作者:来自 Elastic Lorenzo Soligo

探索多租户 ECK 部署的架构策略,包括软多租户与硬多租户、Kubernetes 隔离以及 Elastic operator 的注意事项。
测试 Elastic 领先的开箱即用功能。浏览我们的示例笔记本,开始免费的云试用,或在本地尝试 Elastic。
解决复杂的基础设施和架构挑战是我们在 Elastic 最喜欢的工作之一。设计可扩展且高效的多租户架构确实是一项艰巨挑战,尤其是在多样化的企业环境中......但哪位工程师不喜欢解决问题呢?
在之前的一篇文章中,我们提到如何在 GKE 上使用 ECK 入门,通过基础设施即代码的方式,使用 Git 和 GitOps 对基础设施进行可管理和可控的操作。在本文中,我们将探索客户在 Elastic Cloud on Kubernetes(ECK)中实现多租户所采用的各种架构方法,概述各自的优缺点,帮助你找到最适合的方案。
免责声明
本文将讨论多租户 ECK 部署的主题,也就是说,我们将重点关注 Kubernetes 内的资源分配。关于 Elasticsearch 内的多租户,请参考 Elastic 官方文档。
多租户:定义
Kubernetes 中的多租户是指在共享 Kubernetes 集群上运行多个用户、团队或组织(租户)的能力,同时保证隔离、安全和资源公平。多租户通过避免为每个租户创建单独集群(可能导致所谓的集群泛滥),实现高效的资源利用和成本节约,并简化运维操作。
