可以使用如下的方式来创建一个 Azure OpenAI 的 chat completion 推理端点:
bash
`
1. PUT _inference/completion/azure_openai_completion
2. {
3. "service": "azureopenai",
4. "service_settings": {
5. "api_key": "${AZURE_API_KEY}",
6. "resource_name": "${AZURE_RESOURCE_NAME}",
7. "deployment_id": "${AZURE_DEPLOYMENT_ID}",
8. "api_version": "${AZURE_API_VERSION}"
9. }
10. }
`AI写代码我们可以使用如下的方法来使用这个 chat completion 推理端点:
bash
`
1. POST _inference/completion/azure_openai_completion
2. {
3. "input": "What is Elastic?"
4. }
`AI写代码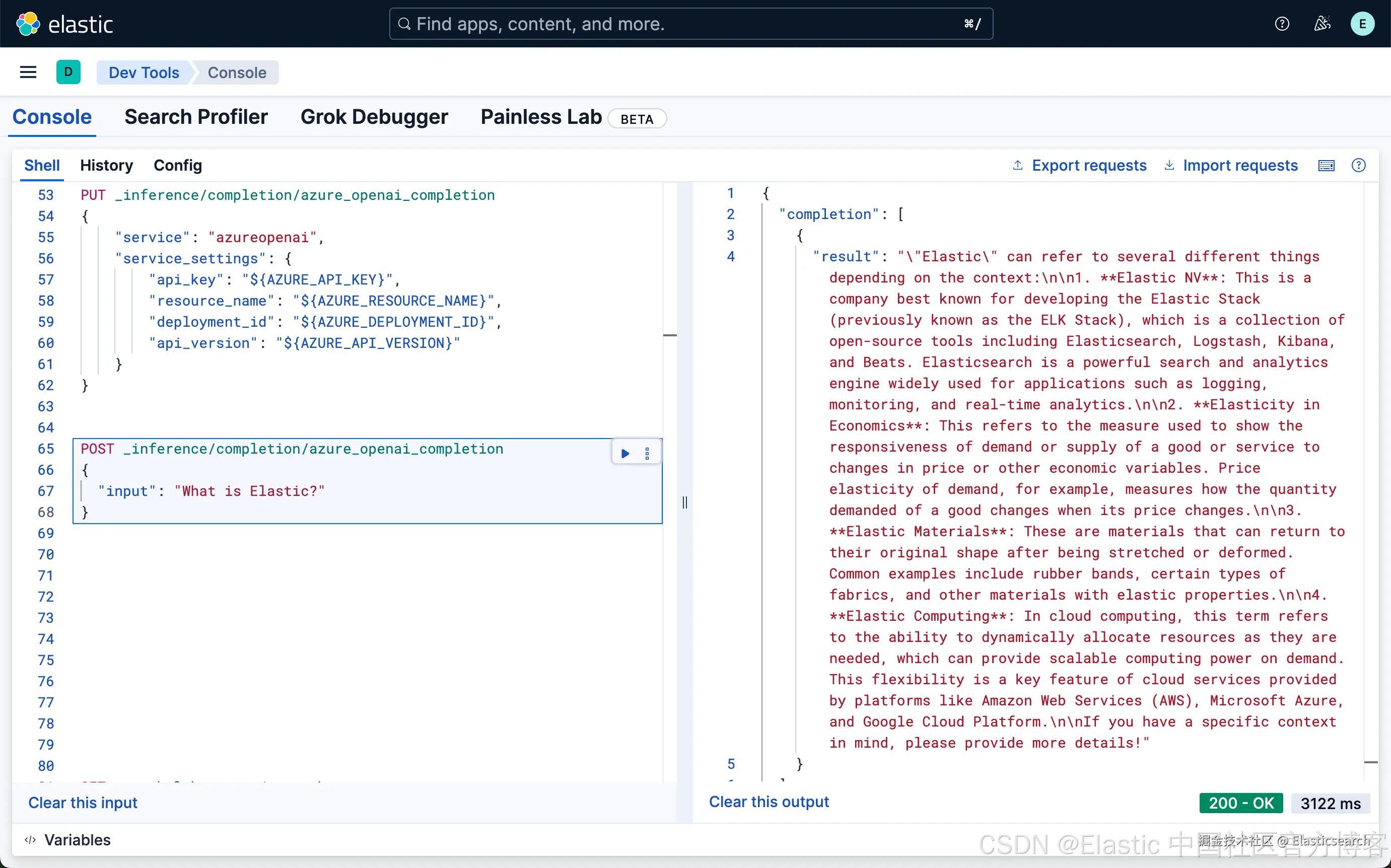
E5
在上面我们已经部署了 E5 small 模型。我们可以事业如下的方式来创建一个端点:
bash
`
1. PUT _inference/text_embedding/multilingual_embeddings
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": ".multilingual-e5-small",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码我们可以使用如下的方式来获取嵌入:
bash
`
1. POST /_ml/trained_models/.multilingual-e5-small/_infer
2. {
3. "docs": {
4. "text_field": "我爱北京天安门"
5. }
6. }
`AI写代码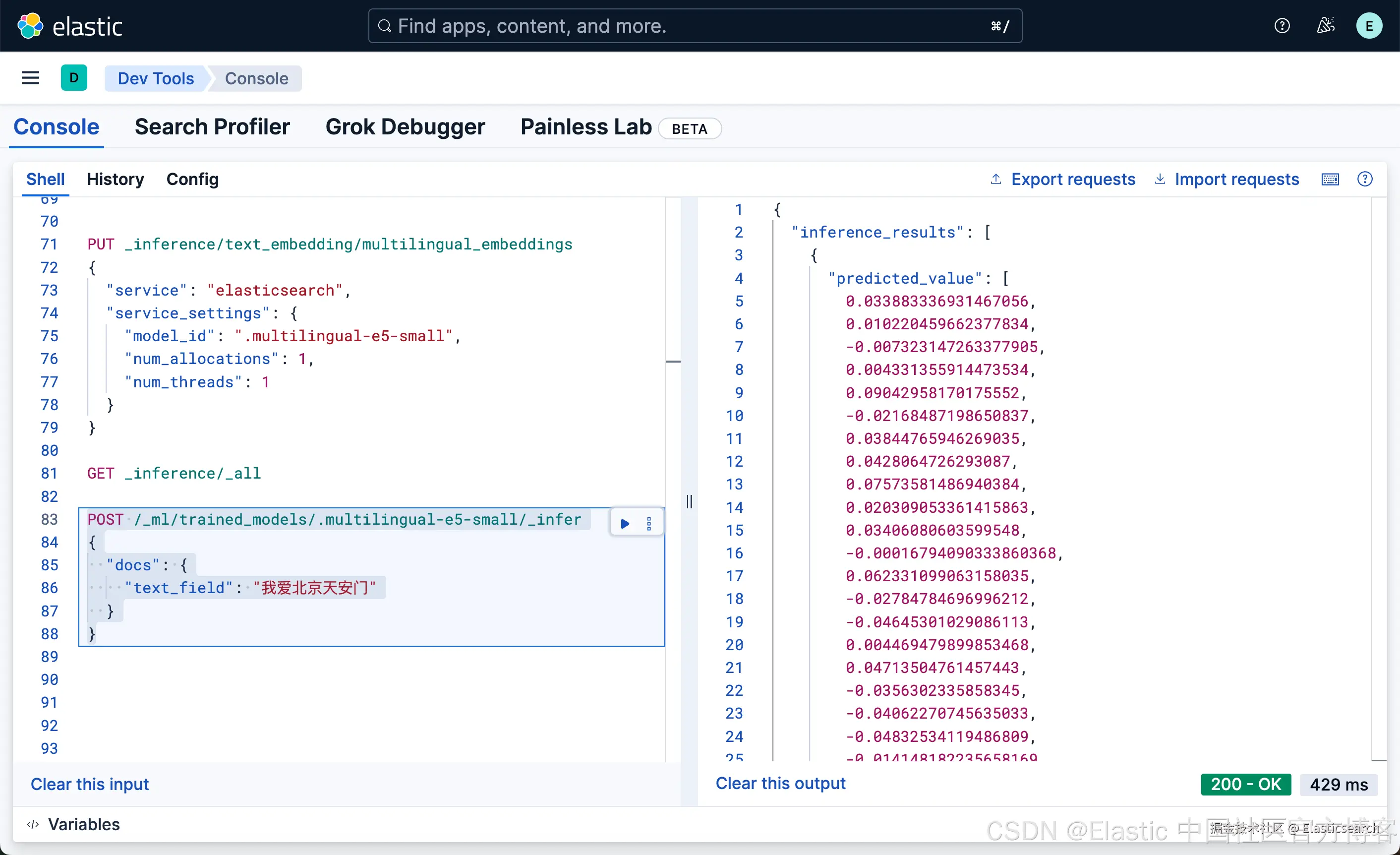
我们也可以使用我们刚才已经创建好的端点 multilingual_embeddings 来创建:
