最近在做项目时,需要在服务器端获取客户端的麦克风输入语音,然后将语音识别成文字再返回给客户端。然后体验了阿里开源的FunASR,确实让人眼前一亮,主要部署相对简单(但还是走了一些抗,不过是我自己的问题。)其核心的Paraformer模型,号称"非自回归",实际体验下来,推理速度确实可以,接近实时,对追求效率的应用非常友好。 另一个亮点是"一体化"解决方案。它将语音端点检测(VAD)、标点恢复(PUNC)和ASR无缝串联,省去了自己拼接模块的麻烦。而且在这些环节还可以自己替换想用的模型开箱即用的体验极佳。在官方仓库中,还给出了许多使用demo,可以说非常的贴心。本文就使用的它给的websockt中的例子进行讲解,只需要改一两行代码就可以完美运行。 废话不多说,现在开始。
服务器端环境搭建
初始化目录
服务器环境,我放在了腾讯云的cloud studio上,安装环境配置什么的都很方便(没广告费,就不详细介绍了)。当然如果本地有环境的话,可以使用本地环境,显存只要3G就够用了。 首先使用uv初始化目录。
shell
uv init asr-server-learn
cd asr-client-server-learn
# 创建并激活虚拟环境
uv venv
.venv\Scripts\activate安装依赖
使用uv初始化环境时,如果为安装python,默认会下载最新的python版本,如果想自定义下载版本比如3.12,可以使用uv python install 3.12这个命令下载,但是由于github的原因可能会下载失败,如果目前我只知道两种办法解决,如果想要了解的可以留言,就不再这篇博客详细说了。
然后克隆FunASR仓库,如果无法访问的话,可以通过gitee来克隆,不知道怎么操作的话可以留言寻求帮助。 进入websockt的例子目录FunASR\runtime\python\websocket,修改代码,关闭ssl验证功能,非常简单,操作如下:
python
# 在`funasr_wss_server.py`文件下找到如下代码:
parser.add_argument(
"--certfile",
type=str,
default="../../ssl_key/server.crt",
required=False,
help="certfile for ssl",
)
# 替换为
parser.add_argument(
"--certfile",
type=str,
default="",
required=False,
help="certfile for ssl",
