我总要言说一些东西,因为我的心始终在喋喋不休。
前言
HTTP的发展现状
最近脑海里面始终活跃着一些想法,一部分是对过去错误认知的纠正,比如HTTP/2。在《HTTP学习笔记(三) HTTP/2》,这里已经提过了,HTTP 1.0的性能缺点是每一个连接都对应一个TCP连接,到HTTP 1.1对这个问题进行了解决,也就是keep-alive和流水线,所谓keep-alive, 也就是说客户端和服务端请求维持这个TCP连接一段时间,这样有效的减少了频繁建立TCP连接的开销。
而流水线则是允许客户端在收到上一个响应之前,连续发送其他请求,这看起来是个不错的设计,有效的将请求报文传输并行化。但这一般是一个误解,英文原文是:
HTTP pipelining is a way to send another request while waiting for the response to a previous request.
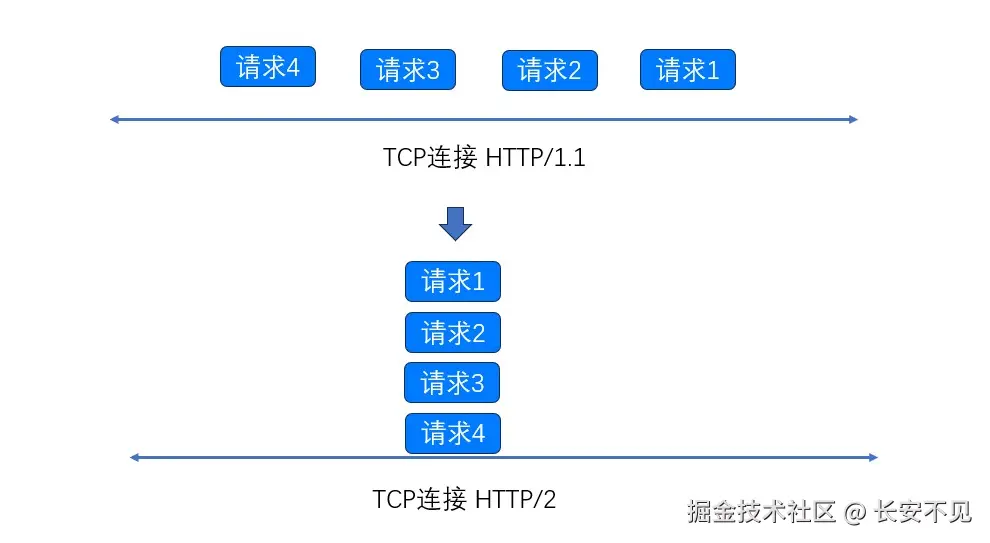
但其实表达的真实意思应该是将多个HTTP请求放到一个TCP连接中一一发送,而在发送过程中不需要等待服务器对前一个请求的响应。但是遗憾的是HTTP 1.1 要求,服务器必须严格按照接收到请求的相同顺序来回送HTTP响应。但就像在超市排队一样,如果队头的人买了很多东西,那么后续排队人都要在这里等待。
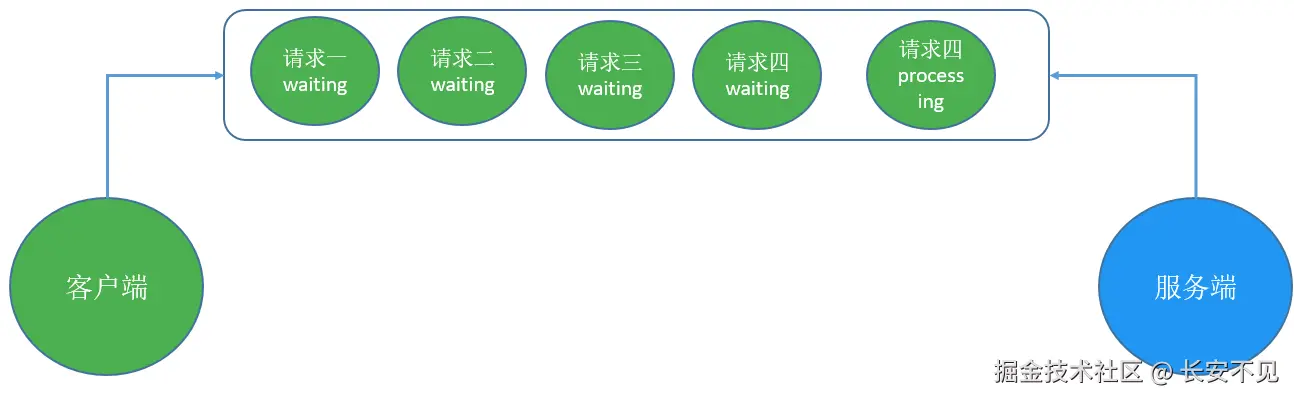
当然你也可以和超市协商再起一个新队伍,即新建一个TCP连接。但不管怎么样,你总归得选择一个队伍,而且一旦选定之后,就不能更换队伍。但是新队伍也会导致资源耗费和性能损失。
我们分析一下HTTP 1.1 为什么要这么要求,原因在于如果不强制要求顺序,那接收响应的时候怎么知道对应的是哪个请求的呢? 于是这些HTTP请求看起来还是串行处理,在一个TCP连接上。
管线化的问题
管线化的思路没什么问题,我们在RFC-2616,也就是参考文档2可以看到对管线化的论述:
Clients which assume persistent connections and pipeline immediately after connection establishment SHOULD be prepared to retry their connection if the first pipelined attempt fails.
