一、后端核心配置:决定下载的 "基础规则"
后端通过 HTTP 响应头控制文件的传输行为,这是所有下载逻辑的起点,关键配置有 3 个:
1. Content-Disposition:控制 "下载" 或 "预览"
-
配置 1(强制下载) :
cssContent-Disposition: attachment; filename="file.xlsx"- 作用:告诉浏览器 "这是一个需要下载的附件",无论文件类型是什么(图片 / PDF/Excel),都会直接触发下载弹窗。
- 细节:
filename指定默认下载文件名,支持 UTF-8 编码(需处理中文:filename*=UTF-8''%E6%88%91%E7%9A%84%E6%96%87%E4%BB%B6.xlsx)。
-
配置 2(在线预览) :
scalaContent-Disposition: inline- 作用:告诉浏览器 "直接在页面内预览文件",比如图片直接显示、PDF 在浏览器打开、TXT 直接渲染。
- 细节:若不设置该字段,浏览器会根据
Content-Type自动判断(图片 / PDF 默认预览,Excel / 压缩包默认下载)。
2. Content-Type:定义文件的 "类型标识"
-
作用:告诉浏览器文件的 MIME 类型,决定浏览器如何解析文件(即使配置了
attachment,浏览器也会根据类型处理下载)。 -
常见配置: # Excel 文件 Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet # PDF 文件 Content-Type: application/pdf # 图片 Content-Type: image/jpeg # 二进制流(通用,推荐大文件) Content-Type: application/octet-stream
-
关键:若后端返回
application/octet-stream(二进制流),浏览器会直接判定为 "可下载文件",优先级高于inline。
3. Content-Length:提供文件的 "总大小"
-
配置:
yamlContent-Length: 10485760 # 表示文件大小为 10MB -
作用:告诉前端文件的总字节数,是前端计算下载进度的必要条件(没有这个头,前端无法知道 "总大小",只能显示 "已下载字节",无法算百分比)。
-
注意:若后端用 "分块传输"(
Transfer-Encoding: chunked),则不会返回Content-Length,前端无法计算进度。
4. 其他辅助配置
Accept-Ranges: bytes:支持断点续传,前端可请求文件的某一部分(Range: bytes=0-1023),适合大文件分段下载。Access-Control-Expose-Headers: Content-Length:跨域场景下,允许前端读取Content-Length等响应头(否则前端拿不到总大小)。
二、前端下载方式:根据需求选择 "策略"
前端有 3 种主流下载方式,对应不同场景,和后端配置直接关联:
方式 1:原生 <a> 标签(最简单,无进度)
-
用法:
ini<a href="/api/download/file" download="自定义文件名.xlsx">下载</a> -
适用场景 :后端已配置
Content-Disposition: attachment,且无需监控进度(小文件、对进度无要求)。 -
和后端配置的关联:
- 若后端配了
attachment:点击直接下载,download属性可自定义文件名(优先级高于后端的filename)。 - 若后端配了
inline:浏览器会预览文件,此时加download属性可强制触发下载(部分浏览器支持)。
- 若后端配了
-
局限性:无法监控进度、无法处理复杂逻辑(如权限验证、Token 携带)。
方式 2:window.open()(和 <a> 标签类似)
-
用法:
javascriptwindow.open('/api/download/file?token=xxx'); -
适用场景:需要携带参数(如 Token)的下载,或需要新开窗口处理。
-
缺点:同样无法监控进度,且可能被浏览器拦截(弹窗拦截)。
方式 3:AJAX/fetch + Blob(支持进度,最灵活)
-
核心逻辑:前端主动请求文件二进制流,监控传输过程,最后模拟下载。
-
和后端配置的关联:
- 后端需返回二进制流(
Content-Type: application/octet-stream或对应文件类型)。 - 若后端配了
Content-Length,可计算精确进度;否则只能监控 "已下载字节"。
- 后端需返回二进制流(
-
完整代码示例(带进度) :
ini// 1. 创建请求对象 const xhr = new XMLHttpRequest(); xhr.open('GET', '/api/download/large-file.zip', true); xhr.responseType = 'blob'; // 关键:以 Blob 接收响应 // 2. 监控进度 xhr.addEventListener('progress', (e) => { if (e.lengthComputable) { const progress = (e.loaded / e.total) * 100; // 进度百分比 console.log(`下载进度:${progress.toFixed(2)}%`); // 更新 UI:比如进度条宽度、文字提示 document.getElementById('progress-bar').style.width = `${progress}%`; } else { console.log(`已下载:${e.loaded} 字节`); // 无总大小,只能显示已下载 } }); // 3. 请求成功:生成下载链接 xhr.addEventListener('load', () => { if (xhr.status === 200) { const blob = xhr.response; const url = URL.createObjectURL(blob); const a = document.createElement('a'); a.href = url; a.download = '大文件.zip'; // 自定义文件名 a.click(); URL.revokeObjectURL(url); // 释放内存 } }); // 4. 发送请求(可携带 Token) xhr.setRequestHeader('Authorization', 'Bearer ' + token); xhr.send(); -
优势:
- 可监控实时进度;
- 可携带自定义请求头(如 Token),处理权限验证;
- 可中断请求(
xhr.abort()); - 可处理后端返回的错误(如权限不足时,后端返回 JSON 而非文件,前端可捕获)。
三、下载进度的关联逻辑:为什么只有 Blob 方式能监控?