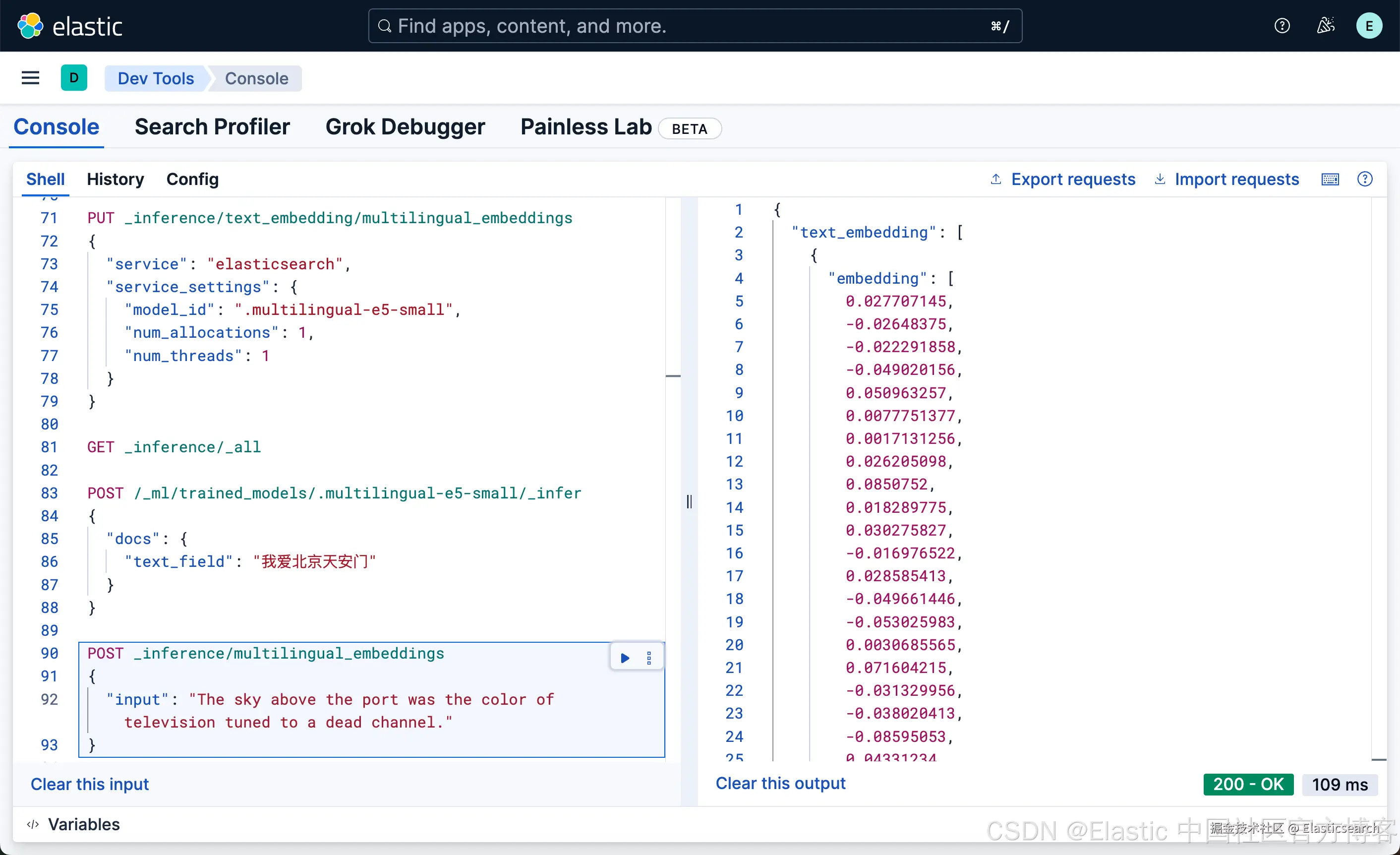
第三方模型
我们可以参考之前的文章 "Elasticsearch:如何部署 NLP:文本嵌入和向量搜索" 来部署一个第三方的模型,比如 sentence-transformers__msmarco-distilbert-base-tas-b。
arduino
`
1. eland_import_hub_model --url https://elastic:GK1JT0+tbYQV02R9jVP*@localhost:9200 \
2. --hub-model-id sentence-transformers/msmarco-distilbert-base-tas-b \
3. --task-type text_embedding \
4. --insecure \
5. --start
`AI写代码在运行完上面的命令后,我们可以在 Trained models 界面看到如下已经部署的模型:
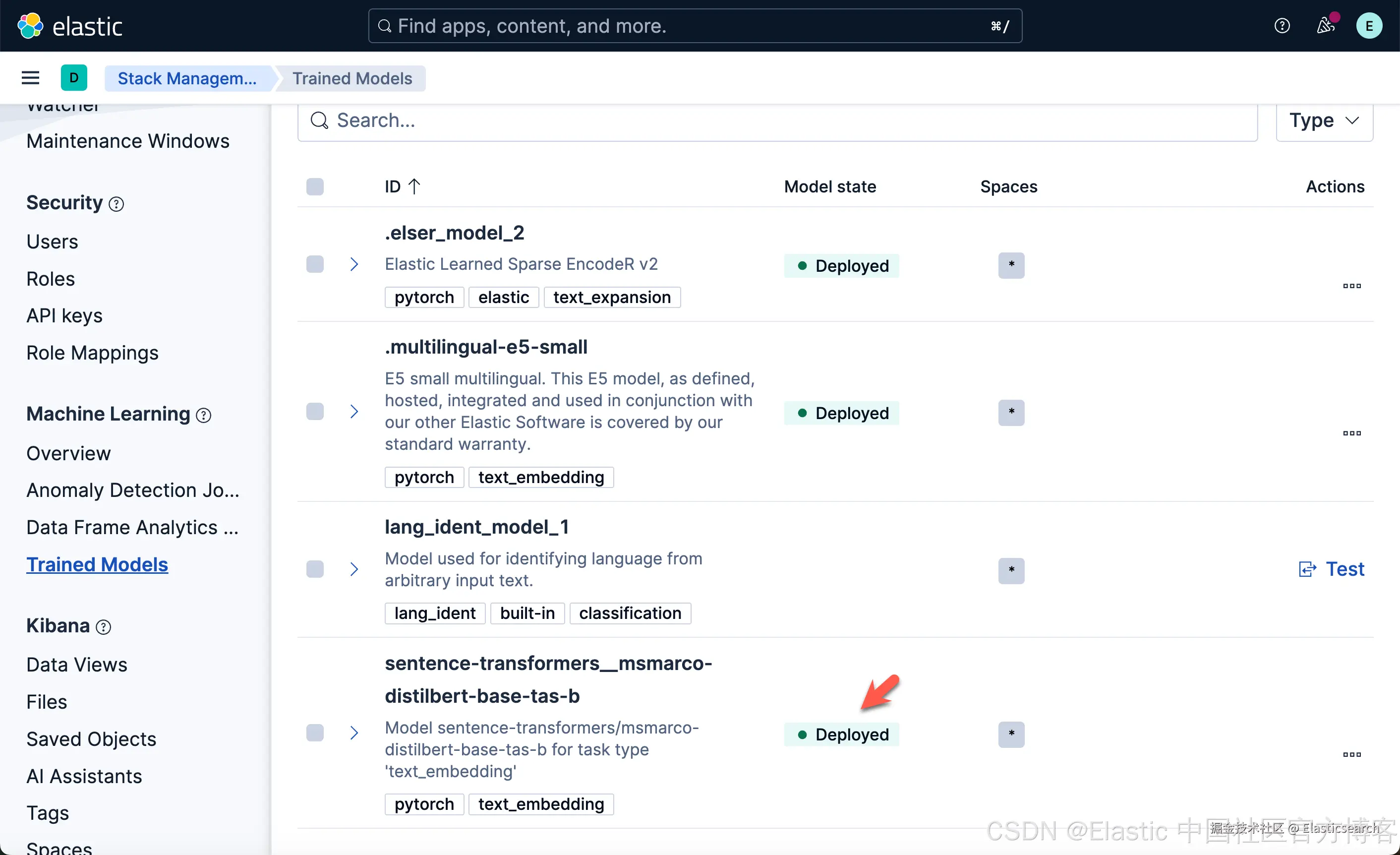
我们可以使用的如下的命令来生成嵌入:
bash
`
1. POST /_ml/trained_models/sentence-transformers__msmarco-distilbert-base-tas-b/_infer
2. {
3. "docs": {
4. "text_field": "how is the weather in jamaica"
5. }
6. }
`AI写代码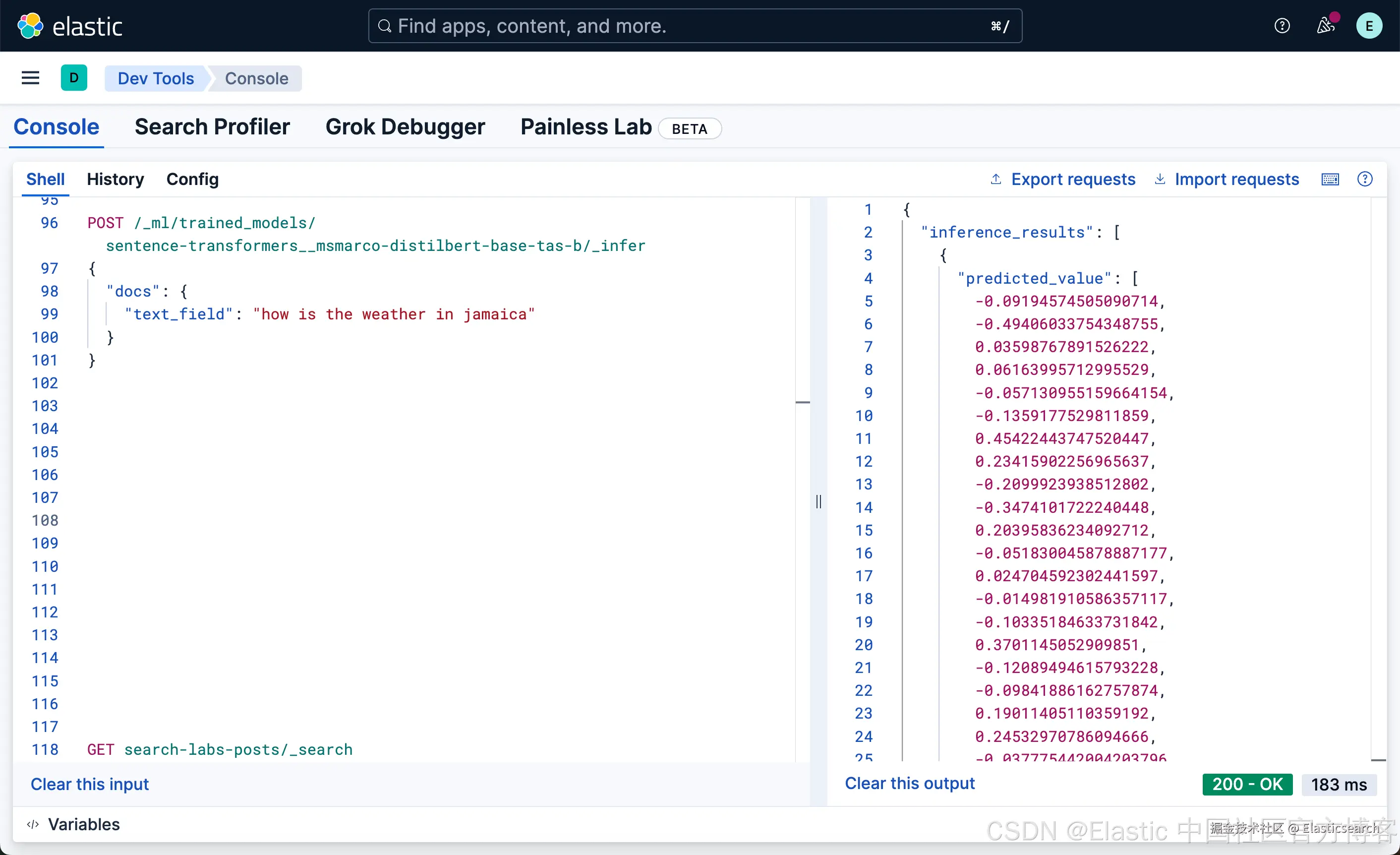
我们也可以创建一个推理端点来实现:
bash
`
1. PUT _inference/text_embedding/distilbert
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": "sentence-transformers__msmarco-distilbert-base-tas-b",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码然后,我们使用如下的方法来创建嵌入:
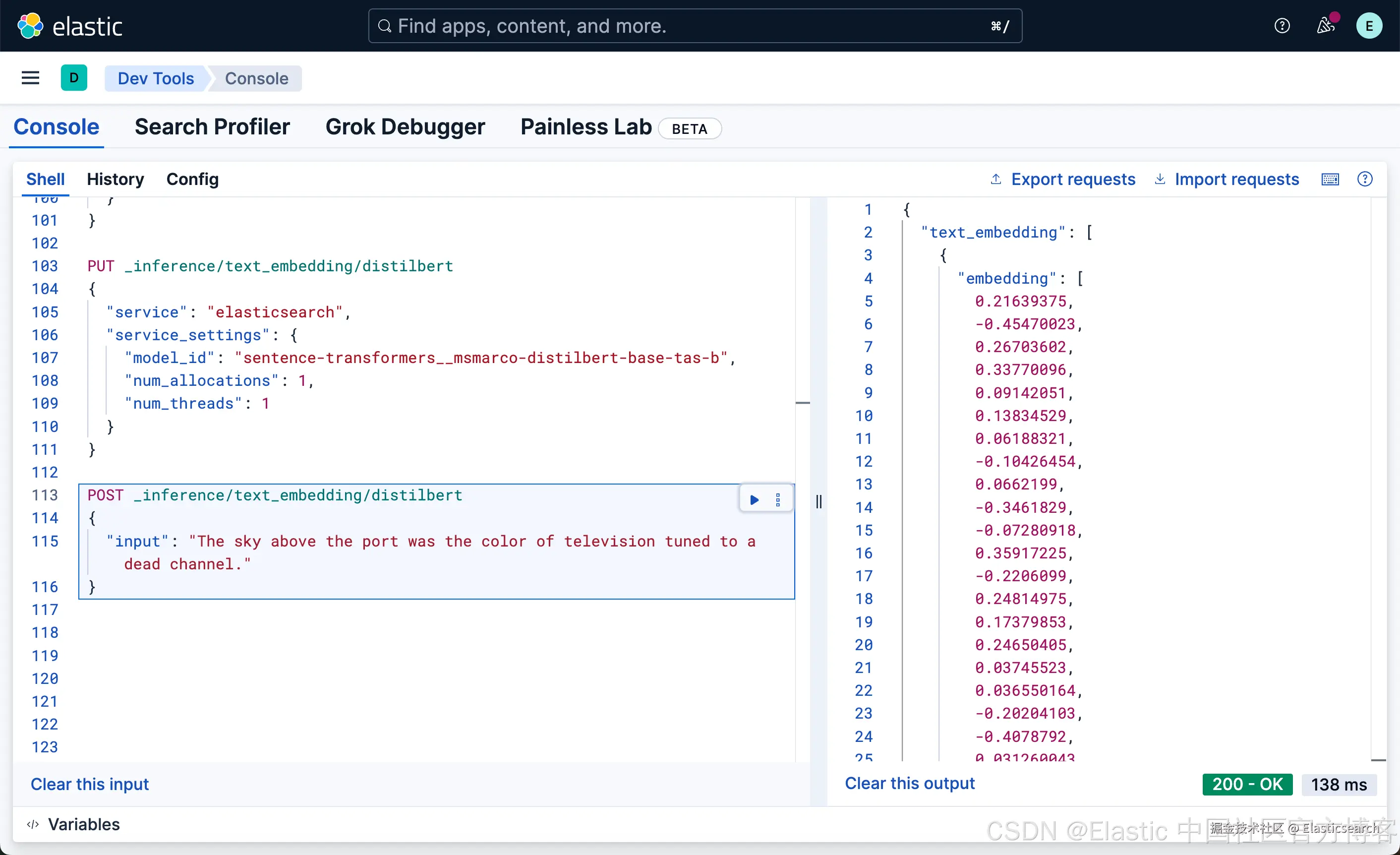
Huggingface