我们还可以将多租户 "拆分" 为两个子类别:硬多租户 和软多租户。硬多租户可视为 "物理" 隔离(例如主机级别),而软多租户更像是 "逻辑" 隔离(例如 Kubernetes 命名空间)。
为什么多租户对 ECK 很重要?
虽然 Elasticsearch 和 Kibana 内的多租户经常被讨论且有详细文档,但决定如何在 Kubernetes 上分配 Elastic Stack 部署的架构任务通常高度依赖于用户的具体环境和需求。定义多租户策略需要理解并平衡成本优化、高效资源分配、处理"嘈杂邻居"的可能性、所需硬件可用性以及许多其他虽小但重要的细节。
参考架构 #0:All-in-one
对于首次测试 ECK 的用户,这可能是你进行快速测试时选择的架构。当前,这种部署模型完全可以使用,并提供了一个非常有教学意义的设置,让你了解平台及其功能。只需按照文档说明运行 helm install 或 kubectl apply,即可开始学习 ECK。无论如何,我们以后还有充足时间来提升其弹性和性能。
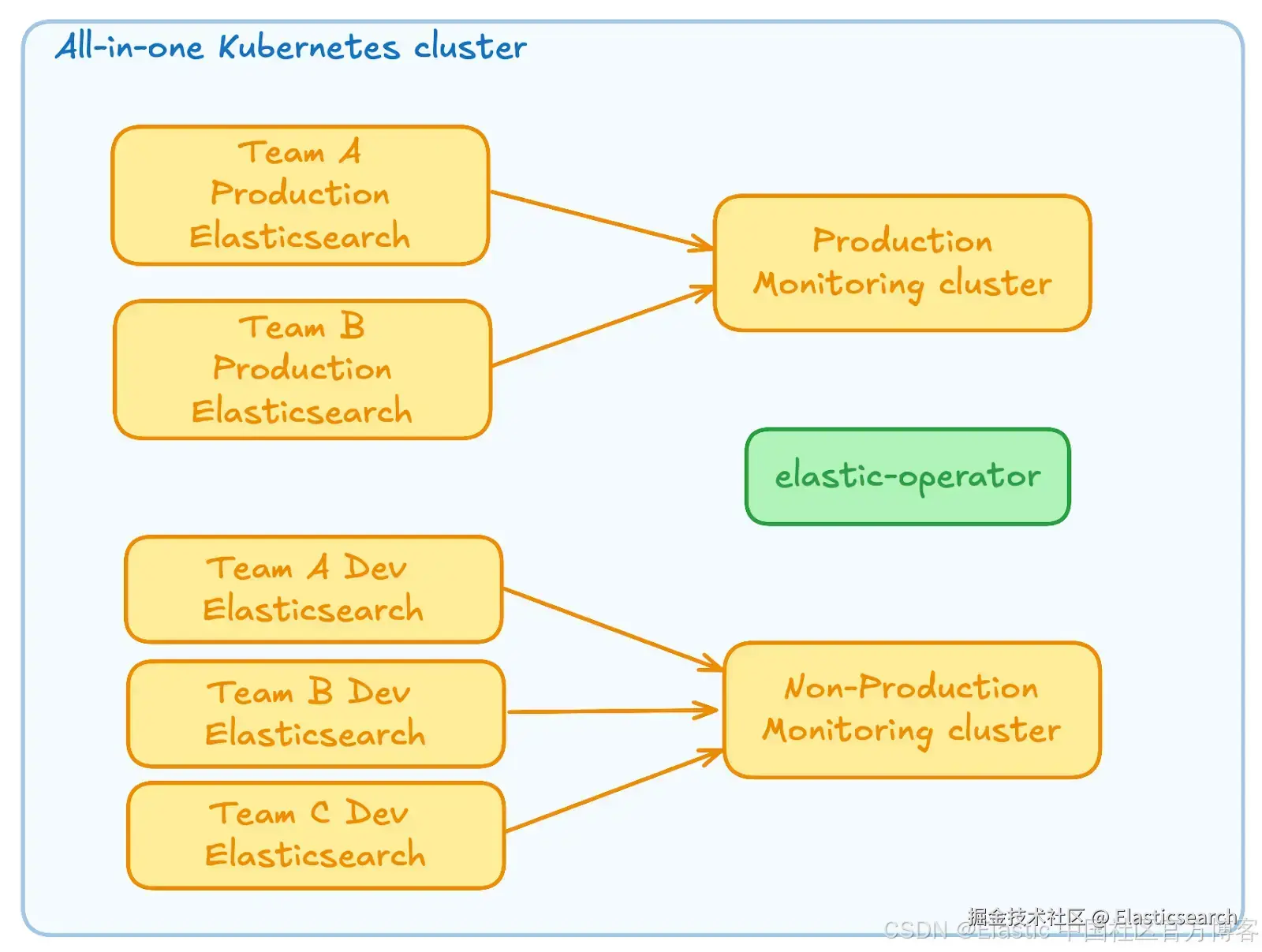
在这个简化架构中,我们有一个单一的 Kubernetes 集群运行:
-
两个监控 Elasticsearch 集群:一个用于 Elastic Stack 的生产部署,另一个用于非生产部署
-