If a client does such a retry, it MUST NOT pipeline before it knows the connection is persistent. Clients MUST also be prepared to resend their requests if the server closes the connection before sending all of the corresponding responses
那些假定连接是持久的、并且在连接建立后立即使用流水线的客户端,应该准备好在第一次流水线尝试失败之后,重试他们与服务器之间的连接。如果客户端进行了这样的重试,那么在它确认该连接是持久的之前,客户端必须禁止再次使用流水线。如果客户端在发送完所有的响应之前就关闭了连接,客户端必须准备重发它们的请求。
注意这个持久连接,默认情况下,HTTP/1.0会在每次请求/响应交互关闭连接,这个连接是TCP连接,因此HTTP/1.0的持久连接必须经过明确协商。也就是请求头里面加入Connection: keep-alive来保持连接,连接的其他参数可以通过 keep-alive来指定,如果希望关闭连接,则是在请求标头里面加入Connection:close。这是http/1.0请求的默认值。如果在Http/1.1下面将会自动维持长连接,自动启用keep-alive。
注意这里的话,我认为这个假设有点脆弱,原因在于没有经过假设,客户端只能通过猜测的方式来判断服务器是否支持这一特性,为什么这么说呢? 原因在于我们考虑服务端早期对 http 1.0的支持,许多Http 1.1web服务器是从 1.0演变过来的,由于无法判断这一特性是否被这些服务器支持,客户端必须猜测这一特性是否被服务端支持。在参考资料可以看到,火狐浏览器为了支持这个特性做出的努力,通过尝试和维护黑名单(网站不支持加入黑名单,黑名单里面的网站默认不会开启这个特性),最终还是发现风险大于收益。
举个例子,请求A、B、C依次到达代理服务器,假设代理服务器不支持这一特性,返回顺序是B、C、A,对于一些页面渲染就会出现问题。由此就引出来了HTTP/2的多路复用。
多路复用解决了这个问题
观测流水线
我们在这里再度明确一下,我们希望在发送请求的时候尽可能的降低延迟,但是遇到有依赖的网络资源的话,HTTP 1.1给出的方案是可以向服务端发送多个请求而不等待响应。一般我们用HttpClient发送请求的伪代码如下所示:
java
Request request = new Request():
response = httpclient.send(request);在Http 1.1下面我们可以写成下面这样:
java
// 注意这里是伪代码
Request requestOne = new Request();
Request requestTwo = new Request():
List<Request> listRequest = new ArrayList<>();
listRequest.add(requestOne);
listRequest.add(requestTwo);
List<Response> response = httpclient.send(request);注意这里的核心问题在于,如何知道请求和响应之间的对应关系,HTTP /1.1的设计响应顺序即为发送请求的顺序。我们不妨看看一些Http Client是怎么实现你这个特性的,这里以Vertx为例我们来做个简单的分析, 首先我们需要引入Vertx:
xml
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web-client</artifactId>
<version>5.0.4</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
<version>5.0.4</version>
</dependency>注意如果你在Spring Boot 中写Vertx相关的代码,会有依赖冲突的问题,原因在于Spring Boot 锁定了Netty的版本,Vertx也依赖了Netty:
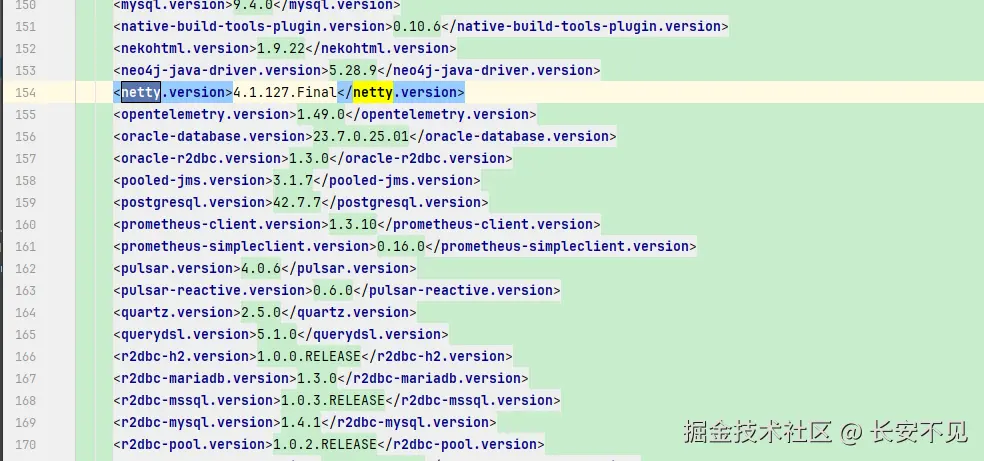
而Vertx 依赖Netty的版本是4.2.5,所以这里要注意对齐Netty的版本, 所以这里要对齐Netty的版本,在maven里面声明一下:
xml
<properties>
<java.version>17</java.version>
<netty.version>4.2.5.Final</netty.version>
</properties>首先我们用Vertx 写一个简单的WebServer:
java
public class SimpleWebServer extends AbstractVerticle {
@Override
public void start(Promise<Void> startPromise) throws Exception {
HttpServer server = vertx.createHttpServer();
Router router = Router.router(vertx);
router.get("/test-1").handler(ctx -> {
try {
// 注意这里的延时是为了测试队头阻塞问题,
// 为了模拟队头阻塞问题,看响应是否按顺序返回
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
HttpServerResponse response = ctx.response();
response.putHeader("content-type", "text/plain"); // 设置响应头
response.end("你好,这里是 /test-1 的响应!");
});
router.get("/test-2").handler(ctx -> {
HttpServerResponse response = ctx.response();