你需要在 huggingface 网站上使用自己的信用卡来创建一个端点,并且获取在该网站上的 API key。我们可以使用如下的方式来创建一个端点:
bash
`
1. PUT _inference/text_embedding/hugging-face-embeddings
2. {
3. "service": "hugging_face",
4. "service_settings": {
5. "api_key": "Your Huggingface key",
6. "url": "Your endpoint"
7. }
8. }
`AI写代码Alibaba
我在之前的文章 "Elasticsearch:使用阿里 infererence API 及 semantic text 进行向量搜索" 详述了如何创建阿里的嵌入及 completion 端点。这里就不再赘述了。
语义搜索示例
我们使用如下的命令来创建一个叫做 dense_vectors 的索引:
bash
`
1. PUT dense_vectors
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text",
7. "inference_id": ".multilingual-e5-small-elasticsearch"
8. }
9. }
10. }
11. }
`AI写代码我们使用如下的命令来创建两个文档:
bash
`
1. PUT dense_vectors/_bulk
2. {"index": {"_id": "1"}}
3. {"inference_field": "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"}
4. {"index": {"_id": "2"}}
5. {"inference_field": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}
`AI写代码我们使用如下的方式来进行搜索:
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "semantic": {
5. "field": "inference_field",
6. "query": "腾讯是什么样的一家公司?"