)如果这样的话,在运行时会出现如下错误: 
然后安装client所需的包,具体命令如下:
shell
uv add -r .\requirements_server.txt这样安装的依赖不全,不过不用担心uv run funasr_wss_server.py运行这个命令会提示有哪些包没装,就像下面这样  然后使用
然后使用uv add omegaconf添加依赖就行了,然后继续运行funasr_wss_server.py这个文件,每缺一个依赖,就使用uv add挨个添加就行。 当然如果想一步到位安装全部的依赖的话,评论说一下,我会传到GitHub上,暂时懒得传了。 依赖安装完成后,运行funasr_wss_server.py启动websocket服务端,还是这个命令。
shell
uv run funasr_wss_server.py第一次运行会网上下载所需的模型,如果是本地部署,也可以提前下载模型,但是需要改下相关代码,如果不知道如何改的话,后续我会补充(想得起来的话)。 等模型下载完成后,依赖也全部安装完成的话,再运行funasr_wss_server,不出意外的话,你会得到下面这个报错no runing event_loop: 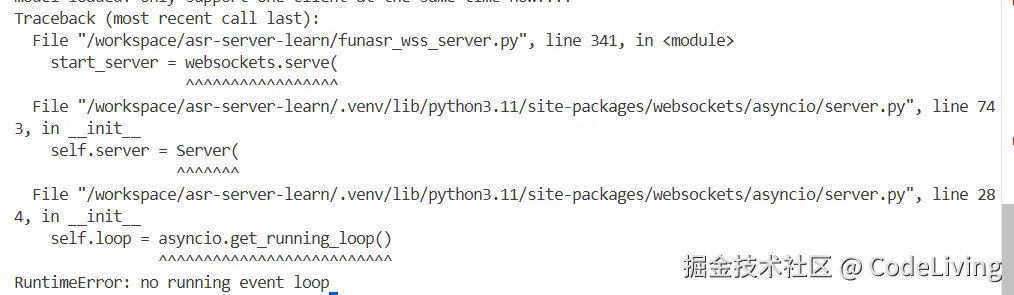 不要灰心,这已经完成服务器端部署80%的工作了,胜利就在眼前。这就需要改代码了。
不要灰心,这已经完成服务器端部署80%的工作了,胜利就在眼前。这就需要改代码了。
修改代码
首先在funasr_wss_server.py文件最下面,找到如下代码并全部注释掉。 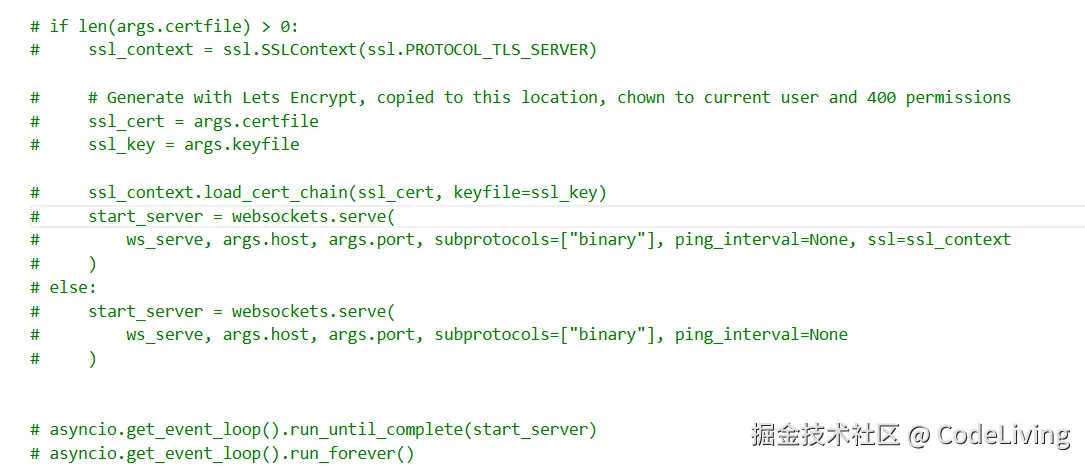 这是已经注释过了,然后在文件最下方添加如下代码
这是已经注释过了,然后在文件最下方添加如下代码
python
async def main():
async with websockets.serve(
ws_serve, args.host, args.port, subprotocols=["binary"], ping_interval=None
) as server:
# 保持服务器运行
await asyncio.Future() # 这会让服务器一直运行
asyncio.run(main())最后,运行命令uv run funasr_wss_server.py,如果你看到下面这样, 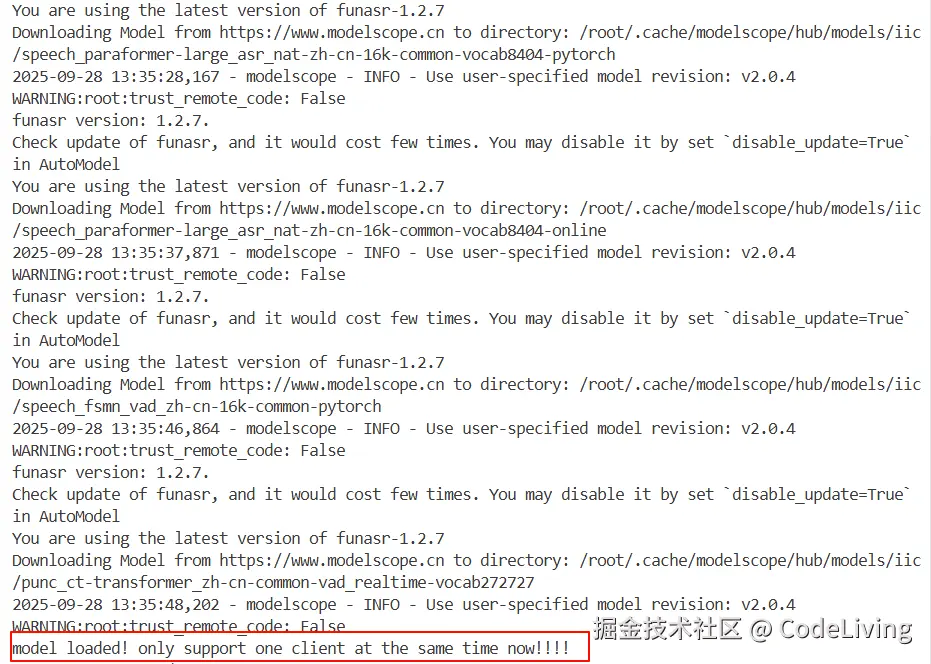 那么恭喜你,服务器端运行成功。