一定数量的生产和非生产 Elasticsearch 集群
当然,在实际场景中,我们很可能还会有 Kibana 部署以及更多组件。目前,我们重点关注 Elasticsearch 作为平台的核心,因为它是有状态的应用程序,比 Kibana 或 Logstash 需要更多关注。
虽然这种架构对于非常简单、非关键任务的部署完全可行,但在尝试应用良好工程实践时,其缺点会很快显现。
具体来说,其优点明显:
-
易于管理:一个 Kubernetes 集群,一个 elastic-operator
-
成本优化:仅有一个 Kubernetes 集群承载所有 pods
然而,其缺点很快就会超过优点,让你对决策感到后悔:
-
没有环境用于测试 Kubernetes 和 elastic-operator 升级,这意味着每次升级都像 "盲打" 一样
-
根据具体实现,这种架构可能导致 "嘈杂邻居" 问题。例如,一个配置错误的开发集群可能会占用底层主机的资源或带宽,从而影响同一主机上部署的 pods 性能
参考架构 #1:生产与非生产
鉴于上一架构的不足,让我们考虑一种可以将生产工作负载与其他负载分离的方法。这听起来是改进平台设计的合理下一步,同时避免过度设计。
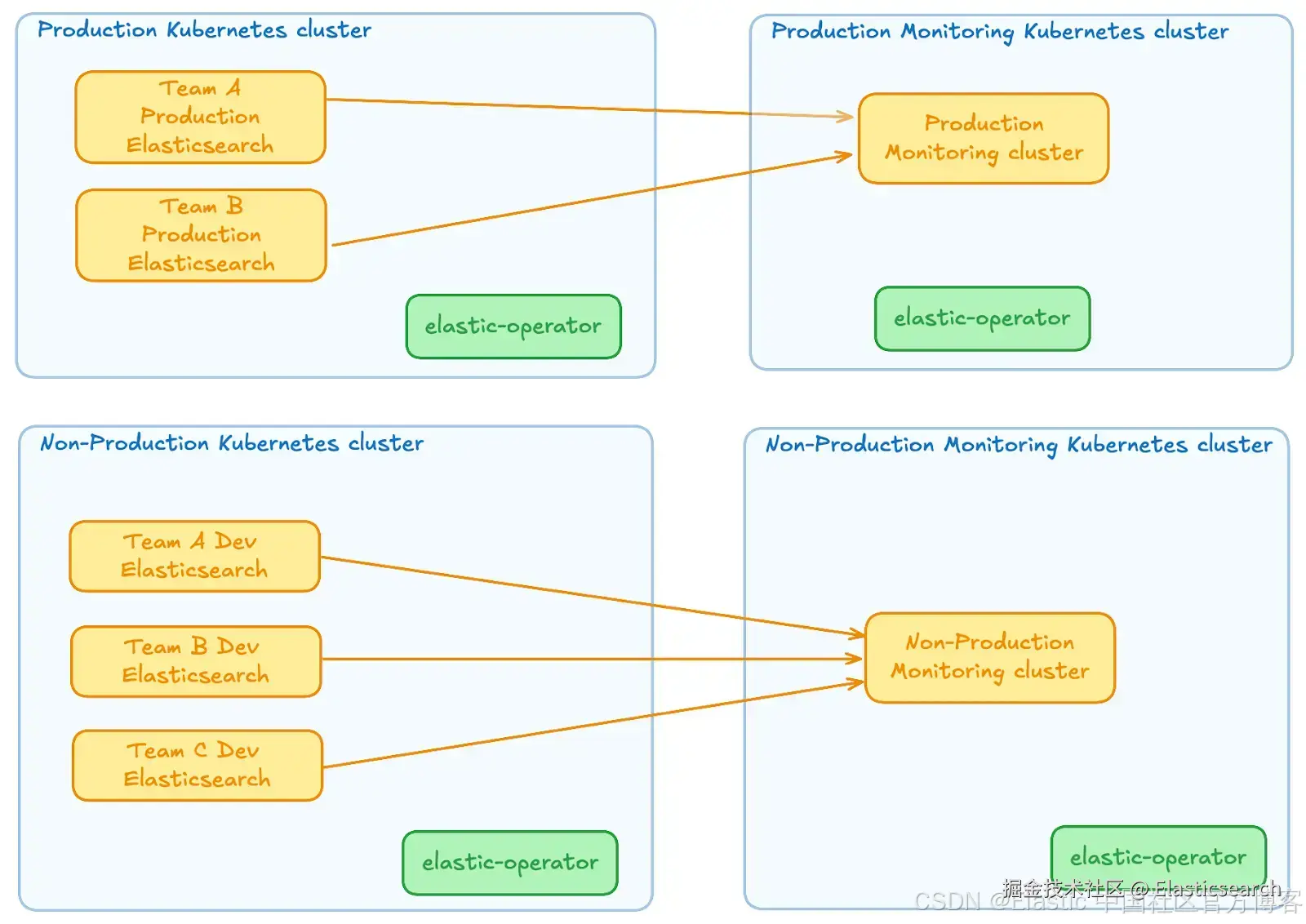
在此设置中,我们将拥有:
-
一个用于生产工作负载的 "数据平面" Kubernetes 集群
-
一个用于非生产工作负载的 "数据平面" Kubernetes 集群