7. }
8. }
9. }
`AI写代码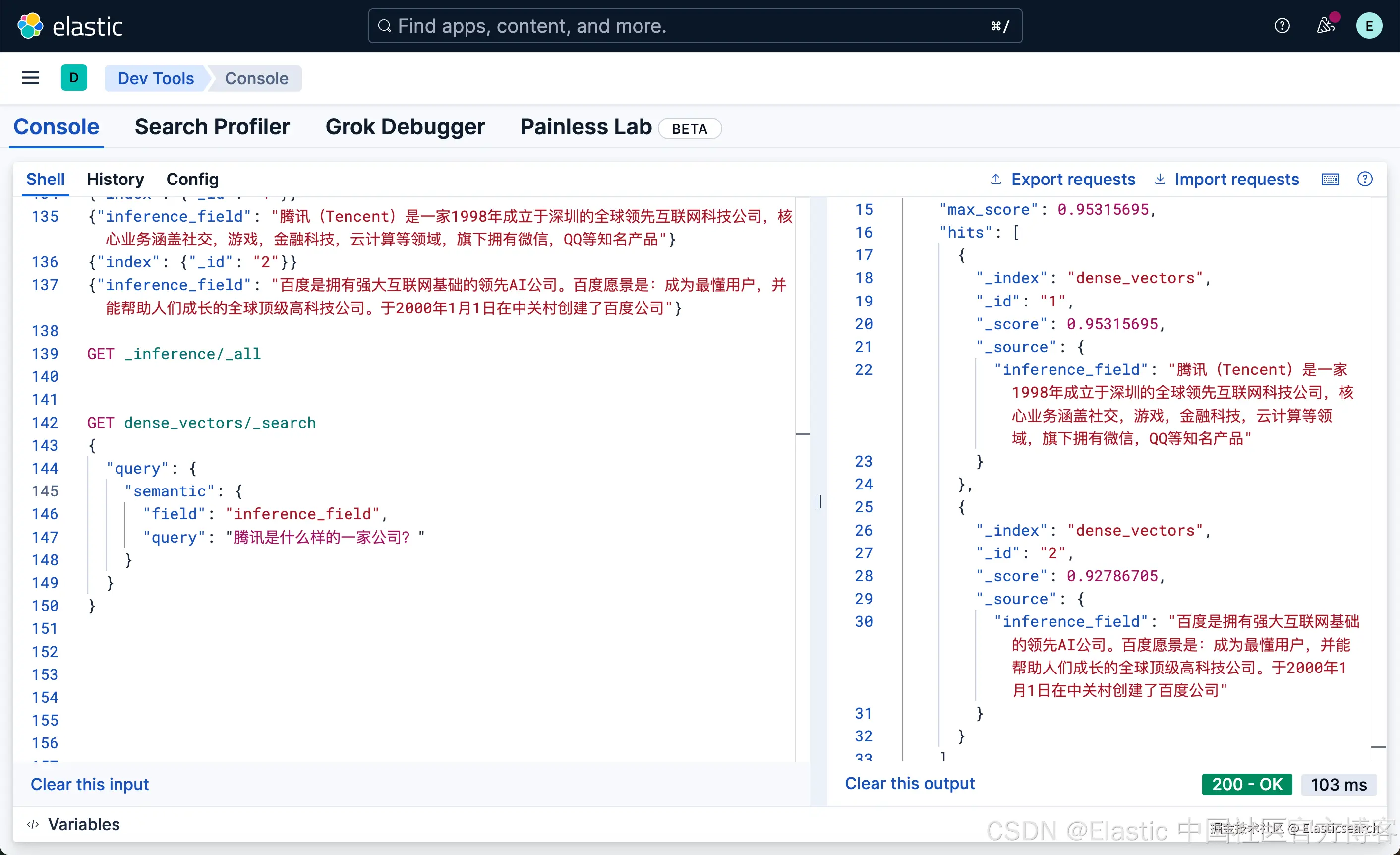
很显然,含有腾讯的文档排名是第一的,尽管百度的结果也出现了。因为我们只有两个文档,含有百度的文档的得分没有腾讯的高,所以排在第二位。
我们也可以使用如下的命令来进行搜索:
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "match": {
5. "inference_field": "腾讯是什么样的一家公司?"
6. }
7. }
8. }
`AI写代码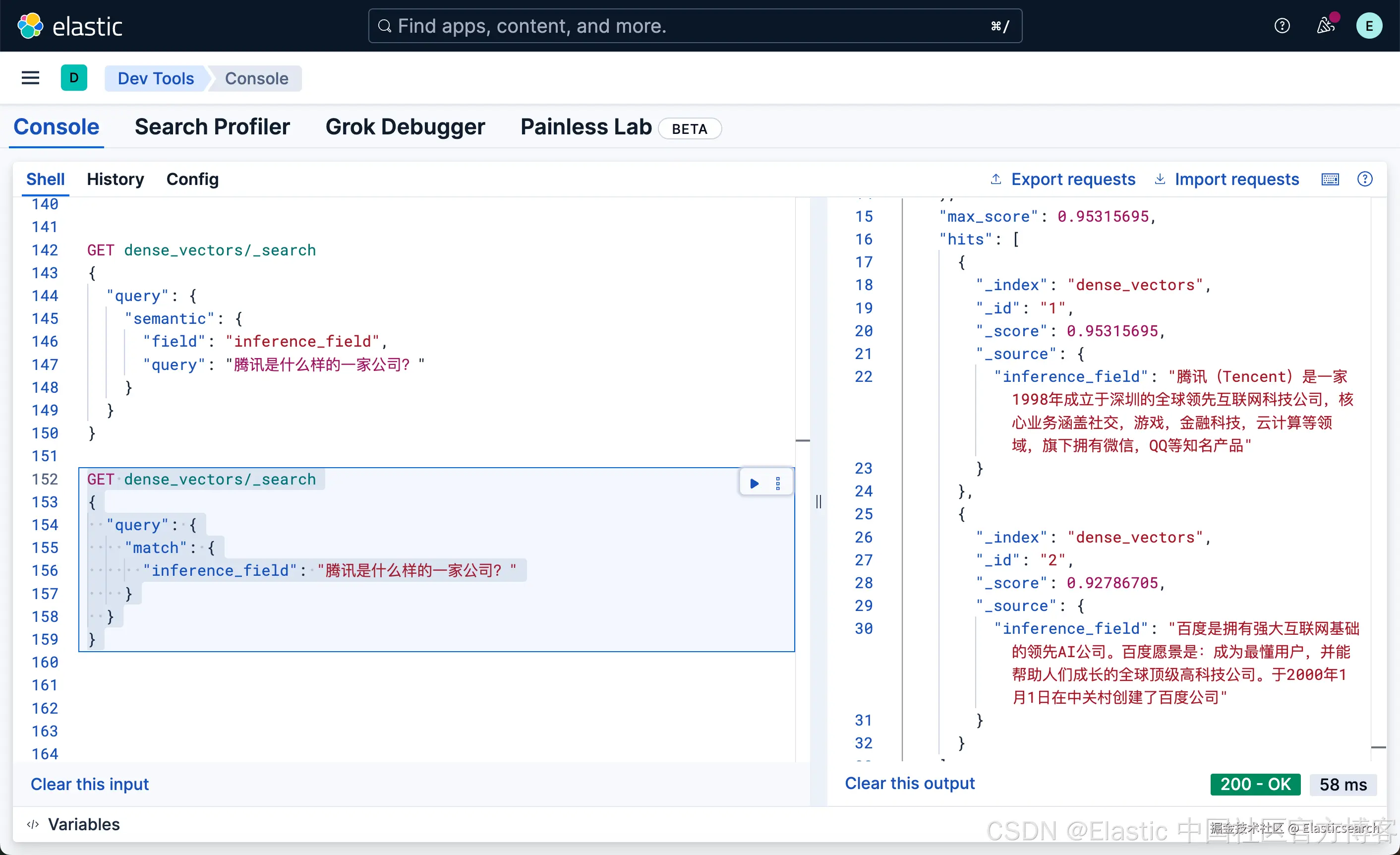
很显然,这种写法和我们之前的 DSL 的 match 写法没有任何的区别,尽管 inference_field 是一个向量字段。相比较之前的词汇搜索:
bash
`
1. PUT lexical_index/_bulk
2. {"index": {"_id": "1"}}
3. {"text": "腾讯全称"深圳腾讯计算机系统有限公司",由马化腾,张志东等五位创始人于1998年11月创立,总部位于中国深圳南山区。2004年数据显示,腾讯年营业额达6090亿元,员工超10.5万人,位列《财富》世界500强第141位"}
4. {"index": {"_id": "2"}}
5. {"text": "百度拥有数万名研发工程师,这是中国乃至全球都顶尖的技术团队。这支队伍掌握着世界上领先的搜索引擎技术,使百度成为美国,俄罗斯和韩国之外,全球仅有的4个拥有搜索引擎核心技术的国家之一"}