那么恭喜你,服务器端运行成功。
客户端环境搭建
初始化目录和安装依赖
首先在本地使用uv初始化目录,千万不要在腾讯云服务器端,不然,就算连接成功,也识别不出来语音。
shell
uv init asr-client-learn
cd asr-client-learn
# 创建并激活虚拟环境
uv venv
.venv\Scripts\activate进入websockt的例子目录FunASR\runtime\python\websocket,然后安装client所需的包,具体命令如下:
shell
uv add -r .\requirements_client.txt同样,在安装依赖时,也会出现和服务器端安装依赖一样的问题,解决方法同上。
修改代码
在FunASR\runtime\python\websocket目录下找到funasr_wss_client.py文件并打开。 先修改--ssl参数为0,关闭ssl功能。  然后将
然后将--host参数中的默认地址修改为服务器的地址。先打开腾讯云服务器的页面,然后点击端口管理(红箭头的按钮)。 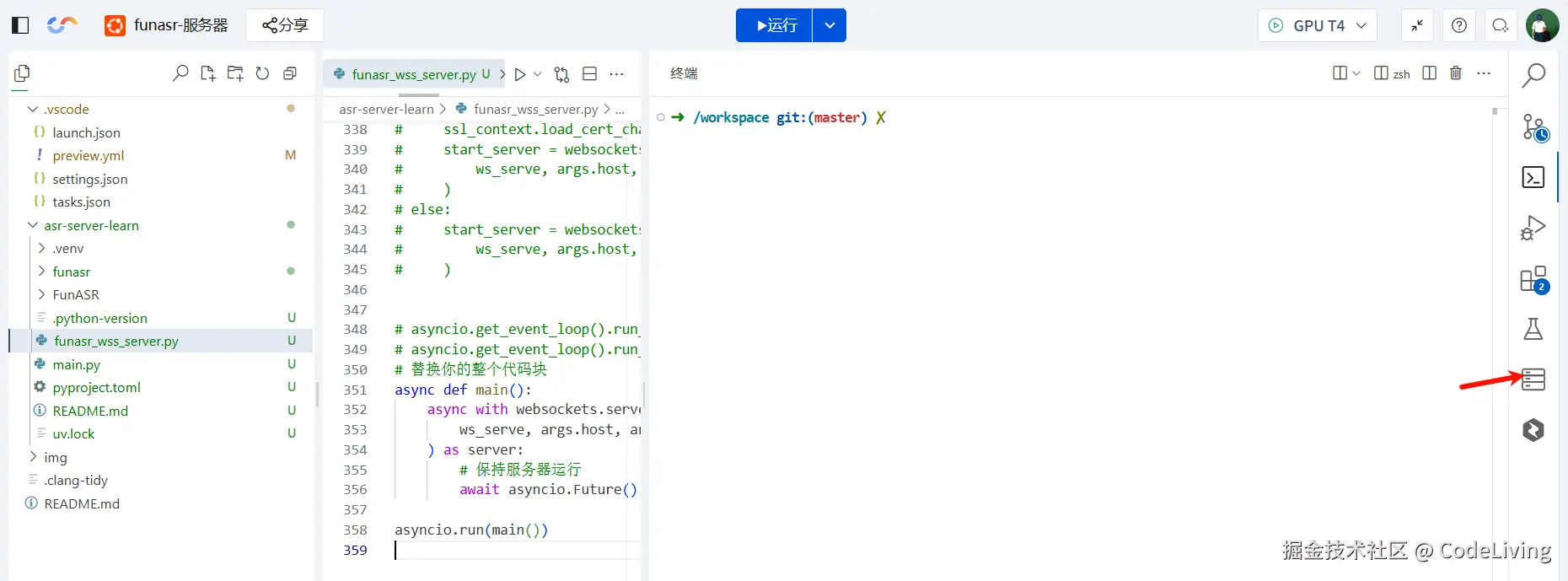
点击红色方框中的链接复制下来,注意要看好端口号是10095。 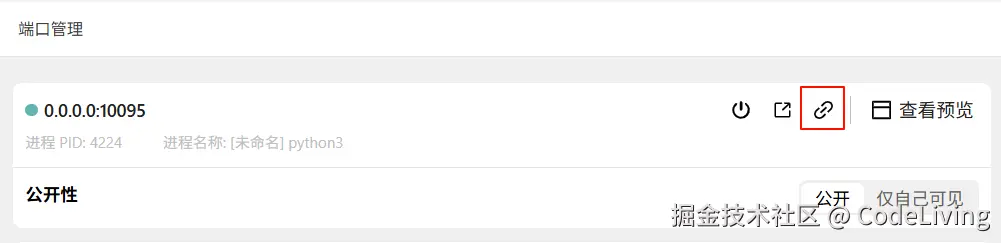 将链接复制到
将链接复制到--host的默认参数中。 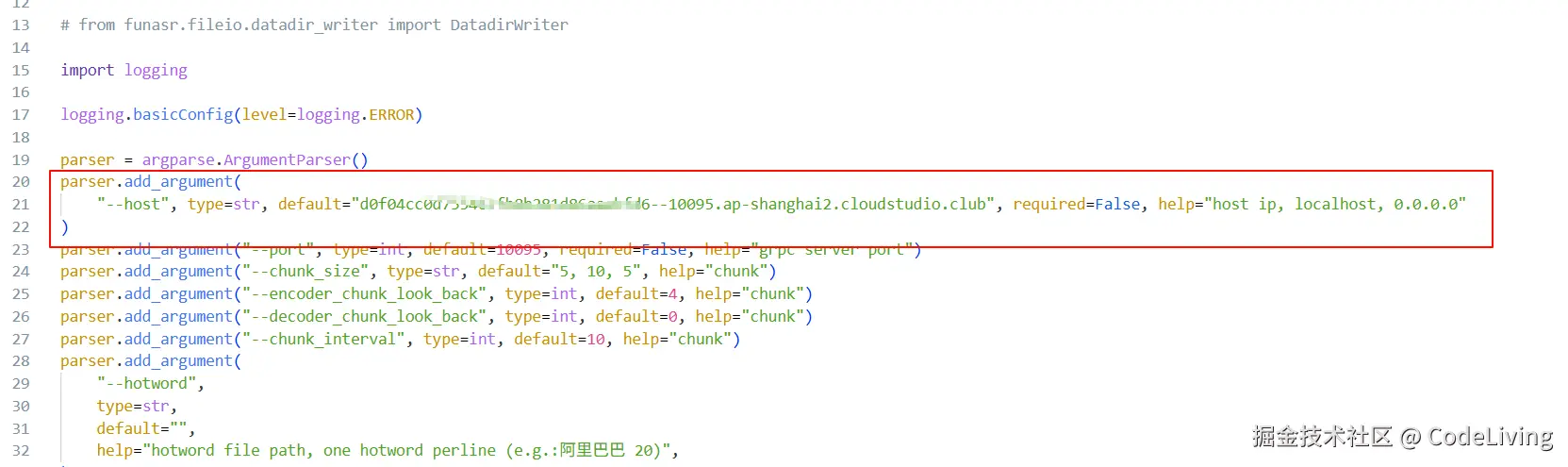 然后使用
然后使用uv run funasr_wss_client.py运行客户端命令,如果显示connect to....表示连接成功,注意要把服务器端也运行起来哦。  接下来就可以测试了最近在做项目时,需要在服务器端获取客户端的麦克风输入语音,然后将语音识别成文字再返回给客户端。然后体验了阿里开源的FunASR,确实让人眼前一亮,主要部署相对简单(但还是走了一些抗,不过是我自己的问题。)其核心的Paraformer模型,号称"非自回归",实际体验下来,推理速度确实可以,接近实时,对追求效率的应用非常友好。 另一个亮点是"一体化"解决方案。它将语音端点检测(VAD)、标点恢复(PUNC)和ASR无缝串联,省去了自己拼接模块的麻烦。而且在这些环节还可以自己替换想用的模型开箱即用的体验极佳。在官方仓库中,还给出了许多使用demo,可以说非常的贴心。本文就使用的它给的websockt中的例子进行讲解,只需要改一两行代码就可以完美运行。 废话不多说,现在开始。