response.putHeader("content-type", "application/json");
JsonObject myJson = new JsonObject()
.put("message", "成功访问 /test-2")
.put("timestamp", System.currentTimeMillis());
response.end(myJson.encodePrettily());
});
router.get("/test-3").handler(this::handleTest3);
server.requestHandler(router);
server.listen(8080,"localhost");
super.start(startPromise);
}
private void handleTest3(RoutingContext ctx) {
HttpServerResponse response = ctx.response();
response.putHeader("content-type", "text/plain; charset=utf-8");
response.end("你好, " + "! 欢迎来到 /test-3。");
}
public static void main(String[] args) {
Vertx vertx = Vertx.vertx();
vertx.deployVerticle(new SimpleWebServer());
}
}下面是客户端的代码:
java
HttpClientOptions options = new HttpClientOptions()
.setProtocolVersion(HttpVersion.HTTP_1_1)
.setPipelining(true)
.setPipeliningLimit(4);
Vertx vertx = Vertx.vertx(new VertxOptions().setWorkerPoolSize(40));
HttpClientAgent client = vertx.createHttpClient(options);
List<Future<HttpClientResponse>> futureList = new ArrayList<>();
RequestOptions requestOptionsOne = new RequestOptions()
.setMethod(HttpMethod.GET)
.setHost("localhost")
.setPort(8080)
.setURI("/test-1");
RequestOptions requestOptionsTwo = new RequestOptions()
.setMethod(HttpMethod.GET)
.setHost("localhost")
.setPort(8080)
.setURI("/test-2");
RequestOptions requestOptionsThree = new RequestOptions()
.setMethod(HttpMethod.GET)
.setHost("localhost")
.setPort(8080)
.setURI("/test-3");
List<RequestOptions> requestOptionsList = new ArrayList<>();
requestOptionsList.add(requestOptionsOne);
requestOptionsList.add(requestOptionsTwo);
requestOptionsList.add(requestOptionsThree);
for (int i = 0; i < 3; i++) {
Future<HttpClientResponse> responseFuture = client.request(requestOptionsList.get(i)).compose(HttpClientRequest::send);
futureList.add(responseFuture);
}
for (Future<HttpClientResponse> responseFuture : futureList) {
HttpClientResponse clientResponse = responseFuture.await();
Buffer bodyBuf = null;
try {
bodyBuf = clientResponse.body().toCompletionStage()
.toCompletableFuture()
.get();
String body = bodyBuf.toString("UTF-8");
System.out.println(body);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
}最终输出结果为:
bash
你好,这里是 /test-1 的响应!
{
"message" : "成功访问 /test-2",
"timestamp" : 1759046207167
}
你好, ! 欢迎来到 /test-3。可以看到Vertx的思路和我们想象的是一致的。 到现在我们总结一下,Http 1.0面临的问题,虽然在一个TCP连接上可以并发的发送报文,但是由于没有报文标识,报文请求和响应没办法形成对应关系,所以就只能要求请求报文排队被处理,然后按请求顺序返回。
那Http/2的解药就是改造Http 1.1的报文,为了解决请求和响应之间的映射关系,Http/2 为报文引入了标识符的概念:
Streams are identified with an unsigned 31-bit integer.
流由一个无符号的31位整数来标识
那什么是流? 在RFC 7540 我们可以看到对应的描述:
A "stream" is an independent, bidirectional sequence of frames exchanged between the client and server within an HTTP/2 connection.