`AI写代码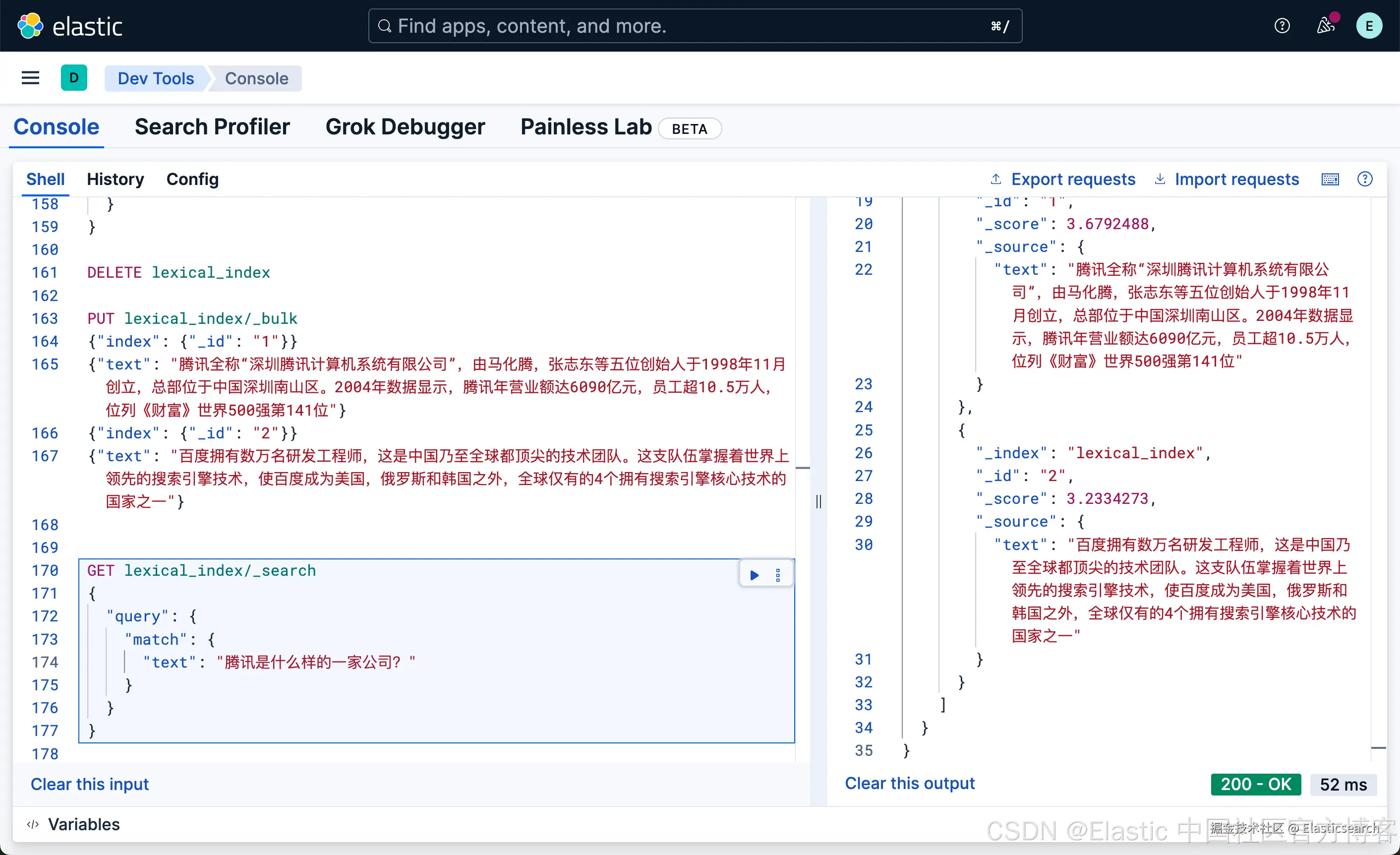
我们还可以使用 ES|QL 来实现向量字段的搜索:
python
`
1. POST _query?format=txt
2. {
3. "query": """
4. FROM dense_vectors METADATA _score
5. | WHERE inference_field : "Baidu 是什么样的公司?"
6. | SORT _score DESC
7. """
8. }
`AI写代码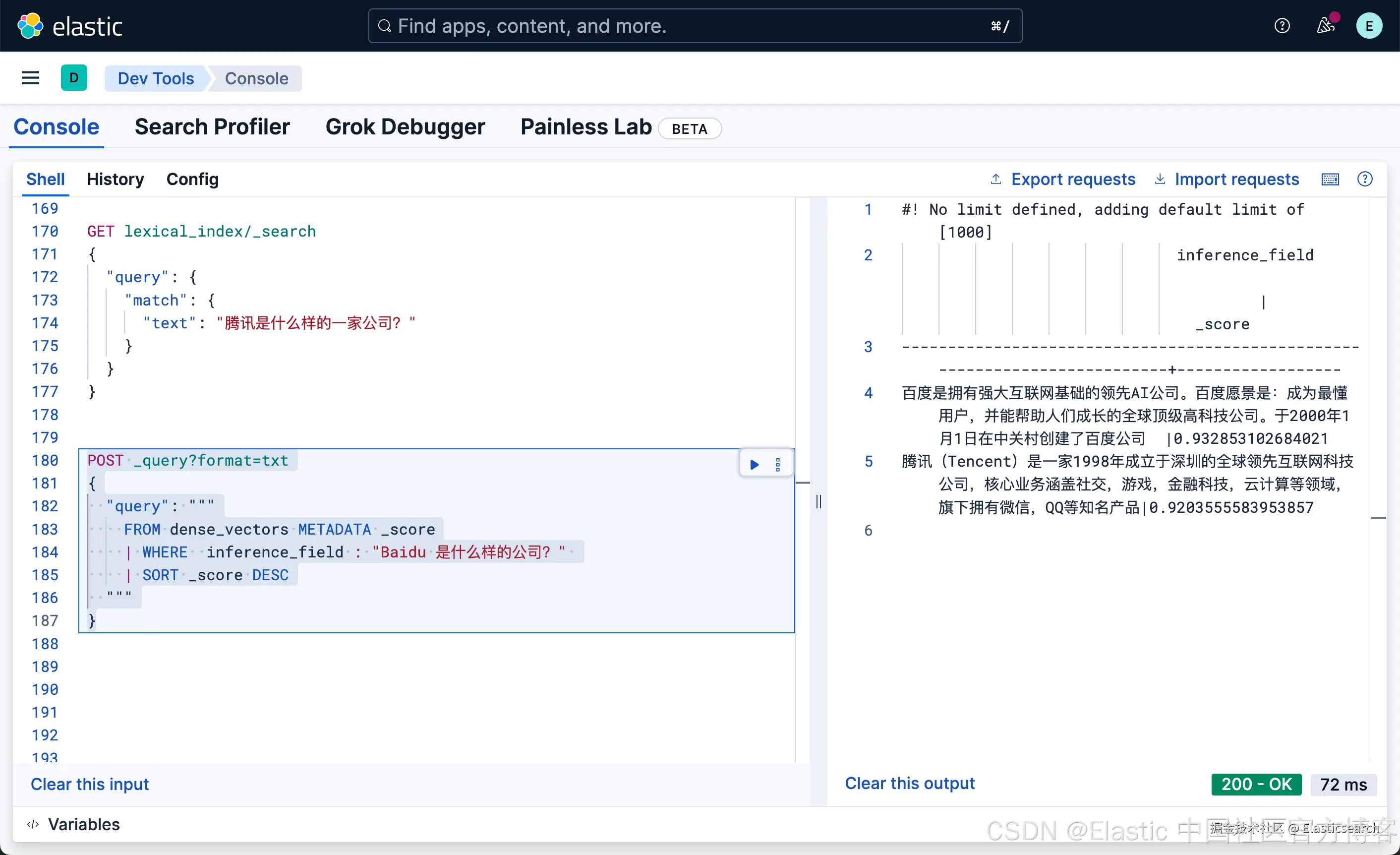
这次我们搜索的结果,百度排名第一,但是细心的开发者可能会发现我们原来的文本中并不含有 Baidu 这样的英文单词?那么它是怎么做到的呢?其实 E5 模型是一个多语言的模型,它可以针对多国语言进行搜索。
我们还可以尝试如下的搜:
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "semantic": {
5. "field": "inference_field",
6. "query": "which company owns QQ product?"
7. }
8. }
9. }
`AI写代码
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "semantic": {
5. "field": "inference_field",
6. "query": "which company has the chat product?"
