本课程以微服务分布式架构为基础,阐述全文检索基础知识、ElasticSearch组件、数据分析与可视化平台Kibana、ElasticSearch微服务、Spring Data ElasticSearch微服务等实用技术,讲述企业级全文检索ElasticSearch开发技术栈知识。
在本课程中,会讲到如下技术栈内容:
1、全文检索基础知识
2、ElasticSearch组件
3、数据分析与可视化平台Kibana
4、ElasticSearch微服务
5、Spring Data ElasticSearch微服务
适合人群: 本课程是来自一线开发者的实战经验总结,对微服务分布式架构开发、设计感兴趣的所有技术人员。
一、全文检索基础知识
1、全文检索简介
全文检索是以非结构化数据为对象的计算机检索技术,允许用户通过自然语言直接匹配文本中的字符、词语或短语进行内容搜索,其核心流程包括文本索引构建与快速匹配查询 。该技术通过分词处理将文档切分为独立词汇,基于倒排索引建立词汇与文档的映射关系,支持通配符、模糊搜索、精确短语检索等多种查询方式,并采用BM25算法进行相关性排序。
全文检索系统由索引构建、查询处理、结果展示三大模块构成,其中索引核心采用层次化存储结构,支持分布式分片与副本机制以实现高可用性。典型系统如Elasticsearch基于Apache Lucene构建,集成分词器、倒排索引和列式存储技术,可应用在搜索引擎、文档管理等场景。
全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。对于全文数据库这种比较非结构化的数据,用关系数据库管理系统RDBMS技术来管理是最好的一种方式。但是由于RDBMS底层结构的缘故使得它管理大量非结构化数据显得有些先天不足,特别是查询这些海量非结构化数据的速度较慢,而通过全文检索技术就能高效地管理这些非结构化数据。
将非结构化数据中的一部分信息提取出来重新整理后的数据,使其变得有一定结构,然后对整理后的数据进行搜索,达到可以进行全文检索的目的。这部分从非结构化数据中提取出的数据,进行重新构建的数据信息即为索引。
索引库:存储在磁盘上的一系列的索引文件。里面存储了建立好的索引信息以及文档对象。
document对象:在索引前需要将原始内容创建成文档Document,文档中包括域Field,域中存储内容。每个文档都有一个唯一的编号,就是文档id。document对象相对于数据库表中的一条记录。
field对象:文档document相对于数据库中一条记录,field相当于记录中的字段。field是索引库中存储数据的最小单位。field的数据类型大致可以分为数值类型和文本类型,一般需要查询的字段都是文本类型的,field的还有如下属性:
是否分词:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
是否索引:将Field分词后的词或整个Field值进行索引。
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取。
term对象:从文档对象中拆分出来的每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。term是创建索引的关键词对象。
2、全文检索流程
针对全文数据系统的构建,提出全文检索系统的实现技术,主要分为5个步骤。
(1)数据准备:它是指针对计划加载到全文数据库中的数据进行收集、整理、归类等预先处理的过程。加载到全文数据中的数据可以从多种途径获得,常见的数据来源有:电脑打字产生的文件,电子印刷产生的文稿,计算机网上传送的文件,电子出版物,图文处理产生的文件,专门组织人力录入建库。
(2)文本预处理:包括规范格式,当格式多种多样时,应加以整理,使文献的格式规范化;批式标引,文本预处理阶段完成的批式标引,不受全文数据库结构的限制,效率较高。
(3)数据加载:数据准备好以后,便可以加载(拷入、输入)到数据库文件中去了。加载数据可有单篇方式或批量方式。单篇方式一次加载一篇,适于平时文献随时加载的情况。批量方式一次加载多篇,适于集中大量加载的情况。
(4)数据检索:数据库建立起来之后,便可根据全文检索系统提供的检索功能对数据库进行检索。
(5)数据维护:全文数据建立以后,需要经常对数据库的内容进行索引、更新、追加和清理。
创建索引库:获得原始文档,构建文档对象;对原始文档进行分词操作,按相关的映射规则创建索引库。
查询索引库:构建用户查询接口,创建索引查询,执行索引查询,在可视端渲染索引查询结果。
文档解析:将PDF、DOC、PPT、XLS、HTML、TXT、PNG等多格式文档转换为标准格式,满足企业级知识库建设、技术文档迁移、内容平台结构化存储等需求。
文本切片:文本切片是将长文本分割为短片段的技术,用于适配模型输入、提升处理效率或信息检索,平衡片段长度与语义连贯性,适用于NLP、数据分析等场景。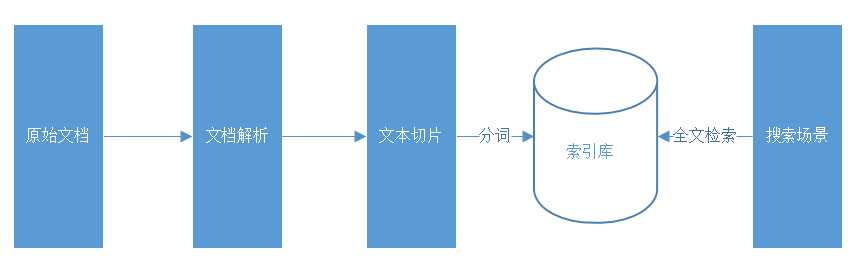