一个"流"(Stream)是存在于一个HTTP/2连接内部的,客户端与服务器之间交换的一个独立的、双向的帧(Frame)序列
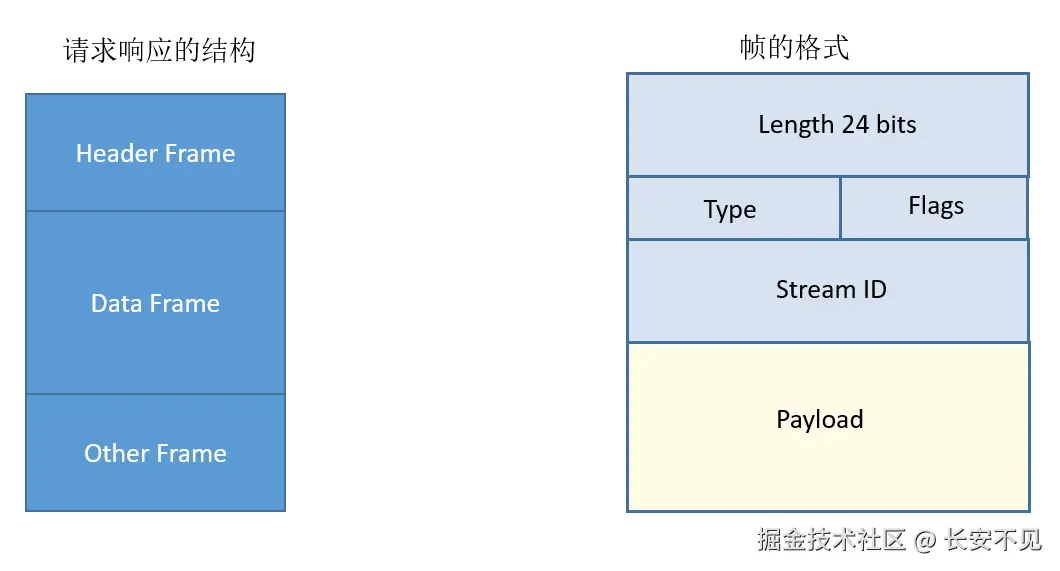
因为是服务器和客户端之间交换,所以是双向的,那帧是什么? 帧是HTTP/2的基本单元,HEADERS(头部)帧 和DATA(数据)帧 构成了HTTP请求和响应的基础,其他类型的帧,如SETTINGS 、**WINDOW_UPDATE*和*PUSH_PROMISE,则用于支持HTTP/2的其他各项功能。这也就是HTTP/2的另一个重要特性: 基于二进制的协议。
Tomcat对流水线的支持
按道理测试应该结束了,但是我还想测试一下Tomcat对流水线的支持是怎么样的,Tomcat对流水线的支持见参考链接5关于maxKeepAliveRequests的说明:
The maximum number of HTTP requests which can be pipelined until the connection is closed by the server.
直到连接被关闭之前,这个连接可以被管线化发送HTTP请求的最大数量。
Setting this attribute to 1 will disable HTTP/1.0 keep-alive, as well as HTTP/1.1 keep-alive and pipelining.
将此属性设置为1将会禁用HTTP/1.0的keep-alive功能,以及Http/1.1的keep-alive和流水线功能。
Setting this to -1 will allow an unlimited amount of pipelined or keep-alive HTTP requests. If not specified, this attribute is set to 100.
将这个值设置为-1表示在流水线上不限制最大请求数量,如果没有具体设置,那么这个属性是100。
遗憾的是我用vertx向Tomcat发流水线支持
二进制的协议
熟悉HTTP协议的同学可能会有点印象,HTTP/1.1是基于文本的,那这个基于文本的是什么意思? 底层不都是二进制嘛? 在Java里面,我们可以通过String,将字符串转成字节数组。本质上就是二进制式的。那HTTP/2的二进制式是什么意思?我们在RFC-7540里面可以看到,相同的报文在1.1和2.0格式之间的区别:
ini
// request line
GET /resouce HTTP/1.1 HEADERS
// request header
Host: example.org ==> + END_STREAM
Accept: image/jpeg + END_HEADERS
:method = GET
:scheme = https
:path = /resource
host = example.org