7. }
8. }
9. }
`AI写代码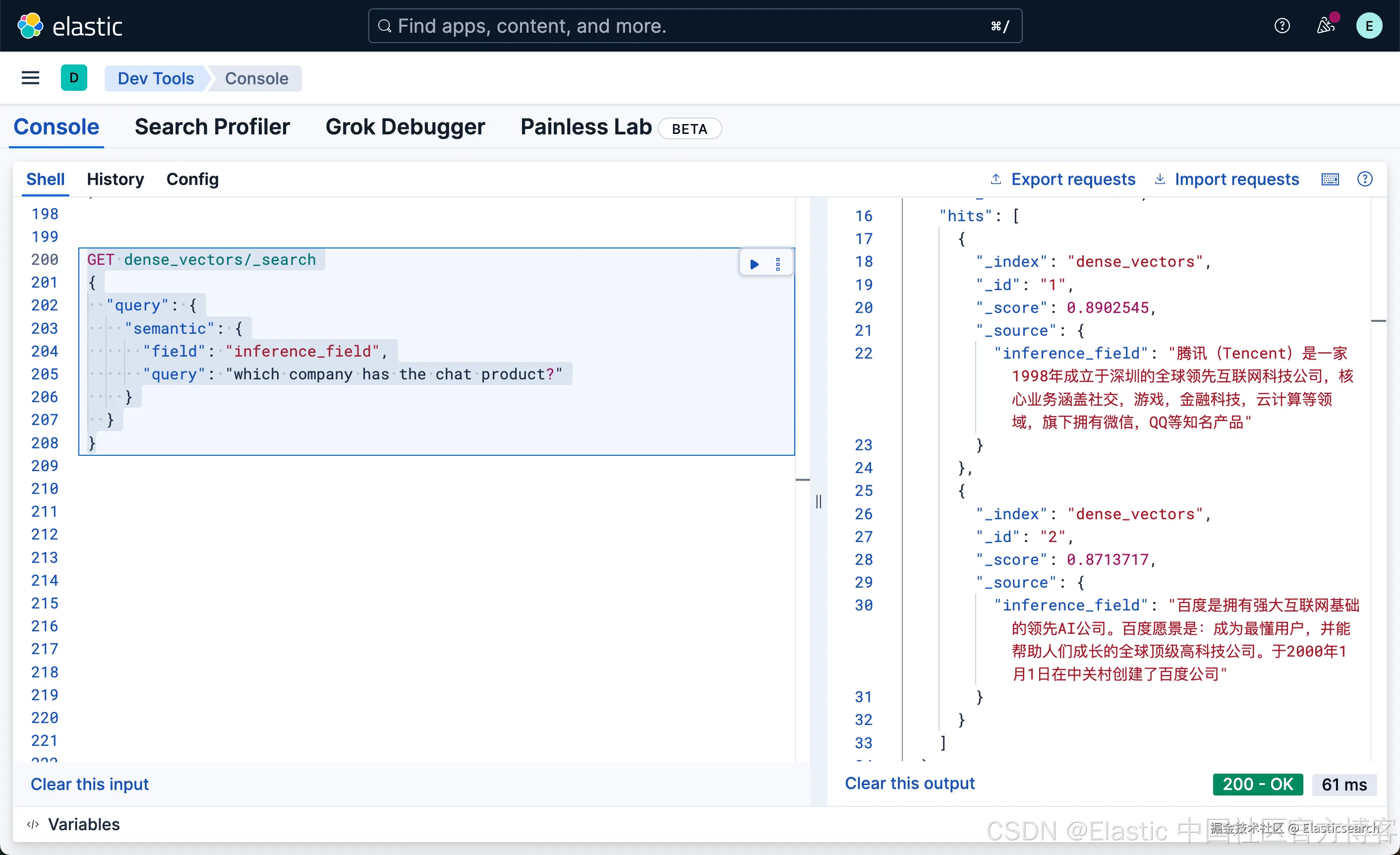
很显然,我们的文档中并没有含有聊天这样的词汇,但是我们使用英文搜索 chat 这样的词,它也能帮我们找到腾讯微第一。我们甚至可以使用日文来进行搜索:
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "semantic": {
5. "field": "inference_field",
6. "query": "チャット製品を提供している会社はどれですか?"
7. }
8. }
9. }
`AI写代码
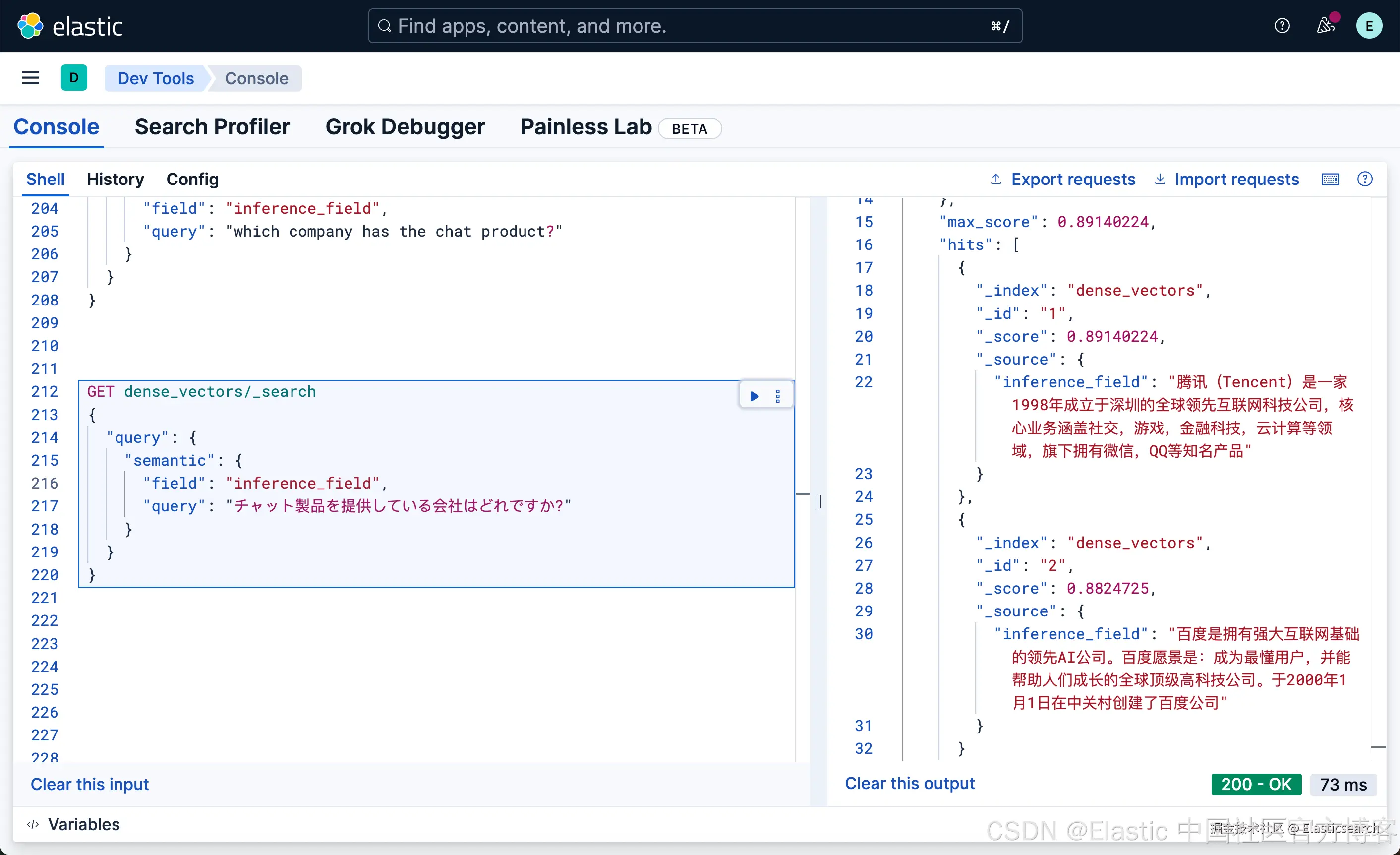
我们可以看出来,使用日文也可以搜素出我们想要的结果。
我们再看看如下的搜索结果:
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "match": {
5. "inference_field": "中国的搜索公司是哪个?"