进度监控的核心是前端能感知 "数据传输的每一步" ,这和请求方式直接相关:
1. <a> 标签 /window.open():进度 "不可见"
-
这两种方式是浏览器直接和后端通信,前端 JS 被排除在传输过程之外:
- 浏览器接收到后端的响应头后,直接启动下载进程,JS 无法获取 "已下载多少字节""总字节数"。
- 相当于 "把下载交给浏览器,前端只能等结果",自然无法监控进度。
2. AJAX/fetch + Blob:进度 "可感知"
-
这种方式是前端 JS 主动和后端通信,数据先流经 JS,再交给浏览器:
- 后端以 "流" 的形式分段返回数据,每返回一段,就触发
progress事件; - 事件对象
e包含loaded(已接收字节)和total(总字节,来自Content-Length),前端可实时计算进度; - 所有数据接收完成后,JS 将二进制流封装成 Blob,再模拟
<a>标签下载。
- 后端以 "流" 的形式分段返回数据,每返回一段,就触发
3. 进度监控的关键前提
- 后端必须返回
Content-Length(否则e.lengthComputable为false,无法算百分比); - 后端不能用 "分块传输"(
Transfer-Encoding: chunked),否则无Content-Length; - 跨域时,后端需配置
Access-Control-Expose-Headers: Content-Length,否则前端拿不到total。
四、完整关联链总结
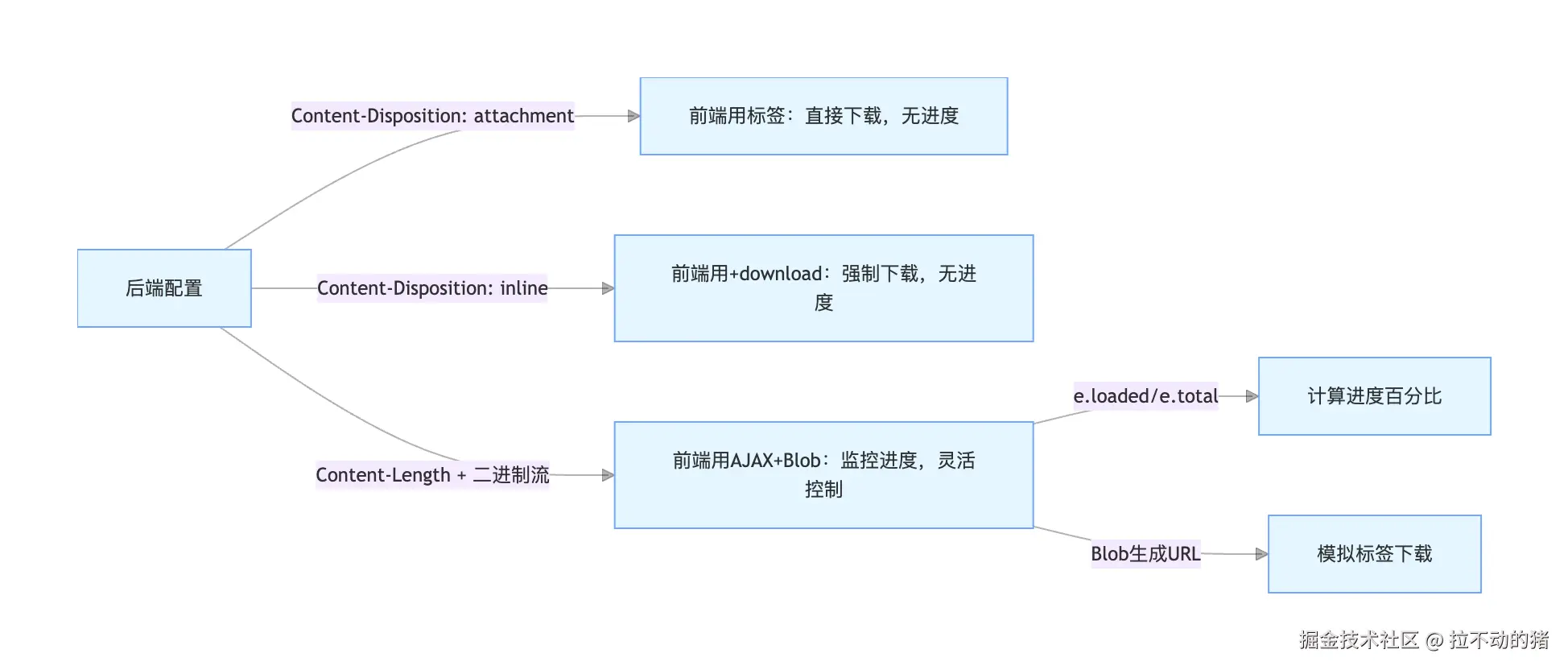
核心关键点回顾
- 后端是基础 :
Content-Disposition决定默认行为,Content-Length决定能否算进度,Content-Type决定文件解析方式。 - 前端选方式 :小文件 / 无进度需求用
<a>标签,大文件 / 需进度用 AJAX+Blob。 - 进度靠流控 :只有让文件以二进制流形式流经前端 JS,才能捕获传输进度,
<a>标签做不到这一点。
简单说:后端定 "规则",前端选 "策略",进度靠 "流控"------ 这就是三者的核心关联!