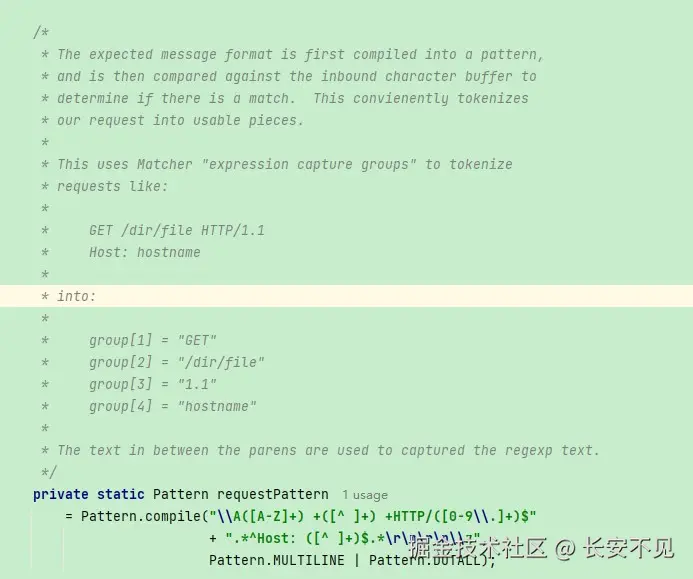
accept = image/jpeg注意我们在解析HTTP/1.1的时候是通过\r\n,分别拿出请求头不同类型比如host、accept。 然后我们可以用正则表达式分别取出报文里面的各个类型的字段,但正则表达式性能很差,Tomcat是一个字符一个字符读取,读完请求行, 读请求头, 读请求体。·在Oracle 给的JDK 8示例中,有一个用新特性写的HTTP Server,用的是正则来分割:
Tomcat则是一个部分,一个部分的截取,在Http11Processor中我们可以看到这一点:
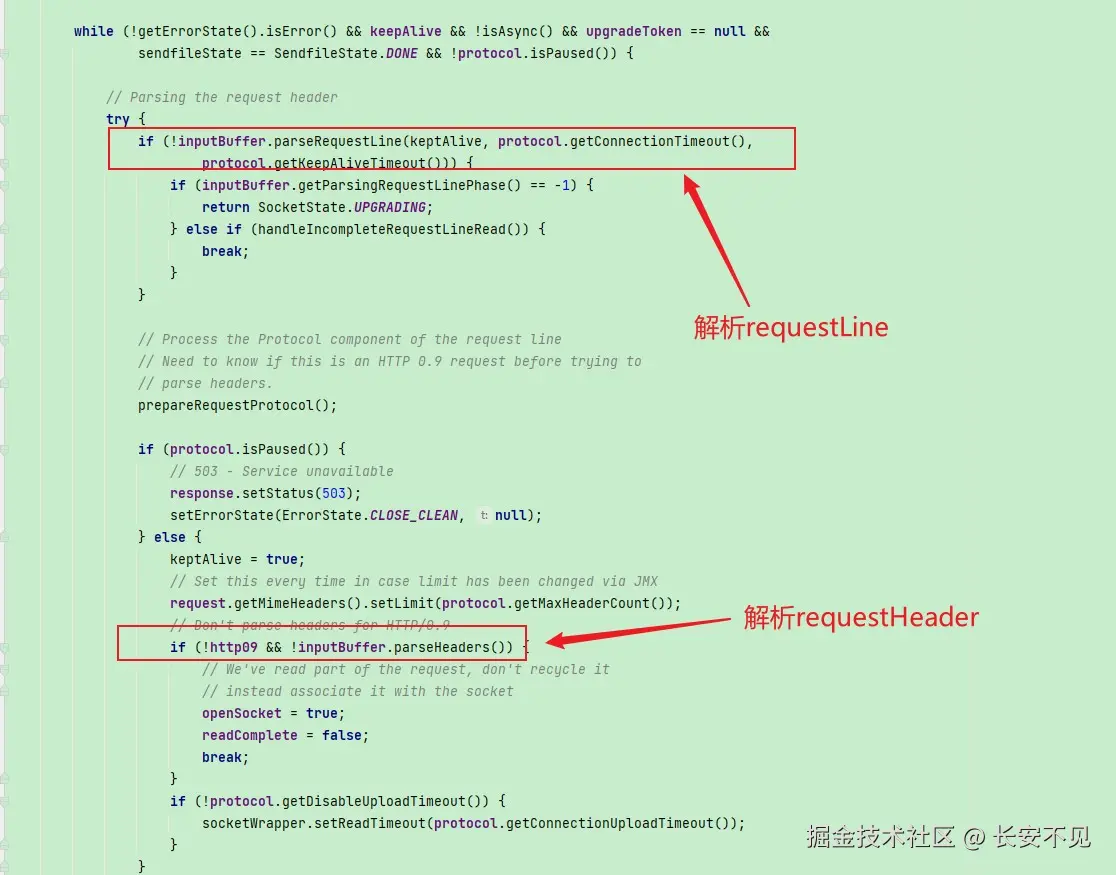
等等,你讲了这么多,还是没讲清楚这个二进制协议是个什么意思, 只是看起来换了一种格式,原先的字符串变换成了Map(存储k-v对的集合)一样。是的二进制格式的语义就是将原先基于文本的报文变成了更加紧凑的报文格式,在解析HTTP/2报文的时候我们根据type就能知道当前的帧是哪种类型,是header 还是 data。
由于HTTP是无状态的,所以就算是相同的请求地址,我们每次请求都得带上和上一次请求相同的请求头,这无疑也有些浪费带宽,由此就引出了压缩对象头。
压缩请求头
HTTP/2 引入了一个静态表,这个静态表是预定义的头字段静态列表组成,比如method、status等等。静态表是只读的。原本我以为动态表维护的是若干key-value对,在一开始value是没有值的,在第一次通信之后,请求方式填值,后面发送请求的时候,发送列表的索引即可。实际的是静态表已经维护了这些key-value对,通信的过程中只需要发送对应的下标即可:
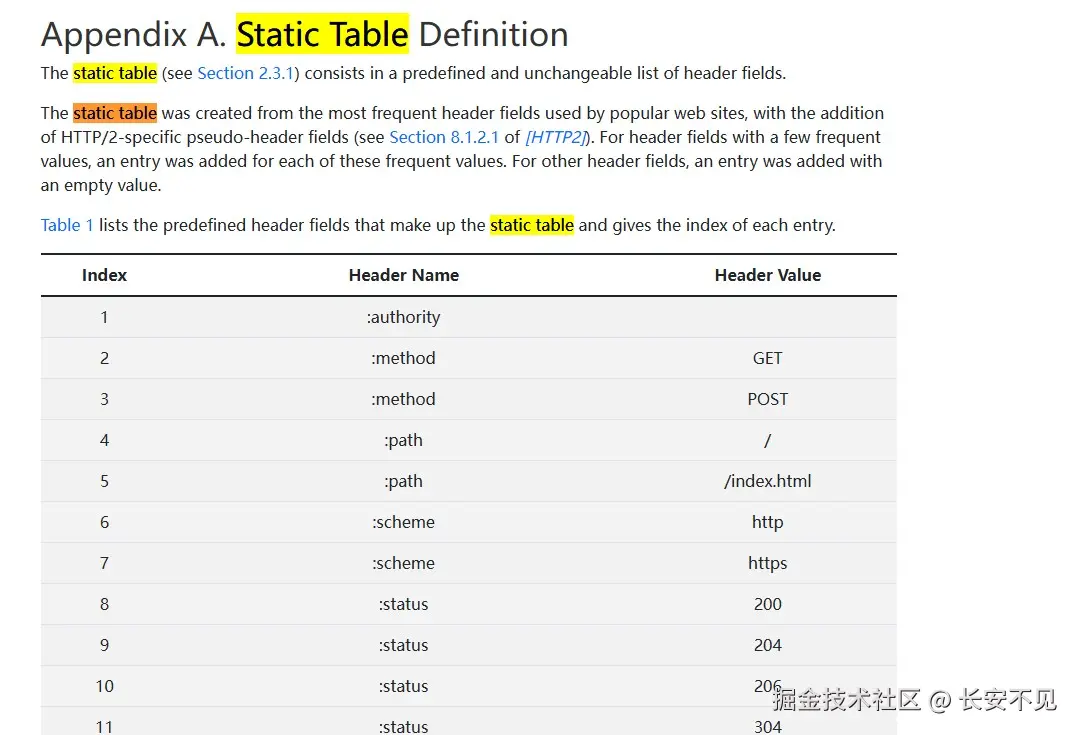
注意到不是所有的请求头的值都是预定义好的,比如cookie,HTTP/2还引入了霍夫曼编码对请求值的字符串进行压缩。动态表这是一个连接期间由客户端和服务端共同维护的表,动态表由一个"先进先出"顺序维护的头部字段列表组成。动态表中最先加入位于最低的索引位置,动态表中最老的位于最高的位置。
多路复用
于是现在我们就可以解决队头阻塞问题了,因为有了流的ID,我们甚至可以做到更进一步,将一个HTTP请求拆成多个流, 也就是请求头流、数据流、其他流,我们可以认为流就是带上了streamID的帧。
那该如何兼容从前
现在我们是客户端要和服务端通信,由于HTTP/2和HTTP/1.1的报文格式都发生了改变,所以就需要确定通信的时候使用哪个版本进行通信。除此之外,在标准制定的时候,大家都将TLS标记为HTTP/2可选的组件,这一点是有点出人意料的,原因在于HTTP/2脱胎于google的SPDY,而SPDY又强依赖TLS。但是Firefox和Chrome都明确地表示,他们只会实现基于TLS的http2. 选择TLS的原因是希望保护以及尊重用户的隐私。