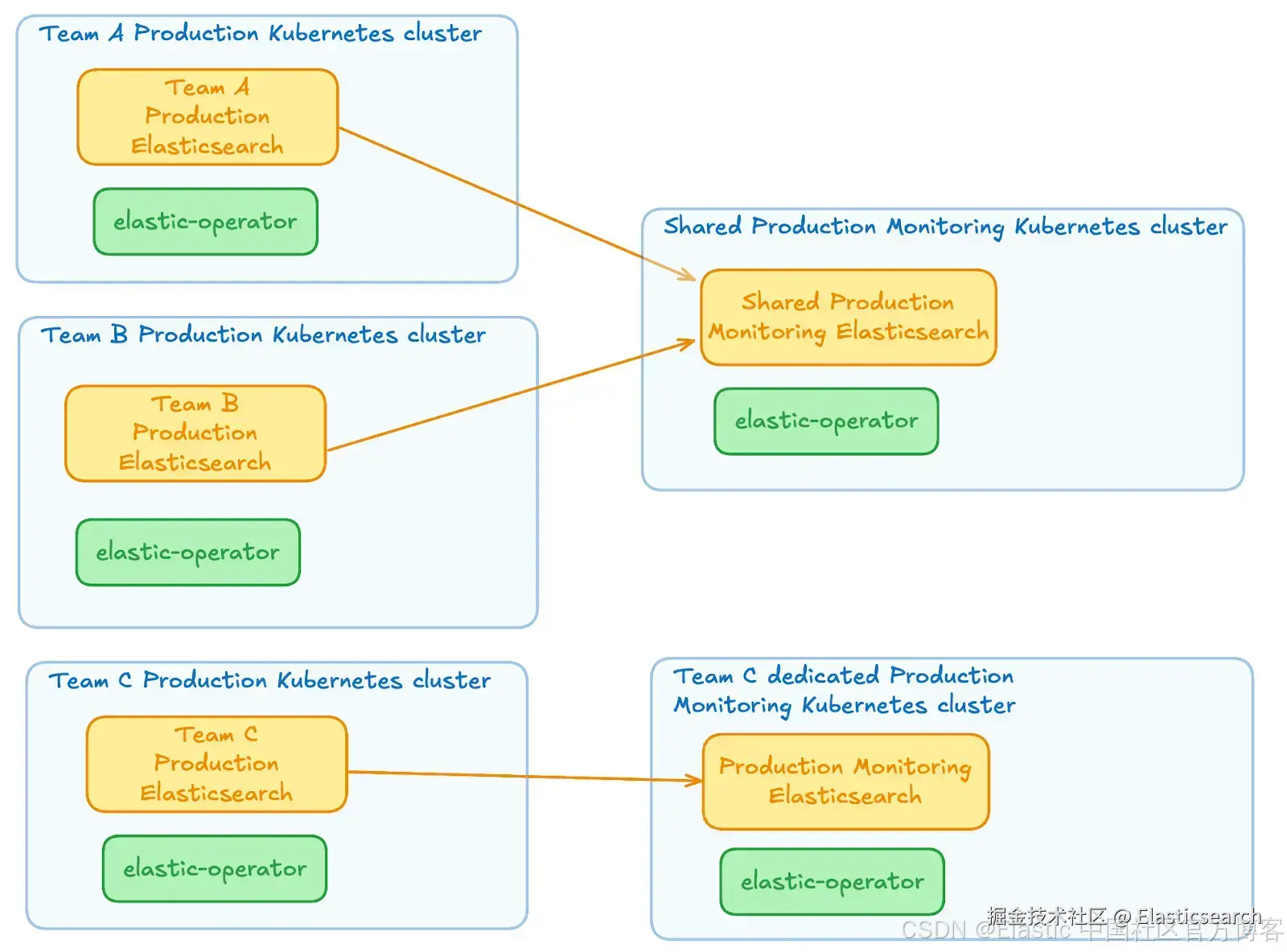
我们可以考虑不同的方式来分配监控集群。
两种主要选项是:
-
生产和非生产监控集群都位于单独的一个 Kubernetes 集群中
-
每个监控集群都位于自己的 Kubernetes 集群中
无论选择哪种方案,将监控 Elasticsearch 集群与其他集群分开都是至关重要的。我们不希望因为某些问题,同时失去 "工作负载" Elasticsearch 集群及其对应的监控集群。
这种架构看起来是一个不错的折中方案,因为它允许我们完全分离生产和非生产工作负载。这意味着我们可以在安全环境中测试多个升级(Kubernetes、Elasticsearch 和 elastic-operator),然后再推广到生产环境。这种隔离程度还保证了低环境(例如开发集群)配置错误时不会影响生产集群。
在接下来的部分中,我们将展示该架构的两种不同迭代 ------ 一种依赖于软多租户,另一种依赖于硬多租户。这类架构的一个有趣副产品是,鉴于 Elastic 的许可结构(一个 Enterprise 许可可以在多个 operator 之间共享),且 elastic-operator 资源需求低(例如 Helm chart 中限制为 1Gi 和 1vCPU),资源和许可的成本开销最小。
参考架构 #1:基于团队的软多租户