接下来就可以测试了最近在做项目时,需要在服务器端获取客户端的麦克风输入语音,然后将语音识别成文字再返回给客户端。然后体验了阿里开源的FunASR,确实让人眼前一亮,主要部署相对简单(但还是走了一些抗,不过是我自己的问题。)其核心的Paraformer模型,号称"非自回归",实际体验下来,推理速度确实可以,接近实时,对追求效率的应用非常友好。 另一个亮点是"一体化"解决方案。它将语音端点检测(VAD)、标点恢复(PUNC)和ASR无缝串联,省去了自己拼接模块的麻烦。而且在这些环节还可以自己替换想用的模型开箱即用的体验极佳。在官方仓库中,还给出了许多使用demo,可以说非常的贴心。本文就使用的它给的websockt中的例子进行讲解,只需要改一两行代码就可以完美运行。 废话不多说,现在开始。
服务器端环境搭建
初始化目录
服务器环境,我放在了腾讯云的cloud studio上,安装环境配置什么的都很方便(没广告费,就不详细介绍了)。当然如果本地有环境的话,可以使用本地环境,显存只要3G就够用了。 首先使用uv初始化目录。
shell
uv init asr-server-learn
cd asr-client-server-learn
# 创建并激活虚拟环境
uv venv
.venv\Scripts\activate安装依赖
使用uv初始化环境时,如果为安装python,默认会下载最新的python版本,如果想自定义下载版本比如3.12,可以使用uv python install 3.12这个命令下载,但是由于github的原因可能会下载失败,如果目前我只知道两种办法解决,如果想要了解的可以留言,就不再这篇博客详细说了。
然后克隆FunASR仓库,如果无法访问的话,可以通过gitee来克隆,不知道怎么操作的话可以留言寻求帮助。 进入websockt的例子目录FunASR\runtime\python\websocket,修改代码,关闭ssl验证功能,非常简单,操作如下:
python
# 在`funasr_wss_server.py`文件下找到如下代码:
parser.add_argument(
"--certfile",
type=str,
default="../../ssl_key/server.crt",
required=False,
help="certfile for ssl",
)
# 替换为
parser.add_argument(
"--certfile",
type=str,
default="",
required=False,