6. }
7. }
8. }
`AI写代码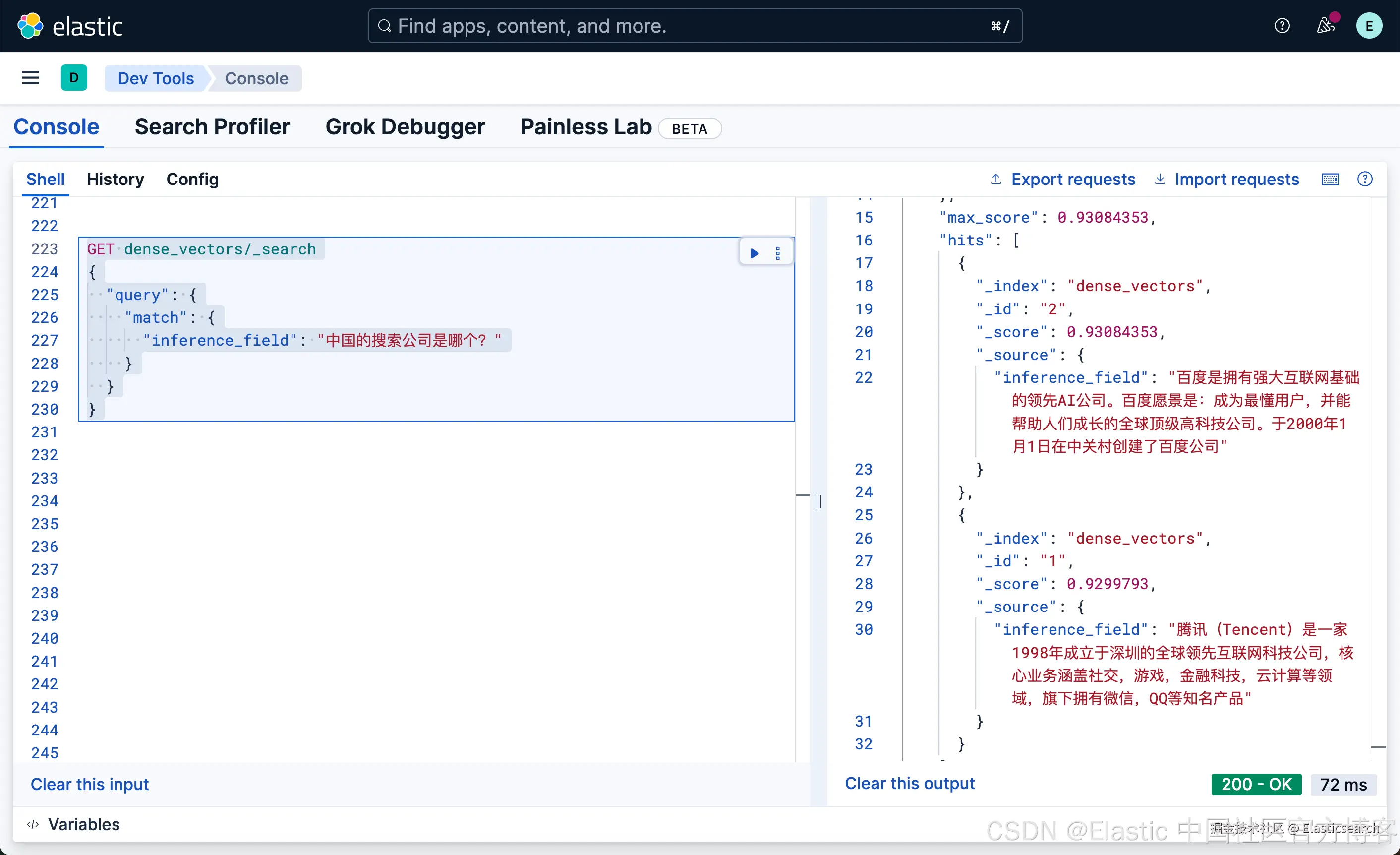
大家如果查看我们的文档,有关百度的文档中 "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司 ",它并不含有任何的搜索关键词,但是我们提问 "中国的搜索公司是哪个",百度的结果排名为第一。这个也许就是语义搜索的魅力吧!
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "match": {
5. "inference_field": "中国的游戏公司是哪个?"
6. }
7. }
8. }
`AI写代码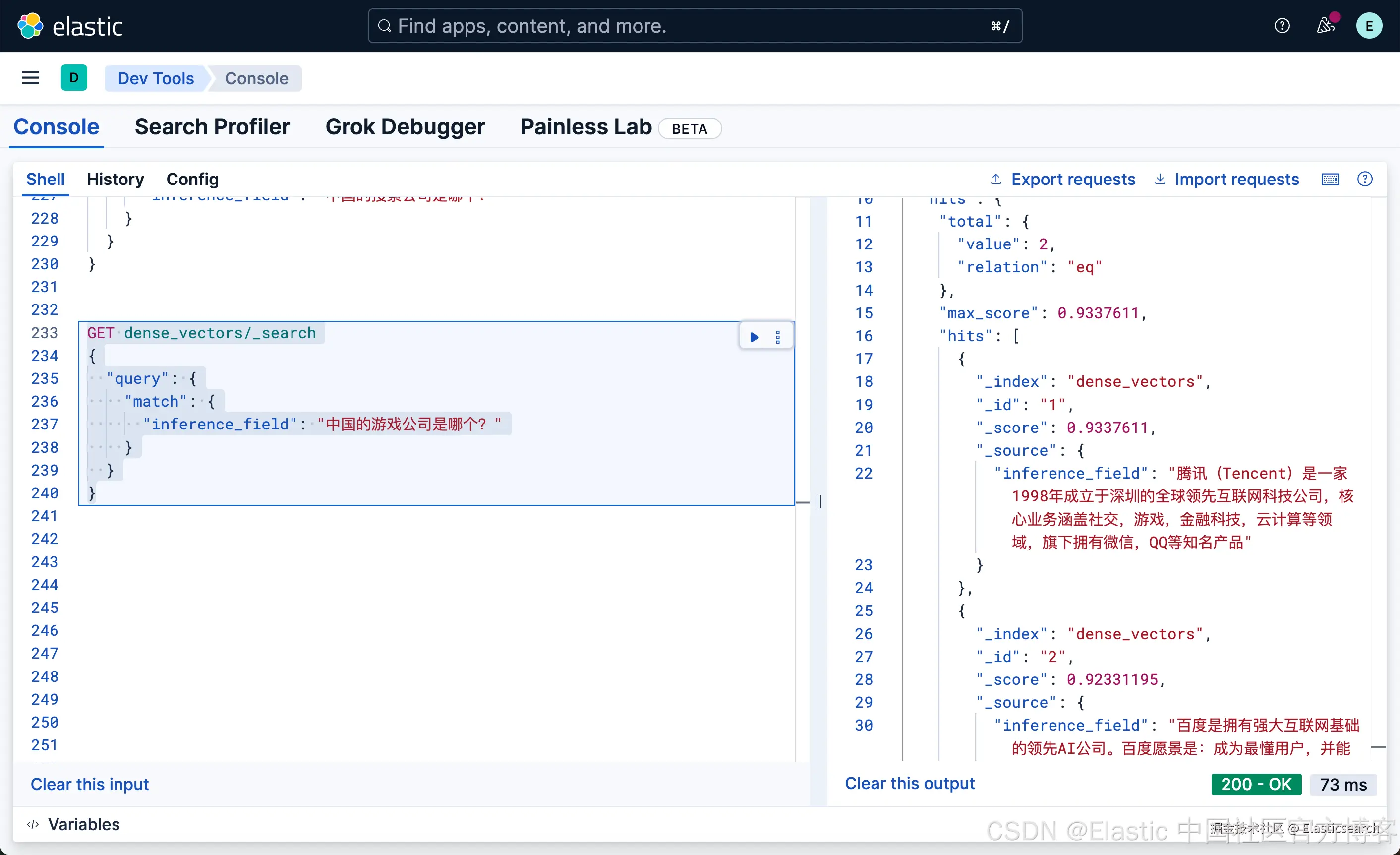
bash
`
1. GET dense_vectors/_search
2. {
3. "query": {
4. "match": {
5. "inference_field": "聊天软件是哪家公司?"