在此架构中,高层次的设置保持不变。变化在于数据平面集群中 pods 的分配。让我们重点关注这一点:
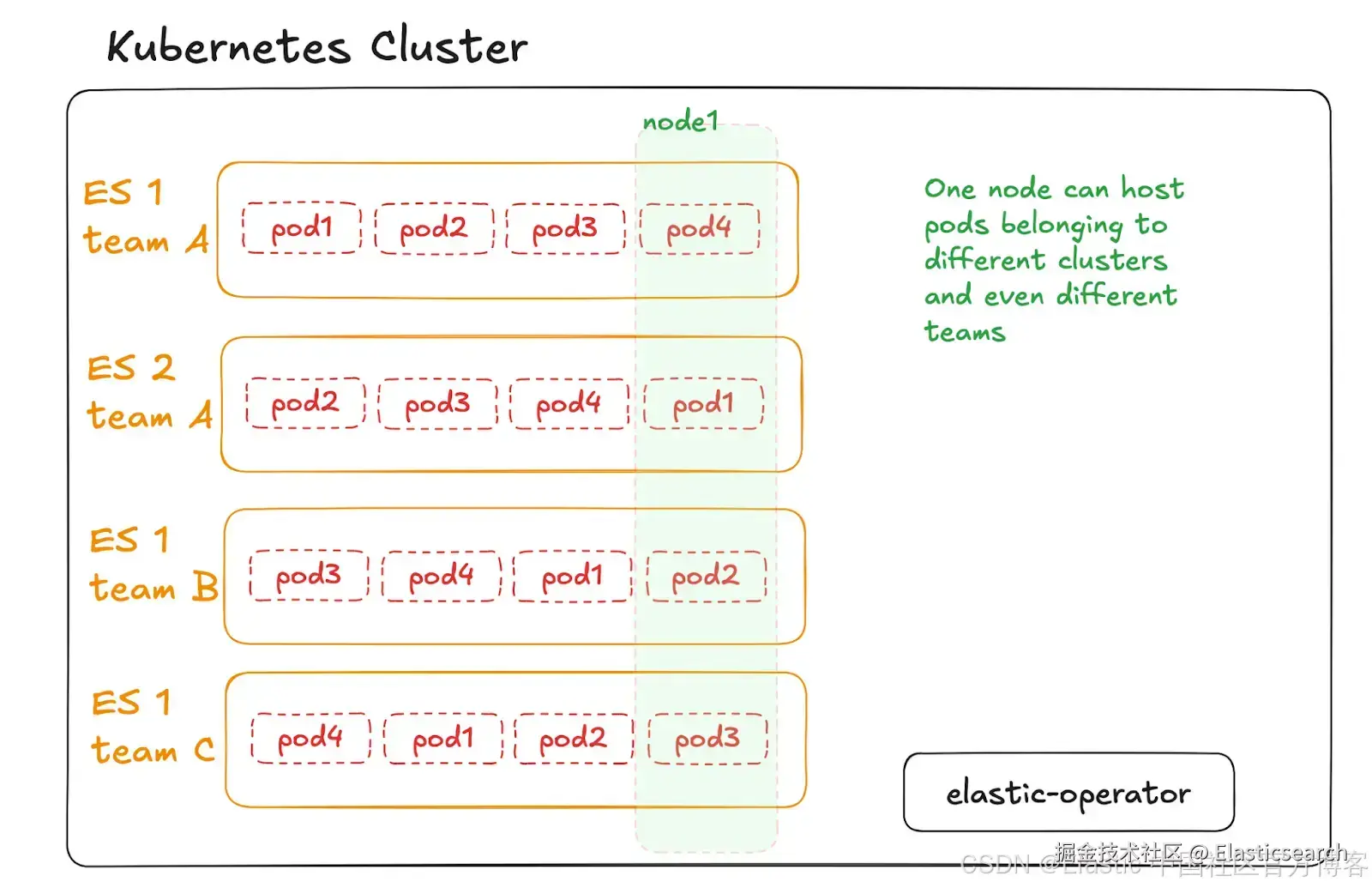
在此架构中,我们使用 Kubernetes 命名空间实现"软"多租户。这意味着 Kubernetes 集群中的每个节点可以承载属于不同 Elasticsearch 集群和不同团队的 pods(即 Elasticsearch 节点)。然而,命名空间通过 RBAC 限制了访问人数,每个团队只能访问自己的工作负载。
这里展示的架构对于大多数 ECK 部署中的多租户用例来说,很可能是复杂性与灵活性之间的最佳平衡点。这种设计适用于租户在 Elastic Stack 配置上需要一定独立性的场景,同时仍能利用共享 Kubernetes 基础设施带来的运维效率。
参考架构 #1:基于团队的硬多租户
该架构比前一个稍微复杂一些,但在需要 "物理" 分离各个 Elasticsearch 集群时可能很有用。与之前类似,高层次设置保持与参考架构 #1 完全相同。变化在于数据平面集群中 pods 的分配方式。
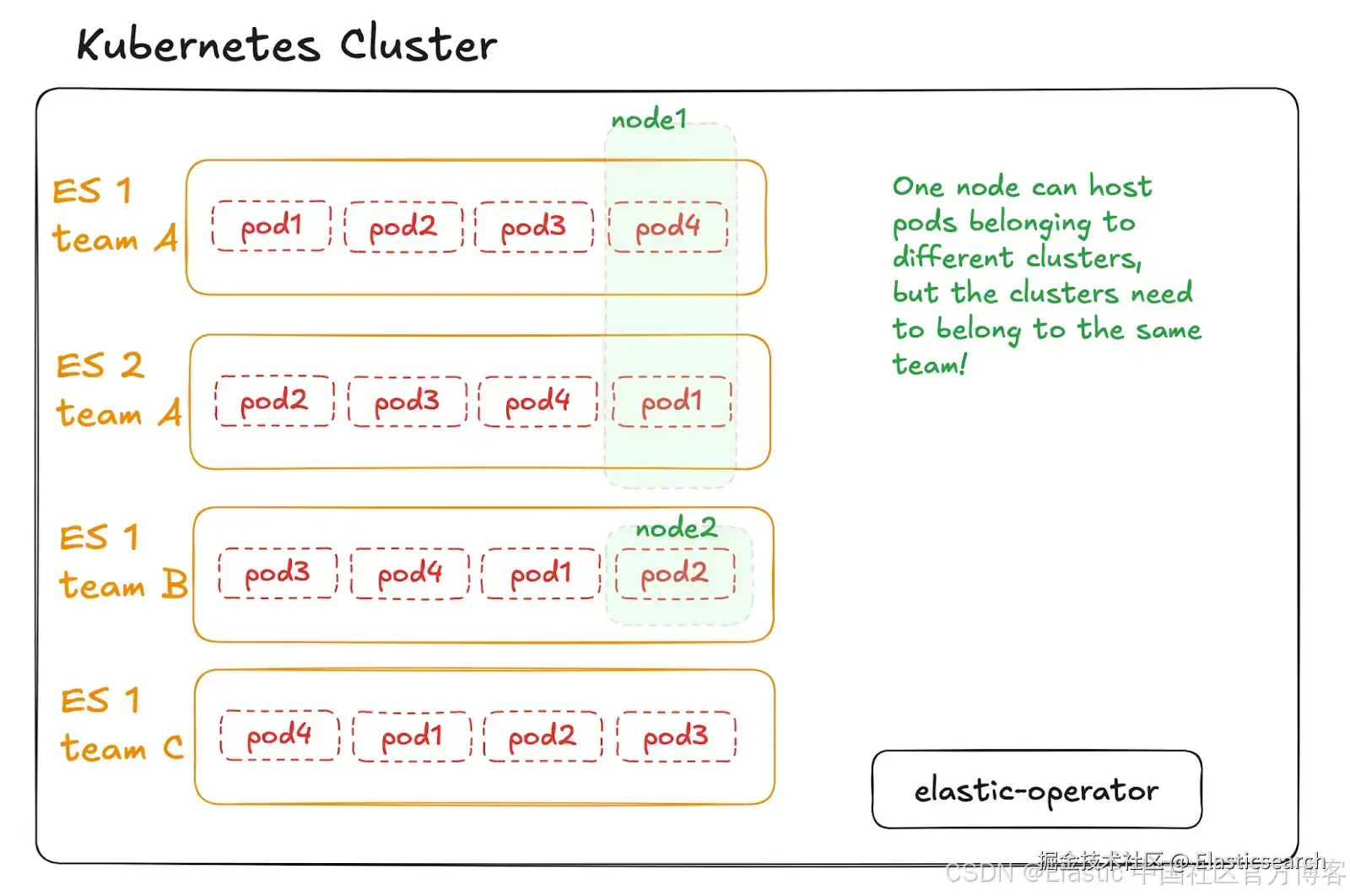
在此架构中,我们使用 Kubernetes 命名空间实现"软"多租户,并结合 Kubernetes 的 taints、tolerations 和 nodeAffinity 实现 "硬" 多租户,从而确保 Kubernetes 集群中的节点只承载属于同一团队的 Elasticsearch 集群的 pods。