二、ElasticSearch组件
1、ElasticSearch简介
Elasticsearch是一个开源的分布式搜索和分析引擎,专为速度、扩展和AI应用而打造。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现AI驱动的应用。
Elasticsearch Service是基于开源搜索引擎Elasticsearch打造的高可用、可伸缩的云端的Elasticsearch服务,包含Kibana及常用插件。
Elasticsearch分布式搜索引擎,可以对海量数据进行存储、全文检索、统计分析等,提供了RESTful API以及各类语言客户端,可以灵活地按照业务需求进行开发。
Elasticsearch本身的兼容与开放,拥有丰富的集群管理功能以及安全、弹性、高可用等特性。可以快速构建海量数据存储搜索、实时日志分析等应用,例如网站搜索导航、企业级搜索、服务日志异常监控、点击流分析等。
数据采集与同步:Elasticsearch提供了易用的RESTful API,用户可以自行开发客户端,调用数据存储API,存储数据到Elasticsearch集群中。
数据存储:支持弹性扩展到上百个节点,能达到PB级数据的存储,满足用户不同类型的业务场景。具备全文检索、向量检索以及两者混合搜索功能。
数据查询分析可视化:Elasticsearch拥有全文检索、结构化搜索、数据过滤和指标统计等搜索功能,可应用于信息搜索和数据分析等多种场景。Elasticsearch提供了简单易用的RESTful API以及各种语言的客户端,用户可以很方便地构建自己的搜索服务。使用Kibana,用户可以方便地在浏览器里对集群的数据进行搜索和统计分析。
Elasticsearch Service非常适合应用于网站搜索、移动应用搜索等场景,特别是针对大数据量、高并发以及对搜索灵活性和相关度要求比较高的情况,通过灵活的关键字、查询条件、模糊匹配等方式,可以从PB级的结构化和非结构化数据中毫秒级返回搜索结果。
数据分析 :Elasticsearch Service拥有结构化查询的能力,支持复杂的过滤和聚合统计功能,帮助客户对海量数据进行高效地个性化统计分析、发现问题与机会、辅助商业决策,让数据产生真正的价值。
数据库查询加速:关系型数据库更偏向事务型查询,在海量数据规模的场景下,容易遇到查询性能不足、可扩展性差的挑战。Elasticsearch Service提供了弹性扩展及海量数据下的高并发低延时查询能力,通过数据同步工具保持与数据库同步,并支持SQL能力,满足客户数据库加速查询的需求,弥补了传统数据库的不足。
Elaticsearch是一个开源的高扩展的分布式全文检索引擎,它可以实现实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。Elaticsearch使用Java开发并使用Lucene作为其核心来实现索引和搜索的功能,通过简单的RESTful API来隐藏Lucene的复杂性,让全文搜索变得简单易用。
2013年初,GitHub抛弃了Solr,采取ElasticSearch来做PB级的搜索。GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码。
Elasticsearch是面向文档document的,它可以存储对象或文档document。然而它不仅仅是存储,还会索引index每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档进行索引、搜索、排序、过滤。Elasticsearch与关系型数据库对应关系是,数据库Database对应Elasticsearch的索引index;表Table对应Type;数据库记录Row对应文档Document;数据表列Column对应字段Field。
索引index:它是不同类型的文档及其属性的集合。索引还使用分片的概念来提高性能。例如,一组文档包含社交网络应用程序的数据。
类型type:在一个索引中,你可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类/分区,其语义完全由你自己来定。
字段Field:相当于是数据表的列,对文档数据根据不同属性进行的分类标识。
映射mapping:映射是存储在索引中的文档的轮廓。它定义了数据类型,如geo_point或字符串,以及文档中显示的字段的格式和规则,以控制动态添加字段的映射。
文档Document:它是以JSON格式定义的特定方式的字段集合。每个文档都属于一种类型,并且位于索引内。每个文档都与一个称为UID的唯一标识符相关联。
2、IKAnalyzer中文分词
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。