所以HTTP/2就有两个版本,一个是HTTP/2 Cleartext 也就是明文版的HTTP/2, 简称为H2C,另一个是基于TLS的HTTP/2。 但是引入TLS,就会有额外加密解密的成本,这往往对于服务间调用的不必要的,这也就是本篇文章的主题,在服务之间的调用使用H2C来提升性能。
这在日常生活中也很常见,假设我们有一个支持120W的充电头,那给手机充电的时候,充电头会直接上120w的充电功率嘛?当然不会他们会首先进行握手,握手的一刻,充电头会进行上报自己支持的充电协议,手机会从中选择自己支持的协议回复给充电头,然后开始充电。
对此客户端会先会首先给出自己支持的协议版本,这也就是Application-Layer Protocol Negotiation,客户端先发送一个协议优先级列表给服务器,由服务器最终选择一个合适的协议版本。这个协商的基础是建立在TLS之上的,现在是一个HTTP1.1的网站,没有TLS,TCP连接建立之后,那该发送什么格式的报文? 对此的解决方案是客户端先使用HTTP/1.1的报文格式,然后发送一个请求升级协议的请求头:Upgrade: h2c
makefile
GET / HTTP/1.1
Host: server.example.com
Connection: Upgrade, HTTP2-Settings
Upgrade: h2c
HTTP2-Settings: <base64url encoding of HTTP/2 SETTINGS payload>这表明客户端希望升级到H2C,如果服务器支持,就响应101,连接升级到h2c。如果一个老旧的服务器不认识这个请求头,它会根据规范忽略这个它不认识的头部,返回一个标准的响应200。这样保证即使升级失败,也不影响后续的通信。
但如果你先验的确认服务端支持H2C,就可以避免这个升级的过程,这也被称为先验的方式支持h2c(prior knowledge)。
走向HTTP/3简介
HTTP/1.1 连接上的队头阻塞问题被HTTP/2解决之后,下一个问题就是TCP层的队头阻塞问题,所谓TCP层的队头阻塞问题。TCP处理数据时有严格的前后顺序,先发送的要先被处理。举个例子: 在一个TCP连接上,我们发送了四个Stream,Stream1、Stream3、Stream4都到了,但是Stream2的第三个frame丢失了,于是接收方要求发送方重传,Stream3和Stream4虽然到达但是不能被处理。那么这时整条TCP连接上排在Stream2之后的报文都被阻塞。
HTTP/3的解药是加强了UDP,也就是QUIC ,UDP 的数据包在接收端没有处理顺序,即使中间丢失一个包,也不会阻塞整条连接,其他的资源会被正常处理。
现在大型网站的架构
现在我们可以来聊一下网站的架构演进,一般我们会有若干微服务,微服务前面会有一个网关,这个网关是流量的入口。但是我们为了保护我们的内网IP,我们一般会用Nginx做反向代理,同时做一个静态服务器资源服务器。