该场景强制执行更严格的职责分离,但代价是:实际上,这种部署不太可能实现类似的资源和成本效率,因为它可能需要向 Kubernetes 集群添加比严格必要更多的节点,导致部分节点可能被低效利用。
如前所述,这种架构并非总是必要或推荐。然而,在以下场景中,这种高度隔离可能是合理的:
-
PCI-DSS(支付卡行业数据安全标准):有助于满足按业务"知情需要"限制访问持卡人数据的要求
-
HIPAA(健康保险流通与责任法案):要求严格的数据隔离,尤其是 ePHI(电子受保护健康信息)
-
政府或国防环境:项目或团队间的隔离可能是强制性的(例如 FedRAMP)
以下是 Elasticsearch CR 的示例。为了演示目的,我们假设节点已被污染并被标记,如图所示。
yaml
`
1. apiVersion: elasticsearch.k8s.elastic.co/v1
2. kind: Elasticsearch
3. metadata:
4. name: cluster-a
5. namespace: team-a
6. spec:
7. [...]
8. podTemplate:
9. metadata:
10. labels:
11. elasticsearch.k8s.elastic.co/cluster-name: cluster-a
12. spec:
13. tolerations: # I "accept" the nodes defined for my team
14. - key: "taints.demo.elastic.co/team"
15. operator: "Equal"
16. value: "team-a"
17. effect: "NoSchedule"
18. affinity: # I want the nodes defined for my project
19. nodeAffinity:
20. requiredDuringSchedulingIgnoredDuringExecution:
21. nodeSelectorTerms:
22. - matchExpressions:
23. - key: "labels.demo.elastic.co/team"
24. operator: "In"
25. values:
26. - "team-a"
27. podAntiAffinity: # Try to not put me on the same host where other pods for the same ES cluster are running
28. preferredDuringSchedulingIgnoredDuringExecution: # or requiredDuring...