help="certfile for ssl",
)如果这样的话,在运行时会出现如下错误:
然后安装client所需的包,具体命令如下:
shell
uv add -r .\requirements_server.txt这样安装的依赖不全,不过不用担心uv run funasr_wss_server.py运行这个命令会提示有哪些包没装,就像下面这样 然后使用uv add omegaconf添加依赖就行了,然后继续运行funasr_wss_server.py这个文件,每缺一个依赖,就使用uv add挨个添加就行。 当然如果想一步到位安装全部的依赖的话,评论说一下,我会传到GitHub上,暂时懒得传了。 依赖安装完成后,运行funasr_wss_server.py启动websocket服务端,还是这个命令。
shell
uv run funasr_wss_server.py第一次运行会网上下载所需的模型,如果是本地部署,也可以提前下载模型,但是需要改下相关代码,如果不知道如何改的话,后续我会补充(想得起来的话)。 等模型下载完成后,依赖也全部安装完成的话,再运行funasr_wss_server,不出意外的话,你会得到下面这个报错no runing event_loop: 不要灰心,这已经完成服务器端部署80%的工作了,胜利就在眼前。这就需要改代码了。
修改代码
首先在funasr_wss_server.py文件最下面,找到如下代码并全部注释掉。 这是已经注释过了,然后在文件最下方添加如下代码
python
async def main():
async with websockets.serve(
ws_serve, args.host, args.port, subprotocols=["binary"], ping_interval=None
) as server:
# 保持服务器运行
await asyncio.Future() # 这会让服务器一直运行
asyncio.run(main())最后,运行命令uv run funasr_wss_server.py,如果你看到下面这样, 那么恭喜你,服务器端运行成功。
客户端环境搭建
初始化目录和安装依赖
首先在本地使用uv初始化目录,千万不要在腾讯云服务器端,不然,就算连接成功,也识别不出来语音。
shell
uv init asr-client-learn
cd asr-client-learn
# 创建并激活虚拟环境
uv venv