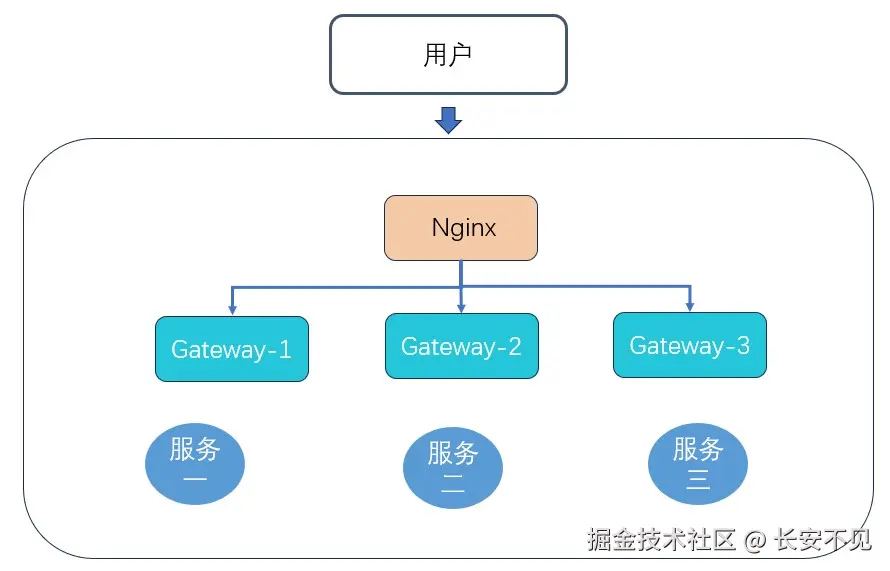
但是往往单机不太牢靠,为了提升整体的可靠性,我们采取了主从的结构,我们期待的是假设主节点挂掉之后,从节点升级为主节点。这也就引出了Keepalived。有了keepAlived之后, 主节点因为意外挂掉之后,从节点就能接管流量。但是很快我们的流量越来越大,单台Nginx已经没有办法再满足我们的要求了,于是我们想到了Nginx集群。
那谁对Nginx进行负载均衡? 这也就引出了HAProxy,HAProxy可以对流量进行转发, 做健康检查。 可能有同学还是会问,如果单台HAProxy还是不够用怎么办? 这里就引出了LVS还有ECMP来分发流量,当然也可以直接向云厂商购买此类服务。
这不是我们本篇的重点,我们不做过多介绍。现在流量涌入之后走HTTP/2, Nginx转发到GateWay这里又降级成了HTTP/1.1, 这无疑是一个性能瓶颈,因此我们的设想是在流量进入到内部服务的时候走h2c。服务之间的调用也尽可能的走h2c, 如果内部服务的调用是Feign的话。本篇我们演示的是在服务调用之间启用H2C,服务从负载均衡到网关这一块,需要不少组件,有些庞大,这里只是做一个理论的推测。目前看Nginx转发的时候是不支持HTTP 2C的, proxy_version 最高只到1.1。
我们只能将目光转向别的反向代理服务器,比如caddy。或者是envoy,在参考文档10 可以看到envoy是支持代理到上游的时候支持HTTP/2C的。这里我并没有做实际的验证,仅仅论证的是理论上的可行性。
如何在Spring Boot 中启用HTTP/2c
如何观测和验证
现在我们有了理论,现在我们来验证我们的猜想,首先我们要知道Tomcat对HTTP/2C的支持,这点我们可以在Tomcat的文档里面可以看到:

也就是说Tomcat是支持H2C的,但是JDK 8 不支持 ALPN机制意味着不能使用基于TLS的HTTP/2协议。 那怎么知道我们成功启用了HTTP/2C呢? 我们通过观测Tomcat的日志来验证。在Spring Boot的配置文件里面加上下面的配置:
ini
logging.level.org.apache.coyote=TRACE我们就能观测到Tomcat解析报文的过程。注意在Spring Boot 2.0的时候我们采用curl来发送HTTP/2的请求报文来验证。 注意在Spring Boot 2.0的文档里面指出 Spring Boot 2.x的文档指出 不支持h2c, 见参考文档7 , 但是实际是支持的,我们可以在参考文档8 里面可以看到这一点:
The documentation is probably worded a bit too strongly at the moment. What it really means is that there's no support for enabling h2c via configuration properties.