29. - weight: 100
30. podAffinityTerm:
31. labelSelector:
32. matchLabels:
33. elasticsearch.k8s.elastic.co/cluster-name: cluster-a
34. topologyKey: kubernetes.io/hostname
`AI写代码甚至可以将此架构进一步扩展,使 Kubernetes 集群中的节点仅承载单个 Elasticsearch 集群的 pods,从而保证更高水平的资源隔离 ------ 但资源效率会更低。
参考架构 #2:每个 Elasticsearch 部署一个 Kubernetes 集群
许多 Elastic Stack 管理员选择 Elasticsearch 集群与 Kubernetes 集群之间的 1:1 映射,即每个 Kubernetes 集群完全专用于一个 Elasticsearch 集群。这允许更强的硬多租户,并且不需要配置节点污点(taints)和容忍设置(tolerations),但需要具备管理多 Kubernetes 集群的能力,这本身就是一项任务。如本文前文所述,你并不希望出现集群泛滥;因此,自动化和集群管理需要成熟且稳固。
对于需要完全隔离的用例,这种架构是完全可行的------再次强调,适用于遵循特别严格资源隔离要求的环境(例如 FedRAMP),在这些场景中,即便是硬多租户也可能不被视为可行选项。然而,本文不会深入讨论这种架构,因为这种设计几乎不存在多租户挑战 ------ 它是你能期望的最强多租户机制之一。
在示例图中,你会看到多个 Kubernetes 集群,每个集群运行 elastic-operator 和一个 Elasticsearch 集群。监控集群的管理方式可以灵活设计,例如可以基于共享监控集群的方式,同时为高敏感工作负载增加一些专用监控集群。
额外部分:elastic-operator 多租户
到目前为止,我们主要讨论了 Elasticsearch 集群本身的多租户。然而,也可以认为需要关注 Elastic operator 的多租户。例如,某些 elastic-operator 升级可能会导致该 operator 管理的 Elasticsearch 集群滚动重启,尤其是在特定版本下。
为了能够更精细地控制 operator 的升级过程,可以考虑让一个 operator 仅属于某个租户,如公司内的开发团队或业务部门。
这种隔离方式还允许使用命名空间 CRD,从而实现更细粒度的新版本发布。如果目标 elastic-operator 版本需要滚动重启,这可以进一步控制 Elasticsearch 集群的重启过程(例如新主版本)。
部署多个 elastic-operator 可以让你将升级策略应用于特定租户,而不仅仅是整个环境,有效地创建一种金丝雀部署模型。
结论
要点 #1
ECK 多租户可以在多个层面实现:
-
在 Elasticsearch 集群内部
-
在 Kubernetes 集群内部,逻辑上
-
在 Kubernetes 集群内部,"物理上"
-
在云提供商层(安全组、NACL 等)
-
在 operator 和控制平面层
理想情况下,上述层面的组合可以帮助我们实现目标。
要点 #2
正如常言道,没有免费的午餐:
-
节点越多 => "浪费"的资源越多
-
DaemonSets 对资源使用百分比影响更大
-
bin-packing 变得更困难
-
负载均衡器越多 => 基础成本越高
-
Kubernetes 集群越多 => 基础成本越高
要点 #3
实践重于纯粹:
-
有些纸面上完美的架构,管理起来可能很困难且成本过高。这类架构的体验可能比更简单、稍微不完美的方案更差
-
Kubernetes 天生适合在同一节点上运行几十个 pods。仅因为不信任 Kubernetes 而强制节点只运行 1 或 2 个工作负载可能不是好主意......除非我们确实不相信自己能配置得当。