.venv\Scripts\activate进入websockt的例子目录FunASR\runtime\python\websocket,然后安装client所需的包,具体命令如下:
shell
uv add -r .\requirements_client.txt同样,在安装依赖时,也会出现和服务器端安装依赖一样的问题,解决方法同上。
修改代码
在FunASR\runtime\python\websocket目录下找到funasr_wss_client.py文件并打开。 先修改--ssl参数为0,关闭ssl功能。 然后将--host参数中的默认地址修改为服务器的地址。先打开腾讯云服务器的页面,然后点击端口管理(红箭头的按钮)。
点击红色方框中的链接复制下来,注意要看好端口号是10095。 将链接复制到--host的默认参数中。 然后使用uv run funasr_wss_client.py运行客户端命令,如果显示connect to....表示连接成功,注意要把服务器端也运行起来哦。 接下来就可以测试了
测试
普通话测试  河南方言测试
河南方言测试 
其他的报错解决办法
Python.h: No such file or directory`
使用uv安装pyaudio这个库的时候如何出现这个错误: src/pyaudio/device_api.h:7:10: fatal error: Python.h: No such file or directory。 那么就需要使用sudo apt-get install python3-dev安装python开发库。目前我只在linux系统发现过这个问题,windows平台下还没发现过。
我计划创建一个学习群,大家可以在群里讨论问题,也会不定期分享一些大模型学习资料。有兴趣可以添加我的微信jsmxok。添加时请备注 学习
参考
测试
普通话测试 河南方言测试
其他的报错解决办法
Python.h: No such file or directory`
使用uv安装pyaudio这个库的时候如何出现这个错误: src/pyaudio/device_api.h:7:10: fatal error: Python.h: No such file or directory。 那么就需要使用sudo apt-get install python3-dev安装python开发库。目前我只在linux系统发现过这个问题,windows平台下还没发现过。
我计划创建一个学习群,大家可以在群里讨论问题,也会不定期分享一些大模型学习资料。有兴趣可以添加我的微信jsmxok。添加时请备注 学习