6. }
7. }
8. }
`AI写代码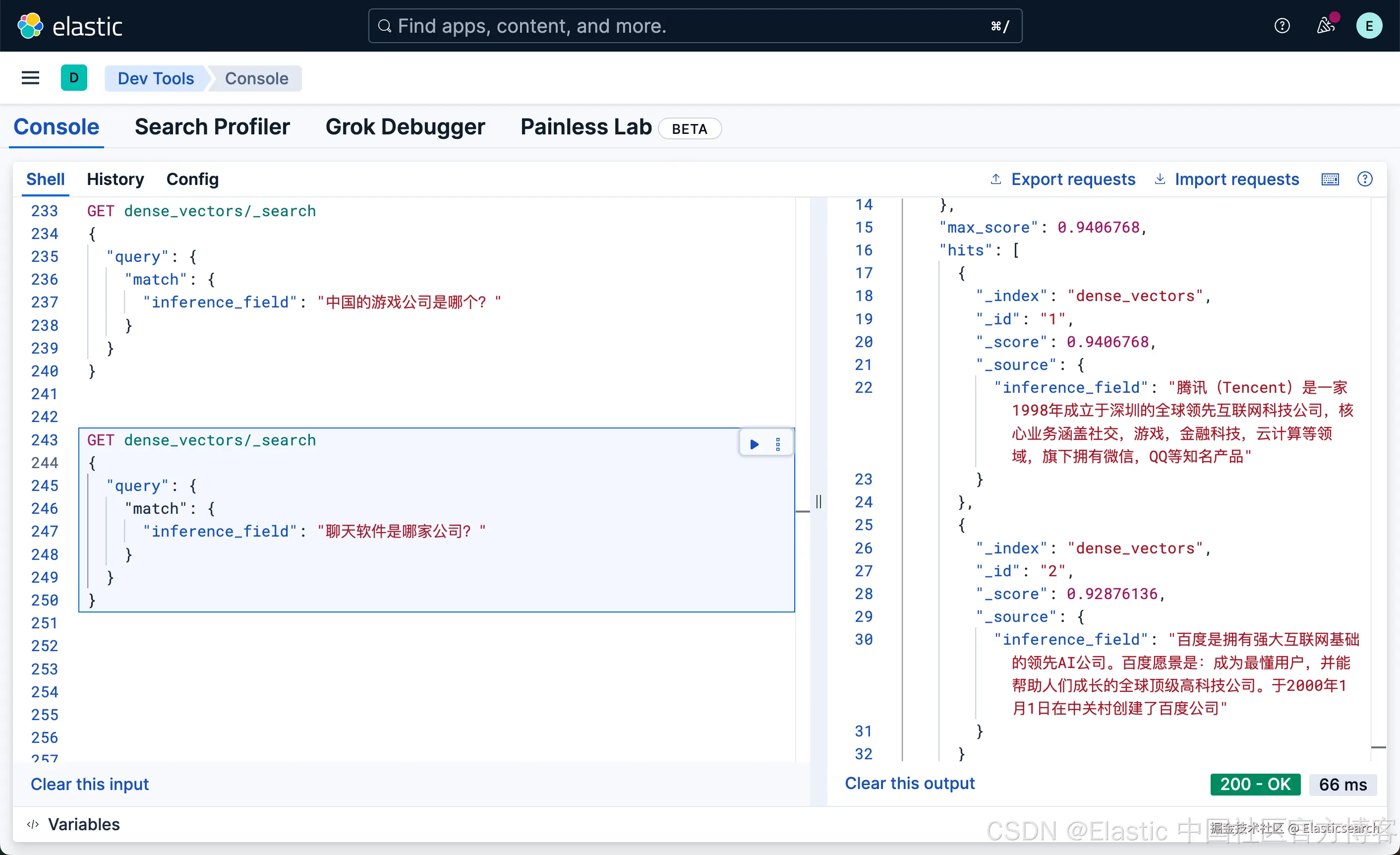
混合搜索
我们知道,单纯的语义搜索有时并不能完全提高我们的召回率及相关性,甚至有时搜索的结果不具有可解释性。我们可以使用混合搜索的方法来提高相关性及召回率。
方法一
我们可以定义如下的索引:
json
`
1. PUT my_index
2. {
3. "mappings": {
4. "properties": {
5. "text": {
6. "type": "text" // raw document text
7. },
8. "embedding.predicted_value": {
9. "type": "dense_vector",
10. "dims": 384, // E5-small output dim is 384
11. "index": true, // enable ANN search
12. "similarity": "cosine" // consine similarity for semantic search
13. }
14. }
15. }
16. }
`AI写代码然后我们定义一个如下的 pipeline:
bash
`
1. PUT _ingest/pipeline/e5-embedding-pipeline
2. {
3. "processors": [
4. {
5. "inference": {
6. "model_id": ".multilingual-e5-small-elasticsearch",
7. "target_field": "embedding",
8. "field_map": {
9. "text": "text_field"
10. }
11. }
12. }
13. ]
14. }
`AI写代码我们为 my_index 创建索引文档:
bash
`
1. PUT my_index/_bulk?pipeline=e5-embedding-pipeline
2. {"index": {"_id": "1"}}
3. {"text": "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"}
4. {"index": {"_id": "2"}}
5. {"text": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}
`AI写代码我们可以使用如下的方法来进行混合搜索:
markdown
`
1. GET my_index/_search
2. {
3. "retriever": {
4. "rrf": {
5. "retrievers": [
6. {
7. "standard": {
8. "query": {
9. "match": {
10. "text": "腾讯"
11. }
12. }
13. }
14. },
15. {
16. "knn": {
17. "field": "",
18. "query_vector_builder": {
19. "text_embedding": {
20. "model_id": ".multilingual-e5-small-elasticsearch",
21. "model_text": "聊天"
22. }
23. },
24. "k": 10,
25. "num_candidates": 100
26. }
27. }
28. ]
29. }
30. }
31. }
`AI写代码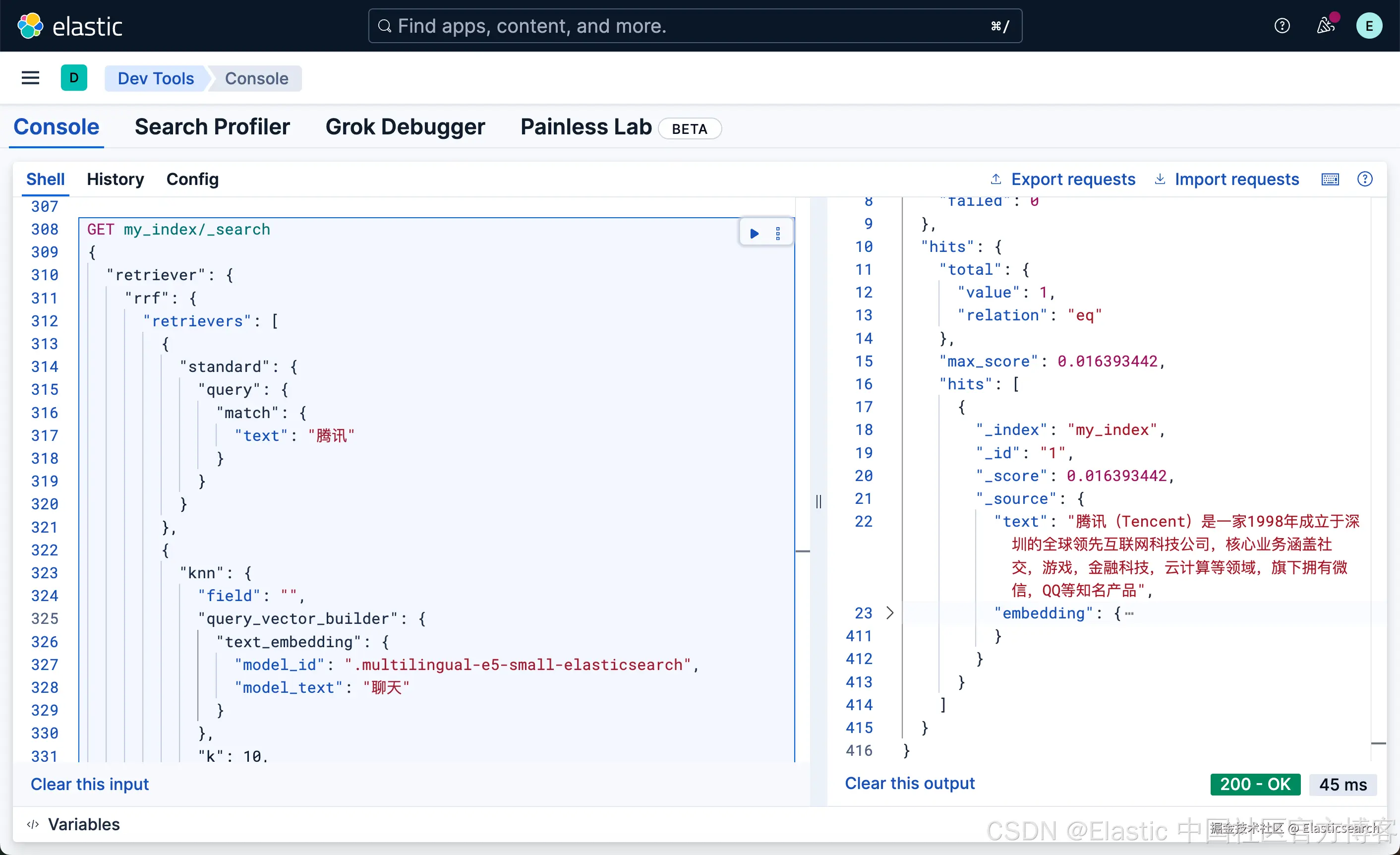
方法二
这个方法更为简单。我们定义如下的一个索引:
bash
`
1. PUT hybrid_vectors
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text",
7. "inference_id": ".multilingual-e5-small-elasticsearch"
8. },
9. "content":{
10. "type": "text",
11. "copy_to": "interence_field"
12. }
13. }
14. }
15. }
`AI写代码我们使用如下的命令来写入文档:
css
`
1. PUT hybrid_vectors/_bulk
2. {"index": {"_id": "1"}}
3. {"content": "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"}
4. {"index": {"_id": "2"}}
5. {"content": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}
`AI写代码我们使用如下的方法来做混合搜索:
markdown
`
1. GET hybrid_vectors/_search
2. {
3. "retriever": {
4. "rrf": {
5. "retrievers": [
6. {
7. "standard": {
8. "query": {
9. "match": {
10. "content": "腾讯"
11. }
12. }
13. }
14. },
15. {
16. "standard": {
17. "query": {
18. "match": {
19. "inference_field": "互联网公司"
20. }
21. }
22. }
23. }
24. ]
25. }
26. }
27. }
`AI写代码