You can still do so by adding a little bit of your own configuration. For example, the following customiser will enable h2c with Tomcat
java
@Bean
public TomcatConnectorCustomizer customizer() {
return (connector) -> connector.addUpgradeProtocol(new Http2Protocol());
}根据我实际的测试,Spring Boot 2.7.14也是能够支持直接开启H2c的,不需要通过这个Bean配置。
Spring Boot 启用H2C
通过一行配置启用即可:
xml
server.http2.enabled=true
server.ssl.enabled=false然后我们使用curl来验证请求:
bash
curl --http2-prior-knowledge http://localhost:9090/test注意这里我电脑的curl版本有点问题,所以我这里用Vertx来验证:
java
Vertx vertx = Vertx.vertx();
WebClientOptions options = new WebClientOptions()
.setSsl(false)
// 这里直接用H2的报文,不用从Http/1.1升级到H2C。
.setHttp2ClearTextUpgrade(false)
.setSslEngineOptions(new JdkSSLEngineOptions())
.setUseAlpn(false)
.setProtocolVersion(HttpVersion.HTTP_2);
WebClient client = WebClient.create(vertx, options);
client.get(9090, "localhost", "/test")
.send()
.onSuccess(response ->
System.out.println(response.bodyAsString()))
.onFailure(err ->
System.out.println(err.getMessage()));然后我们观测日志:

常见的HTTP Client 启用H2C
我们这里只讲OkHttp,首先我们引入依赖:
java
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>下面是代码:
java
OkHttpClient client = new OkHttpClient.Builder()
.protocols(Collections.singletonList(Protocol.H2_PRIOR_KNOWLEDGE))
.build();
Request request = new Request.Builder()
.url("http://localhost:8080/test")
.build();
Response response = client.newCall(request).execute();
System.out.println("Protocol used: " + response.protocol());实测通过,Tomcat里面输出了Http/2的标志。然后我们就能在一般的Spring Cloud 项目中让服务之间的调用使用H2C了。
总结一下
本篇的思路是先从HTTP/1.1的队头阻塞问题开始,所谓队头阻塞说的是HTTP/1.1引入的流水线特性,流水线特性从字面上特性来说就是允许客户端在收到上一个请求对应的响应之前发送下一个响应,其实表达的应当是将多个HTTP请求报文在一条TCP连接上批量发送。但是由于没有报文ID,不知道请求和响应的对应关系,所以HTTP协议标准规定响应按顺序返回。
但如果第一个请求处理时间比较长,那么就算是其他请求已经被处理,也需要让第一个请求处理完,然后按顺序返回。对此HTTP/2的解药是,为报文加上了ID。注意到HTTP是无状态的,这意味着相同的接口,每次都会带上相同的请求头,比如请求方式等等。对此HTTP/2的解药是引入静态表和动态表,静态表统计了常用的请求头,在发送的时候只需要发送索引就可以了。而如果你有不在静态表的请求头,可以用动态表,比如cookie,但有时候cookie的内容比较大,于是HTTP/2引入了哈夫曼编码进行压缩。
除此之外,由于HTTP/1.1 是基于文本的,基于文本的我们姑且就可以理解为字符串,我们解析的时候就要按规则去截取,但是用正则又比较影响性能,主流的HTTP服务器都是从字节数组挨个解析。HTTP/2引入了更换了报文的格式,我们通过frame的类型和长度就能知道该读多少,确定的格式解析效率更高。
但是HTTP/2在指定过程中,为了保护隐私,主流的服务器厂商实现的都是基于TLS的HTTP/2, 尽管这在标准中是可选的,没有TLS的HTTP/2 也被称之为HTTP/2C。
但如何兼容从前呢,HTTP标准规定,从HTTP/1.1升级到HTTP/2, 头一次先放松一个请求升级的报文,也就是报文里面带上, upgrade: h2c。但如果你知道对面的服务器是支持H2C的,就可以省掉这个加密过程。我们希望流量从负载均衡走到我们服务的过程中,都是H2C,这是我们本篇的目标。我们在探索的过程中发现,Spring Boot 的官方文档有点问题,其实Spring Boot 2.x是可以通过配置开启的。
如果你的服务端是微服务,且用的是Spring Cloud Open Feign来实现远程调用,那么我们可以通过替换HTTP Client, 来实现服务之间调用用HTTP/2C。但Nginx做反向代理的时候是不支持转发到服务上是H2C的,我们不得已只能换别的反向代理服务器。
参考资料
1 HTTP的现状 http2-explained.haxx.se/zh/part2
2 datatracker.ietf.org/doc/html/rf...
3 bugzilla.mozilla.org/show_bug.cg...
4 developer.mozilla.org/en-US/docs/...
5 tomcat.apache.org/tomcat-8.0-...
6 一文带你浅入浅出Keepalived zhuanlan.zhihu.com/p/566166393
7 docs.spring.io/spring-boot...
9 caddyserver.com/docs/caddyf...
10 www.envoyproxy.io/docs/envoy/...
11 HTTP/3 原理实战 zhuanlan.zhihu.com/p/143464334